 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Computing Functions Over-the-Air Using Digital Modulations
Mar 01, 2023
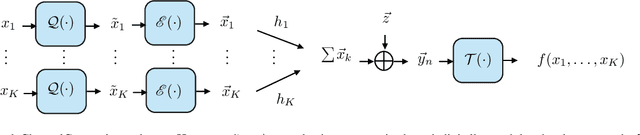
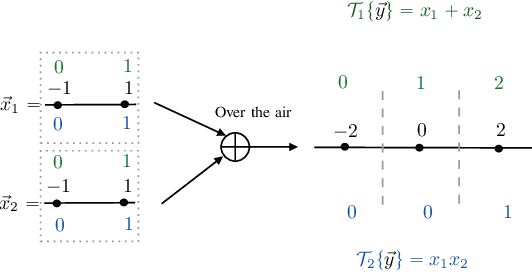
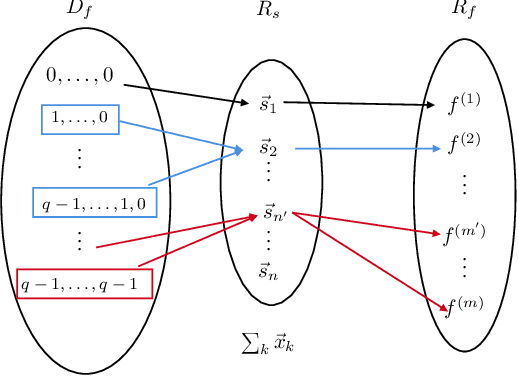
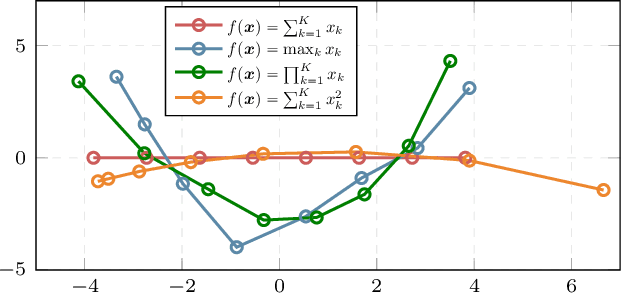
Over-the-air computation (AirComp) is a known technique in which wireless devices transmit values by analog amplitude modulation so that a function of these values is computed over the communication channel at a common receiver. The physical reason is the superposition properties of the electromagnetic waves, which naturally return sums of analog values. Consequently, the applications of AirComp are almost entirely restricted to analog communication systems. However, the use of digital communications for over-the-air computations would have several benefits, such as error correction, synchronization, acquisition of channel state information, and easier adoption by current digital communication systems. Nevertheless, a common belief is that digital modulations are generally unfeasible for computation tasks because the overlapping of digitally modulated signals returns signals that seem to be meaningless for these tasks. This paper breaks through such a belief and proposes a fundamentally new computing method, named ChannelComp, for performing over-the-air computations by any digital modulation. In particular, we propose digital modulation formats that allow us to compute a wider class of functions than AirComp can compute, and we propose a feasibility optimization problem that ascertains the optimal digital modulation for computing functions over-the-air. The simulation results verify the superior performance of ChannelComp in comparison to AirComp, particularly for the product functions, with around 10 dB improvement of the computation error.
Unlimited-Size Diffusion Restoration
Mar 01, 2023



Recently, using diffusion models for zero-shot image restoration (IR) has become a new hot paradigm. This type of method only needs to use the pre-trained off-the-shelf diffusion models, without any finetuning, and can directly handle various IR tasks. The upper limit of the restoration performance depends on the pre-trained diffusion models, which are in rapid evolution. However, current methods only discuss how to deal with fixed-size images, but dealing with images of arbitrary sizes is very important for practical applications. This paper focuses on how to use those diffusion-based zero-shot IR methods to deal with any size while maintaining the excellent characteristics of zero-shot. A simple way to solve arbitrary size is to divide it into fixed-size patches and solve each patch independently. But this may yield significant artifacts since it neither considers the global semantics of all patches nor the local information of adjacent patches. Inspired by the Range-Null space Decomposition, we propose the Mask-Shift Restoration to address local incoherence and propose the Hierarchical Restoration to alleviate out-of-domain issues. Our simple, parameter-free approaches can be used not only for image restoration but also for image generation of unlimited sizes, with the potential to be a general tool for diffusion models. Code: https://github.com/wyhuai/DDNM/tree/main/hq_demo
Bayesian outcome-guided multi-view mixture models with applications in molecular precision medicine
Mar 01, 2023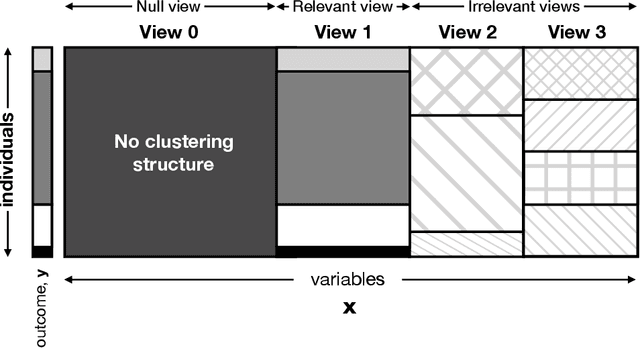
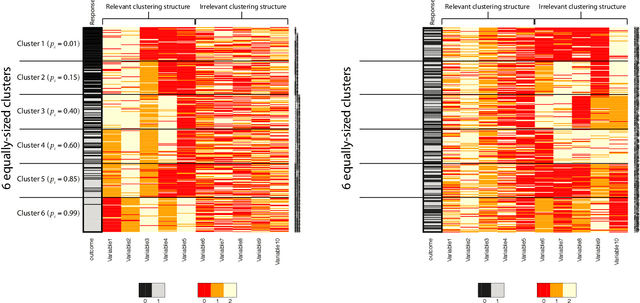
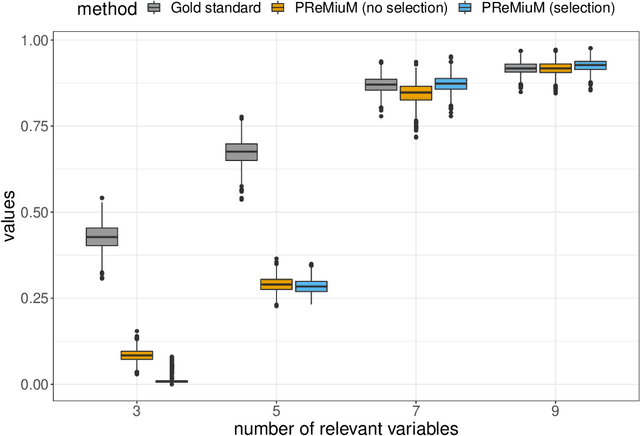

Clustering is commonly performed as an initial analysis step for uncovering structure in 'omics datasets, e.g. to discover molecular subtypes of disease. The high-throughput, high-dimensional nature of these datasets means that they provide information on a diverse array of different biomolecular processes and pathways. Different groups of variables (e.g. genes or proteins) will be implicated in different biomolecular processes, and hence undertaking analyses that are limited to identifying just a single clustering partition of the whole dataset is therefore liable to conflate the multiple clustering structures that may arise from these distinct processes. To address this, we propose a multi-view Bayesian mixture model that identifies groups of variables (``views"), each of which defines a distinct clustering structure. We consider applications in stratified medicine, for which our principal goal is to identify clusters of patients that define distinct, clinically actionable disease subtypes. We adopt the semi-supervised, outcome-guided mixture modelling approach of Bayesian profile regression that makes use of a response variable in order to guide inference toward the clusterings that are most relevant in a stratified medicine context. We present the model, together with illustrative simulation examples, and examples from pan-cancer proteomics. We demonstrate how the approach can be used to perform integrative clustering, and consider an example in which different 'omics datasets are integrated in the context of breast cancer subtyping.
Temporal Scalability of Dynamic Volume Data Using Mesh Compensated Wavelet Lifting
Mar 01, 2023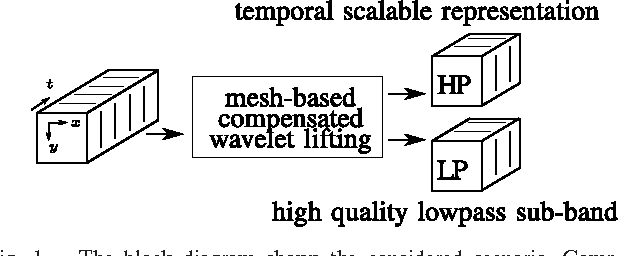
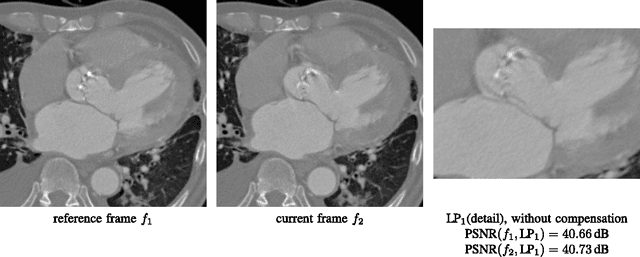
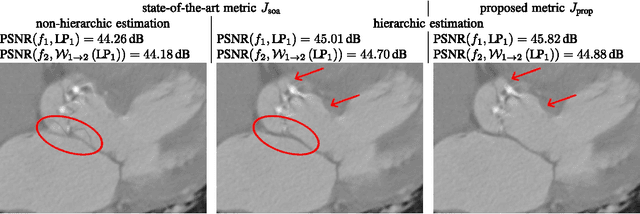

Due to their high resolution, dynamic medical 2D+t and 3D+t volumes from computed tomography (CT) and magnetic resonance tomography (MR) reach a size which makes them very unhandy for teleradiologic applications. A lossless scalable representation offers the advantage of a down-scaled version which can be used for orientation or previewing, while the remaining information for reconstructing the full resolution is transmitted on demand. The wavelet transform offers the desired scalability. A very high quality of the lowpass sub-band is crucial in order to use it as a down-scaled representation. We propose an approach based on compensated wavelet lifting for obtaining a scalable representation of dynamic CT and MR volumes with very high quality. The mesh compensation is feasible to model the displacement in dynamic volumes which is mainly given by expansion and contraction of tissue over time. To achieve this, we propose an optimized estimation of the mesh compensation parameters to optimally fit for dynamic volumes. Within the lifting structure, the inversion of the motion compensation is crucial in the update step. We propose to take this inversion directly into account during the estimation step and can improve the quality of the lowpass sub-band by 0.63 and 0.43 dB on average for our tested dynamic CT and MR volumes at the cost of an increase of the rate by 2.4% and 1.2% on average.
Towards Personalized Review Summarization by Modeling Historical Reviews from Customer and Product Separately
Jan 27, 2023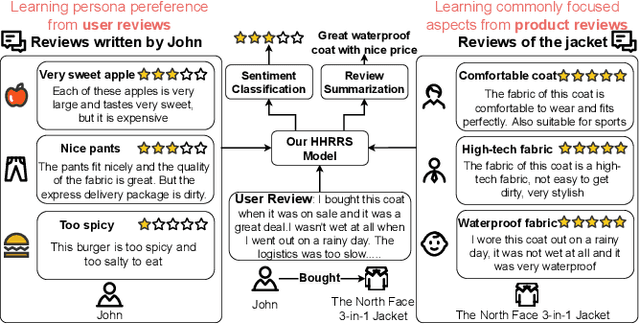
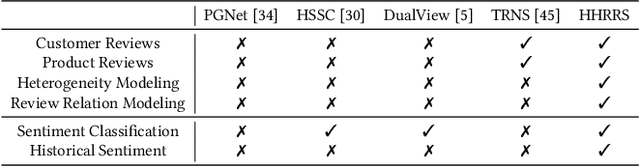
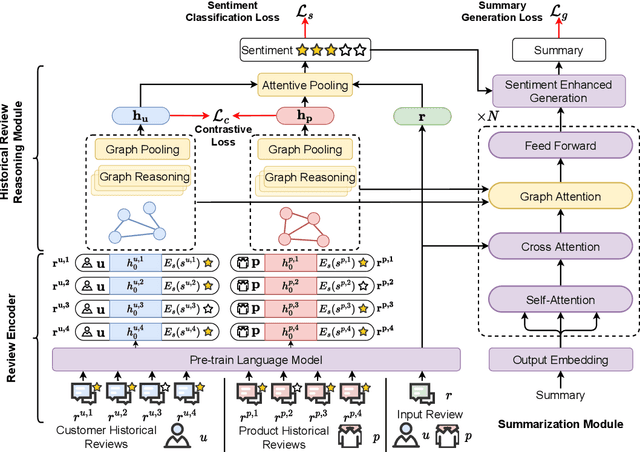
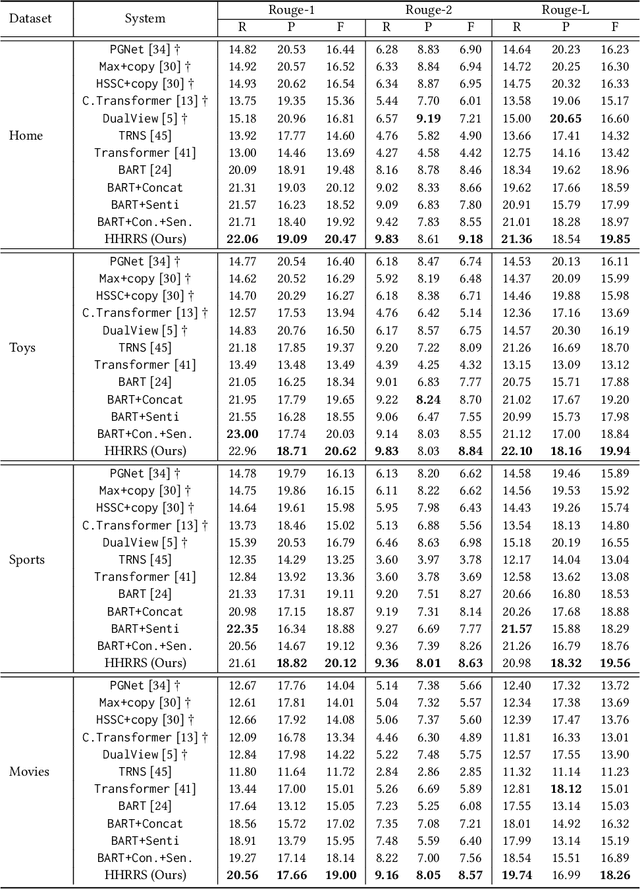
Review summarization is a non-trivial task that aims to summarize the main idea of the product review in the E-commerce website. Different from the document summary which only needs to focus on the main facts described in the document, review summarization should not only summarize the main aspects mentioned in the review but also reflect the personal style of the review author. Although existing review summarization methods have incorporated the historical reviews of both customer and product, they usually simply concatenate and indiscriminately model this two heterogeneous information into a long sequence. Moreover, the rating information can also provide a high-level abstraction of customer preference, it has not been used by the majority of methods. In this paper, we propose the Heterogeneous Historical Review aware Review Summarization Model (HHRRS) which separately models the two types of historical reviews with the rating information by a graph reasoning module with a contrastive loss. We employ a multi-task framework that conducts the review sentiment classification and summarization jointly. Extensive experiments on four benchmark datasets demonstrate the superiority of HHRRS on both tasks.
Exploiting Intelligent Reflecting Surfaces for Interference Channels with SWIPT
Mar 06, 2023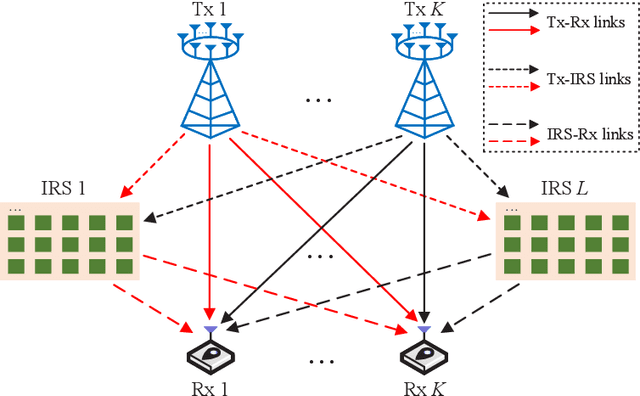
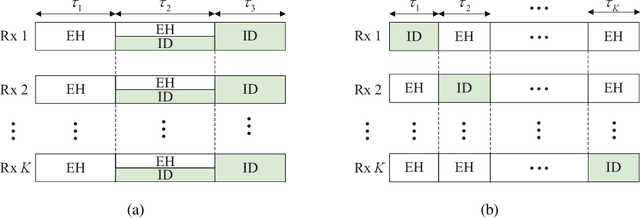
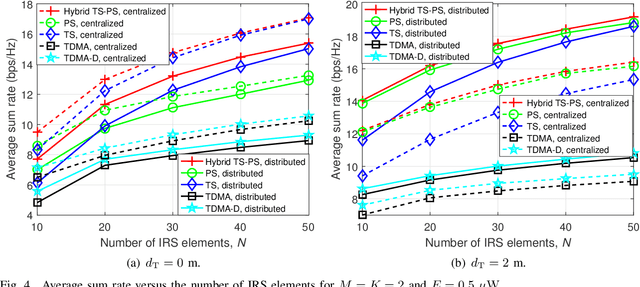
This paper considers intelligent reflecting surface (IRS)-aided simultaneous wireless information and power transfer (SWIPT) in a multi-user multiple-input single-output (MISO) interference channel (IFC), where multiple transmitters (Txs) serve their corresponding receivers (Rxs) in a shared spectrum with the aid of IRSs. Our goal is to maximize the sum rate of the Rxs by jointly optimizing the transmit covariance matrices at the Txs, the phase shifts at the IRSs, and the resource allocation subject to the individual energy harvesting (EH) constraints at the Rxs. Towards this goal and based on the well-known power splitting (PS) and time switching (TS) receiver structures, we consider three practical transmission schemes, namely the IRS-aided hybrid TS-PS scheme, the IRS-aided time-division multiple access (TDMA) scheme, and the IRS-aided TDMA-D scheme. The latter two schemes differ in whether the Txs employ deterministic energy signals known to all the Rxs. Despite the non-convexity of the three optimization problems corresponding to the three transmission schemes, we develop computationally efficient algorithms to address them suboptimally, respectively, by capitalizing on the techniques of alternating optimization (AO) and successive convex approximation (SCA). Moreover, we conceive feasibility checking methods for these problems, based on which the initial points for the proposed algorithms are constructed. Simulation results demonstrate that our proposed IRS-aided schemes significantly outperform their counterparts without IRSs in terms of sum rate and maximum EH requirements that can be satisfied under various setups. In addition, the IRS-aided hybrid TS-PS scheme generally achieves the best sum rate performance among the three proposed IRS-aided schemes, and if not, increasing the number of IRS elements can always accomplish it.
A Brief Report on LawGPT 1.0: A Virtual Legal Assistant Based on GPT-3
Feb 14, 2023LawGPT 1.0 is a virtual legal assistant built on the state-of-the-art language model GPT-3, fine-tuned for the legal domain. The system is designed to provide legal assistance to users in a conversational manner, helping them with tasks such as answering legal questions, generating legal documents, and providing legal advice. In this paper, we provide a brief overview of LawGPT 1.0, its architecture, and its performance on a set of legal benchmark tasks. Please note that the detailed information about the model is protected by a non-disclosure agreement (NDA) and cannot be disclosed in this report.
Synergy between human and machine approaches to sound/scene recognition and processing: An overview of ICASSP special session
Feb 24, 2023Machine Listening, as usually formalized, attempts to perform a task that is, from our perspective, fundamentally human-performable, and performed by humans. Current automated models of Machine Listening vary from purely data-driven approaches to approaches imitating human systems. In recent years, the most promising approaches have been hybrid in that they have used data-driven approaches informed by models of the perceptual, cognitive, and semantic processes of the human system. Not only does the guidance provided by models of human perception and domain knowledge enable better, and more generalizable Machine Listening, in the converse, the lessons learned from these models may be used to verify or improve our models of human perception themselves. This paper summarizes advances in the development of such hybrid approaches, ranging from Machine Listening models that are informed by models of peripheral (human) auditory processes, to those that employ or derive semantic information encoded in relations between sounds. The research described herein was presented in a special session on "Synergy between human and machine approaches to sound/scene recognition and processing" at the 2023 ICASSP meeting.
Few-Shot Table-to-Text Generation with Prompt Planning and Knowledge Memorization
Feb 24, 2023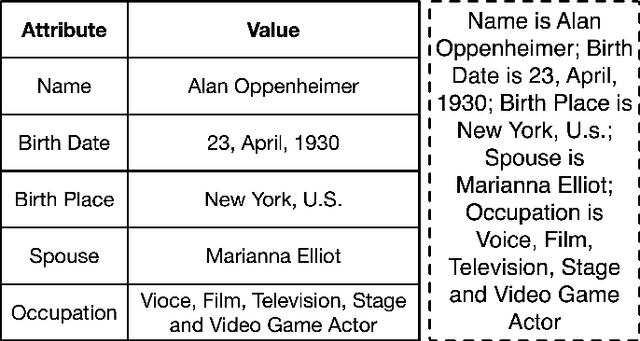
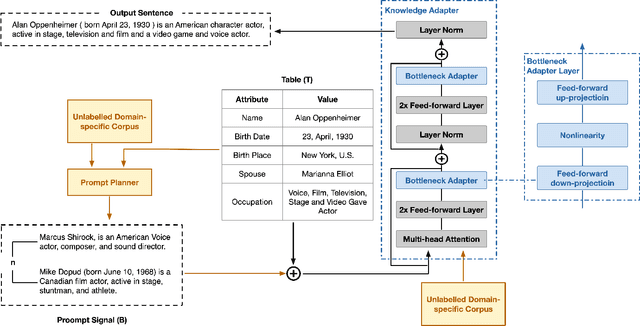

Pre-trained language models (PLM) have achieved remarkable advancement in table-to-text generation tasks. However, the lack of labeled domain-specific knowledge and the topology gap between tabular data and text make it difficult for PLMs to yield faithful text. Low-resource generation likewise faces unique challenges in this domain. Inspired by how humans descript tabular data with prior knowledge, we suggest a new framework: PromptMize, which targets table-to-text generation under few-shot settings. The design of our framework consists of two aspects: a prompt planner and a knowledge adapter. The prompt planner aims to generate a prompt signal that provides instance guidance for PLMs to bridge the topology gap between tabular data and text. Moreover, the knowledge adapter memorizes domain-specific knowledge from the unlabelled corpus to supply essential information during generation. Extensive experiments and analyses are investigated on three open domain few-shot NLG datasets: human, song, and book. Compared with previous state-of-the-art approaches, our model achieves remarkable performance in generating quality as judged by human and automatic evaluations.
Automated Statement Extraction from Press Briefings
Feb 24, 2023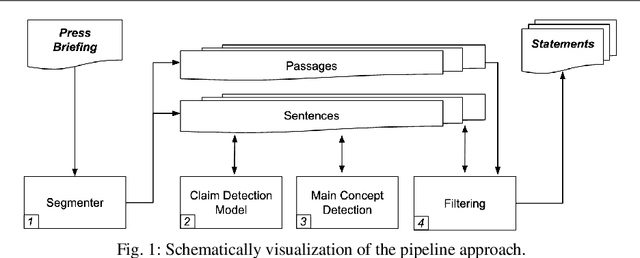
Scientific press briefings are a valuable information source. They consist of alternating expert speeches, questions from the audience and their answers. Therefore, they can contribute to scientific and fact-based media coverage. Even though press briefings are highly informative, extracting statements relevant to individual journalistic tasks is challenging and time-consuming. To support this task, an automated statement extraction system is proposed. Claims are used as the main feature to identify statements in press briefing transcripts. The statement extraction task is formulated as a four-step procedure. First, the press briefings are split into sentences and passages, then claim sentences are identified through sequence classification. Subsequently, topics are detected, and the sentences are filtered to improve the coherence and assess the length of the statements. The results indicate that claim detection can be used to identify statements in press briefings. While many statements can be extracted automatically with this system, they are not always as coherent as needed to be understood without context and may need further review by knowledgeable persons.