 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Active Reward Learning from Multiple Teachers
Mar 02, 2023
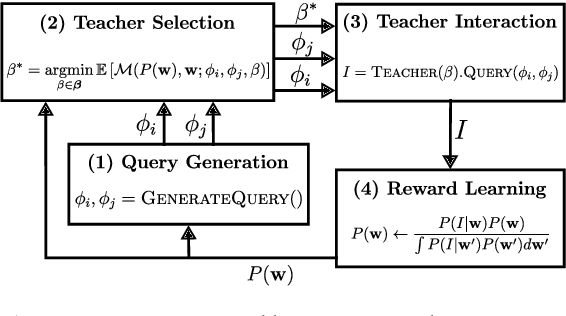

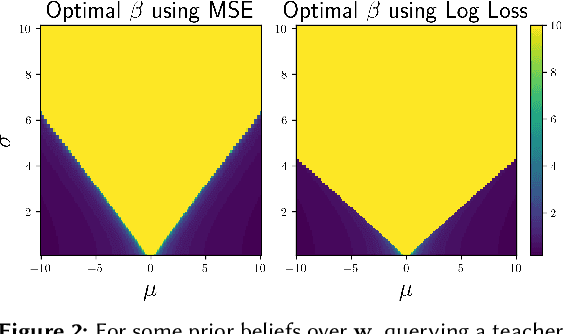
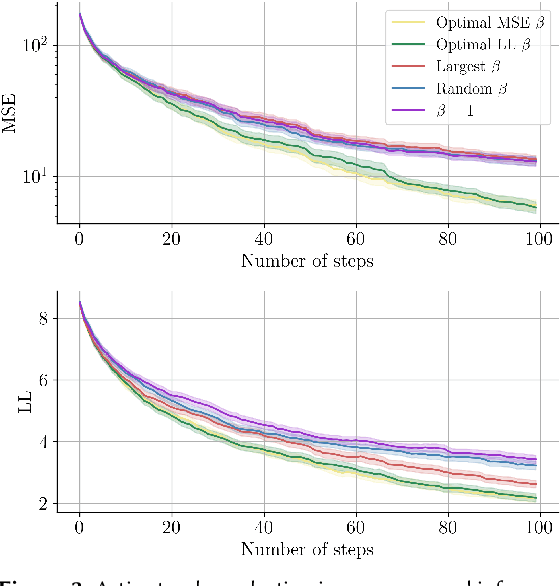
Reward learning algorithms utilize human feedback to infer a reward function, which is then used to train an AI system. This human feedback is often a preference comparison, in which the human teacher compares several samples of AI behavior and chooses which they believe best accomplishes the objective. While reward learning typically assumes that all feedback comes from a single teacher, in practice these systems often query multiple teachers to gather sufficient training data. In this paper, we investigate this disparity, and find that algorithmic evaluation of these different sources of feedback facilitates more accurate and efficient reward learning. We formally analyze the value of information (VOI) when reward learning from teachers with varying levels of rationality, and define and evaluate an algorithm that utilizes this VOI to actively select teachers to query for feedback. Surprisingly, we find that it is often more informative to query comparatively irrational teachers. By formalizing this problem and deriving an analytical solution, we hope to facilitate improvement in reward learning approaches to aligning AI behavior with human values.
Unsupervised Meta-Learning via Few-shot Pseudo-supervised Contrastive Learning
Mar 02, 2023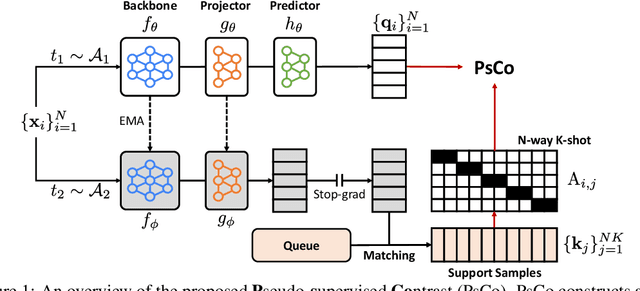
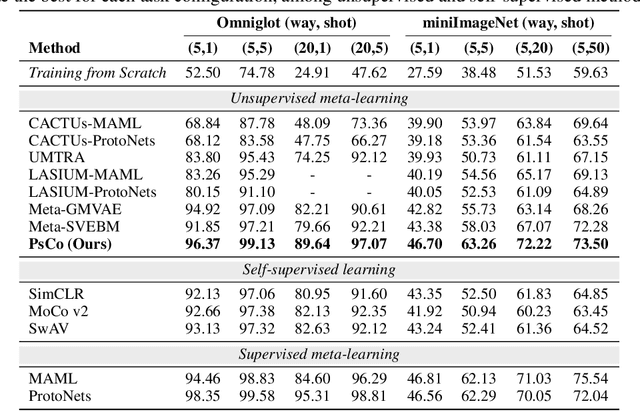
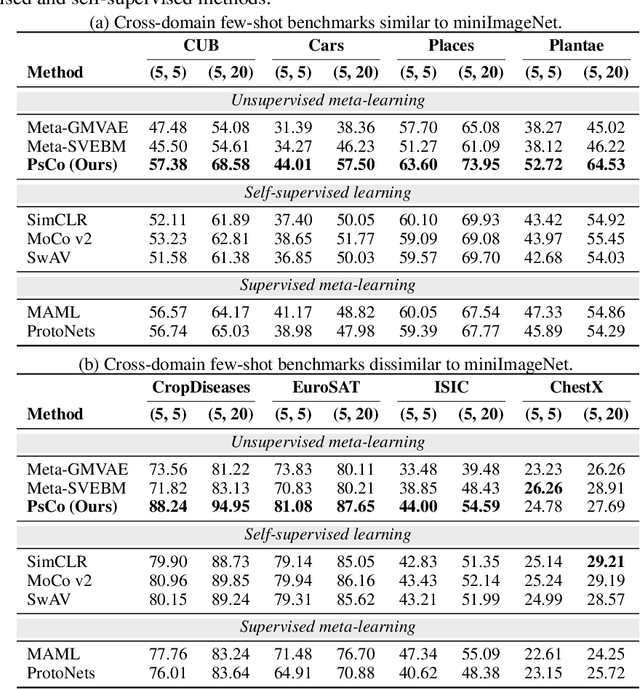
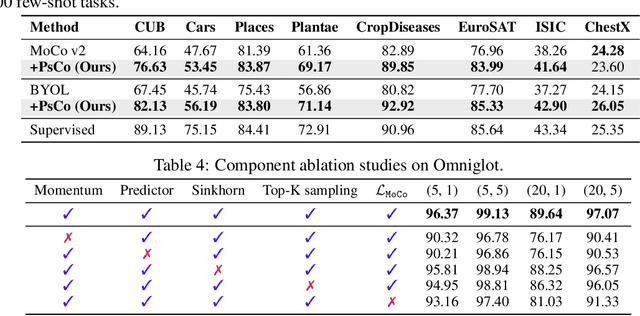
Unsupervised meta-learning aims to learn generalizable knowledge across a distribution of tasks constructed from unlabeled data. Here, the main challenge is how to construct diverse tasks for meta-learning without label information; recent works have proposed to create, e.g., pseudo-labeling via pretrained representations or creating synthetic samples via generative models. However, such a task construction strategy is fundamentally limited due to heavy reliance on the immutable pseudo-labels during meta-learning and the quality of the representations or the generated samples. To overcome the limitations, we propose a simple yet effective unsupervised meta-learning framework, coined Pseudo-supervised Contrast (PsCo), for few-shot classification. We are inspired by the recent self-supervised learning literature; PsCo utilizes a momentum network and a queue of previous batches to improve pseudo-labeling and construct diverse tasks in a progressive manner. Our extensive experiments demonstrate that PsCo outperforms existing unsupervised meta-learning methods under various in-domain and cross-domain few-shot classification benchmarks. We also validate that PsCo is easily scalable to a large-scale benchmark, while recent prior-art meta-schemes are not.
Supervised topological data analysis for MALDI imaging applications
Feb 27, 2023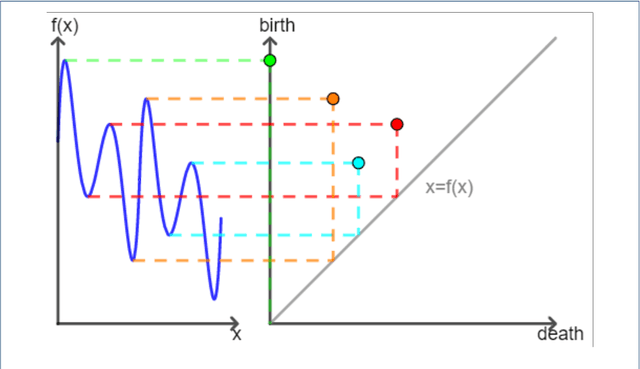
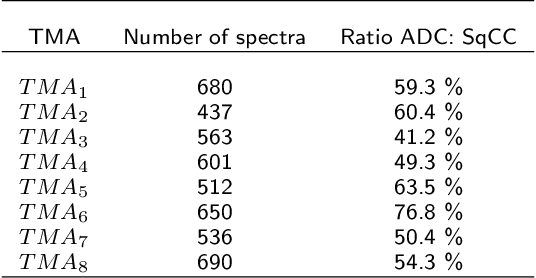
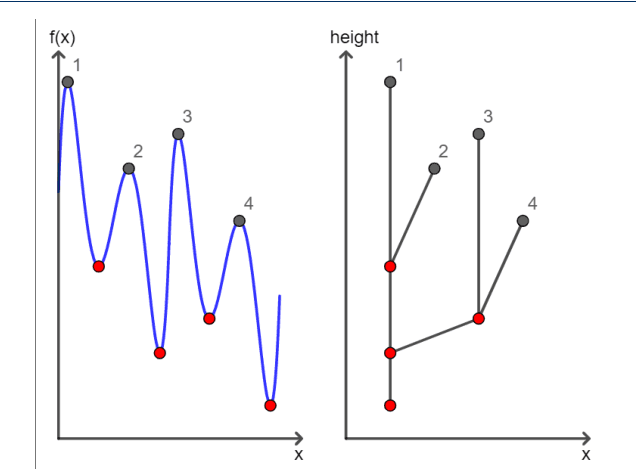
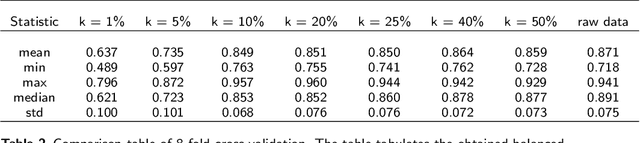
We propose a new algebraic topological framework, which obtains intrinsic information from the MALDI data and transforms it to reflect topological persistence in the data. Our framework has two main advantages. First, the topological persistence helps us to distinguish the signal from noise. Second, it compresses the MALDI data, which results in saving storage space, and also optimizes the computational time for further classification tasks. We introduce an algorithm that performs our topological framework and depends on a single tuning parameter. Furthermore, we show that it is computationally efficient. Following the persistence extraction, logistic regression and random forest classifiers are executed based on the resulting persistence transformation diagrams to classify the observational units into binary class labels, describing the lung cancer subtypes. Further, we utilized the proposed framework in a real-world MALDI data set, and the competitiveness of the methods is illustrated via cross-validation.
DST: Deformable Speech Transformer for Emotion Recognition
Feb 27, 2023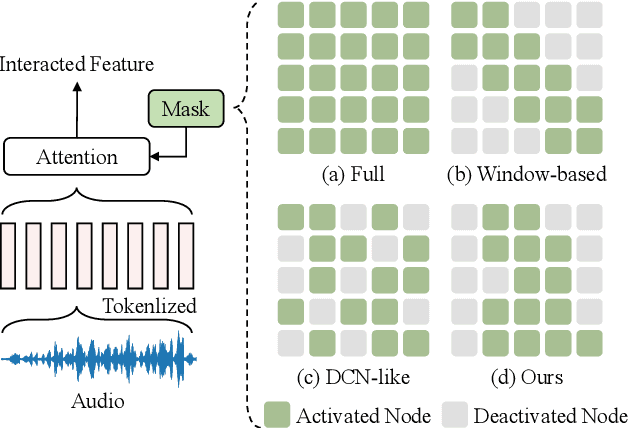
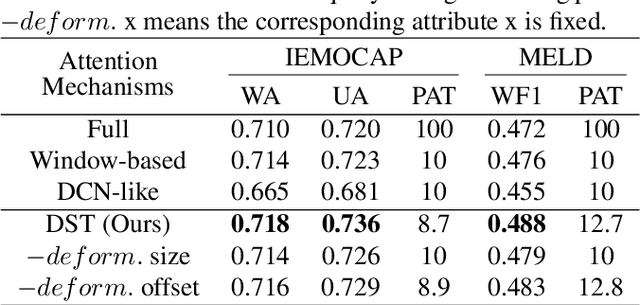
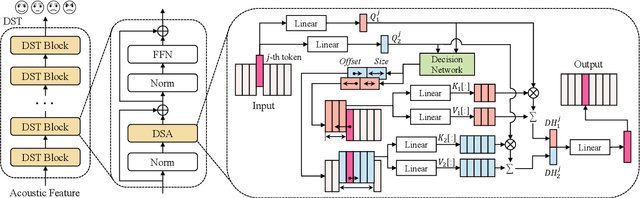
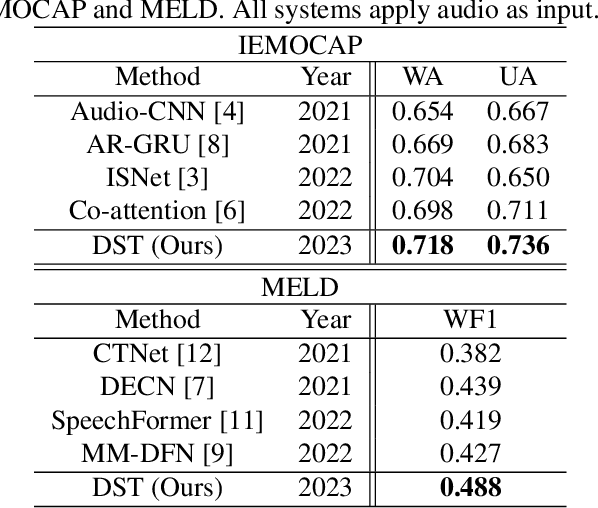
Enabled by multi-head self-attention, Transformer has exhibited remarkable results in speech emotion recognition (SER). Compared to the original full attention mechanism, window-based attention is more effective in learning fine-grained features while greatly reducing model redundancy. However, emotional cues are present in a multi-granularity manner such that the pre-defined fixed window can severely degrade the model flexibility. In addition, it is difficult to obtain the optimal window settings manually. In this paper, we propose a Deformable Speech Transformer, named DST, for SER task. DST determines the usage of window sizes conditioned on input speech via a light-weight decision network. Meanwhile, data-dependent offsets derived from acoustic features are utilized to adjust the positions of the attention windows, allowing DST to adaptively discover and attend to the valuable information embedded in the speech. Extensive experiments on IEMOCAP and MELD demonstrate the superiority of DST.
Active Reward Learning from Online Preferences
Feb 27, 2023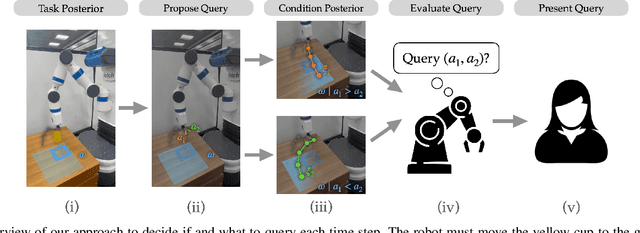


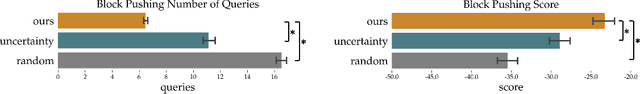
Robot policies need to adapt to human preferences and/or new environments. Human experts may have the domain knowledge required to help robots achieve this adaptation. However, existing works often require costly offline re-training on human feedback, and those feedback usually need to be frequent and too complex for the humans to reliably provide. To avoid placing undue burden on human experts and allow quick adaptation in critical real-world situations, we propose designing and sparingly presenting easy-to-answer pairwise action preference queries in an online fashion. Our approach designs queries and determines when to present them to maximize the expected value derived from the queries' information. We demonstrate our approach with experiments in simulation, human user studies, and real robot experiments. In these settings, our approach outperforms baseline techniques while presenting fewer queries to human experts. Experiment videos, code and appendices are found at https://sites.google.com/view/onlineactivepreferences.
Object Reconfiguration with Simulation-Derived Feasible Actions
Feb 27, 2023
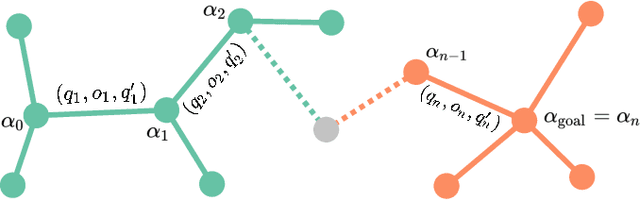
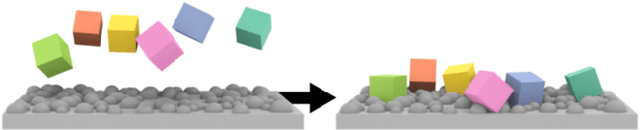

3D object reconfiguration encompasses common robot manipulation tasks in which a set of objects must be moved through a series of physically feasible state changes into a desired final configuration. Object reconfiguration is challenging to solve in general, as it requires efficient reasoning about environment physics that determine action validity. This information is typically manually encoded in an explicit transition system. Constructing these explicit encodings is tedious and error-prone, and is often a bottleneck for planner use. In this work, we explore embedding a physics simulator within a motion planner to implicitly discover and specify the valid actions from any state, removing the need for manual specification of action semantics. Our experiments demonstrate that the resulting simulation-based planner can effectively produce physically valid rearrangement trajectories for a range of 3D object reconfiguration problems without requiring more than an environment description and start and goal arrangements.
Item Cold Start Recommendation via Adversarial Variational Auto-encoder Warm-up
Feb 28, 2023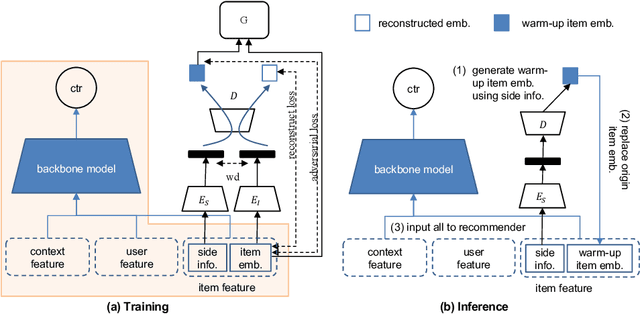
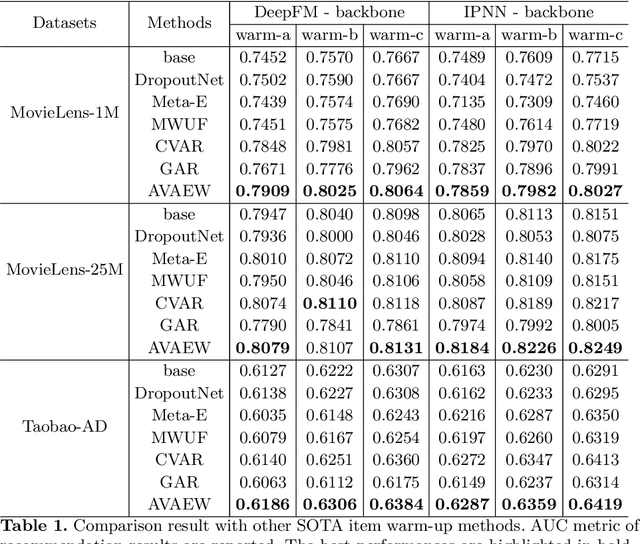
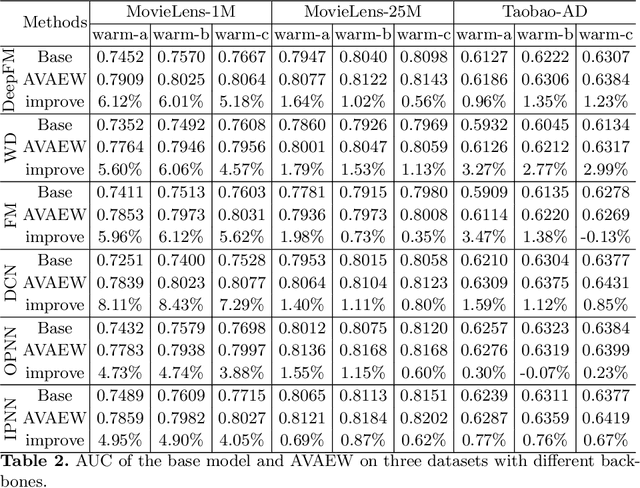
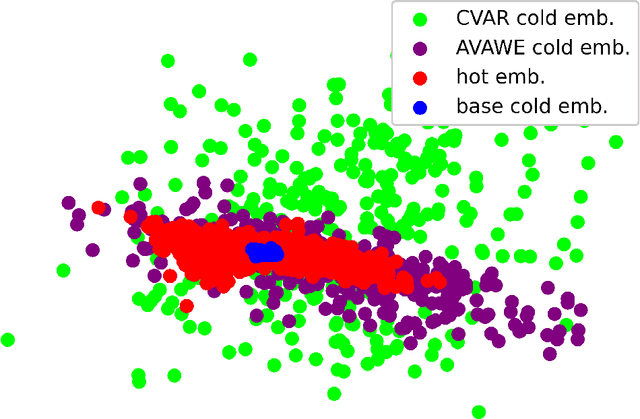
The gap between the randomly initialized item ID embedding and the well-trained warm item ID embedding makes the cold items hard to suit the recommendation system, which is trained on the data of historical warm items. To alleviate the performance decline of new items recommendation, the distribution of the new item ID embedding should be close to that of the historical warm items. To achieve this goal, we propose an Adversarial Variational Auto-encoder Warm-up model (AVAEW) to generate warm-up item ID embedding for cold items. Specifically, we develop a conditional variational auto-encoder model to leverage the side information of items for generating the warm-up item ID embedding. Particularly, we introduce an adversarial module to enforce the alignment between warm-up item ID embedding distribution and historical item ID embedding distribution. We demonstrate the effectiveness and compatibility of the proposed method by extensive offline experiments on public datasets and online A/B tests on a real-world large-scale news recommendation platform.
IntrinsicNGP: Intrinsic Coordinate based Hash Encoding for Human NeRF
Feb 28, 2023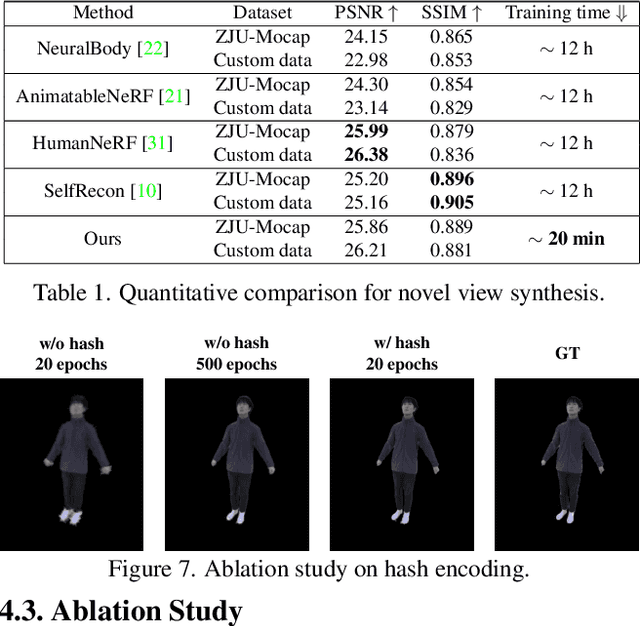
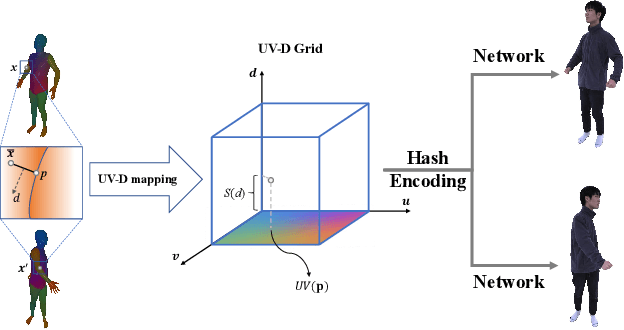
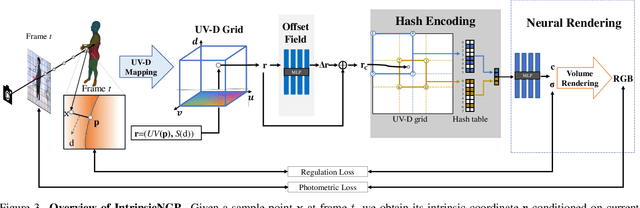
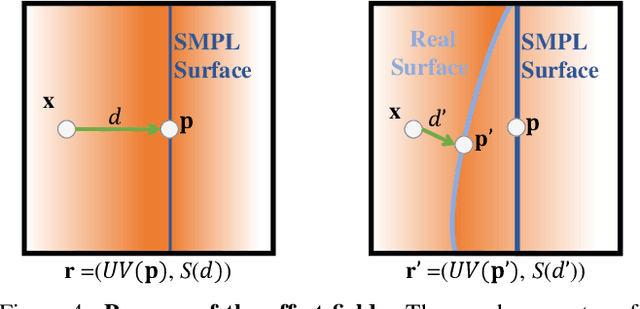
Recently, many works have been proposed to utilize the neural radiance field for novel view synthesis of human performers. However, most of these methods require hours of training, making them difficult for practical use. To address this challenging problem, we propose IntrinsicNGP, which can train from scratch and achieve high-fidelity results in few minutes with videos of a human performer. To achieve this target, we introduce a continuous and optimizable intrinsic coordinate rather than the original explicit Euclidean coordinate in the hash encoding module of instant-NGP. With this novel intrinsic coordinate, IntrinsicNGP can aggregate inter-frame information for dynamic objects with the help of proxy geometry shapes. Moreover, the results trained with the given rough geometry shapes can be further refined with an optimizable offset field based on the intrinsic coordinate.Extensive experimental results on several datasets demonstrate the effectiveness and efficiency of IntrinsicNGP. We also illustrate our approach's ability to edit the shape of reconstructed subjects.
Learnt Deep Hyperparameter selection in Adversarial Training for compressed video enhancement with perceptual critic
Feb 28, 2023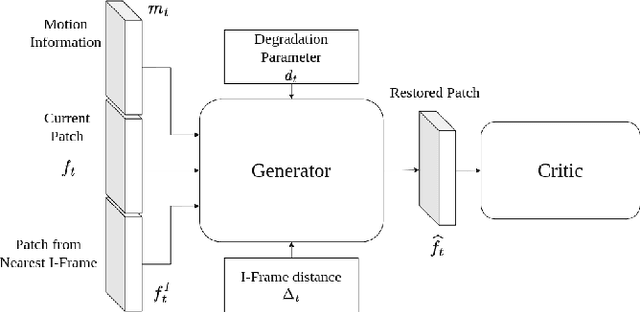
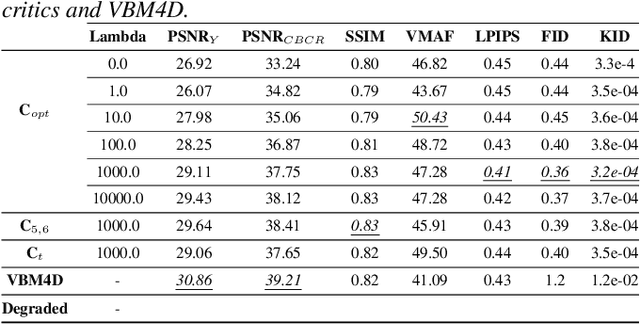
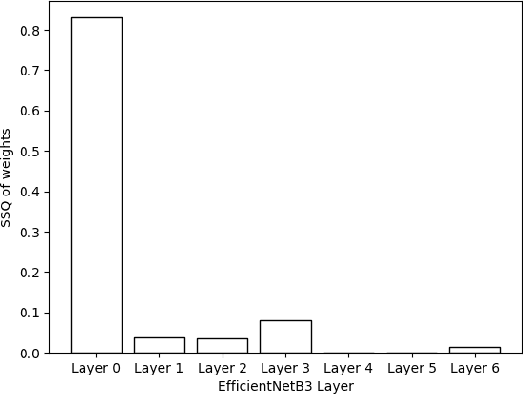
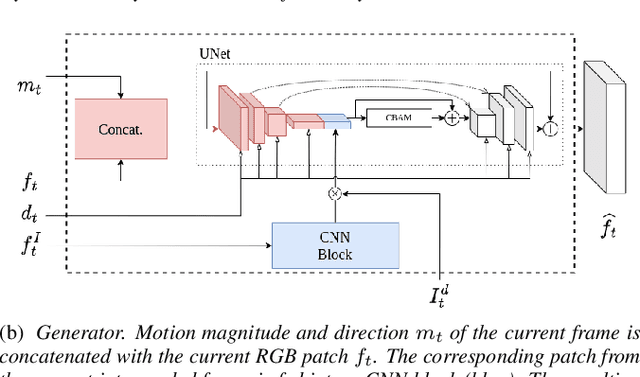
Image based Deep Feature Quality Metrics (DFQMs) have been shown to better correlate with subjective perceptual scores over traditional metrics. The fundamental focus of these DFQMs is to exploit internal representations from a large scale classification network as the metric feature space. Previously, no attention has been given to the problem of identifying which layers are most perceptually relevant. In this paper we present a new method for selecting perceptually relevant layers from such a network, based on a neuroscience interpretation of layer behaviour. The selected layers are treated as a hyperparameter to the critic network in a W-GAN. The critic uses the output from these layers in the preliminary stages to extract perceptual information. A video enhancement network is trained adversarially with this critic. Our results show that the introduction of these selected features into the critic yields up to 10% (FID) and 15% (KID) performance increase against other critic networks that do not exploit the idea of optimised feature selection.
Knowledge Discovery from Atomic Structures using Feature Importances
Feb 28, 2023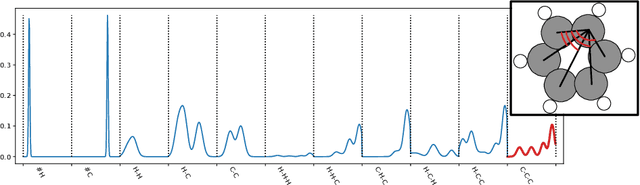
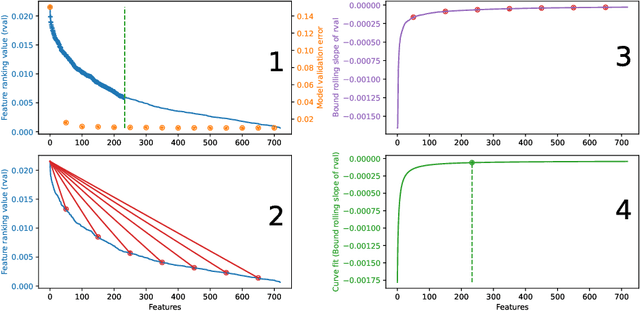
Molecular-level understanding of the interactions between the constituents of an atomic structure is essential for designing novel materials in various applications. This need goes beyond the basic knowledge of the number and types of atoms, their chemical composition, and the character of the chemical interactions. The bigger picture takes place on the quantum level which can be addressed by using the Density-functional theory (DFT). Use of DFT, however, is a computationally taxing process, and its results do not readily provide easily interpretable insight into the atomic interactions which would be useful information in material design. An alternative way to address atomic interactions is to use an interpretable machine learning approach, where a predictive DFT surrogate is constructed and analyzed. The purpose of this paper is to propose such a procedure using a modification of the recently published interpretable distance-based regression method. Our tests with a representative benchmark set of molecules and a complex hybrid nanoparticle confirm the viability and usefulness of the proposed approach.