 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Energy-Aware Resource Allocation and Trajectory Design for UAV-Enabled ISAC
Feb 20, 2023
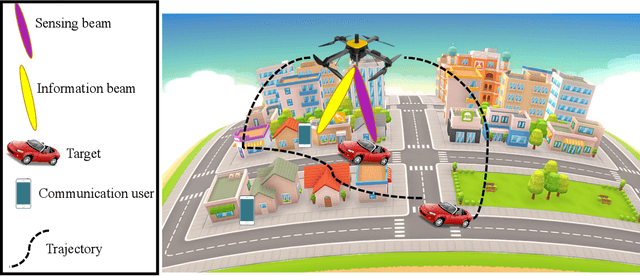
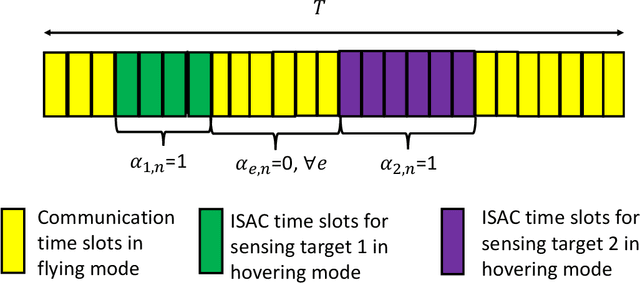
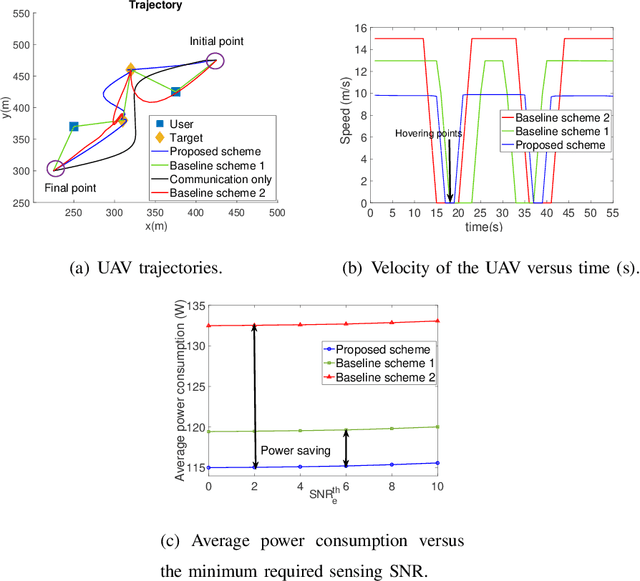

In this paper, we investigate joint resource allocation and trajectory design for multi-user multi-target unmanned aerial vehicle (UAV)-enabled integrated sensing and communication (ISAC). To improve sensing accuracy, the UAV is forced to hover during sensing.~In particular, we jointly optimize the two-dimensional trajectory, velocity, downlink information and sensing beamformers, and sensing indicator to minimize the average power consumption of a fixed-altitude UAV, while considering the quality of service of the communication users and the sensing tasks. To tackle the resulting non-convex mixed integer non-linear program (MINLP), we exploit semidefinite relaxation, the big-M method, and successive convex approximation to develop an alternating optimization-based algorithm.~Our simulation results demonstrate the significant power savings enabled by the proposed scheme compared to two baseline schemes employing heuristic trajectories.
Learning the Effects of Physical Actions in a Multi-modal Environment
Feb 03, 2023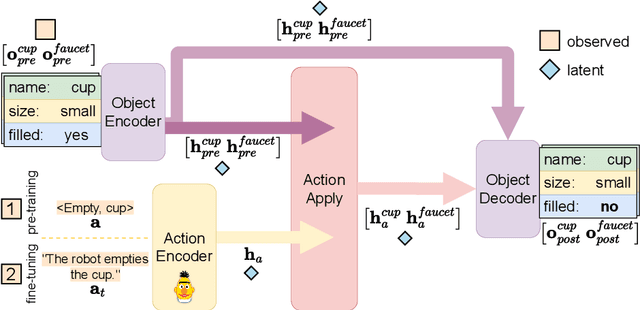
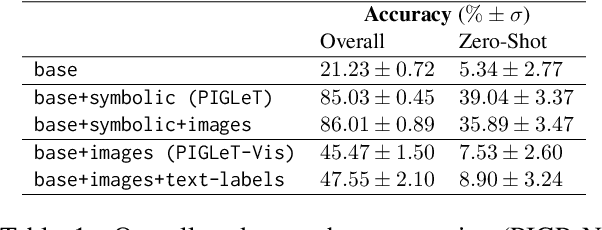
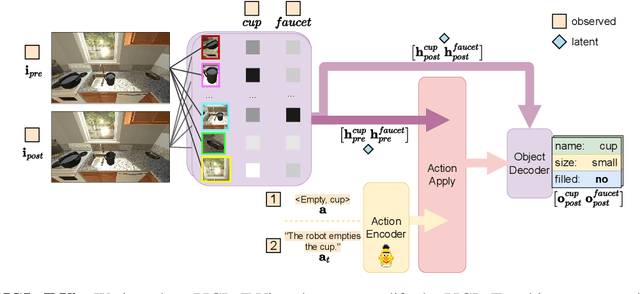
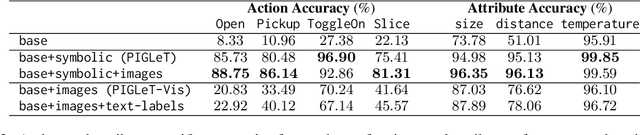
Large Language Models (LLMs) handle physical commonsense information inadequately. As a result of being trained in a disembodied setting, LLMs often fail to predict an action's outcome in a given environment. However, predicting the effects of an action before it is executed is crucial in planning, where coherent sequences of actions are often needed to achieve a goal. Therefore, we introduce the multi-modal task of predicting the outcomes of actions solely from realistic sensory inputs (images and text). Next, we extend an LLM to model latent representations of objects to better predict action outcomes in an environment. We show that multi-modal models can capture physical commonsense when augmented with visual information. Finally, we evaluate our model's performance on novel actions and objects and find that combining modalities help models to generalize and learn physical commonsense reasoning better.
Semantic Segmentation of Urban Textured Meshes Through Point Sampling
Feb 21, 2023
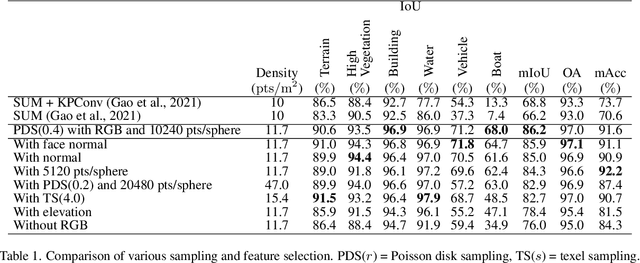


Textured meshes are becoming an increasingly popular representation combining the 3D geometry and radiometry of real scenes. However, semantic segmentation algorithms for urban mesh have been little investigated and do not exploit all radiometric information. To address this problem, we adopt an approach consisting in sampling a point cloud from the textured mesh, then using a point cloud semantic segmentation algorithm on this cloud, and finally using the obtained semantic to segment the initial mesh. In this paper, we study the influence of different parameters such as the sampling method, the density of the extracted cloud, the features selected (color, normal, elevation) as well as the number of points used at each training period. Our result outperforms the state-of-the-art on the SUM dataset, earning about 4 points in OA and 18 points in mIoU.
* 9 pages, 6 figures, conference, presented at XXIV ISPRS Congress
On Interpretable Approaches to Cluster, Classify and Represent Multi-Subspace Data via Minimum Lossy Coding Length based on Rate-Distortion Theory
Feb 21, 2023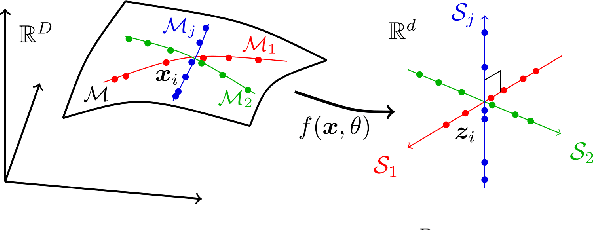
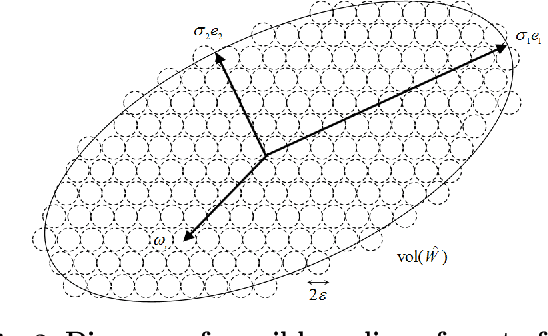
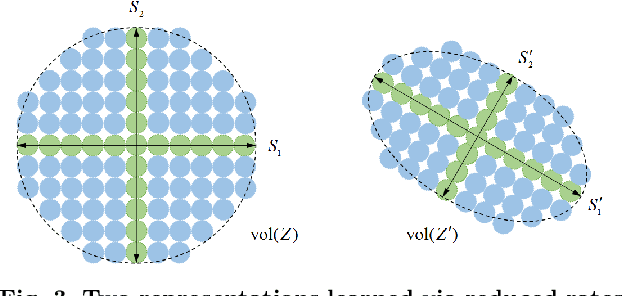
To cluster, classify and represent are three fundamental objectives of learning from high-dimensional data with intrinsic structure. To this end, this paper introduces three interpretable approaches, i.e., segmentation (clustering) via the Minimum Lossy Coding Length criterion, classification via the Minimum Incremental Coding Length criterion and representation via the Maximal Coding Rate Reduction criterion. These are derived based on the lossy data coding and compression framework from the principle of rate distortion in information theory. These algorithms are particularly suitable for dealing with finite-sample data (allowed to be sparse or almost degenerate) of mixed Gaussian distributions or subspaces. The theoretical value and attractive features of these methods are summarized by comparison with other learning methods or evaluation criteria. This summary note aims to provide a theoretical guide to researchers (also engineers) interested in understanding 'white-box' machine (deep) learning methods.
Sedition Hunters: A Quantitative Study of the Crowdsourced Investigation into the 2021 U.S. Capitol Attack
Feb 21, 2023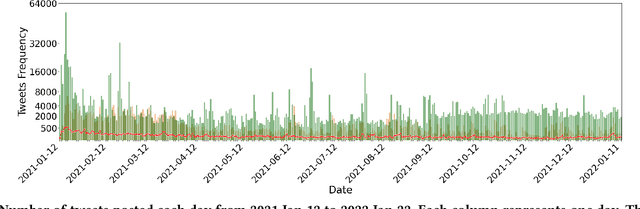
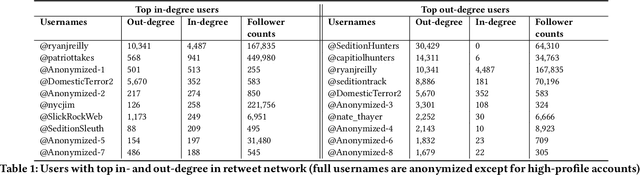

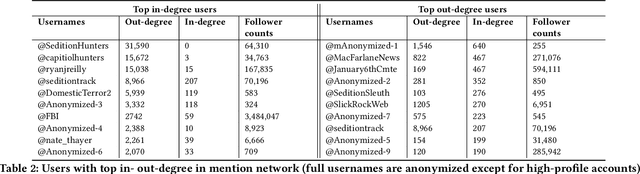
Social media platforms have enabled extremists to organize violent events, such as the 2021 U.S. Capitol Attack. Simultaneously, these platforms enable professional investigators and amateur sleuths to collaboratively collect and identify imagery of suspects with the goal of holding them accountable for their actions. Through a case study of Sedition Hunters, a Twitter community whose goal is to identify individuals who participated in the 2021 U.S. Capitol Attack, we explore what are the main topics or targets of the community, who participates in the community, and how. Using topic modeling, we find that information sharing is the main focus of the community. We also note an increase in awareness of privacy concerns. Furthermore, using social network analysis, we show how some participants played important roles in the community. Finally, we discuss implications for the content and structure of online crowdsourced investigations.
Information FOMO: The unhealthy fear of missing out on information. A method for removing misleading data for healthier models
Aug 27, 2022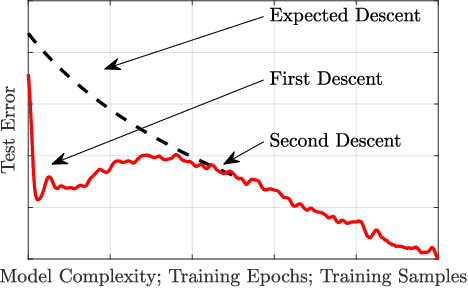
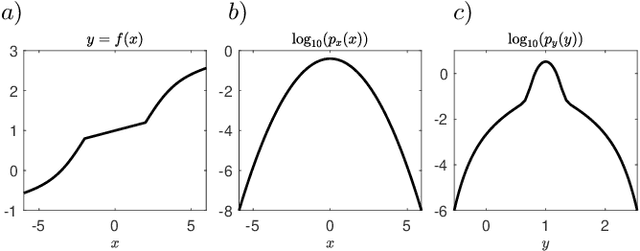
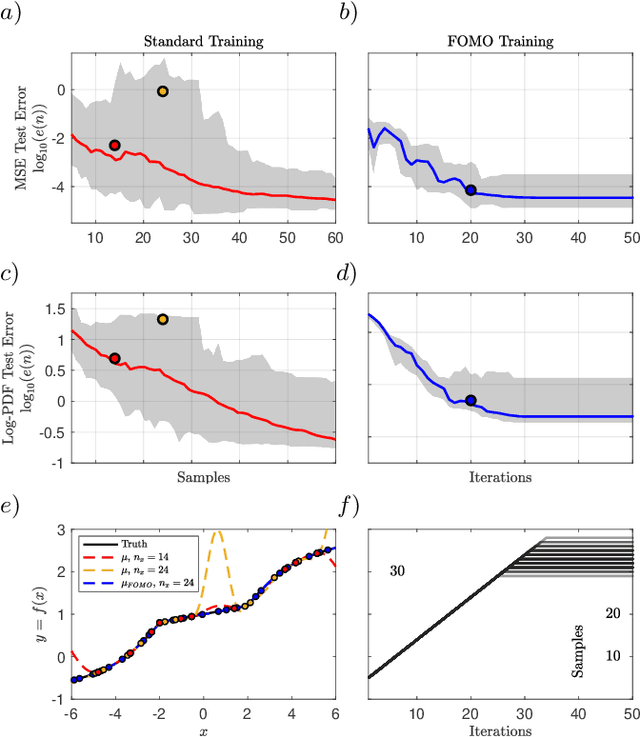
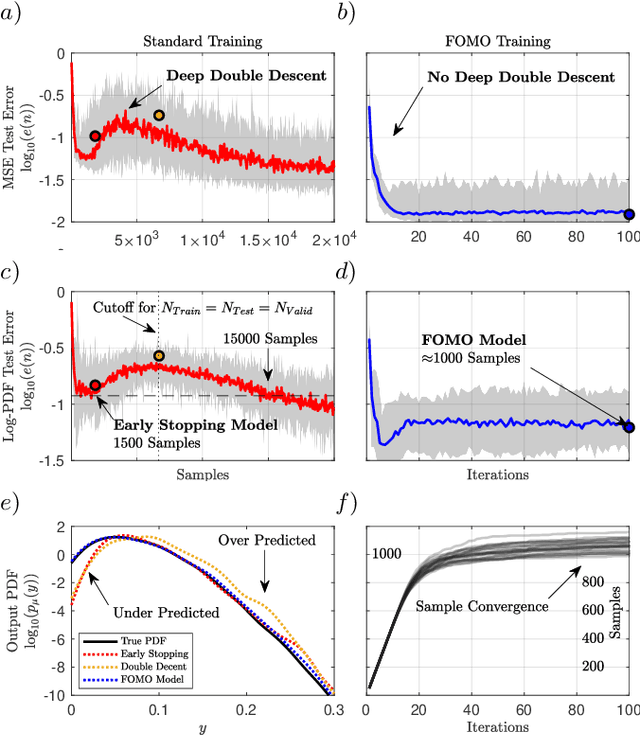
Not all data are equal. Misleading or unnecessary data can critically hinder the accuracy of Machine Learning (ML) models. When data is plentiful, misleading effects can be overcome, but in many real-world applications data is sparse and expensive to acquire. We present a method that substantially reduces the data size necessary to accurately train ML models, potentially opening the door for many new, limited-data applications in ML. Our method extracts the most informative data, while ignoring and omitting data that misleads the ML model to inferior generalization properties. Specifically, the method eliminates the phenomena of "double descent", where more data leads to worse performance. This approach brings several key features to the ML community. Notably, the method naturally converges and removes the traditional need to divide the dataset into training, testing, and validation data. Instead, the selection metric inherently assesses testing error. This ensures that key information is never wasted in testing or validation.
S3I-PointHop: SO(3)-Invariant PointHop for 3D Point Cloud Classification
Feb 22, 2023
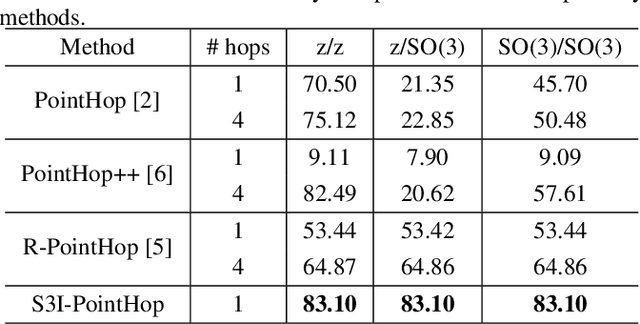
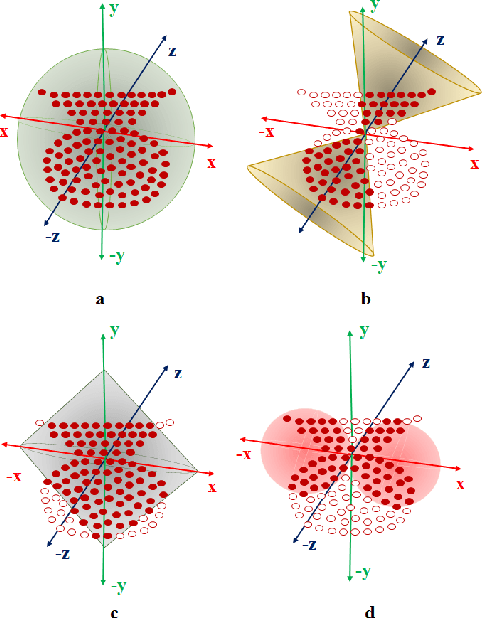
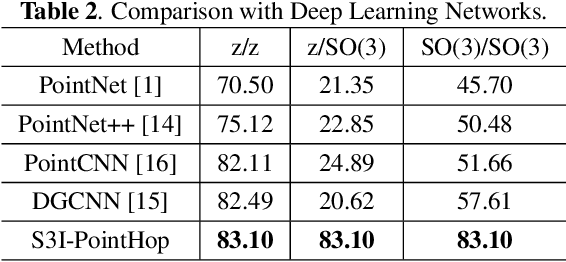
Many point cloud classification methods are developed under the assumption that all point clouds in the dataset are well aligned with the canonical axes so that the 3D Cartesian point coordinates can be employed to learn features. When input point clouds are not aligned, the classification performance drops significantly. In this work, we focus on a mathematically transparent point cloud classification method called PointHop, analyze its reason for failure due to pose variations, and solve the problem by replacing its pose dependent modules with rotation invariant counterparts. The proposed method is named SO(3)-Invariant PointHop (or S3I-PointHop in short). We also significantly simplify the PointHop pipeline using only one single hop along with multiple spatial aggregation techniques. The idea of exploiting more spatial information is novel. Experiments on the ModelNet40 dataset demonstrate the superiority of S3I-PointHop over traditional PointHop-like methods.
A Survey on User Behavior Modeling in Recommender Systems
Feb 22, 2023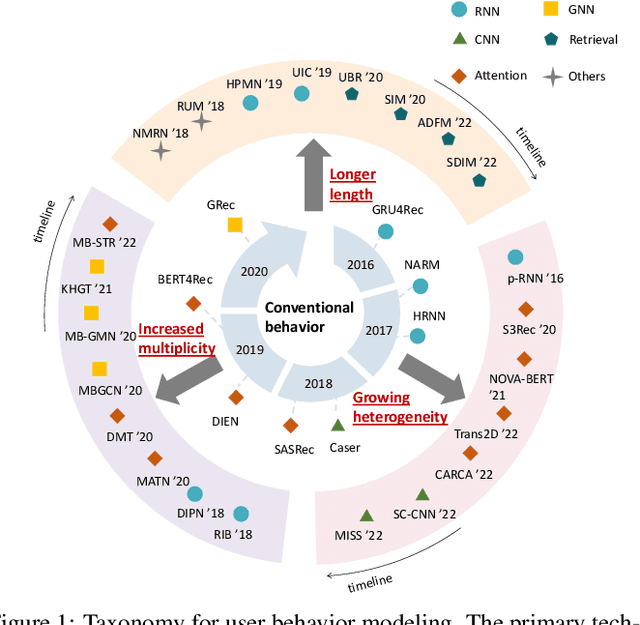

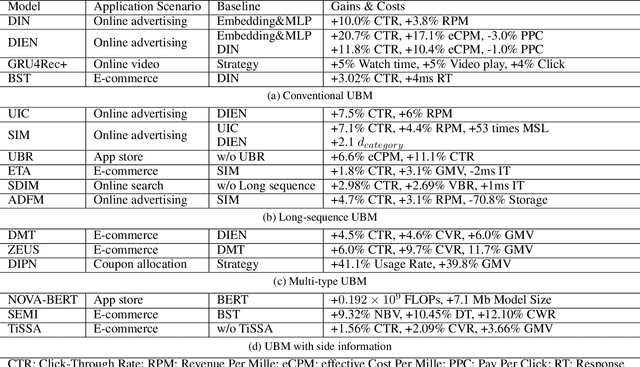
User Behavior Modeling (UBM) plays a critical role in user interest learning, which has been extensively used in recommender systems. Crucial interactive patterns between users and items have been exploited, which brings compelling improvements in many recommendation tasks. In this paper, we attempt to provide a thorough survey of this research topic. We start by reviewing the research background of UBM. Then, we provide a systematic taxonomy of existing UBM research works, which can be categorized into four different directions including Conventional UBM, Long-Sequence UBM, Multi-Type UBM, and UBM with Side Information. Within each direction, representative models and their strengths and weaknesses are comprehensively discussed. Besides, we elaborate on the industrial practices of UBM methods with the hope of providing insights into the application value of existing UBM solutions. Finally, we summarize the survey and discuss the future prospects of this field.
Asymptotically Unbiased Off-Policy Policy Evaluation when Reusing Old Data in Nonstationary Environments
Feb 23, 2023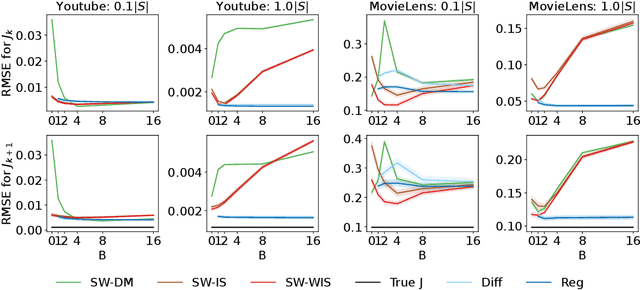
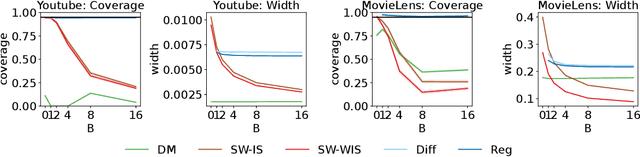
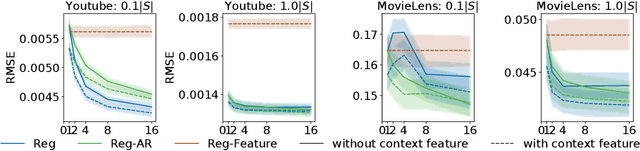
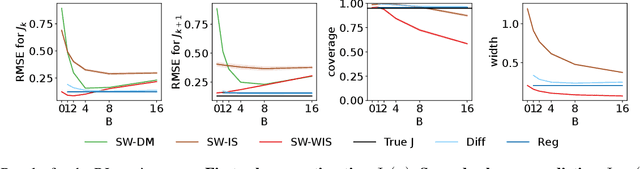
In this work, we consider the off-policy policy evaluation problem for contextual bandits and finite horizon reinforcement learning in the nonstationary setting. Reusing old data is critical for policy evaluation, but existing estimators that reuse old data introduce large bias such that we can not obtain a valid confidence interval. Inspired from a related field called survey sampling, we introduce a variant of the doubly robust (DR) estimator, called the regression-assisted DR estimator, that can incorporate the past data without introducing a large bias. The estimator unifies several existing off-policy policy evaluation methods and improves on them with the use of auxiliary information and a regression approach. We prove that the new estimator is asymptotically unbiased, and provide a consistent variance estimator to a construct a large sample confidence interval. Finally, we empirically show that the new estimator improves estimation for the current and future policy values, and provides a tight and valid interval estimation in several nonstationary recommendation environments.
Combining search strategies to improve performance in the calibration of economic ABMs
Feb 23, 2023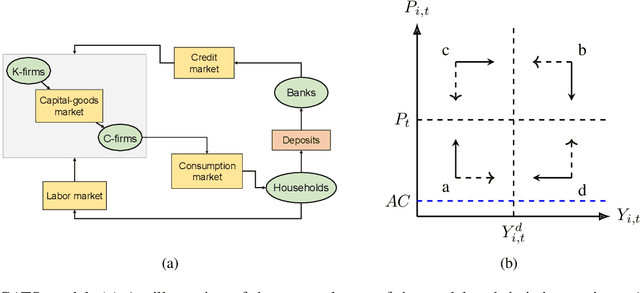

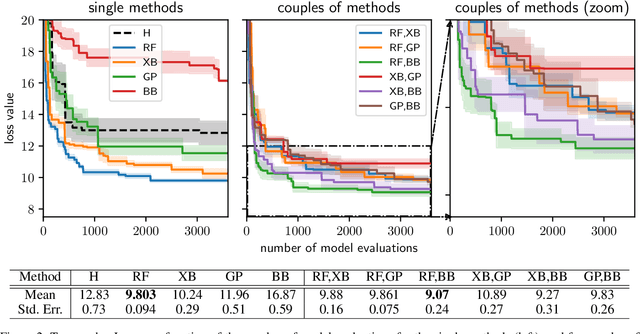
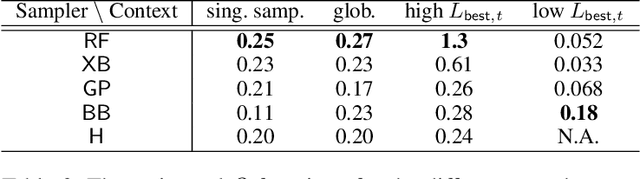
Calibrating agent-based models (ABMs) in economics and finance typically involves a derivative-free search in a very large parameter space. In this work, we benchmark a number of search methods in the calibration of a well-known macroeconomic ABM on real data, and further assess the performance of "mixed strategies" made by combining different methods. We find that methods based on random-forest surrogates are particularly efficient, and that combining search methods generally increases performance since the biases of any single method are mitigated. Moving from these observations, we propose a reinforcement learning (RL) scheme to automatically select and combine search methods on-the-fly during a calibration run. The RL agent keeps exploiting a specific method only as long as this keeps performing well, but explores new strategies when the specific method reaches a performance plateau. The resulting RL search scheme outperforms any other method or method combination tested, and does not rely on any prior information or trial and error procedure.