 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Learning-Based Channel Extrapolation for Pattern Reconfigurable Massive MIMO
Mar 08, 2023
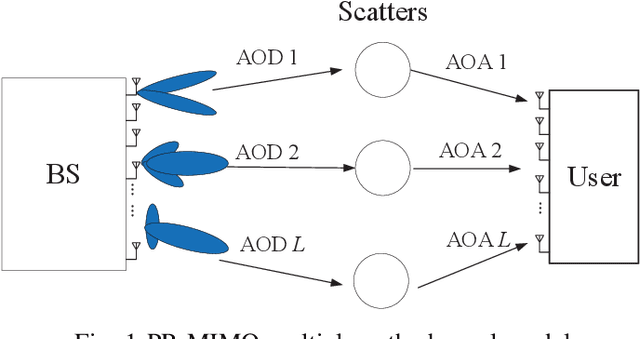
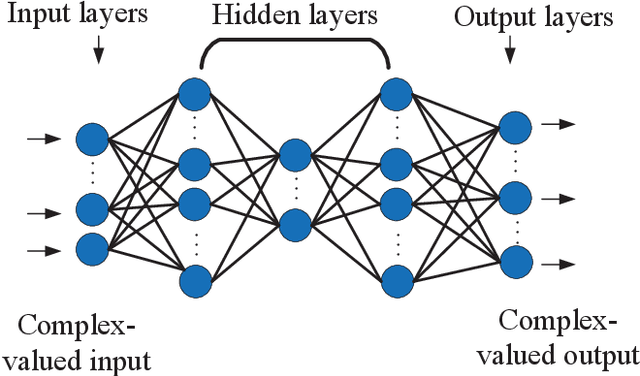
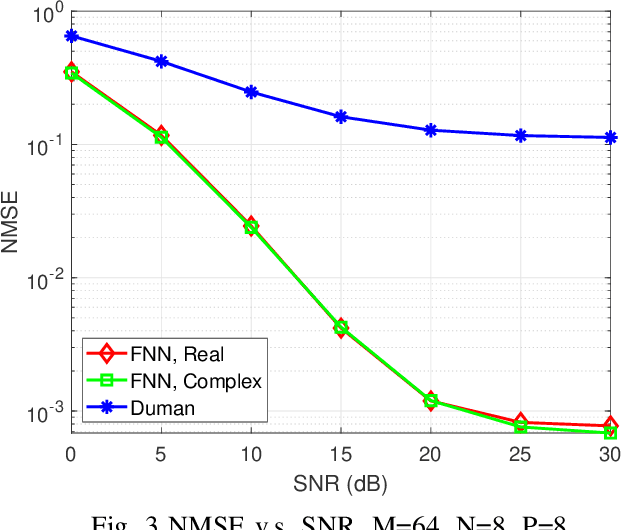
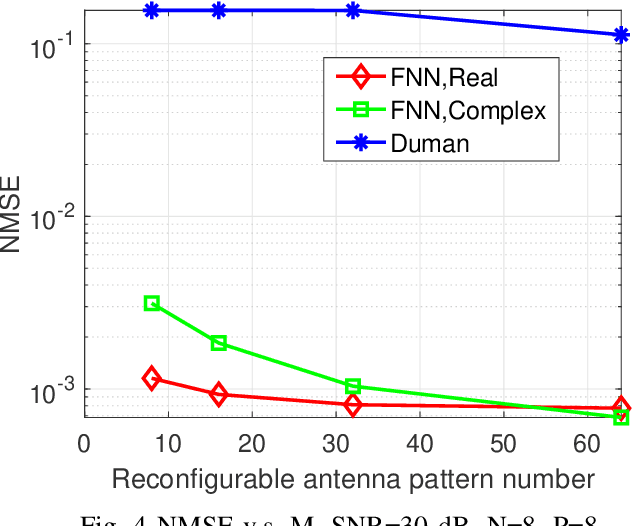
Antennas that can dynamically change the operation state exhibit excellent adaptivity and flexibility over traditional antennas, and MIMO arrays that consist of Multifunctional and reconfigurable antennas (MRAs) are foreseen as one promising solution towards future Holographic MIMO. Specifically, in pattern reconfigurable MIMO (PR-MIMO) communication systems, accurate acquisition of channel state information (CSI) of all the radiation modes is a challenging task, because using conventional pilot-based channel estimation techniques in PR-MIMO systems incurs overwhelming pilot overheads. In this letter, we leverage deep learning methods to design a PR neural network, which can use the estimated CSI for one radiation mode to infer CSIs for the other radiation modes. In order to reduce the pilot overheads, we propose a new channel estimation method specially for PR-MIMO systems which divides the transmit antennas of PR-MIMO into groups, where antennas in different groups employ different radiation modes. Comparing with conventional full connected deep neural networks (FNN), the PR neural network which uses complex weight coefficients can work directly in the complex domain. Experiment results show that the proposed channel extrapolation method offers significant performance gains in terms of prediction accuracy over benchmark schemes.
A study on the use of perceptual hashing to detect manipulation of embedded messages in images
Feb 28, 2023
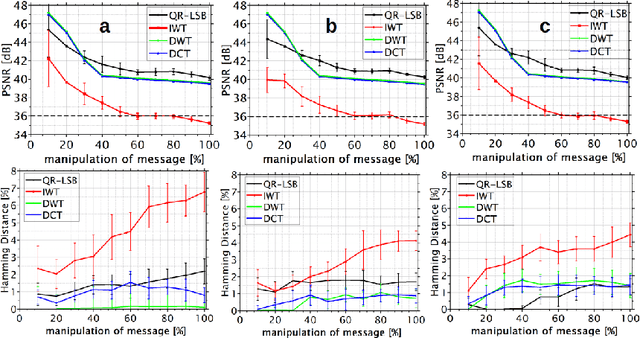
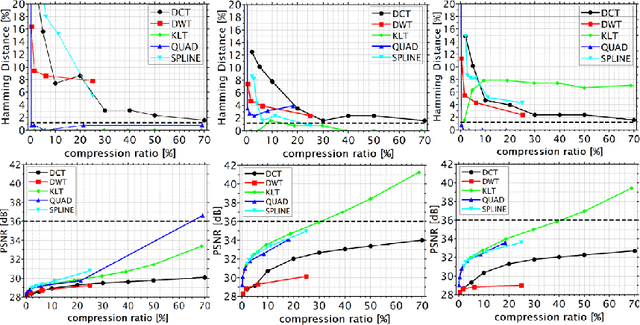
Typically, metadata of images are stored in a specific data segment of the image file. However, to securely detect changes, data can also be embedded within images. This follows the goal to invisibly and robustly embed as much information as possible to, ideally, even survive compression. This work searches for embedding principles which allow to distinguish between unintended changes by lossy image compression and malicious manipulation of the embedded message based on the change of its perceptual or robust hash. Different embedding and compression algorithms are compared. The study shows that embedding a message via integer wavelet transform and compression with Karhunen-Loeve-transform yields the best results. However, it was not possible to distinguish between manipulation and compression in all cases.
Attention-based Point Cloud Edge Sampling
Feb 28, 2023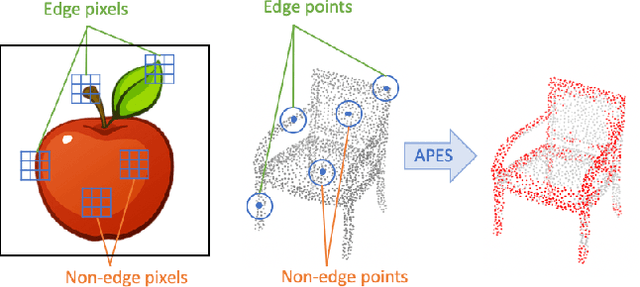
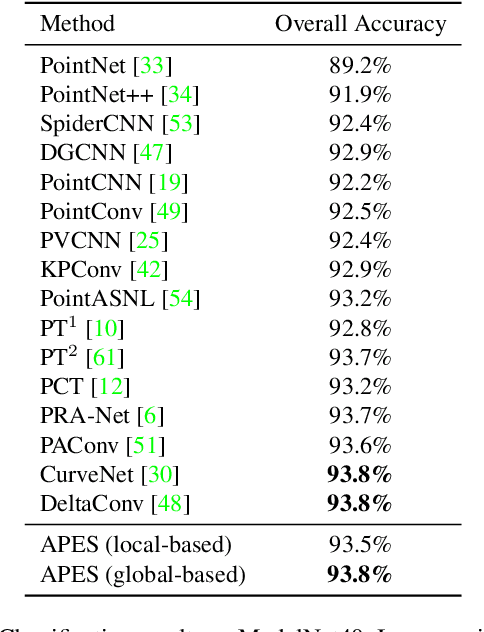
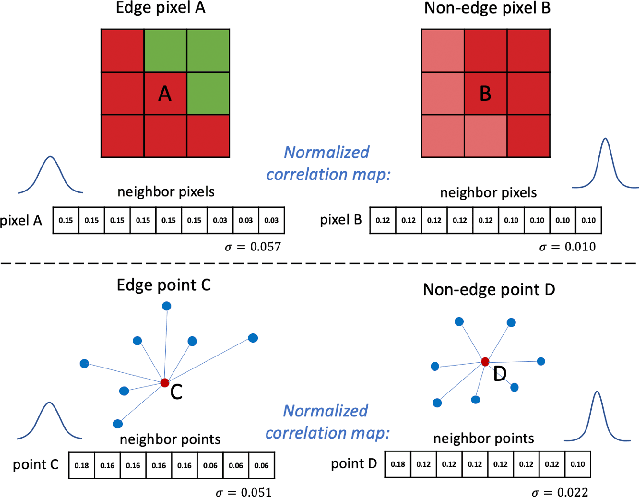
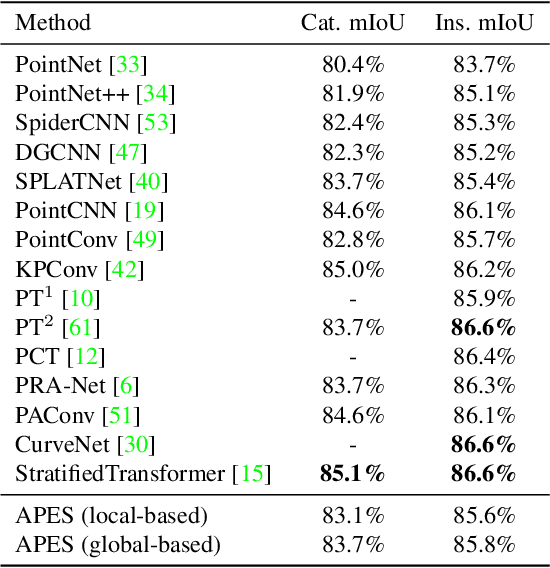
Point cloud sampling is a less explored research topic for this data representation. The most common sampling methods nowadays are still classical random sampling and farthest point sampling. With the development of neural networks, various methods have been proposed to sample point clouds in a task-based learning manner. However, these methods are mostly generative-based, other than selecting points directly with mathematical statistics. Inspired by the Canny edge detection algorithm for images and with the help of the attention mechanism, this paper proposes a non-generative Attention-based Point cloud Edge Sampling method (APES), which can capture the outline of input point clouds. Experimental results show that better performances are achieved with our sampling method due to the important outline information it learned.
Enhancing Protein Language Models with Structure-based Encoder and Pre-training
Mar 11, 2023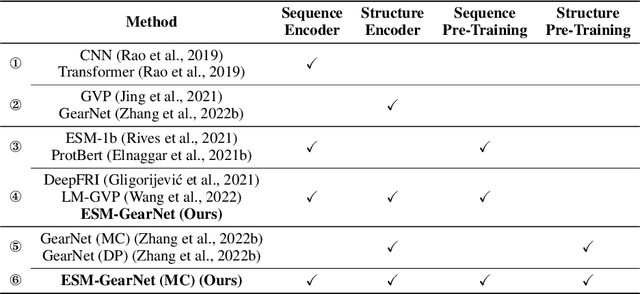
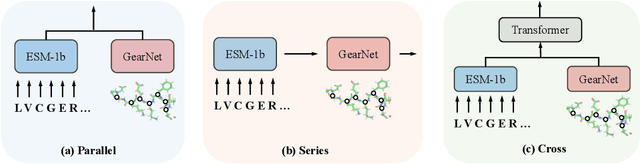
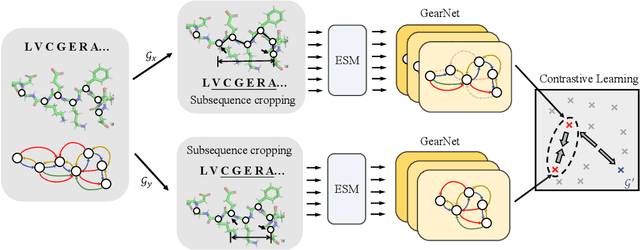
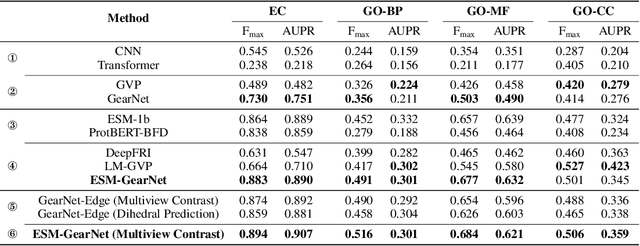
Protein language models (PLMs) pre-trained on large-scale protein sequence corpora have achieved impressive performance on various downstream protein understanding tasks. Despite the ability to implicitly capture inter-residue contact information, transformer-based PLMs cannot encode protein structures explicitly for better structure-aware protein representations. Besides, the power of pre-training on available protein structures has not been explored for improving these PLMs, though structures are important to determine functions. To tackle these limitations, in this work, we enhance the PLMs with structure-based encoder and pre-training. We first explore feasible model architectures to combine the advantages of a state-of-the-art PLM (i.e., ESM-1b1) and a state-of-the-art protein structure encoder (i.e., GearNet). We empirically verify the ESM-GearNet that connects two encoders in a series way as the most effective combination model. To further improve the effectiveness of ESM-GearNet, we pre-train it on massive unlabeled protein structures with contrastive learning, which aligns representations of co-occurring subsequences so as to capture their biological correlation. Extensive experiments on EC and GO protein function prediction benchmarks demonstrate the superiority of ESM-GearNet over previous PLMs and structure encoders, and clear performance gains are further achieved by structure-based pre-training upon ESM-GearNet. Our implementation is available at https://github.com/DeepGraphLearning/GearNet.
Hardware Acceleration of Neural Graphics
Mar 16, 2023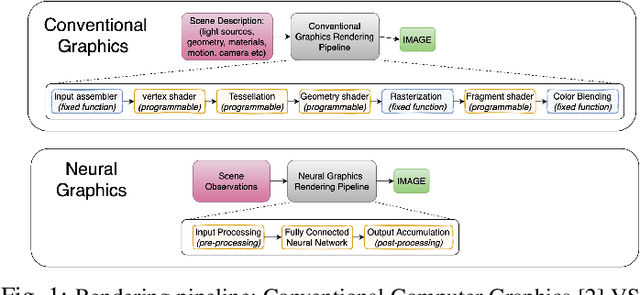
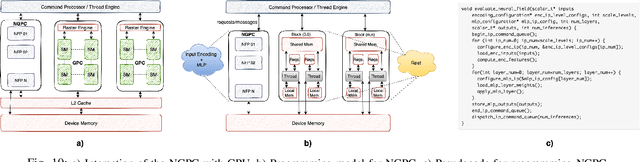
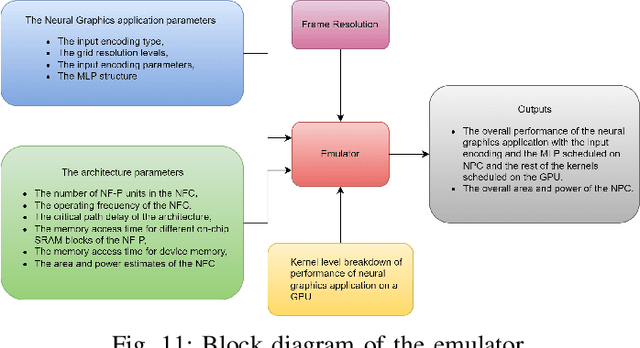
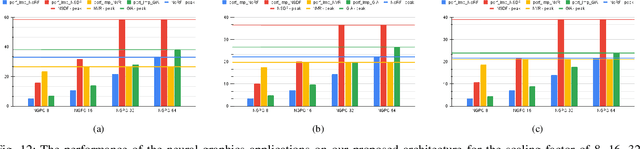
Rendering and inverse-rendering algorithms that drive conventional computer graphics have recently been superseded by neural representations (NR). NRs have recently been used to learn the geometric and the material properties of the scenes and use the information to synthesize photorealistic imagery, thereby promising a replacement for traditional rendering algorithms with scalable quality and predictable performance. In this work we ask the question: Does neural graphics (NG) need hardware support? We studied representative NG applications showing that, if we want to render 4k res. at 60FPS there is a gap of 1.5X-55X in the desired performance on current GPUs. For AR/VR applications, there is an even larger gap of 2-4 OOM between the desired performance and the required system power. We identify that the input encoding and the MLP kernels are the performance bottlenecks, consuming 72%,60% and 59% of application time for multi res. hashgrid, multi res. densegrid and low res. densegrid encodings, respectively. We propose a NG processing cluster, a scalable and flexible hardware architecture that directly accelerates the input encoding and MLP kernels through dedicated engines and supports a wide range of NG applications. We also accelerate the rest of the kernels by fusing them together in Vulkan, which leads to 9.94X kernel-level performance improvement compared to un-fused implementation of the pre-processing and the post-processing kernels. Our results show that, NGPC gives up to 58X end-to-end application-level performance improvement, for multi res. hashgrid encoding on average across the four NG applications, the performance benefits are 12X,20X,33X and 39X for the scaling factor of 8,16,32 and 64, respectively. Our results show that with multi res. hashgrid encoding, NGPC enables the rendering of 4k res. at 30FPS for NeRF and 8k res. at 120FPS for all our other NG applications.
Fast 3D Volumetric Image Reconstruction from 2D MRI Slices by Parallel Processing
Mar 16, 2023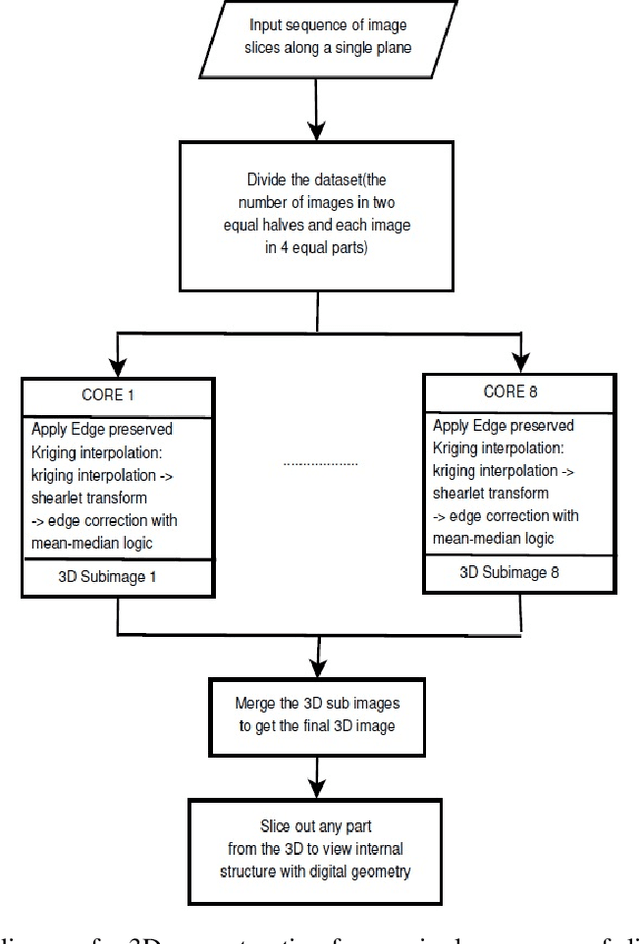
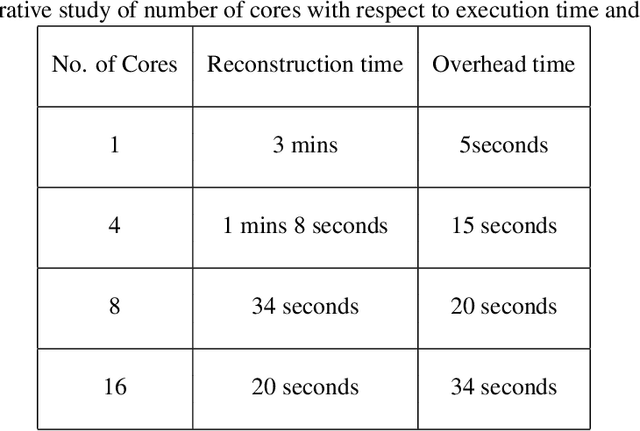
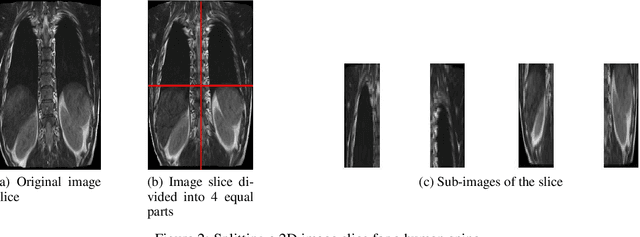
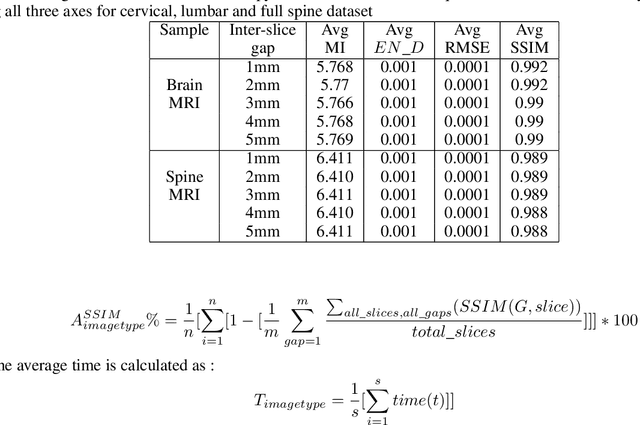
Magnetic Resonance Imaging (MRI) is a technology for non-invasive imaging of anatomical features in detail. It can help in functional analysis of organs of a specimen but it is very costly. In this work, methods for (i) virtual three-dimensional (3D) reconstruction from a single sequence of two-dimensional (2D) slices of MR images of a human spine and brain along a single axis, and (ii) generation of missing inter-slice data are proposed. Our approach helps in preserving the edges, shape, size, as well as the internal tissue structures of the object being captured. The sequence of original 2D slices along a single axis is divided into smaller equal sub-parts which are then reconstructed using edge preserved kriging interpolation to predict the missing slice information. In order to speed up the process of interpolation, we have used multiprocessing by carrying out the initial interpolation on parallel cores. From the 3D matrix thus formed, shearlet transform is applied to estimate the edges considering the 2D blocks along the $Z$ axis, and to minimize the blurring effect using a proposed mean-median logic. Finally, for visualization, the sub-matrices are merged into a final 3D matrix. Next, the newly formed 3D matrix is split up into voxels and marching cubes method is applied to get the approximate 3D image for viewing. To the best of our knowledge it is a first of its kind approach based on kriging interpolation and multiprocessing for 3D reconstruction from 2D slices, and approximately 98.89\% accuracy is achieved with respect to similarity metrics for image comparison. The time required for reconstruction has also been reduced by approximately 70\% with multiprocessing even for a large input data set compared to that with single core processing.
A General Visual Representation Guided Framework with Global Affinity for Weakly Supervised Salient Object Detection
Feb 21, 2023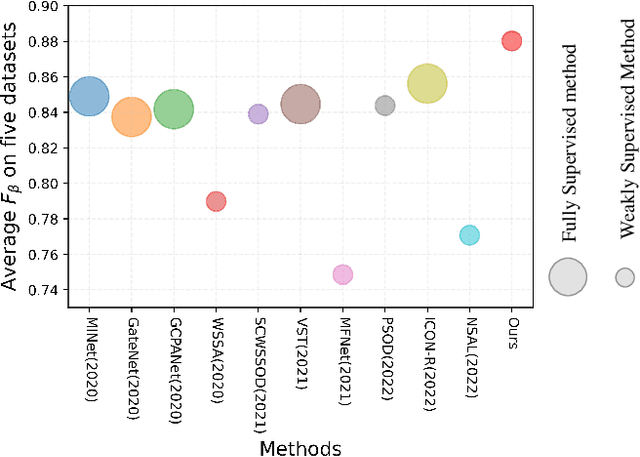
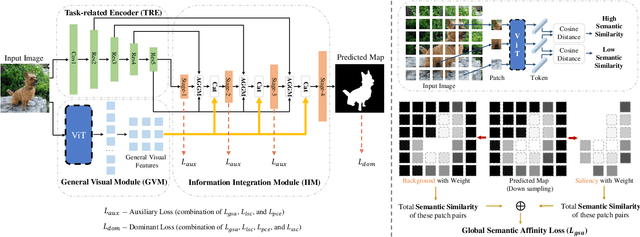
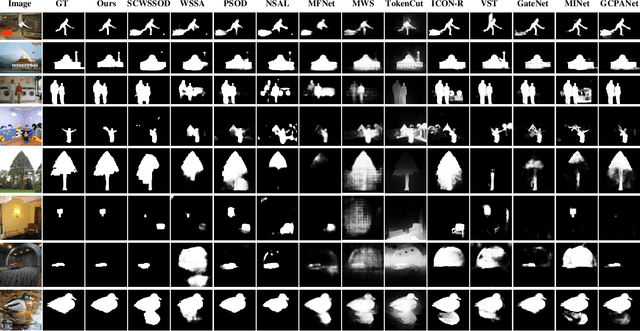

Fully supervised salient object detection (SOD) methods have made considerable progress in performance, yet these models rely heavily on expensive pixel-wise labels. Recently, to achieve a trade-off between labeling burden and performance, scribble-based SOD methods have attracted increasing attention. Previous models directly implement the SOD task only based on small-scale SOD training data. Due to the limited information provided by the weakly scribble tags and such small-scale training data, it is extremely difficult for them to understand the image and further achieve a superior SOD task. In this paper, we propose a simple yet effective framework guided by general visual representations that simulate the general cognition of humans for scribble-based SOD. It consists of a task-related encoder, a general visual module, and an information integration module to combine efficiently the general visual representations learned from large-scale unlabeled datasets with task-related features to perform the SOD task based on understanding the contextual connections of images. Meanwhile, we propose a novel global semantic affinity loss to guide the model to perceive the global structure of the salient objects. Experimental results on five public benchmark datasets demonstrate that our method that only utilizes scribble annotations without introducing any extra label outperforms the state-of-the-art weakly supervised SOD methods and is comparable or even superior to the state-of-the-art fully supervised models.
Personalized Privacy Auditing and Optimization at Test Time
Jan 31, 2023
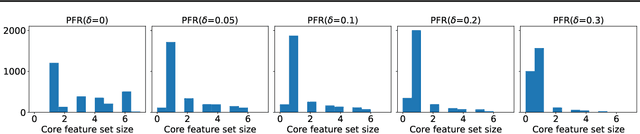
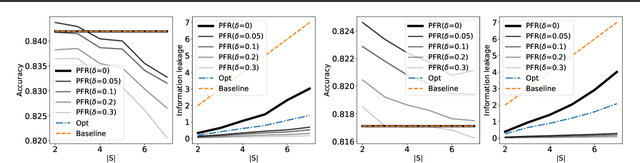

A number of learning models used in consequential domains, such as to assist in legal, banking, hiring, and healthcare decisions, make use of potentially sensitive users' information to carry out inference. Further, the complete set of features is typically required to perform inference. This not only poses severe privacy risks for the individuals using the learning systems, but also requires companies and organizations massive human efforts to verify the correctness of the released information. This paper asks whether it is necessary to require \emph{all} input features for a model to return accurate predictions at test time and shows that, under a personalized setting, each individual may need to release only a small subset of these features without impacting the final decisions. The paper also provides an efficient sequential algorithm that chooses which attributes should be provided by each individual. Evaluation over several learning tasks shows that individuals may be able to report as little as 10\% of their information to ensure the same level of accuracy of a model that uses the complete users' information.
What Is Synthetic Data? The Good, The Bad, and The Ugly
Mar 01, 2023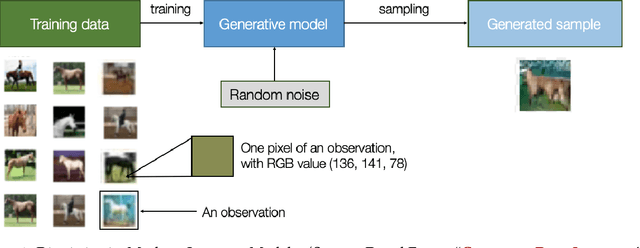
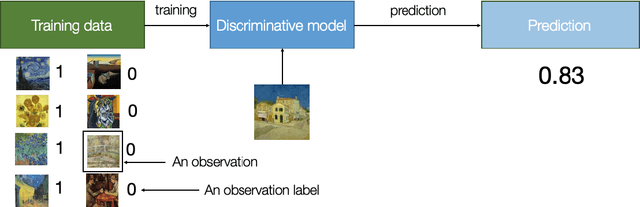

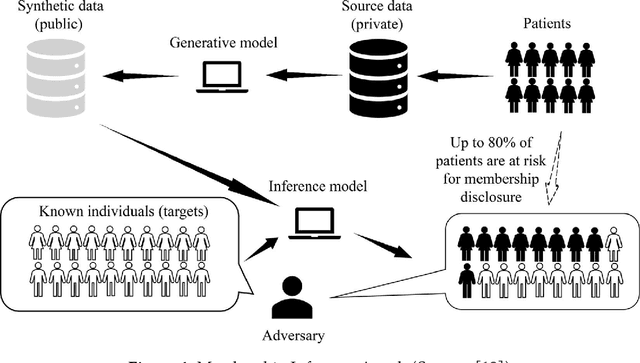
Sharing data can often enable compelling applications and analytics. However, more often than not, valuable datasets contain information of sensitive nature, and thus sharing them can endanger the privacy of users and organizations. A possible alternative gaining momentum in the research community is to share synthetic data instead. The idea is to release artificially generated datasets that resemble the actual data -- more precisely, having similar statistical properties. So how do you generate synthetic data? What is that useful for? What are the benefits and the risks? What are the open research questions that remain unanswered? In this article, we provide a gentle introduction to synthetic data and discuss its use cases, the privacy challenges that are still unaddressed, and its inherent limitations as an effective privacy-enhancing technology.
Balancing Privacy Protection and Interpretability in Federated Learning
Feb 16, 2023


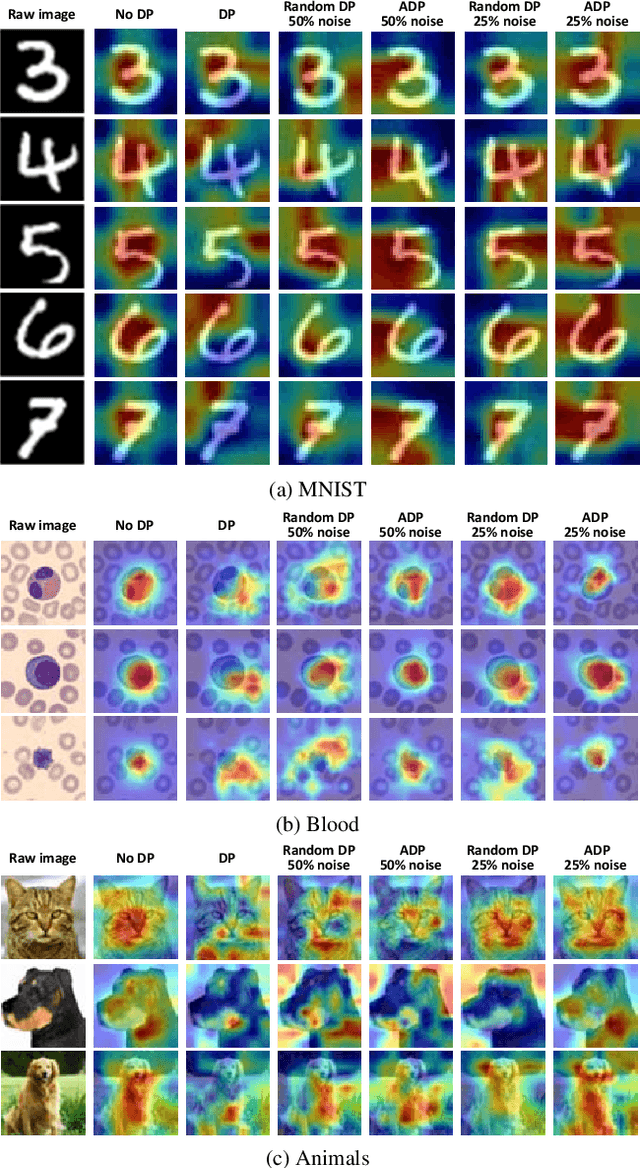
Federated learning (FL) aims to collaboratively train the global model in a distributed manner by sharing the model parameters from local clients to a central server, thereby potentially protecting users' private information. Nevertheless, recent studies have illustrated that FL still suffers from information leakage as adversaries try to recover the training data by analyzing shared parameters from local clients. To deal with this issue, differential privacy (DP) is adopted to add noise to the gradients of local models before aggregation. It, however, results in the poor performance of gradient-based interpretability methods, since some weights capturing the salient region in feature map will be perturbed. To overcome this problem, we propose a simple yet effective adaptive differential privacy (ADP) mechanism that selectively adds noisy perturbations to the gradients of client models in FL. We also theoretically analyze the impact of gradient perturbation on the model interpretability. Finally, extensive experiments on both IID and Non-IID data demonstrate that the proposed ADP can achieve a good trade-off between privacy and interpretability in FL.