 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LaMPP: Language Models as Probabilistic Priors for Perception and Action
Feb 03, 2023
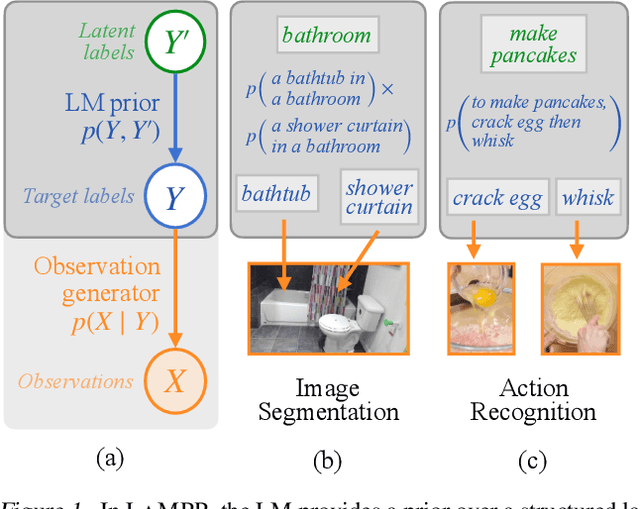
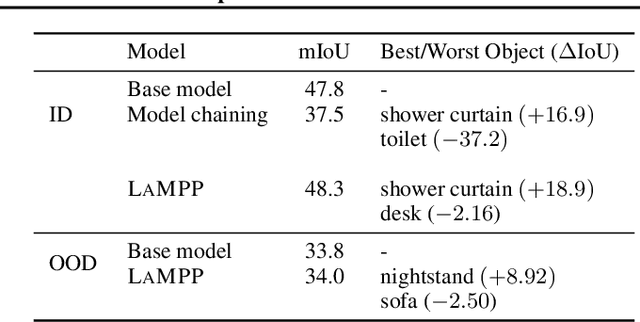
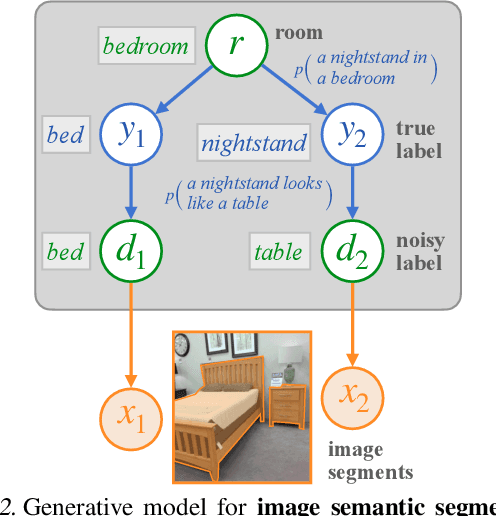
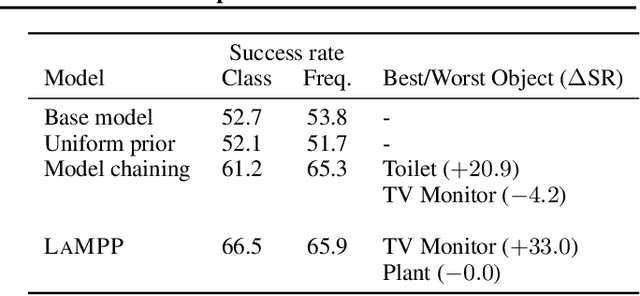
Language models trained on large text corpora encode rich distributional information about real-world environments and action sequences. This information plays a crucial role in current approaches to language processing tasks like question answering and instruction generation. We describe how to leverage language models for *non-linguistic* perception and control tasks. Our approach casts labeling and decision-making as inference in probabilistic graphical models in which language models parameterize prior distributions over labels, decisions and parameters, making it possible to integrate uncertain observations and incomplete background knowledge in a principled way. Applied to semantic segmentation, household navigation, and activity recognition tasks, this approach improves predictions on rare, out-of-distribution, and structurally novel inputs.
Human-Imperceptible Identification with Learnable Lensless Imaging
Feb 04, 2023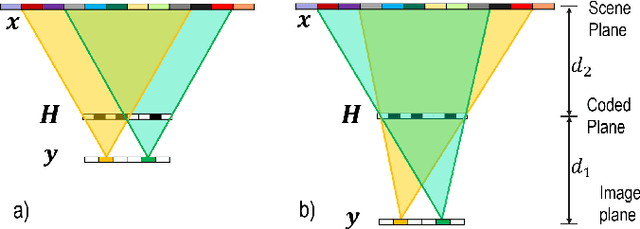



Lensless imaging protects visual privacy by capturing heavily blurred images that are imperceptible for humans to recognize the subject but contain enough information for machines to infer information. Unfortunately, protecting visual privacy comes with a reduction in recognition accuracy and vice versa. We propose a learnable lensless imaging framework that protects visual privacy while maintaining recognition accuracy. To make captured images imperceptible to humans, we designed several loss functions based on total variation, invertibility, and the restricted isometry property. We studied the effect of privacy protection with blurriness on the identification of personal identity via a quantitative method based on a subjective evaluation. Moreover, we validate our simulation by implementing a hardware realization of lensless imaging with photo-lithographically printed masks.
Pre-training for Information Retrieval: Are Hyperlinks Fully Explored?
Sep 14, 2022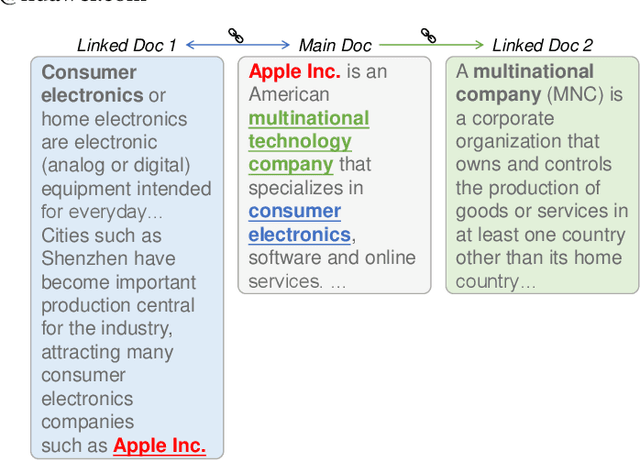
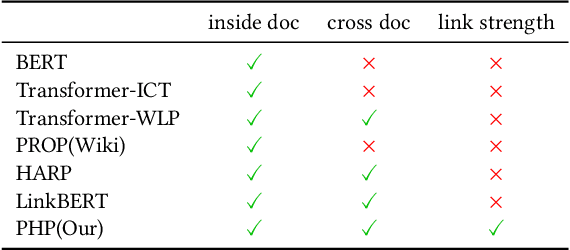
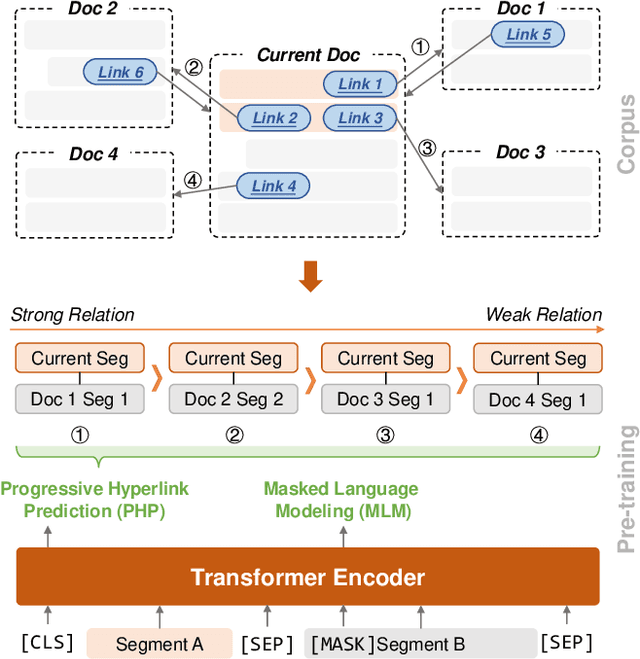
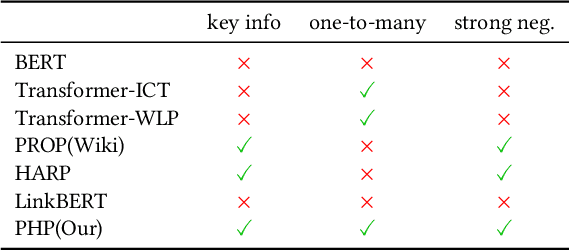
Recent years have witnessed great progress on applying pre-trained language models, e.g., BERT, to information retrieval (IR) tasks. Hyperlinks, which are commonly used in Web pages, have been leveraged for designing pre-training objectives. For example, anchor texts of the hyperlinks have been used for simulating queries, thus constructing tremendous query-document pairs for pre-training. However, as a bridge across two web pages, the potential of hyperlinks has not been fully explored. In this work, we focus on modeling the relationship between two documents that are connected by hyperlinks and designing a new pre-training objective for ad-hoc retrieval. Specifically, we categorize the relationships between documents into four groups: no link, unidirectional link, symmetric link, and the most relevant symmetric link. By comparing two documents sampled from adjacent groups, the model can gradually improve its capability of capturing matching signals. We propose a progressive hyperlink predication ({PHP}) framework to explore the utilization of hyperlinks in pre-training. Experimental results on two large-scale ad-hoc retrieval datasets and six question-answering datasets demonstrate its superiority over existing pre-training methods.
A Threefold Review on Deep Semantic Segmentation: Efficiency-oriented, Temporal and Depth-aware design
Mar 08, 2023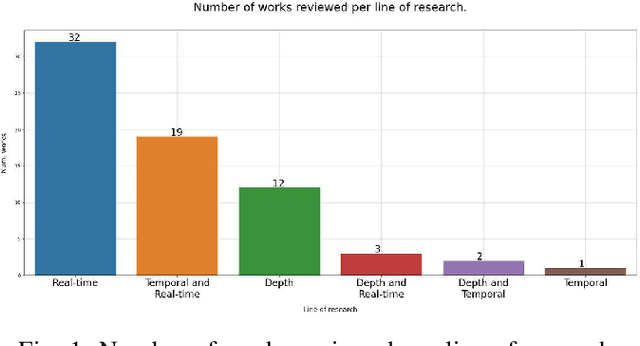
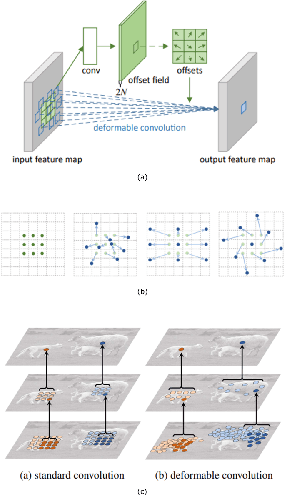
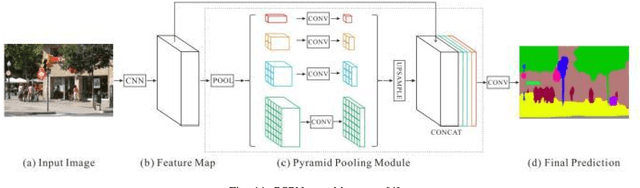
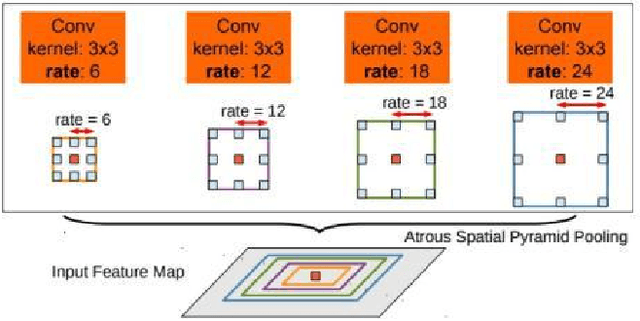
Semantic image and video segmentation stand among the most important tasks in computer vision nowadays, since they provide a complete and meaningful representation of the environment by means of a dense classification of the pixels in a given scene. Recently, Deep Learning, and more precisely Convolutional Neural Networks, have boosted semantic segmentation to a new level in terms of performance and generalization capabilities. However, designing Deep Semantic Segmentation models is a complex task, as it may involve application-dependent aspects. Particularly, when considering autonomous driving applications, the robustness-efficiency trade-off, as well as intrinsic limitations - computational/memory bounds and data-scarcity - and constraints - real-time inference - should be taken into consideration. In this respect, the use of additional data modalities, such as depth perception for reasoning on the geometry of a scene, and temporal cues from videos to explore redundancy and consistency, are promising directions yet not explored to their full potential in the literature. In this paper, we conduct a survey on the most relevant and recent advances in Deep Semantic Segmentation in the context of vision for autonomous vehicles, from three different perspectives: efficiency-oriented model development for real-time operation, RGB-Depth data integration (RGB-D semantic segmentation), and the use of temporal information from videos in temporally-aware models. Our main objective is to provide a comprehensive discussion on the main methods, advantages, limitations, results and challenges faced from each perspective, so that the reader can not only get started, but also be up to date in respect to recent advances in this exciting and challenging research field.
UT-Net: Combining U-Net and Transformer for Joint Optic Disc and Cup Segmentation and Glaucoma Detection
Mar 08, 2023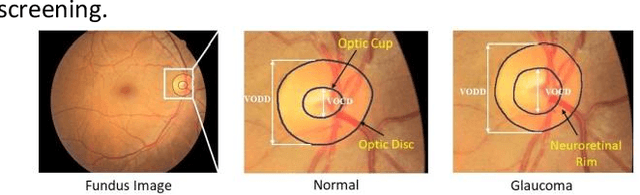
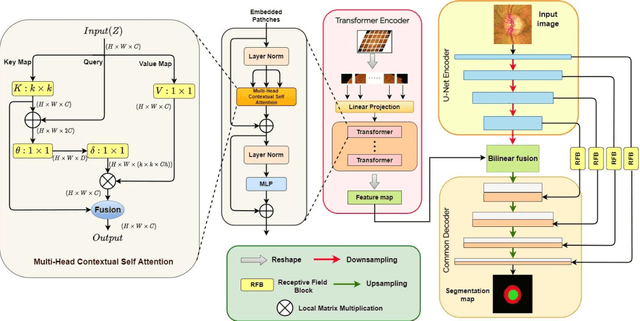
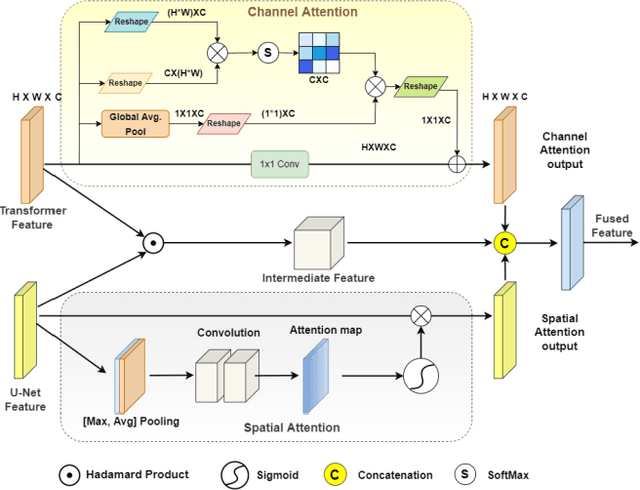
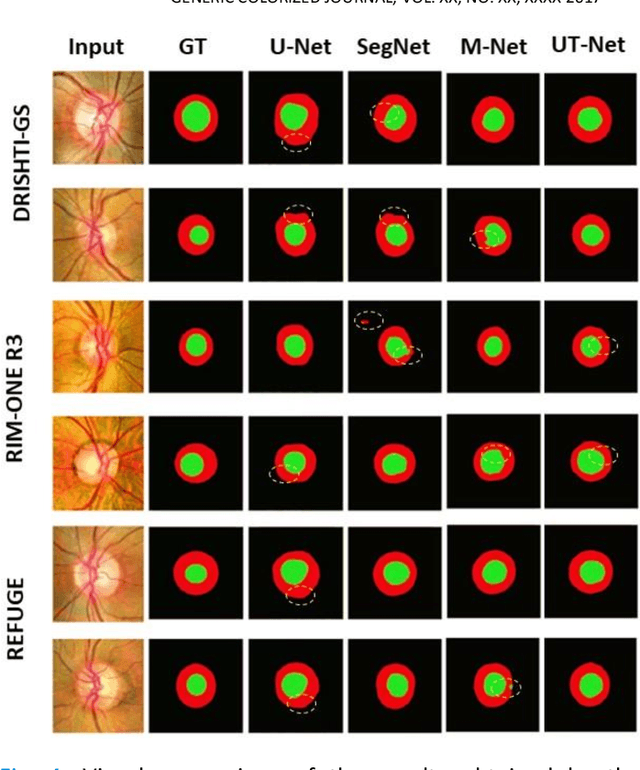
Glaucoma is a chronic visual disease that may cause permanent irreversible blindness. Measurement of the cup-to-disc ratio (CDR) plays a pivotal role in the detection of glaucoma in its early stage, preventing visual disparities. Therefore, accurate and automatic segmentation of optic disc (OD) and optic cup (OC) from retinal fundus images is a fundamental requirement. Existing CNN-based segmentation frameworks resort to building deep encoders with aggressive downsampling layers, which suffer from a general limitation on modeling explicit long-range dependency. To this end, in this paper, we propose a new segmentation pipeline, called UT-Net, availing the advantages of U-Net and transformer both in its encoding layer, followed by an attention-gated bilinear fusion scheme. In addition to this, we incorporate Multi-Head Contextual attention to enhance the regular self-attention used in traditional vision transformers. Thus low-level features along with global dependencies are captured in a shallow manner. Besides, we extract context information at multiple encoding layers for better exploration of receptive fields, and to aid the model to learn deep hierarchical representations. Finally, an enhanced mixing loss is proposed to tightly supervise the overall learning process. The proposed model has been implemented for joint OD and OC segmentation on three publicly available datasets: DRISHTI-GS, RIM-ONE R3, and REFUGE. Additionally, to validate our proposal, we have performed exhaustive experimentation on Glaucoma detection from all three datasets by measuring the Cup to Disc Ratio (CDR) value. Experimental results demonstrate the superiority of UT-Net as compared to the state-of-the-art methods.
Taking a Language Detour: How International Migrants Speaking a Minority Language Seek COVID-Related Information in Their Host Countries
Sep 07, 2022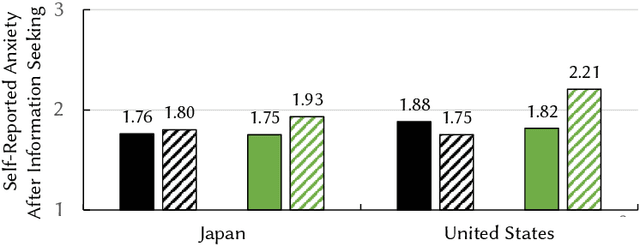
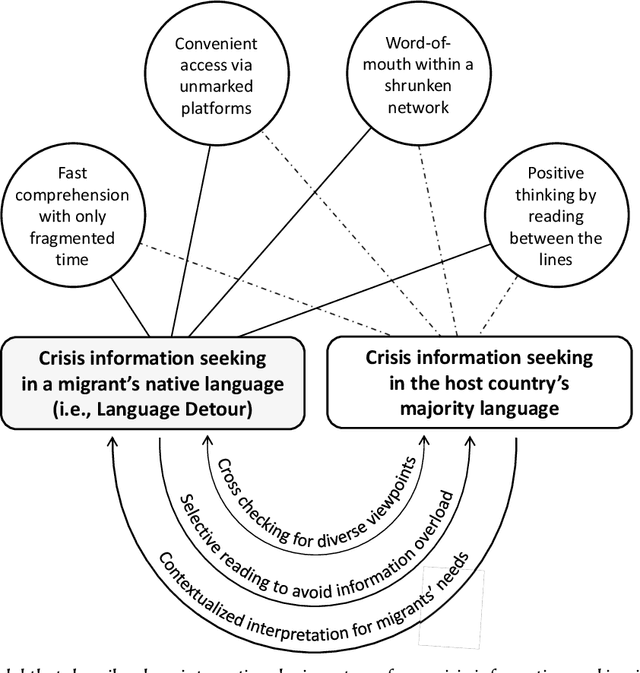
Information seeking is crucial for people's self-care and wellbeing in times of public crises. Extensive research has investigated empirical understandings as well as technical solutions to facilitate information seeking by domestic citizens of affected regions. However, limited knowledge is established to support international migrants who need to survive a crisis in their host countries. The current paper presents an interview study with two cohorts of Chinese migrants living in Japan (N=14) and the United States (N=14). Participants reflected on their information seeking experiences during the COVID pandemic. The reflection was supplemented by two weeks of self-tracking where participants maintained records of their COVIDrelated information seeking practice. Our data indicated that participants often took language detours, or visits to Mandarin resources for information about the COVID outbreak in their host countries. They also made strategic use of the Mandarin information to perform selective reading, cross-checking, and contextualized interpretation of COVID-related information in Japanese or English. While such practices enhanced participants' perceived effectiveness of COVID-related information gathering and sensemaking, they disadvantaged people through sometimes incognizant ways. Further, participants lacked the awareness or preference to review migrant-oriented information that was issued by the host country's public authorities despite its availability. Building upon these findings, we discussed solutions to improve international migrants' COVID-related information seeking in their non-native language and cultural environment. We advocated inclusive crisis infrastructures that would engage people with diverse levels of local language fluency, information literacy, and experience in leveraging public services.
ESceme: Vision-and-Language Navigation with Episodic Scene Memory
Mar 02, 2023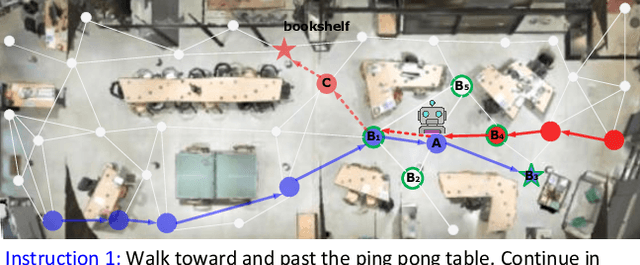
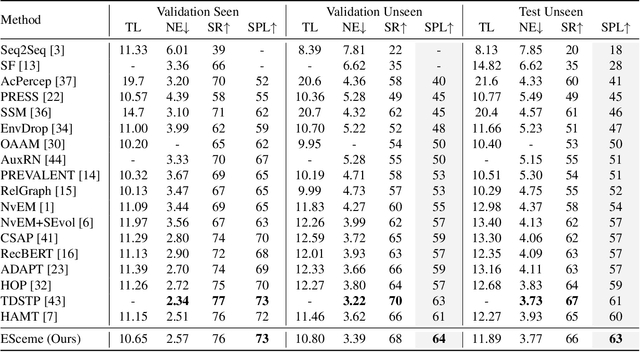
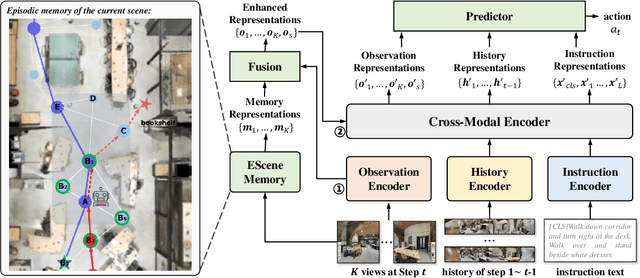
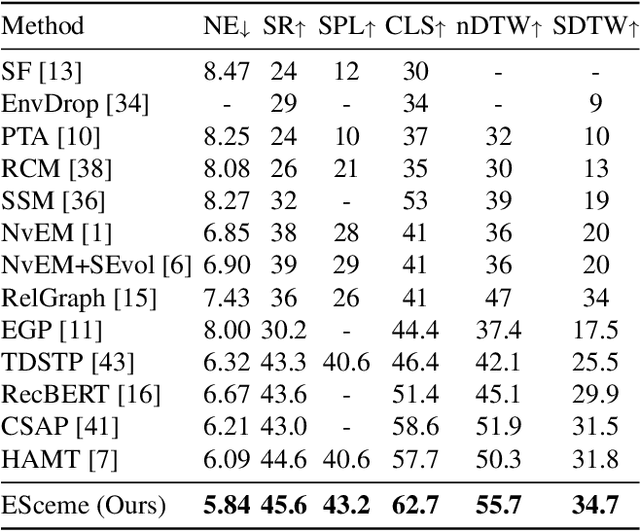
Vision-and-language navigation (VLN) simulates a visual agent that follows natural-language navigation instructions in real-world scenes. Existing approaches have made enormous progress in navigation in new environments, such as beam search, pre-exploration, and dynamic or hierarchical history encoding. To balance generalization and efficiency, we resort to memorizing visited scenarios apart from the ongoing route while navigating. In this work, we introduce a mechanism of Episodic Scene memory (ESceme) for VLN that wakes an agent's memories of past visits when it enters the current scene. The episodic scene memory allows the agent to envision a bigger picture of the next prediction. In this way, the agent learns to make the most of currently available information instead of merely adapting to the seen environments. We provide a simple yet effective implementation by enhancing the observation features of candidate nodes during training. We verify the superiority of ESceme on three VLN tasks, including short-horizon navigation (R2R), long-horizon navigation (R4R), and vision-and-dialog navigation (CVDN), and achieve a new state-of-the-art. Code is available: \url{https://github.com/qizhust/esceme}.
Jointly Visual- and Semantic-Aware Graph Memory Networks for Temporal Sentence Localization in Videos
Mar 02, 2023
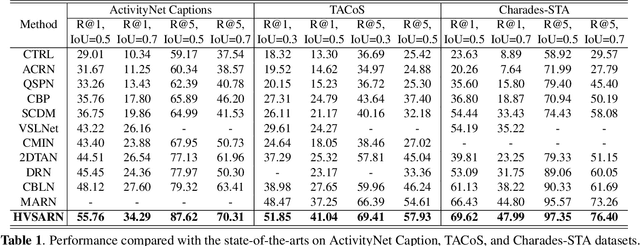
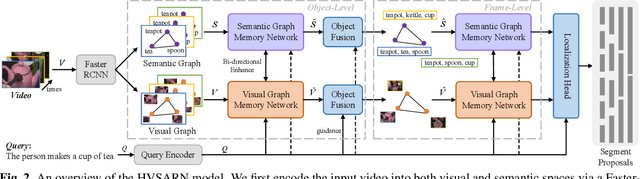
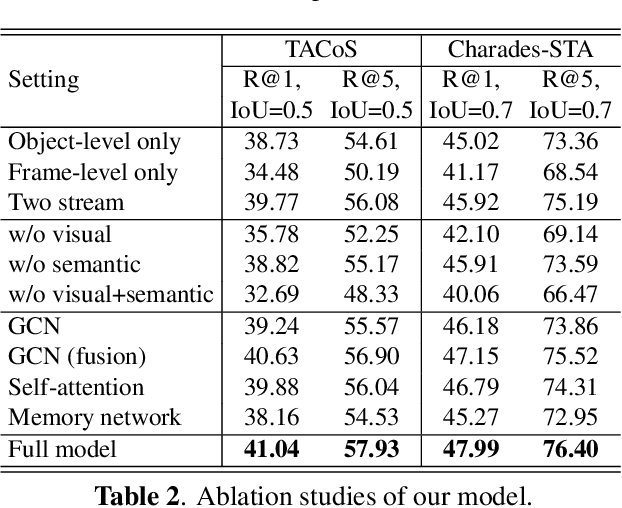
Temporal sentence localization in videos (TSLV) aims to retrieve the most interested segment in an untrimmed video according to a given sentence query. However, almost of existing TSLV approaches suffer from the same limitations: (1) They only focus on either frame-level or object-level visual representation learning and corresponding correlation reasoning, but fail to integrate them both; (2) They neglect to leverage the rich semantic contexts to further benefit the query reasoning. To address these issues, in this paper, we propose a novel Hierarchical Visual- and Semantic-Aware Reasoning Network (HVSARN), which enables both visual- and semantic-aware query reasoning from object-level to frame-level. Specifically, we present a new graph memory mechanism to perform visual-semantic query reasoning: For visual reasoning, we design a visual graph memory to leverage visual information of video; For semantic reasoning, a semantic graph memory is also introduced to explicitly leverage semantic knowledge contained in the classes and attributes of video objects, and perform correlation reasoning in the semantic space. Experiments on three datasets demonstrate that our HVSARN achieves a new state-of-the-art performance.
MoSS: Monocular Shape Sensing for Continuum Robots
Mar 02, 2023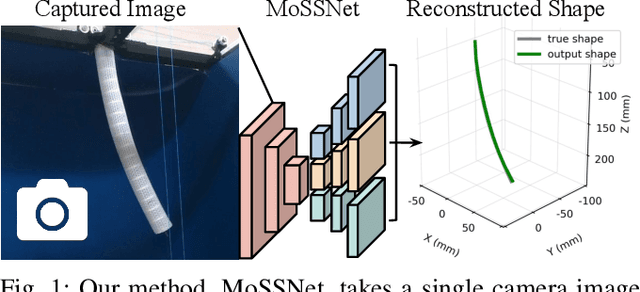
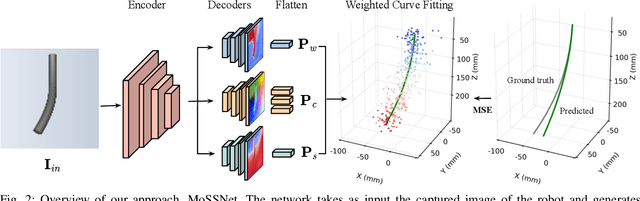

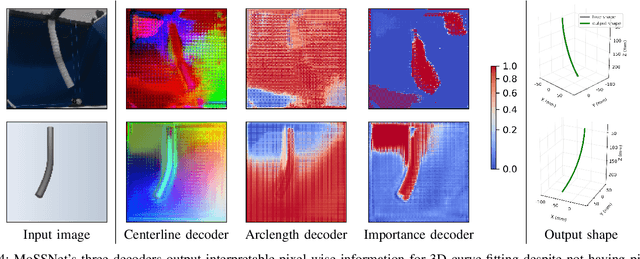
Continuum robots are promising candidates for interactive tasks in various applications due to their unique shape, compliance, and miniaturization capability. Accurate and real-time shape sensing is essential for such tasks yet remains a challenge. Embedded shape sensing has high hardware complexity and cost, while vision-based methods require stereo setup and struggle to achieve real-time performance. This paper proposes the first eye-to-hand monocular approach to continuum robot shape sensing. Utilizing a deep encoder-decoder network, our method, MoSSNet, eliminates the computation cost of stereo matching and reduces requirements on sensing hardware. In particular, MoSSNet comprises an encoder and three parallel decoders to uncover spatial, length, and contour information from a single RGB image, and then obtains the 3D shape through curve fitting. A two-segment tendon-driven continuum robot is used for data collection and testing, demonstrating accurate (mean shape error of 0.91 mm, or 0.36% of robot length) and real-time (70 fps) shape sensing on real-world data. Additionally, the method is optimized end-to-end and does not require fiducial markers, manual segmentation, or camera calibration. Code and datasets will be made available at https://github.com/ContinuumRoboticsLab/MoSSNet.
Attention Mechanism for Contrastive Learning in GAN-based Image-to-Image Translation
Feb 23, 2023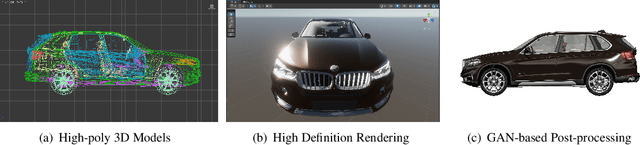

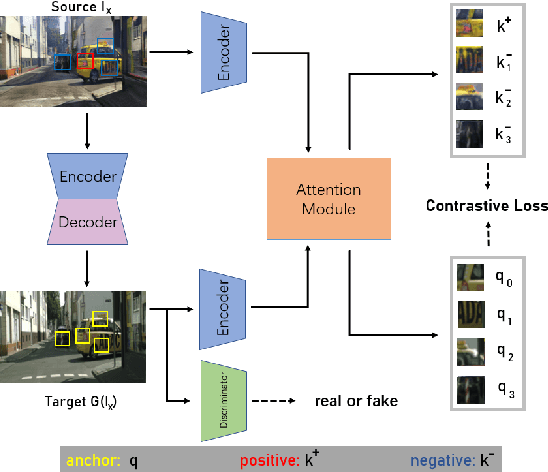
Using real road testing to optimize autonomous driving algorithms is time-consuming and capital-intensive. To solve this problem, we propose a GAN-based model that is capable of generating high-quality images across different domains. We further leverage Contrastive Learning to train the model in a self-supervised way using image data acquired in the real world using real sensors and simulated images from 3D games. In this paper, we also apply an Attention Mechanism module to emphasize features that contain more information about the source domain according to their measurement of significance. Finally, the generated images are used as datasets to train neural networks to perform a variety of downstream tasks to verify that the approach can fill in the gaps between the virtual and real worlds.