 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Automated Statement Extraction from Press Briefings
Feb 24, 2023
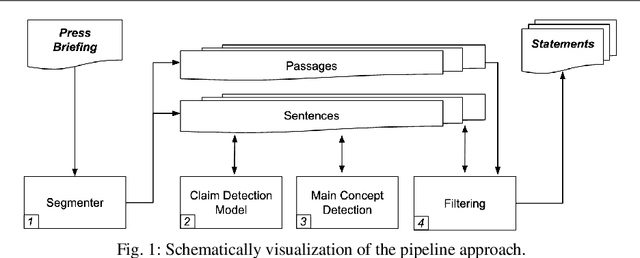
Scientific press briefings are a valuable information source. They consist of alternating expert speeches, questions from the audience and their answers. Therefore, they can contribute to scientific and fact-based media coverage. Even though press briefings are highly informative, extracting statements relevant to individual journalistic tasks is challenging and time-consuming. To support this task, an automated statement extraction system is proposed. Claims are used as the main feature to identify statements in press briefing transcripts. The statement extraction task is formulated as a four-step procedure. First, the press briefings are split into sentences and passages, then claim sentences are identified through sequence classification. Subsequently, topics are detected, and the sentences are filtered to improve the coherence and assess the length of the statements. The results indicate that claim detection can be used to identify statements in press briefings. While many statements can be extracted automatically with this system, they are not always as coherent as needed to be understood without context and may need further review by knowledgeable persons.
LMPDNet: TOF-PET list-mode image reconstruction using model-based deep learning method
Feb 21, 2023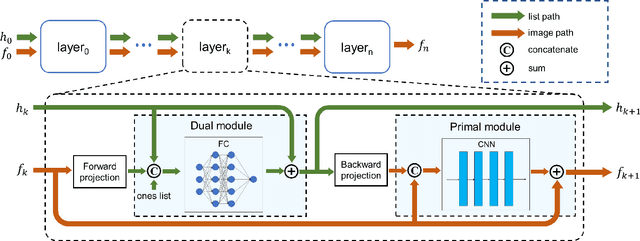
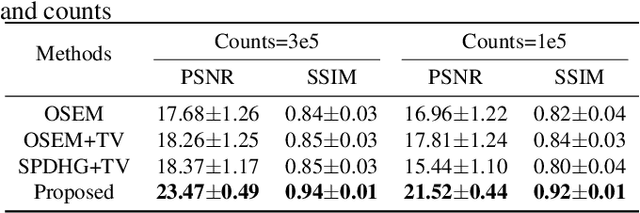
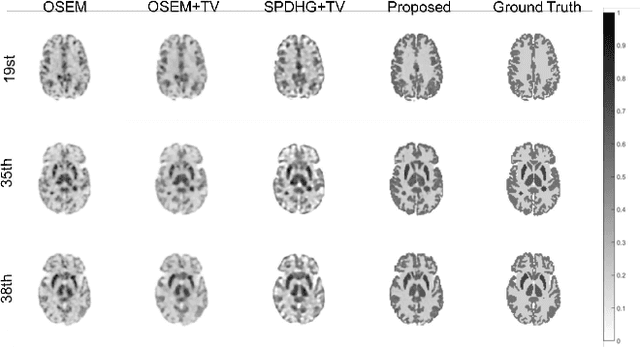
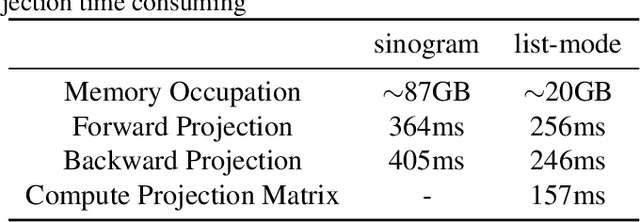
The integration of Time-of-Flight (TOF) information in the reconstruction process of Positron Emission Tomography (PET) yields improved image properties. However, implementing the cutting-edge model-based deep learning methods for TOF-PET reconstruction is challenging due to the substantial memory requirements. In this study, we present a novel model-based deep learning approach, LMPDNet, for TOF-PET reconstruction from list-mode data. We address the issue of real-time parallel computation of the projection matrix for list-mode data, and propose an iterative model-based module that utilizes a dedicated network model for list-mode data. Our experimental results indicate that the proposed LMPDNet outperforms traditional iteration-based TOF-PET list-mode reconstruction algorithms. Additionally, we compare the spatial and temporal consumption of list-mode data and sinogram data in model-based deep learning methods, demonstrating the superiority of list-mode data in model-based TOF-PET reconstruction.
Energy-Based Test Sample Adaptation for Domain Generalization
Feb 22, 2023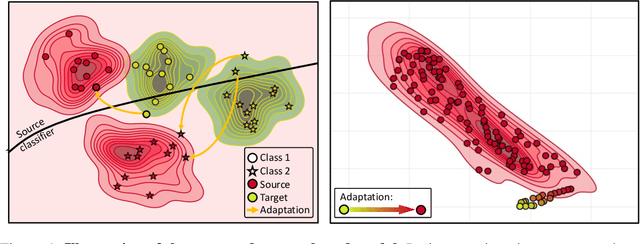

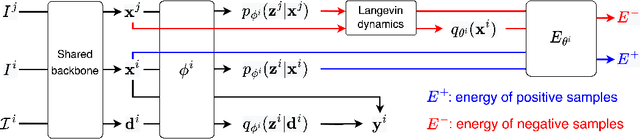
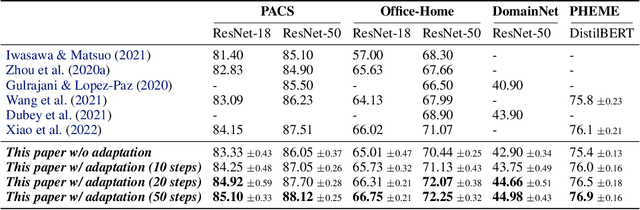
In this paper, we propose energy-based sample adaptation at test time for domain generalization. Where previous works adapt their models to target domains, we adapt the unseen target samples to source-trained models. To this end, we design a discriminative energy-based model, which is trained on source domains to jointly model the conditional distribution for classification and data distribution for sample adaptation. The model is optimized to simultaneously learn a classifier and an energy function. To adapt target samples to source distributions, we iteratively update the samples by energy minimization with stochastic gradient Langevin dynamics. Moreover, to preserve the categorical information in the sample during adaptation, we introduce a categorical latent variable into the energy-based model. The latent variable is learned from the original sample before adaptation by variational inference and fixed as a condition to guide the sample update. Experiments on six benchmarks for classification of images and microblog threads demonstrate the effectiveness of our proposal.
Faster Riemannian Newton-type Optimization by Subsampling and Cubic Regularization
Feb 22, 2023
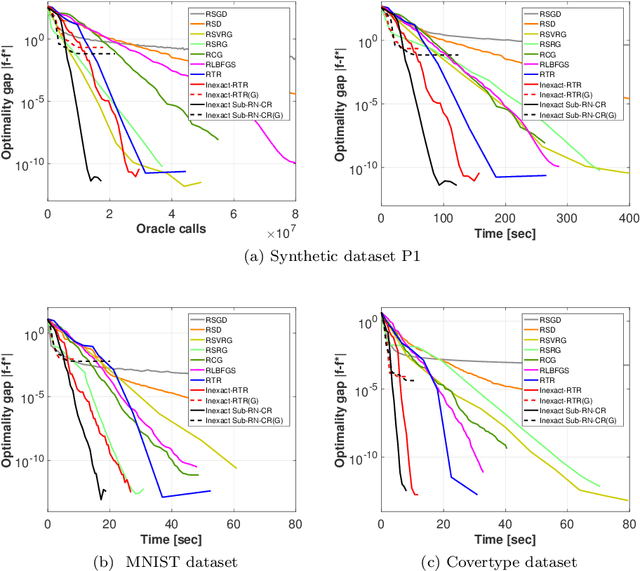
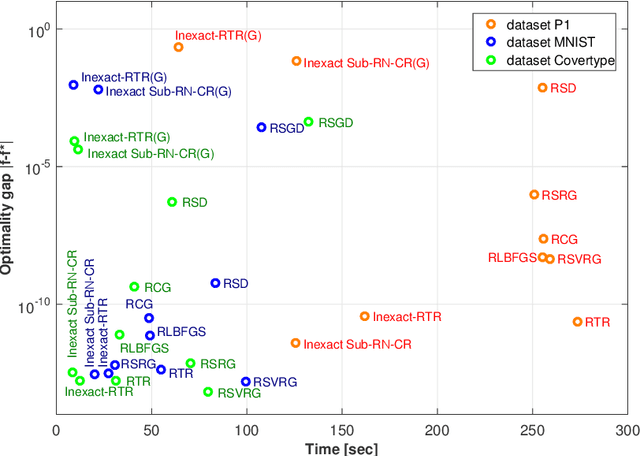
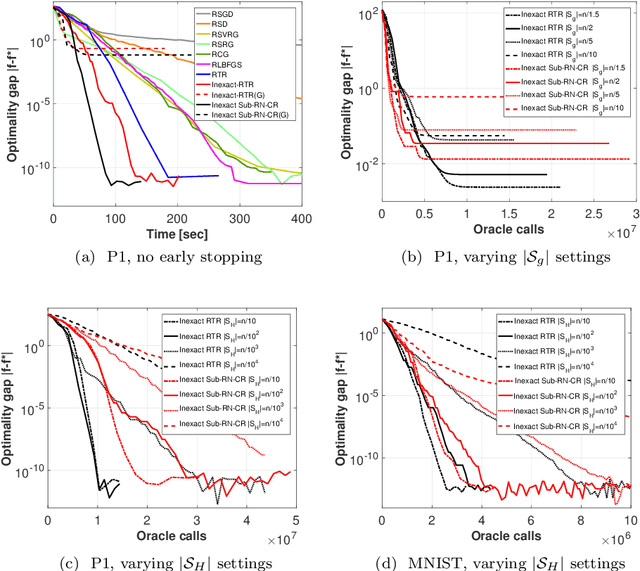
This work is on constrained large-scale non-convex optimization where the constraint set implies a manifold structure. Solving such problems is important in a multitude of fundamental machine learning tasks. Recent advances on Riemannian optimization have enabled the convenient recovery of solutions by adapting unconstrained optimization algorithms over manifolds. However, it remains challenging to scale up and meanwhile maintain stable convergence rates and handle saddle points. We propose a new second-order Riemannian optimization algorithm, aiming at improving convergence rate and reducing computational cost. It enhances the Riemannian trust-region algorithm that explores curvature information to escape saddle points through a mixture of subsampling and cubic regularization techniques. We conduct rigorous analysis to study the convergence behavior of the proposed algorithm. We also perform extensive experiments to evaluate it based on two general machine learning tasks using multiple datasets. The proposed algorithm exhibits improved computational speed and convergence behavior compared to a large set of state-of-the-art Riemannian optimization algorithms.
A Multi-Modal Neural Geometric Solver with Textual Clauses Parsed from Diagram
Feb 22, 2023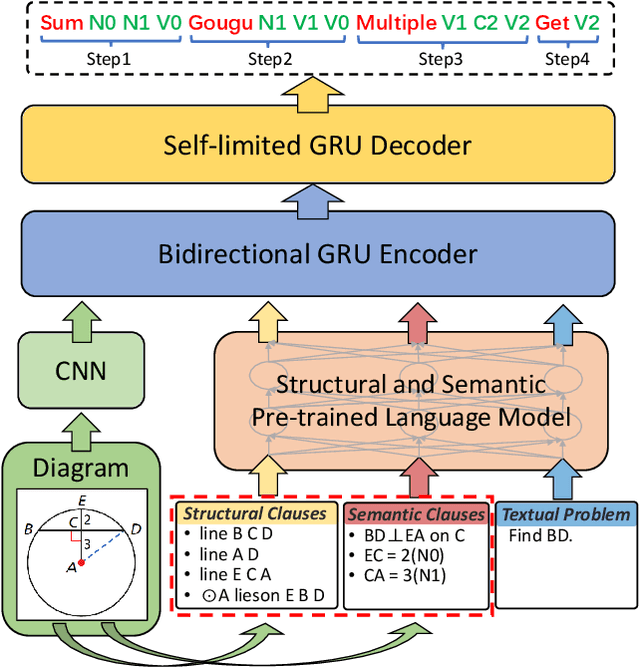


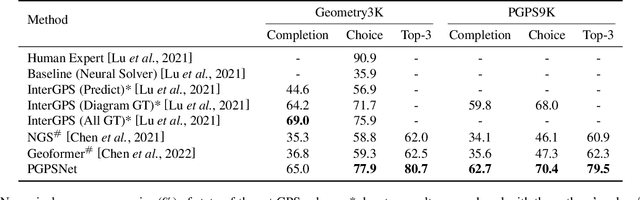
Geometry problem solving (GPS) is a high-level mathematical reasoning requiring the capacities of multi-modal fusion and geometric knowledge application. Recently, neural solvers have shown great potential in GPS but still be short in diagram presentation and modal fusion. In this work, we convert diagrams into basic textual clauses to describe diagram features effectively, and propose a new neural solver called PGPSNet to fuse multi-modal information efficiently. Combining structural and semantic pre-training, data augmentation and self-limited decoding, PGPSNet is endowed with rich knowledge of geometry theorems and geometric representation, and therefore promotes geometric understanding and reasoning. In addition, to facilitate the research of GPS, we build a new large-scale and fine-annotated GPS dataset named PGPS9K, labeled with both fine-grained diagram annotation and interpretable solution program. Experiments on PGPS9K and an existing dataset Geometry3K validate the superiority of our method over the state-of-the-art neural solvers. The code and dataset will be public available soon.
HSIC-InfoGAN: Learning Unsupervised Disentangled Representations by Maximising Approximated Mutual Information
Aug 06, 2022
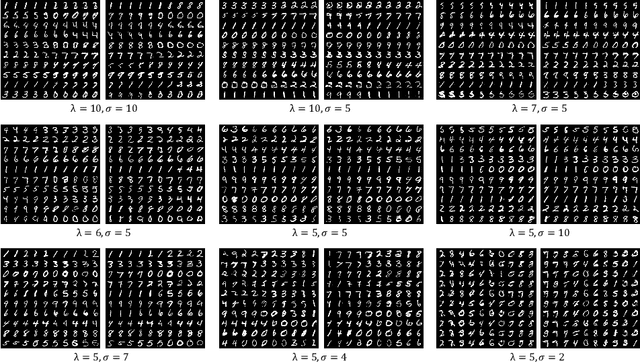
Learning disentangled representations requires either supervision or the introduction of specific model designs and learning constraints as biases. InfoGAN is a popular disentanglement framework that learns unsupervised disentangled representations by maximising the mutual information between latent representations and their corresponding generated images. Maximisation of mutual information is achieved by introducing an auxiliary network and training with a latent regression loss. In this short exploratory paper, we study the use of the Hilbert-Schmidt Independence Criterion (HSIC) to approximate mutual information between latent representation and image, termed HSIC-InfoGAN. Directly optimising the HSIC loss avoids the need for an additional auxiliary network. We qualitatively compare the level of disentanglement in each model, suggest a strategy to tune the hyperparameters of HSIC-InfoGAN, and discuss the potential of HSIC-InfoGAN for medical applications.
Understanding metric-related pitfalls in image analysis validation
Feb 09, 2023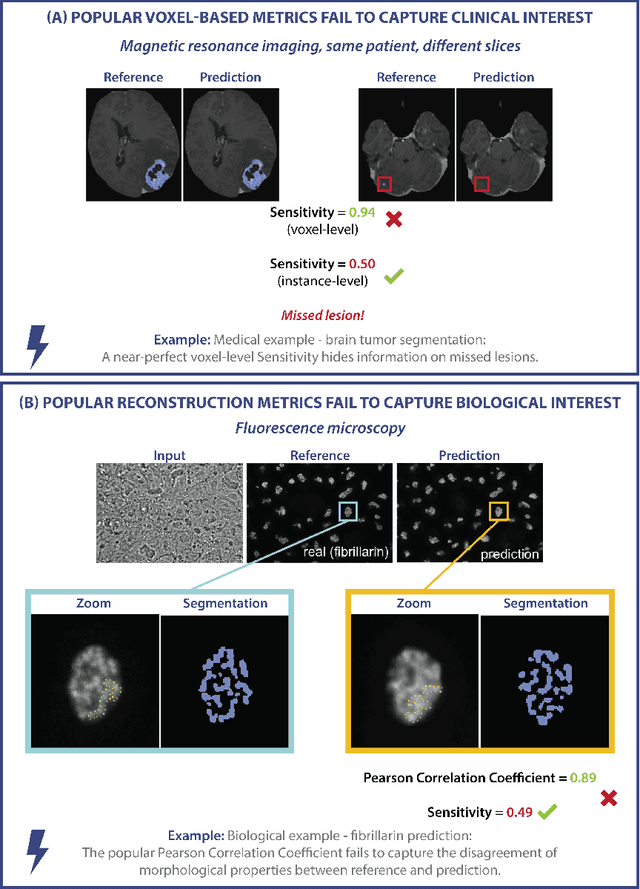
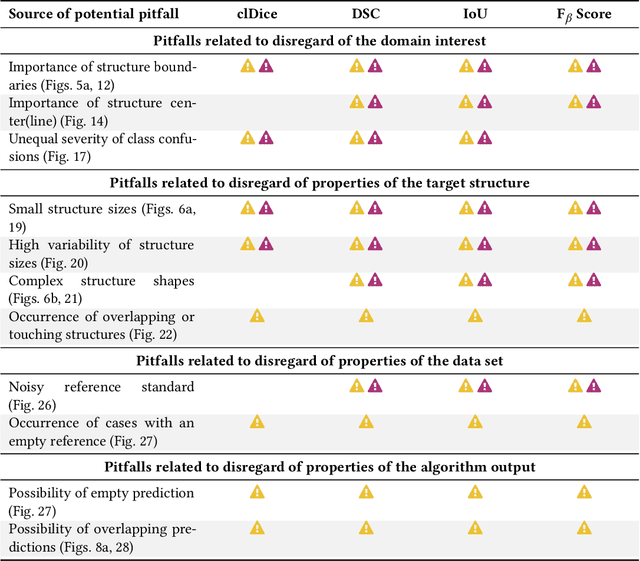

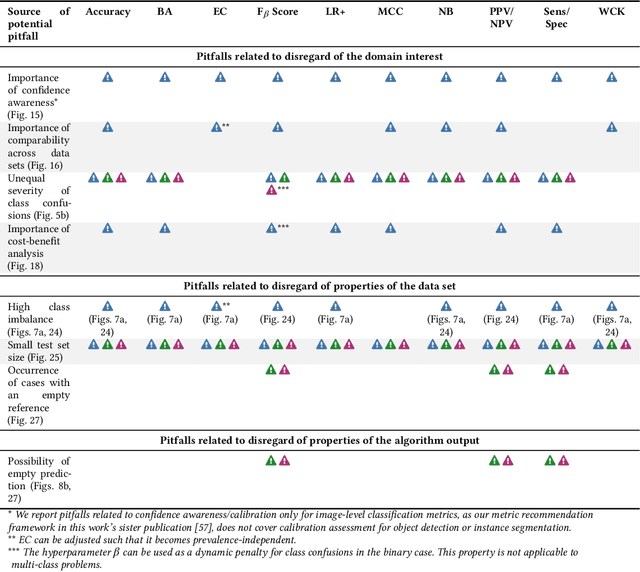
Validation metrics are key for the reliable tracking of scientific progress and for bridging the current chasm between artificial intelligence (AI) research and its translation into practice. However, increasing evidence shows that particularly in image analysis, metrics are often chosen inadequately in relation to the underlying research problem. This could be attributed to a lack of accessibility of metric-related knowledge: While taking into account the individual strengths, weaknesses, and limitations of validation metrics is a critical prerequisite to making educated choices, the relevant knowledge is currently scattered and poorly accessible to individual researchers. Based on a multi-stage Delphi process conducted by a multidisciplinary expert consortium as well as extensive community feedback, the present work provides the first reliable and comprehensive common point of access to information on pitfalls related to validation metrics in image analysis. Focusing on biomedical image analysis but with the potential of transfer to other fields, the addressed pitfalls generalize across application domains and are categorized according to a newly created, domain-agnostic taxonomy. To facilitate comprehension, illustrations and specific examples accompany each pitfall. As a structured body of information accessible to researchers of all levels of expertise, this work enhances global comprehension of a key topic in image analysis validation.
Self-Supervised Node Representation Learning via Node-to-Neighbourhood Alignment
Feb 09, 2023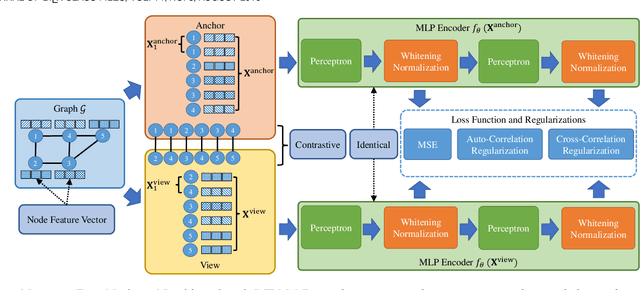
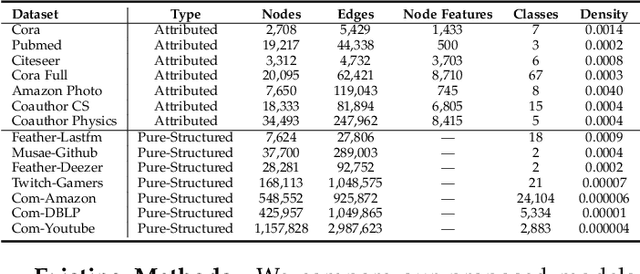
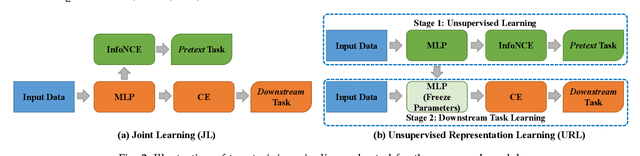
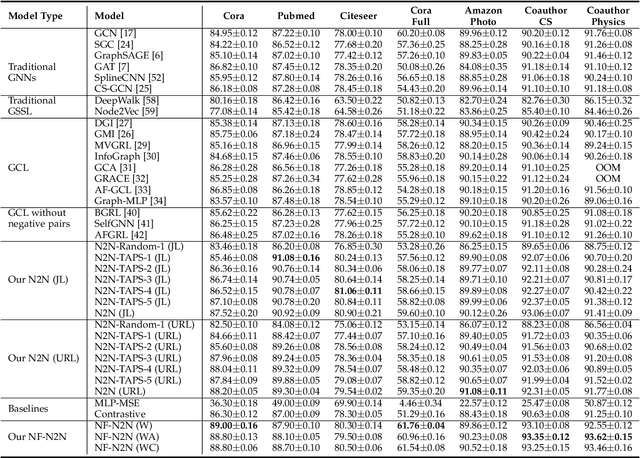
Self-supervised node representation learning aims to learn node representations from unlabelled graphs that rival the supervised counterparts. The key towards learning informative node representations lies in how to effectively gain contextual information from the graph structure. In this work, we present simple-yet-effective self-supervised node representation learning via aligning the hidden representations of nodes and their neighbourhood. Our first idea achieves such node-to-neighbourhood alignment by directly maximizing the mutual information between their representations, which, we prove theoretically, plays the role of graph smoothing. Our framework is optimized via a surrogate contrastive loss and a Topology-Aware Positive Sampling (TAPS) strategy is proposed to sample positives by considering the structural dependencies between nodes, which enables offline positive selection. Considering the excessive memory overheads of contrastive learning, we further propose a negative-free solution, where the main contribution is a Graph Signal Decorrelation (GSD) constraint to avoid representation collapse and over-smoothing. The GSD constraint unifies some of the existing constraints and can be used to derive new implementations to combat representation collapse. By applying our methods on top of simple MLP-based node representation encoders, we learn node representations that achieve promising node classification performance on a set of graph-structured datasets from small- to large-scale.
Physical Layer Security in Near-Field Communications: What Will Be Changed?
Feb 15, 2023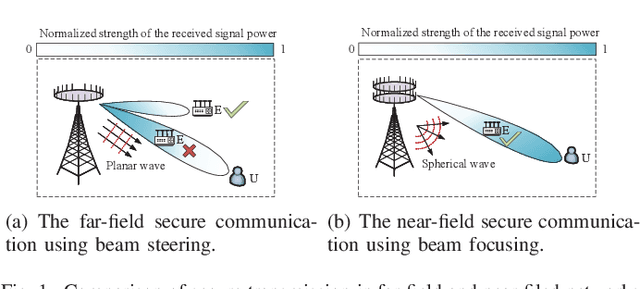
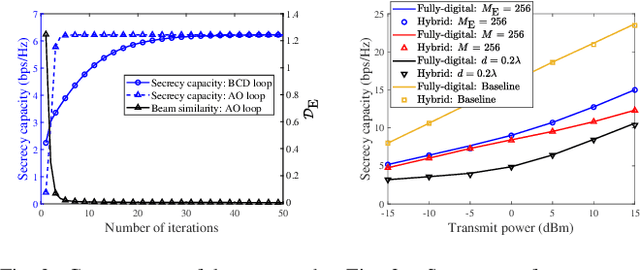
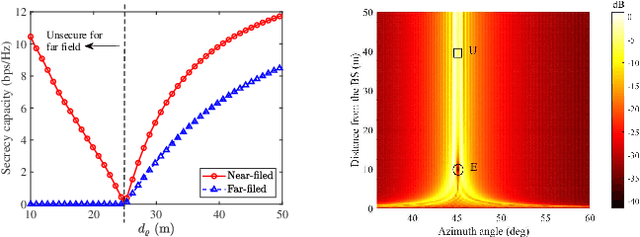
A near-field secure transmission framework is proposed. Employing the hybrid beamforming architecture, a base station (BS) transmits the confidential information to a legitimate user (U) against an eavesdropper (E) in the near field. A two-stage algorithm is proposed to maximize the near-field secrecy capacity. Based on the fully-digital beamformers obtained in the first stage, the optimal analog beamformers and baseband digital beamformers can be alternatingly derived in the closed-form expressions in the second stage. Numerical results demonstrate that in contrast to the far-field secure communication relying on the angular disparity, the near-filed secure communication mainly relies on the distance disparity between U and E.
SCRIMP: Scalable Communication for Reinforcement- and Imitation-Learning-Based Multi-Agent Pathfinding
Mar 02, 2023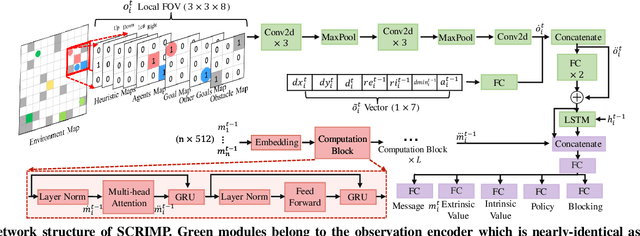
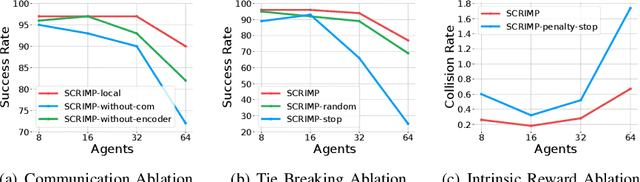
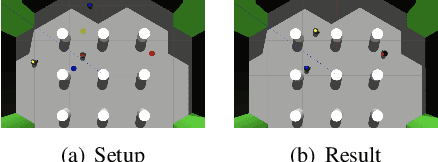
Trading off performance guarantees in favor of scalability, the Multi-Agent Path Finding (MAPF) community has recently started to embrace Multi-Agent Reinforcement Learning (MARL), where agents learn to collaboratively generate individual, collision-free (but often suboptimal) paths. Scalability is usually achieved by assuming a local field of view (FOV) around the agents, helping scale to arbitrary world sizes. However, this assumption significantly limits the amount of information available to the agents, making it difficult for them to enact the type of joint maneuvers needed in denser MAPF tasks. In this paper, we propose SCRIMP, where agents learn individual policies from even very small (down to 3x3) FOVs, by relying on a highly-scalable global/local communication mechanism based on a modified transformer. We further equip agents with a state-value-based tie-breaking strategy to further improve performance in symmetric situations, and introduce intrinsic rewards to encourage exploration while mitigating the long-term credit assignment problem. Empirical evaluations on a set of experiments indicate that SCRIMP can achieve higher performance with improved scalability compared to other state-of-the-art learning-based MAPF planners with larger FOVs, and even yields similar performance as a classical centralized planner in many cases. Ablation studies further validate the effectiveness of our proposed techniques. Finally, we show that our trained model can be directly implemented on real robots for online MAPF through high-fidelity simulations in gazebo.