 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Survey on User Behavior Modeling in Recommender Systems
Feb 22, 2023
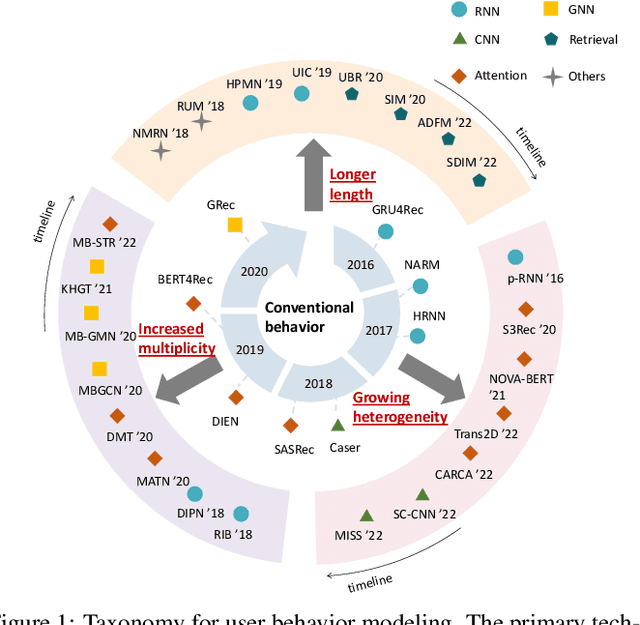

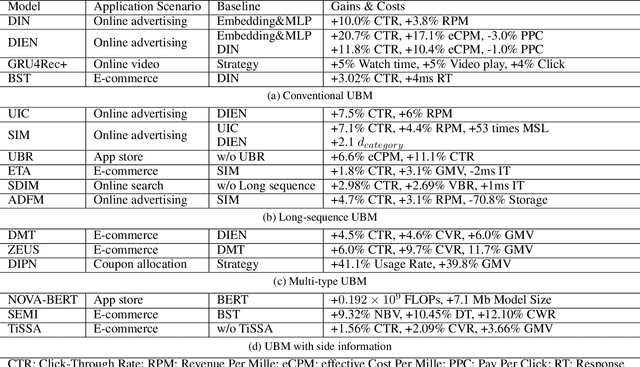
User Behavior Modeling (UBM) plays a critical role in user interest learning, which has been extensively used in recommender systems. Crucial interactive patterns between users and items have been exploited, which brings compelling improvements in many recommendation tasks. In this paper, we attempt to provide a thorough survey of this research topic. We start by reviewing the research background of UBM. Then, we provide a systematic taxonomy of existing UBM research works, which can be categorized into four different directions including Conventional UBM, Long-Sequence UBM, Multi-Type UBM, and UBM with Side Information. Within each direction, representative models and their strengths and weaknesses are comprehensively discussed. Besides, we elaborate on the industrial practices of UBM methods with the hope of providing insights into the application value of existing UBM solutions. Finally, we summarize the survey and discuss the future prospects of this field.
Combining search strategies to improve performance in the calibration of economic ABMs
Feb 23, 2023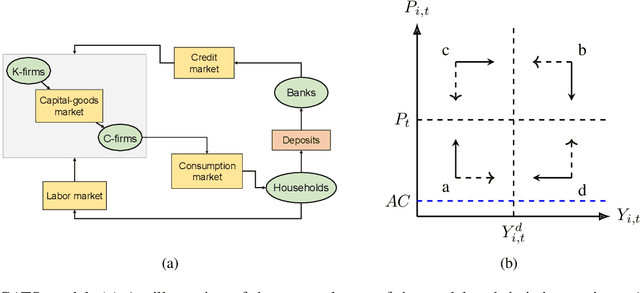

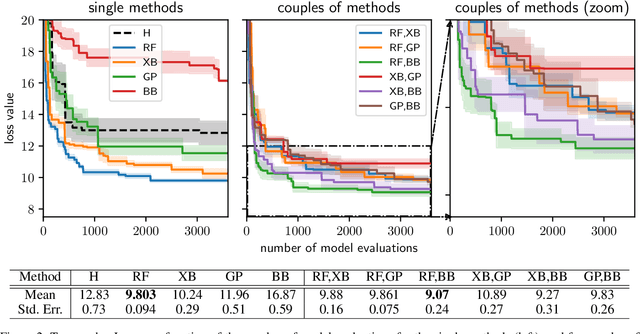
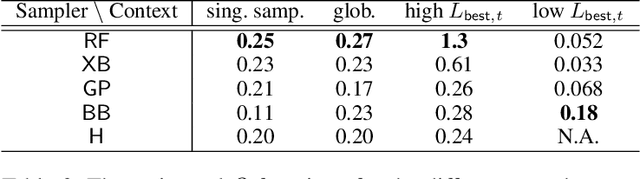
Calibrating agent-based models (ABMs) in economics and finance typically involves a derivative-free search in a very large parameter space. In this work, we benchmark a number of search methods in the calibration of a well-known macroeconomic ABM on real data, and further assess the performance of "mixed strategies" made by combining different methods. We find that methods based on random-forest surrogates are particularly efficient, and that combining search methods generally increases performance since the biases of any single method are mitigated. Moving from these observations, we propose a reinforcement learning (RL) scheme to automatically select and combine search methods on-the-fly during a calibration run. The RL agent keeps exploiting a specific method only as long as this keeps performing well, but explores new strategies when the specific method reaches a performance plateau. The resulting RL search scheme outperforms any other method or method combination tested, and does not rely on any prior information or trial and error procedure.
Asymptotically Unbiased Off-Policy Policy Evaluation when Reusing Old Data in Nonstationary Environments
Feb 23, 2023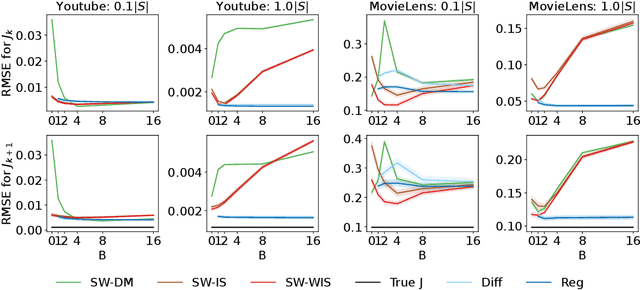
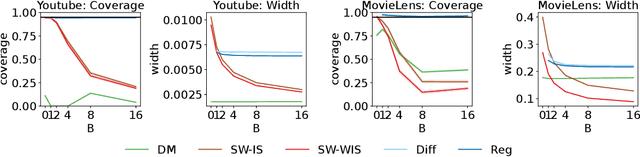
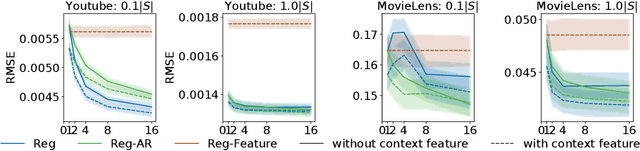
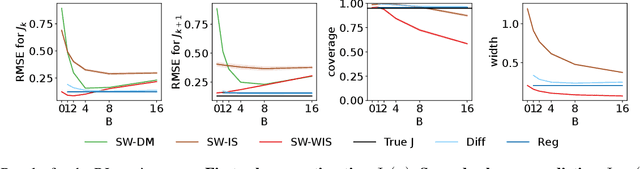
In this work, we consider the off-policy policy evaluation problem for contextual bandits and finite horizon reinforcement learning in the nonstationary setting. Reusing old data is critical for policy evaluation, but existing estimators that reuse old data introduce large bias such that we can not obtain a valid confidence interval. Inspired from a related field called survey sampling, we introduce a variant of the doubly robust (DR) estimator, called the regression-assisted DR estimator, that can incorporate the past data without introducing a large bias. The estimator unifies several existing off-policy policy evaluation methods and improves on them with the use of auxiliary information and a regression approach. We prove that the new estimator is asymptotically unbiased, and provide a consistent variance estimator to a construct a large sample confidence interval. Finally, we empirically show that the new estimator improves estimation for the current and future policy values, and provides a tight and valid interval estimation in several nonstationary recommendation environments.
Improving Adaptive Conformal Prediction Using Self-Supervised Learning
Feb 23, 2023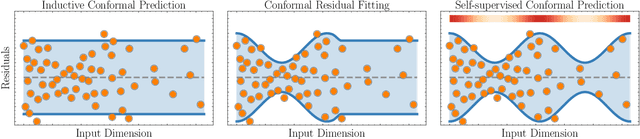
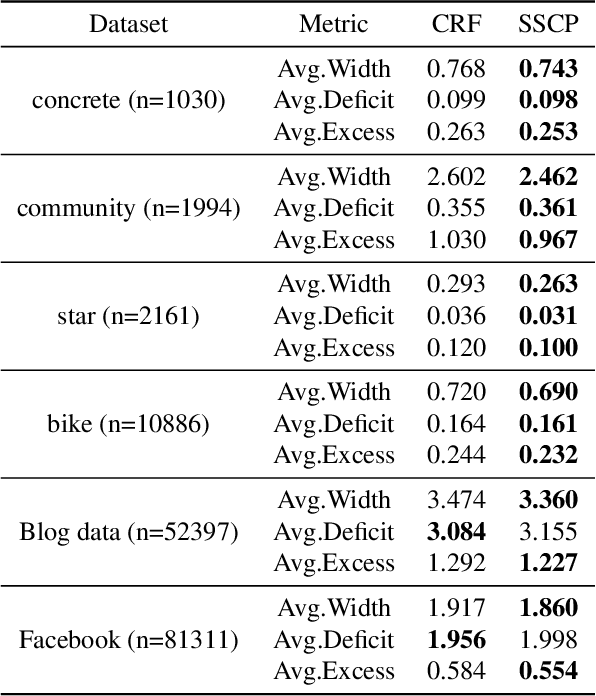
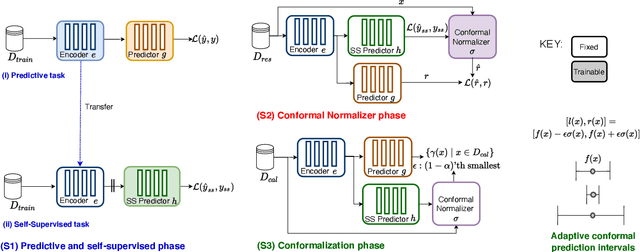
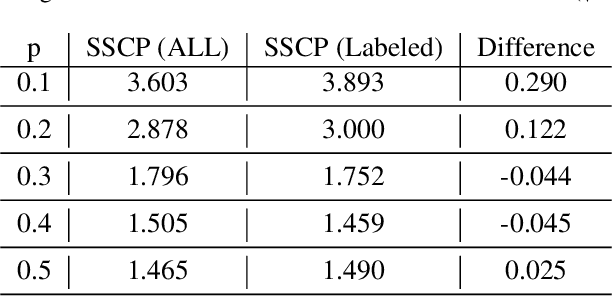
Conformal prediction is a powerful distribution-free tool for uncertainty quantification, establishing valid prediction intervals with finite-sample guarantees. To produce valid intervals which are also adaptive to the difficulty of each instance, a common approach is to compute normalized nonconformity scores on a separate calibration set. Self-supervised learning has been effectively utilized in many domains to learn general representations for downstream predictors. However, the use of self-supervision beyond model pretraining and representation learning has been largely unexplored. In this work, we investigate how self-supervised pretext tasks can improve the quality of the conformal regressors, specifically by improving the adaptability of conformal intervals. We train an auxiliary model with a self-supervised pretext task on top of an existing predictive model and use the self-supervised error as an additional feature to estimate nonconformity scores. We empirically demonstrate the benefit of the additional information using both synthetic and real data on the efficiency (width), deficit, and excess of conformal prediction intervals.
CP+: Camera Poses Augmentation with Large-scale LiDAR Maps
Feb 23, 2023
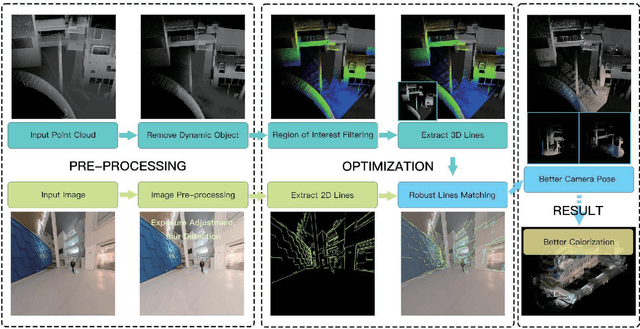
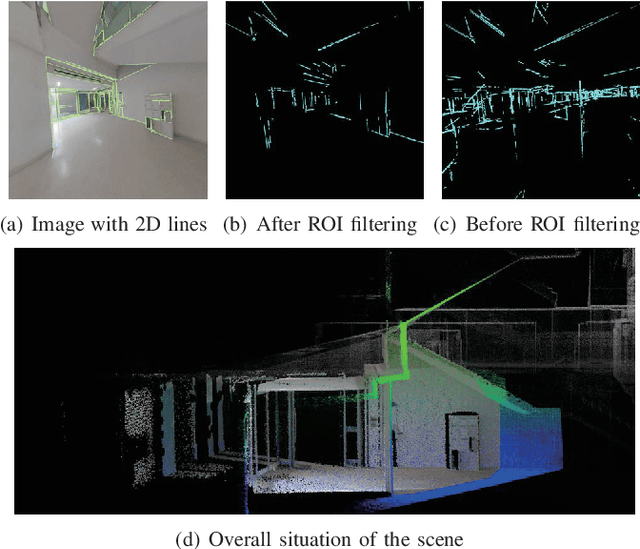

Large-scale colored point clouds have many advantages in navigation or scene display. Relying on cameras and LiDARs, which are now widely used in reconstruction tasks, it is possible to obtain such colored point clouds. However, the information from these two kinds of sensors is not well fused in many existing frameworks, resulting in poor colorization results, thus resulting in inaccurate camera poses and damaged point colorization results. We propose a novel framework called Camera Pose Augmentation (CP+) to improve the camera poses and align them directly with the LiDAR-based point cloud. Initial coarse camera poses are given by LiDAR-Inertial or LiDAR-Inertial-Visual Odometry with approximate extrinsic parameters and time synchronization. The key steps to improve the alignment of the images consist of selecting a point cloud corresponding to a region of interest in each camera view, extracting reliable edge features from this point cloud, and deriving 2D-3D line correspondences which are used towards iterative minimization of the re-projection error.
A Convolutional-Transformer Network for Crack Segmentation with Boundary Awareness
Feb 23, 2023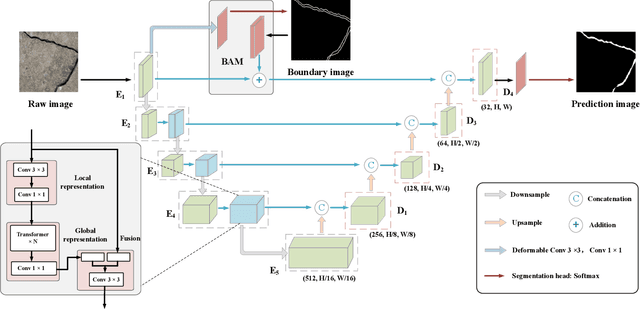
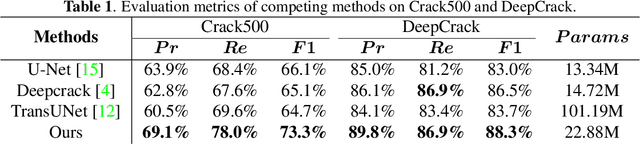
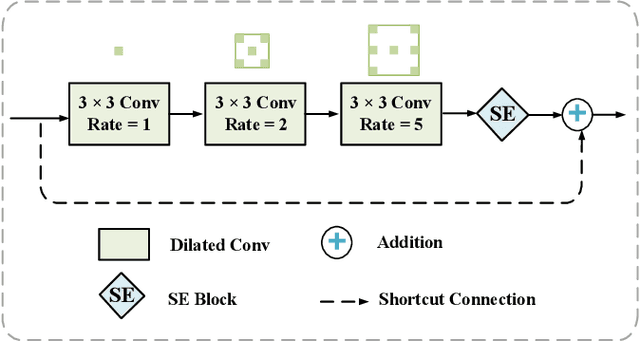

Cracks play a crucial role in assessing the safety and durability of manufactured buildings. However, the long and sharp topological features and complex background of cracks make the task of crack segmentation extremely challenging. In this paper, we propose a novel convolutional-transformer network based on encoder-decoder architecture to solve this challenge. Particularly, we designed a Dilated Residual Block (DRB) and a Boundary Awareness Module (BAM). The DRB pays attention to the local detail of cracks and adjusts the feature dimension for other blocks as needed. And the BAM learns the boundary features from the dilated crack label. Furthermore, the DRB is combined with a lightweight transformer that captures global information to serve as an effective encoder. Experimental results show that the proposed network performs better than state-of-the-art algorithms on two typical datasets. Datasets, code, and trained models are available for research at https://github.com/HqiTao/CT-crackseg.
A numerical approximation method for the Fisher-Rao distance between multivariate normal distributions
Feb 16, 2023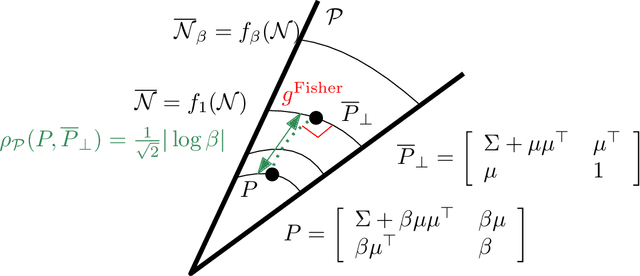
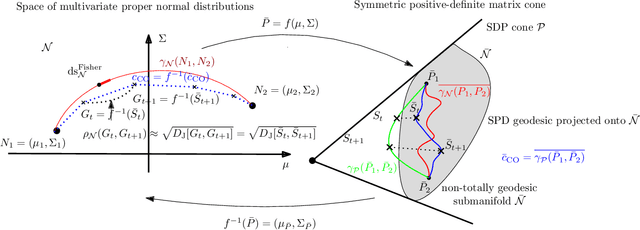
We present a method to approximate Rao's distance between multivariate normal distributions based on discretizing curves joining normal distributions and approximating Rao distances between successive nearby normals on the curve by using Jeffrey's divergence. We consider experimentally the linear interpolation curves in the ordinary, natural and expectation parameterizations of the normal distributions. We further consider a curve derived from the Calvo and Oller's isometric embedding of the Fisher-Rao $d$-variate normal manifold into the cone of $(d+1)\times (d+1)$ symmetric positive-definite matrices [Journal of multivariate analysis 35.2 (1990): 223-242]. Last, we present some information-geometric properties of the Calvo and Oller's mapping.
Distinguishability Calibration to In-Context Learning
Feb 13, 2023
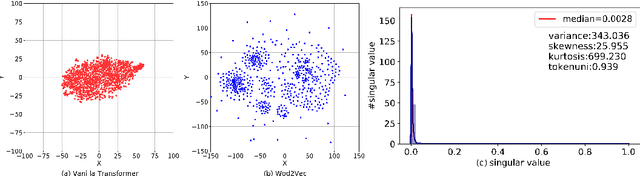
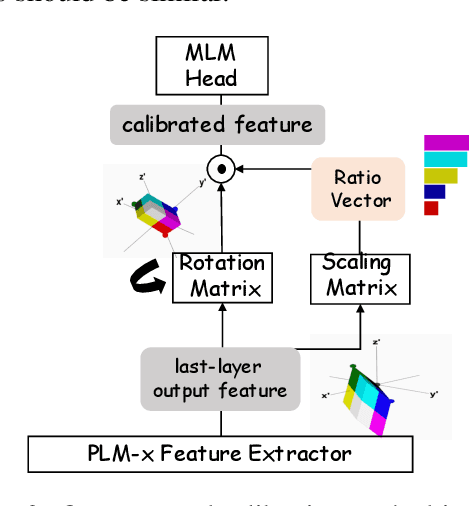
Recent years have witnessed increasing interests in prompt-based learning in which models can be trained on only a few annotated instances, making them suitable in low-resource settings. When using prompt-based learning for text classification, the goal is to use a pre-trained language model (PLM) to predict a missing token in a pre-defined template given an input text, which can be mapped to a class label. However, PLMs built on the transformer architecture tend to generate similar output embeddings, making it difficult to discriminate between different class labels. The problem is further exacerbated when dealing with classification tasks involving many fine-grained class labels. In this work, we alleviate this information diffusion issue, i.e., different tokens share a large proportion of similar information after going through stacked multiple self-attention layers in a transformer, by proposing a calibration method built on feature transformations through rotation and scaling to map a PLM-encoded embedding into a new metric space to guarantee the distinguishability of the resulting embeddings. Furthermore, we take the advantage of hyperbolic embeddings to capture the hierarchical relations among fine-grained class-associated token embedding by a coarse-to-fine metric learning strategy to enhance the distinguishability of the learned output embeddings. Extensive experiments on the three datasets under various settings demonstrate the effectiveness of our approach. Our code can be found at https://github.com/donttal/TARA.
Transient Hemodynamics Prediction Using an Efficient Octree-Based Deep Learning Model
Feb 13, 2023
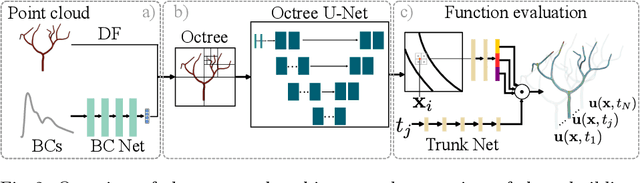
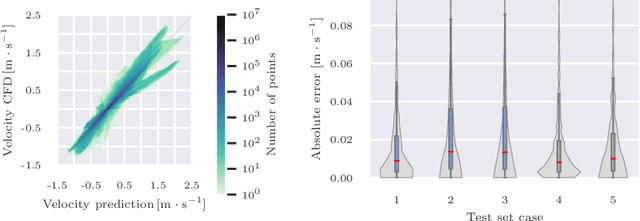
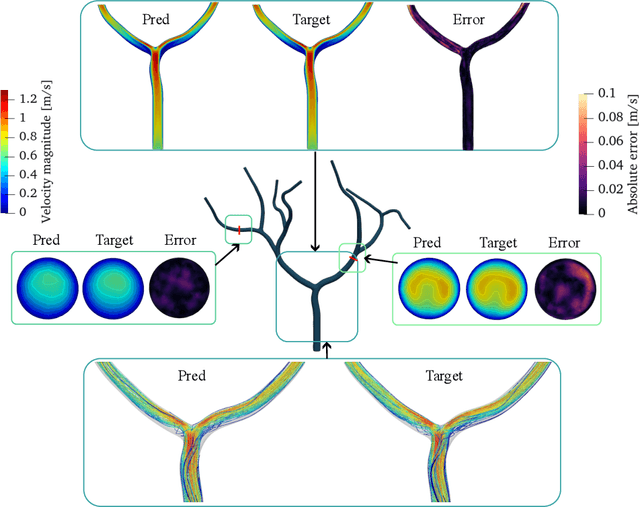
Patient-specific hemodynamics assessment could support diagnosis and treatment of neurovascular diseases. Currently, conventional medical imaging modalities are not able to accurately acquire high-resolution hemodynamic information that would be required to assess complex neurovascular pathologies. Therefore, computational fluid dynamics (CFD) simulations can be applied to tomographic reconstructions to obtain clinically relevant information. However, three-dimensional (3D) CFD simulations require enormous computational resources and simulation-related expert knowledge that are usually not available in clinical environments. Recently, deep-learning-based methods have been proposed as CFD surrogates to improve computational efficiency. Nevertheless, the prediction of high-resolution transient CFD simulations for complex vascular geometries poses a challenge to conventional deep learning models. In this work, we present an architecture that is tailored to predict high-resolution (spatial and temporal) velocity fields for complex synthetic vascular geometries. For this, an octree-based spatial discretization is combined with an implicit neural function representation to efficiently handle the prediction of the 3D velocity field for each time step. The presented method is evaluated for the task of cerebral hemodynamics prediction before and during the injection of contrast agent in the internal carotid artery (ICA). Compared to CFD simulations, the velocity field can be estimated with a mean absolute error of 0.024 m/s, whereas the run time reduces from several hours on a high-performance cluster to a few seconds on a consumer graphical processing unit.
adaPARL: Adaptive Privacy-Aware Reinforcement Learning for Sequential-Decision Making Human-in-the-Loop Systems
Mar 07, 2023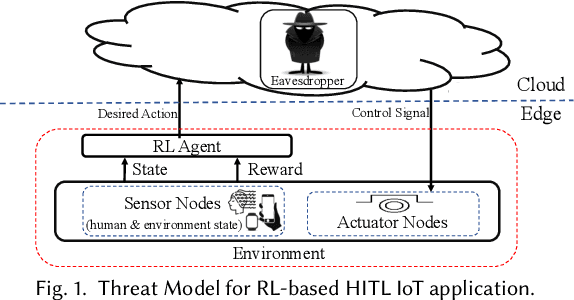
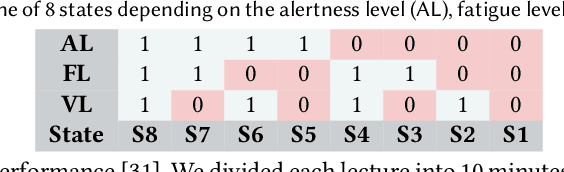
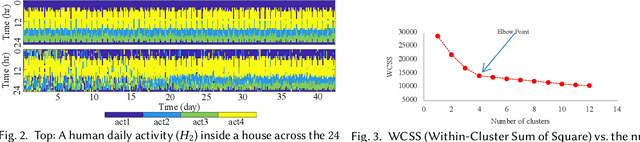
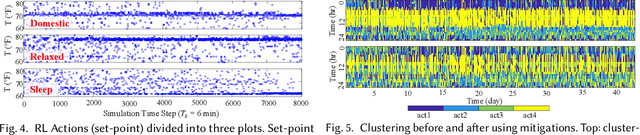
Reinforcement learning (RL) presents numerous benefits compared to rule-based approaches in various applications. Privacy concerns have grown with the widespread use of RL trained with privacy-sensitive data in IoT devices, especially for human-in-the-loop systems. On the one hand, RL methods enhance the user experience by trying to adapt to the highly dynamic nature of humans. On the other hand, trained policies can leak the user's private information. Recent attention has been drawn to designing privacy-aware RL algorithms while maintaining an acceptable system utility. A central challenge in designing privacy-aware RL, especially for human-in-the-loop systems, is that humans have intrinsic variability and their preferences and behavior evolve. The effect of one privacy leak mitigation can be different for the same human or across different humans over time. Hence, we can not design one fixed model for privacy-aware RL that fits all. To that end, we propose adaPARL, an adaptive approach for privacy-aware RL, especially for human-in-the-loop IoT systems. adaPARL provides a personalized privacy-utility trade-off depending on human behavior and preference. We validate the proposed adaPARL on two IoT applications, namely (i) Human-in-the-Loop Smart Home and (ii) Human-in-the-Loop Virtual Reality (VR) Smart Classroom. Results obtained on these two applications validate the generality of adaPARL and its ability to provide a personalized privacy-utility trade-off. On average, for the first application, adaPARL improves the utility by $57\%$ over the baseline and by $43\%$ over randomization. adaPARL also reduces the privacy leak by $23\%$ on average. For the second application, adaPARL decreases the privacy leak to $44\%$ before the utility drops by $15\%$.