 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Survey on Causal Reinforcement Learning
Feb 27, 2023
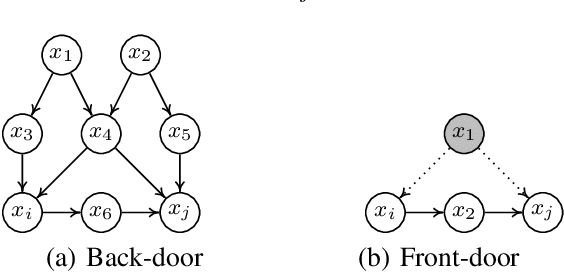
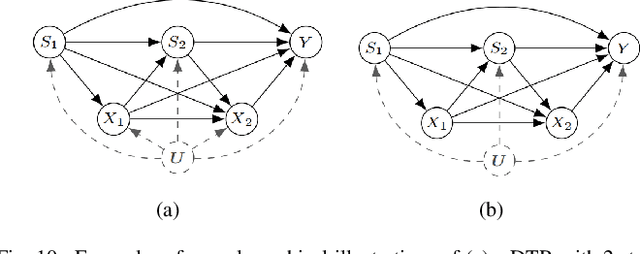
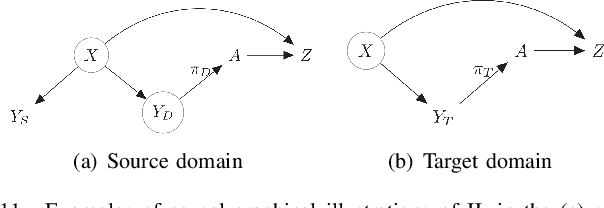
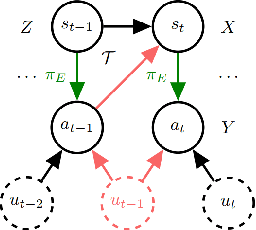
While Reinforcement Learning (RL) achieves tremendous success in sequential decision-making problems of many domains, it still faces key challenges of data inefficiency and the lack of interpretability. Interestingly, many researchers have leveraged insights from the causality literature recently, bringing forth flourishing works to unify the merits of causality and address well the challenges from RL. As such, it is of great necessity and significance to collate these Causal Reinforcement Learning (CRL) works, offer a review of CRL methods, and investigate the potential functionality from causality toward RL. In particular, we divide existing CRL approaches into two categories according to whether their causality-based information is given in advance or not. We further analyze each category in terms of the formalization of different models, ranging from the Markov Decision Process (MDP), Partially Observed Markov Decision Process (POMDP), Multi-Arm Bandits (MAB), and Dynamic Treatment Regime (DTR). Moreover, we summarize the evaluation matrices and open sources while we discuss emerging applications, along with promising prospects for the future development of CRL.
3D Neural Beamforming for Multi-channel Speech Separation Against Location Uncertainty
Feb 27, 2023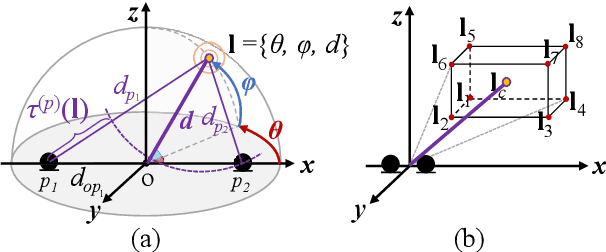
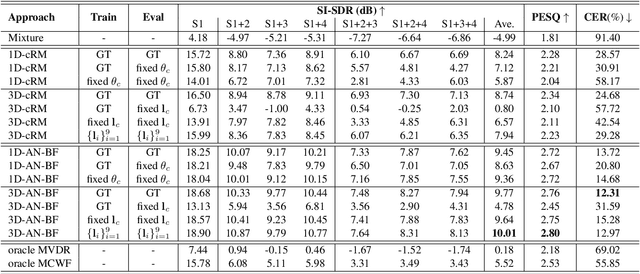
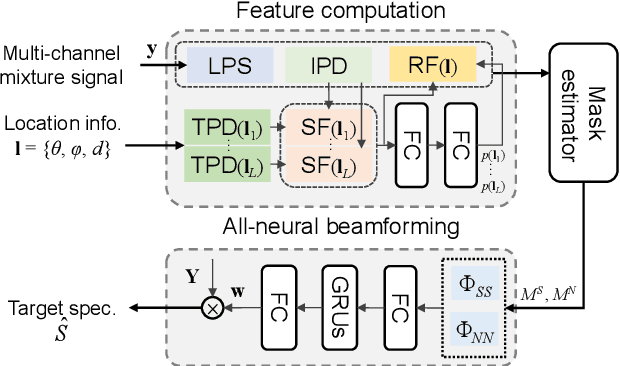

Multi-channel speech separation using speaker's directional information has demonstrated significant gains over blind speech separation. However, it has two limitations. First, substantial performance degradation is observed when the coming directions of two sounds are close. Second, the result highly relies on the precise estimation of the speaker's direction. To overcome these issues, this paper proposes 3D features and an associated 3D neural beamformer for multi-channel speech separation. Previous works in this area are extended in two important directions. First, the traditional 1D directional beam patterns are generalized to 3D. This enables the model to extract speech from any target region in the 3D space. Thus, speakers with similar directions but different elevations or distances become separable. Second, to handle the speaker location uncertainty, previously proposed spatial feature is extended to a new 3D region feature. The proposed 3D region feature and 3D neural beamformer are evaluated under an in-car scenario. Experimental results demonstrated that the combination of 3D feature and 3D beamformer can achieve comparable performance to the separation model with ground truth speaker location as input.
TwERC: High Performance Ensembled Candidate Generation for Ads Recommendation at Twitter
Feb 27, 2023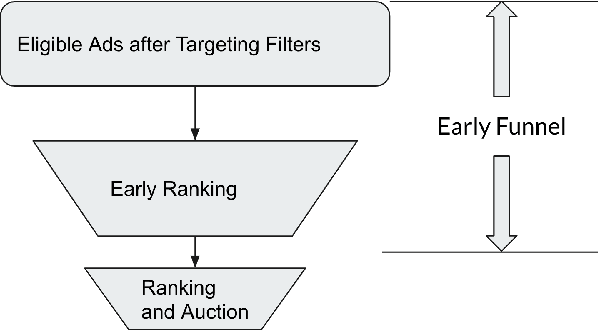
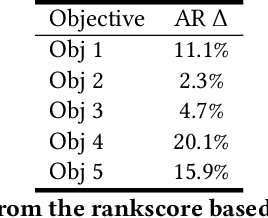
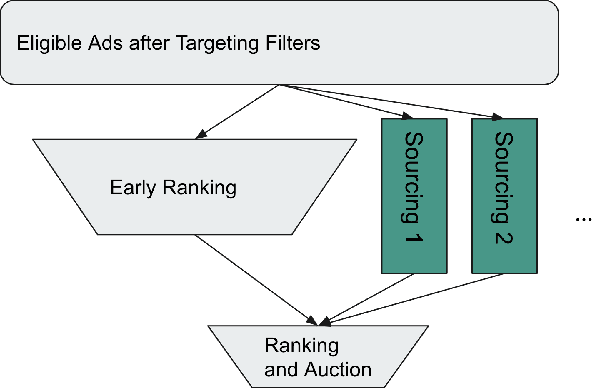

Recommendation systems are a core feature of social media companies with their uses including recommending organic and promoted contents. Many modern recommendation systems are split into multiple stages - candidate generation and heavy ranking - to balance computational cost against recommendation quality. We focus on the candidate generation phase of a large-scale ads recommendation problem in this paper, and present a machine learning first heterogeneous re-architecture of this stage which we term TwERC. We show that a system that combines a real-time light ranker with sourcing strategies capable of capturing additional information provides validated gains. We present two strategies. The first strategy uses a notion of similarity in the interaction graph, while the second strategy caches previous scores from the ranking stage. The graph based strategy achieves a 4.08% revenue gain and the rankscore based strategy achieves a 1.38% gain. These two strategies have biases that complement both the light ranker and one another. Finally, we describe a set of metrics that we believe are valuable as a means of understanding the complex product trade offs inherent in industrial candidate generation systems.
Communication-efficient Federated Learning with Single-Step Synthetic Features Compressor for Faster Convergence
Feb 27, 2023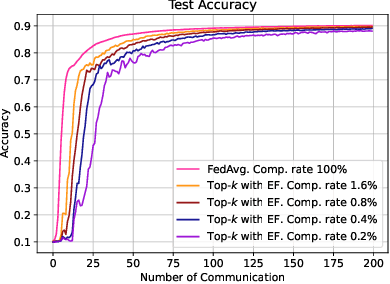
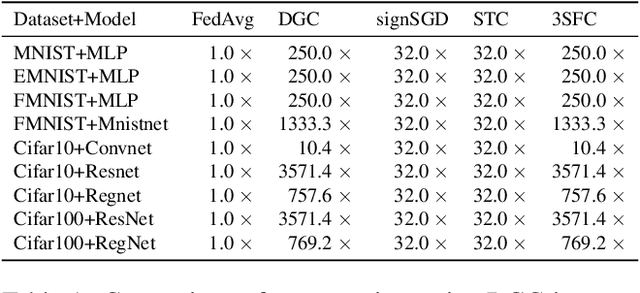
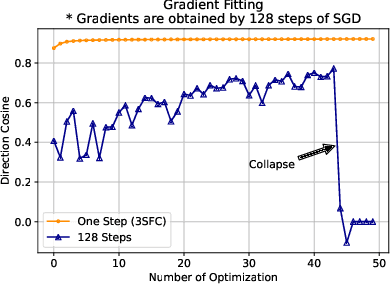
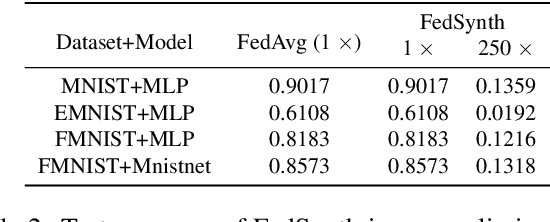
Reducing communication overhead in federated learning (FL) is challenging but crucial for large-scale distributed privacy-preserving machine learning. While methods utilizing sparsification or others can largely lower the communication overhead, the convergence rate is also greatly compromised. In this paper, we propose a novel method, named single-step synthetic features compressor (3SFC), to achieve communication-efficient FL by directly constructing a tiny synthetic dataset based on raw gradients. Thus, 3SFC can achieve an extremely low compression rate when the constructed dataset contains only one data sample. Moreover, 3SFC's compressing phase utilizes a similarity-based objective function so that it can be optimized with just one step, thereby considerably improving its performance and robustness. In addition, to minimize the compressing error, error feedback (EF) is also incorporated into 3SFC. Experiments on multiple datasets and models suggest that 3SFC owns significantly better convergence rates compared to competing methods with lower compression rates (up to 0.02%). Furthermore, ablation studies and visualizations show that 3SFC can carry more information than competing methods for every communication round, further validating its effectiveness.
Private Status Updating with Erasures: A Case for Retransmission Without Resampling
Feb 23, 2023
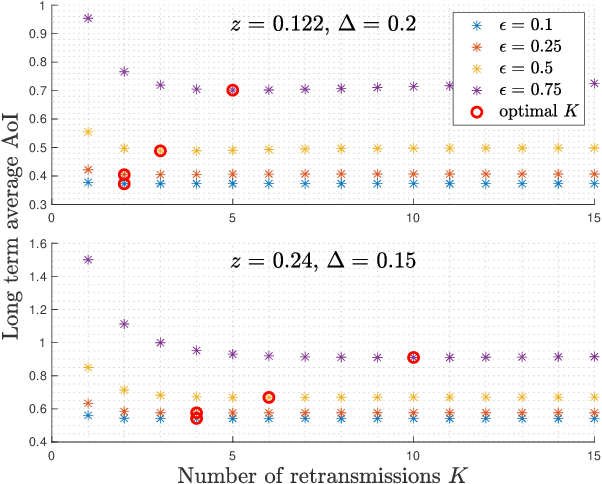
A status updating system is considered in which a source updates a destination over an erasure channel. The utility of the updates is measured through a function of their age-of-information (AoI), which assesses their freshness. Correlated with the status updates is another process that needs to be kept private from the destination. Privacy is measured through a leakage function that depends on the amount and time of the status updates received: stale updates are more private than fresh ones. Different from most of the current AoI literature, a post-sampling waiting time is introduced in order to provide a privacy cover at the expense of AoI. More importantly, it is also shown that, depending on the leakage budget and the channel statistics, it can be useful to retransmit stale status updates following erasure events without resampling fresh ones.
A novel efficient Multi-view traffic-related object detection framework
Feb 23, 2023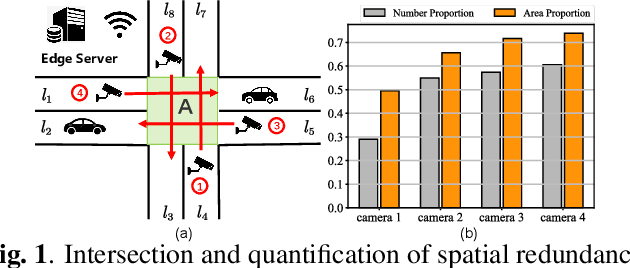
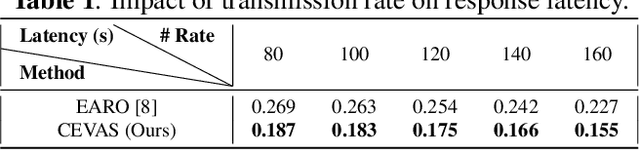

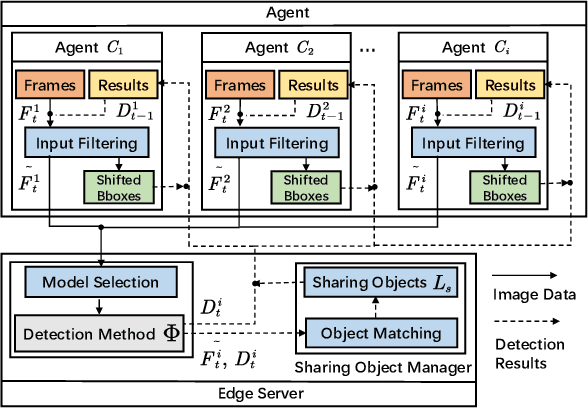
With the rapid development of intelligent transportation system applications, a tremendous amount of multi-view video data has emerged to enhance vehicle perception. However, performing video analytics efficiently by exploiting the spatial-temporal redundancy from video data remains challenging. Accordingly, we propose a novel traffic-related framework named CEVAS to achieve efficient object detection using multi-view video data. Briefly, a fine-grained input filtering policy is introduced to produce a reasonable region of interest from the captured images. Also, we design a sharing object manager to manage the information of objects with spatial redundancy and share their results with other vehicles. We further derive a content-aware model selection policy to select detection methods adaptively. Experimental results show that our framework significantly reduces response latency while achieving the same detection accuracy as the state-of-the-art methods.
MVKT-ECG: Efficient Single-lead ECG Classification on Multi-Label Arrhythmia by Multi-View Knowledge Transferring
Jan 28, 2023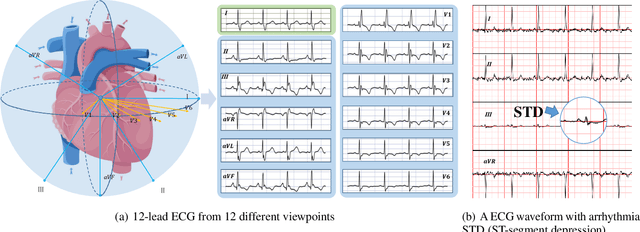
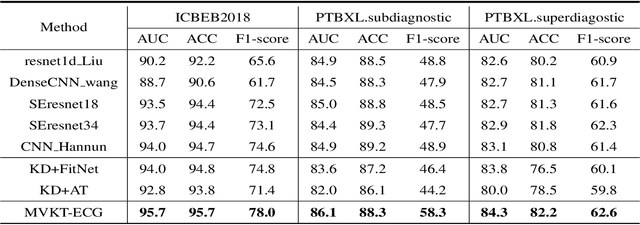
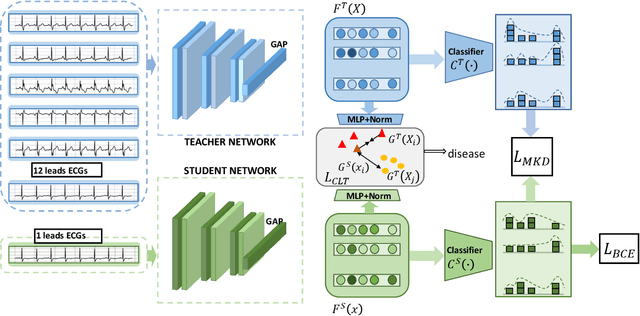
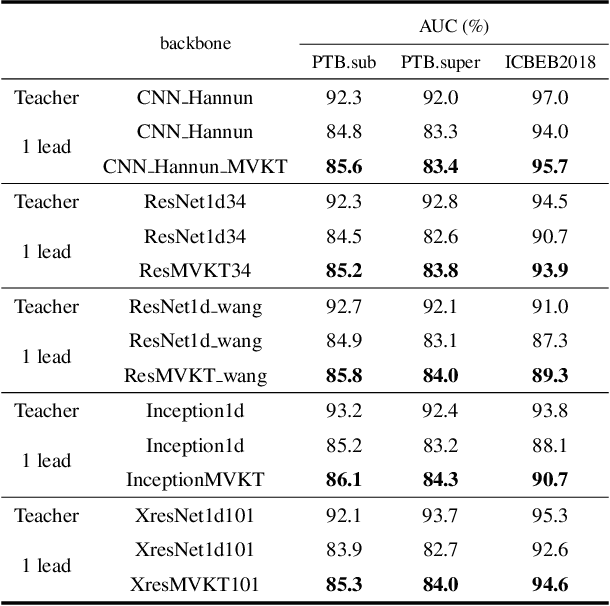
The widespread emergence of smart devices for ECG has sparked demand for intelligent single-lead ECG-based diagnostic systems. However, it is challenging to develop a single-lead-based ECG interpretation model for multiple diseases diagnosis due to the lack of some key disease information. In this work, we propose inter-lead Multi-View Knowledge Transferring of ECG (MVKT-ECG) to boost single-lead ECG's ability for multi-label disease diagnosis. This training strategy can transfer superior disease knowledge from multiple different views of ECG (e.g. 12-lead ECG) to single-lead-based ECG interpretation model to mine details in single-lead ECG signals that are easily overlooked by neural networks. MVKT-ECG allows this lead variety as a supervision signal within a teacher-student paradigm, where the teacher observes multi-lead ECG educates a student who observes only single-lead ECG. Since the mutual disease information between the single-lead ECG and muli-lead ECG plays a key role in knowledge transferring, we present a new disease-aware Contrastive Lead-information Transferring(CLT) to improve the mutual disease information between the single-lead ECG and muli-lead ECG. Moreover, We modify traditional Knowledge Distillation to multi-label disease Knowledge Distillation (MKD) to make it applicable for multi-label disease diagnosis. The comprehensive experiments verify that MVKT-ECG has an excellent performance in improving the diagnostic effect of single-lead ECG.
Frequency and Scale Perspectives of Feature Extraction
Feb 24, 2023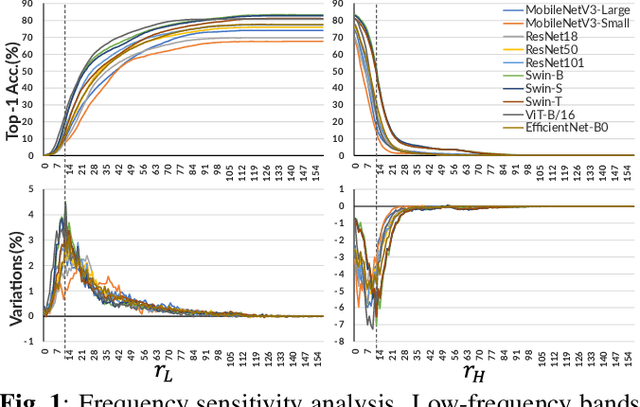
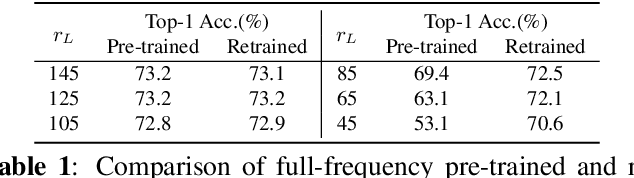

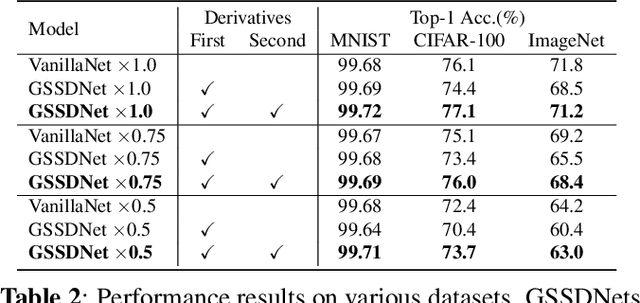
Convolutional neural networks (CNNs) have achieved superior performance but still lack clarity about the nature and properties of feature extraction. In this paper, by analyzing the sensitivity of neural networks to frequencies and scales, we find that neural networks not only have low- and medium-frequency biases but also prefer different frequency bands for different classes, and the scale of objects influences the preferred frequency bands. These observations lead to the hypothesis that neural networks must learn the ability to extract features at various scales and frequencies. To corroborate this hypothesis, we propose a network architecture based on Gaussian derivatives, which extracts features by constructing scale space and employing partial derivatives as local feature extraction operators to separate high-frequency information. This manually designed method of extracting features from different scales allows our GSSDNets to achieve comparable accuracy with vanilla networks on various datasets.
Improving Speech Enhancement via Event-based Query
Feb 24, 2023
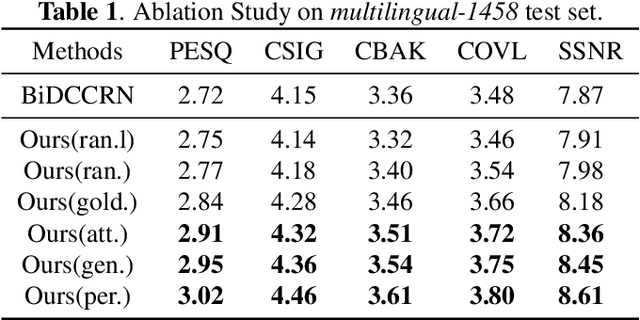
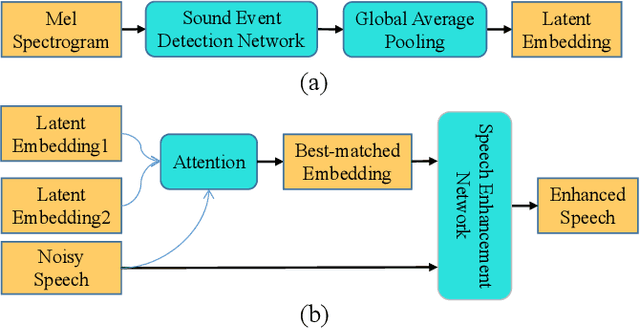
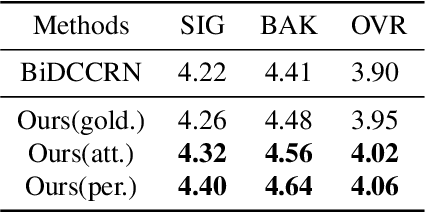
Existing deep learning based speech enhancement (SE) methods either use blind end-to-end training or explicitly incorporate speaker embedding or phonetic information into the SE network to enhance speech quality. In this paper, we perceive speech and noises as different types of sound events and propose an event-based query method for SE. Specifically, representative speech embeddings that can discriminate speech with noises are first pre-trained with the sound event detection (SED) task. The embeddings are then clustered into fixed golden speech queries to assist the SE network to enhance the speech from noisy audio. The golden speech queries can be obtained offline and generalizable to different SE datasets and networks. Therefore, little extra complexity is introduced and no enrollment is needed for each speaker. Experimental results show that the proposed method yields significant gains compared with baselines and the golden queries are well generalized to different datasets.
DCLP: Neural Architecture Predictor with Curriculum Contrastive Learning
Feb 25, 2023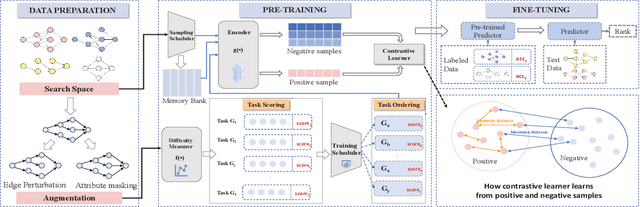
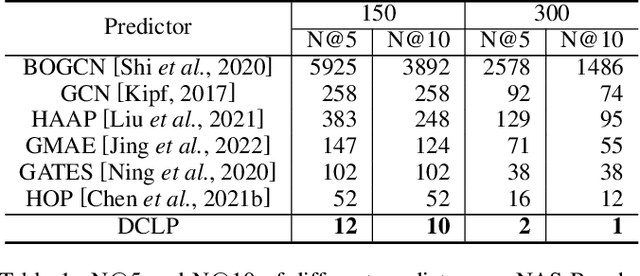
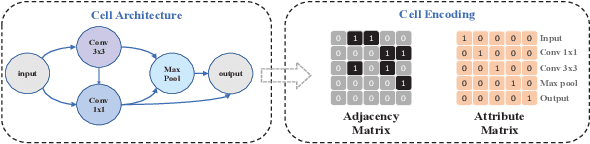

Neural predictors currently show great potential in the performance evaluation phase of neural architecture search (NAS). Despite their efficiency in the evaluation process, it is challenging to train the predictor with fewer architecture evaluations for efficient NAS. However, most of the current approaches are more concerned with improving the structure of the predictor to solve this problem, while the full use of the information contained in unlabeled data is less explored. To address this issue, we introduce a contrastive learning framework with curriculum learning guidance for the neural predictor called DCLP. To be specific, we develop a plan for the training order of positive samples during pre-training through the proposed difficulty measurer and training scheduler, and utilize the contrastive learner to learn representations of data. Compared with existing predictors, we experimentally demonstrate that DCLP has high accuracy and efficiency, and also shows an encouraging ability to discover superior architectures in multiple search spaces when combined with search strategies.