 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Attention Mechanism for Contrastive Learning in GAN-based Image-to-Image Translation
Feb 23, 2023
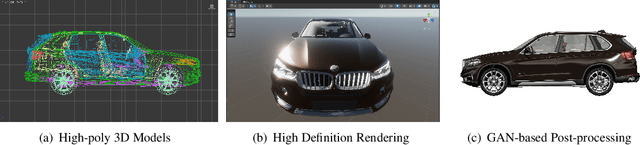

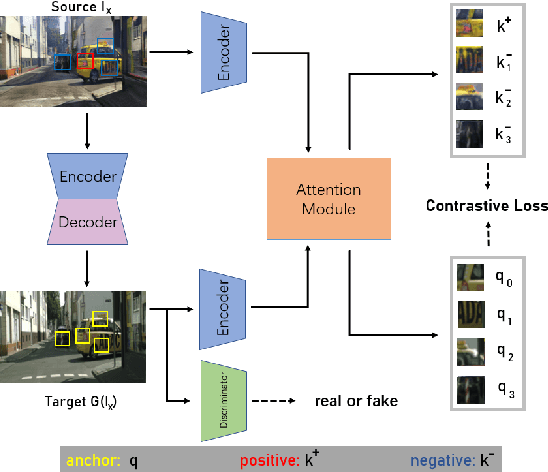
Using real road testing to optimize autonomous driving algorithms is time-consuming and capital-intensive. To solve this problem, we propose a GAN-based model that is capable of generating high-quality images across different domains. We further leverage Contrastive Learning to train the model in a self-supervised way using image data acquired in the real world using real sensors and simulated images from 3D games. In this paper, we also apply an Attention Mechanism module to emphasize features that contain more information about the source domain according to their measurement of significance. Finally, the generated images are used as datasets to train neural networks to perform a variety of downstream tasks to verify that the approach can fill in the gaps between the virtual and real worlds.
DeepMAD: Mathematical Architecture Design for Deep Convolutional Neural Network
Mar 05, 2023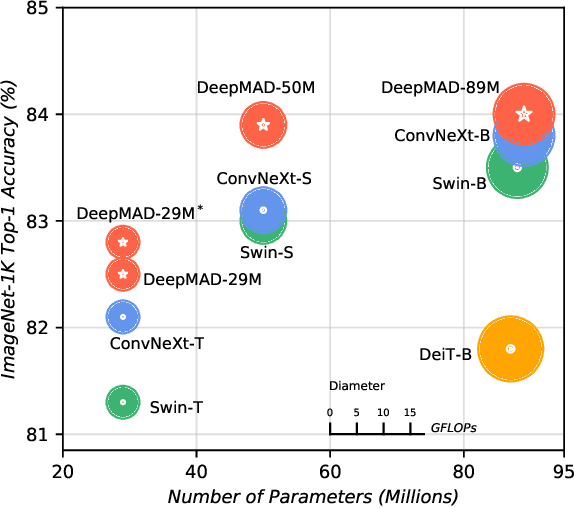
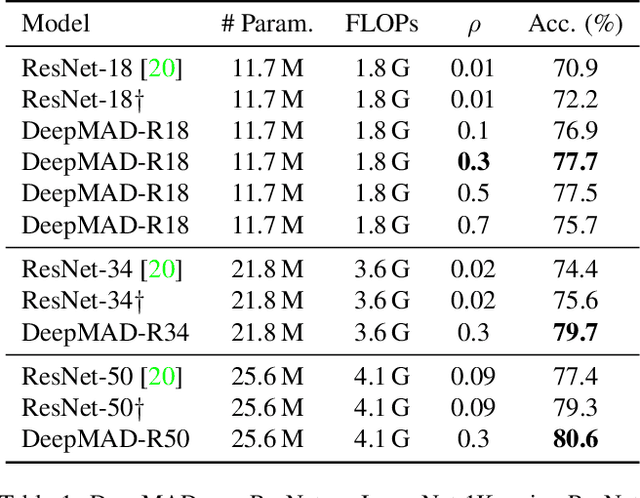
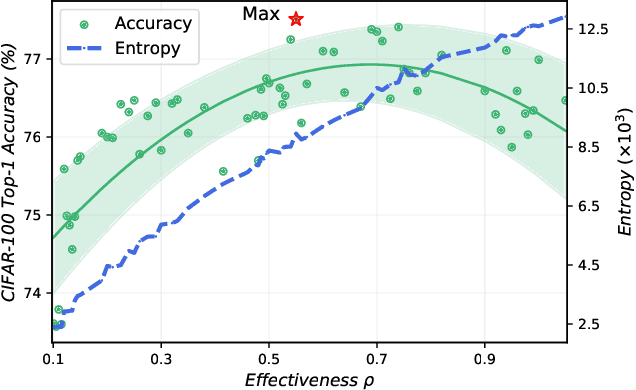
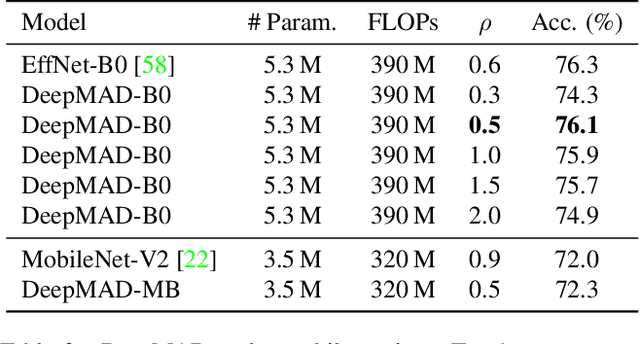
The rapid advances in Vision Transformer (ViT) refresh the state-of-the-art performances in various vision tasks, overshadowing the conventional CNN-based models. This ignites a few recent striking-back research in the CNN world showing that pure CNN models can achieve as good performance as ViT models when carefully tuned. While encouraging, designing such high-performance CNN models is challenging, requiring non-trivial prior knowledge of network design. To this end, a novel framework termed Mathematical Architecture Design for Deep CNN (DeepMAD) is proposed to design high-performance CNN models in a principled way. In DeepMAD, a CNN network is modeled as an information processing system whose expressiveness and effectiveness can be analytically formulated by their structural parameters. Then a constrained mathematical programming (MP) problem is proposed to optimize these structural parameters. The MP problem can be easily solved by off-the-shelf MP solvers on CPUs with a small memory footprint. In addition, DeepMAD is a pure mathematical framework: no GPU or training data is required during network design. The superiority of DeepMAD is validated on multiple large-scale computer vision benchmark datasets. Notably on ImageNet-1k, only using conventional convolutional layers, DeepMAD achieves 0.7% and 1.5% higher top-1 accuracy than ConvNeXt and Swin on Tiny level, and 0.8% and 0.9% higher on Small level.
Cross-Lingual Transfer of Cognitive Processing Complexity
Feb 24, 2023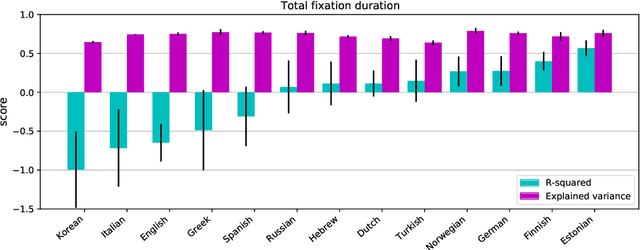
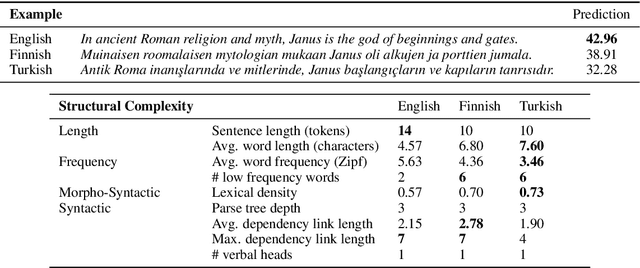
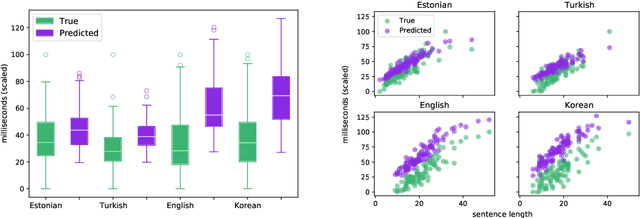
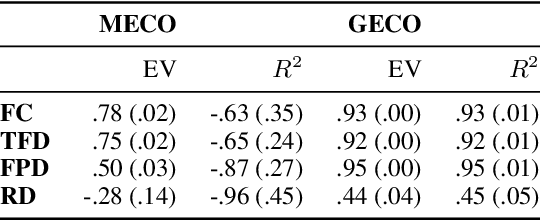
When humans read a text, their eye movements are influenced by the structural complexity of the input sentences. This cognitive phenomenon holds across languages and recent studies indicate that multilingual language models utilize structural similarities between languages to facilitate cross-lingual transfer. We use sentence-level eye-tracking patterns as a cognitive indicator for structural complexity and show that the multilingual model XLM-RoBERTa can successfully predict varied patterns for 13 typologically diverse languages, despite being fine-tuned only on English data. We quantify the sensitivity of the model to structural complexity and distinguish a range of complexity characteristics. Our results indicate that the model develops a meaningful bias towards sentence length but also integrates cross-lingual differences. We conduct a control experiment with randomized word order and find that the model seems to additionally capture more complex structural information.
Better Predict the Dynamic of Geometry of In-Pit Stockpiles Using Geospatial Data and Polygon Models
Feb 24, 2023

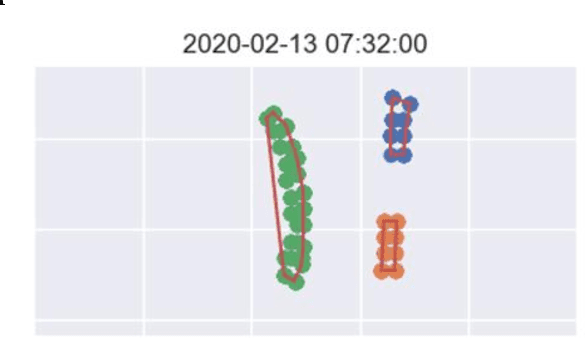
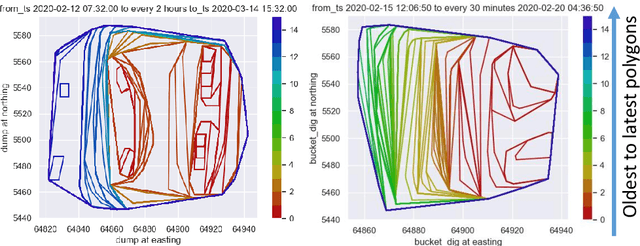
Modelling stockpile is a key factor of a project economic and operation in mining, because not all the mined ores are not able to mill for many reasons. Further, the financial value of the ore in the stockpile needs to be reflected on the balance sheet. Therefore, automatically tracking the frontiers of the stockpile facilitates the mine scheduling engineers to calculate the tonnage of the ore remaining in the stockpile. This paper suggests how the dynamic of stockpile shape changes caused by dumping and reclaiming operations can be inferred using polygon models. The presented work also demonstrates how the geometry of stockpiles can be inferred in the absence of reclaimed bucket information, in which case the reclaim polygons are established using the diggers GPS positional data at the time of truck loading. This work further compares two polygon models for creating 2D shapes.
Efficient Implicit Neural Reconstruction Using LiDAR
Feb 28, 2023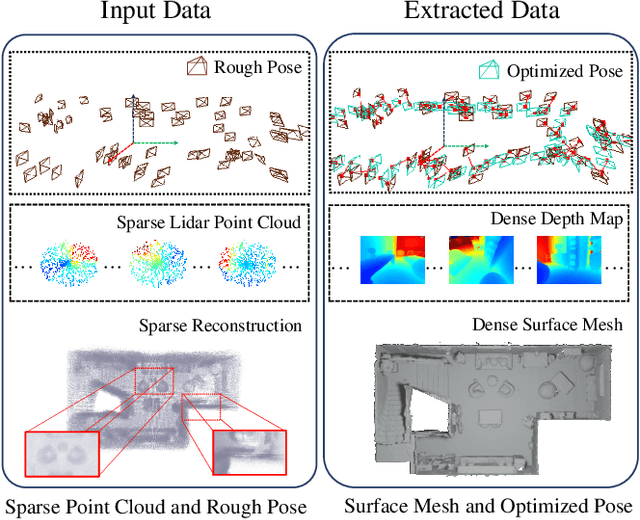
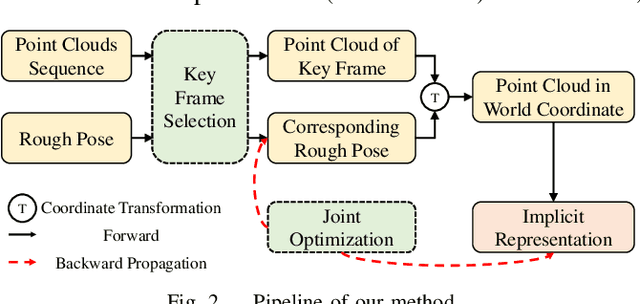
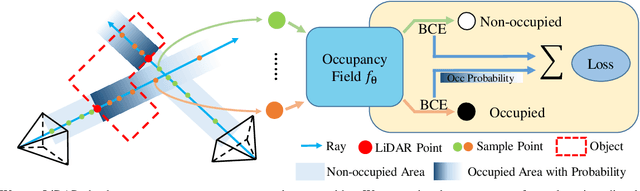
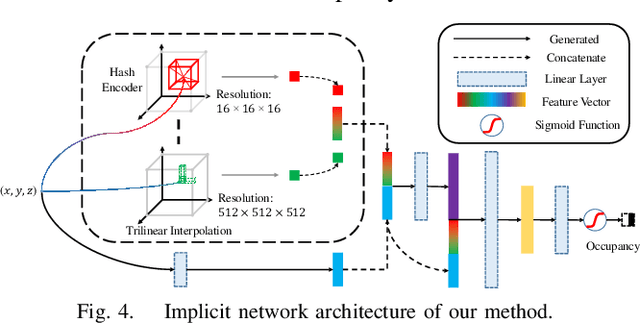
Modeling scene geometry using implicit neural representation has revealed its advantages in accuracy, flexibility, and low memory usage. Previous approaches have demonstrated impressive results using color or depth images but still have difficulty handling poor light conditions and large-scale scenes. Methods taking global point cloud as input require accurate registration and ground truth coordinate labels, which limits their application scenarios. In this paper, we propose a new method that uses sparse LiDAR point clouds and rough odometry to reconstruct fine-grained implicit occupancy field efficiently within a few minutes. We introduce a new loss function that supervises directly in 3D space without 2D rendering, avoiding information loss. We also manage to refine poses of input frames in an end-to-end manner, creating consistent geometry without global point cloud registration. As far as we know, our method is the first to reconstruct implicit scene representation from LiDAR-only input. Experiments on synthetic and real-world datasets, including indoor and outdoor scenes, prove that our method is effective, efficient, and accurate, obtaining comparable results with existing methods using dense input.
Improving Transformer-based Networks With Locality For Automatic Speaker Verification
Feb 28, 2023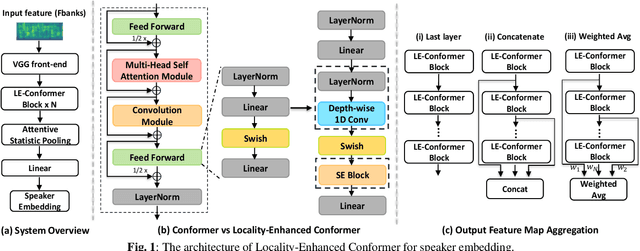
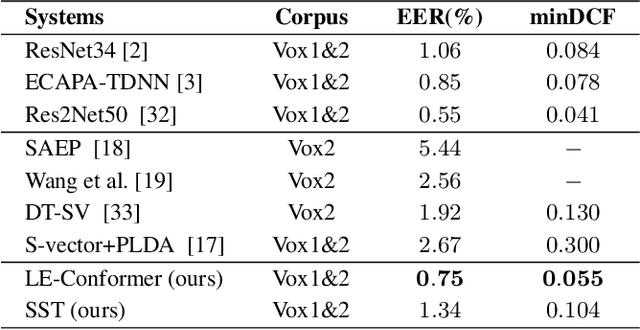
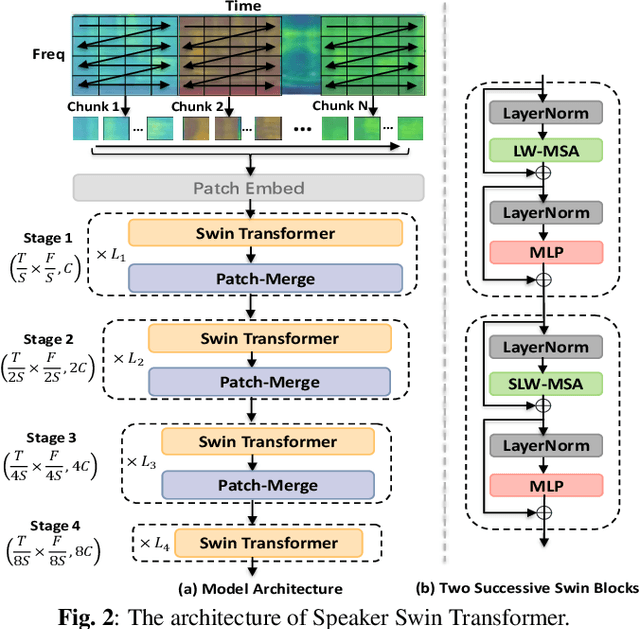
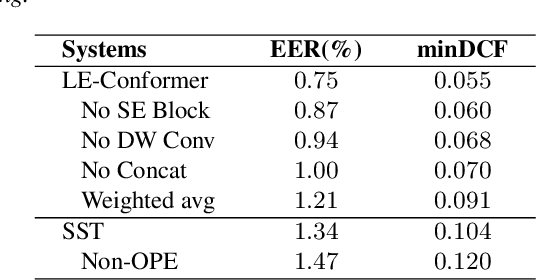
Recently, Transformer-based architectures have been explored for speaker embedding extraction. Although the Transformer employs the self-attention mechanism to efficiently model the global interaction between token embeddings, it is inadequate for capturing short-range local context, which is essential for the accurate extraction of speaker information. In this study, we enhance the Transformer with the enhanced locality modeling in two directions. First, we propose the Locality-Enhanced Conformer (LE-Confomer) by introducing depth-wise convolution and channel-wise attention into the Conformer blocks. Second, we present the Speaker Swin Transformer (SST) by adapting the Swin Transformer, originally proposed for vision tasks, into speaker embedding network. We evaluate the proposed approaches on the VoxCeleb datasets and a large-scale Microsoft internal multilingual (MS-internal) dataset. The proposed models achieve 0.75% EER on VoxCeleb 1 test set, outperforming the previously proposed Transformer-based models and CNN-based models, such as ResNet34 and ECAPA-TDNN. When trained on the MS-internal dataset, the proposed models achieve promising results with 14.6% relative reduction in EER over the Res2Net50 model.
Plan-then-Seam: Towards Efficient Table-to-Text Generation
Feb 28, 2023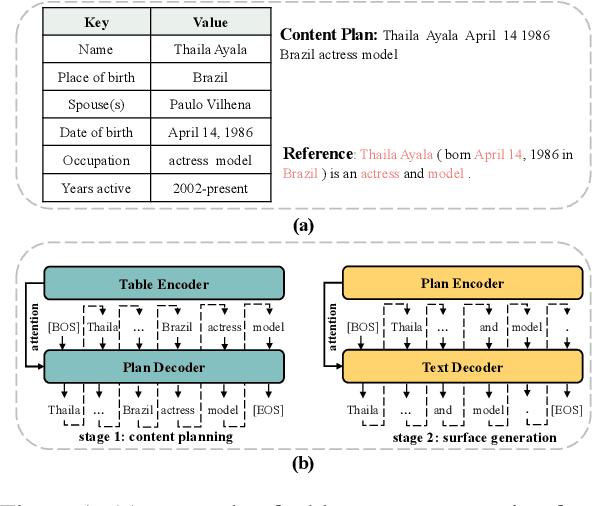
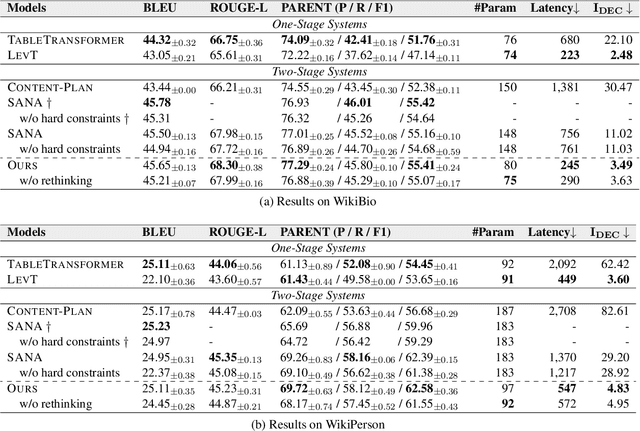
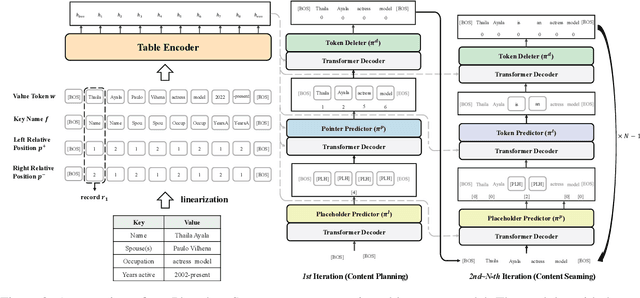

Table-to-text generation aims at automatically generating text to help people conveniently obtain salient information in tables. Recent works explicitly decompose the generation process into content planning and surface generation stages, employing two autoregressive networks for them respectively. However, they are computationally expensive due to the non-parallelizable nature of autoregressive decoding and the redundant parameters of two networks. In this paper, we propose the first totally non-autoregressive table-to-text model (Plan-then-Seam, PTS) that produces its outputs in parallel with one single network. PTS firstly writes and calibrates one plan of the content to be generated with a novel rethinking pointer predictor, and then takes the plan as the context for seaming to decode the description. These two steps share parameters and perform iteratively to capture token inter-dependency while keeping parallel decoding. Experiments on two public benchmarks show that PTS achieves 3.0~5.6 times speedup for inference time, reducing 50% parameters, while maintaining as least comparable performance against strong two-stage table-to-text competitors.
Completeness of Atomic Structure Representations
Feb 28, 2023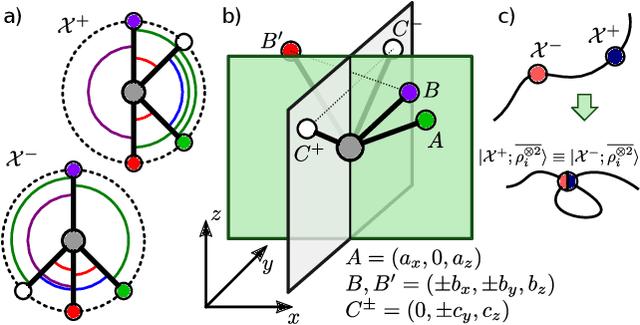
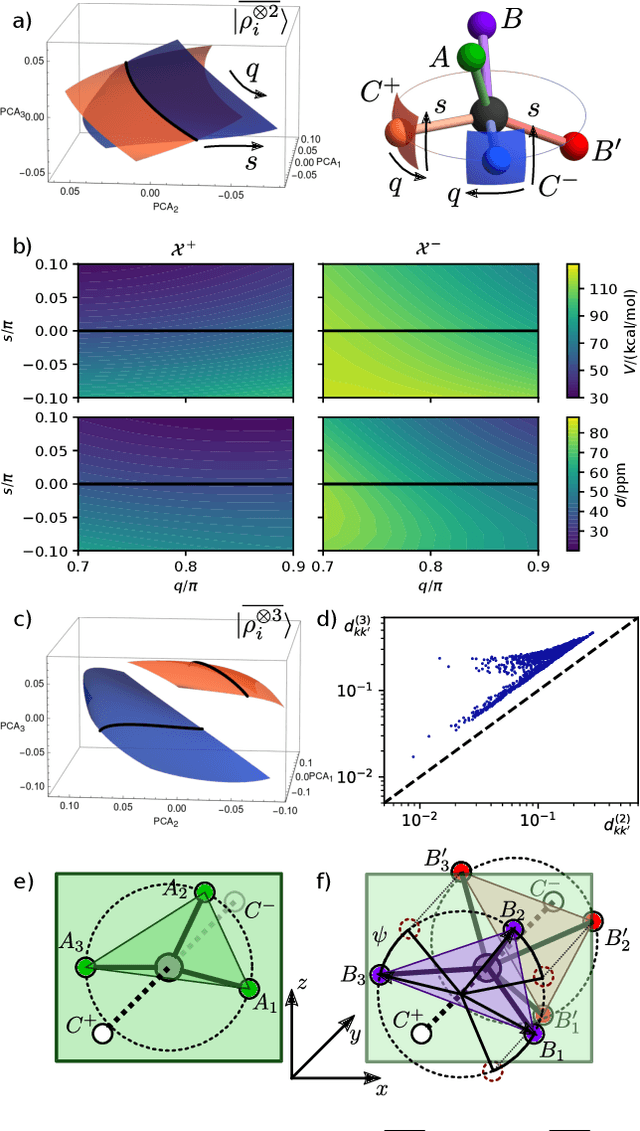
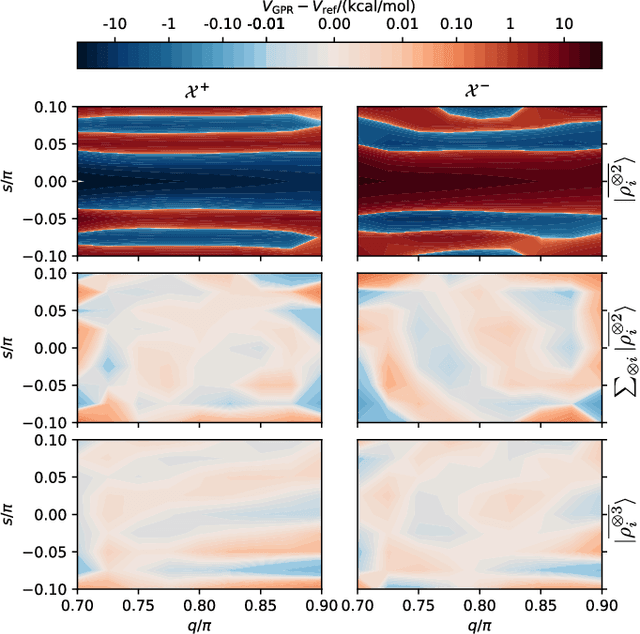
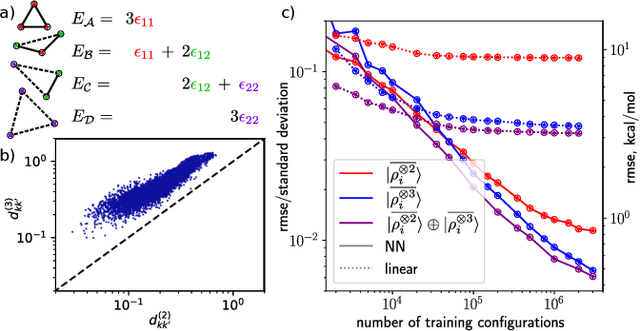
Achieving a complete and symmetric description of a group of point particles, such as atoms in a molecule, is a common problem in physics and theoretical chemistry. The introduction of machine learning to science has made this issue even more critical, as it underpins the ability of a model to reproduce arbitrary physical relationships, and to do so while being consistent with basic symmetries and conservation laws. However, the descriptors that are commonly used to represent point clouds -- most notably those adopted to describe matter at the atomic scale -- are unable to distinguish between special arrangements of particles. This makes it impossible to machine learn their properties. Frameworks that are provably complete exist, but are only so in the limit in which they simultaneously describe the mutual relationship between all atoms, which is impractical. We introduce, and demonstrate on a particularly insidious class of atomic arrangements, a strategy to build descriptors that rely solely on information on the relative arrangement of triplets of particles, but can be used to construct symmetry-adapted models that have universal approximation power.
Language-Universal Adapter Learning with Knowledge Distillation for End-to-End Multilingual Speech Recognition
Feb 28, 2023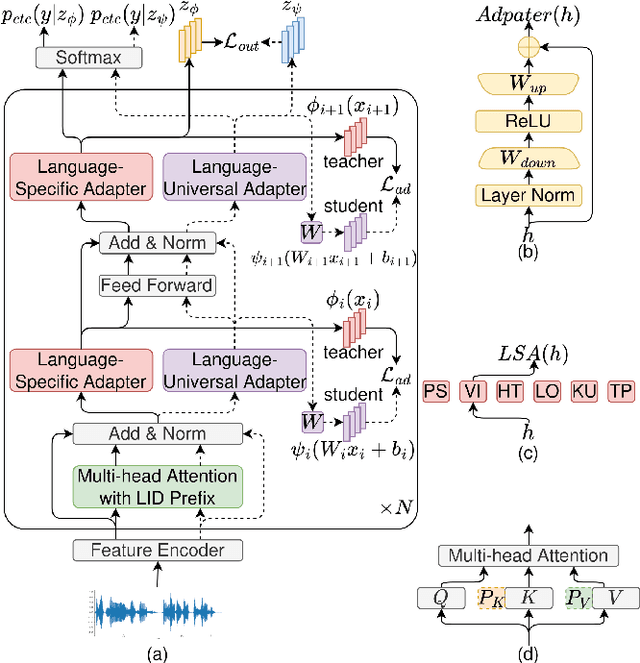
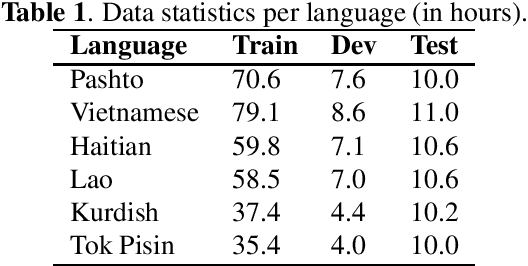
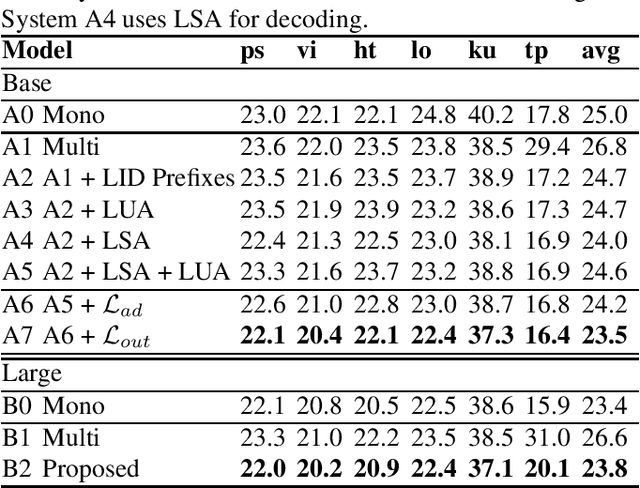

In this paper, we propose a language-universal adapter learning framework based on a pre-trained model for end-to-end multilingual automatic speech recognition (ASR). For acoustic modeling, the wav2vec 2.0 pre-trained model is fine-tuned by inserting language-specific and language-universal adapters. An online knowledge distillation is then used to enable the language-universal adapters to learn both language-specific and universal features. The linguistic information confusion is also reduced by leveraging language identifiers (LIDs). With LIDs we perform a position-wise modification on the multi-head attention outputs. In the inference procedure, the language-specific adapters are removed while the language-universal adapters are kept activated. The proposed method improves the recognition accuracy and addresses the linear increase of the number of adapters' parameters with the number of languages in common multilingual ASR systems. Experiments on the BABEL dataset confirm the effectiveness of the proposed framework. Compared to the conventional multilingual model, a 3.3% absolute error rate reduction is achieved. The code is available at: https://github.com/shen9712/UniversalAdapterLearning.
Your time series is worth a binary image: machine vision assisted deep framework for time series forecasting
Feb 28, 2023
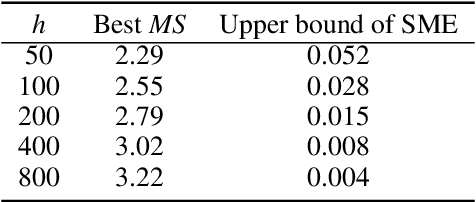
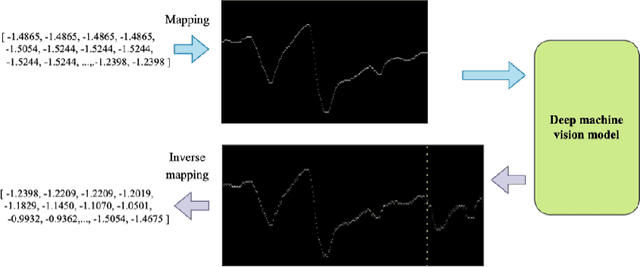

Time series forecasting (TSF) has been a challenging research area, and various models have been developed to address this task. However, almost all these models are trained with numerical time series data, which is not as effectively processed by the neural system as visual information. To address this challenge, this paper proposes a novel machine vision assisted deep time series analysis (MV-DTSA) framework. The MV-DTSA framework operates by analyzing time series data in a novel binary machine vision time series metric space, which includes a mapping and an inverse mapping function from the numerical time series space to the binary machine vision space, and a deep machine vision model designed to address the TSF task in the binary space. A comprehensive computational analysis demonstrates that the proposed MV-DTSA framework outperforms state-of-the-art deep TSF models, without requiring sophisticated data decomposition or model customization. The code for our framework is accessible at https://github.com/IkeYang/ machine-vision-assisted-deep-time-series-analysis-MV-DTSA-.