 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ESceme: Vision-and-Language Navigation with Episodic Scene Memory
Mar 07, 2023
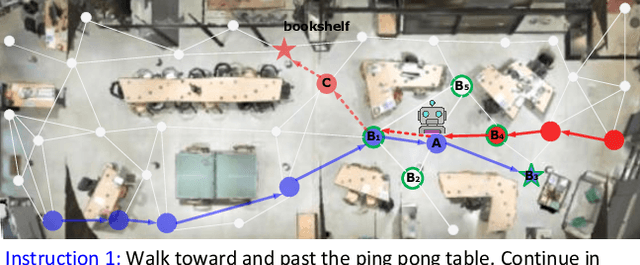
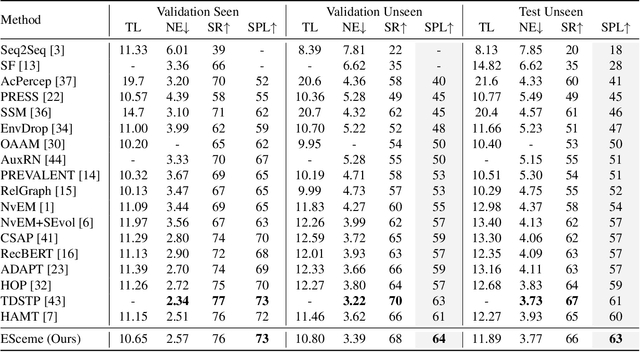
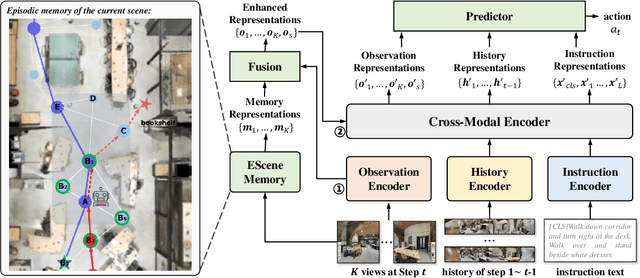
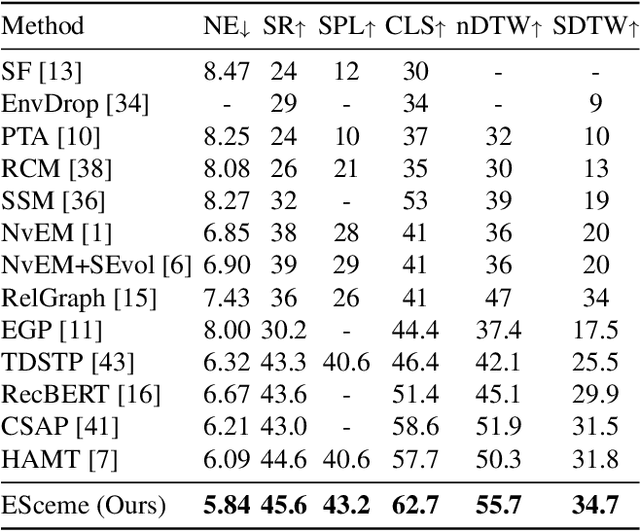
Vision-and-language navigation (VLN) simulates a visual agent that follows natural-language navigation instructions in real-world scenes. Existing approaches have made enormous progress in navigation in new environments, such as beam search, pre-exploration, and dynamic or hierarchical history encoding. To balance generalization and efficiency, we resort to memorizing visited scenarios apart from the ongoing route while navigating. In this work, we introduce a mechanism of Episodic Scene memory (ESceme) for VLN that wakes an agent's memories of past visits when it enters the current scene. The episodic scene memory allows the agent to envision a bigger picture of the next prediction. This way, the agent learns to utilize dynamically updated information instead of merely adapting to static observations. We provide a simple yet effective implementation of ESceme by enhancing the accessible views at each location and progressively completing the memory while navigating. We verify the superiority of ESceme on short-horizon (R2R), long-horizon (R4R), and vision-and-dialog (CVDN) VLN tasks. Our ESceme also wins first place on the CVDN leaderboard. Code is available: \url{https://github.com/qizhust/esceme}.}
Parsing Line Segments of Floor Plan Images Using Graph Neural Networks
Mar 07, 2023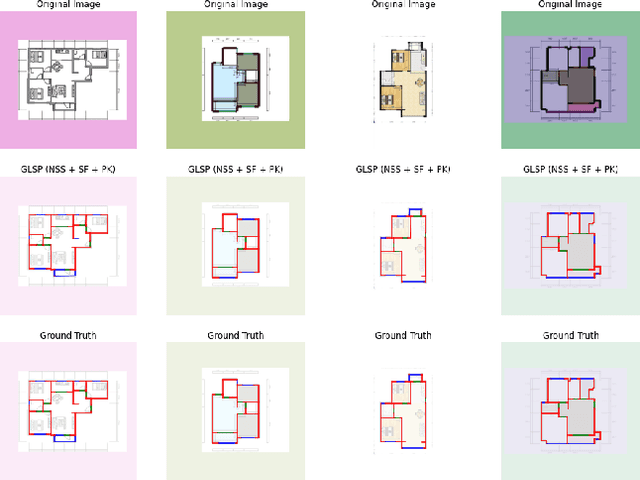
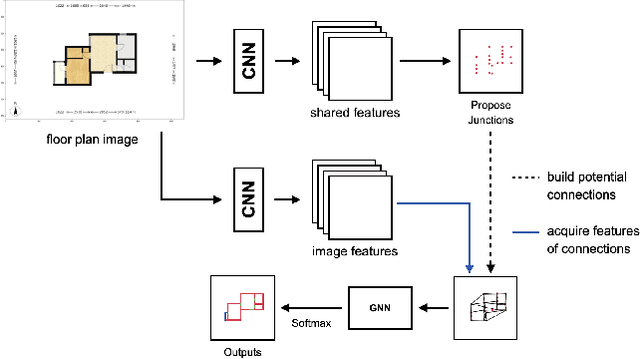
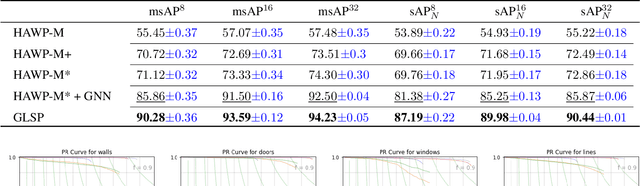

In this paper, we present a GNN-based Line Segment Parser (GLSP), which uses a junction heatmap to predict line segments' endpoints, and graph neural networks to extract line segments and their categories. Different from previous floor plan recognition methods, which rely on semantic segmentation, our proposed method is able to output vectorized line segment and requires less post-processing steps to be put into practical use. Our experiments show that the methods outperform state-of-the-art line segment detection models on multi-class line segment detection tasks with floor plan images. In the paper, we use our floor plan dataset named Large-scale Residential Floor Plan data (LRFP). The dataset contains a total of 271,035 floor plan images. The label corresponding to each picture contains the scale information, the categories and outlines of rooms, and the endpoint positions of line segments such as doors, windows, and walls. Our augmentation method makes the dataset adaptable to the drawing styles of as many countries and regions as possible.
Building Shortcuts between Distant Nodes with Biaffine Mapping for Graph Convolutional Networks
Feb 17, 2023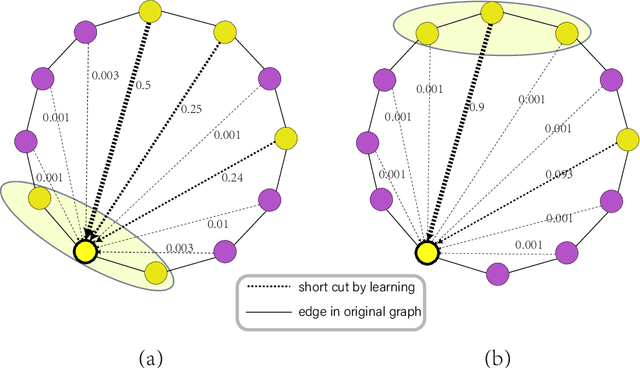
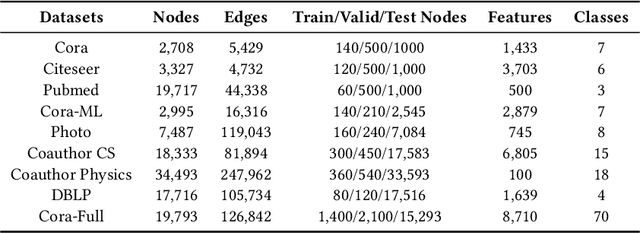
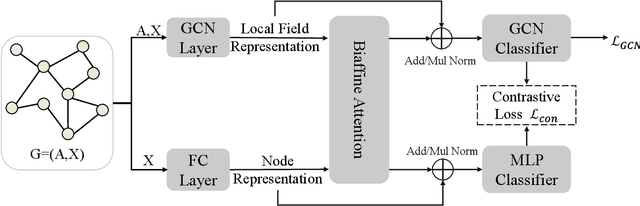
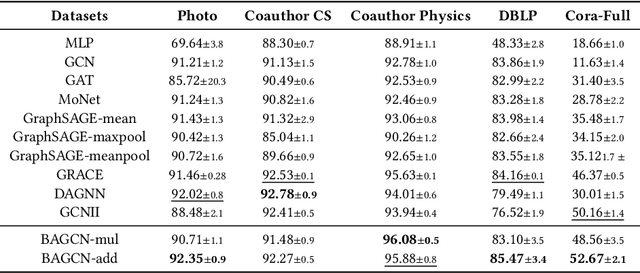
Multiple recent studies show a paradox in graph convolutional networks (GCNs), that is, shallow architectures limit the capability of learning information from high-order neighbors, while deep architectures suffer from over-smoothing or over-squashing. To enjoy the simplicity of shallow architectures and overcome their limits of neighborhood extension, in this work, we introduce Biaffine technique to improve the expressiveness of graph convolutional networks with a shallow architecture. The core design of our method is to learn direct dependency on long-distance neighbors for nodes, with which only one-hop message passing is capable of capturing rich information for node representation. Besides, we propose a multi-view contrastive learning method to exploit the representations learned from long-distance dependencies. Extensive experiments on nine graph benchmark datasets suggest that the shallow biaffine graph convolutional networks (BAGCN) significantly outperforms state-of-the-art GCNs (with deep or shallow architectures) on semi-supervised node classification. We further verify the effectiveness of biaffine design in node representation learning and the performance consistency on different sizes of training data.
Copula-based synthetic population generation
Feb 17, 2023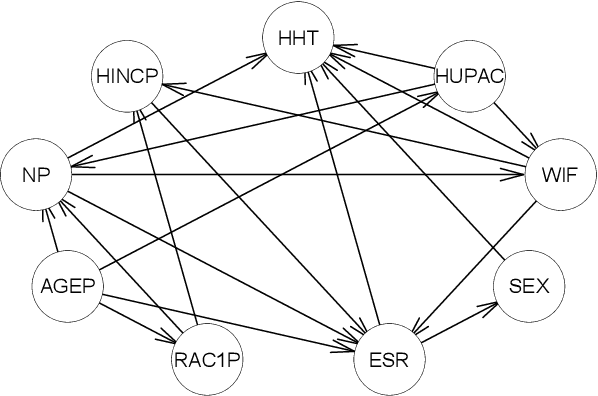
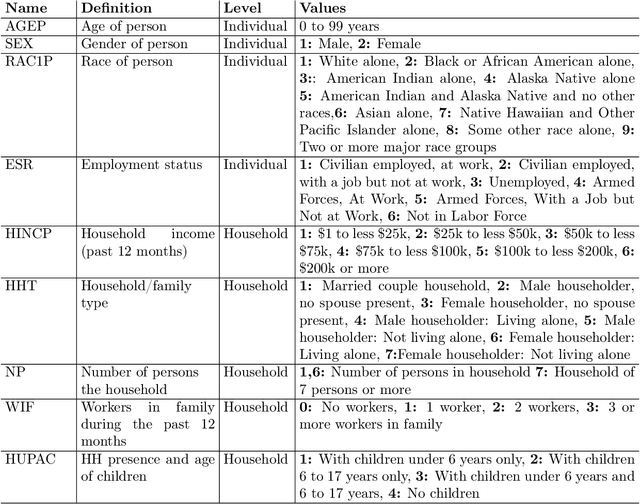
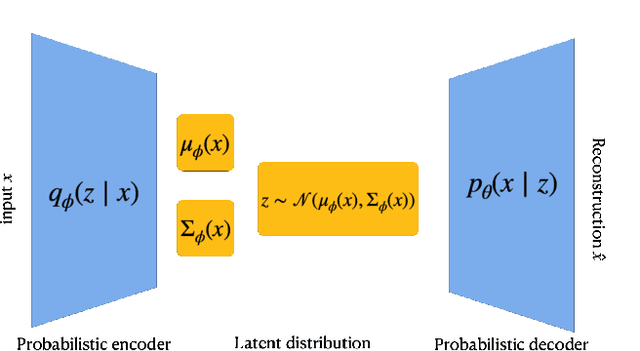
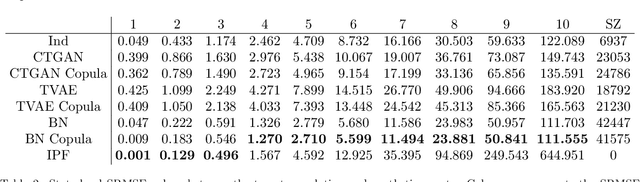
Population synthesis consists of generating synthetic but realistic representations of a target population of micro-agents for the purpose of behavioral modeling and simulation. We introduce a new framework based on copulas to generate synthetic data for a target population of which only the empirical marginal distributions are known by using a sample from another population sharing similar marginal dependencies. This makes it possible to include a spatial component in the generation of population synthesis and to combine various sources of information to obtain more realistic population generators. Specifically, we normalize the data and treat them as realizations of a given copula, and train a generative model on the normalized data before injecting the information on the marginals. We compare the copulas framework to IPF and to modern probabilistic approaches such as Bayesian networks, variational auto-encoders, and generative adversarial networks. We also illustrate on American Community Survey data that the method proposed allows to study the structure of the data at different geographical levels in a way that is robust to the peculiarities of the marginal distributions.
STACC: Code Comment Classification using SentenceTransformers
Feb 25, 2023
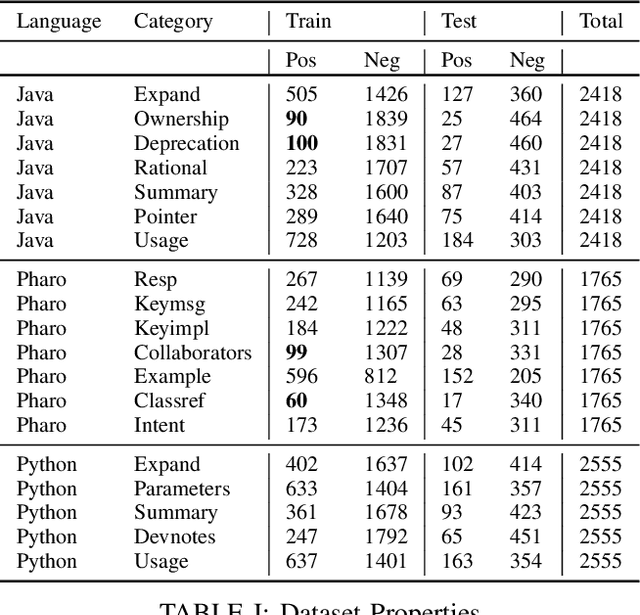


Code comments are a key resource for information about software artefacts. Depending on the use case, only some types of comments are useful. Thus, automatic approaches to classify these comments are proposed. In this work, we address this need by proposing, STACC, a set of SentenceTransformers-based binary classifiers. These lightweight classifiers are trained and tested on the NLBSE Code Comment Classification tool competition dataset, and surpass the baseline by a significant margin, achieving an average F1 score of 0.74 against the baseline of 0.31, which is an improvement of 139%. A replication package, as well as the models themselves, are publicly available.
A Laplace-inspired Distribution on SO(3) for Probabilistic Rotation Estimation
Mar 03, 2023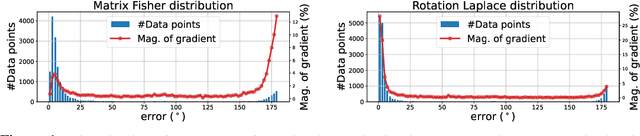
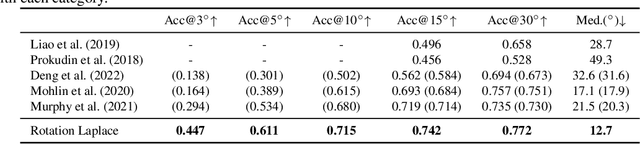
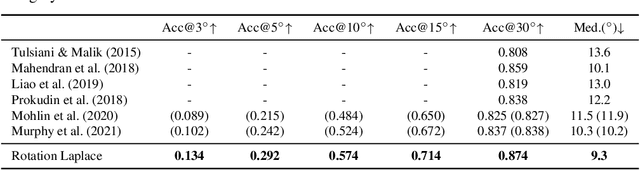
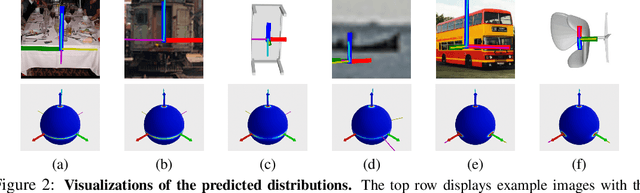
Estimating the 3DoF rotation from a single RGB image is an important yet challenging problem. Probabilistic rotation regression has raised more and more attention with the benefit of expressing uncertainty information along with the prediction. Though modeling noise using Gaussian-resembling Bingham distribution and matrix Fisher distribution is natural, they are shown to be sensitive to outliers for the nature of quadratic punishment to deviations. In this paper, we draw inspiration from multivariate Laplace distribution and propose a novel Rotation Laplace distribution on SO(3). Rotation Laplace distribution is robust to the disturbance of outliers and enforces much gradient to the low-error region, resulting in a better convergence. Our extensive experiments show that our proposed distribution achieves state-of-the-art performance for rotation regression tasks over both probabilistic and non-probabilistic baselines. Our project page is at https://pku-epic.github.io/RotationLaplace.
Exploiting spatial information with the informed complex-valued spatial autoencoder for target speaker extraction
Oct 27, 2022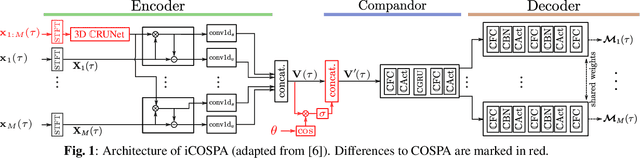
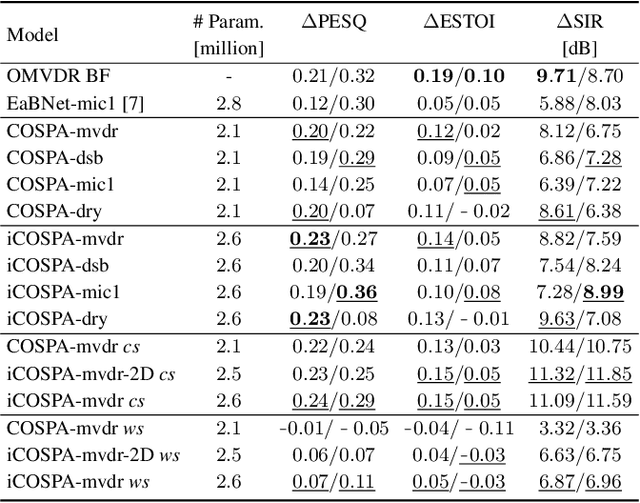
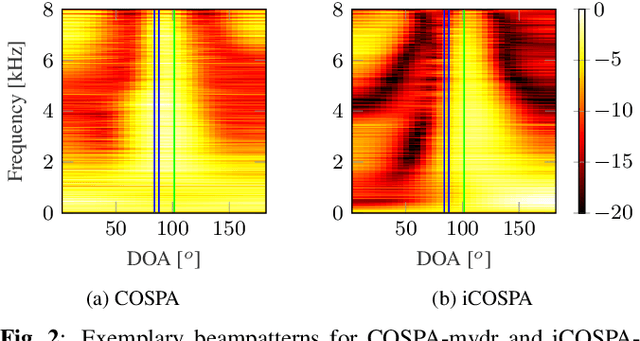
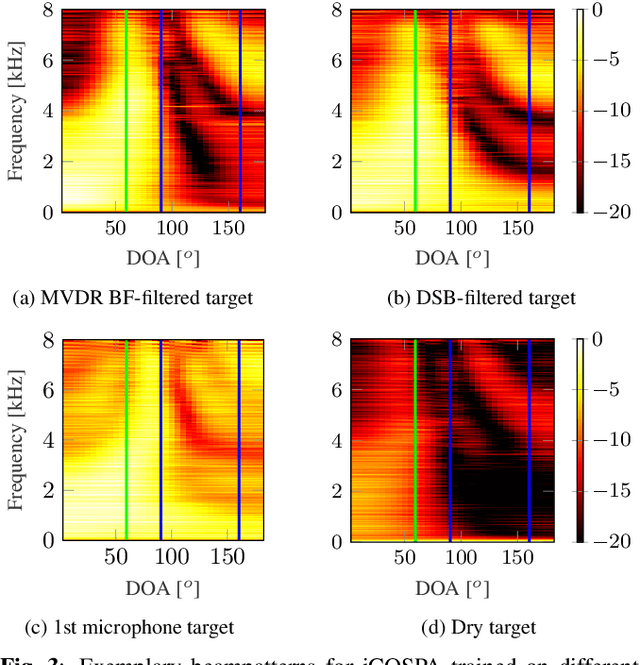
In conventional multichannel audio signal enhancement, spatial and spectral filtering are often performed sequentially. In contrast, it has been shown that for neural spatial filtering a joint approach of spectro-spatial filtering is more beneficial. In this contribution, we investigate the influence of the training target on the spatial selectivity of such a time-varying spectro-spatial filter. We extend the recently proposed complex-valued spatial autoencoder (COSPA) for target speaker extraction by leveraging its interpretable structure and purposefully informing the network of the target speaker's position. Consequently, this approach uses a multichannel complex-valued neural network architecture that is capable of processing spatial and spectral information rendering informed COSPA (iCOSPA) an effective neural spatial filtering method. We train iCOSPA for several training targets that enforce different amounts of spatial processing and analyze the network's spatial filtering capacity. We find that the proposed architecture is indeed capable of learning different spatial selectivity patterns to attain the different training targets.
Vision based Virtual Guidance for Navigation
Mar 05, 2023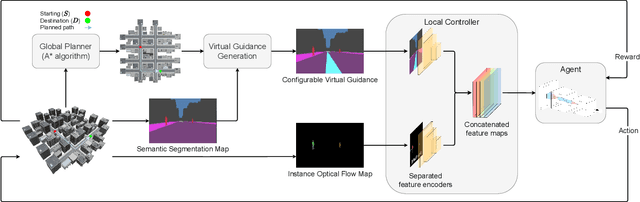

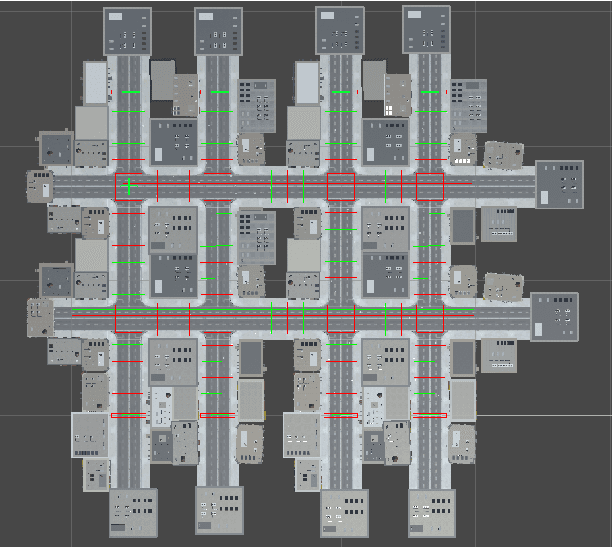
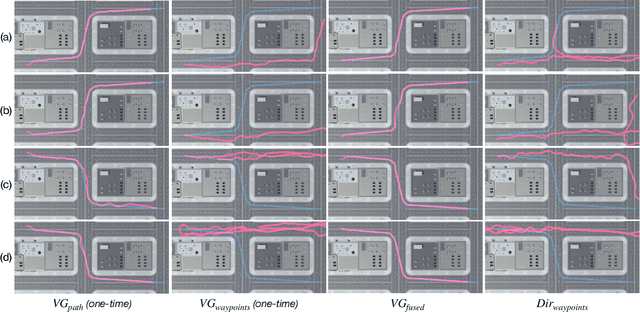
This paper explores the impact of virtual guidance on mid-level representation-based navigation, where an agent performs navigation tasks based solely on visual observations. Instead of providing distance measures or numerical directions to guide the agent, which may be difficult for it to interpret visually, the paper investigates the potential of different forms of virtual guidance schemes on navigation performance. Three schemes of virtual guidance signals are explored: virtual navigation path, virtual waypoints, and a combination of both. The experiments were conducted using a virtual city built with the Unity engine to train the agents while avoiding obstacles. The results show that virtual guidance provides the agent with more meaningful navigation information and achieves better performance in terms of path completion rates and navigation efficiency. In addition, a set of analyses were provided to investigate the failure cases and the navigated trajectories, and a pilot study was conducted for the real-world scenarios.
Rank and Condition Number Analysis for UAV MIMO Channels Using Ray Tracing
Mar 05, 2023
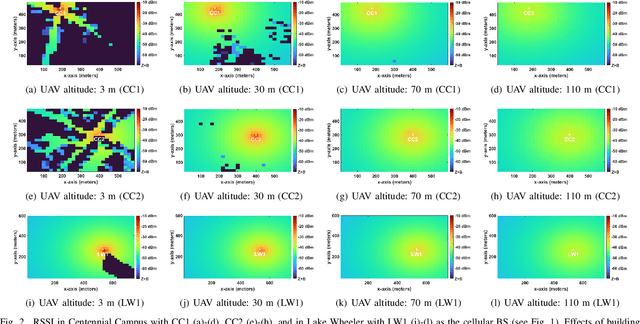
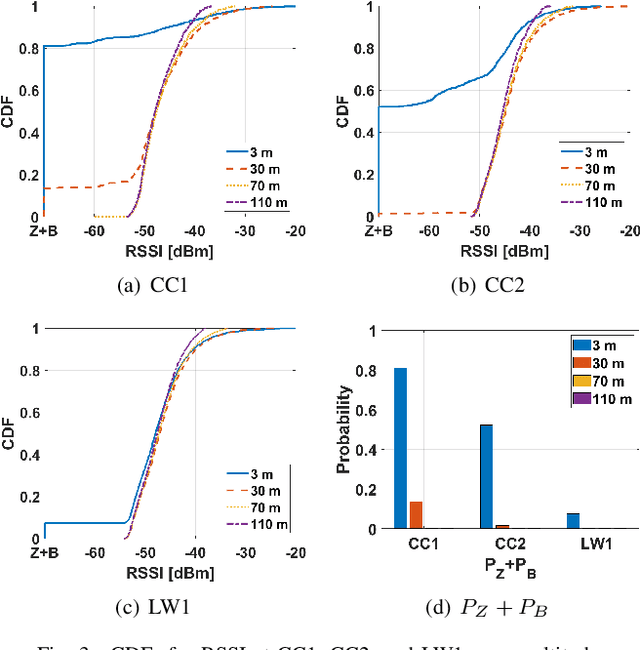
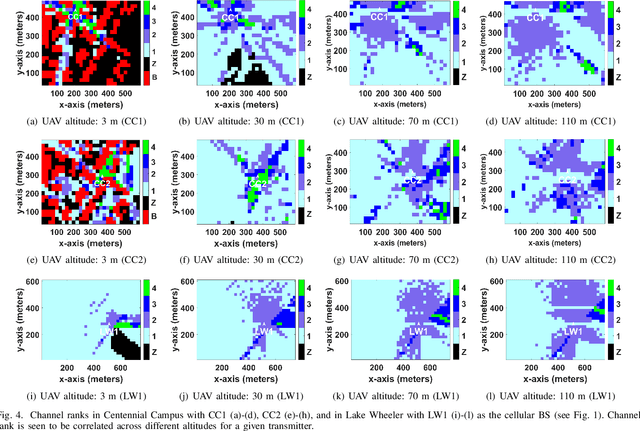
Channel rank and condition number of multi-input multi-output (MIMO) channels can be effective indicators of achievable rates with spatial multiplexing in mobile networks. In this paper, we use extensive ray tracing simulations to investigate channel rank, condition number, and signal coverage distribution for air-to-ground MIMO channels. We consider UAV-based user equipment (UE) at altitudes of 3 m, 30 m, 70 m, and 110 m from the ground. Moreover, we also consider their communication link with a cellular base station in urban and rural areas. In particular, Centennial Campus and Lake Wheeler Road Field Labs of NC State University are considered, and their geographical information extracted from the open street map (OSM) database is incorporated into ray tracing simulations. Our results characterize how the channel rank tends to reduce as a function of UAV altitude, while also providing insights into the effects of geography, building distribution, and threshold parameters on channel rank and condition number.
Ultrafast single-channel machine vision based on neuro-inspired photonic computing
Feb 15, 2023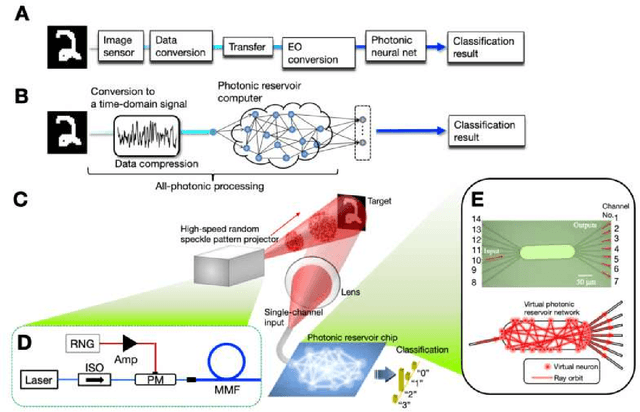
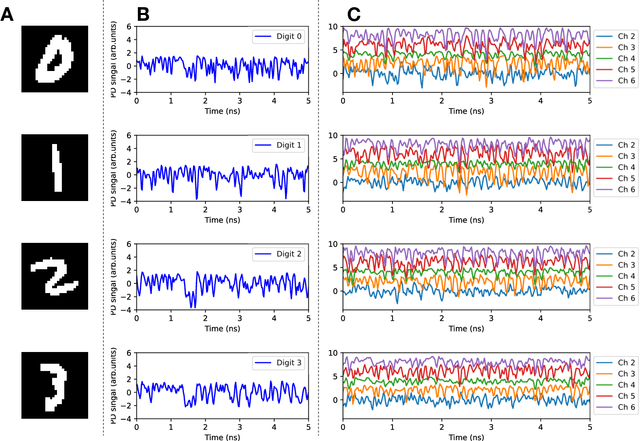
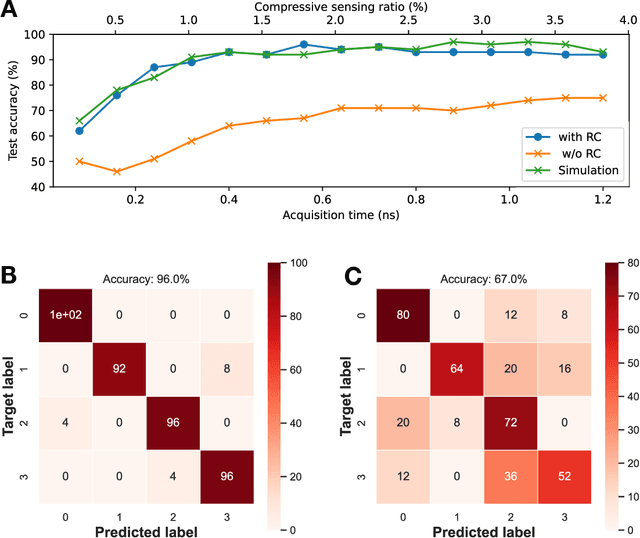
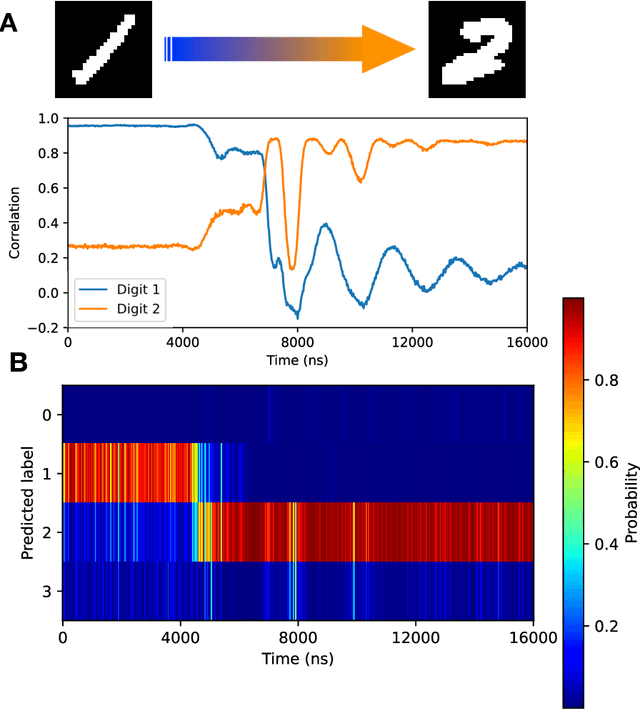
High-speed machine vision is increasing its importance in both scientific and technological applications. Neuro-inspired photonic computing is a promising approach to speed-up machine vision processing with ultralow latency. However, the processing rate is fundamentally limited by the low frame rate of image sensors, typically operating at tens of hertz. Here, we propose an image-sensor-free machine vision framework, which optically processes real-world visual information with only a single input channel, based on a random temporal encoding technique. This approach allows for compressive acquisitions of visual information with a single channel at gigahertz rates, outperforming conventional approaches, and enables its direct photonic processing using a photonic reservoir computer in a time domain. We experimentally demonstrate that the proposed approach is capable of high-speed image recognition and anomaly detection, and furthermore, it can be used for high-speed imaging. The proposed approach is multipurpose and can be extended for a wide range of applications, including tracking, controlling, and capturing sub-nanosecond phenomena.