 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Enhancing Knowledge Graph Embedding Models with Semantic-driven Loss Functions
Mar 09, 2023


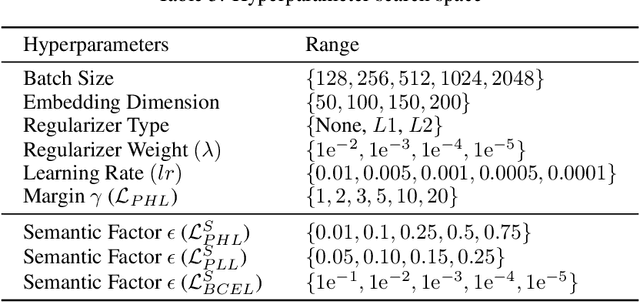
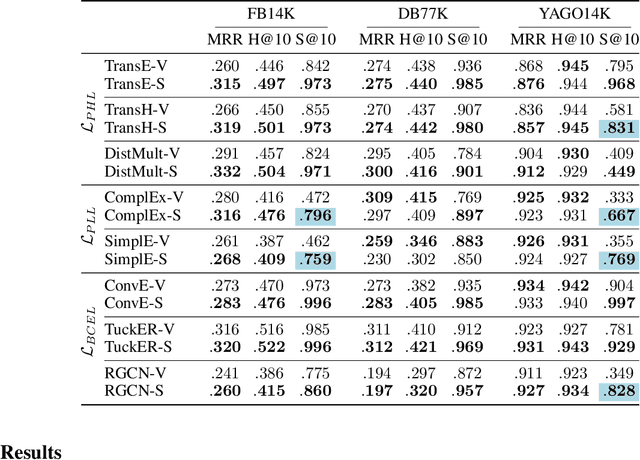
Knowledge graph embedding models (KGEMs) are used for various tasks related to knowledge graphs (KGs), including link prediction. They are trained with loss functions that are computed considering a batch of scored triples and their corresponding labels. Traditional approaches consider the label of a triple to be either true or false. However, recent works suggest that all negative triples should not be valued equally. In line with this recent assumption, we posit that semantically valid negative triples might be high-quality negative triples. As such, loss functions should treat them differently from semantically invalid negative ones. To this aim, we propose semantic-driven versions for the three main loss functions for link prediction. In particular, we treat the scores of negative triples differently by injecting background knowledge about relation domains and ranges into the loss functions. In an extensive and controlled experimental setting, we show that the proposed loss functions systematically provide satisfying results on three public benchmark KGs underpinned with different schemas, which demonstrates both the generality and superiority of our proposed approach. In fact, the proposed loss functions do (1) lead to better MRR and Hits@$10$ values, (2) drive KGEMs towards better semantic awareness. This highlights that semantic information globally improves KGEMs, and thus should be incorporated into loss functions. Domains and ranges of relations being largely available in schema-defined KGs, this makes our approach both beneficial and widely usable in practice.
Finding the Law: Enhancing Statutory Article Retrieval via Graph Neural Networks
Jan 30, 2023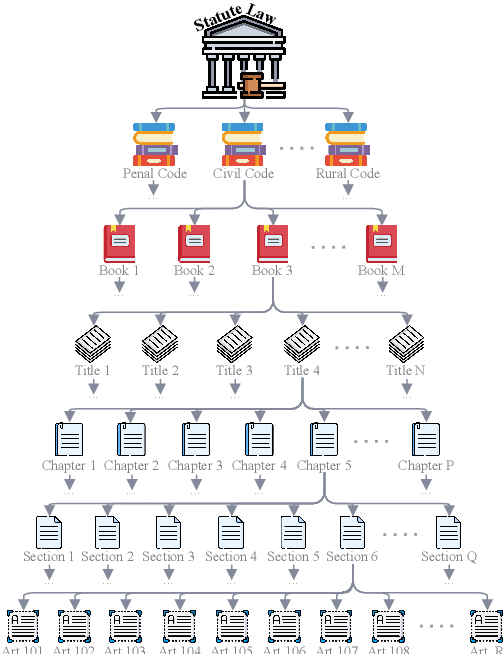
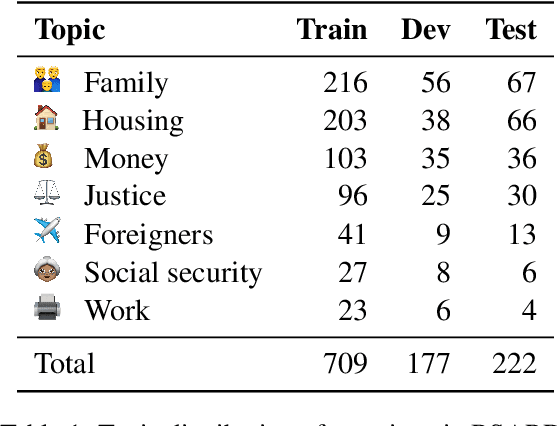
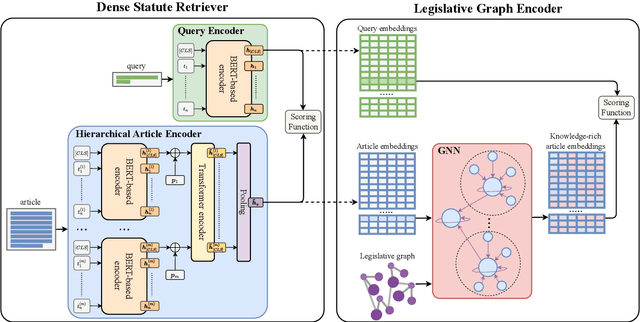
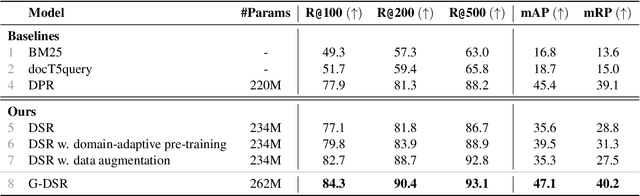
Statutory article retrieval (SAR), the task of retrieving statute law articles relevant to a legal question, is a promising application of legal text processing. In particular, high-quality SAR systems can improve the work efficiency of legal professionals and provide basic legal assistance to citizens in need at no cost. Unlike traditional ad-hoc information retrieval, where each document is considered a complete source of information, SAR deals with texts whose full sense depends on complementary information from the topological organization of statute law. While existing works ignore these domain-specific dependencies, we propose a novel graph-augmented dense statute retriever (G-DSR) model that incorporates the structure of legislation via a graph neural network to improve dense retrieval performance. Experimental results show that our approach outperforms strong retrieval baselines on a real-world expert-annotated SAR dataset.
Quantifying Context Mixing in Transformers
Jan 30, 2023
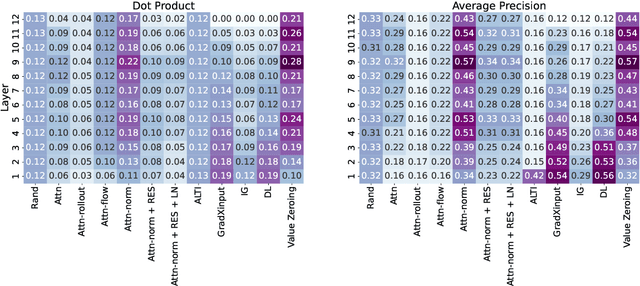
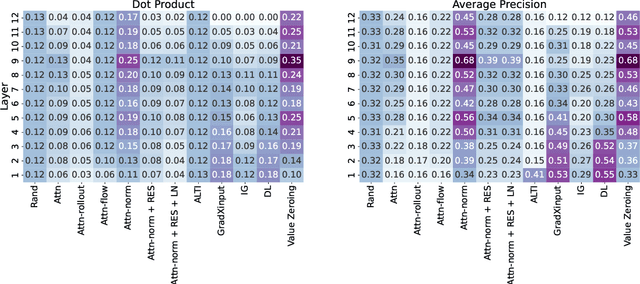
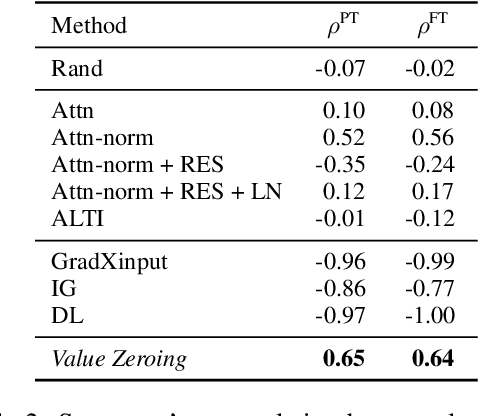
Self-attention weights and their transformed variants have been the main source of information for analyzing token-to-token interactions in Transformer-based models. But despite their ease of interpretation, these weights are not faithful to the models' decisions as they are only one part of an encoder, and other components in the encoder layer can have considerable impact on information mixing in the output representations. In this work, by expanding the scope of analysis to the whole encoder block, we propose Value Zeroing, a novel context mixing score customized for Transformers that provides us with a deeper understanding of how information is mixed at each encoder layer. We demonstrate the superiority of our context mixing score over other analysis methods through a series of complementary evaluations with different viewpoints based on linguistically informed rationales, probing, and faithfulness analysis.
Visible and Near Infrared Image Fusion Based on Texture Information
Jul 22, 2022



Multi-sensor fusion is widely used in the environment perception system of the autonomous vehicle. It solves the interference caused by environmental changes and makes the whole driving system safer and more reliable. In this paper, a novel visible and near-infrared fusion method based on texture information is proposed to enhance unstructured environmental images. It aims at the problems of artifact, information loss and noise in traditional visible and near infrared image fusion methods. Firstly, the structure information of the visible image (RGB) and the near infrared image (NIR) after texture removal is obtained by relative total variation (RTV) calculation as the base layer of the fused image; secondly, a Bayesian classification model is established to calculate the noise weight and the noise information and the noise information in the visible image is adaptively filtered by joint bilateral filter; finally, the fused image is acquired by color space conversion. The experimental results demonstrate that the proposed algorithm can preserve the spectral characteristics and the unique information of visible and near-infrared images without artifacts and color distortion, and has good robustness as well as preserving the unique texture.
EvHandPose: Event-based 3D Hand Pose Estimation with Sparse Supervision
Mar 06, 2023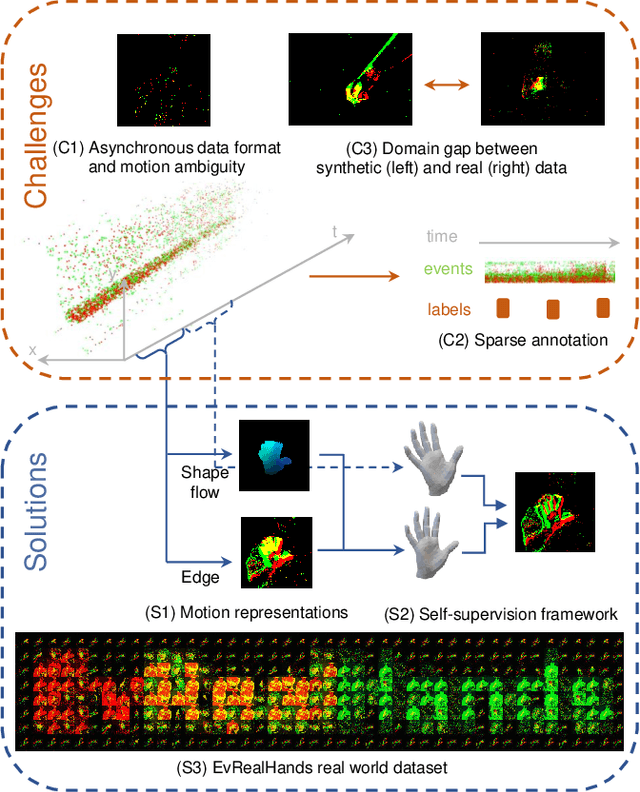

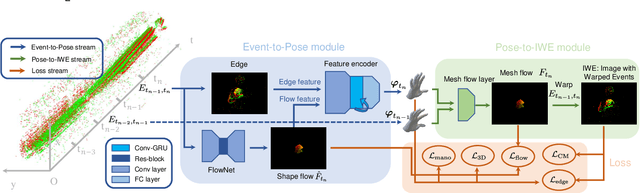

Event camera shows great potential in 3D hand pose estimation, especially addressing the challenges of fast motion and high dynamic range in a low-power way. However, due to the asynchronous differential imaging mechanism, it is challenging to design event representation to encode hand motion information especially when the hands are not moving (causing motion ambiguity), and it is infeasible to fully annotate the temporally dense event stream. In this paper, we propose EvHandPose with novel hand flow representations in Event-to-Pose module for accurate hand pose estimation and alleviating the motion ambiguity issue. To solve the problem under sparse annotation, we design contrast maximization and edge constraints in Pose-to-IWE (Image with Warped Events) module and formulate EvHandPose in a self-supervision framework. We further build EvRealHands, the first large-scale real-world event-based hand pose dataset on several challenging scenes to bridge the domain gap due to relying on synthetic data and facilitate future research. Experiments on EvRealHands demonstrate that EvHandPose outperforms previous event-based method under all evaluation scenes with 15 $\sim$ 20 mm lower MPJPE and achieves accurate and stable hand pose estimation in fast motion and strong light scenes compared with RGB-based methods. Furthermore, EvHandPose demonstrates 3D hand pose estimation at 120 fps or higher.
Knowledge-embedded meta-learning model for lift coefficient prediction of airfoils
Mar 06, 2023
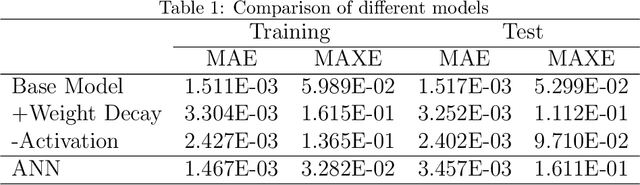
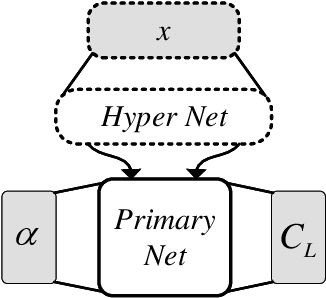
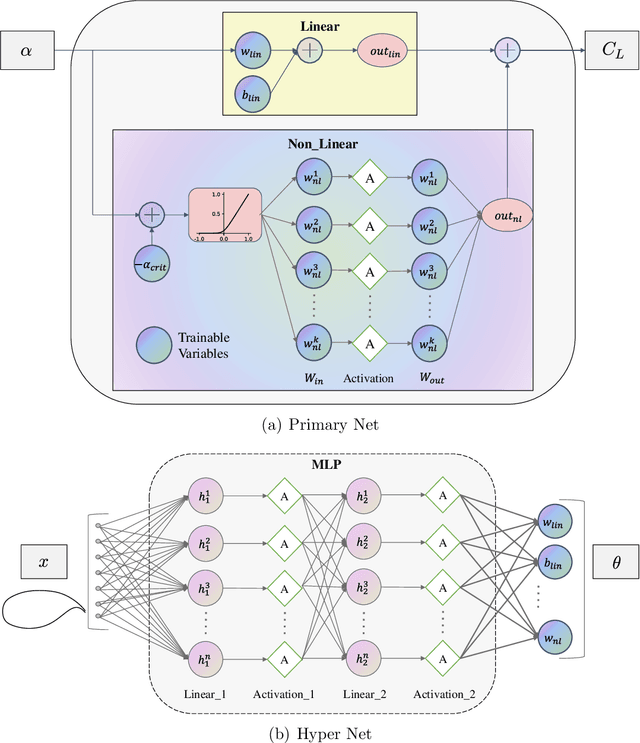
Aerodynamic performance evaluation is an important part of the aircraft aerodynamic design optimization process; however, traditional methods are costly and time-consuming. Despite the fact that various machine learning methods can achieve high accuracy, their application in engineering is still difficult due to their poor generalization performance and "black box" nature. In this paper, a knowledge-embedded meta learning model, which fully integrates data with the theoretical knowledge of the lift curve, is developed to obtain the lift coefficients of an arbitrary supercritical airfoil under various angle of attacks. In the proposed model, a primary network is responsible for representing the relationship between the lift and angle of attack, while the geometry information is encoded into a hyper network to predict the unknown parameters involved in the primary network. Specifically, three models with different architectures are trained to provide various interpretations. Compared to the ordinary neural network, our proposed model can exhibit better generalization capability with competitive prediction accuracy. Afterward, interpretable analysis is performed based on the Integrated Gradients and Saliency methods. Results show that the proposed model can tend to assess the influence of airfoil geometry to the physical characteristics. Furthermore, the exceptions and shortcomings caused by the proposed model are analysed and discussed in detail.
An Online Algorithm for Chance Constrained Resource Allocation
Mar 06, 2023
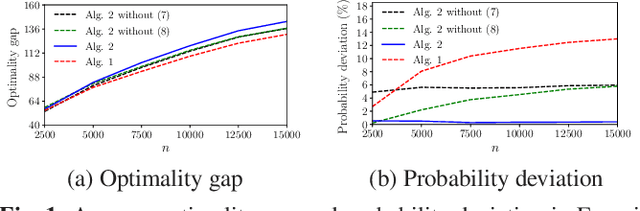
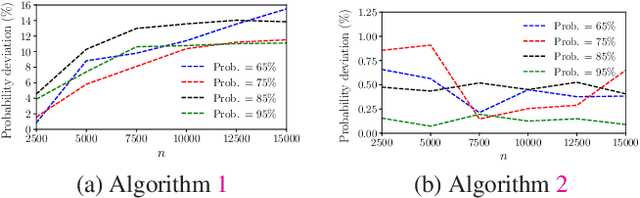
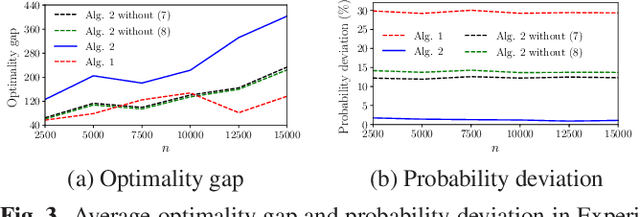
This paper studies the online stochastic resource allocation problem (RAP) with chance constraints. The online RAP is a 0-1 integer linear programming problem where the resource consumption coefficients are revealed column by column along with the corresponding revenue coefficients. When a column is revealed, the corresponding decision variables are determined instantaneously without future information. Moreover, in online applications, the resource consumption coefficients are often obtained by prediction. To model their uncertainties, we take the chance constraints into the consideration. To the best of our knowledge, this is the first time chance constraints are introduced in the online RAP problem. Assuming that the uncertain variables have known Gaussian distributions, the stochastic RAP can be transformed into a deterministic but nonlinear problem with integer second-order cone constraints. Next, we linearize this nonlinear problem and analyze the performance of vanilla online primal-dual algorithm for solving the linearized stochastic RAP. Under mild technical assumptions, the optimality gap and constraint violation are both on the order of $\sqrt{n}$. Then, to further improve the performance of the algorithm, several modified online primal-dual algorithms with heuristic corrections are proposed. Finally, extensive numerical experiments on both synthetic and real data demonstrate the applicability and effectiveness of our methods.
Unsupervised Active Visual Search with Monte Carlo planning under Uncertain Detections
Mar 06, 2023

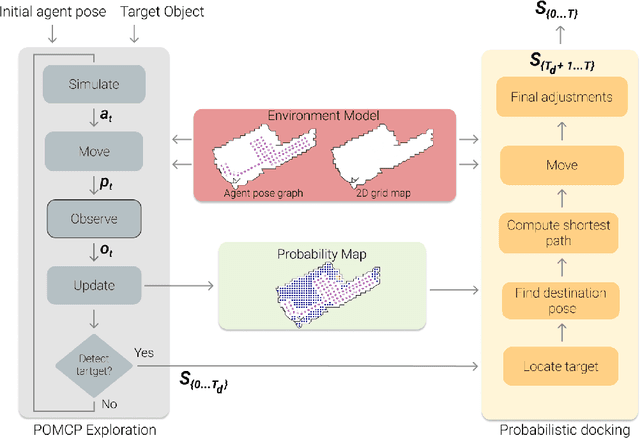
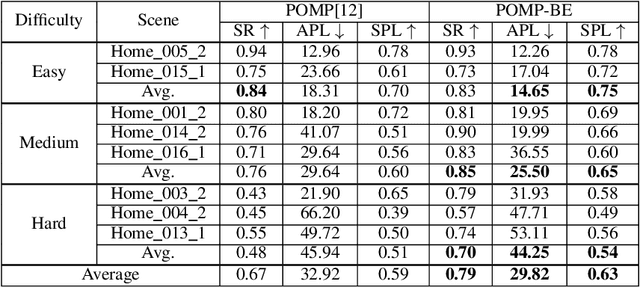
We propose a solution for Active Visual Search of objects in an environment, whose 2D floor map is the only known information. Our solution has three key features that make it more plausible and robust to detector failures compared to state-of-the-art methods: (i) it is unsupervised as it does not need any training sessions. (ii) During the exploration, a probability distribution on the 2D floor map is updated according to an intuitive mechanism, while an improved belief update increases the effectiveness of the agent's exploration. (iii) We incorporate the awareness that an object detector may fail into the aforementioned probability modelling by exploiting the success statistics of a specific detector. Our solution is dubbed POMP-BE-PD (Pomcp-based Online Motion Planning with Belief by Exploration and Probabilistic Detection). It uses the current pose of an agent and an RGB-D observation to learn an optimal search policy, exploiting a POMDP solved by a Monte-Carlo planning approach. On the Active Vision Database benchmark, we increase the average success rate over all the environments by a significant 35% while decreasing the average path length by 4% with respect to competing methods. Thus, our results are state-of-the-art, even without using any training procedure.
Learning Enabled Fast Planning and Control in Dynamic Environments with Intermittent Information
Sep 09, 2022
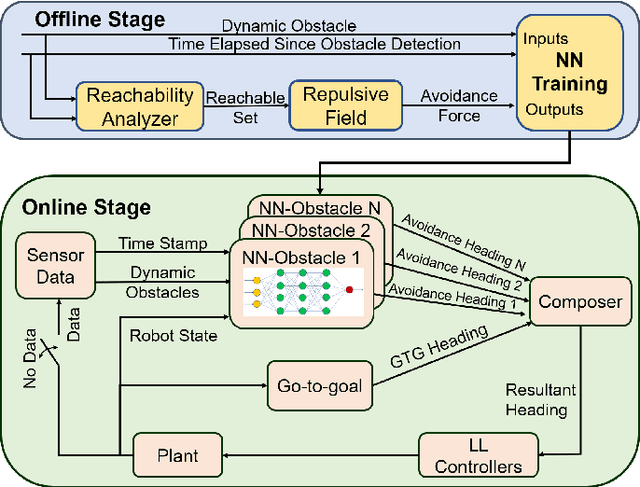
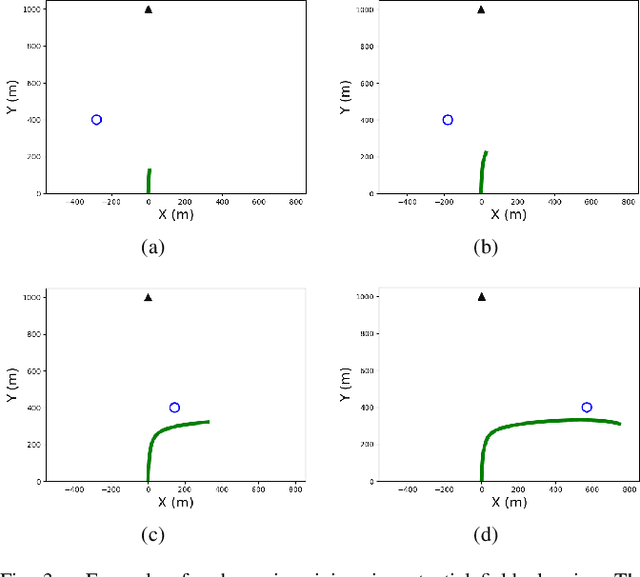
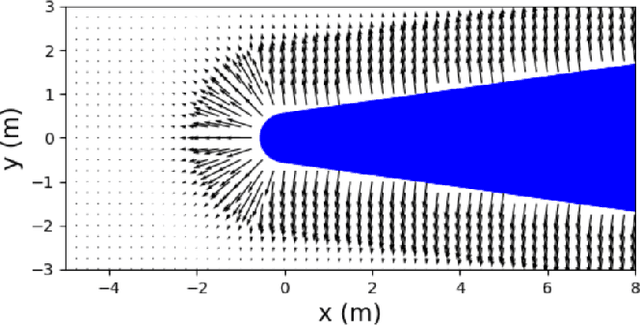
This paper addresses a safe planning and control problem for mobile robots operating in communication- and sensor-limited dynamic environments. In this case the robots cannot sense the objects around them and must instead rely on intermittent, external information about the environment, as e.g., in underwater applications. The challenge in this case is that the robots must plan using only this stale data, while accounting for any noise in the data or uncertainty in the environment. To address this challenge we propose a compositional technique which leverages neural networks to quickly plan and control a robot through crowded and dynamic environments using only intermittent information. Specifically, our tool uses reachability analysis and potential fields to train a neural network that is capable of generating safe control actions. We demonstrate our technique both in simulation with an underwater vehicle crossing a crowded shipping channel and with real experiments with ground vehicles in communication- and sensor-limited environments.
How deep convolutional neural networks lose spatial information with training
Oct 04, 2022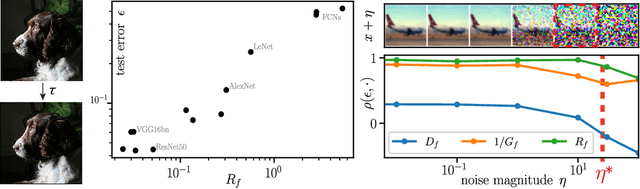
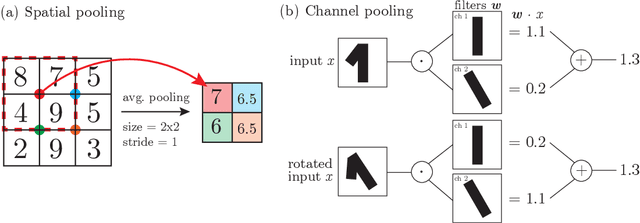
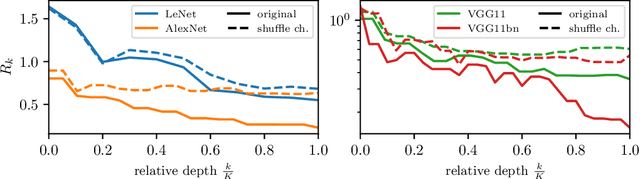
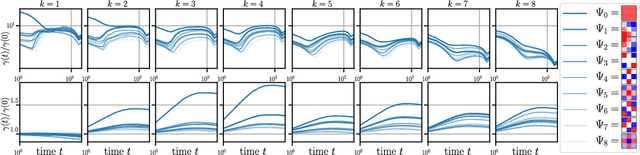
A central question of machine learning is how deep nets manage to learn tasks in high dimensions. An appealing hypothesis is that they achieve this feat by building a representation of the data where information irrelevant to the task is lost. For image datasets, this view is supported by the observation that after (and not before) training, the neural representation becomes less and less sensitive to diffeomorphisms acting on images as the signal propagates through the net. This loss of sensitivity correlates with performance, and surprisingly correlates with a gain of sensitivity to white noise acquired during training. These facts are unexplained, and as we demonstrate still hold when white noise is added to the images of the training set. Here, we (i) show empirically for various architectures that stability to image diffeomorphisms is achieved by spatial pooling in the first half of the net, and by channel pooling in the second half, (ii) introduce a scale-detection task for a simple model of data where pooling is learned during training, which captures all empirical observations above and (iii) compute in this model how stability to diffeomorphisms and noise scale with depth. The scalings are found to depend on the presence of strides in the net architecture. We find that the increased sensitivity to noise is due to the perturbing noise piling up during pooling, after being rectified by ReLU units.