 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Physical Layer Security in Near-Field Communications: What Will Be Changed?
Feb 15, 2023
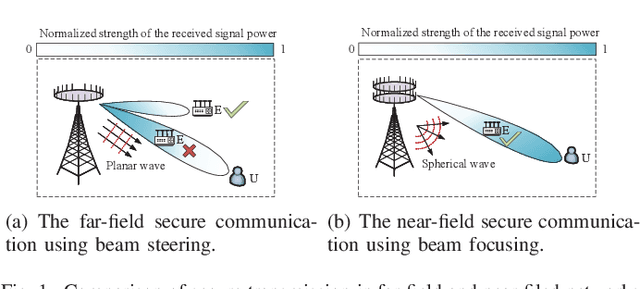
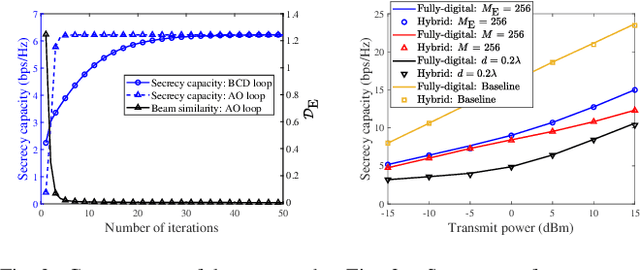
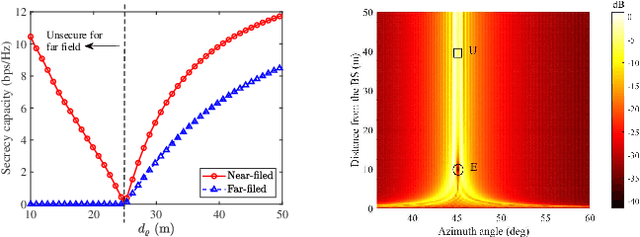
A near-field secure transmission framework is proposed. Employing the hybrid beamforming architecture, a base station (BS) transmits the confidential information to a legitimate user (U) against an eavesdropper (E) in the near field. A two-stage algorithm is proposed to maximize the near-field secrecy capacity. Based on the fully-digital beamformers obtained in the first stage, the optimal analog beamformers and baseband digital beamformers can be alternatingly derived in the closed-form expressions in the second stage. Numerical results demonstrate that in contrast to the far-field secure communication relying on the angular disparity, the near-filed secure communication mainly relies on the distance disparity between U and E.
SCRIMP: Scalable Communication for Reinforcement- and Imitation-Learning-Based Multi-Agent Pathfinding
Mar 02, 2023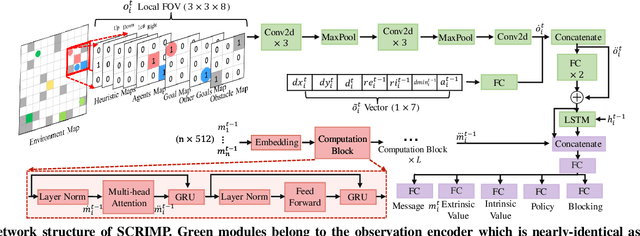
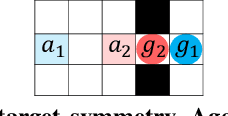
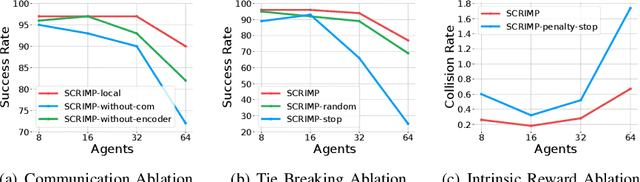
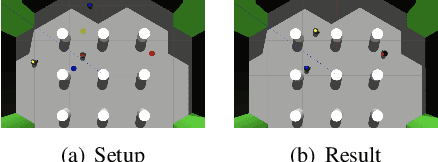
Trading off performance guarantees in favor of scalability, the Multi-Agent Path Finding (MAPF) community has recently started to embrace Multi-Agent Reinforcement Learning (MARL), where agents learn to collaboratively generate individual, collision-free (but often suboptimal) paths. Scalability is usually achieved by assuming a local field of view (FOV) around the agents, helping scale to arbitrary world sizes. However, this assumption significantly limits the amount of information available to the agents, making it difficult for them to enact the type of joint maneuvers needed in denser MAPF tasks. In this paper, we propose SCRIMP, where agents learn individual policies from even very small (down to 3x3) FOVs, by relying on a highly-scalable global/local communication mechanism based on a modified transformer. We further equip agents with a state-value-based tie-breaking strategy to further improve performance in symmetric situations, and introduce intrinsic rewards to encourage exploration while mitigating the long-term credit assignment problem. Empirical evaluations on a set of experiments indicate that SCRIMP can achieve higher performance with improved scalability compared to other state-of-the-art learning-based MAPF planners with larger FOVs, and even yields similar performance as a classical centralized planner in many cases. Ablation studies further validate the effectiveness of our proposed techniques. Finally, we show that our trained model can be directly implemented on real robots for online MAPF through high-fidelity simulations in gazebo.
Pay Less But Get More: A Dual-Attention-based Channel Estimation Network for Massive MIMO Systems with Low-Density Pilots
Mar 02, 2023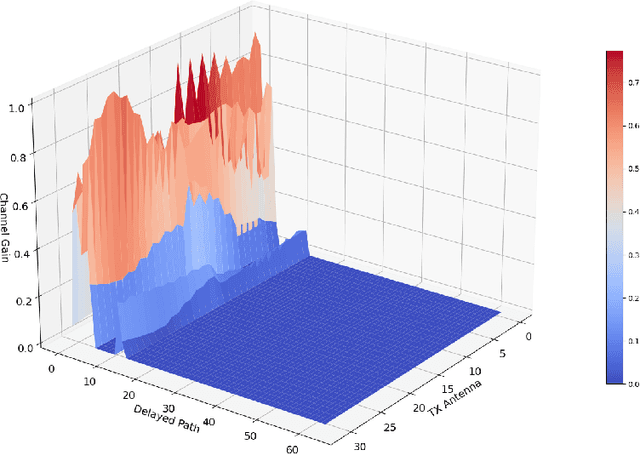
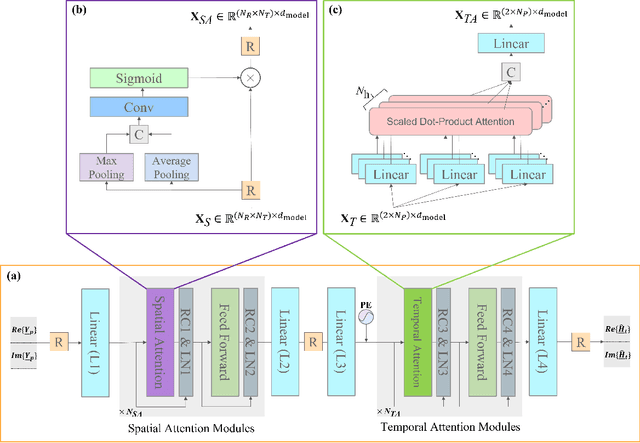
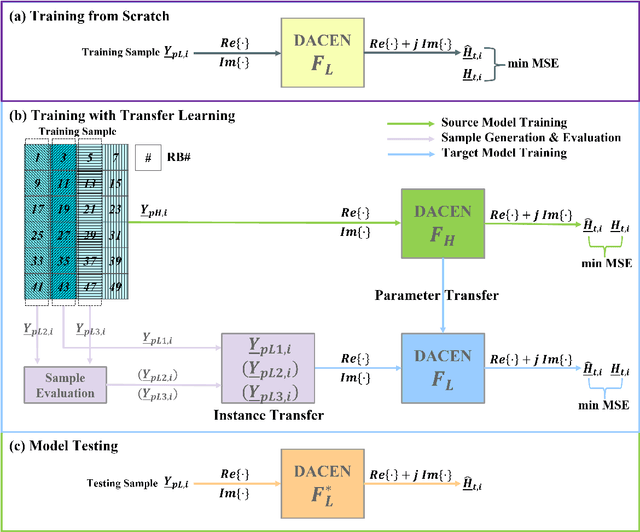
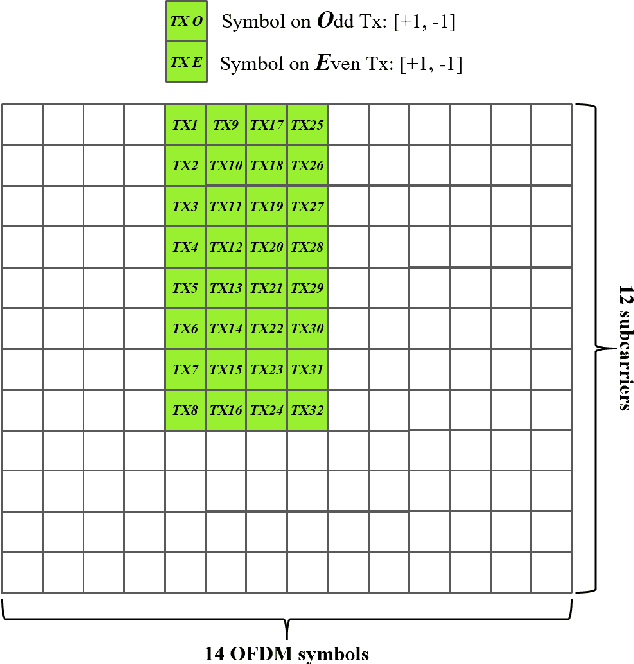
To reap the promising benefits of massive multiple-input multiple-output (MIMO) systems, accurate channel state information (CSI) is required through channel estimation. However, due to the complicated wireless propagation environment and large-scale antenna arrays, precise channel estimation for massive MIMO systems is significantly challenging and costs an enormous training overhead. Considerable time-frequency resources are consumed to acquire sufficient accuracy of CSI, which thus severely degrades systems' spectral and energy efficiencies. In this paper, we propose a dual-attention-based channel estimation network (DACEN) to realize accurate channel estimation via low-density pilots, by decoupling the spatial-temporal domain features of massive MIMO channels with the temporal attention module and the spatial attention module. To further improve the estimation accuracy, we propose a parameter-instance transfer learning approach based on the DACEN to transfer the channel knowledge learned from the high-density pilots pre-acquired during the training dataset collection period. Experimental results on a publicly available dataset reveal that the proposed DACEN-based method with low-density pilots ($\rho_L=6/52$) achieves better channel estimation performance than the existing methods even with higher-density pilots ($\rho_H=26/52$). Additionally, with the proposed transfer learning approach, the DACEN-based method with ultra-low-density pilots ($\rho_L^\prime=2/52$) achieves higher estimation accuracy than the existing methods with low-density pilots, thereby demonstrating the effectiveness and the superiority of the proposed method.
On the Role of Memory in Robust Opinion Dynamics
Feb 16, 2023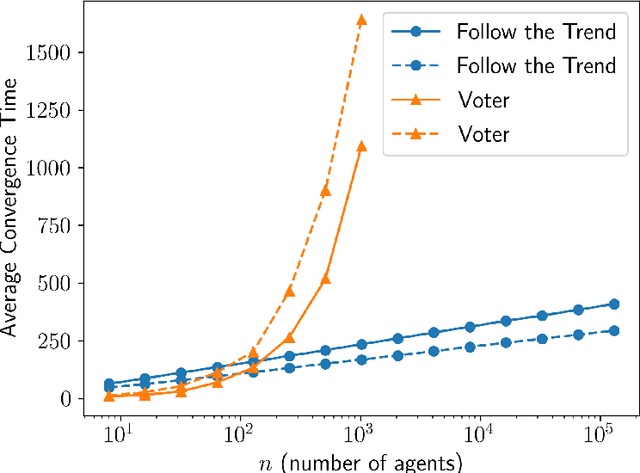
We investigate opinion dynamics in a fully-connected system, consisting of $n$ identical and anonymous agents, where one of the opinions (which is called correct) represents a piece of information to disseminate. In more detail, one source agent initially holds the correct opinion and remains with this opinion throughout the execution. The goal for non-source agents is to quickly agree on this correct opinion, and do that robustly, i.e., from any initial configuration. The system evolves in rounds. In each round, one agent chosen uniformly at random is activated: unless it is the source, the agent pulls the opinions of $\ell$ random agents and then updates its opinion according to some rule. We consider a restricted setting, in which agents have no memory and they only revise their opinions on the basis of those of the agents they currently sample. As restricted as it is, this setting encompasses very popular opinion dynamics, such as the voter model and best-of-$k$ majority rules. Qualitatively speaking, we show that lack of memory prevents efficient convergence. Specifically, we prove that no dynamics can achieve correct convergence in an expected number of steps that is sub-quadratic in $n$, even under a strong version of the model in which activated agents have complete access to the current configuration of the entire system, i.e., the case $\ell=n$. Conversely, we prove that the simple voter model (in which $\ell=1$) correctly solves the problem, while almost matching the aforementioned lower bound. These results suggest that, in contrast to symmetric consensus problems (that do not involve a notion of correct opinion), fast convergence on the correct opinion using stochastic opinion dynamics may indeed require the use of memory. This insight may reflect on natural information dissemination processes that rely on a few knowledgeable individuals.
Joint-MAE: 2D-3D Joint Masked Autoencoders for 3D Point Cloud Pre-training
Feb 27, 2023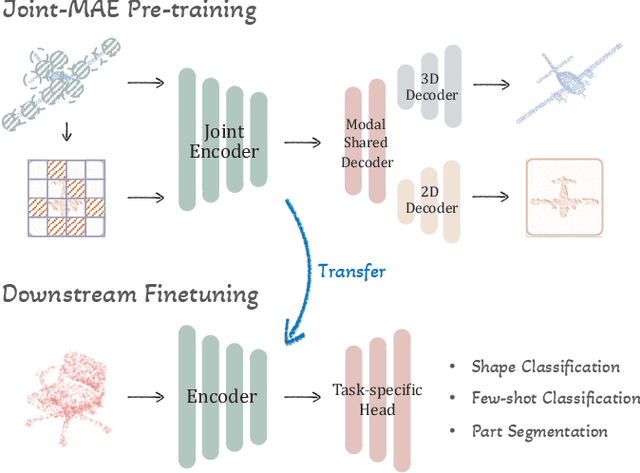
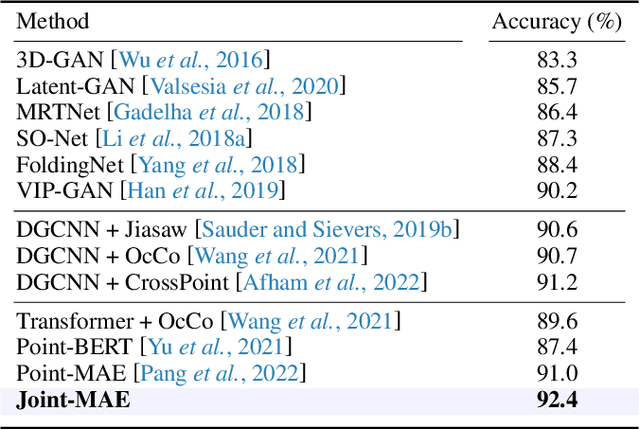
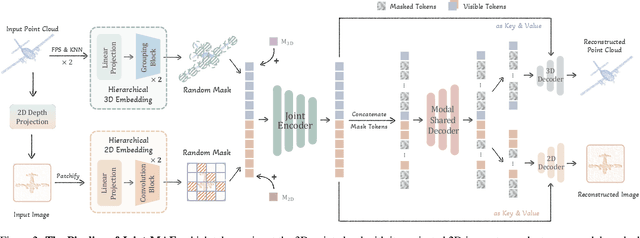
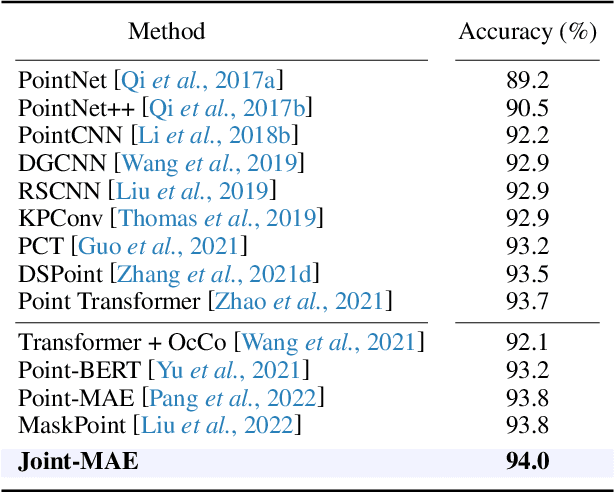
Masked Autoencoders (MAE) have shown promising performance in self-supervised learning for both 2D and 3D computer vision. However, existing MAE-style methods can only learn from the data of a single modality, i.e., either images or point clouds, which neglect the implicit semantic and geometric correlation between 2D and 3D. In this paper, we explore how the 2D modality can benefit 3D masked autoencoding, and propose Joint-MAE, a 2D-3D joint MAE framework for self-supervised 3D point cloud pre-training. Joint-MAE randomly masks an input 3D point cloud and its projected 2D images, and then reconstructs the masked information of the two modalities. For better cross-modal interaction, we construct our JointMAE by two hierarchical 2D-3D embedding modules, a joint encoder, and a joint decoder with modal-shared and model-specific decoders. On top of this, we further introduce two cross-modal strategies to boost the 3D representation learning, which are local-aligned attention mechanisms for 2D-3D semantic cues, and a cross-reconstruction loss for 2D-3D geometric constraints. By our pre-training paradigm, Joint-MAE achieves superior performance on multiple downstream tasks, e.g., 92.4% accuracy for linear SVM on ModelNet40 and 86.07% accuracy on the hardest split of ScanObjectNN.
VE-KWS: Visual Modality Enhanced End-to-End Keyword Spotting
Feb 27, 2023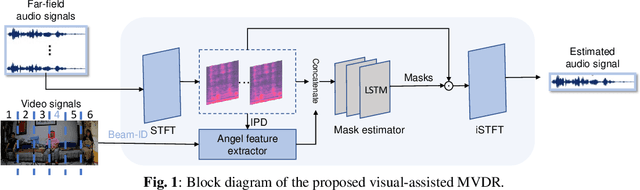
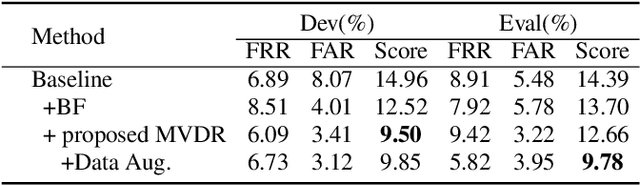
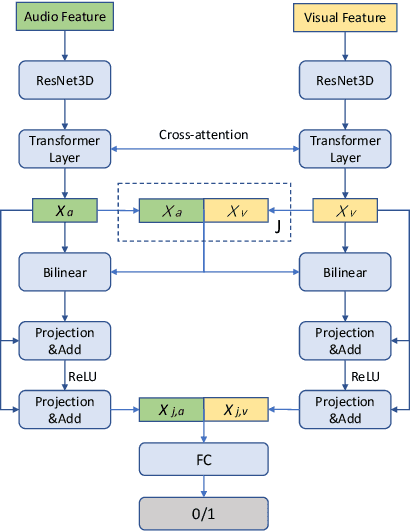

The performance of the keyword spotting (KWS) system based on audio modality, commonly measured in false alarms and false rejects, degrades significantly under the far field and noisy conditions. Therefore, audio-visual keyword spotting, which leverages complementary relationships over multiple modalities, has recently gained much attention. However, current studies mainly focus on combining the exclusively learned representations of different modalities, instead of exploring the modal relationships during each respective modeling. In this paper, we propose a novel visual modality enhanced end-to-end KWS framework (VE-KWS), which fuses audio and visual modalities from two aspects. The first one is utilizing the speaker location information obtained from the lip region in videos to assist the training of multi-channel audio beamformer. By involving the beamformer as an audio enhancement module, the acoustic distortions, caused by the far field or noisy environments, could be significantly suppressed. The other one is conducting cross-attention between different modalities to capture the inter-modal relationships and help the representation learning of each modality. Experiments on the MSIP challenge corpus show that our proposed model achieves 2.79% false rejection rate and 2.95% false alarm rate on the Eval set, resulting in a new SOTA performance compared with the top-ranking systems in the ICASSP2022 MISP challenge.
Image-based Pose Estimation and Shape Reconstruction for Robot Manipulators and Soft, Continuum Robots via Differentiable Rendering
Feb 27, 2023
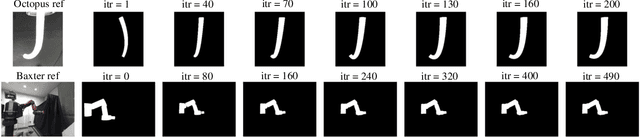
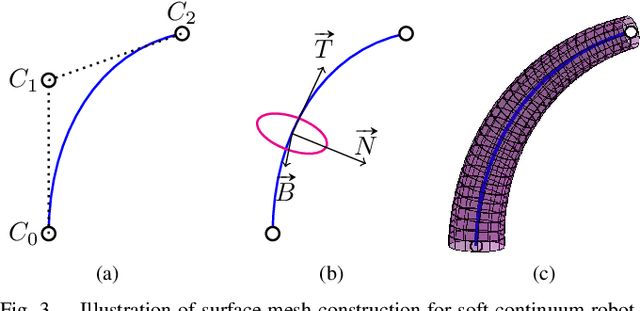
State estimation from measured data is crucial for robotic applications as autonomous systems rely on sensors to capture the motion and localize in the 3D world. Among sensors that are designed for measuring a robot's pose, or for soft robots, their shape, vision sensors are favorable because they are information-rich, easy to set up, and cost-effective. With recent advancements in computer vision, deep learning-based methods no longer require markers for identifying feature points on the robot. However, learning-based methods are data-hungry and hence not suitable for soft and prototyping robots, as building such bench-marking datasets is usually infeasible. In this work, we achieve image-based robot pose estimation and shape reconstruction from camera images. Our method requires no precise robot meshes, but rather utilizes a differentiable renderer and primitive shapes. It hence can be applied to robots for which CAD models might not be available or are crude. Our parameter estimation pipeline is fully differentiable. The robot shape and pose are estimated iteratively by back-propagating the image loss to update the parameters. We demonstrate that our method of using geometrical shape primitives can achieve high accuracy in shape reconstruction for a soft continuum robot and pose estimation for a robot manipulator.
Diacritic Recognition Performance in Arabic ASR
Feb 27, 2023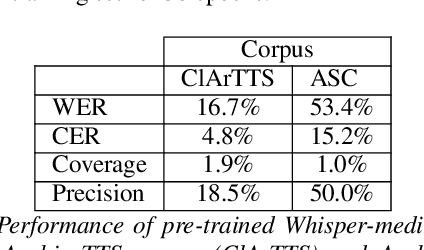
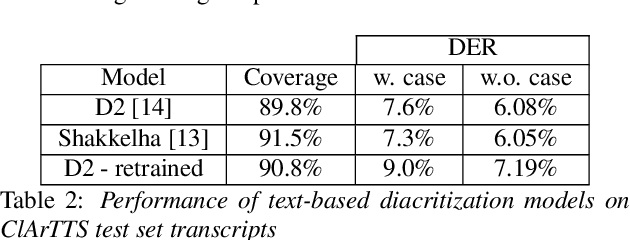
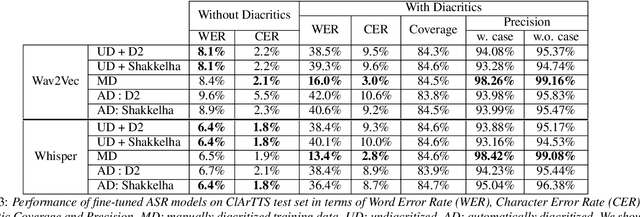
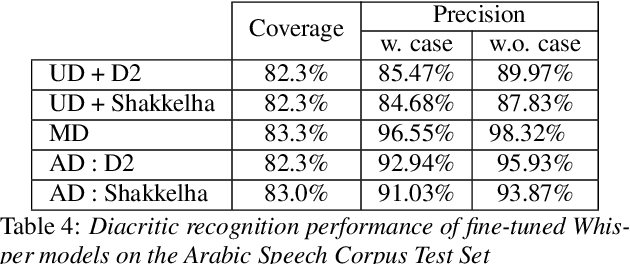
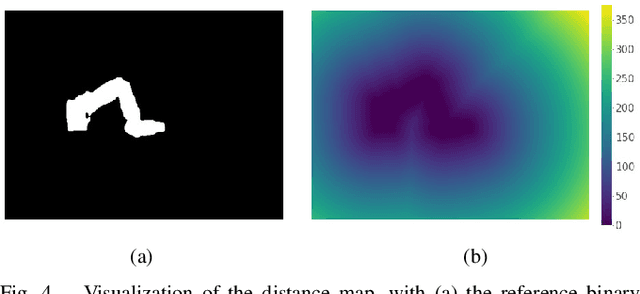
We present an analysis of diacritic recognition performance in Arabic Automatic Speech Recognition (ASR) systems. As most existing Arabic speech corpora do not contain all diacritical marks, which represent short vowels and other phonetic information in Arabic script, current state-of-the-art ASR models do not produce full diacritization in their output. Automatic text-based diacritization has previously been employed both as a pre-processing step to train diacritized ASR, or as a post-processing step to diacritize the resulting ASR hypotheses. It is generally believed that input diacritization degrades ASR performance, but no systematic evaluation of ASR diacritization performance, independent of ASR performance, has been conducted to date. In this paper, we attempt to experimentally clarify whether input diacritiztation indeed degrades ASR quality, and to compare the diacritic recognition performance against text-based diacritization as a post-processing step. We start with pre-trained Arabic ASR models and fine-tune them on transcribed speech data with different diacritization conditions: manual, automatic, and no diacritization. We isolate diacritic recognition performance from the overall ASR performance using coverage and precision metrics. We find that ASR diacritization significantly outperforms text-based diacritization in post-processing, particularly when the ASR model is fine-tuned with manually diacritized transcripts.
Natural Gradient Hybrid Variational Inference with Application to Deep Mixed Models
Feb 27, 2023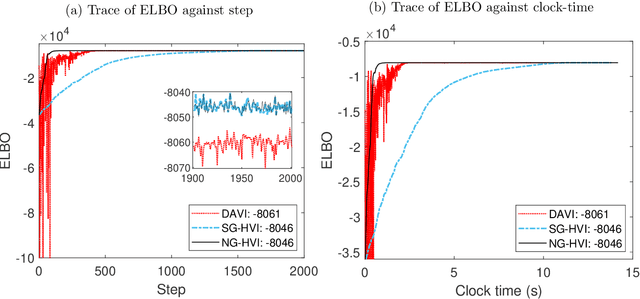
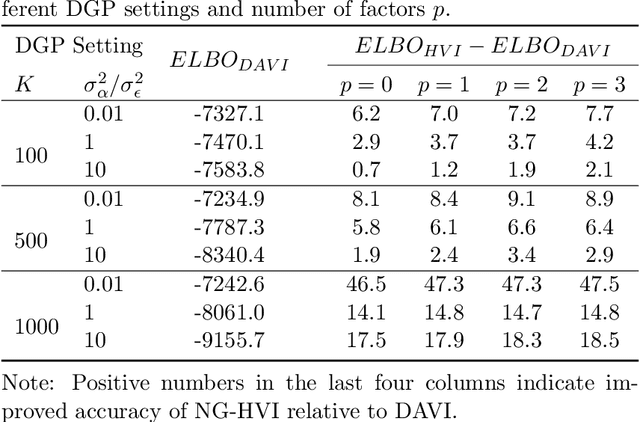
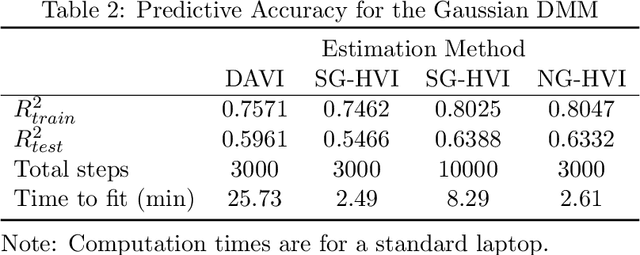
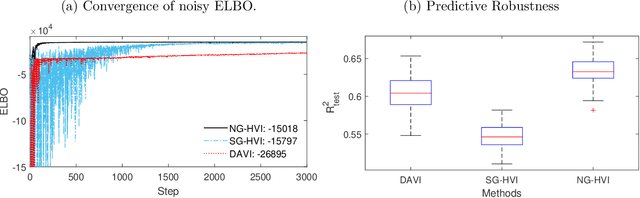
Stochastic models with global parameters $\bm{\theta}$ and latent variables $\bm{z}$ are common, and variational inference (VI) is popular for their estimation. This paper uses a variational approximation (VA) that comprises a Gaussian with factor covariance matrix for the marginal of $\bm{\theta}$, and the exact conditional posterior of $\bm{z}|\bm{\theta}$. Stochastic optimization for learning the VA only requires generation of $\bm{z}$ from its conditional posterior, while $\bm{\theta}$ is updated using the natural gradient, producing a hybrid VI method. We show that this is a well-defined natural gradient optimization algorithm for the joint posterior of $(\bm{z},\bm{\theta})$. Fast to compute expressions for the Tikhonov damped Fisher information matrix required to compute a stable natural gradient update are derived. We use the approach to estimate probabilistic Bayesian neural networks with random output layer coefficients to allow for heterogeneity. Simulations show that using the natural gradient is more efficient than using the ordinary gradient, and that the approach is faster and more accurate than two leading benchmark natural gradient VI methods. In a financial application we show that accounting for industry level heterogeneity using the deep model improves the accuracy of probabilistic prediction of asset pricing models.
Joint Task and Data Oriented Semantic Communications: A Deep Separate Source-channel Coding Scheme
Feb 27, 2023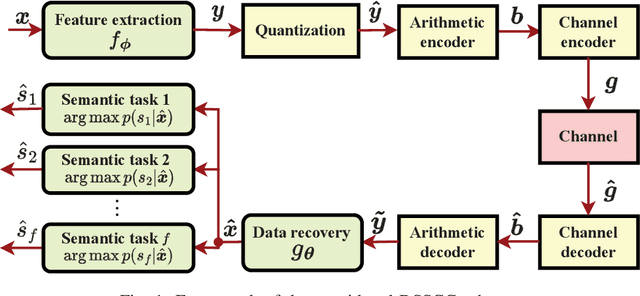
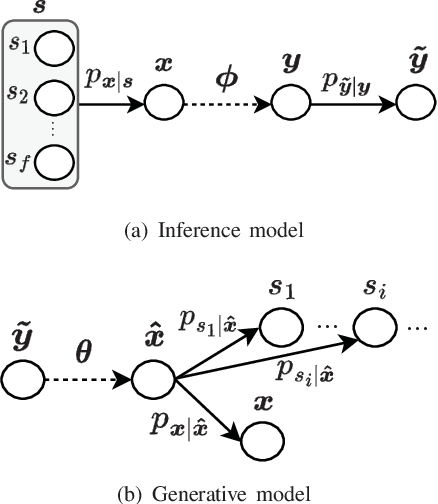
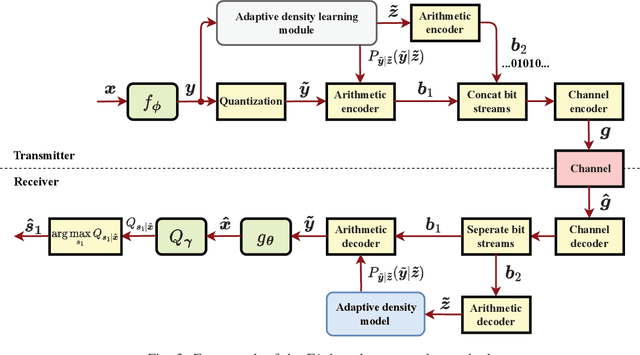
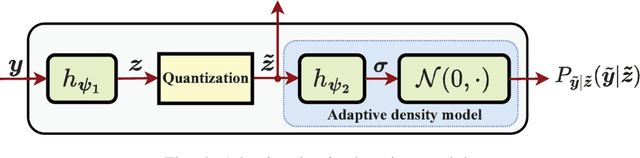
Semantic communications are expected to accomplish various semantic tasks with relatively less spectrum resource by exploiting the semantic feature of source data. To simultaneously serve both the data transmission and semantic tasks, joint data compression and semantic analysis has become pivotal issue in semantic communications. This paper proposes a deep separate source-channel coding (DSSCC) framework for the joint task and data oriented semantic communications (JTD-SC) and utilizes the variational autoencoder approach to solve the rate-distortion problem with semantic distortion. First, by analyzing the Bayesian model of the DSSCC framework, we derive a novel rate-distortion optimization problem via the Bayesian inference approach for general data distributions and semantic tasks. Next, for a typical application of joint image transmission and classification, we combine the variational autoencoder approach with a forward adaption scheme to effectively extract image features and adaptively learn the density information of the obtained features. Finally, an iterative training algorithm is proposed to tackle the overfitting issue of deep learning models. Simulation results reveal that the proposed scheme achieves better coding gain as well as data recovery and classification performance in most scenarios, compared to the classical compression schemes and the emerging deep joint source-channel schemes.