 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Synthesis-based Imaging-Differentiation Representation Learning for Multi-Sequence 3D/4D MRI
Feb 01, 2023
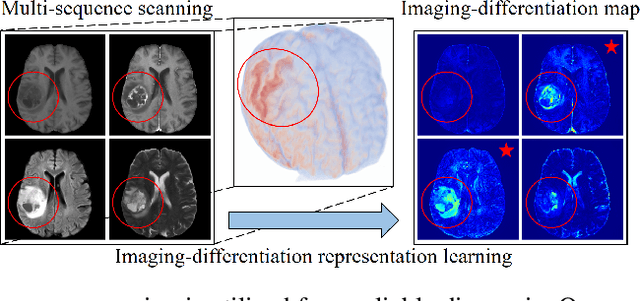
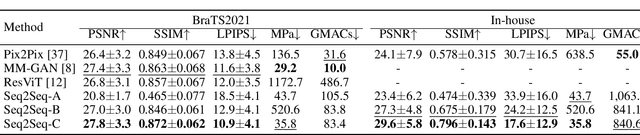
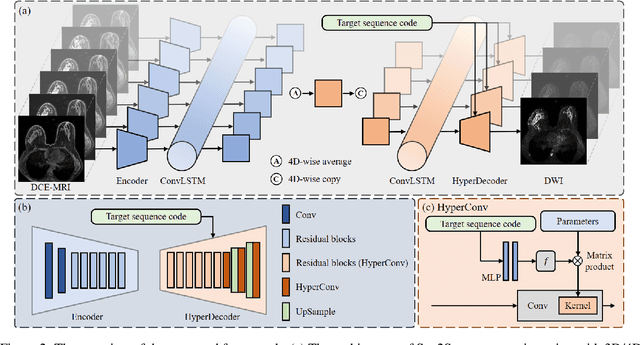
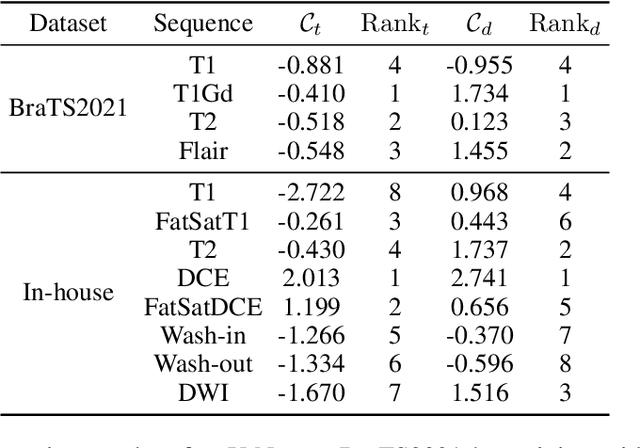
Multi-sequence MRIs can be necessary for reliable diagnosis in clinical practice due to the complimentary information within sequences. However, redundant information exists across sequences, which interferes with mining efficient representations by modern machine learning or deep learning models. To handle various clinical scenarios, we propose a sequence-to-sequence generation framework (Seq2Seq) for imaging-differentiation representation learning. In this study, not only do we propose arbitrary 3D/4D sequence generation within one model to generate any specified target sequence, but also we are able to rank the importance of each sequence based on a new metric estimating the difficulty of a sequence being generated. Furthermore, we also exploit the generation inability of the model to extract regions that contain unique information for each sequence. We conduct extensive experiments using three datasets including a toy dataset of 20,000 simulated subjects, a brain MRI dataset of 1,251 subjects, and a breast MRI dataset of 2,101 subjects, to demonstrate that (1) our proposed Seq2Seq is efficient and lightweight for complex clinical datasets and can achieve excellent image quality; (2) top-ranking sequences can be used to replace complete sequences with non-inferior performance; (3) combining MRI with our imaging-differentiation map leads to better performance in clinical tasks such as glioblastoma MGMT promoter methylation status prediction and breast cancer pathological complete response status prediction. Our code is available at https://github.com/fiy2W/mri_seq2seq.
A Unified BEV Model for Joint Learning of 3D Local Features and Overlap Estimation
Feb 28, 2023
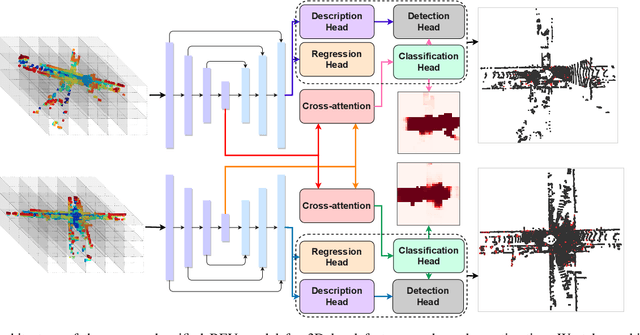
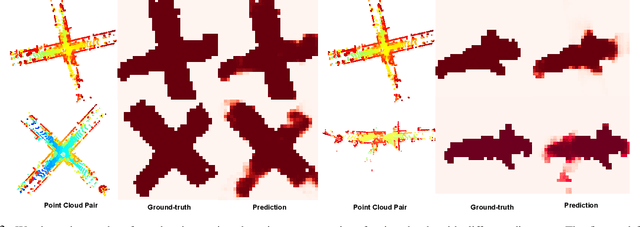
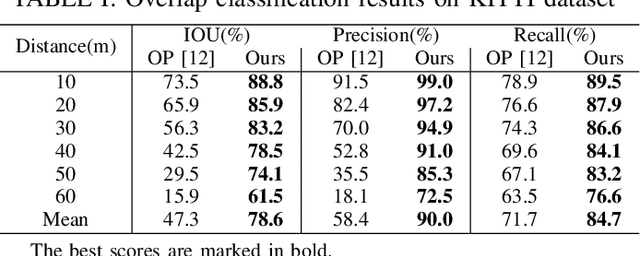
Pairwise point cloud registration is a critical task for many applications, which heavily depends on finding the right correspondences from the two point clouds. However, the low overlap between the input point clouds makes the registration prone to fail, leading to mistaken overlapping and mismatched correspondences, especially in scenes where non-overlapping regions contain similar structures. In this paper, we present a unified bird's-eye view (BEV) model for jointly learning of 3D local features and overlap estimation to fulfill the pairwise registration and loop closure. Feature description based on BEV representation is performed by a sparse UNet-like network, and the 3D keypoints are extracted by a detection head for 2D locations and a regression head for heights, respectively. For overlap detection, a cross-attention module is applied for interacting contextual information of the input point clouds, followed by a classification head to estimate the overlapping region. We evaluate our unified model extensively on the KITTI dataset and Apollo-SouthBay dataset. The experiments demonstrate that our method significantly outperforms existing methods on overlap prediction, especially in scenes with small overlaps. The registration precision also achieves top performance on both datasets in terms of translation and rotation errors. Source codes will be available soon.
DC-Former: Diverse and Compact Transformer for Person Re-Identification
Feb 28, 2023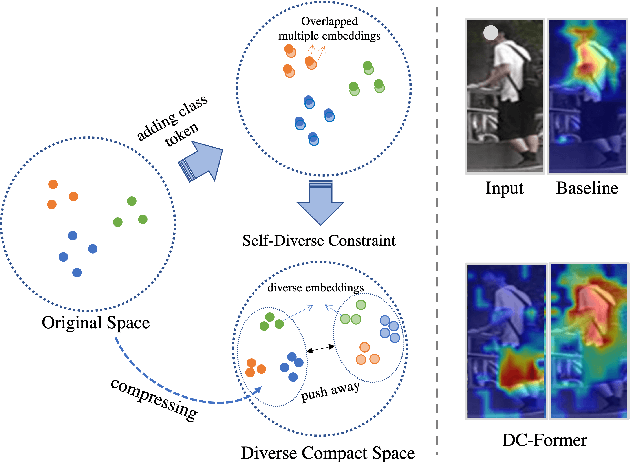
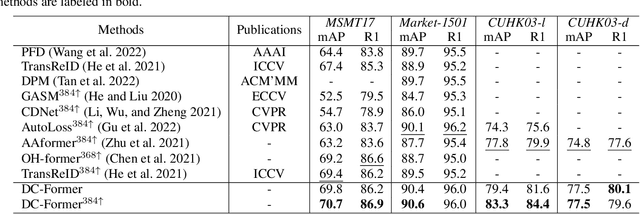
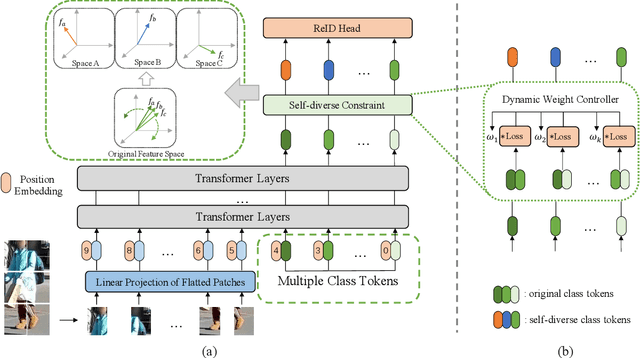
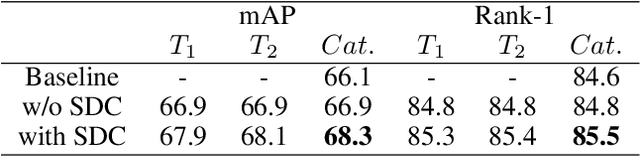
In person re-identification (re-ID) task, it is still challenging to learn discriminative representation by deep learning, due to limited data. Generally speaking, the model will get better performance when increasing the amount of data. The addition of similar classes strengthens the ability of the classifier to identify similar identities, thereby improving the discrimination of representation. In this paper, we propose a Diverse and Compact Transformer (DC-Former) that can achieve a similar effect by splitting embedding space into multiple diverse and compact subspaces. Compact embedding subspace helps model learn more robust and discriminative embedding to identify similar classes. And the fusion of these diverse embeddings containing more fine-grained information can further improve the effect of re-ID. Specifically, multiple class tokens are used in vision transformer to represent multiple embedding spaces. Then, a self-diverse constraint (SDC) is applied to these spaces to push them away from each other, which makes each embedding space diverse and compact. Further, a dynamic weight controller(DWC) is further designed for balancing the relative importance among them during training. The experimental results of our method are promising, which surpass previous state-of-the-art methods on several commonly used person re-ID benchmarks.
LIW-OAM: Lidar-Inertial-Wheel Odometry and Mapping
Feb 28, 2023
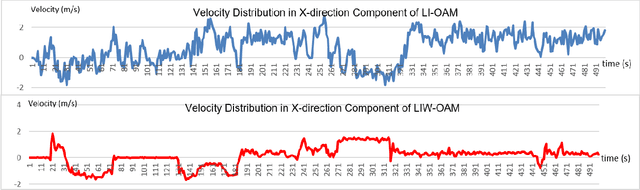
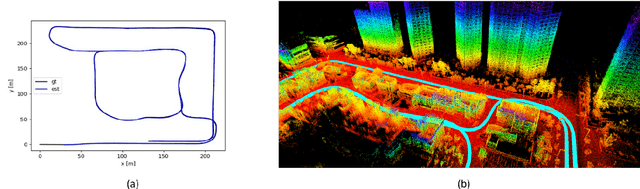
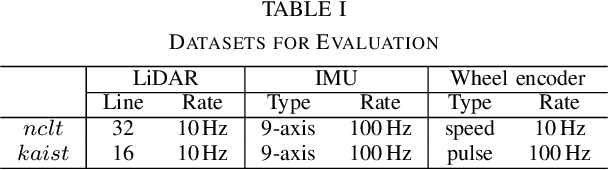
LiDAR-inertial odometry and mapping (LIOAM), which fuses complementary information of a LiDAR and an Inertial Measurement Unit (IMU), is an attractive solution for pose estimation and mapping. In LI-OAM, both pose and velocity are regarded as state variables that need to be solved. However, the widely-used Iterative Closest Point (ICP) algorithm can only provide constraint for pose, while the velocity can only be constrained by IMU pre-integration. As a result, the velocity estimates inclined to be updated accordingly with the pose results. In this paper, we propose LIW-OAM, an accurate and robust LiDAR-inertial-wheel odometry and mapping system, which fuses the measurements from LiDAR, IMU and wheel encoder in a bundle adjustment (BA) based optimization framework. The involvement of a wheel encoder could provide velocity measurement as an important observation, which assists LI-OAM to provide a more accurate state prediction. In addition, constraining the velocity variable by the observation from wheel encoder in optimization can further improve the accuracy of state estimation. Experiment results on two public datasets demonstrate that our system outperforms all state-of-the-art LI-OAM systems in terms of smaller absolute trajectory error (ATE), and embedding a wheel encoder can greatly improve the performance of LI-OAM based on the BA framework.
Applying Plain Transformers to Real-World Point Clouds
Feb 28, 2023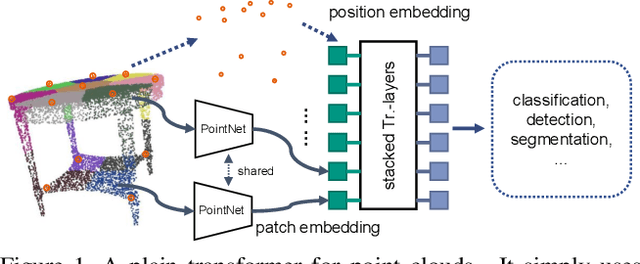
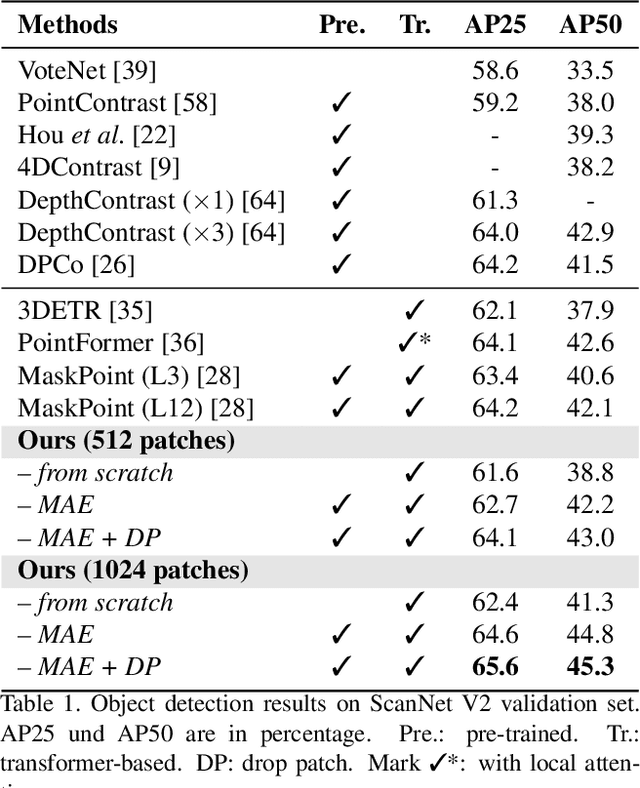
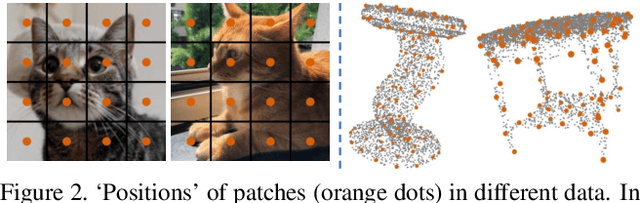
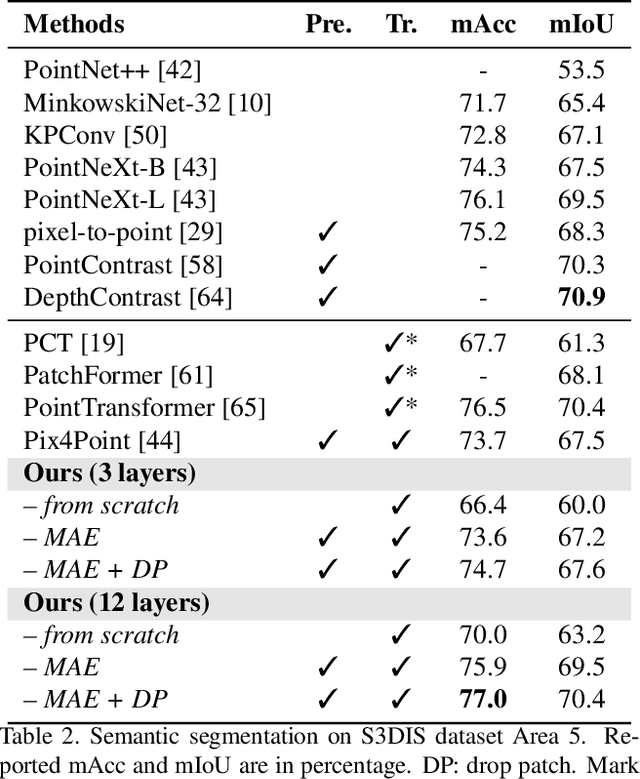
Due to the lack of inductive bias, transformer-based models usually require a large amount of training data. The problem is especially concerning in 3D vision, as 3D data are harder to acquire and annotate. To overcome this problem, previous works modify the architecture of transformers to incorporate inductive biases by applying, e.g., local attention and down-sampling. Although they have achieved promising results, earlier works on transformers for point clouds have two issues. First, the power of plain transformers is still under-explored. Second, they focus on simple and small point clouds instead of complex real-world ones. This work revisits the plain transformers in real-world point cloud understanding. We first take a closer look at some fundamental components of plain transformers, e.g., patchifier and positional embedding, for both efficiency and performance. To close the performance gap due to the lack of inductive bias and annotated data, we investigate self-supervised pre-training with masked autoencoder (MAE). Specifically, we propose drop patch, which prevents information leakage and significantly improves the effectiveness of MAE. Our models achieve SOTA results in semantic segmentation on the S3DIS dataset and object detection on the ScanNet dataset with lower computational costs. Our work provides a new baseline for future research on transformers for point clouds.
RGB-D Grasp Detection via Depth Guided Learning with Cross-modal Attention
Feb 28, 2023
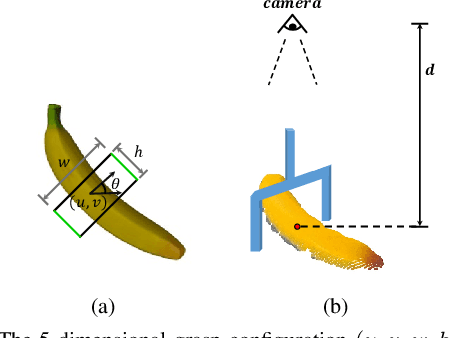
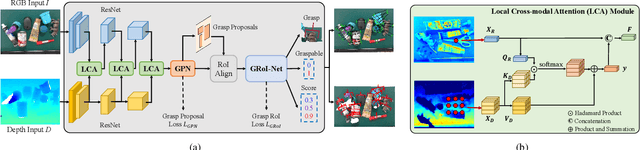

Planar grasp detection is one of the most fundamental tasks to robotic manipulation, and the recent progress of consumer-grade RGB-D sensors enables delivering more comprehensive features from both the texture and shape modalities. However, depth maps are generally of a relatively lower quality with much stronger noise compared to RGB images, making it challenging to acquire grasp depth and fuse multi-modal clues. To address the two issues, this paper proposes a novel learning based approach to RGB-D grasp detection, namely Depth Guided Cross-modal Attention Network (DGCAN). To better leverage the geometry information recorded in the depth channel, a complete 6-dimensional rectangle representation is adopted with the grasp depth dedicatedly considered in addition to those defined in the common 5-dimensional one. The prediction of the extra grasp depth substantially strengthens feature learning, thereby leading to more accurate results. Moreover, to reduce the negative impact caused by the discrepancy of data quality in two modalities, a Local Cross-modal Attention (LCA) module is designed, where the depth features are refined according to cross-modal relations and concatenated to the RGB ones for more sufficient fusion. Extensive simulation and physical evaluations are conducted and the experimental results highlight the superiority of the proposed approach.
GRAN: Ghost Residual Attention Network for Single Image Super Resolution
Feb 28, 2023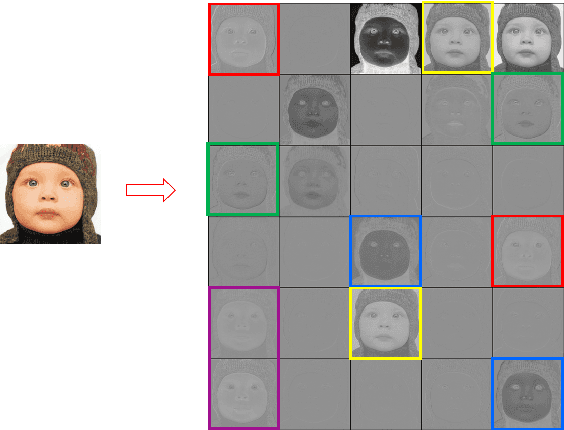
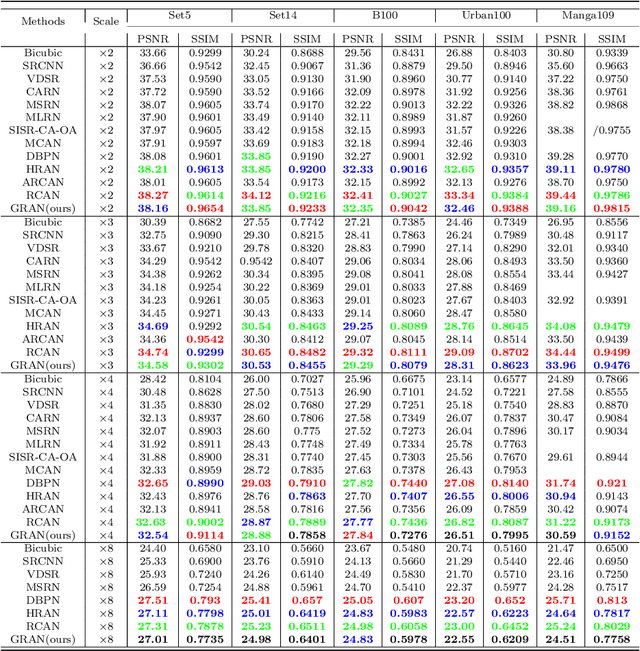
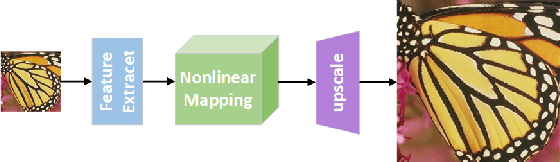

Recently, many works have designed wider and deeper networks to achieve higher image super-resolution performance. Despite their outstanding performance, they still suffer from high computational resources, preventing them from directly applying to embedded devices. To reduce the computation resources and maintain performance, we propose a novel Ghost Residual Attention Network (GRAN) for efficient super-resolution. This paper introduces Ghost Residual Attention Block (GRAB) groups to overcome the drawbacks of the standard convolutional operation, i.e., redundancy of the intermediate feature. GRAB consists of the Ghost Module and Channel and Spatial Attention Module (CSAM) to alleviate the generation of redundant features. Specifically, Ghost Module can reveal information underlying intrinsic features by employing linear operations to replace the standard convolutions. Reducing redundant features by the Ghost Module, our model decreases memory and computing resource requirements in the network. The CSAM pays more comprehensive attention to where and what the feature extraction is, which is critical to recovering the image details. Experiments conducted on the benchmark datasets demonstrate the superior performance of our method in both qualitative and quantitative. Compared to the baseline models, we achieve higher performance with lower computational resources, whose parameters and FLOPs have decreased by more than ten times.
Vision, Deduction and Alignment: An Empirical Study on Multi-modal Knowledge Graph Alignment
Feb 17, 2023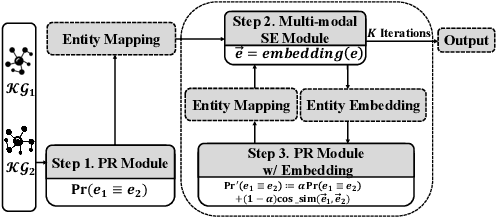
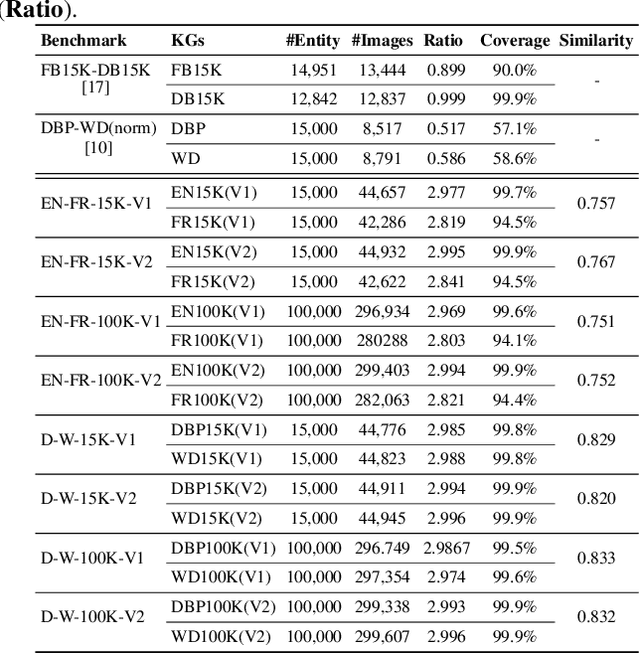
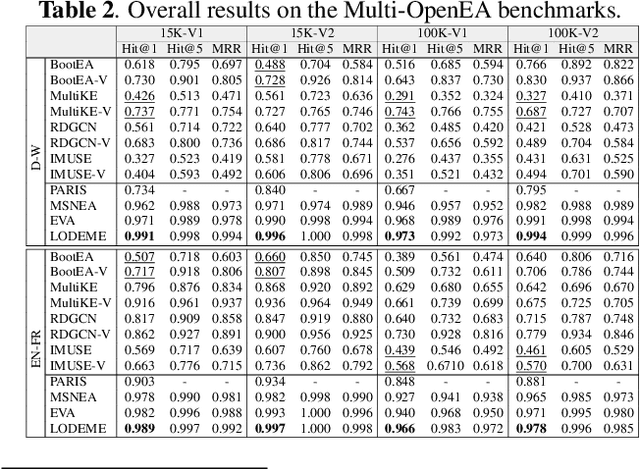
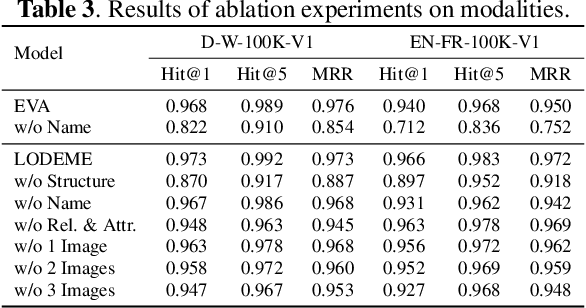
Entity alignment (EA) for knowledge graphs (KGs) plays a critical role in knowledge engineering. Existing EA methods mostly focus on utilizing the graph structures and entity attributes (including literals), but ignore images that are common in modern multi-modal KGs. In this study we first constructed Multi-OpenEA -- eight large-scale, image-equipped EA benchmarks, and then evaluated some existing embedding-based methods for utilizing images. In view of the complementary nature of visual modal information and logical deduction, we further developed a new multi-modal EA method named LODEME using logical deduction and multi-modal KG embedding, with state-of-the-art performance achieved on Multi-OpenEA and other existing multi-modal EA benchmarks.
Cross-Layer Retrospective Retrieving via Layer Attention
Feb 08, 2023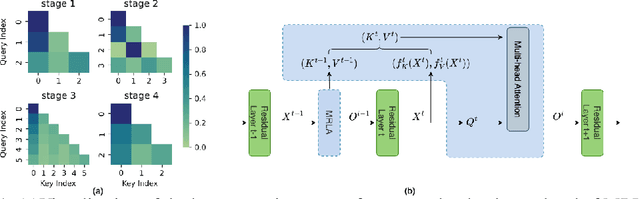
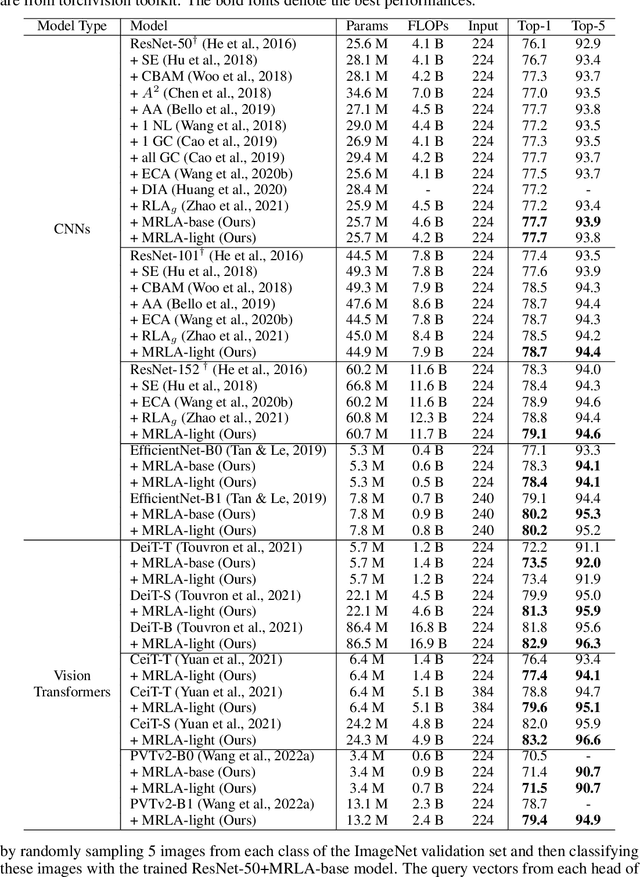
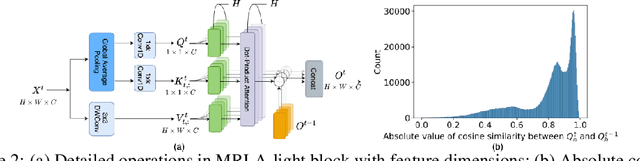
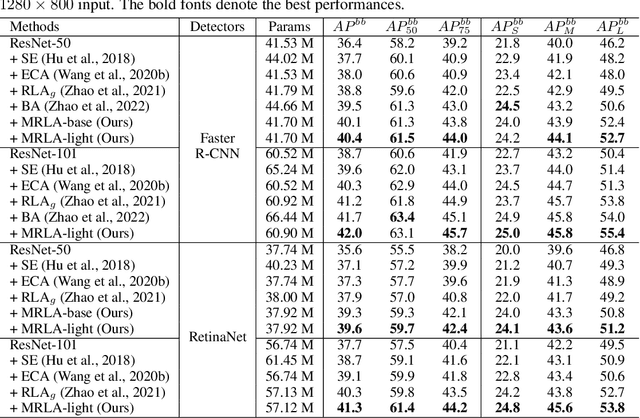
More and more evidence has shown that strengthening layer interactions can enhance the representation power of a deep neural network, while self-attention excels at learning interdependencies by retrieving query-activated information. Motivated by this, we devise a cross-layer attention mechanism, called multi-head recurrent layer attention (MRLA), that sends a query representation of the current layer to all previous layers to retrieve query-related information from different levels of receptive fields. A light-weighted version of MRLA is also proposed to reduce the quadratic computation cost. The proposed layer attention mechanism can enrich the representation power of many state-of-the-art vision networks, including CNNs and vision transformers. Its effectiveness has been extensively evaluated in image classification, object detection and instance segmentation tasks, where improvements can be consistently observed. For example, our MRLA can improve 1.6\% Top-1 accuracy on ResNet-50, while only introducing 0.16M parameters and 0.07B FLOPs. Surprisingly, it can boost the performances by a large margin of 3-4\% box AP and mask AP in dense prediction tasks. Our code is available at https://github.com/joyfang1106/MRLA.
Age of Information in Federated Learning over Wireless Networks
Sep 14, 2022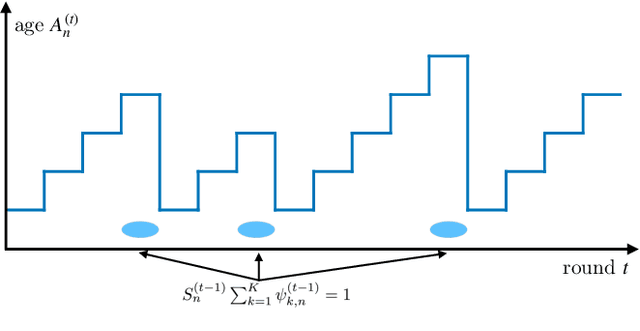
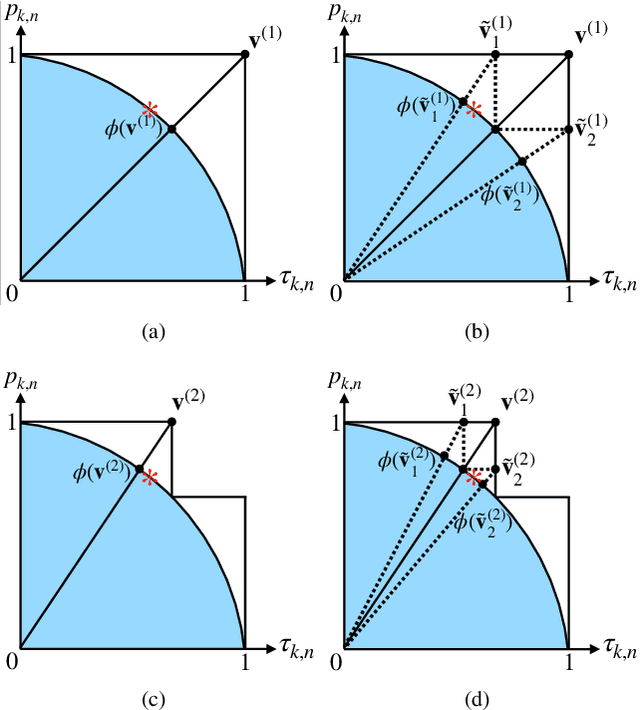
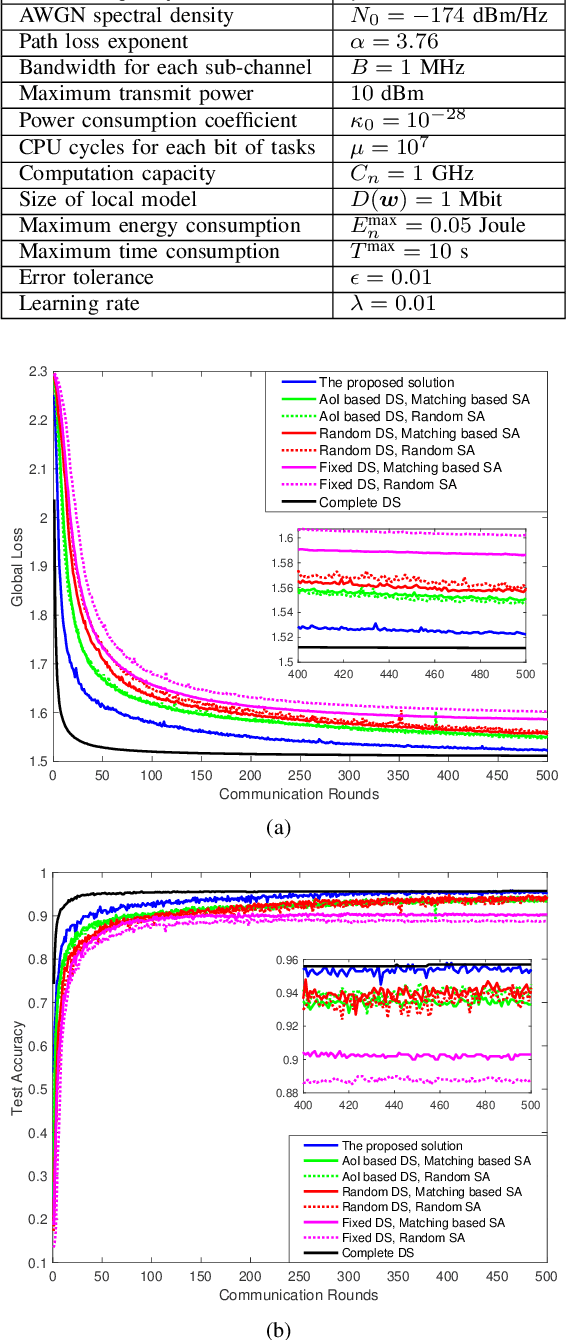
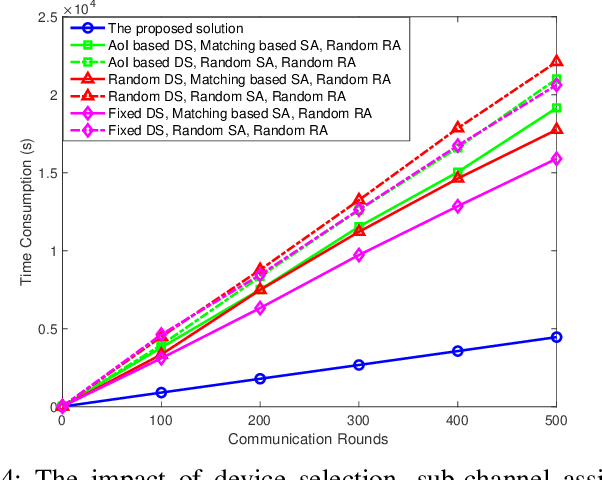
In this paper, federated learning (FL) over wireless networks is investigated. In each communication round, a subset of devices is selected to participate in the aggregation with limited time and energy. In order to minimize the convergence time, global loss and latency are jointly considered in a Stackelberg game based framework. Specifically, age of information (AoI) based device selection is considered at leader-level as a global loss minimization problem, while sub-channel assignment, computational resource allocation, and power allocation are considered at follower-level as a latency minimization problem. By dividing the follower-level problem into two sub-problems, the best response of the follower is obtained by a monotonic optimization based resource allocation algorithm and a matching based sub-channel assignment algorithm. By deriving the upper bound of convergence rate, the leader-level problem is reformulated, and then a list based device selection algorithm is proposed to achieve Stackelberg equilibrium. Simulation results indicate that the proposed device selection scheme outperforms other schemes in terms of the global loss, and the developed algorithms can significantly decrease the time consumption of computation and communication.