 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Tiny Time-series Transformer: Low-latency High-throughput Classification of Astronomical Transients using Deep Model Compression
Mar 15, 2023
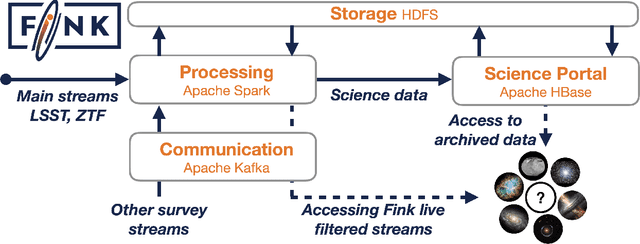
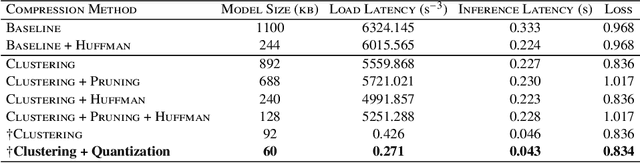
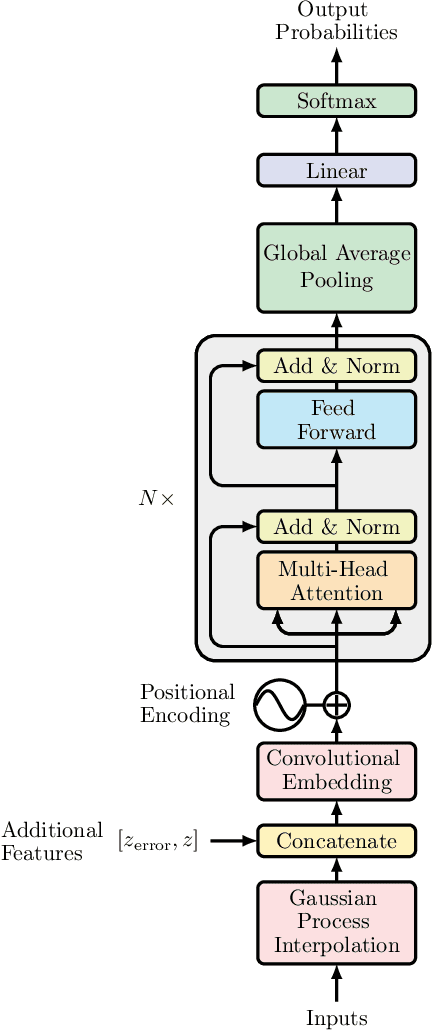
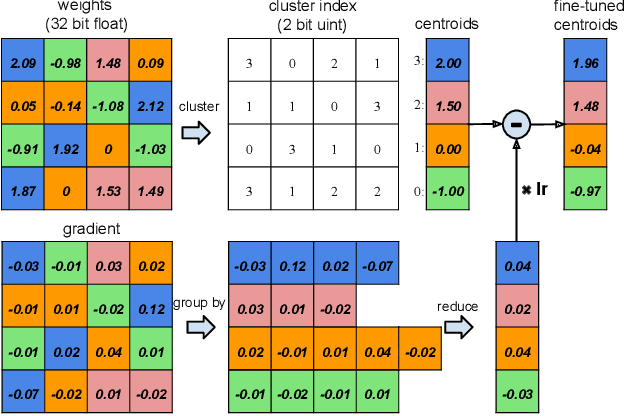
A new golden age in astronomy is upon us, dominated by data. Large astronomical surveys are broadcasting unprecedented rates of information, demanding machine learning as a critical component in modern scientific pipelines to handle the deluge of data. The upcoming Legacy Survey of Space and Time (LSST) of the Vera C. Rubin Observatory will raise the big-data bar for time-domain astronomy, with an expected 10 million alerts per-night, and generating many petabytes of data over the lifetime of the survey. Fast and efficient classification algorithms that can operate in real-time, yet robustly and accurately, are needed for time-critical events where additional resources can be sought for follow-up analyses. In order to handle such data, state-of-the-art deep learning architectures coupled with tools that leverage modern hardware accelerators are essential. We showcase how the use of modern deep compression methods can achieve a $18\times$ reduction in model size, whilst preserving classification performance. We also show that in addition to the deep compression techniques, careful choice of file formats can improve inference latency, and thereby throughput of alerts, on the order of $8\times$ for local processing, and $5\times$ in a live production setting. To test this in a live setting, we deploy this optimised version of the original time-series transformer, t2, into the community alert broking system of FINK on real Zwicky Transient Facility (ZTF) alert data, and compare throughput performance with other science modules that exist in FINK. The results shown herein emphasise the time-series transformer's suitability for real-time classification at LSST scale, and beyond, and introduce deep model compression as a fundamental tool for improving deploy-ability and scalable inference of deep learning models for transient classification.
Graph Feedback via Reduction to Regression
Feb 17, 2023


When feedback is partial, leveraging all available information is critical to minimizing data requirements. Graph feedback, which interpolates between the supervised and bandit regimes, has been extensively studied; but the mature theory is grounded in impractical algorithms. We present and analyze an approach to contextual bandits with graph feedback based upon reduction to regression. The resulting algorithms are practical and achieve known minimax rates.
PriSTI: A Conditional Diffusion Framework for Spatiotemporal Imputation
Feb 20, 2023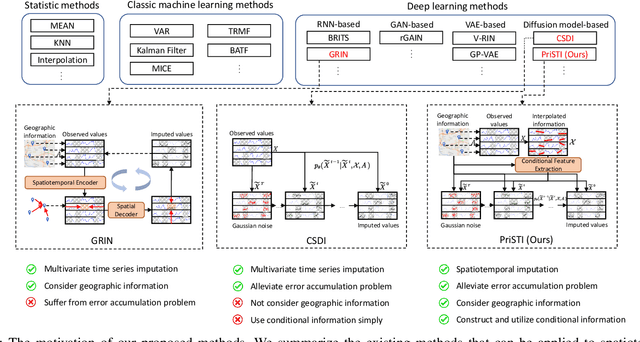
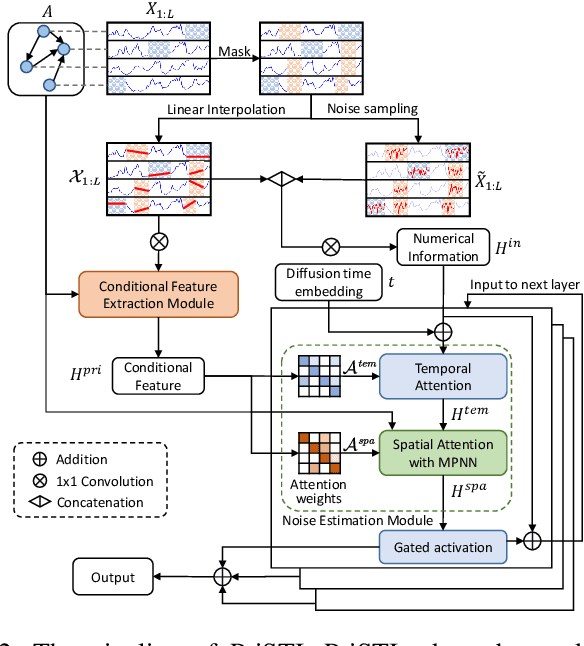
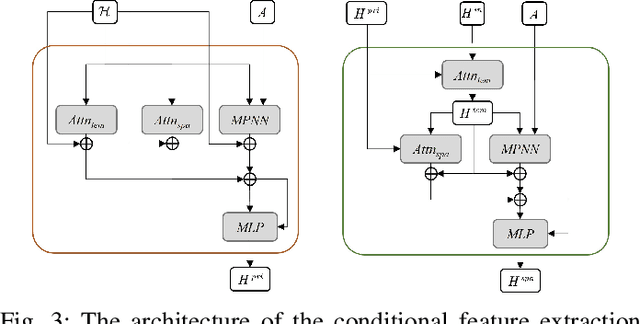
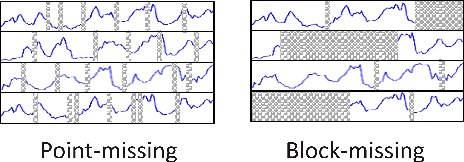
Spatiotemporal data mining plays an important role in air quality monitoring, crowd flow modeling, and climate forecasting. However, the originally collected spatiotemporal data in real-world scenarios is usually incomplete due to sensor failures or transmission loss. Spatiotemporal imputation aims to fill the missing values according to the observed values and the underlying spatiotemporal dependence of them. The previous dominant models impute missing values autoregressively and suffer from the problem of error accumulation. As emerging powerful generative models, the diffusion probabilistic models can be adopted to impute missing values conditioned by observations and avoid inferring missing values from inaccurate historical imputation. However, the construction and utilization of conditional information are inevitable challenges when applying diffusion models to spatiotemporal imputation. To address above issues, we propose a conditional diffusion framework for spatiotemporal imputation with enhanced prior modeling, named PriSTI. Our proposed framework provides a conditional feature extraction module first to extract the coarse yet effective spatiotemporal dependencies from conditional information as the global context prior. Then, a noise estimation module transforms random noise to realistic values, with the spatiotemporal attention weights calculated by the conditional feature, as well as the consideration of geographic relationships. PriSTI outperforms existing imputation methods in various missing patterns of different real-world spatiotemporal data, and effectively handles scenarios such as high missing rates and sensor failure. The implementation code is available at https://github.com/LMZZML/PriSTI.
À-la-carte Prompt Tuning (APT): Combining Distinct Data Via Composable Prompting
Feb 15, 2023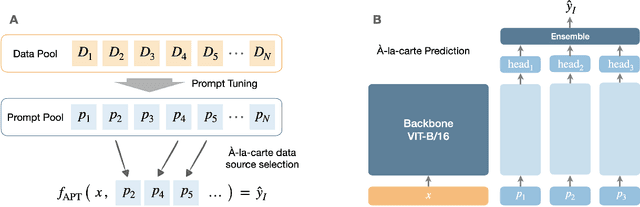


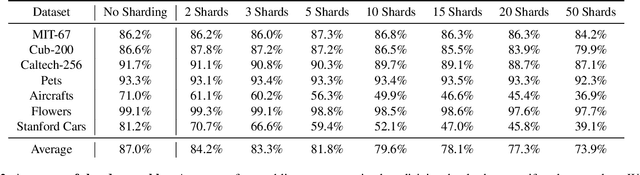
We introduce \`A-la-carte Prompt Tuning (APT), a transformer-based scheme to tune prompts on distinct data so that they can be arbitrarily composed at inference time. The individual prompts can be trained in isolation, possibly on different devices, at different times, and on different distributions or domains. Furthermore each prompt only contains information about the subset of data it was exposed to during training. During inference, models can be assembled based on arbitrary selections of data sources, which we call "\`a-la-carte learning". \`A-la-carte learning enables constructing bespoke models specific to each user's individual access rights and preferences. We can add or remove information from the model by simply adding or removing the corresponding prompts without retraining from scratch. We demonstrate that \`a-la-carte built models achieve accuracy within $5\%$ of models trained on the union of the respective sources, with comparable cost in terms of training and inference time. For the continual learning benchmarks Split CIFAR-100 and CORe50, we achieve state-of-the-art performance.
Multi-View Ensemble Learning With Missing Data: Computational Framework and Evaluations using Novel Data from the Safe Autonomous Driving Domain
Jan 30, 2023

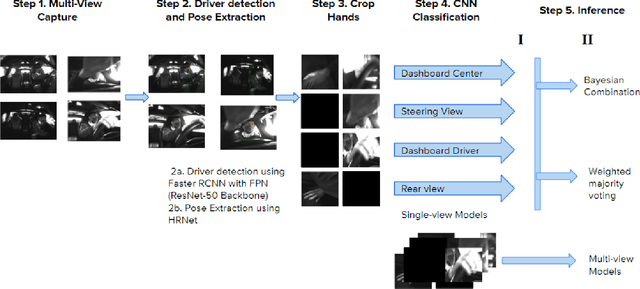
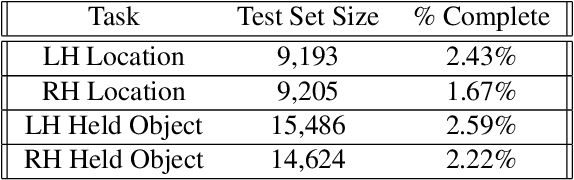
Real-world applications with multiple sensors observing an event are expected to make continuously-available predictions, even in cases where information may be intermittently missing. We explore methods in ensemble learning and sensor fusion to make use of redundancy and information shared between four camera views, applied to the task of hand activity classification for autonomous driving. In particular, we show that a late-fusion approach between parallel convolutional neural networks can outperform even the best-placed single camera model. To enable this approach, we propose a scheme for handling missing information, and then provide comparative analysis of this late-fusion approach to additional methods such as weighted majority voting and model combination schemes.
IMU-based online multi-lidar calibration without lidar odometry
Feb 28, 2023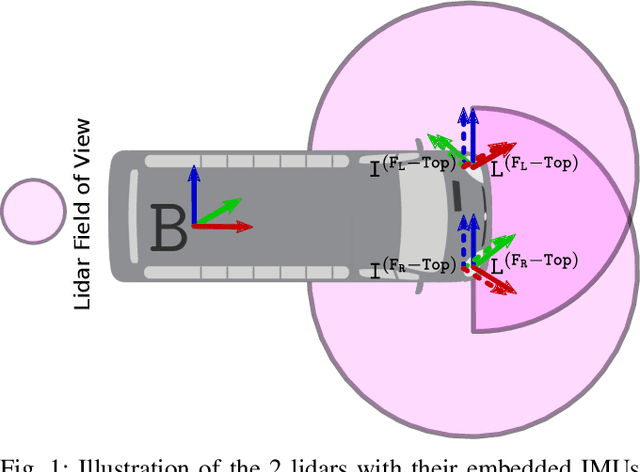
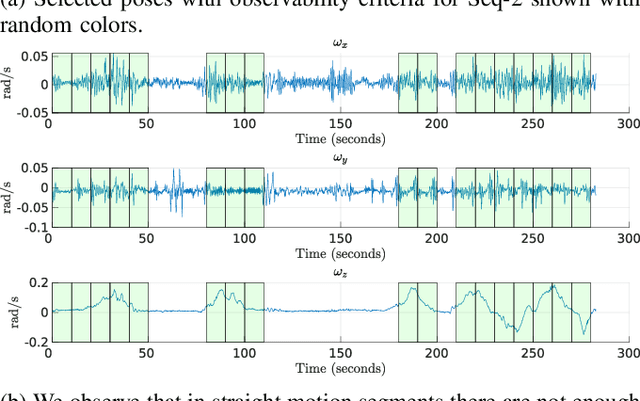

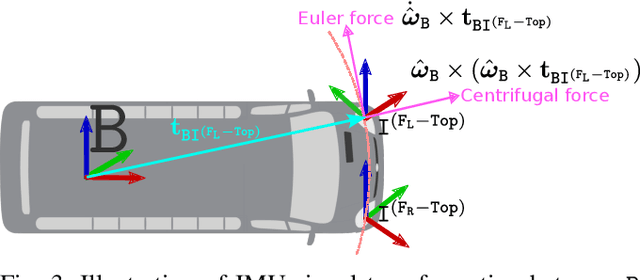
When deploying autonomous systems that require several sensors for perception, accurate and reliable extrinsic calibration is required. In this research, we offer a reliable technique that can extrinsically calibrate numerous lidars in the base frame of a moving vehicle without the use of odometry estimation or fiducial markers. Our method is based on comparing the raw IMU signals between a collocated IMU present with the lidar and the IMU measurements from the GNSS system in the vehicle base frame. Additionally, based on our observability criterion, we choose measurements that include the most mutual information rather than comparing all comparable IMU readings. This enables us to locate the measurements that are most useful for real-time calibration. Utilizing data gathered from Scania test vehicles with various sensor setups, we have successfully validated our methodology.
Synthesizing Mixed-type Electronic Health Records using Diffusion Models
Feb 28, 2023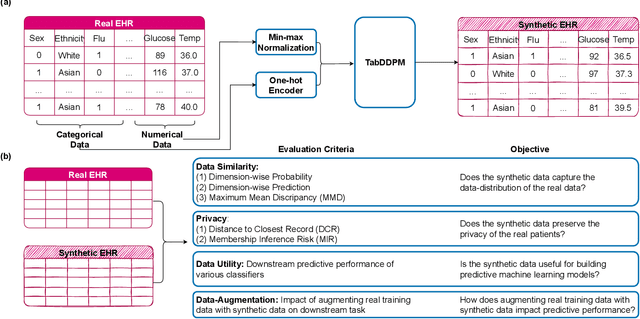
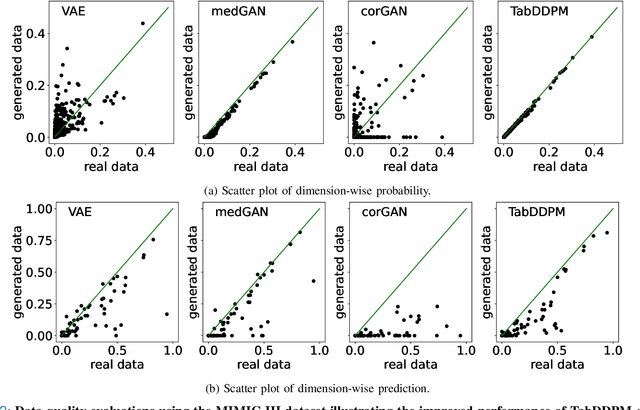
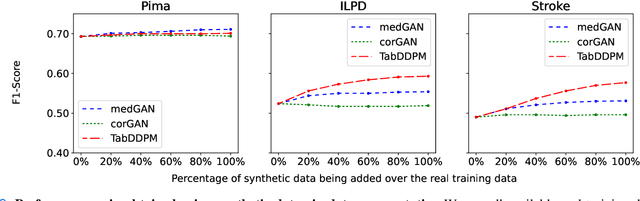

Electronic Health Records (EHRs) contain sensitive patient information, which presents privacy concerns when sharing such data. Synthetic data generation is a promising solution to mitigate these risks, often relying on deep generative models such as Generative Adversarial Networks (GANs). However, recent studies have shown that diffusion models offer several advantages over GANs, such as generation of more realistic synthetic data and stable training in generating data modalities, including image, text, and sound. In this work, we investigate the potential of diffusion models for generating realistic mixed-type tabular EHRs, comparing TabDDPM model with existing methods on four datasets in terms of data quality, utility, privacy, and augmentation. Our experiments demonstrate that TabDDPM outperforms the state-of-the-art models across all evaluation metrics, except for privacy, which confirms the trade-off between privacy and utility.
Fradulent User Detection Via Behavior Information Aggregation Network (BIAN) On Large-Scale Financial Social Network
Nov 04, 2022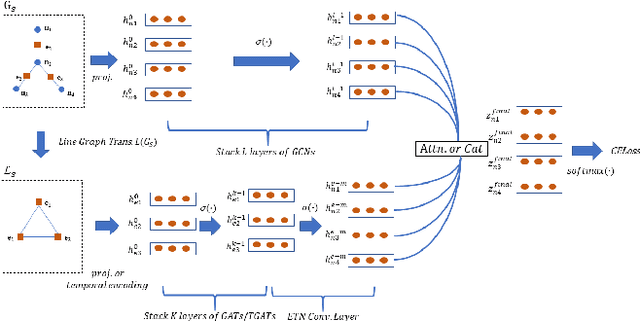
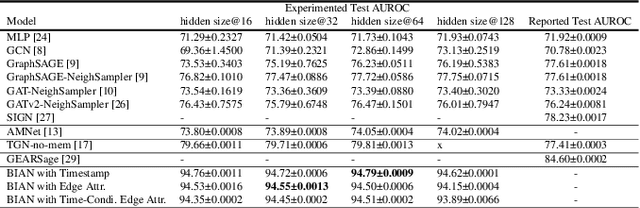
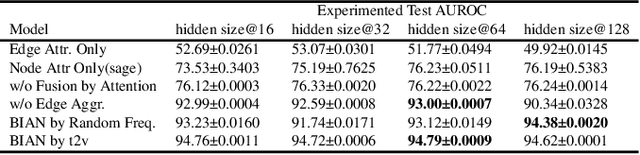
Financial frauds cause billions of losses annually and yet it lacks efficient approaches in detecting frauds considering user profile and their behaviors simultaneously in social network . A social network forms a graph structure whilst Graph neural networks (GNN), a promising research domain in Deep Learning, can seamlessly process non-Euclidean graph data . In financial fraud detection, the modus operandi of criminals can be identified by analyzing user profile and their behaviors such as transaction, loaning etc. as well as their social connectivity. Currently, most GNNs are incapable of selecting important neighbors since the neighbors' edge attributes (i.e., behaviors) are ignored. In this paper, we propose a novel behavior information aggregation network (BIAN) to combine the user behaviors with other user features. Different from its close "relatives" such as Graph Attention Networks (GAT) and Graph Transformer Networks (GTN), it aggregates neighbors based on neighboring edge attribute distribution, namely, user behaviors in financial social network. The experimental results on a real-world large-scale financial social network dataset, DGraph, show that BIAN obtains the 10.2% gain in AUROC comparing with the State-Of-The-Art models.
Time Associated Meta Learning for Clinical Prediction
Mar 05, 2023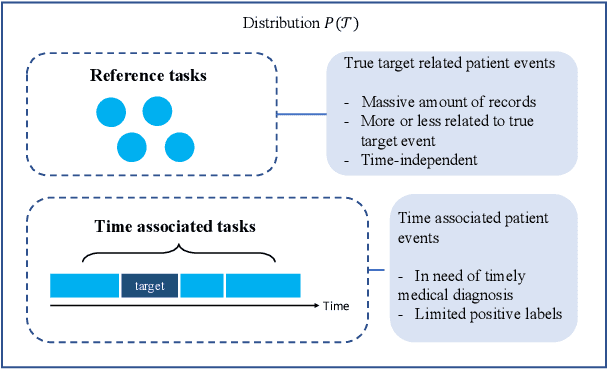
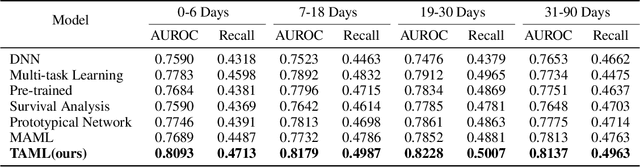
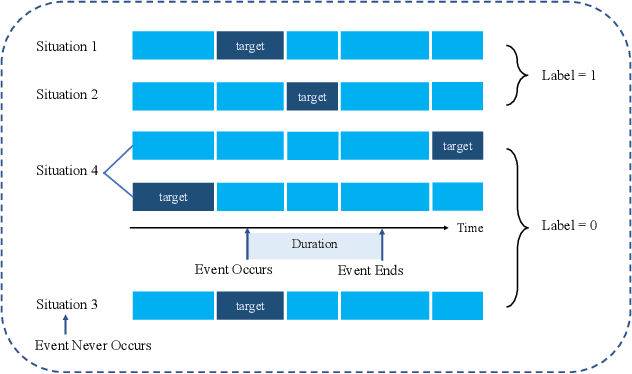
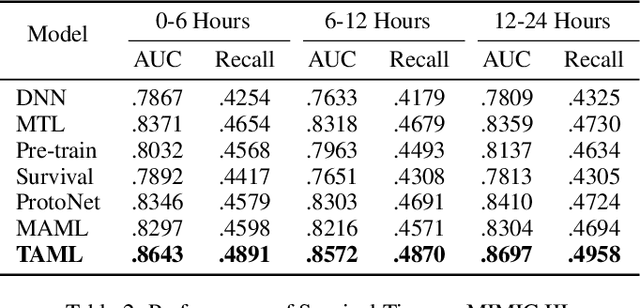
Rich Electronic Health Records (EHR), have created opportunities to improve clinical processes using machine learning methods. Prediction of the same patient events at different time horizons can have very different applications and interpretations; however, limited number of events in each potential time window hurts the effectiveness of conventional machine learning algorithms. We propose a novel time associated meta learning (TAML) method to make effective predictions at multiple future time points. We view time-associated disease prediction as classification tasks at multiple time points. Such closely-related classification tasks are an excellent candidate for model-based meta learning. To address the sparsity problem after task splitting, TAML employs a temporal information sharing strategy to augment the number of positive samples and include the prediction of related phenotypes or events in the meta-training phase. We demonstrate the effectiveness of TAML on multiple clinical datasets, where it consistently outperforms a range of strong baselines. We also develop a MetaEHR package for implementing both time-associated and time-independent few-shot prediction on EHR data.
Semantic-aware Occlusion Filtering Neural Radiance Fields in the Wild
Mar 05, 2023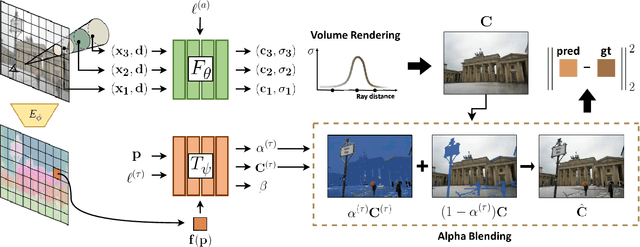
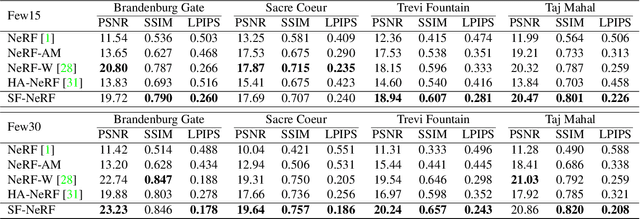

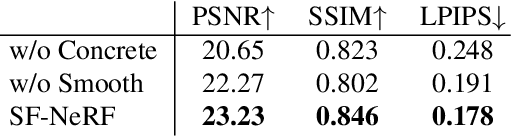
We present a learning framework for reconstructing neural scene representations from a small number of unconstrained tourist photos. Since each image contains transient occluders, decomposing the static and transient components is necessary to construct radiance fields with such in-the-wild photographs where existing methods require a lot of training data. We introduce SF-NeRF, aiming to disentangle those two components with only a few images given, which exploits semantic information without any supervision. The proposed method contains an occlusion filtering module that predicts the transient color and its opacity for each pixel, which enables the NeRF model to solely learn the static scene representation. This filtering module learns the transient phenomena guided by pixel-wise semantic features obtained by a trainable image encoder that can be trained across multiple scenes to learn the prior of transient objects. Furthermore, we present two techniques to prevent ambiguous decomposition and noisy results of the filtering module. We demonstrate that our method outperforms state-of-the-art novel view synthesis methods on Phototourism dataset in a few-shot setting.