 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TimeMAE: Self-Supervised Representations of Time Series with Decoupled Masked Autoencoders
Mar 14, 2023
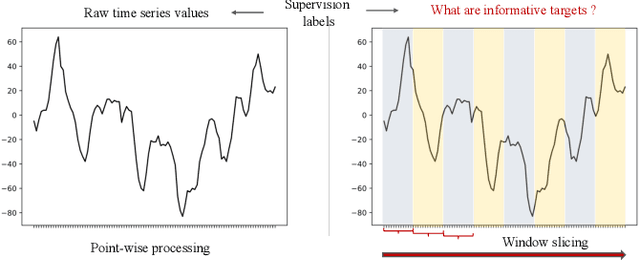
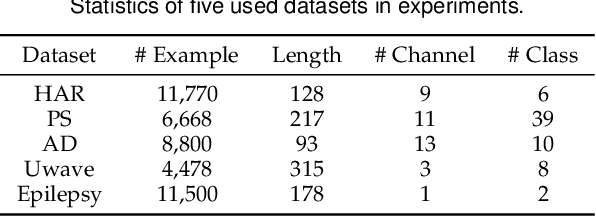

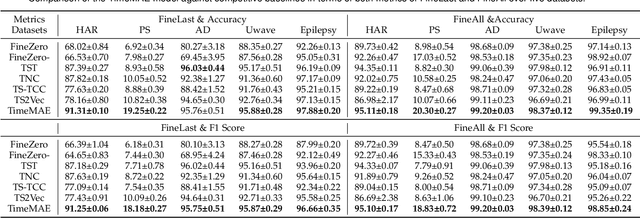
Enhancing the expressive capacity of deep learning-based time series models with self-supervised pre-training has become ever-increasingly prevalent in time series classification. Even though numerous efforts have been devoted to developing self-supervised models for time series data, we argue that the current methods are not sufficient to learn optimal time series representations due to solely unidirectional encoding over sparse point-wise input units. In this work, we propose TimeMAE, a novel self-supervised paradigm for learning transferrable time series representations based on transformer networks. The distinct characteristics of the TimeMAE lie in processing each time series into a sequence of non-overlapping sub-series via window-slicing partitioning, followed by random masking strategies over the semantic units of localized sub-series. Such a simple yet effective setting can help us achieve the goal of killing three birds with one stone, i.e., (1) learning enriched contextual representations of time series with a bidirectional encoding scheme; (2) increasing the information density of basic semantic units; (3) efficiently encoding representations of time series using transformer networks. Nevertheless, it is a non-trivial to perform reconstructing task over such a novel formulated modeling paradigm. To solve the discrepancy issue incurred by newly injected masked embeddings, we design a decoupled autoencoder architecture, which learns the representations of visible (unmasked) positions and masked ones with two different encoder modules, respectively. Furthermore, we construct two types of informative targets to accomplish the corresponding pretext tasks. One is to create a tokenizer module that assigns a codeword to each masked region, allowing the masked codeword classification (MCC) task to be completed effectively...
Traffic4cast at NeurIPS 2022 -- Predict Dynamics along Graph Edges from Sparse Node Data: Whole City Traffic and ETA from Stationary Vehicle Detectors
Mar 14, 2023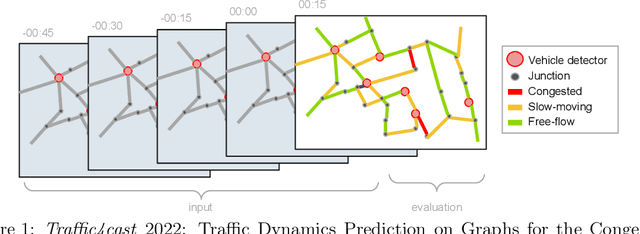
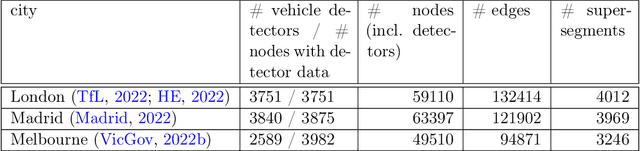
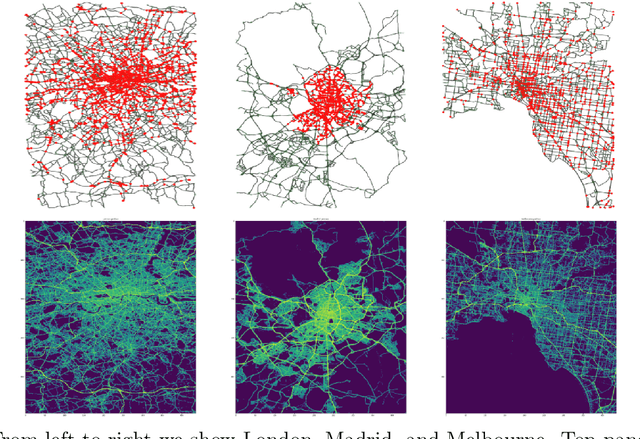
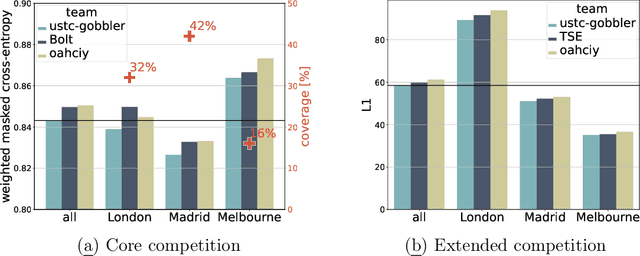
The global trends of urbanization and increased personal mobility force us to rethink the way we live and use urban space. The Traffic4cast competition series tackles this problem in a data-driven way, advancing the latest methods in machine learning for modeling complex spatial systems over time. In this edition, our dynamic road graph data combine information from road maps, $10^{12}$ probe data points, and stationary vehicle detectors in three cities over the span of two years. While stationary vehicle detectors are the most accurate way to capture traffic volume, they are only available in few locations. Traffic4cast 2022 explores models that have the ability to generalize loosely related temporal vertex data on just a few nodes to predict dynamic future traffic states on the edges of the entire road graph. In the core challenge, participants are invited to predict the likelihoods of three congestion classes derived from the speed levels in the GPS data for the entire road graph in three cities 15 min into the future. We only provide vehicle count data from spatially sparse stationary vehicle detectors in these three cities as model input for this task. The data are aggregated in 15 min time bins for one hour prior to the prediction time. For the extended challenge, participants are tasked to predict the average travel times on super-segments 15 min into the future - super-segments are longer sequences of road segments in the graph. The competition results provide an important advance in the prediction of complex city-wide traffic states just from publicly available sparse vehicle data and without the need for large amounts of real-time floating vehicle data.
Parallel Vertex Diffusion for Unified Visual Grounding
Mar 14, 2023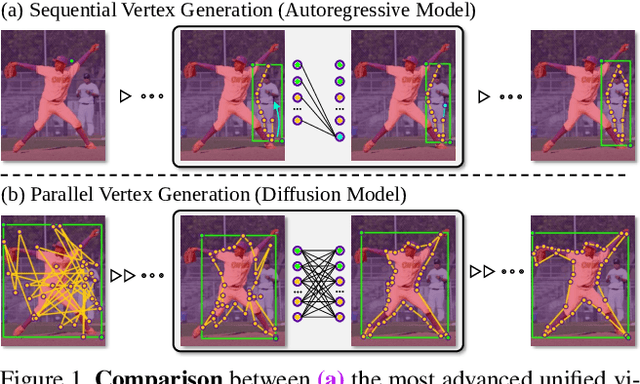
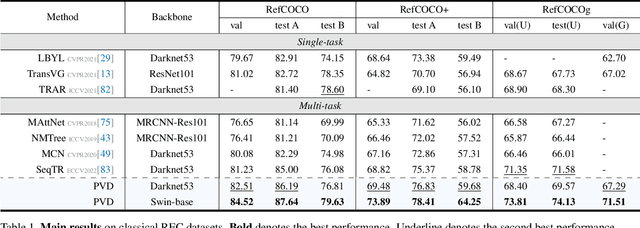

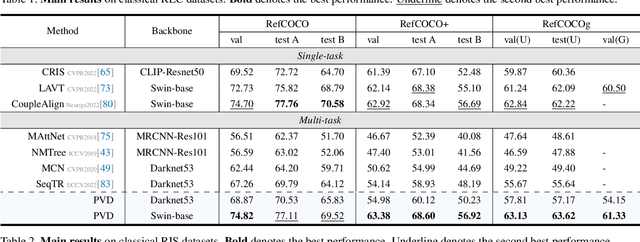
Unified visual grounding pursues a simple and generic technical route to leverage multi-task data with less task-specific design. The most advanced methods typically present boxes and masks as vertex sequences to model referring detection and segmentation as an autoregressive sequential vertex generation paradigm. However, generating high-dimensional vertex sequences sequentially is error-prone because the upstream of the sequence remains static and cannot be refined based on downstream vertex information, even if there is a significant location gap. Besides, with limited vertexes, the inferior fitting of objects with complex contours restricts the performance upper bound. To deal with this dilemma, we propose a parallel vertex generation paradigm for superior high-dimension scalability with a diffusion model by simply modifying the noise dimension. An intuitive materialization of our paradigm is Parallel Vertex Diffusion (PVD) to directly set vertex coordinates as the generation target and use a diffusion model to train and infer. We claim that it has two flaws: (1) unnormalized coordinate caused a high variance of loss value; (2) the original training objective of PVD only considers point consistency but ignores geometry consistency. To solve the first flaw, Center Anchor Mechanism (CAM) is designed to convert coordinates as normalized offset values to stabilize the training loss value. For the second flaw, Angle summation loss (ASL) is designed to constrain the geometry difference of prediction and ground truth vertexes for geometry-level consistency. Empirical results show that our PVD achieves state-of-the-art in both referring detection and segmentation, and our paradigm is more scalable and efficient than sequential vertex generation with high-dimension data.
TrafficBots: Towards World Models for Autonomous Driving Simulation and Motion Prediction
Mar 07, 2023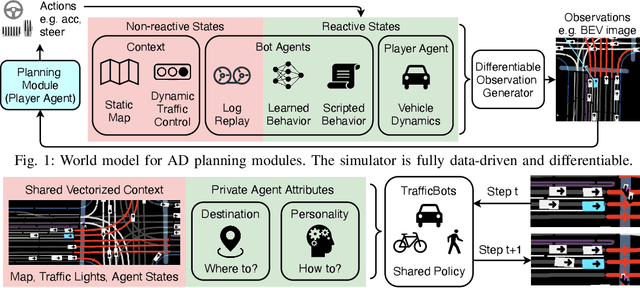
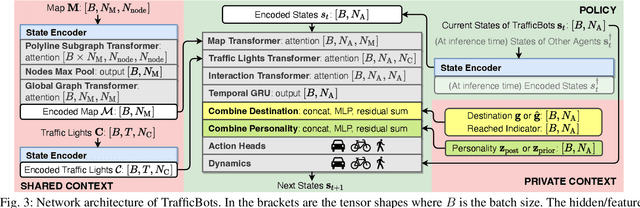
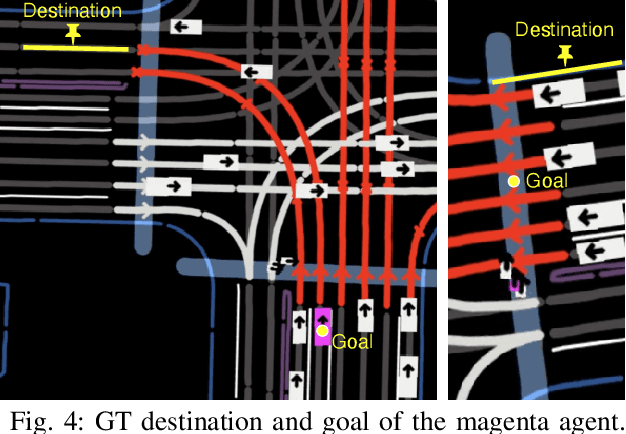
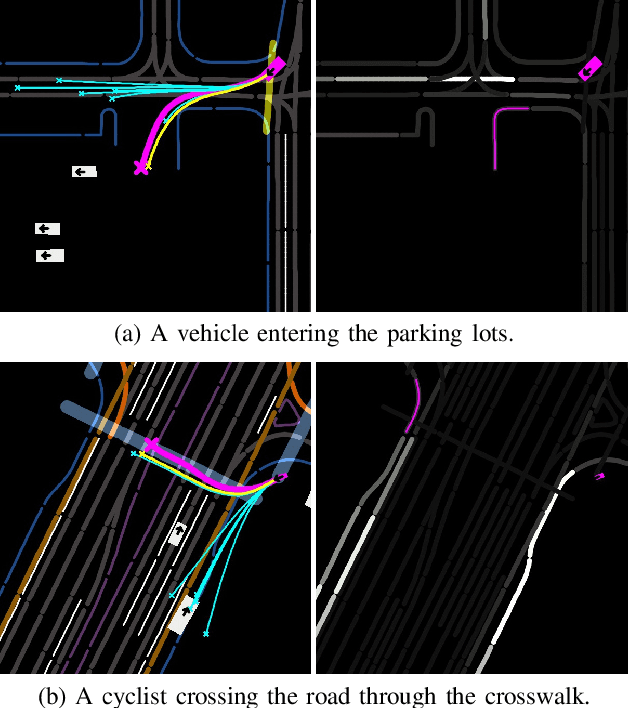
Data-driven simulation has become a favorable way to train and test autonomous driving algorithms. The idea of replacing the actual environment with a learned simulator has also been explored in model-based reinforcement learning in the context of world models. In this work, we show data-driven traffic simulation can be formulated as a world model. We present TrafficBots, a multi-agent policy built upon motion prediction and end-to-end driving, and based on TrafficBots we obtain a world model tailored for the planning module of autonomous vehicles. Existing data-driven traffic simulators are lacking configurability and scalability. To generate configurable behaviors, for each agent we introduce a destination as navigational information, and a time-invariant latent personality that specifies the behavioral style. To improve the scalability, we present a new scheme of positional encoding for angles, allowing all agents to share the same vectorized context and the use of an architecture based on dot-product attention. As a result, we can simulate all traffic participants seen in dense urban scenarios. Experiments on the Waymo open motion dataset show TrafficBots can simulate realistic multi-agent behaviors and achieve good performance on the motion prediction task.
Gradient-Guided Knowledge Distillation for Object Detectors
Mar 07, 2023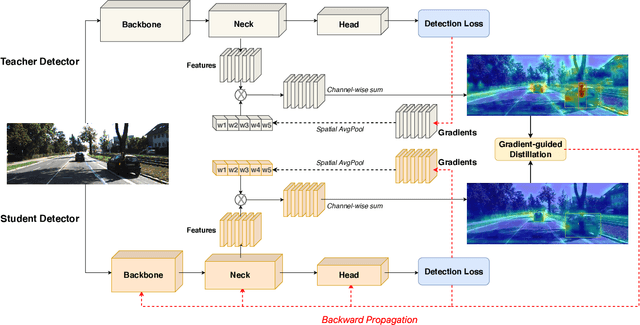
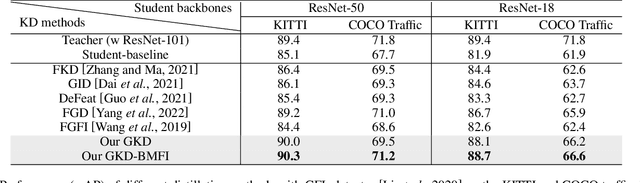

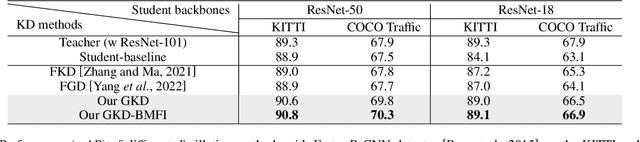
Deep learning models have demonstrated remarkable success in object detection, yet their complexity and computational intensity pose a barrier to deploying them in real-world applications (e.g., self-driving perception). Knowledge Distillation (KD) is an effective way to derive efficient models. However, only a small number of KD methods tackle object detection. Also, most of them focus on mimicking the plain features of the teacher model but rarely consider how the features contribute to the final detection. In this paper, we propose a novel approach for knowledge distillation in object detection, named Gradient-guided Knowledge Distillation (GKD). Our GKD uses gradient information to identify and assign more weights to features that significantly impact the detection loss, allowing the student to learn the most relevant features from the teacher. Furthermore, we present bounding-box-aware multi-grained feature imitation (BMFI) to further improve the KD performance. Experiments on the KITTI and COCO-Traffic datasets demonstrate our method's efficacy in knowledge distillation for object detection. On one-stage and two-stage detectors, our GKD-BMFI leads to an average of 5.1% and 3.8% mAP improvement, respectively, beating various state-of-the-art KD methods.
Inseq: An Interpretability Toolkit for Sequence Generation Models
Feb 27, 2023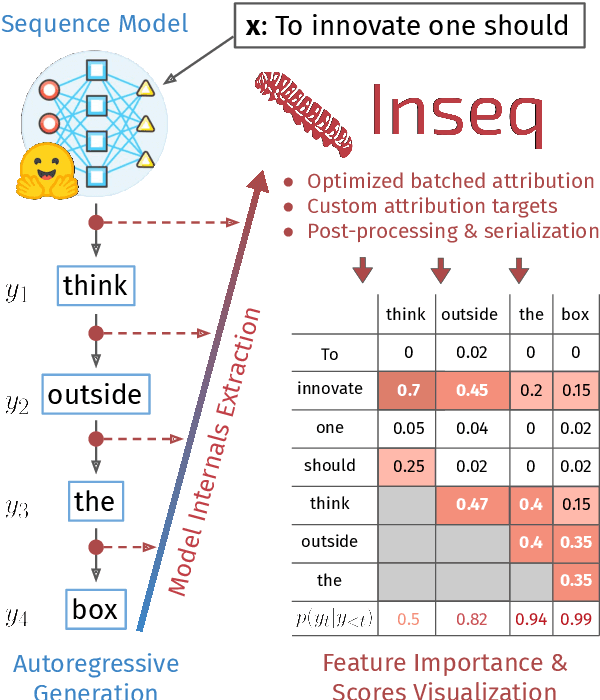
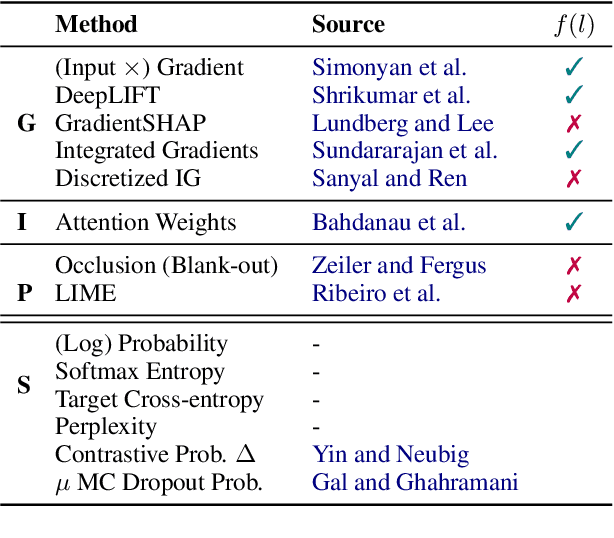
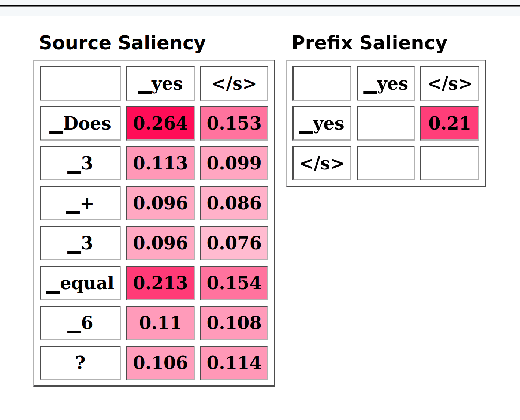
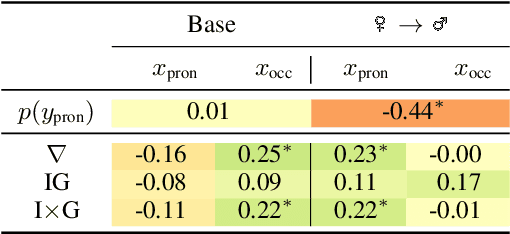
Past work in natural language processing interpretability focused mainly on popular classification tasks while largely overlooking generation settings, partly due to a lack of dedicated tools. In this work, we introduce Inseq, a Python library to democratize access to interpretability analyses of sequence generation models. Inseq enables intuitive and optimized extraction of models' internal information and feature importance scores for popular decoder-only and encoder-decoder Transformers architectures. We showcase its potential by adopting it to highlight gender biases in machine translation models and locate factual knowledge inside GPT-2. Thanks to its extensible interface supporting cutting-edge techniques such as contrastive feature attribution, Inseq can drive future advances in explainable natural language generation, centralizing good practices and enabling fair and reproducible model evaluations.
On Differentially Private Online Predictions
Feb 27, 2023In this work we introduce an interactive variant of joint differential privacy towards handling online processes in which existing privacy definitions seem too restrictive. We study basic properties of this definition and demonstrate that it satisfies (suitable variants) of group privacy, composition, and post processing. We then study the cost of interactive joint privacy in the basic setting of online classification. We show that any (possibly non-private) learning rule can be effectively transformed to a private learning rule with only a polynomial overhead in the mistake bound. This demonstrates a stark difference with more restrictive notions of privacy such as the one studied by Golowich and Livni (2021), where only a double exponential overhead on the mistake bound is known (via an information theoretic upper bound).
Fradulent User Detection Via Behavior Information Aggregation Network (BIAN) On Large-Scale Financial Social Network
Nov 04, 2022
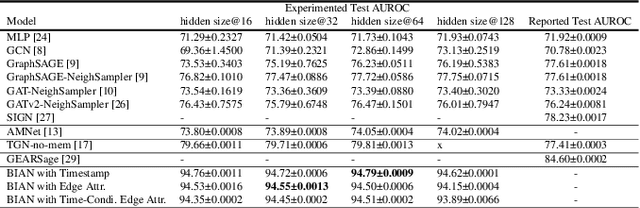
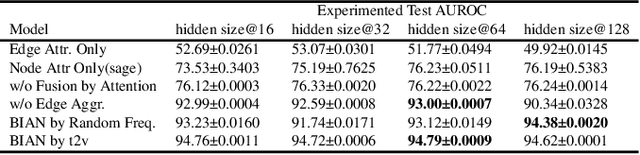
Financial frauds cause billions of losses annually and yet it lacks efficient approaches in detecting frauds considering user profile and their behaviors simultaneously in social network . A social network forms a graph structure whilst Graph neural networks (GNN), a promising research domain in Deep Learning, can seamlessly process non-Euclidean graph data . In financial fraud detection, the modus operandi of criminals can be identified by analyzing user profile and their behaviors such as transaction, loaning etc. as well as their social connectivity. Currently, most GNNs are incapable of selecting important neighbors since the neighbors' edge attributes (i.e., behaviors) are ignored. In this paper, we propose a novel behavior information aggregation network (BIAN) to combine the user behaviors with other user features. Different from its close "relatives" such as Graph Attention Networks (GAT) and Graph Transformer Networks (GTN), it aggregates neighbors based on neighboring edge attribute distribution, namely, user behaviors in financial social network. The experimental results on a real-world large-scale financial social network dataset, DGraph, show that BIAN obtains the 10.2% gain in AUROC comparing with the State-Of-The-Art models.
Graph Feedback via Reduction to Regression
Feb 17, 2023


When feedback is partial, leveraging all available information is critical to minimizing data requirements. Graph feedback, which interpolates between the supervised and bandit regimes, has been extensively studied; but the mature theory is grounded in impractical algorithms. We present and analyze an approach to contextual bandits with graph feedback based upon reduction to regression. The resulting algorithms are practical and achieve known minimax rates.
Material Identification From Radiographs Without Energy Resolution
Mar 10, 2023
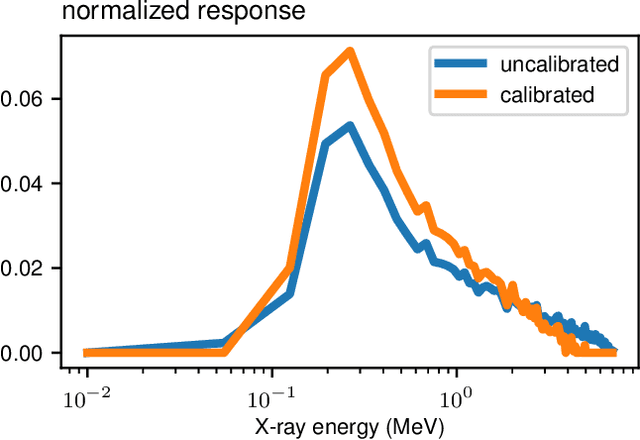
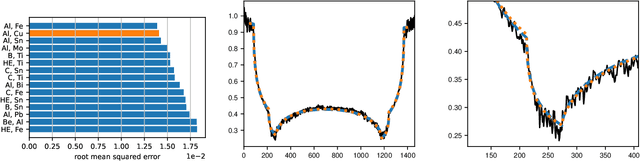
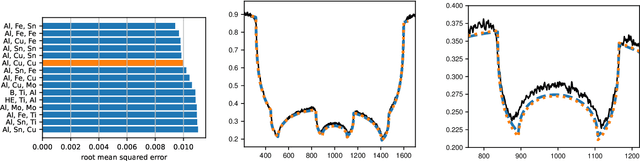
We propose a method for performing material identification from radiographs without energy-resolved measurements. Material identification has a wide variety of applications, including in biomedical imaging, nondestructive testing, and security. While existing techniques for radiographic material identification make use of dual energy sources, energy-resolving detectors, or additional (e.g., neutron) measurements, such setups are not always practical-requiring additional hardware and complicating imaging. We tackle material identification without energy resolution, allowing standard X-ray systems to provide material identification information without requiring additional hardware. Assuming a setting where the geometry of each object in the scene is known and the materials come from a known set of possible materials, we pose the problem as a combinatorial optimization with a loss function that accounts for the presence of scatter and an unknown gain and propose a branch and bound algorithm to efficiently solve it. We present experiments on both synthetic data and real, experimental data with relevance to security applications-thick, dense objects imaged with MeV X-rays. We show that material identification can be efficient and accurate, for example, in a scene with three shells (two copper, one aluminum), our algorithm ran in six minutes on a consumer-level laptop and identified the correct materials as being among the top 10 best matches out of 8,000 possibilities.