 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fair Attribute Completion on Graph with Missing Attributes
Mar 02, 2023
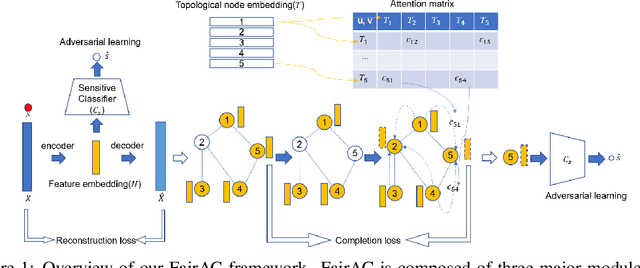
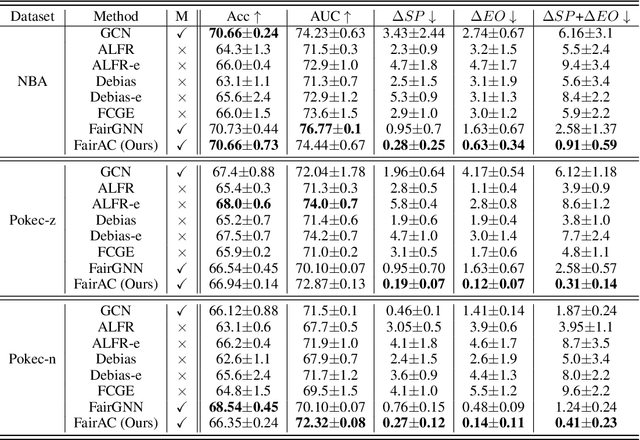
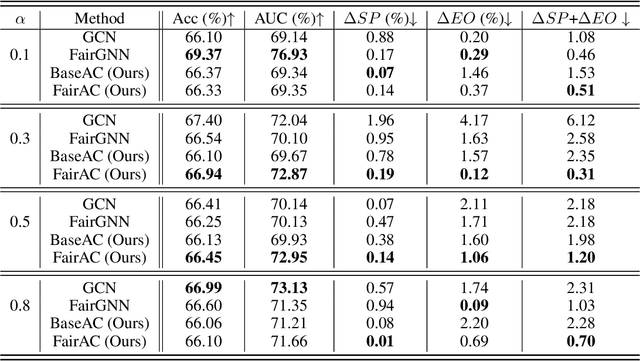
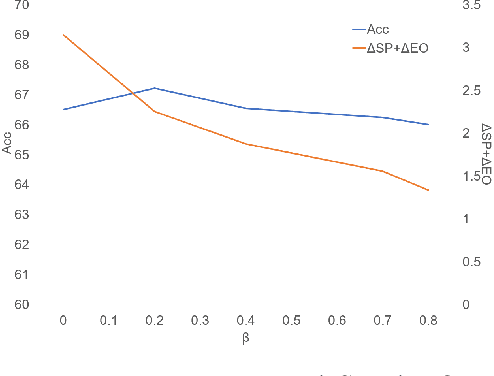
Tackling unfairness in graph learning models is a challenging task, as the unfairness issues on graphs involve both attributes and topological structures. Existing work on fair graph learning simply assumes that attributes of all nodes are available for model training and then makes fair predictions. In practice, however, the attributes of some nodes might not be accessible due to missing data or privacy concerns, which makes fair graph learning even more challenging. In this paper, we propose FairAC, a fair attribute completion method, to complement missing information and learn fair node embeddings for graphs with missing attributes. FairAC adopts an attention mechanism to deal with the attribute missing problem and meanwhile, it mitigates two types of unfairness, i.e., feature unfairness from attributes and topological unfairness due to attribute completion. FairAC can work on various types of homogeneous graphs and generate fair embeddings for them and thus can be applied to most downstream tasks to improve their fairness performance. To our best knowledge, FairAC is the first method that jointly addresses the graph attribution completion and graph unfairness problems. Experimental results on benchmark datasets show that our method achieves better fairness performance with less sacrifice in accuracy, compared with the state-of-the-art methods of fair graph learning. Code is available at: https://github.com/donglgcn/FairAC.
ACL-SPC: Adaptive Closed-Loop system for Self-Supervised Point Cloud Completion
Mar 02, 2023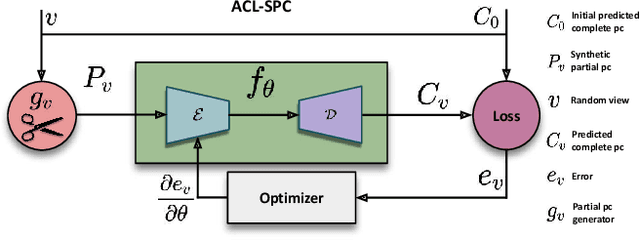

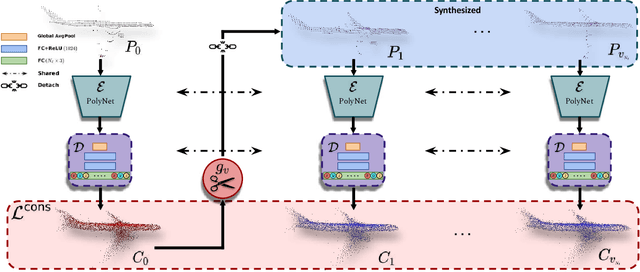
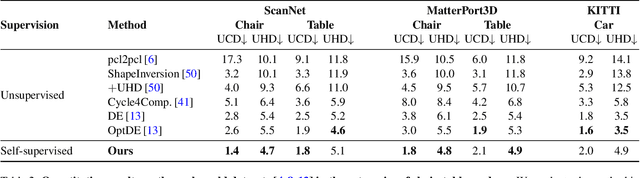
Point cloud completion addresses filling in the missing parts of a partial point cloud obtained from depth sensors and generating a complete point cloud. Although there has been steep progress in the supervised methods on the synthetic point cloud completion task, it is hardly applicable in real-world scenarios due to the domain gap between the synthetic and real-world datasets or the requirement of prior information. To overcome these limitations, we propose a novel self-supervised framework ACL-SPC for point cloud completion to train and test on the same data. ACL-SPC takes a single partial input and attempts to output the complete point cloud using an adaptive closed-loop (ACL) system that enforces the output same for the variation of an input. We evaluate our proposed ACL-SPC on various datasets to prove that it can successfully learn to complete a partial point cloud as the first self-supervised scheme. Results show that our method is comparable with unsupervised methods and achieves superior performance on the real-world dataset compared to the supervised methods trained on the synthetic dataset. Extensive experiments justify the necessity of self-supervised learning and the effectiveness of our proposed method for the real-world point cloud completion task. The code is publicly available from https://github.com/Sangminhong/ACL-SPC_PyTorch
Leveraging Large Text Corpora for End-to-End Speech Summarization
Mar 02, 2023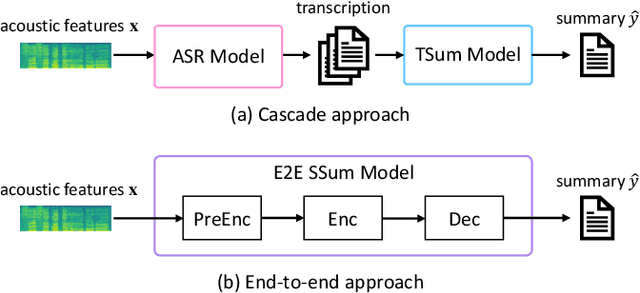

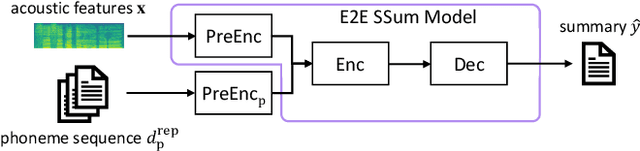

End-to-end speech summarization (E2E SSum) is a technique to directly generate summary sentences from speech. Compared with the cascade approach, which combines automatic speech recognition (ASR) and text summarization models, the E2E approach is more promising because it mitigates ASR errors, incorporates nonverbal information, and simplifies the overall system. However, since collecting a large amount of paired data (i.e., speech and summary) is difficult, the training data is usually insufficient to train a robust E2E SSum system. In this paper, we present two novel methods that leverage a large amount of external text summarization data for E2E SSum training. The first technique is to utilize a text-to-speech (TTS) system to generate synthesized speech, which is used for E2E SSum training with the text summary. The second is a TTS-free method that directly inputs phoneme sequence instead of synthesized speech to the E2E SSum model. Experiments show that our proposed TTS- and phoneme-based methods improve several metrics on the How2 dataset. In particular, our best system outperforms a previous state-of-the-art one by a large margin (i.e., METEOR score improvements of more than 6 points). To the best of our knowledge, this is the first work to use external language resources for E2E SSum. Moreover, we report a detailed analysis of the How2 dataset to confirm the validity of our proposed E2E SSum system.
Energy-Aware Resource Allocation and Trajectory Design for UAV-Enabled ISAC
Feb 20, 2023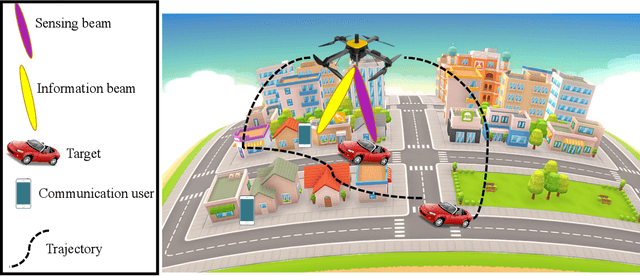
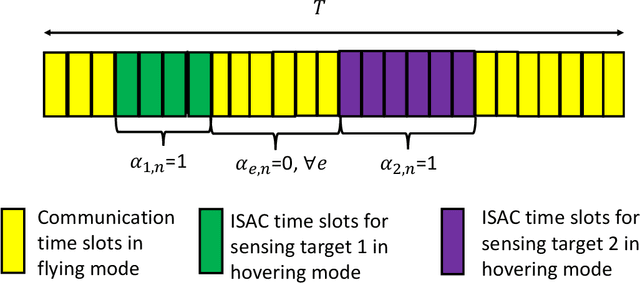
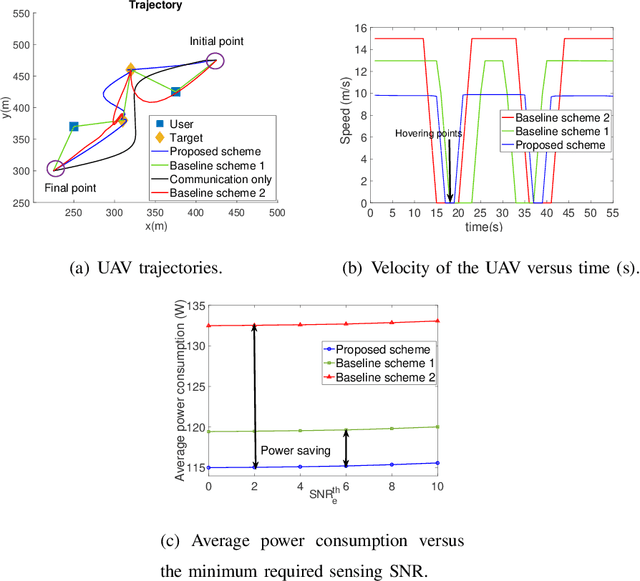

In this paper, we investigate joint resource allocation and trajectory design for multi-user multi-target unmanned aerial vehicle (UAV)-enabled integrated sensing and communication (ISAC). To improve sensing accuracy, the UAV is forced to hover during sensing.~In particular, we jointly optimize the two-dimensional trajectory, velocity, downlink information and sensing beamformers, and sensing indicator to minimize the average power consumption of a fixed-altitude UAV, while considering the quality of service of the communication users and the sensing tasks. To tackle the resulting non-convex mixed integer non-linear program (MINLP), we exploit semidefinite relaxation, the big-M method, and successive convex approximation to develop an alternating optimization-based algorithm.~Our simulation results demonstrate the significant power savings enabled by the proposed scheme compared to two baseline schemes employing heuristic trajectories.
Sharp analysis of EM for learning mixtures of pairwise differences
Feb 20, 2023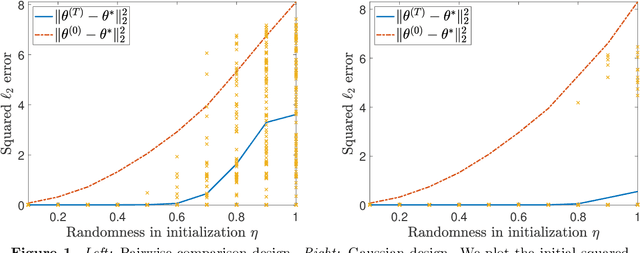
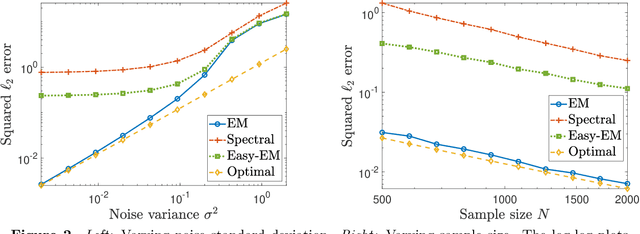
We consider a symmetric mixture of linear regressions with random samples from the pairwise comparison design, which can be seen as a noisy version of a type of Euclidean distance geometry problem. We analyze the expectation-maximization (EM) algorithm locally around the ground truth and establish that the sequence converges linearly, providing an $\ell_\infty$-norm guarantee on the estimation error of the iterates. Furthermore, we show that the limit of the EM sequence achieves the sharp rate of estimation in the $\ell_2$-norm, matching the information-theoretically optimal constant. We also argue through simulation that convergence from a random initialization is much more delicate in this setting, and does not appear to occur in general. Our results show that the EM algorithm can exhibit several unique behaviors when the covariate distribution is suitably structured.
Cross-domain Compositing with Pretrained Diffusion Models
Feb 20, 2023
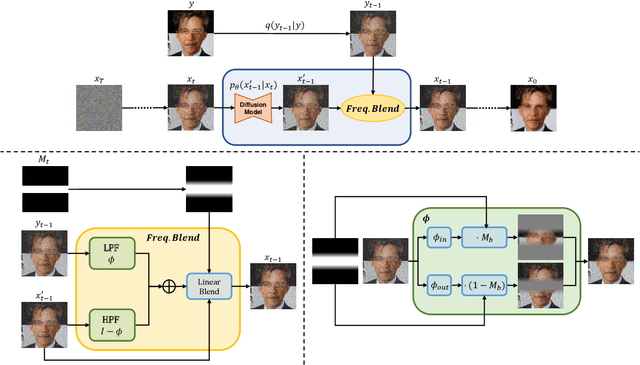


Diffusion models have enabled high-quality, conditional image editing capabilities. We propose to expand their arsenal, and demonstrate that off-the-shelf diffusion models can be used for a wide range of cross-domain compositing tasks. Among numerous others, these include image blending, object immersion, texture-replacement and even CG2Real translation or stylization. We employ a localized, iterative refinement scheme which infuses the injected objects with contextual information derived from the background scene, and enables control over the degree and types of changes the object may undergo. We conduct a range of qualitative and quantitative comparisons to prior work, and exhibit that our method produces higher quality and realistic results without requiring any annotations or training. Finally, we demonstrate how our method may be used for data augmentation of downstream tasks.
Learning the Effects of Physical Actions in a Multi-modal Environment
Feb 03, 2023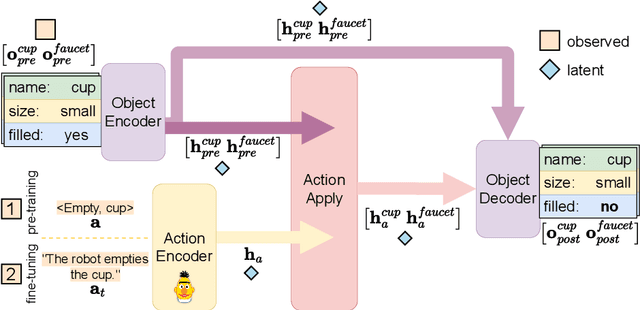
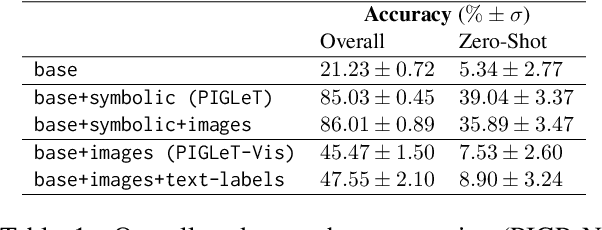
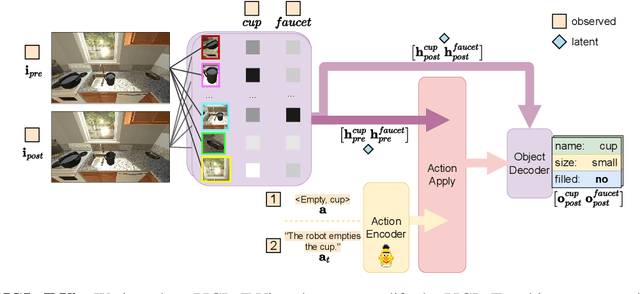
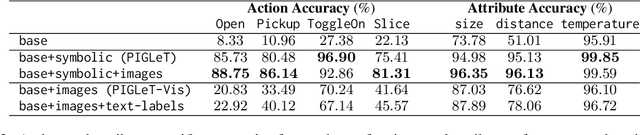
Large Language Models (LLMs) handle physical commonsense information inadequately. As a result of being trained in a disembodied setting, LLMs often fail to predict an action's outcome in a given environment. However, predicting the effects of an action before it is executed is crucial in planning, where coherent sequences of actions are often needed to achieve a goal. Therefore, we introduce the multi-modal task of predicting the outcomes of actions solely from realistic sensory inputs (images and text). Next, we extend an LLM to model latent representations of objects to better predict action outcomes in an environment. We show that multi-modal models can capture physical commonsense when augmented with visual information. Finally, we evaluate our model's performance on novel actions and objects and find that combining modalities help models to generalize and learn physical commonsense reasoning better.
adaPARL: Adaptive Privacy-Aware Reinforcement Learning for Sequential-Decision Making Human-in-the-Loop Systems
Mar 07, 2023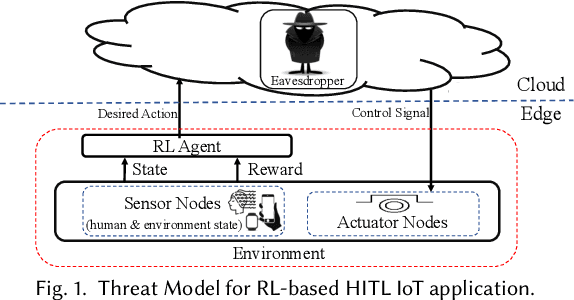
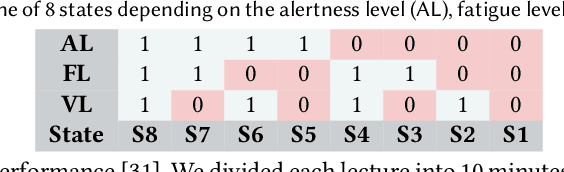
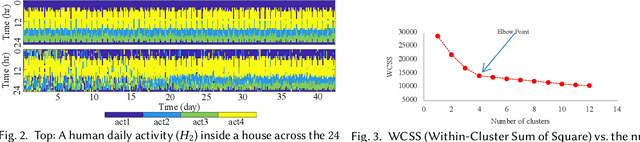
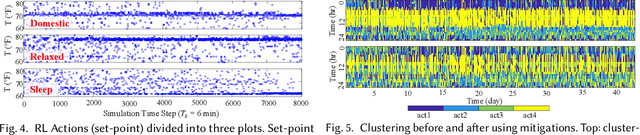
Reinforcement learning (RL) presents numerous benefits compared to rule-based approaches in various applications. Privacy concerns have grown with the widespread use of RL trained with privacy-sensitive data in IoT devices, especially for human-in-the-loop systems. On the one hand, RL methods enhance the user experience by trying to adapt to the highly dynamic nature of humans. On the other hand, trained policies can leak the user's private information. Recent attention has been drawn to designing privacy-aware RL algorithms while maintaining an acceptable system utility. A central challenge in designing privacy-aware RL, especially for human-in-the-loop systems, is that humans have intrinsic variability and their preferences and behavior evolve. The effect of one privacy leak mitigation can be different for the same human or across different humans over time. Hence, we can not design one fixed model for privacy-aware RL that fits all. To that end, we propose adaPARL, an adaptive approach for privacy-aware RL, especially for human-in-the-loop IoT systems. adaPARL provides a personalized privacy-utility trade-off depending on human behavior and preference. We validate the proposed adaPARL on two IoT applications, namely (i) Human-in-the-Loop Smart Home and (ii) Human-in-the-Loop Virtual Reality (VR) Smart Classroom. Results obtained on these two applications validate the generality of adaPARL and its ability to provide a personalized privacy-utility trade-off. On average, for the first application, adaPARL improves the utility by $57\%$ over the baseline and by $43\%$ over randomization. adaPARL also reduces the privacy leak by $23\%$ on average. For the second application, adaPARL decreases the privacy leak to $44\%$ before the utility drops by $15\%$.
Semantic Segmentation of Urban Textured Meshes Through Point Sampling
Feb 21, 2023
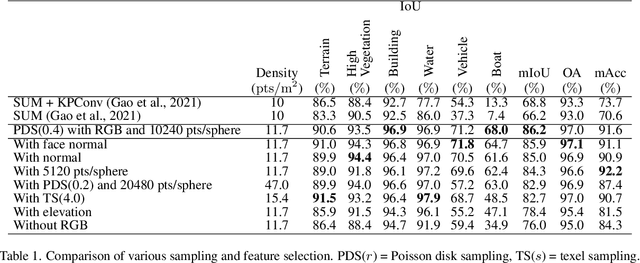


Textured meshes are becoming an increasingly popular representation combining the 3D geometry and radiometry of real scenes. However, semantic segmentation algorithms for urban mesh have been little investigated and do not exploit all radiometric information. To address this problem, we adopt an approach consisting in sampling a point cloud from the textured mesh, then using a point cloud semantic segmentation algorithm on this cloud, and finally using the obtained semantic to segment the initial mesh. In this paper, we study the influence of different parameters such as the sampling method, the density of the extracted cloud, the features selected (color, normal, elevation) as well as the number of points used at each training period. Our result outperforms the state-of-the-art on the SUM dataset, earning about 4 points in OA and 18 points in mIoU.
* 9 pages, 6 figures, conference, presented at XXIV ISPRS Congress
Sedition Hunters: A Quantitative Study of the Crowdsourced Investigation into the 2021 U.S. Capitol Attack
Feb 21, 2023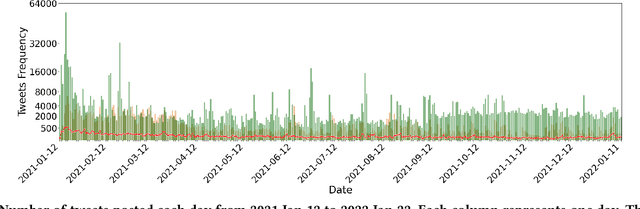
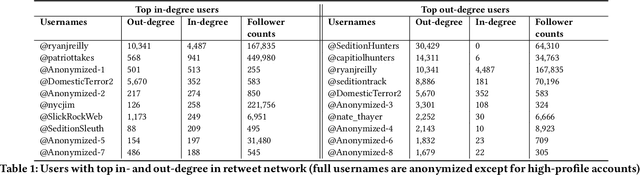

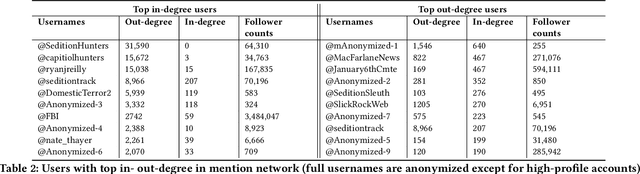
Social media platforms have enabled extremists to organize violent events, such as the 2021 U.S. Capitol Attack. Simultaneously, these platforms enable professional investigators and amateur sleuths to collaboratively collect and identify imagery of suspects with the goal of holding them accountable for their actions. Through a case study of Sedition Hunters, a Twitter community whose goal is to identify individuals who participated in the 2021 U.S. Capitol Attack, we explore what are the main topics or targets of the community, who participates in the community, and how. Using topic modeling, we find that information sharing is the main focus of the community. We also note an increase in awareness of privacy concerns. Furthermore, using social network analysis, we show how some participants played important roles in the community. Finally, we discuss implications for the content and structure of online crowdsourced investigations.