 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An evaluation of Google Translate for Sanskrit to English translation via sentiment and semantic analysis
Feb 28, 2023

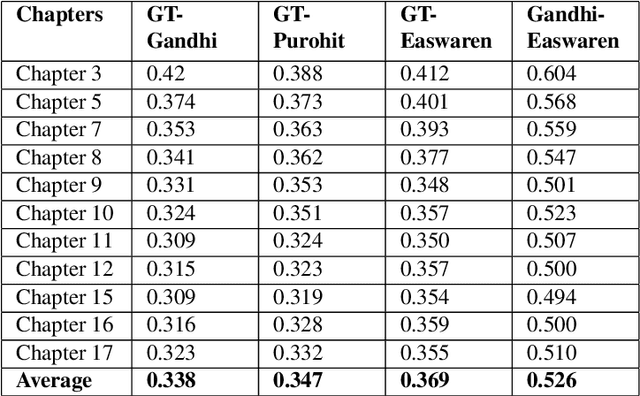
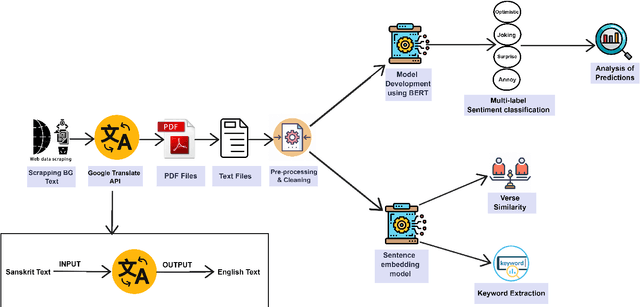
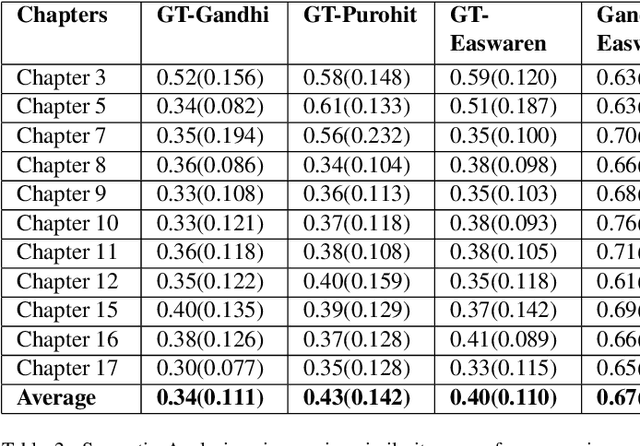
Google Translate has been prominent for language translation; however, limited work has been done in evaluating the quality of translation when compared to human experts. Sanskrit one of the oldest written languages in the world. In 2022, the Sanskrit language was added to the Google Translate engine. Sanskrit is known as the mother of languages such as Hindi and an ancient source of the Indo-European group of languages. Sanskrit is the original language for sacred Hindu texts such as the Bhagavad Gita. In this study, we present a framework that evaluates the Google Translate for Sanskrit using the Bhagavad Gita. We first publish a translation of the Bhagavad Gita in Sanskrit using Google Translate. Our framework then compares Google Translate version of Bhagavad Gita with expert translations using sentiment and semantic analysis via BERT-based language models. Our results indicate that in terms of sentiment and semantic analysis, there is low level of similarity in selected verses of Google Translate when compared to expert translations. In the qualitative evaluation, we find that Google translate is unsuitable for translation of certain Sanskrit words and phrases due to its poetic nature, contextual significance, metaphor and imagery. The mistranslations are not surprising since the Bhagavad Gita is known as a difficult text not only to translate, but also to interpret since it relies on contextual, philosophical and historical information. Our framework lays the foundation for automatic evaluation of other languages by Google Translate
Knowledge Graph Completion with Counterfactual Augmentation
Feb 25, 2023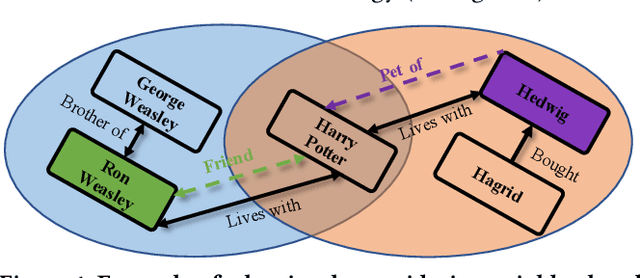
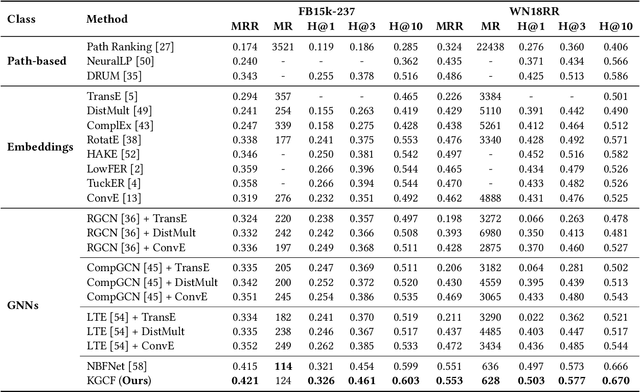

Graph Neural Networks (GNNs) have demonstrated great success in Knowledge Graph Completion (KGC) by modeling how entities and relations interact in recent years. However, most of them are designed to learn from the observed graph structure, which appears to have imbalanced relation distribution during the training stage. Motivated by the causal relationship among the entities on a knowledge graph, we explore this defect through a counterfactual question: "would the relation still exist if the neighborhood of entities became different from observation?". With a carefully designed instantiation of a causal model on the knowledge graph, we generate the counterfactual relations to answer the question by regarding the representations of entity pair given relation as context, structural information of relation-aware neighborhood as treatment, and validity of the composed triplet as the outcome. Furthermore, we incorporate the created counterfactual relations with the GNN-based framework on KGs to augment their learning of entity pair representations from both the observed and counterfactual relations. Experiments on benchmarks show that our proposed method outperforms existing methods on the task of KGC, achieving new state-of-the-art results. Moreover, we demonstrate that the proposed counterfactual relations-based augmentation also enhances the interpretability of the GNN-based framework through the path interpretations of predictions.
Knowledge-infused Contrastive Learning for Urban Imagery-based Socioeconomic Prediction
Feb 25, 2023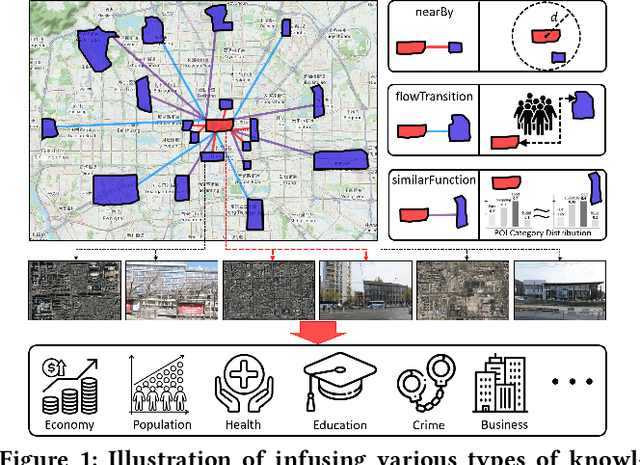
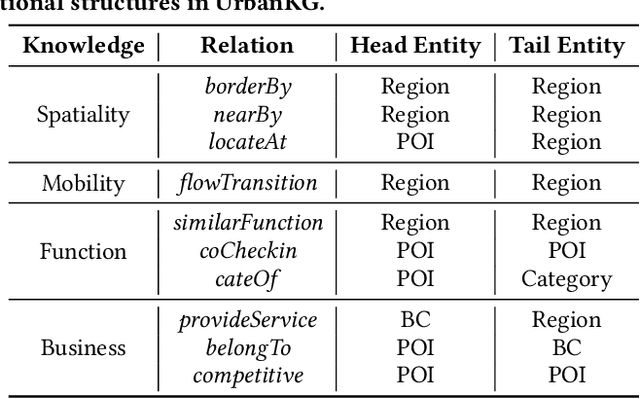
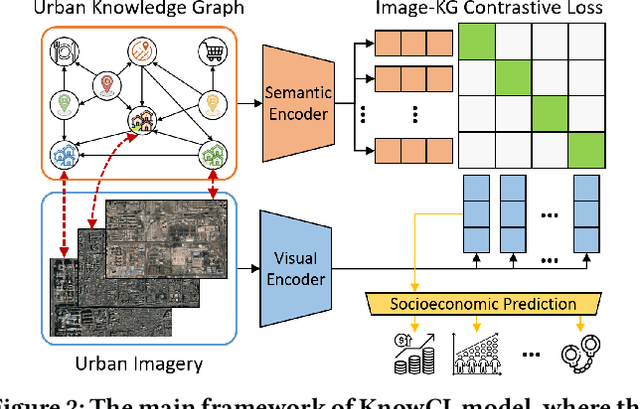
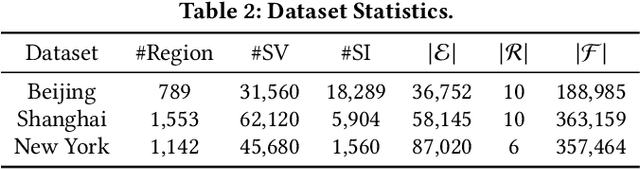
Monitoring sustainable development goals requires accurate and timely socioeconomic statistics, while ubiquitous and frequently-updated urban imagery in web like satellite/street view images has emerged as an important source for socioeconomic prediction. Especially, recent studies turn to self-supervised contrastive learning with manually designed similarity metrics for urban imagery representation learning and further socioeconomic prediction, which however suffers from effectiveness and robustness issues. To address such issues, in this paper, we propose a Knowledge-infused Contrastive Learning (KnowCL) model for urban imagery-based socioeconomic prediction. Specifically, we firstly introduce knowledge graph (KG) to effectively model the urban knowledge in spatiality, mobility, etc., and then build neural network based encoders to learn representations of an urban image in associated semantic and visual spaces, respectively. Finally, we design a cross-modality based contrastive learning framework with a novel image-KG contrastive loss, which maximizes the mutual information between semantic and visual representations for knowledge infusion. Extensive experiments of applying the learnt visual representations for socioeconomic prediction on three datasets demonstrate the superior performance of KnowCL with over 30\% improvements on $R^2$ compared with baselines. Especially, our proposed KnowCL model can apply to both satellite and street imagery with both effectiveness and transferability achieved, which provides insights into urban imagery-based socioeconomic prediction.
Fair Attribute Completion on Graph with Missing Attributes
Feb 25, 2023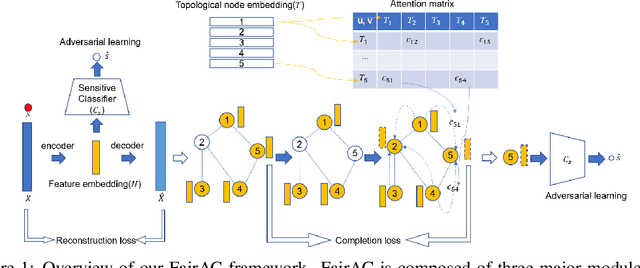
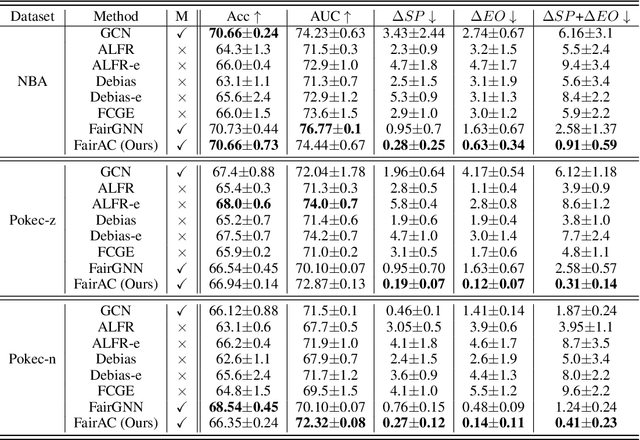
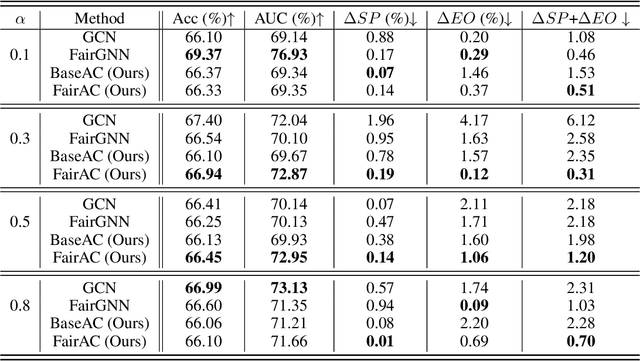
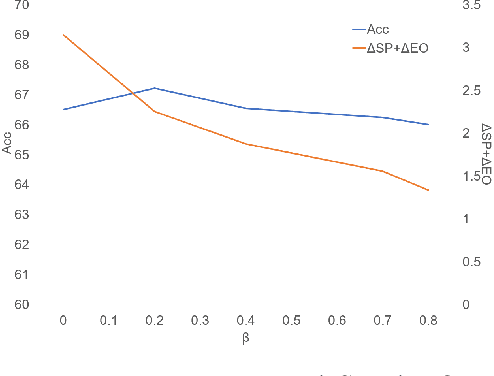
Tackling unfairness in graph learning models is a challenging task, as the unfairness issues on graphs involve both attributes and topological structures. Existing work on fair graph learning simply assumes that attributes of all nodes are available for model training and then makes fair predictions. In practice, however, the attributes of some nodes might not be accessible due to missing data or privacy concerns, which makes fair graph learning even more challenging. In this paper, we propose FairAC, a fair attribute completion method, to complement missing information and learn fair node embeddings for graphs with missing attributes. FairAC adopts an attention mechanism to deal with the attribute missing problem and meanwhile, it mitigates two types of unfairness, i.e., feature unfairness from attributes and topological unfairness due to attribute completion. FairAC can work on various types of homogeneous graphs and generate fair embeddings for them and thus can be applied to most downstream tasks to improve their fairness performance. To our best knowledge, FairAC is the first method that jointly addresses the graph attribution completion and graph unfairness problems. Experimental results on benchmark datasets show that our method achieves better fairness performance with less sacrifice in accuracy, compared with the state-of-the-art methods of fair graph learning.
A Surrogate-Assisted Highly Cooperative Coevolutionary Algorithm for Hyperparameter Optimization in Deep Convolutional Neural Network
Feb 25, 2023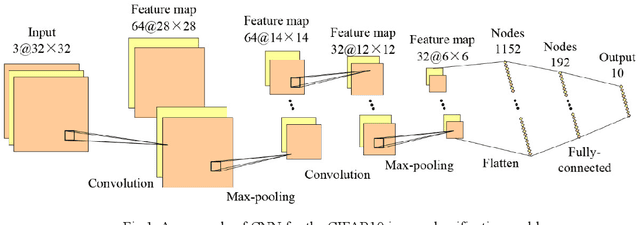
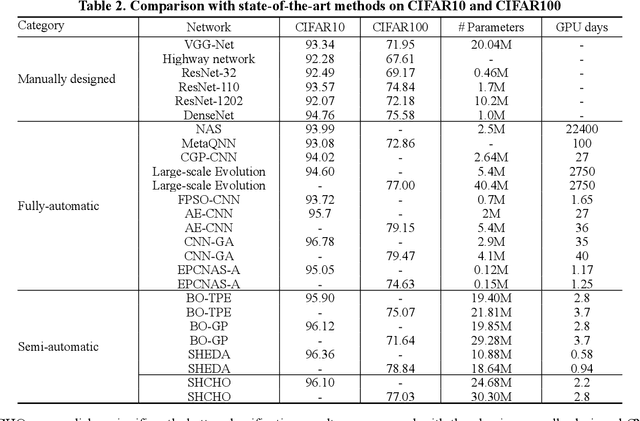

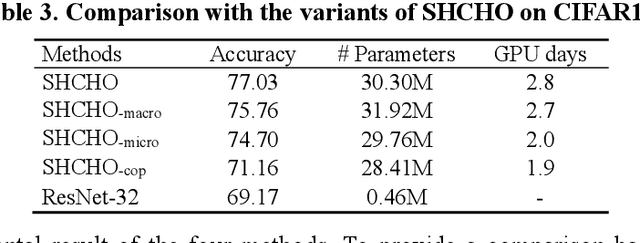
Convolutional neural networks (CNNs) have gained remarkable success in recent years. However, their performance highly relies on the architecture hyperparameters, and finding proper hyperparameters for a deep CNN is a challenging optimization problem owing to its high-dimensional and computationally expensive characteristics. Given these difficulties, this study proposes a surrogate-assisted highly cooperative hyperparameter optimization (SHCHO) algorithm for chain-styled CNNs. To narrow the large search space, SHCHO first decomposes the whole CNN into several overlapping sub-CNNs in accordance with the overlapping hyperparameter interaction structure and then cooperatively optimizes these hyperparameter subsets. Two cooperation mechanisms are designed during this process. One coordinates all the sub-CNNs to reproduce the information flow in the whole CNN and achieve macro cooperation among them, and the other tackles the overlapping components by simultaneously considering the involved two sub-CNNs and facilitates micro cooperation between them. As a result, a proper hyperparameter configuration can be effectively located for the whole CNN. Besides, SHCHO also employs the well-performing surrogate technique to assist in the hyperparameter optimization of each sub-CNN, thereby greatly reducing the expensive computational cost. Extensive experimental results on two widely-used image classification datasets indicate that SHCHO can significantly improve the performance of CNNs.
Rehabilitating Homeless: Dataset and Key Insights
Feb 10, 2023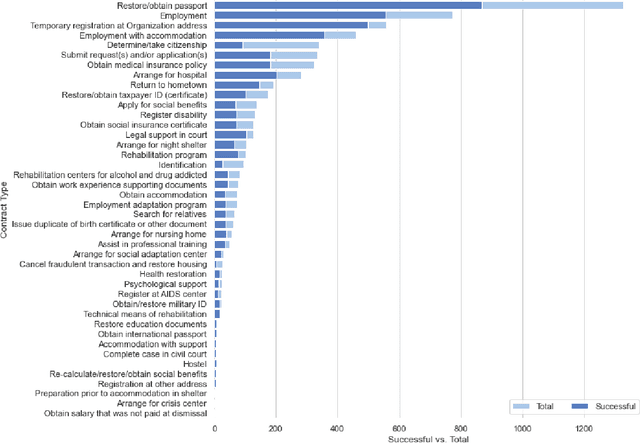
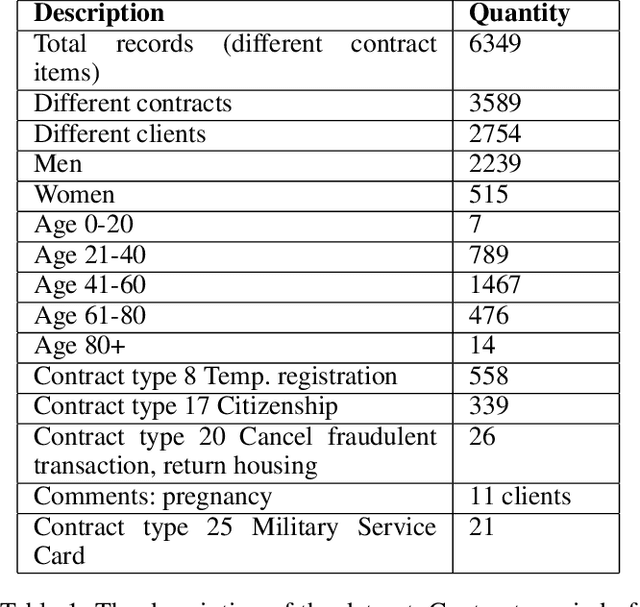
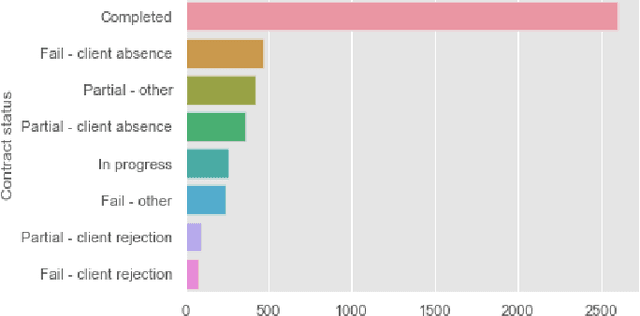
This paper presents a large anonymized dataset of homelessness alongside insights into the data-driven rehabilitation of homeless people. The dataset was gathered by a large nonprofit organization working on rehabilitating the homeless for twenty years. This is the first dataset that we know of that contains rich information on thousands of homeless individuals seeking rehabilitation. We show how data analysis can help to make the rehabilitation of homeless people more effective and successful. Thus, we hope this paper alerts the data science community to the problem of homelessness.
Aggregation of Disentanglement: Reconsidering Domain Variations in Domain Generalization
Feb 05, 2023
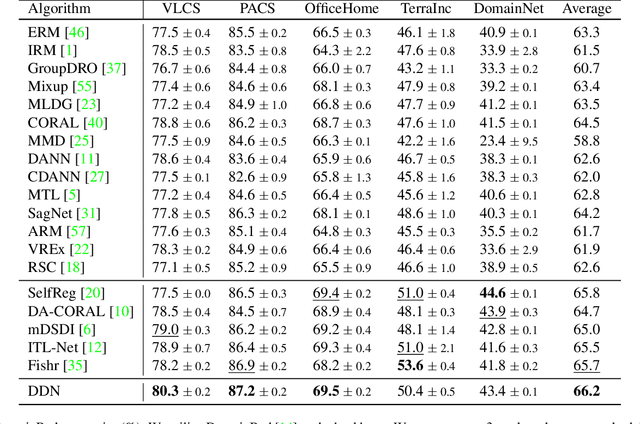
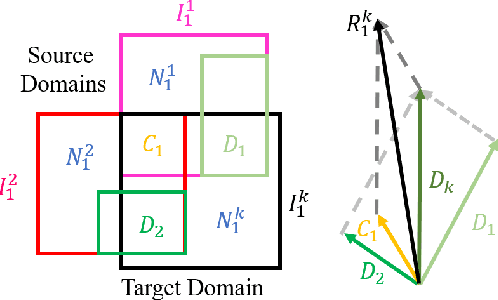

Domain Generalization (DG) is a fundamental challenge for machine learning models, which aims to improve model generalization on various domains. Previous methods focus on generating domain invariant features from various source domains. However, we argue that the domain variantions also contain useful information, ie, classification-aware information, for downstream tasks, which has been largely ignored. Different from learning domain invariant features from source domains, we decouple the input images into Domain Expert Features and noise. The proposed domain expert features lie in a learned latent space where the images in each domain can be classified independently, enabling the implicit use of classification-aware domain variations. Based on the analysis, we proposed a novel paradigm called Domain Disentanglement Network (DDN) to disentangle the domain expert features from the source domain images and aggregate the source domain expert features for representing the target test domain. We also propound a new contrastive learning method to guide the domain expert features to form a more balanced and separable feature space. Experiments on the widely-used benchmarks of PACS, VLCS, OfficeHome, DomainNet, and TerraIncognita demonstrate the competitive performance of our method compared to the recently proposed alternatives.
SINC: Service Information Augmented Open-Domain Conversation
Jun 28, 2022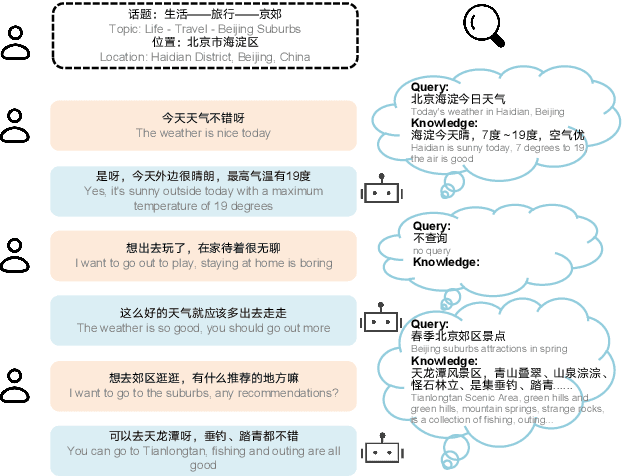
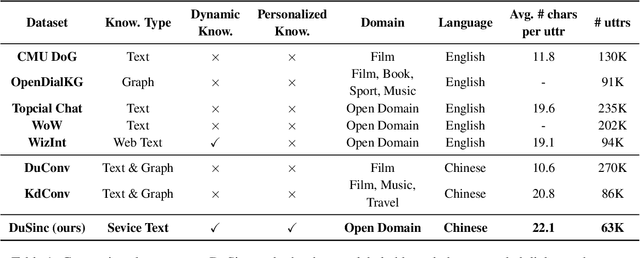
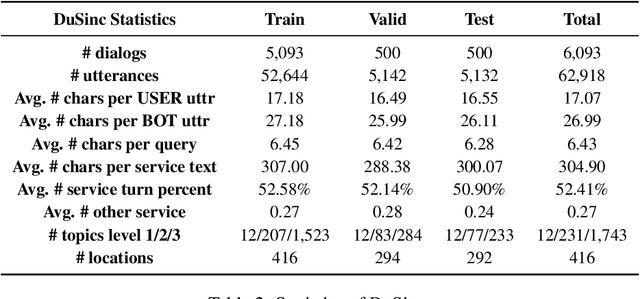
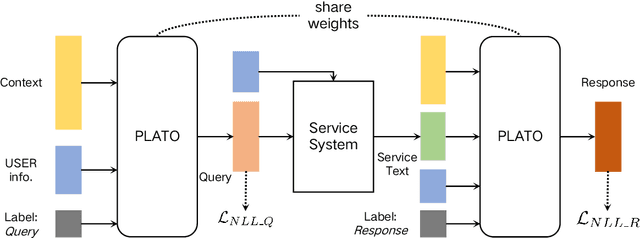
Generative open-domain dialogue systems can benefit from external knowledge, but the lack of external knowledge resources and the difficulty in finding relevant knowledge limit the development of this technology. To this end, we propose a knowledge-driven dialogue task using dynamic service information. Specifically, we use a large number of service APIs that can provide high coverage and spatiotemporal sensitivity as external knowledge sources. The dialogue system generates queries to request external services along with user information, get the relevant knowledge, and generate responses based on this knowledge. To implement this method, we collect and release the first open domain Chinese service knowledge dialogue dataset DuSinc. At the same time, we construct a baseline model PLATO-SINC, which realizes the automatic utilization of service information for dialogue. Both automatic evaluation and human evaluation show that our proposed new method can significantly improve the effect of open-domain conversation, and the session-level overall score in human evaluation is improved by 59.29% compared with the dialogue pre-training model PLATO-2. The dataset and benchmark model will be open sourced.
Motion Estimation for Fisheye Video With an Application to Temporal Resolution Enhancement
Mar 01, 2023


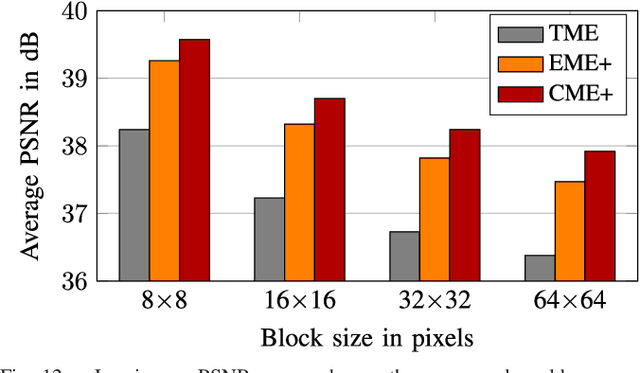
Surveying wide areas with only one camera is a typical scenario in surveillance and automotive applications. Ultra wide-angle fisheye cameras employed to that end produce video data with characteristics that differ significantly from conventional rectilinear imagery as obtained by perspective pinhole cameras. Those characteristics are not considered in typical image and video processing algorithms such as motion estimation, where translation is assumed to be the predominant kind of motion. This contribution introduces an adapted technique for use in block-based motion estimation that takes into the account the projection function of fisheye cameras and thus compensates for the non-perspective properties of fisheye videos. By including suitable projections, the translational motion model that would otherwise only hold for perspective material is exploited, leading to improved motion estimation results without altering the source material. In addition, we discuss extensions that allow for a better prediction of the peripheral image areas, where motion estimation falters due to spatial constraints, and further include calibration information to account for lens properties deviating from the theoretical function. Simulations and experiments are conducted on synthetic as well as real-world fisheye video sequences that are part of a data set created in the context of this paper. Average synthetic and real-world gains of 1.45 and 1.51 dB in luminance PSNR are achieved compared against conventional block matching. Furthermore, the proposed fisheye motion estimation method is successfully applied to motion compensated temporal resolution enhancement, where average gains amount to 0.79 and 0.76 dB.
Multiperspective Teaching of Unknown Objects via Shared-gaze-based Multimodal Human-Robot Interaction
Mar 01, 2023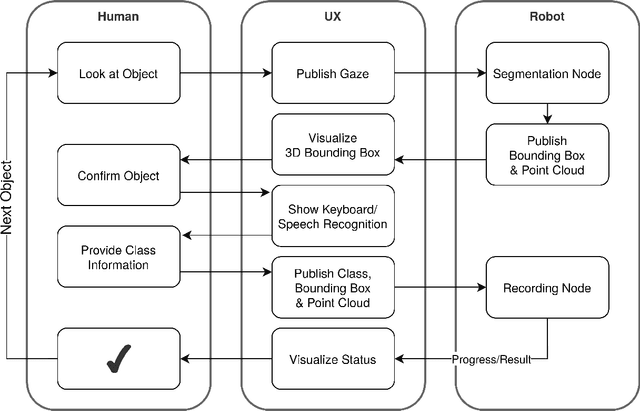
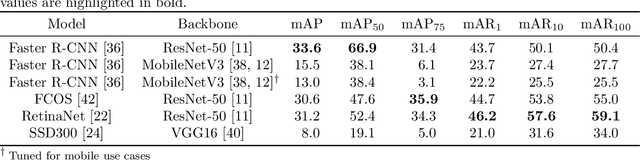

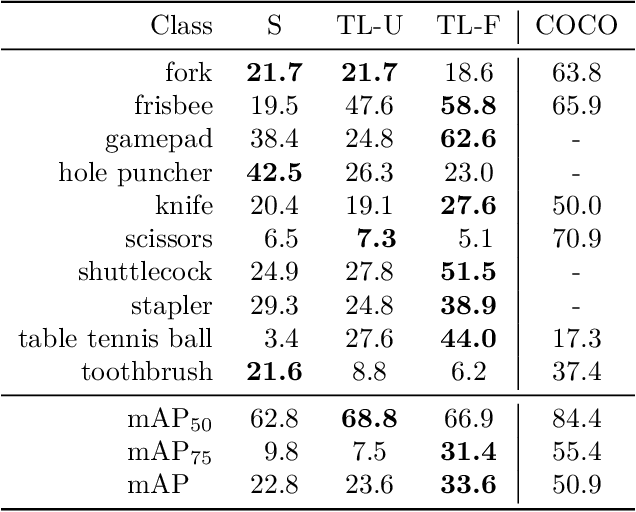
For successful deployment of robots in multifaceted situations, an understanding of the robot for its environment is indispensable. With advancing performance of state-of-the-art object detectors, the capability of robots to detect objects within their interaction domain is also enhancing. However, it binds the robot to a few trained classes and prevents it from adapting to unfamiliar surroundings beyond predefined scenarios. In such scenarios, humans could assist robots amidst the overwhelming number of interaction entities and impart the requisite expertise by acting as teachers. We propose a novel pipeline that effectively harnesses human gaze and augmented reality in a human-robot collaboration context to teach a robot novel objects in its surrounding environment. By intertwining gaze (to guide the robot's attention to an object of interest) with augmented reality (to convey the respective class information) we enable the robot to quickly acquire a significant amount of automatically labeled training data on its own. Training in a transfer learning fashion, we demonstrate the robot's capability to detect recently learned objects and evaluate the influence of different machine learning models and learning procedures as well as the amount of training data involved. Our multimodal approach proves to be an efficient and natural way to teach the robot novel objects based on a few instances and allows it to detect classes for which no training dataset is available. In addition, we make our dataset publicly available to the research community, which consists of RGB and depth data, intrinsic and extrinsic camera parameters, along with regions of interest.