 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Novel Building Detection and Location Intelligence Collection in Aerial Satellite Imagery
Feb 06, 2023

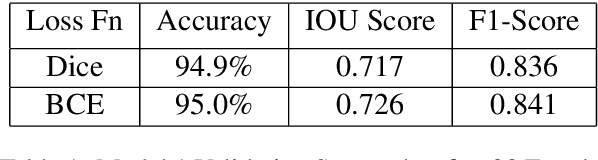
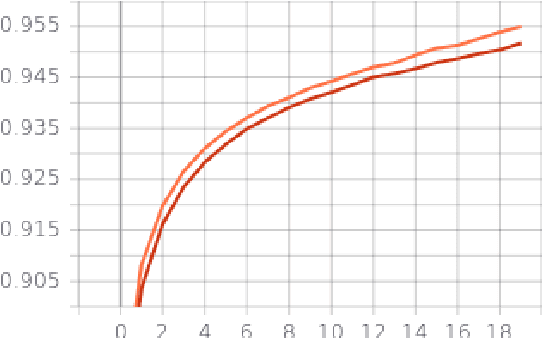
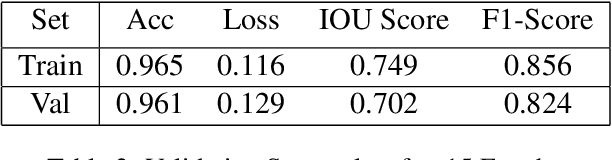
Building structures detection and information about these buildings in aerial images is an important solution for city planning and management, land use analysis. It can be the center piece to answer important questions such as planning evacuation routes in case of an earthquake, flood management, etc. These applications rely on being able to accurately retrieve up-to-date information. Being able to accurately detect buildings in a bounding box centered on a specific latitude-longitude value can help greatly. The key challenge is to be able to detect buildings which can be commercial, industrial, hut settlements, or skyscrapers. Once we are able to detect such buildings, our goal will be to cluster and categorize similar types of buildings together.
A Human-Centered Safe Robot Reinforcement Learning Framework with Interactive Behaviors
Feb 25, 2023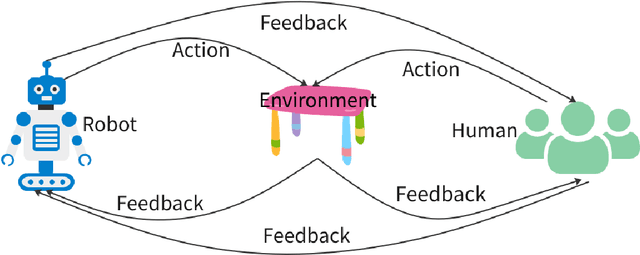
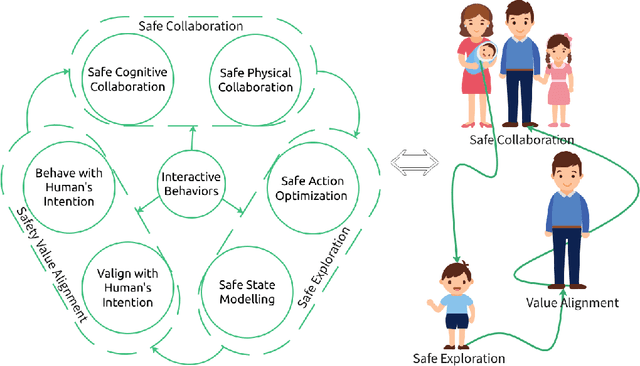
Deployment of reinforcement learning algorithms for robotics applications in the real world requires ensuring the safety of the robot and its environment. Safe robot reinforcement learning (SRRL) is a crucial step towards achieving human-robot coexistence. In this paper, we envision a human-centered SRRL framework consisting of three stages: safe exploration, safety value alignment, and safe collaboration. We examine the research gaps in these areas and propose to leverage interactive behaviors for SRRL. Interactive behaviors enable bi-directional information transfer between humans and robots, such as conversational robot ChatGPT. We argue that interactive behaviors need further attention from the SRRL community. We discuss four open challenges related to the robustness, efficiency, transparency, and adaptability of SRRL with interactive behaviors.
Autodecompose: A generative self-supervised model for semantic decomposition
Feb 13, 2023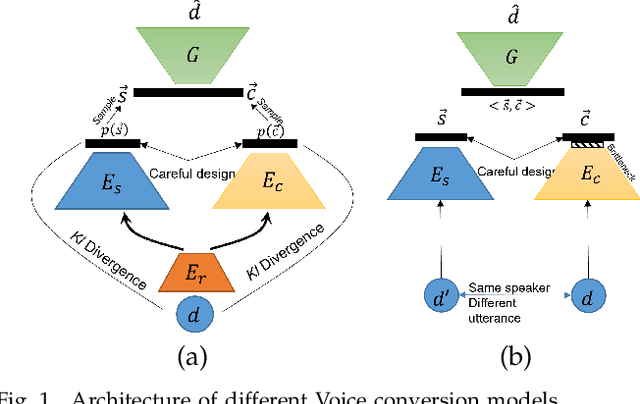

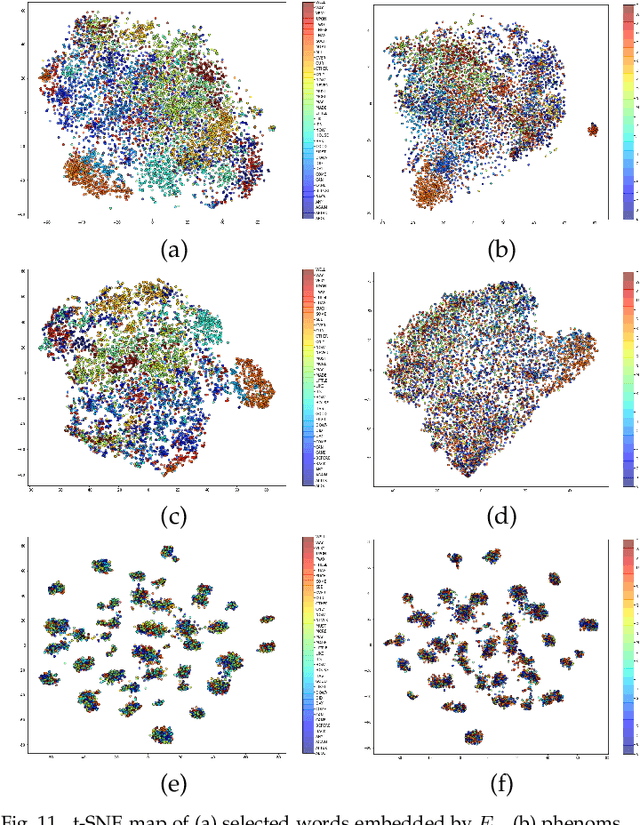
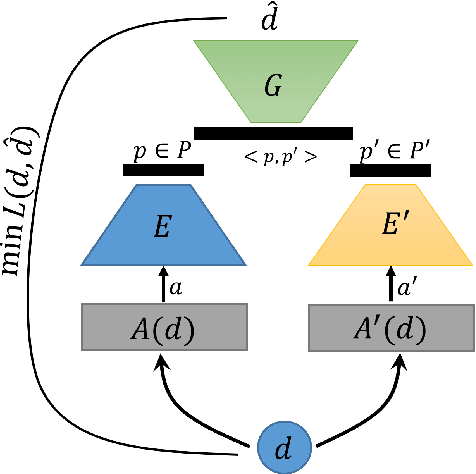
We introduce Autodecompose, a novel self-supervised generative model that decomposes data into two semantically independent properties: the desired property, which captures a specific aspect of the data (e.g. the voice in an audio signal), and the context property, which aggregates all other information (e.g. the content of the audio signal), without any labels given. Autodecompose uses two complementary augmentations, one that manipulates the context while preserving the desired property and the other that manipulates the desired property while preserving the context. The augmented variants of the data are encoded by two encoders and reconstructed by a decoder. We prove that one of the encoders embeds the desired property while the other embeds the context property. We apply Autodecompose to audio signals to encode sound source (human voice) and content. We pre-trained the model on YouTube and LibriSpeech datasets and fine-tuned in a self-supervised manner without exposing the labels. Our results showed that, using the sound source encoder of pre-trained Autodecompose, a linear classifier achieves F1 score of 97.6\% in recognizing the voice of 30 speakers using only 10 seconds of labeled samples, compared to 95.7\% for supervised models. Additionally, our experiments showed that Autodecompose is robust against overfitting even when a large model is pre-trained on a small dataset. A large Autodecompose model was pre-trained from scratch on 60 seconds of audio from 3 speakers achieved over 98.5\% F1 score in recognizing those three speakers in other unseen utterances. We finally show that the context encoder embeds information about the content of the speech and ignores the sound source information. Our sample code for training the model, as well as examples for using the pre-trained models are available here: \url{https://github.com/rezabonyadi/autodecompose}
Joint Communication, Sensing and Computation enabled 6G Intelligent Machine System
Feb 21, 2023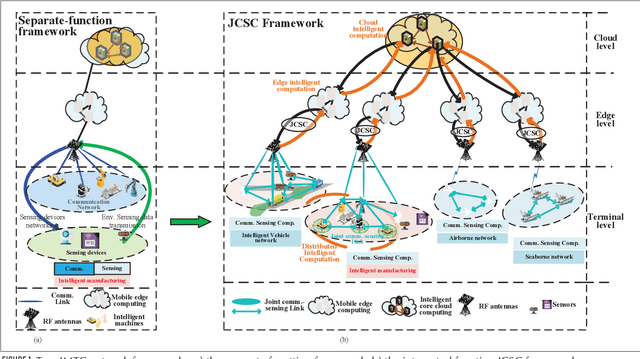

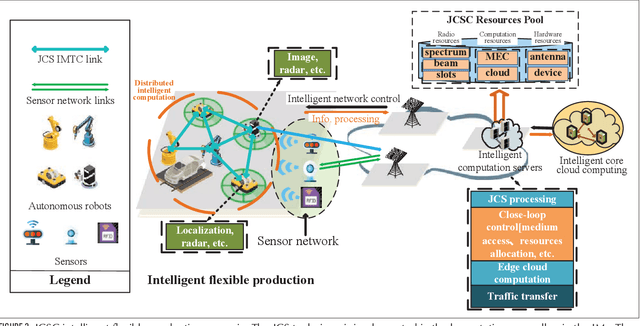
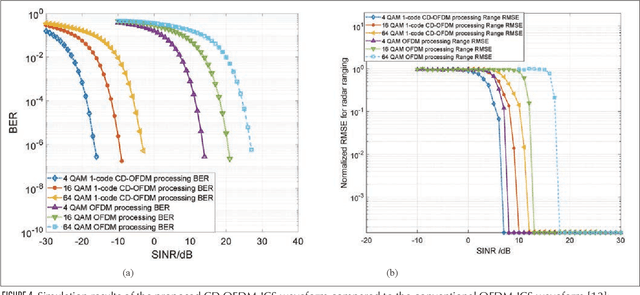
With the rapid development of the smart city, high-level autonomous driving, intelligent manufacturing, and etc., the stringent industrial-level requirements of the extremely low latency and high reliability for communication and new trends for sub-centimeter sensing have transcended the abilities of 5G and call for the development of 6G. Based on analyzing the function design of the communication, sensing and the emerging intelligent computation systems, we propose the joint communication, sensing and computation (JCSC) framework for 6G intelligent machine-type communication (IMTC) network to realize low latency and high reliability of communication, highly accurate sensing and fast environment adaption. In the proposed JCSC framework, the communication, sensing and computation abilities cooperate to benefit each other by utilizing the unified hardware, resource and protocol design. Sensing information is exploited as priori information to enhance the reliability and latency performance of wireless communication and to optimize the resource utilization of the communication network, which further improves the distributed computation and cooperative sensing ability. We propose the promising enabling technologies such as joint communication and sensing (JCS) technique, JCSC wireless networking techniques and intelligent computation techniques. We also summarize the challenges to achieve the JCSC framework. Then, we introduce the intelligent flexible manufacturing as a typical use case of the IMTC with JCSC framework, where the enabling technologies are deployed. Finally, we present the simulation results to prove the feasibility of the JCSC framework by evaluating the JCS waveform, the JCSC enabled neighbor discovery (ND) and medium access control (MAC).
* 9 pages, 6 figures, published by IEEE Network
LoS sensing-based superimposed CSI feedback for UAV-Assisted mmWave systems
Feb 21, 2023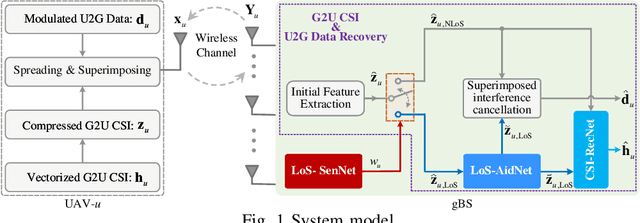
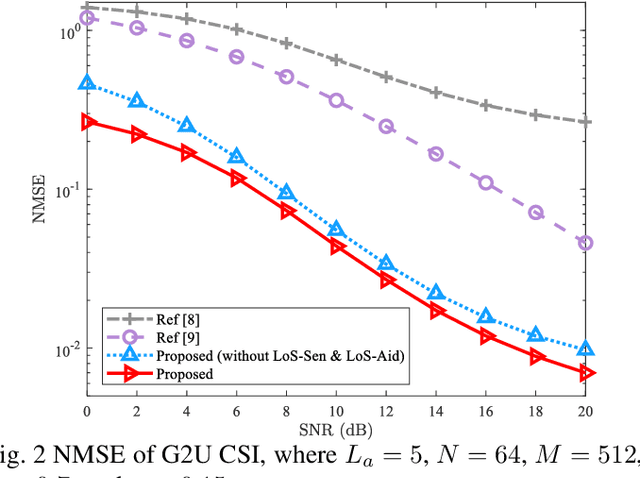
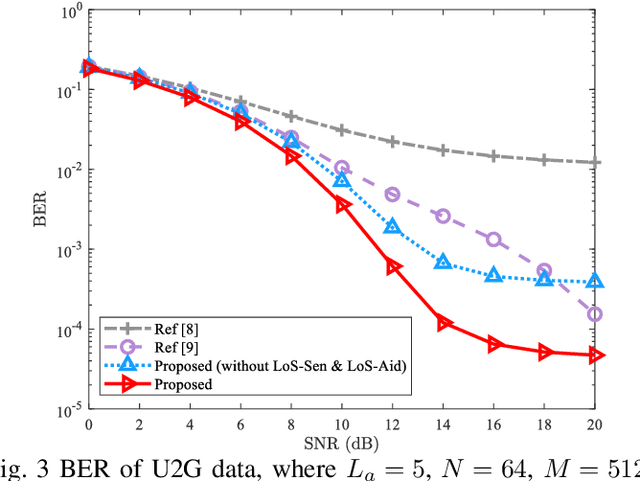
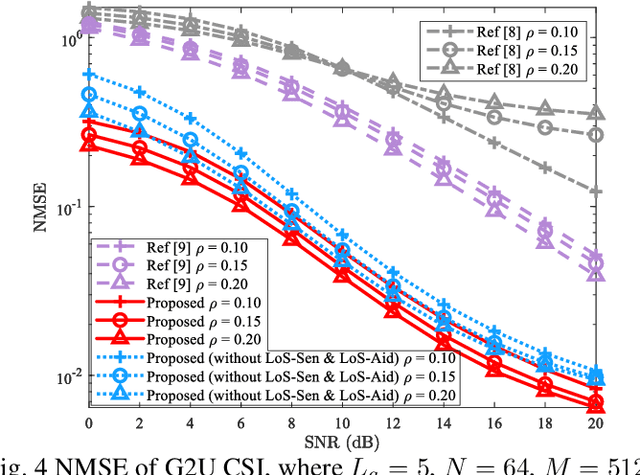
In unmanned aerial vehicle (UAV)-assisted millimeter wave (mmWave) systems, channel state information (CSI) feedback is critical for the selection of modulation schemes, resource management, beamforming, etc. However, traditional CSI feedback methods lead to significant feedback overhead and energy consumption of the UAV transmitter, therefore shortening the system operation time. To tackle these issues, inspired by superimposed feedback and integrated sensing and communications (ISAC), a line of sight (LoS) sensing-based superimposed CSI feedback scheme is proposed. Specifically, on the UAV transmitter side, the ground-to-UAV (G2U) CSI is superimposed on the UAVto-ground (U2G) data to feed back to the ground base station (gBS). At the gBS, the dedicated LoS sensing network (LoSSenNet) is designed to sense the U2G CSI in LoS and NLoS scenarios. With the sensed result of LoS-SenNet, the determined G2U CSI from the initial feature extraction will work as the priori information to guide the subsequent operation. Specifically, for the G2U CSI in NLoS, a CSI recovery network (CSI-RecNet) and superimposed interference cancellation are developed to recover the G2U CSI and U2G data. As for the LoS scenario, a dedicated LoS aid network (LoS-AidNet) is embedded before the CSI-RecNet and the block of superimposed interference cancellation to highlight the feature of the G2U CSI. Compared with other methods of superimposed CSI feedback, simulation results demonstrate that the proposed feedback scheme effectively improves the recovery accuracy of the G2U CSI and U2G data. Besides, against parameter variations, the proposed feedback scheme presents its robustness.
Deformable Proposal-Aware P2PNet: A Universal Network for Cell Recognition under Point Supervision
Mar 05, 2023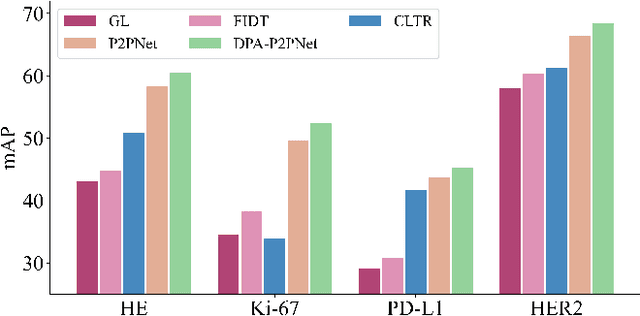

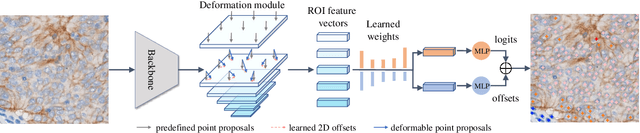
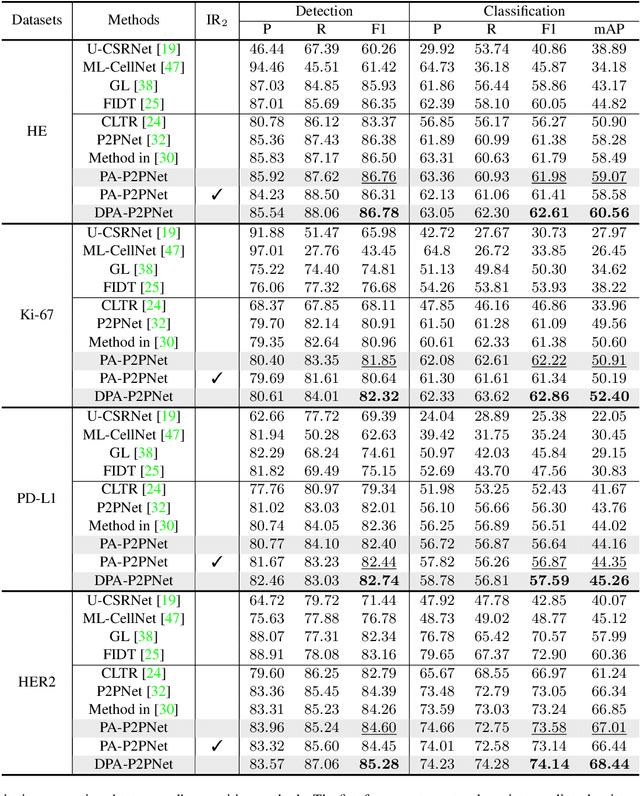
Point-based cell recognition, which aims to localize and classify cells present in a pathology image, is a fundamental task in digital pathology image analysis. The recently developed point-to-point network (P2PNet) has achieved unprecedented cell recognition accuracy and efficiency compared to methods that rely on intermediate density map representations. However, P2PNet could not leverage multi-scale information since it can only decode a single feature map. Moreover, the distribution of predefined point proposals, which is determined by data properties, restricts the resolution of the feature map to decode, i.e., the encoder design. To lift these limitations, we propose a variant of P2PNet named deformable proposal-aware P2PNet (DPA-P2PNet) in this study. The proposed method uses coordinates of point proposals to directly extract multi-scale region-of-interest (ROI) features for feature enhancement. Such a design also opens up possibilities to exploit dynamic distributions of proposals. We further devise a deformation module to improve the proposal quality. Extensive experiments on four datasets with various staining styles demonstrate that DPA-P2PNet outperforms the state-of-the-art methods on point-based cell recognition, which reveals the high potentiality in assisting pathologist assessments.
Neuroevolutionary algorithms driven by neuron coverage metrics for semi-supervised classification
Mar 05, 2023
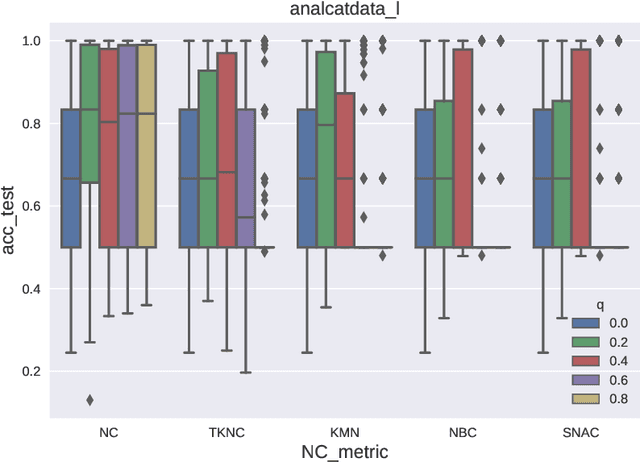
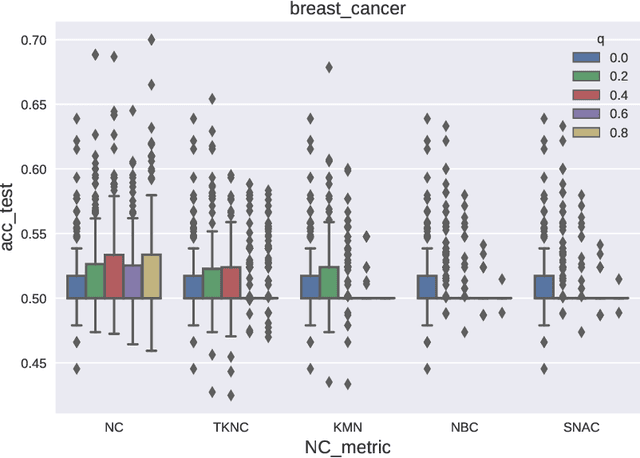
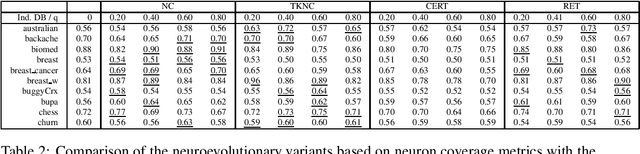
In some machine learning applications the availability of labeled instances for supervised classification is limited while unlabeled instances are abundant. Semi-supervised learning algorithms deal with these scenarios and attempt to exploit the information contained in the unlabeled examples. In this paper, we address the question of how to evolve neural networks for semi-supervised problems. We introduce neuroevolutionary approaches that exploit unlabeled instances by using neuron coverage metrics computed on the neural network architecture encoded by each candidate solution. Neuron coverage metrics resemble code coverage metrics used to test software, but are oriented to quantify how the different neural network components are covered by test instances. In our neuroevolutionary approach, we define fitness functions that combine classification accuracy computed on labeled examples and neuron coverage metrics evaluated using unlabeled examples. We assess the impact of these functions on semi-supervised problems with a varying amount of labeled instances. Our results show that the use of neuron coverage metrics helps neuroevolution to become less sensitive to the scarcity of labeled data, and can lead in some cases to a more robust generalization of the learned classifiers.
CTE: A Dataset for Contextualized Table Extraction
Feb 13, 2023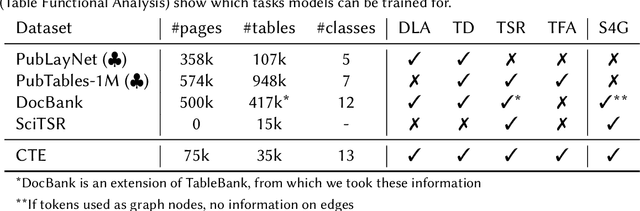

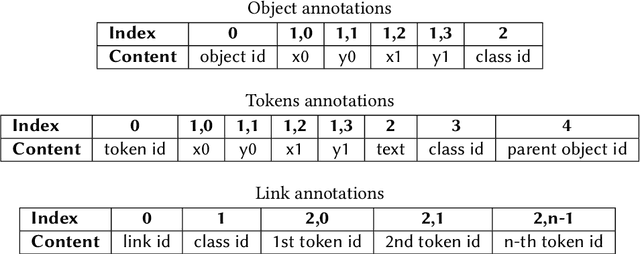

Relevant information in documents is often summarized in tables, helping the reader to identify useful facts. Most benchmark datasets support either document layout analysis or table understanding, but lack in providing data to apply both tasks in a unified way. We define the task of Contextualized Table Extraction (CTE), which aims to extract and define the structure of tables considering the textual context of the document. The dataset comprises 75k fully annotated pages of scientific papers, including more than 35k tables. Data are gathered from PubMed Central, merging the information provided by annotations in the PubTables-1M and PubLayNet datasets. The dataset can support CTE and adds new classes to the original ones. The generated annotations can be used to develop end-to-end pipelines for various tasks, including document layout analysis, table detection, structure recognition, and functional analysis. We formally define CTE and evaluation metrics, showing which subtasks can be tackled, describing advantages, limitations, and future works of this collection of data. Annotations and code will be accessible a https://github.com/AILab-UniFI/cte-dataset.
Contour Context: Abstract Structural Distribution for 3D LiDAR Loop Detection and Metric Pose Estimation
Feb 13, 2023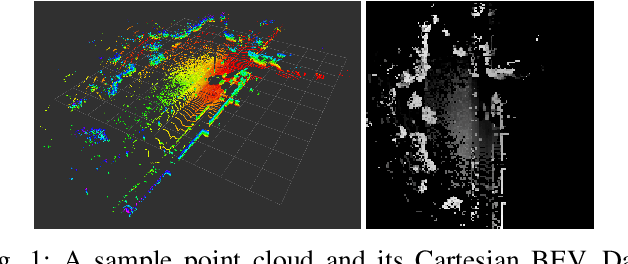
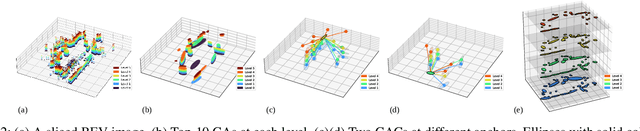
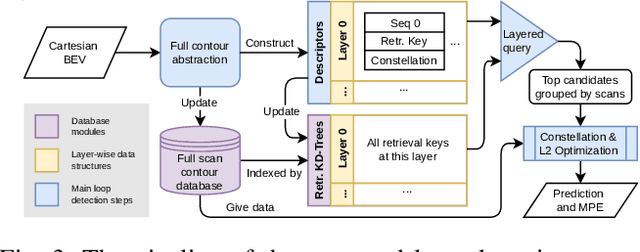
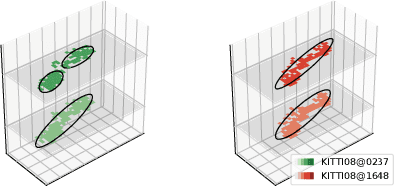
This paper proposes \textit{Contour Context}, a simple, effective, and efficient topological loop closure detection pipeline with accurate 3-DoF metric pose estimation, targeting the urban utonomous driving scenario. We interpret the Cartesian birds' eye view (BEV) image projected from 3D LiDAR points as layered distribution of structures. To recover elevation information from BEVs, we slice them at different heights, and connected pixels at each level will form contours. Each contour is parameterized by abstract information, e.g., pixel count, center position, covariance, and mean height. The similarity of two BEVs is calculated in sequential discrete and continuous steps. The first step considers the geometric consensus of graph-like constellations formed by contours in particular localities. The second step models the majority of contours as a 2.5D Gaussian mixture model, which is used to calculate correlation and optimize relative transform in continuous space. A retrieval key is designed to accelerate the search of a database indexed by layered KD-trees. We validate the efficacy of our method by comparing it with recent works on public datasets.
Exploring Navigation Maps for Learning-Based Motion Prediction
Feb 13, 2023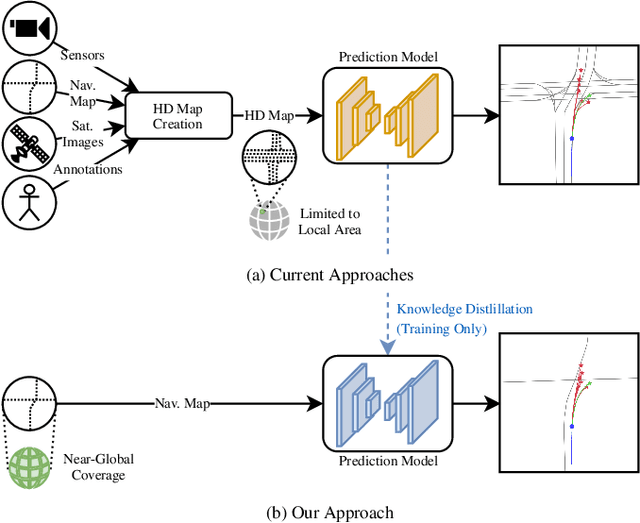
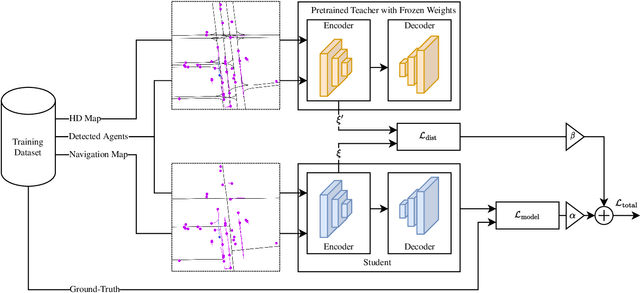
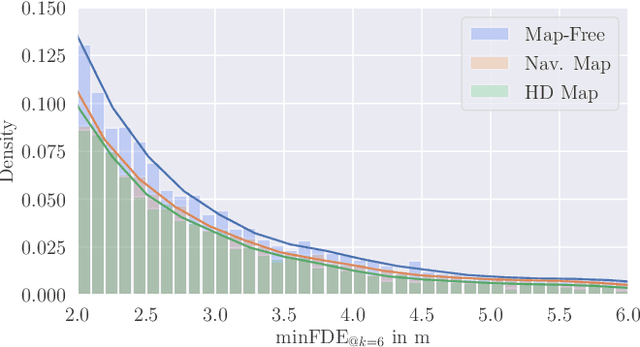
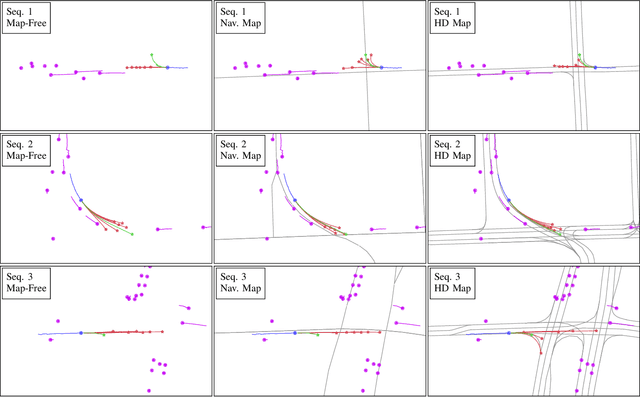
The prediction of surrounding agents' motion is a key for safe autonomous driving. In this paper, we explore navigation maps as an alternative to the predominant High Definition (HD) maps for learning-based motion prediction. Navigation maps provide topological and geometrical information on road-level, HD maps additionally have centimeter-accurate lane-level information. As a result, HD maps are costly and time-consuming to obtain, while navigation maps with near-global coverage are freely available. We describe an approach to integrate navigation maps into learning-based motion prediction models. To exploit locally available HD maps during training, we additionally propose a model-agnostic method for knowledge distillation. In experiments on the publicly available Argoverse dataset with navigation maps obtained from OpenStreetMap, our approach shows a significant improvement over not using a map at all. Combined with our method for knowledge distillation, we achieve results that are close to the original HD map-reliant models. Our publicly available navigation map API for Argoverse enables researchers to develop and evaluate their own approaches using navigation maps.