 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Streamlining models with explanations in the learning loop
Feb 15, 2023
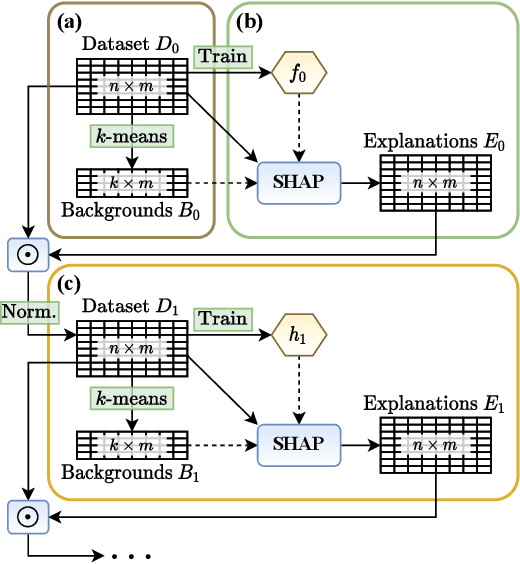
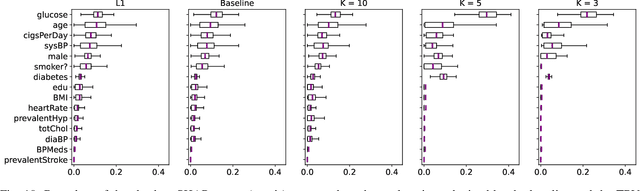
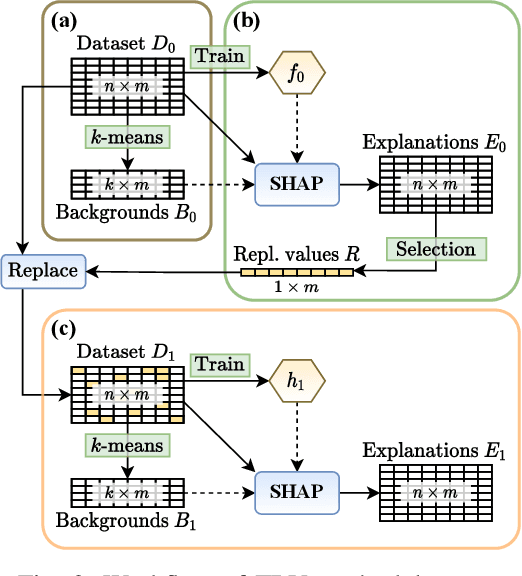
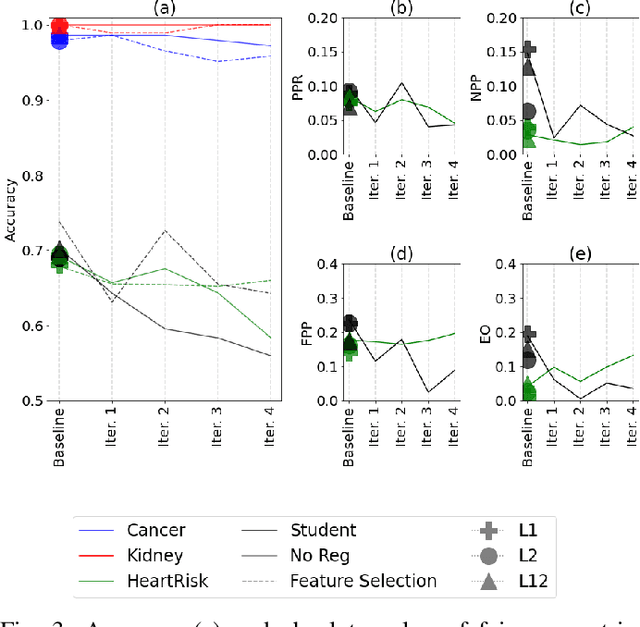
Several explainable AI methods allow a Machine Learning user to get insights on the classification process of a black-box model in the form of local linear explanations. With such information, the user can judge which features are locally relevant for the classification outcome, and get an understanding of how the model reasons. Standard supervised learning processes are purely driven by the original features and target labels, without any feedback loop informed by the local relevance of the features identified by the post-hoc explanations. In this paper, we exploit this newly obtained information to design a feature engineering phase, where we combine explanations with feature values. To do so, we develop two different strategies, named Iterative Dataset Weighting and Targeted Replacement Values, which generate streamlined models that better mimic the explanation process presented to the user. We show how these streamlined models compare to the original black-box classifiers, in terms of accuracy and compactness of the newly produced explanations.
* 16 pages, 10 figures, available repository
Model Extraction Attacks on Split Federated Learning
Mar 13, 2023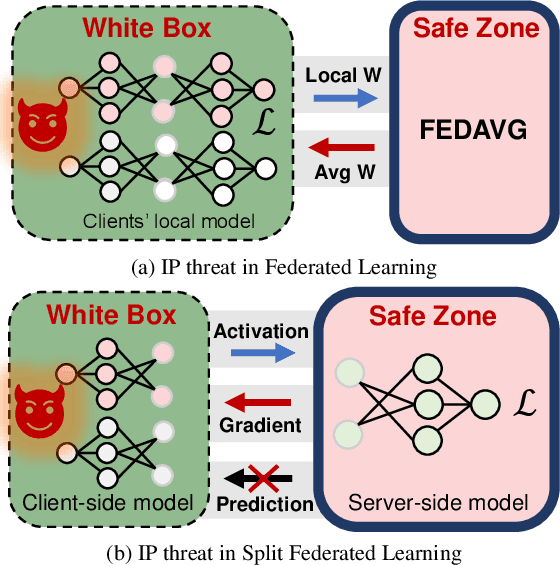
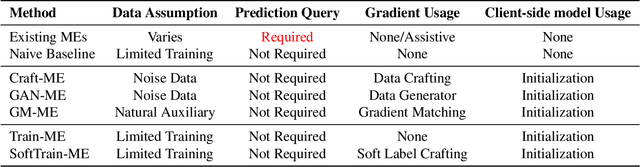
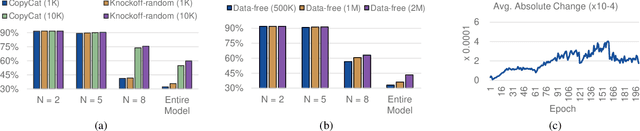
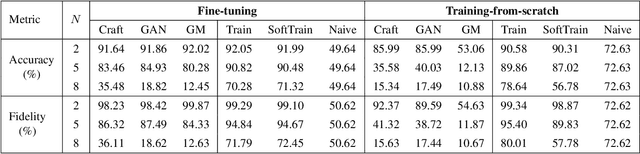
Federated Learning (FL) is a popular collaborative learning scheme involving multiple clients and a server. FL focuses on protecting clients' data but turns out to be highly vulnerable to Intellectual Property (IP) threats. Since FL periodically collects and distributes the model parameters, a free-rider can download the latest model and thus steal model IP. Split Federated Learning (SFL), a recent variant of FL that supports training with resource-constrained clients, splits the model into two, giving one part of the model to clients (client-side model), and the remaining part to the server (server-side model). Thus SFL prevents model leakage by design. Moreover, by blocking prediction queries, it can be made resistant to advanced IP threats such as traditional Model Extraction (ME) attacks. While SFL is better than FL in terms of providing IP protection, it is still vulnerable. In this paper, we expose the vulnerability of SFL and show how malicious clients can launch ME attacks by querying the gradient information from the server side. We propose five variants of ME attack which differs in the gradient usage as well as in the data assumptions. We show that under practical cases, the proposed ME attacks work exceptionally well for SFL. For instance, when the server-side model has five layers, our proposed ME attack can achieve over 90% accuracy with less than 2% accuracy degradation with VGG-11 on CIFAR-10.
Improving Out-of-Distribution Generalization of Neural Rerankers with Contextualized Late Interaction
Feb 13, 2023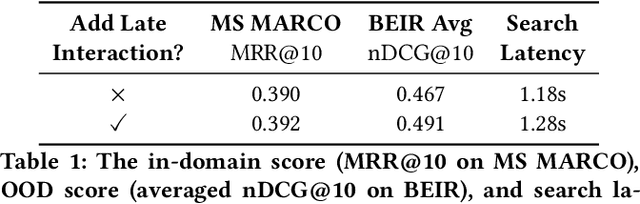

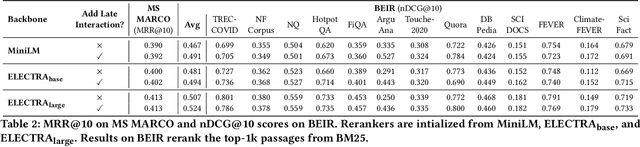
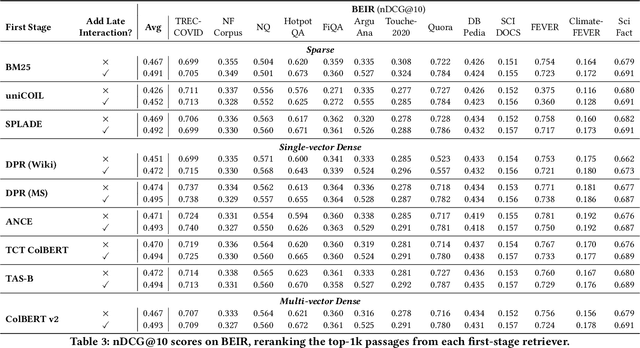
Recent progress in information retrieval finds that embedding query and document representation into multi-vector yields a robust bi-encoder retriever on out-of-distribution datasets. In this paper, we explore whether late interaction, the simplest form of multi-vector, is also helpful to neural rerankers that only use the [CLS] vector to compute the similarity score. Although intuitively, the attention mechanism of rerankers at the previous layers already gathers the token-level information, we find adding late interaction still brings an extra 5% improvement in average on out-of-distribution datasets, with little increase in latency and no degradation in in-domain effectiveness. Through extensive experiments and analysis, we show that the finding is consistent across different model sizes and first-stage retrievers of diverse natures and that the improvement is more prominent on longer queries.
Exploiting spatial information with the informed complex-valued spatial autoencoder for target speaker extraction
Oct 27, 2022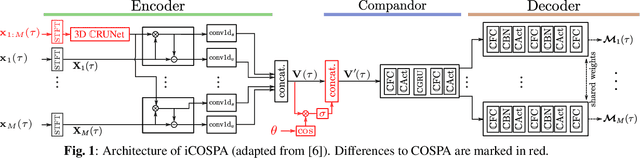
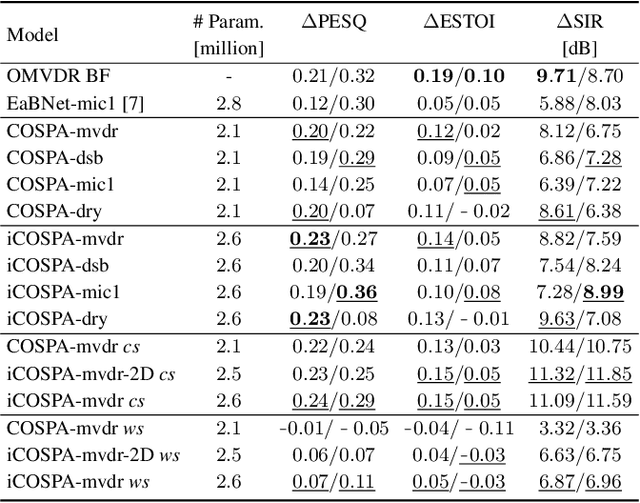
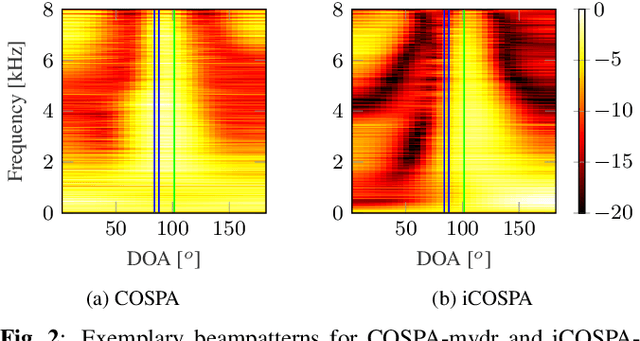
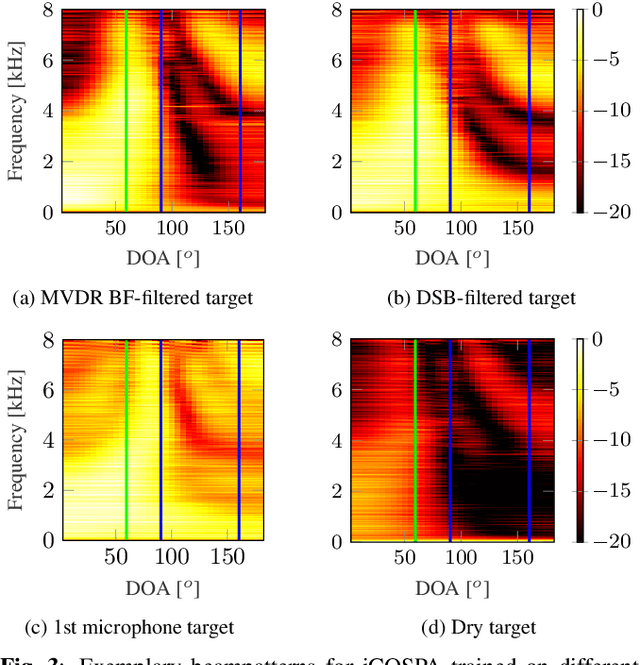
In conventional multichannel audio signal enhancement, spatial and spectral filtering are often performed sequentially. In contrast, it has been shown that for neural spatial filtering a joint approach of spectro-spatial filtering is more beneficial. In this contribution, we investigate the influence of the training target on the spatial selectivity of such a time-varying spectro-spatial filter. We extend the recently proposed complex-valued spatial autoencoder (COSPA) for target speaker extraction by leveraging its interpretable structure and purposefully informing the network of the target speaker's position. Consequently, this approach uses a multichannel complex-valued neural network architecture that is capable of processing spatial and spectral information rendering informed COSPA (iCOSPA) an effective neural spatial filtering method. We train iCOSPA for several training targets that enforce different amounts of spatial processing and analyze the network's spatial filtering capacity. We find that the proposed architecture is indeed capable of learning different spatial selectivity patterns to attain the different training targets.
CoSyn: Detecting Implicit Hate Speech in Online Conversations Using a Context Synergized Hyperbolic Network
Mar 10, 2023
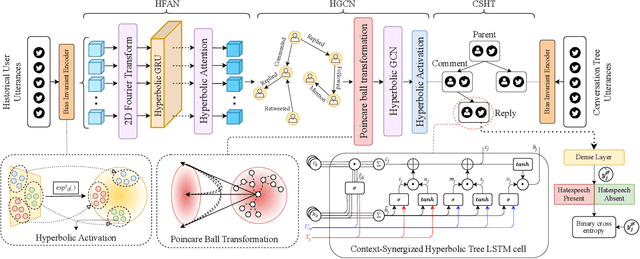
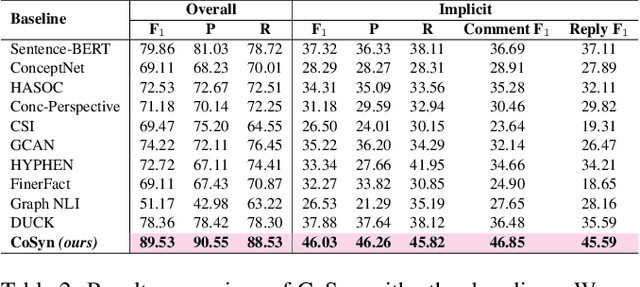
The tremendous growth of social media users interacting in online conversations has also led to significant growth in hate speech. Most of the prior works focus on detecting explicit hate speech, which is overt and leverages hateful phrases, with very little work focusing on detecting hate speech that is implicit or denotes hatred through indirect or coded language. In this paper, we present CoSyn, a user- and conversational-context synergized network for detecting implicit hate speech in online conversation trees. CoSyn first models the user's personal historical and social context using a novel hyperbolic Fourier attention mechanism and hyperbolic graph convolution network. Next, we jointly model the user's personal context and the conversational context using a novel context interaction mechanism in the hyperbolic space that clearly captures the interplay between the two and makes independent assessments on the amounts of information to be retrieved from both contexts. CoSyn performs all operations in the hyperbolic space to account for the scale-free dynamics of social media. We demonstrate the effectiveness of CoSyn both qualitatively and quantitatively on an open-source hate speech dataset with Twitter conversations and show that CoSyn outperforms all our baselines in detecting implicit hate speech with absolute improvements in the range of 8.15% - 19.50%.
Lifelong Machine Learning Potentials
Mar 10, 2023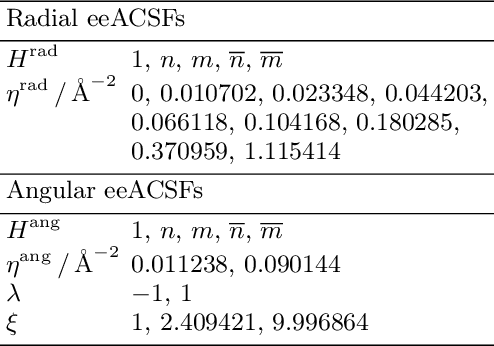
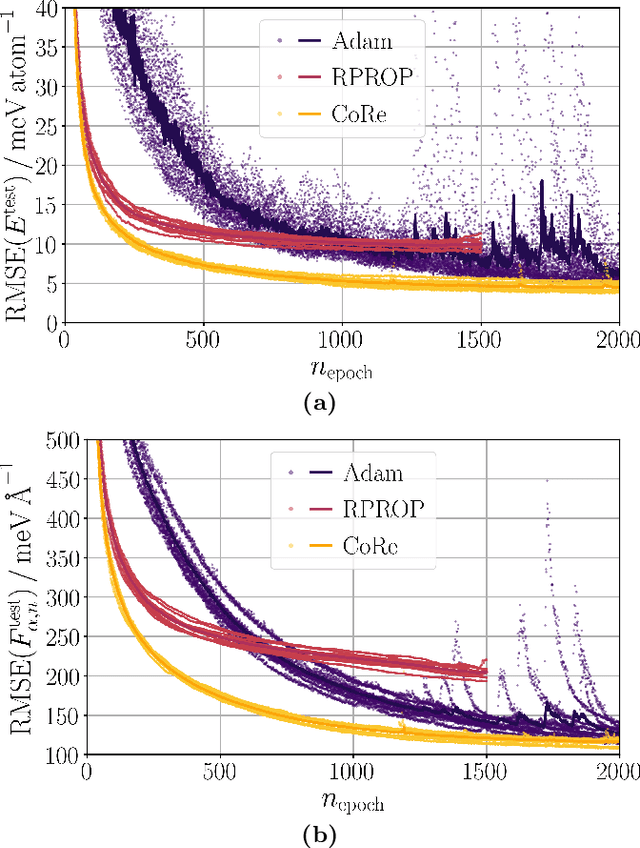
Machine learning potentials (MLPs) trained on accurate quantum chemical data can retain the high accuracy, while inflicting little computational demands. On the downside, they need to be trained for each individual system. In recent years, a vast number of MLPs has been trained from scratch because learning additional data typically requires to train again on all data to not forget previously acquired knowledge. Additionally, most common structural descriptors of MLPs cannot represent efficiently a large number of different chemical elements. In this work, we tackle these problems by introducing element-embracing atom-centered symmetry functions (eeACSFs) which combine structural properties and element information from the periodic table. These eeACSFs are a key for our development of a lifelong machine learning potential (lMLP). Uncertainty quantification can be exploited to transgress a fixed, pre-trained MLP to arrive at a continuously adapting lMLP, because a predefined level of accuracy can be ensured. To extend the applicability of an lMLP to new systems, we apply continual learning strategies to enable autonomous and on-the-fly training on a continuous stream of new data. For the training of deep neural networks, we propose the continual resilient (CoRe) optimizer and incremental learning strategies relying on rehearsal of data, regularization of parameters, and the architecture of the model.
An Adaptive GViT for Gas Mixture Identification and Concentration Estimation
Mar 10, 2023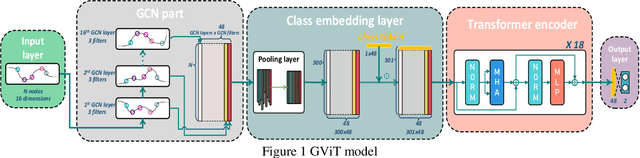
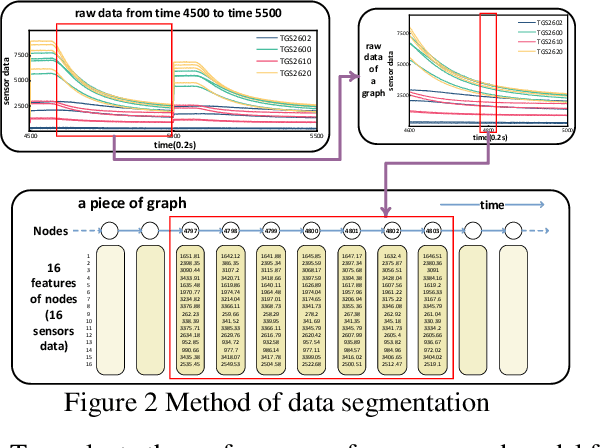
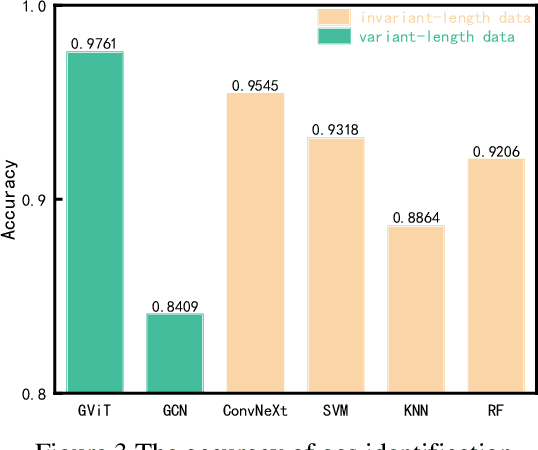
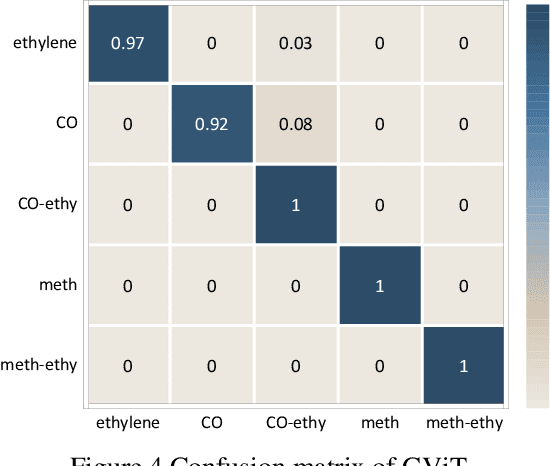
Estimating the composition and concentration of ambient gases is crucial for industrial gas safety. Even though other researchers have proposed some gas identification and con-centration estimation algorithms, these algorithms still suffer from severe flaws, particularly in fulfilling industry demands. One example is that the lengths of data collected in an industrial setting tend to vary. The conventional algorithm, yet, cannot be used to analyze the variant-length data effectively. Trimming the data will preserve only steady-state values, inevitably leading to the loss of vital information. The gas identification and concentration estimation model called GCN-ViT(GViT) is proposed in this paper; we view the sensor data to be a one-way chain that has only been downscaled to retain the majority of the original in-formation. The GViT model can directly utilize sensor ar-rays' variable-length real-time signal data as input. We validated the above model on a dataset of 12-hour uninterrupted monitoring of two randomly varying gas mixtures, CO-ethylene and methane-ethylene. The accuracy of gas identification can reach 97.61%, R2 of the pure gas concentration estimation is above 99.5% on average, and R2 of the mixed gas concentration estimation is above 95% on average.
Understanding and Constructing Latent Modality Structures in Multi-modal Representation Learning
Mar 10, 2023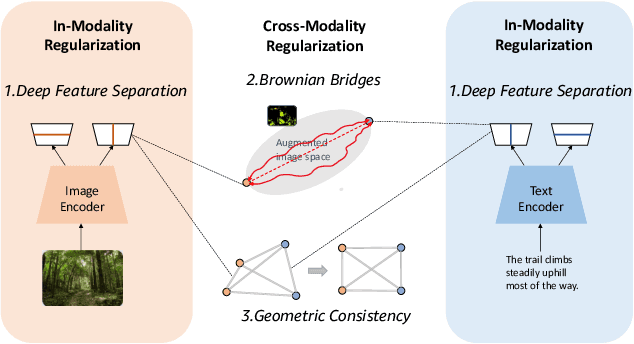


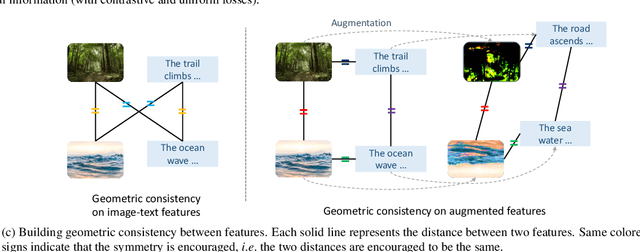
Contrastive loss has been increasingly used in learning representations from multiple modalities. In the limit, the nature of the contrastive loss encourages modalities to exactly match each other in the latent space. Yet it remains an open question how the modality alignment affects the downstream task performance. In this paper, based on an information-theoretic argument, we first prove that exact modality alignment is sub-optimal in general for downstream prediction tasks. Hence we advocate that the key of better performance lies in meaningful latent modality structures instead of perfect modality alignment. To this end, we propose three general approaches to construct latent modality structures. Specifically, we design 1) a deep feature separation loss for intra-modality regularization; 2) a Brownian-bridge loss for inter-modality regularization; and 3) a geometric consistency loss for both intra- and inter-modality regularization. Extensive experiments are conducted on two popular multi-modal representation learning frameworks: the CLIP-based two-tower model and the ALBEF-based fusion model. We test our model on a variety of tasks including zero/few-shot image classification, image-text retrieval, visual question answering, visual reasoning, and visual entailment. Our method achieves consistent improvements over existing methods, demonstrating the effectiveness and generalizability of our proposed approach on latent modality structure regularization.
Finetuning Pretrained Vision-Language Models with Correlation Information Bottleneck for Robust Visual Question Answering
Sep 14, 2022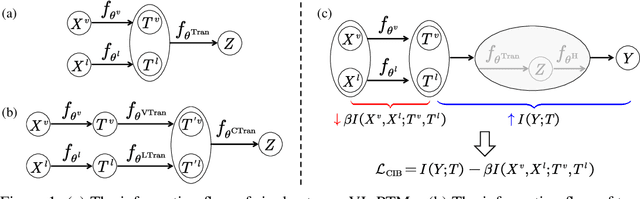
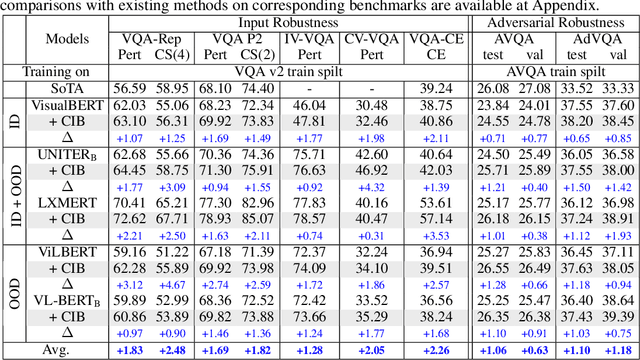
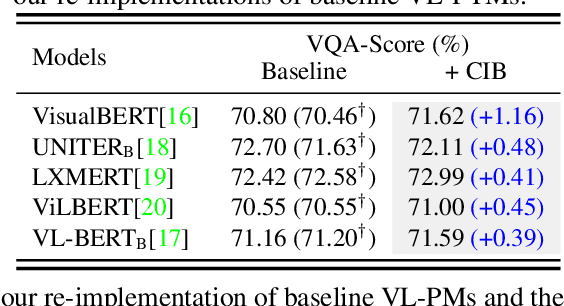

Benefiting from large-scale Pretrained Vision-Language Models (VL-PMs), the performance of Visual Question Answering (VQA) has started to approach human oracle performance. However, finetuning large-scale VL-PMs with limited data for VQA usually faces overfitting and poor generalization issues, leading to a lack of robustness. In this paper, we aim to improve the robustness of VQA systems (ie, the ability of the systems to defend against input variations and human-adversarial attacks) from the perspective of Information Bottleneck when finetuning VL-PMs for VQA. Generally, internal representations obtained by VL-PMs inevitably contain irrelevant and redundant information for the downstream VQA task, resulting in statistically spurious correlations and insensitivity to input variations. To encourage representations to converge to a minimal sufficient statistic in vision-language learning, we propose the Correlation Information Bottleneck (CIB) principle, which seeks a tradeoff between representation compression and redundancy by minimizing the mutual information (MI) between the inputs and internal representations while maximizing the MI between the outputs and the representations. Meanwhile, CIB measures the internal correlations among visual and linguistic inputs and representations by a symmetrized joint MI estimation. Extensive experiments on five VQA benchmarks of input robustness and two VQA benchmarks of human-adversarial robustness demonstrate the effectiveness and superiority of the proposed CIB in improving the robustness of VQA systems.
Hashtag-Guided Low-Resource Tweet Classification
Feb 20, 2023
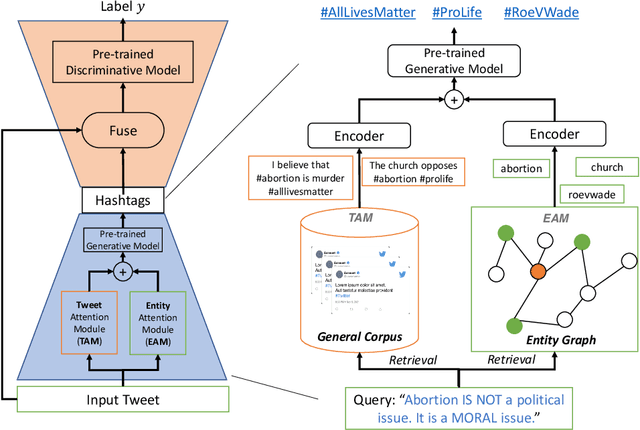

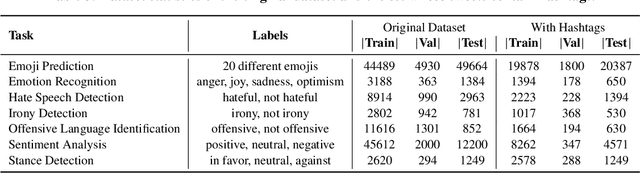
Social media classification tasks (e.g., tweet sentiment analysis, tweet stance detection) are challenging because social media posts are typically short, informal, and ambiguous. Thus, training on tweets is challenging and demands large-scale human-annotated labels, which are time-consuming and costly to obtain. In this paper, we find that providing hashtags to social media tweets can help alleviate this issue because hashtags can enrich short and ambiguous tweets in terms of various information, such as topic, sentiment, and stance. This motivates us to propose a novel Hashtag-guided Tweet Classification model (HashTation), which automatically generates meaningful hashtags for the input tweet to provide useful auxiliary signals for tweet classification. To generate high-quality and insightful hashtags, our hashtag generation model retrieves and encodes the post-level and entity-level information across the whole corpus. Experiments show that HashTation achieves significant improvements on seven low-resource tweet classification tasks, in which only a limited amount of training data is provided, showing that automatically enriching tweets with model-generated hashtags could significantly reduce the demand for large-scale human-labeled data. Further analysis demonstrates that HashTation is able to generate high-quality hashtags that are consistent with the tweets and their labels. The code is available at https://github.com/shizhediao/HashTation.