 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A path in regression Random Forest looking for spatial dependence: a taxonomy and a systematic review
Mar 08, 2023
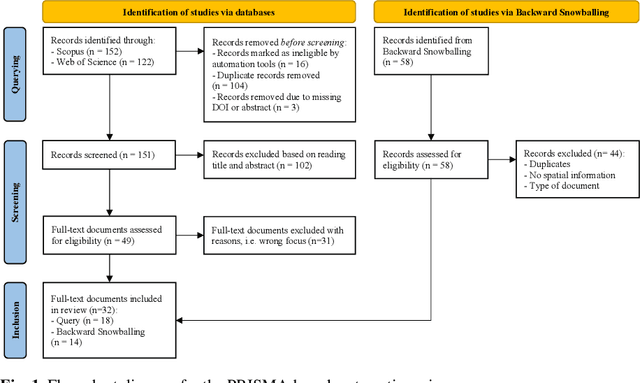
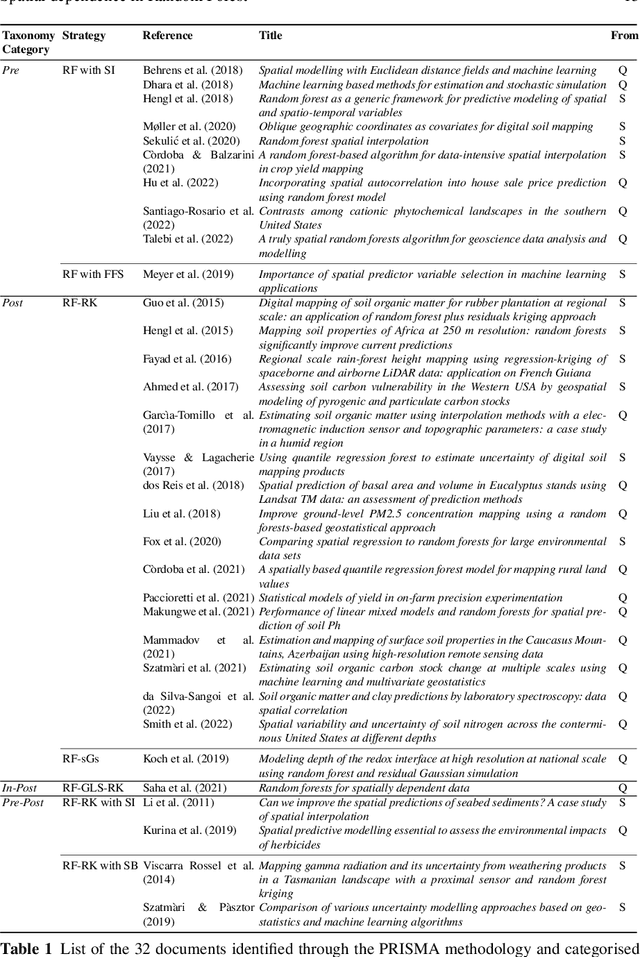
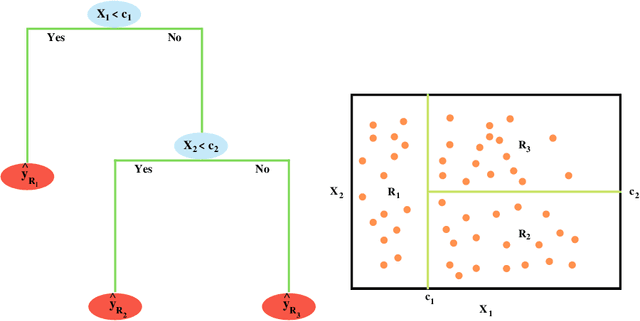
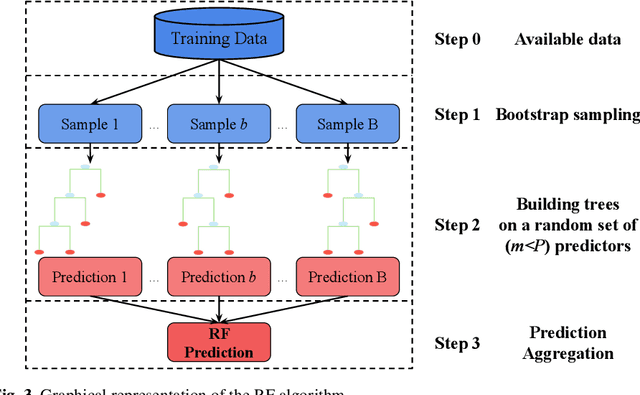
Random Forest (RF) is a well-known data-driven algorithm applied in several fields thanks to its flexibility in modeling the relationship between the response variable and the predictors, also in case of strong non-linearities. In environmental applications, it often occurs that the phenomenon of interest may present spatial and/or temporal dependence that is not taken explicitly into account by RF in its standard version. In this work, we propose a taxonomy to classify strategies according to when (Pre-, In- and/or Post-processing) they try to include the spatial information into regression RF. Moreover, we provide a systematic review and classify the most recent strategies adopted to "adjust" regression RF to spatially dependent data, based on the criteria provided by the Preferred Reporting Items for Systematic reviews and Meta-Analysis (PRISMA). The latter consists of a reproducible methodology for collecting and processing existing literature on a specified topic from different sources. PRISMA starts with a query and ends with a set of scientific documents to review: we performed an online query on the 25$^{th}$ October 2022 and, in the end, 32 documents were considered for review. The employed methodological strategies and the application fields considered in the 32 scientific documents are described and discussed.
MOREA: a GPU-accelerated Evolutionary Algorithm for Multi-Objective Deformable Registration of 3D Medical Images
Mar 08, 2023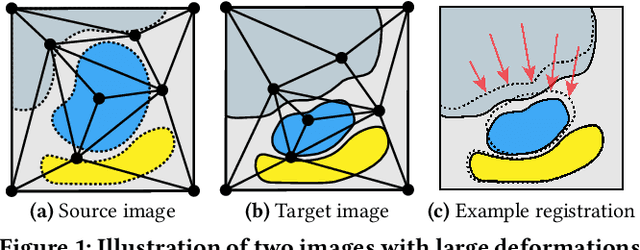

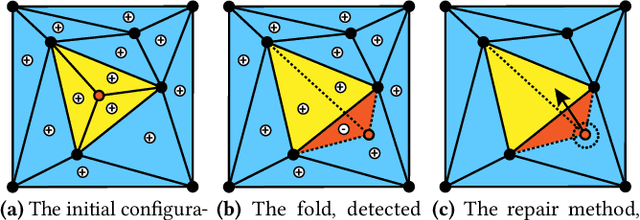
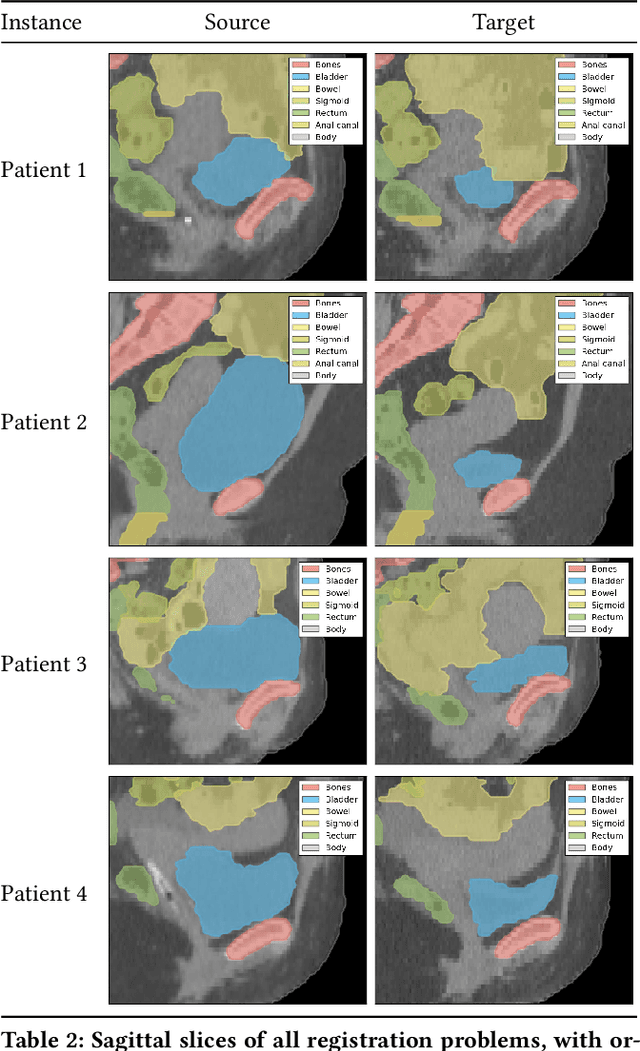
Finding a realistic deformation that transforms one image into another, in case large deformations are required, is considered a key challenge in medical image analysis. Having a proper image registration approach to achieve this could unleash a number of applications requiring information to be transferred between images. Clinical adoption is currently hampered by many existing methods requiring extensive configuration effort before each use, or not being able to (realistically) capture large deformations. A recent multi-objective approach that uses the Multi-Objective Real-Valued Gene-pool Optimal Mixing Evolutionary Algorithm (MO-RV-GOMEA) and a dual-dynamic mesh transformation model has shown promise, exposing the trade-offs inherent to image registration problems and modeling large deformations in 2D. This work builds on this promise and introduces MOREA: the first evolutionary algorithm-based multi-objective approach to deformable registration of 3D images capable of tackling large deformations. MOREA includes a 3D biomechanical mesh model for physical plausibility and is fully GPU-accelerated. We compare MOREA to two state-of-the-art approaches on abdominal CT scans of 4 cervical cancer patients, with the latter two approaches configured for the best results per patient. Without requiring per-patient configuration, MOREA significantly outperforms these approaches on 3 of the 4 patients that represent the most difficult cases.
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
Mar 08, 2023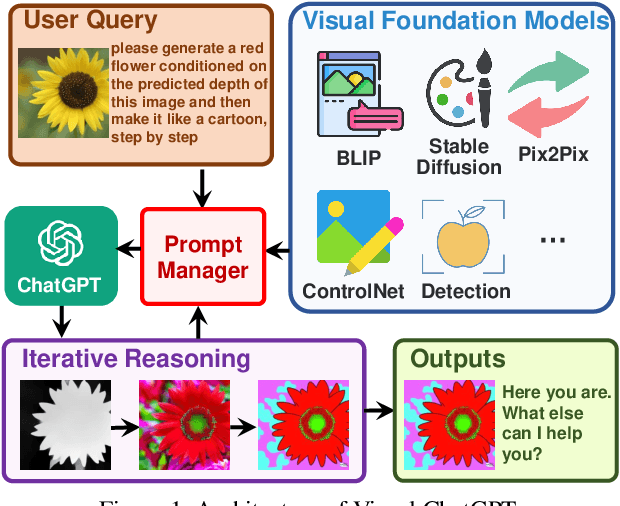
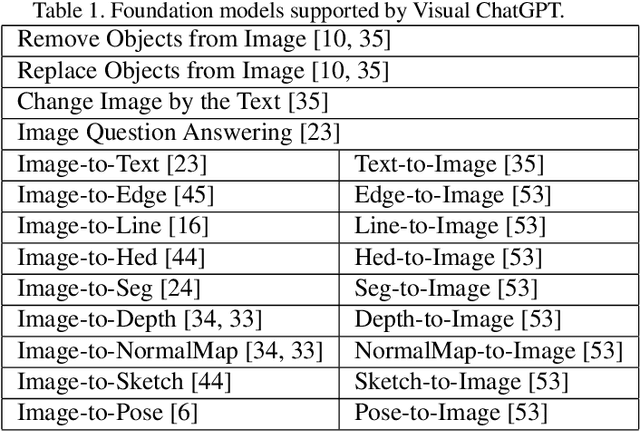
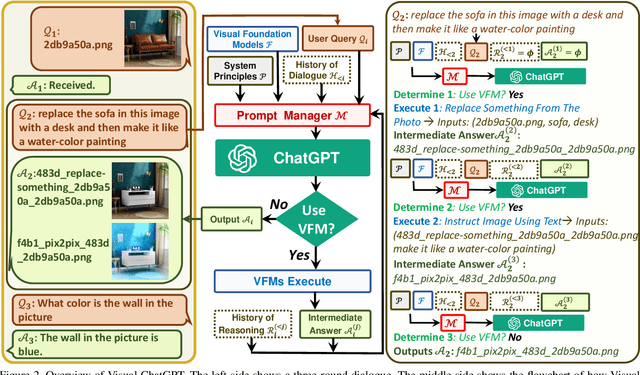
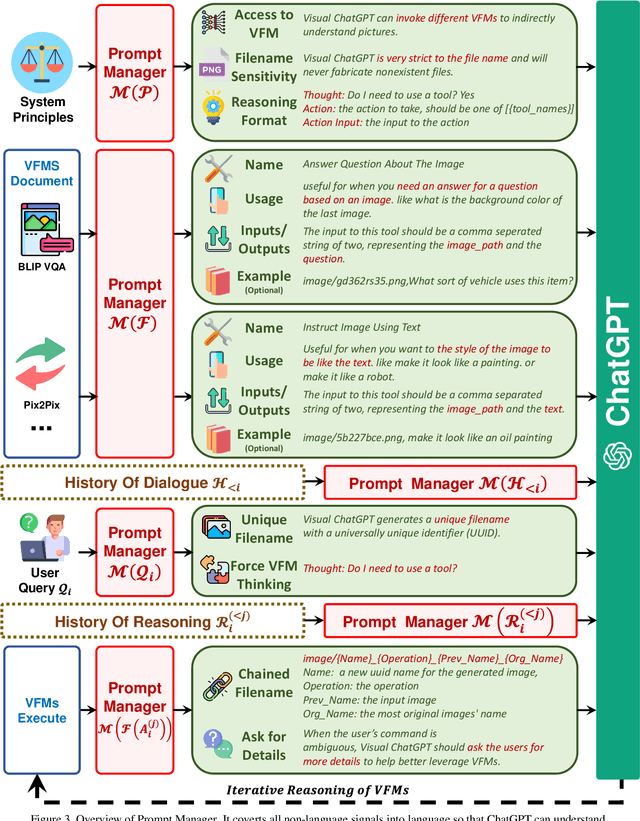
ChatGPT is attracting a cross-field interest as it provides a language interface with remarkable conversational competency and reasoning capabilities across many domains. However, since ChatGPT is trained with languages, it is currently not capable of processing or generating images from the visual world. At the same time, Visual Foundation Models, such as Visual Transformers or Stable Diffusion, although showing great visual understanding and generation capabilities, they are only experts on specific tasks with one-round fixed inputs and outputs. To this end, We build a system called \textbf{Visual ChatGPT}, incorporating different Visual Foundation Models, to enable the user to interact with ChatGPT by 1) sending and receiving not only languages but also images 2) providing complex visual questions or visual editing instructions that require the collaboration of multiple AI models with multi-steps. 3) providing feedback and asking for corrected results. We design a series of prompts to inject the visual model information into ChatGPT, considering models of multiple inputs/outputs and models that require visual feedback. Experiments show that Visual ChatGPT opens the door to investigating the visual roles of ChatGPT with the help of Visual Foundation Models. Our system is publicly available at \url{https://github.com/microsoft/visual-chatgpt}.
Time Series Forecasting via Semi-Asymmetric Convolutional Architecture with Global Atrous Sliding Window
Jan 31, 2023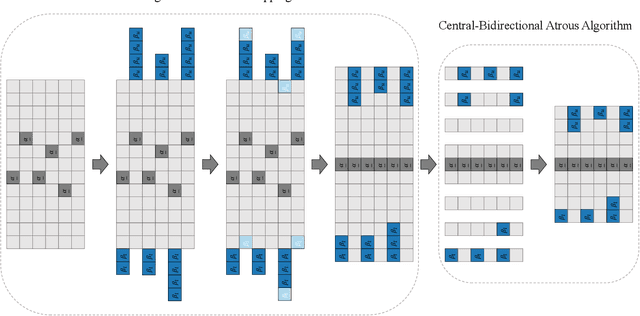
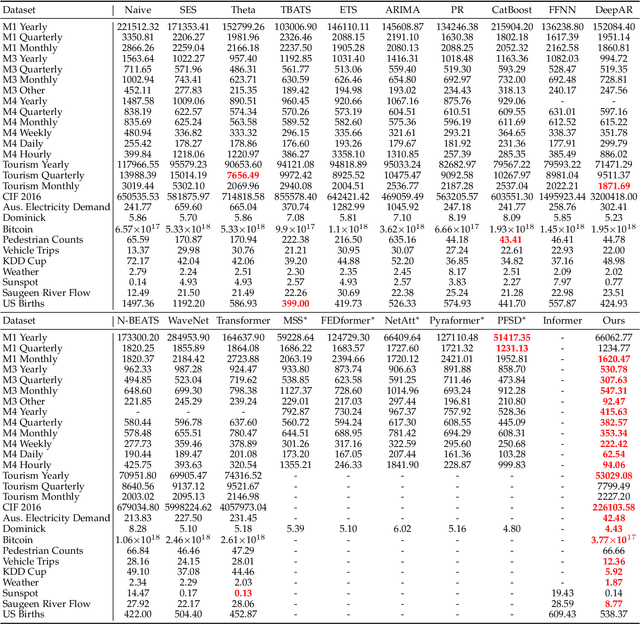
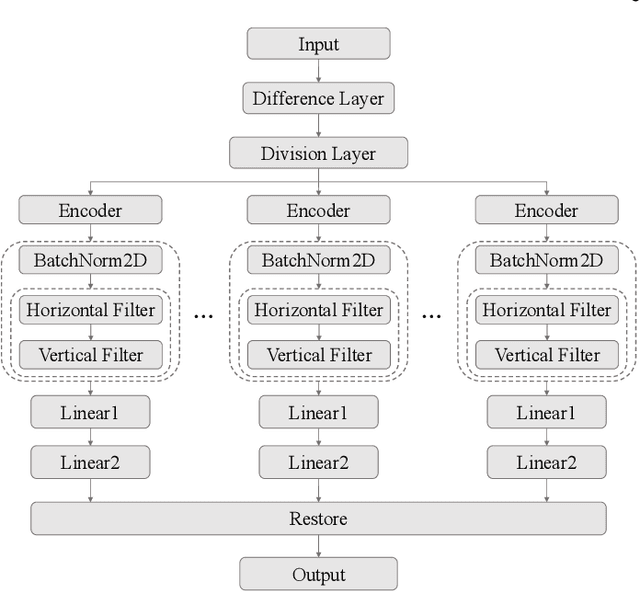
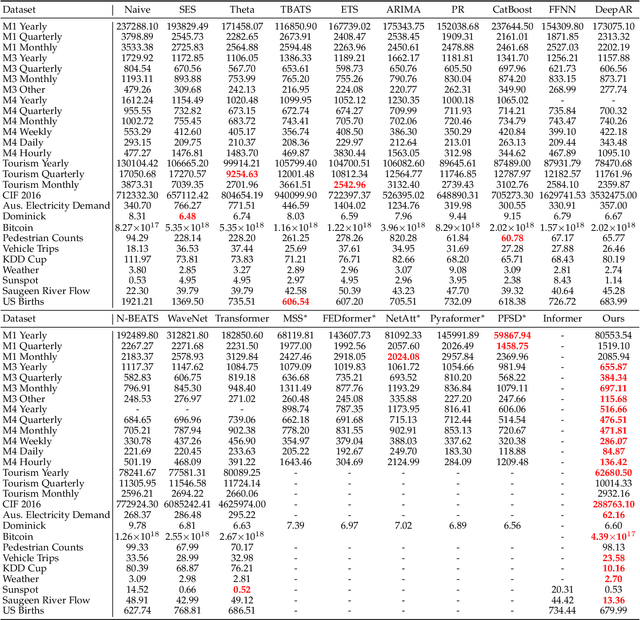
The proposed method in this paper is designed to address the problem of time series forecasting. Although some exquisitely designed models achieve excellent prediction performances, how to extract more useful information and make accurate predictions is still an open issue. Most of modern models only focus on a short range of information, which are fatal for problems such as time series forecasting which needs to capture long-term information characteristics. As a result, the main concern of this work is to further mine relationship between local and global information contained in time series to produce more precise predictions. In this paper, to satisfactorily realize the purpose, we make three main contributions that are experimentally verified to have performance advantages. Firstly, original time series is transformed into difference sequence which serves as input to the proposed model. And secondly, we introduce the global atrous sliding window into the forecasting model which references the concept of fuzzy time series to associate relevant global information with temporal data within a time period and utilizes central-bidirectional atrous algorithm to capture underlying-related features to ensure validity and consistency of captured data. Thirdly, a variation of widely-used asymmetric convolution which is called semi-asymmetric convolution is devised to more flexibly extract relationships in adjacent elements and corresponding associated global features with adjustable ranges of convolution on vertical and horizontal directions. The proposed model in this paper achieves state-of-the-art on most of time series datasets provided compared with competitive modern models.
LiQuiD-MIMO Radar: Distributed MIMO Radar with Low-Bit Quantization
Feb 16, 2023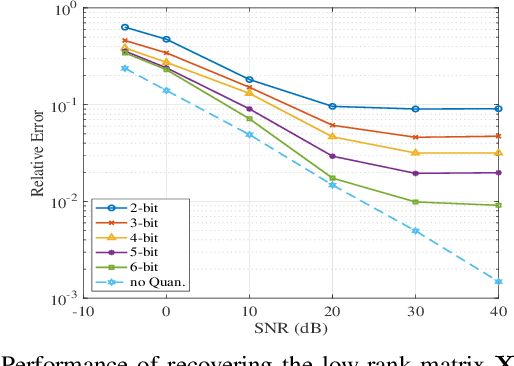
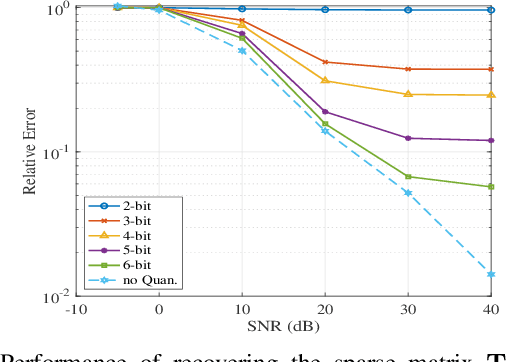
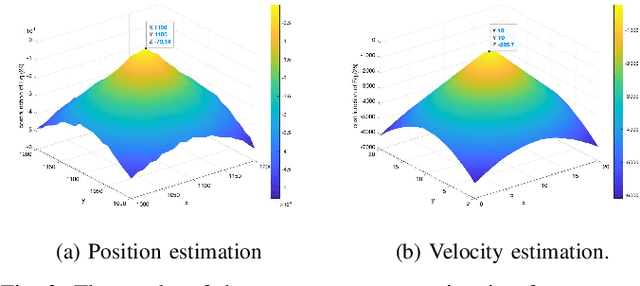
Distributed MIMO radar is known to achieve superior sensing performance by employing widely separated antennas. However, it is challenging to implement a low-complexity distributed MIMO radar due to the complex operations at both the receivers and the fusion center. This work proposed a low-bit quantized distributed MIMO (LiQuiD-MIMO) radar to significantly reduce the burden of signal acquisition and data transmission. In the LiQuiD-MIMO radar, the widely-separated receivers are restricted to operating with low-resolution ADCs and deliver the low-bit quantized data to the fusion center. At the fusion center, the induced quantization distortion is explicitly compensated via digital processing. By exploiting the inherent structure of our problem, a quantized version of the robust principal component analysis (RPCA) problem is formulated to simultaneously recover the low-rank target information matrices as well as the sparse data transmission errors. The least squares-based method is then employed to estimate the targets' positions and velocities from the recovered target information matrices. Numerical experiments demonstrate that the proposed LiQuiD-MIMO radar, configured with the developed algorithm, can achieve accurate target parameter estimation.
Redesigning Electronic Health Record Systems to Support Developing Countries
Jan 31, 2023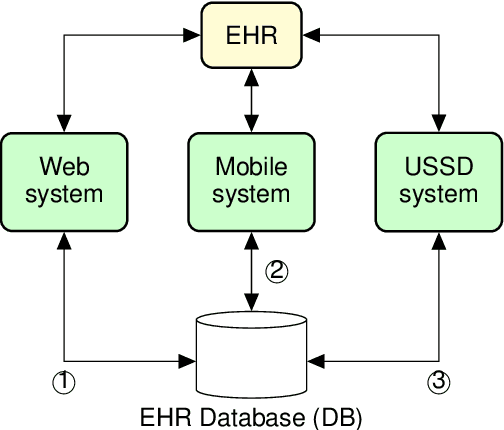
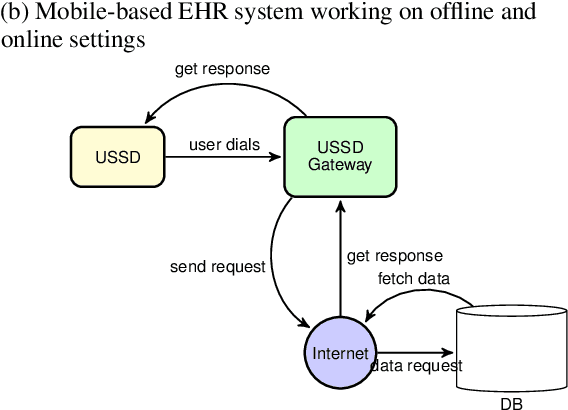
Electronic Health Record (EHR) has become an essential tool in the healthcare ecosystem, providing authorized clinicians with patients' health-related information for better treatment. While most developed countries are taking advantage of EHRs to improve their healthcare system, it remains challenging in developing countries to support clinical decision-making and public health using a computerized patient healthcare information system. This paper proposes a novel EHR architecture suitable for developing countries--an architecture that fosters inclusion and provides solutions tailored to all social classes and socioeconomic statuses. Our architecture foresees an internet-free (offline) solution to allow medical transactions between healthcare organizations, and the storage of EHRs in geographically underserved and rural areas. Moreover, we discuss how artificial intelligence can leverage anonymous health-related information to enable better public health policy and surveillance.
Performance is not enough: a story of the Rashomon's quartet
Feb 26, 2023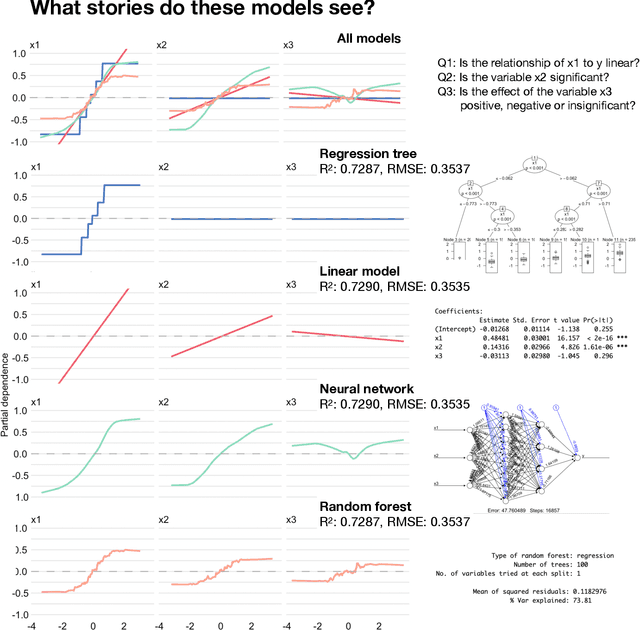
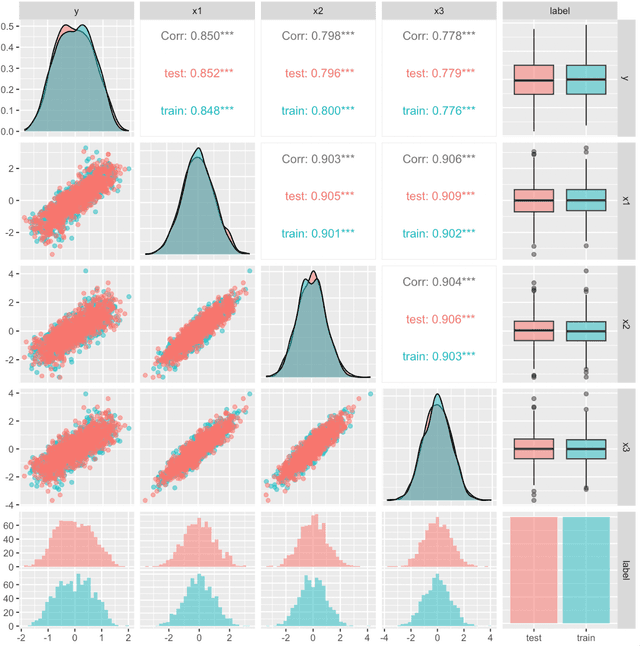
Predictive modelling is often reduced to finding a single best model that optimises a selected model quality criterion. But what if the second best model describes the data equally well but in a completely different way? What about the third best? Following the Anscombe's quartet point, in this paper, we present a synthetic dataset for which four models from different classes have practically identical predictive performance. But, visualisation of these models reveals that they describe this dataset in very different ways. We believe that this simple illustration will encourage data scientists to visualise predictive models in order to better understand them. Explanatory analysis of the set of equally good models can provide valuable information and we need to develop more techniques for this task.
KGTrust: Evaluating Trustworthiness of SIoT via Knowledge Enhanced Graph Neural Networks
Feb 22, 2023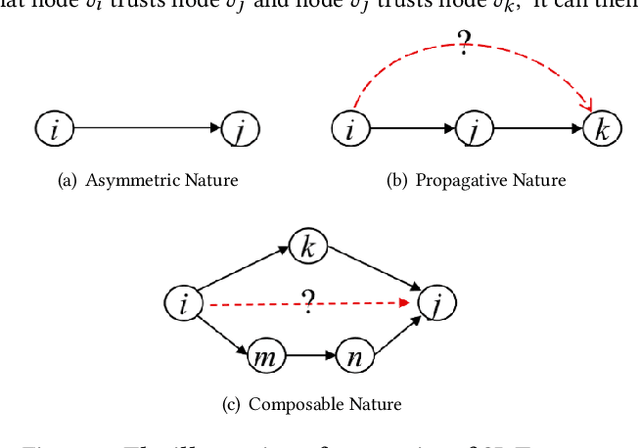
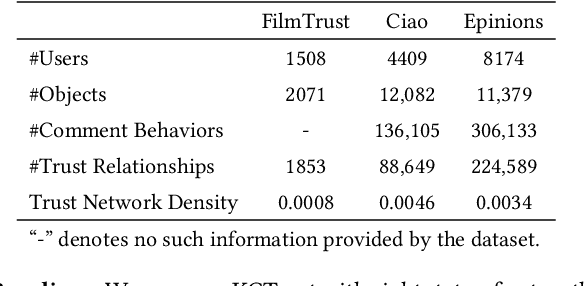
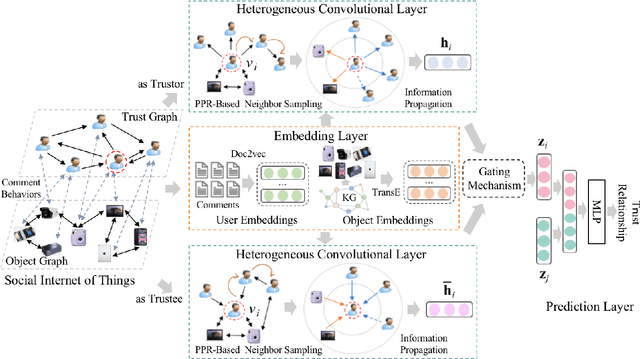
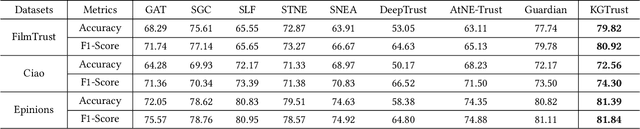
Social Internet of Things (SIoT), a promising and emerging paradigm that injects the notion of social networking into smart objects (i.e., things), paving the way for the next generation of Internet of Things. However, due to the risks and uncertainty, a crucial and urgent problem to be settled is establishing reliable relationships within SIoT, that is, trust evaluation. Graph neural networks for trust evaluation typically adopt a straightforward way such as one-hot or node2vec to comprehend node characteristics, which ignores the valuable semantic knowledge attached to nodes. Moreover, the underlying structure of SIoT is usually complex, including both the heterogeneous graph structure and pairwise trust relationships, which renders hard to preserve the properties of SIoT trust during information propagation. To address these aforementioned problems, we propose a novel knowledge-enhanced graph neural network (KGTrust) for better trust evaluation in SIoT. Specifically, we first extract useful knowledge from users' comment behaviors and external structured triples related to object descriptions, in order to gain a deeper insight into the semantics of users and objects. Furthermore, we introduce a discriminative convolutional layer that utilizes heterogeneous graph structure, node semantics, and augmented trust relationships to learn node embeddings from the perspective of a user as a trustor or a trustee, effectively capturing multi-aspect properties of SIoT trust during information propagation. Finally, a trust prediction layer is developed to estimate the trust relationships between pairwise nodes. Extensive experiments on three public datasets illustrate the superior performance of KGTrust over state-of-the-art methods.
BB-GCN: A Bi-modal Bridged Graph Convolutional Network for Multi-label Chest X-Ray Recognition
Feb 22, 2023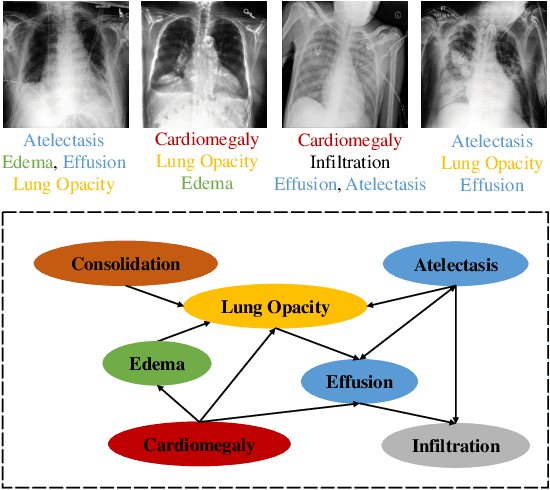

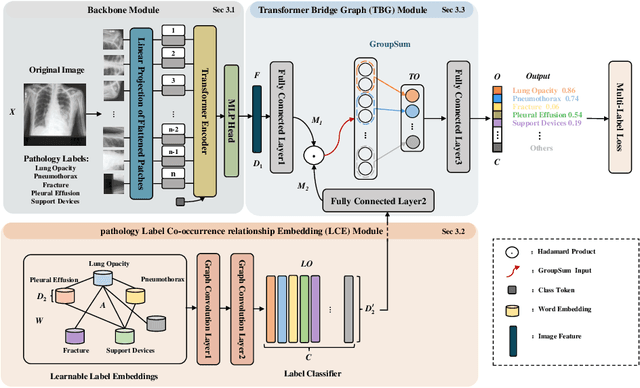
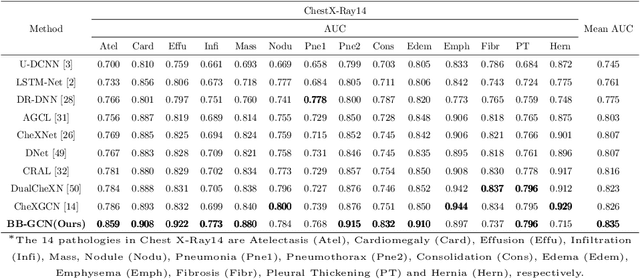
Multi-label chest X-ray (CXR) recognition involves simultaneously diagnosing and identifying multiple labels for different pathologies. Since pathological labels have rich information about their relationship to each other, modeling the co-occurrence dependencies between pathological labels is essential to improve recognition performance. However, previous methods rely on state variable coding and attention mechanisms-oriented to model local label information, and lack learning of global co-occurrence relationships between labels. Furthermore, these methods roughly integrate image features and label embedding, ignoring the alignment and compactness problems in cross-modal vector fusion.To solve these problems, a Bi-modal Bridged Graph Convolutional Network (BB-GCN) model is proposed. This model mainly consists of a backbone module, a pathology Label Co-occurrence relationship Embedding (LCE) module, and a Transformer Bridge Graph (TBG) module. Specifically, the backbone module obtains image visual feature representation. The LCE module utilizes a graph to model the global co-occurrence relationship between multiple labels and employs graph convolutional networks for learning inference. The TBG module bridges the cross-modal vectors more compactly and efficiently through the GroupSum method.We have evaluated the effectiveness of the proposed BB-GCN in two large-scale CXR datasets (ChestX-Ray14 and CheXpert). Our model achieved state-of-the-art performance: the mean AUC scores for the 14 pathologies were 0.835 and 0.813, respectively.The proposed LCE and TBG modules can jointly effectively improve the recognition performance of BB-GCN. Our model also achieves satisfactory results in multi-label chest X-ray recognition and exhibits highly competitive generalization performance.
An Efficient Tester-Learner for Halfspaces
Mar 13, 2023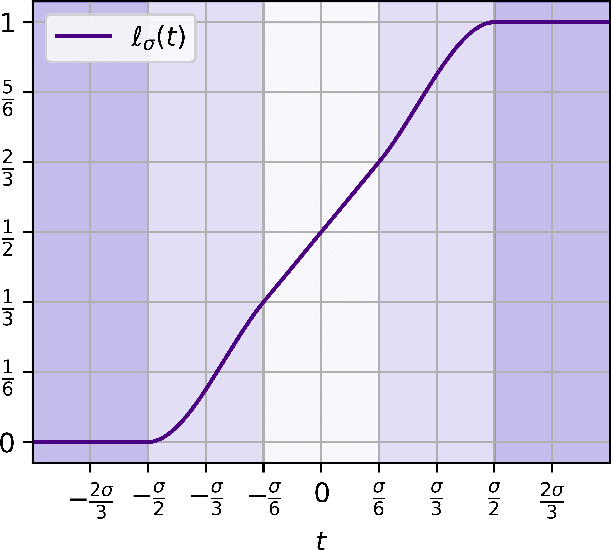
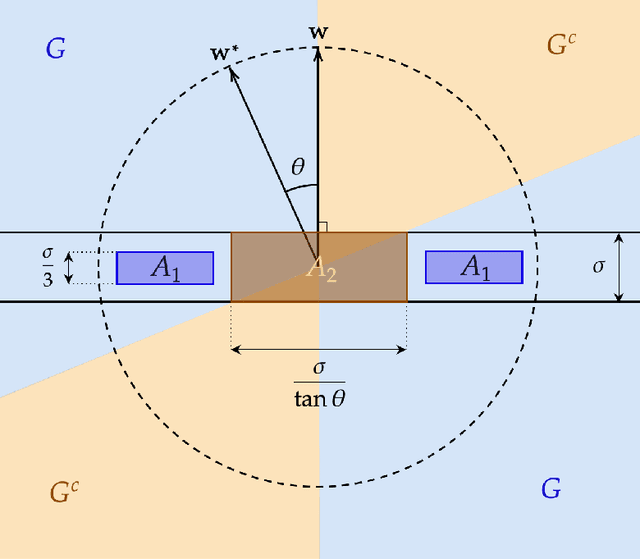
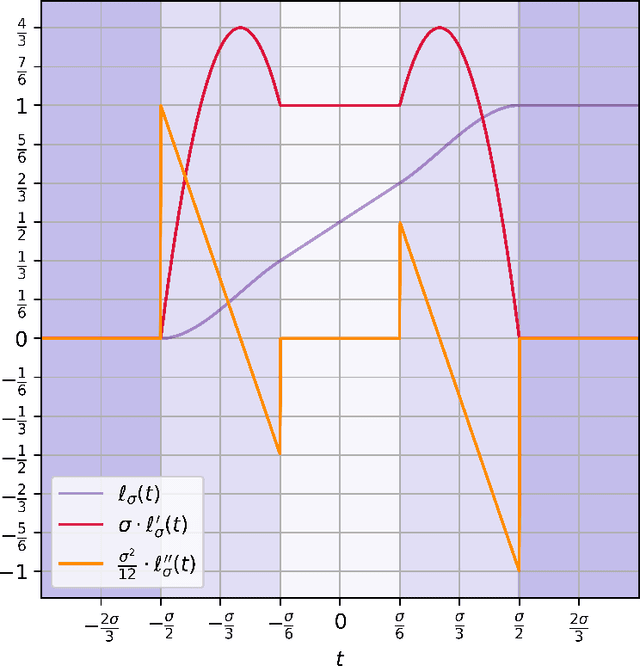
We give the first efficient algorithm for learning halfspaces in the testable learning model recently defined by Rubinfeld and Vasilyan (2023). In this model, a learner certifies that the accuracy of its output hypothesis is near optimal whenever the training set passes an associated test, and training sets drawn from some target distribution -- e.g., the Gaussian -- must pass the test. This model is more challenging than distribution-specific agnostic or Massart noise models where the learner is allowed to fail arbitrarily if the distributional assumption does not hold. We consider the setting where the target distribution is Gaussian (or more generally any strongly log-concave distribution) in $d$ dimensions and the noise model is either Massart or adversarial (agnostic). For Massart noise, our tester-learner runs in polynomial time and outputs a hypothesis with (information-theoretically optimal) error $\mathsf{opt} + \epsilon$ for any strongly log-concave target distribution. For adversarial noise, our tester-learner obtains error $O(\mathsf{opt}) + \epsilon$ in polynomial time when the target distribution is Gaussian; for strongly log-concave distributions, we obtain $\tilde{O}(\mathsf{opt}) + \epsilon$ in quasipolynomial time. Prior work on testable learning ignores the labels in the training set and checks that the empirical moments of the covariates are close to the moments of the base distribution. Here we develop new tests of independent interest that make critical use of the labels and combine them with the moment-matching approach of Gollakota et al. (2023). This enables us to simulate a variant of the algorithm of Diakonikolas et al. (2020) for learning noisy halfspaces using nonconvex SGD but in the testable learning setting.