 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Diffusion Model-Augmented Behavioral Cloning
Feb 26, 2023
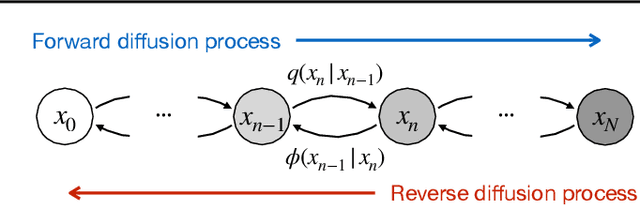
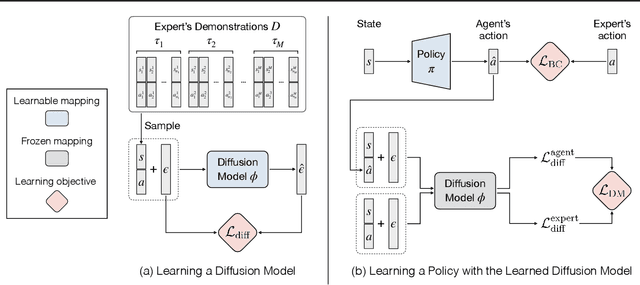
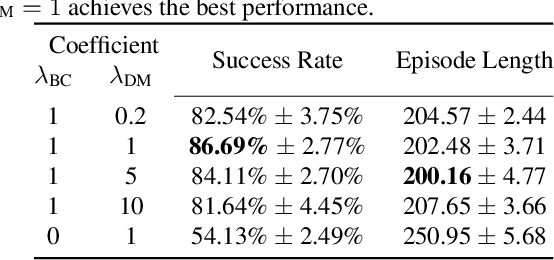
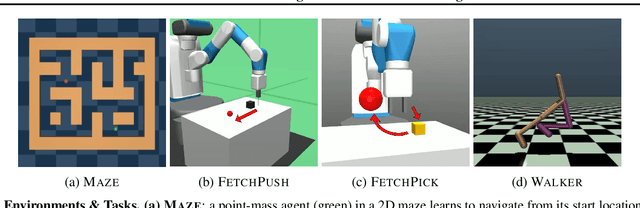
Imitation learning addresses the challenge of learning by observing an expert's demonstrations without access to reward signals from the environment. Behavioral cloning (BC) formulates imitation learning as a supervised learning problem and learns from sampled state-action pairs. Despite its simplicity, it often fails to capture the temporal structure of the task and the global information of expert demonstrations. This work aims to augment BC by employing diffusion models for modeling expert behaviors, and designing a learning objective that leverages learned diffusion models to guide policy learning. To this end, we propose diffusion model-augmented behavioral cloning (Diffusion-BC) that combines our proposed diffusion model guided learning objective with the BC objective, which complements each other. Our proposed method outperforms baselines or achieves competitive performance in various continuous control domains, including navigation, robot arm manipulation, and locomotion. Ablation studies justify our design choices and investigate the effect of balancing the BC and our proposed diffusion model objective.
HARDC : A novel ECG-based heartbeat classification method to detect arrhythmia using hierarchical attention based dual structured RNN with dilated CNN
Mar 06, 2023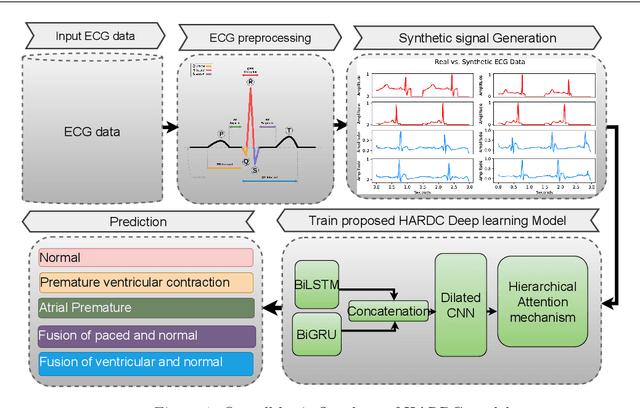
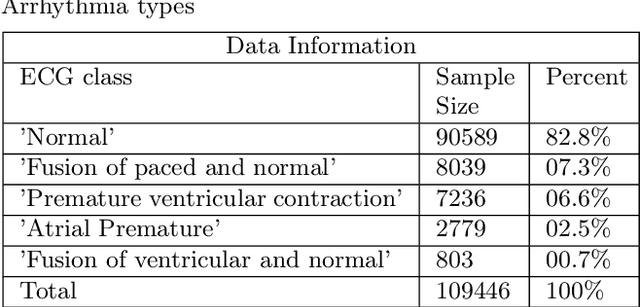
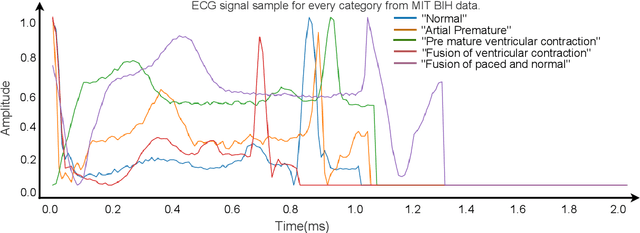
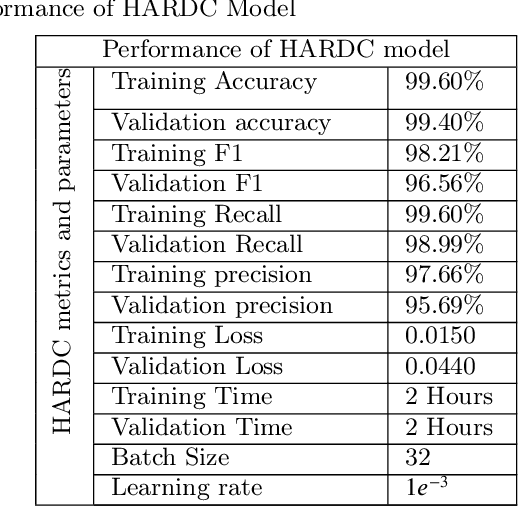
In this paper have developed a novel hybrid hierarchical attention-based bidirectional recurrent neural network with dilated CNN (HARDC) method for arrhythmia classification. This solves problems that arise when traditional dilated convolutional neural network (CNN) models disregard the correlation between contexts and gradient dispersion. The proposed HARDC fully exploits the dilated CNN and bidirectional recurrent neural network unit (BiGRU-BiLSTM) architecture to generate fusion features. As a result of incorporating both local and global feature information and an attention mechanism, the model's performance for prediction is improved.By combining the fusion features with a dilated CNN and a hierarchical attention mechanism, the trained HARDC model showed significantly improved classification results and interpretability of feature extraction on the PhysioNet 2017 challenge dataset. Sequential Z-Score normalization, filtering, denoising, and segmentation are used to prepare the raw data for analysis. CGAN (Conditional Generative Adversarial Network) is then used to generate synthetic signals from the processed data. The experimental results demonstrate that the proposed HARDC model significantly outperforms other existing models, achieving an accuracy of 99.60\%, F1 score of 98.21\%, a precision of 97.66\%, and recall of 99.60\% using MIT-BIH generated ECG. In addition, this approach substantially reduces run time when using dilated CNN compared to normal convolution. Overall, this hybrid model demonstrates an innovative and cost-effective strategy for ECG signal compression and high-performance ECG recognition. Our results indicate that an automated and highly computed method to classify multiple types of arrhythmia signals holds considerable promise.
LBCIM: Loyalty Based Competitive Influence Maximization with epsilon-greedy MCTS strategy
Mar 03, 2023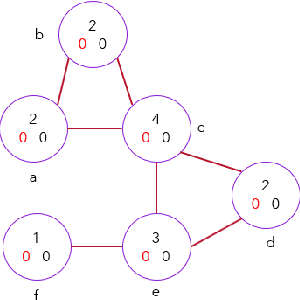

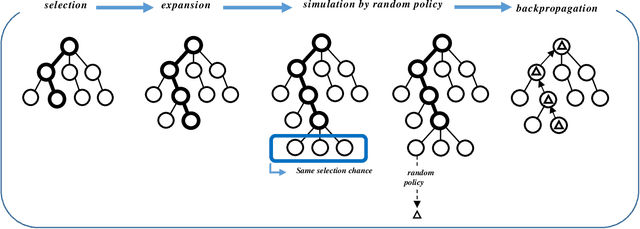
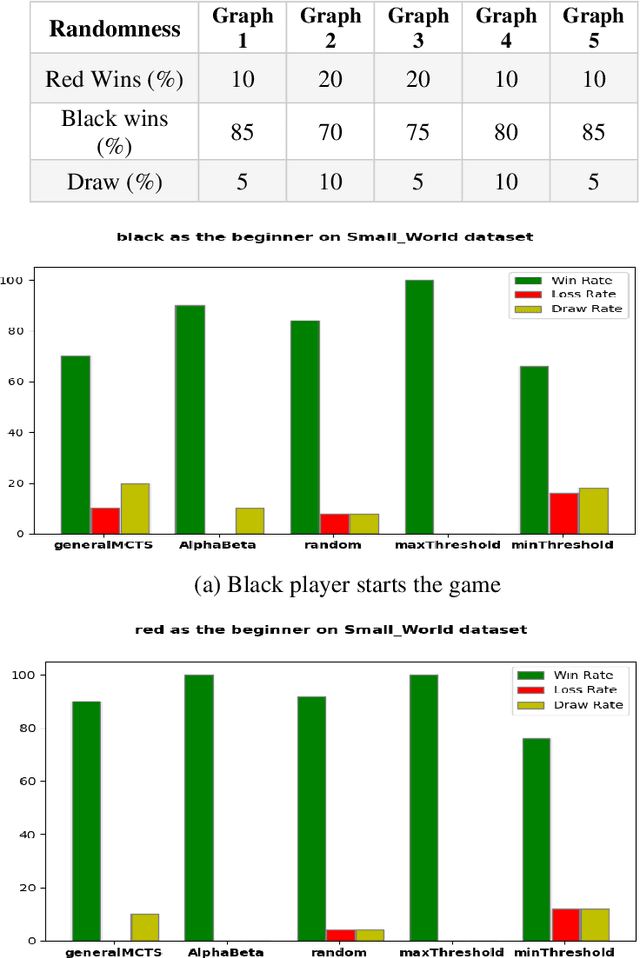
Competitive influence maximization has been studied for several years, and various frameworks have been proposed to model different aspects of information diffusion under the competitive environment. This work presents a new gameboard for two competing parties with some new features representing loyalty in social networks and reflecting the attitude of not completely being loyal to a party when the opponent offers better suggestions. This behavior can be observed in most political occasions where each party tries to attract people by making better suggestions than the opponent and even seeks to impress the fans of the opposition party to change their minds. In order to identify the best move in each step of the game framework, an improved Monte Carlo tree search is developed, which uses some predefined heuristics to apply them on the simulation step of the algorithm and takes advantage of them to search among child nodes of the current state and pick the best one using an epsilon-greedy way instead of choosing them at random. Experimental results on synthetic and real datasets indicate the outperforming of the proposed strategy against some well-known and benchmark strategies like general MCTS, minimax algorithm with alpha-beta pruning, random nodes, nodes with maximum threshold and nodes with minimum threshold.
Decision Transformer under Random Frame Dropping
Mar 03, 2023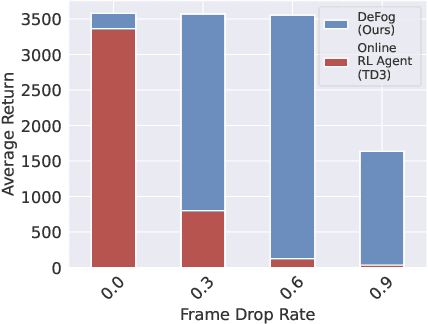
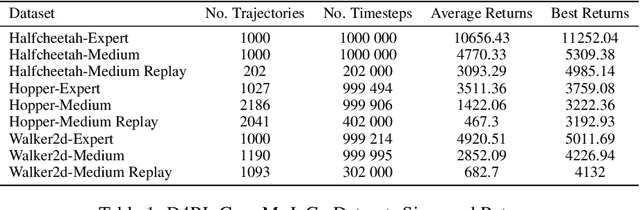
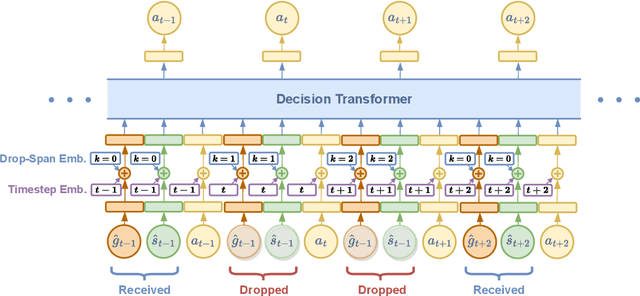
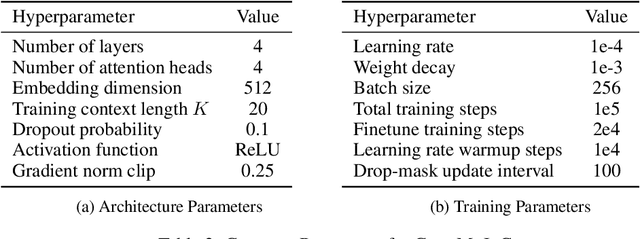
Controlling agents remotely with deep reinforcement learning~(DRL) in the real world is yet to come. One crucial stepping stone is to devise RL algorithms that are robust in the face of dropped information from corrupted communication or malfunctioning sensors. Typical RL methods usually require considerable online interaction data that are costly and unsafe to collect in the real world. Furthermore, when applying to the frame dropping scenarios, they perform unsatisfactorily even with moderate drop rates. To address these issues, we propose Decision Transformer under Random Frame Dropping~(DeFog), an offline RL algorithm that enables agents to act robustly in frame dropping scenarios without online interaction. DeFog first randomly masks out data in the offline datasets and explicitly adds the time span of frame dropping as inputs. After that, a finetuning stage on the same offline dataset with a higher mask rate would further boost the performance. Empirical results show that DeFog outperforms strong baselines under severe frame drop rates like 90\%, while maintaining similar returns under non-frame-dropping conditions in the regular MuJoCo control benchmarks and the Atari environments. Our approach offers a robust and deployable solution for controlling agents in real-world environments with limited or unreliable data.
Retinal Image Restoration using Transformer and Cycle-Consistent Generative Adversarial Network
Mar 03, 2023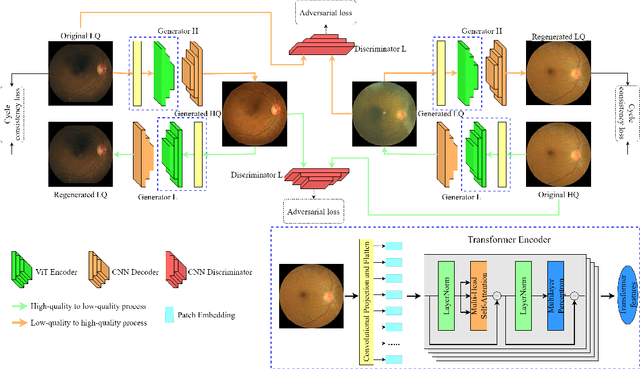

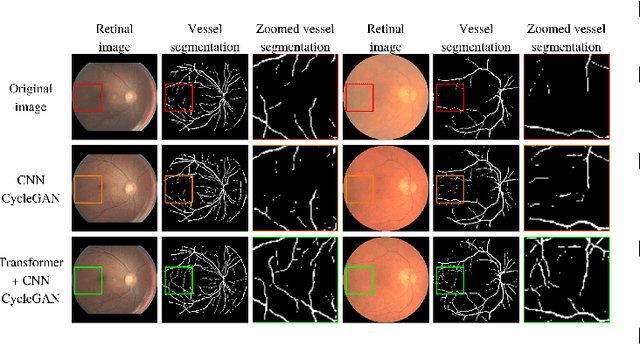
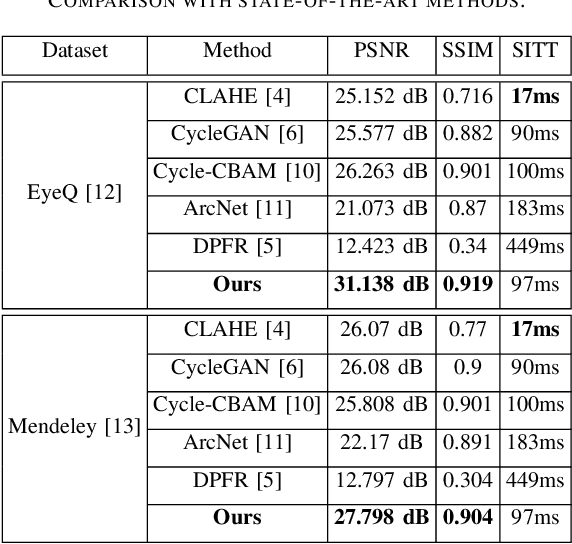
Medical imaging plays a significant role in detecting and treating various diseases. However, these images often happen to be of too poor quality, leading to decreased efficiency, extra expenses, and even incorrect diagnoses. Therefore, we propose a retinal image enhancement method using a vision transformer and convolutional neural network. It builds a cycle-consistent generative adversarial network that relies on unpaired datasets. It consists of two generators that translate images from one domain to another (e.g., low- to high-quality and vice versa), playing an adversarial game with two discriminators. Generators produce indistinguishable images for discriminators that predict the original images from generated ones. Generators are a combination of vision transformer (ViT) encoder and convolutional neural network (CNN) decoder. Discriminators include traditional CNN encoders. The resulting improved images have been tested quantitatively using such evaluation metrics as peak signal-to-noise ratio (PSNR), structural similarity index measure (SSIM), and qualitatively, i.e., vessel segmentation. The proposed method successfully reduces the adverse effects of blurring, noise, illumination disturbances, and color distortions while significantly preserving structural and color information. Experimental results show the superiority of the proposed method. Our testing PSNR is 31.138 dB for the first and 27.798 dB for the second dataset. Testing SSIM is 0.919 and 0.904, respectively.
Differentially Private Maximal Information Coefficients
Jun 21, 2022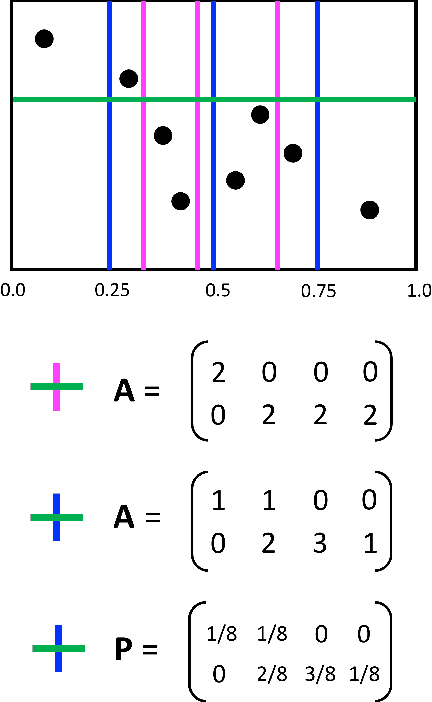

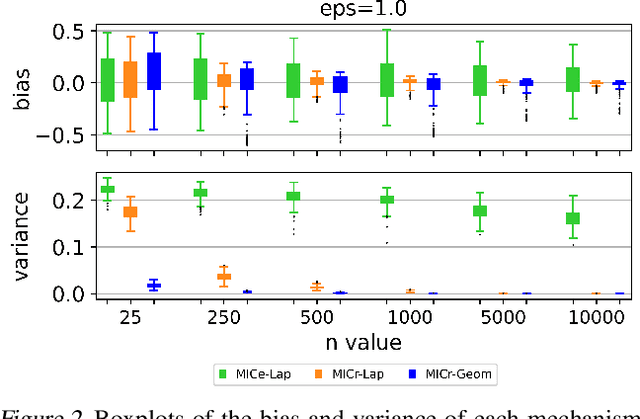

The Maximal Information Coefficient (MIC) is a powerful statistic to identify dependencies between variables. However, it may be applied to sensitive data, and publishing it could leak private information. As a solution, we present algorithms to approximate MIC in a way that provides differential privacy. We show that the natural application of the classic Laplace mechanism yields insufficient accuracy. We therefore introduce the MICr statistic, which is a new MIC approximation that is more compatible with differential privacy. We prove MICr is a consistent estimator for MIC, and we provide two differentially private versions of it. We perform experiments on a variety of real and synthetic datasets. The results show that the private MICr statistics significantly outperform direct application of the Laplace mechanism. Moreover, experiments on real-world datasets show accuracy that is usable when the sample size is at least moderately large.
3M3D: Multi-view, Multi-path, Multi-representation for 3D Object Detection
Feb 16, 2023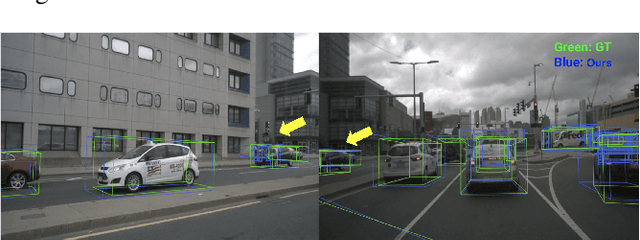
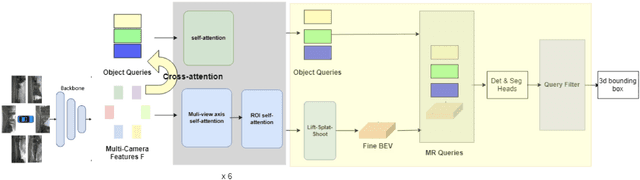

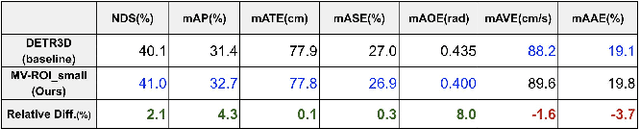
3D visual perception tasks based on multi-camera images are essential for autonomous driving systems. Latest work in this field performs 3D object detection by leveraging multi-view images as an input and iteratively enhancing object queries (object proposals) by cross-attending multi-view features. However, individual backbone features are not updated with multi-view features and it stays as a mere collection of the output of the single-image backbone network. Therefore we propose 3M3D: A Multi-view, Multi-path, Multi-representation for 3D Object Detection where we update both multi-view features and query features to enhance the representation of the scene in both fine panoramic view and coarse global view. Firstly, we update multi-view features by multi-view axis self-attention. It will incorporate panoramic information in the multi-view features and enhance understanding of the global scene. Secondly, we update multi-view features by self-attention of the ROI (Region of Interest) windows which encodes local finer details in the features. It will help exchange the information not only along the multi-view axis but also along the other spatial dimension. Lastly, we leverage the fact of multi-representation of queries in different domains to further boost the performance. Here we use sparse floating queries along with dense BEV (Bird's Eye View) queries, which are later post-processed to filter duplicate detections. Moreover, we show performance improvements on nuScenes benchmark dataset on top of our baselines.
Multi-Armed Bandits with Self-Information Rewards
Sep 06, 2022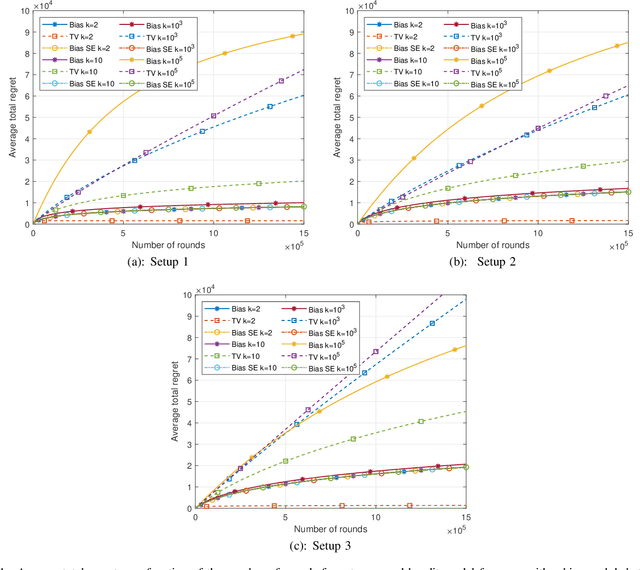
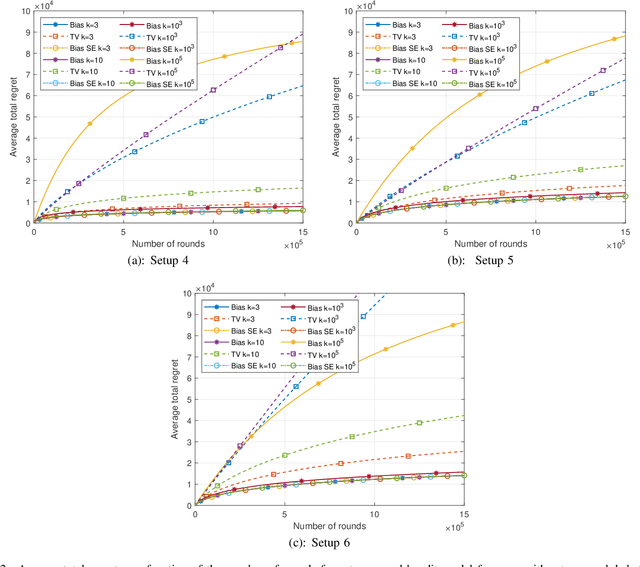
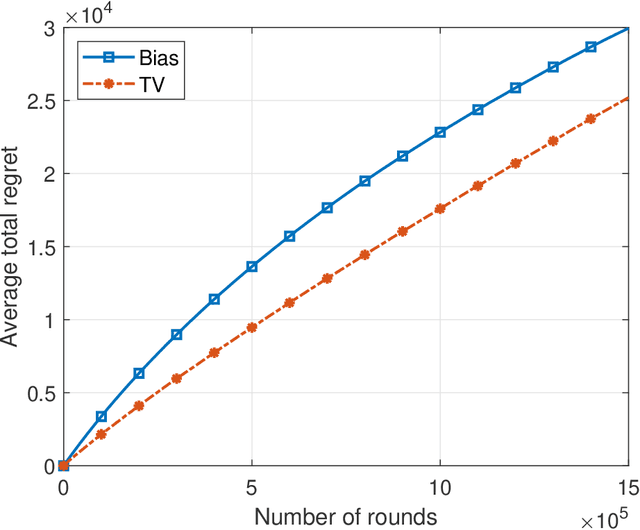
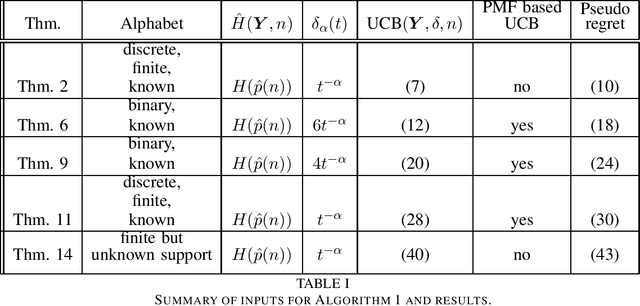
This paper introduces the informational multi-armed bandit (IMAB) model in which at each round, a player chooses an arm, observes a symbol, and receives an unobserved reward in the form of the symbol's self-information. Thus, the expected reward of an arm is the Shannon entropy of the probability mass function of the source that generates its symbols. The player aims to maximize the expected total reward associated with the entropy values of the arms played. Under the assumption that the alphabet size is known, two UCB-based algorithms are proposed for the IMAB model which consider the biases of the plug-in entropy estimator. The first algorithm optimistically corrects the bias term in the entropy estimation. The second algorithm relies on data-dependent confidence intervals that adapt to sources with small entropy values. Performance guarantees are provided by upper bounding the expected regret of each of the algorithms. Furthermore, in the Bernoulli case, the asymptotic behavior of these algorithms is compared to the Lai-Robbins lower bound for the pseudo regret. Additionally, under the assumption that the \textit{exact} alphabet size is unknown, and instead the player only knows a loose upper bound on it, a UCB-based algorithm is proposed, in which the player aims to reduce the regret caused by the unknown alphabet size in a finite time regime. Numerical results illustrating the expected regret of the algorithms presented in the paper are provided.
Scatter-based common spatial patterns -- a unified spatial filtering framework
Mar 07, 2023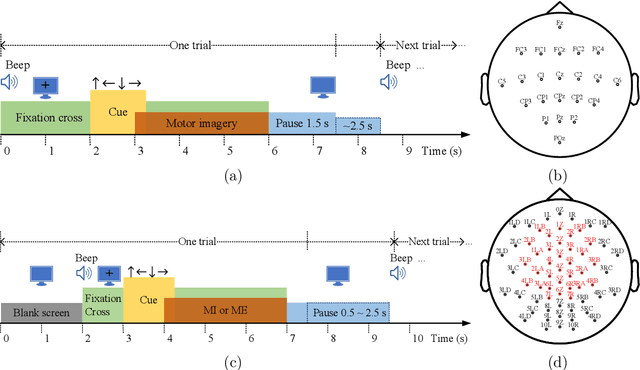
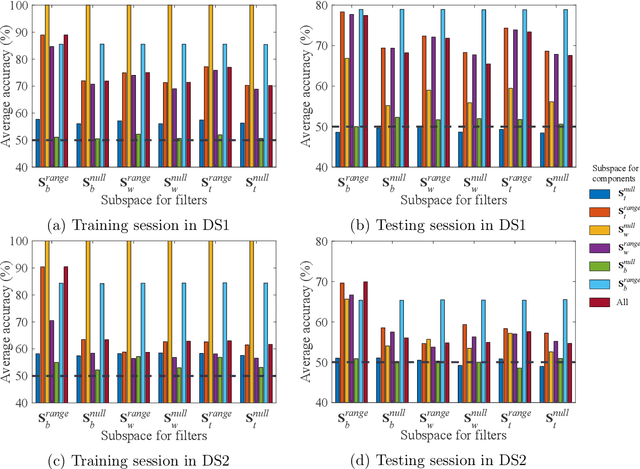
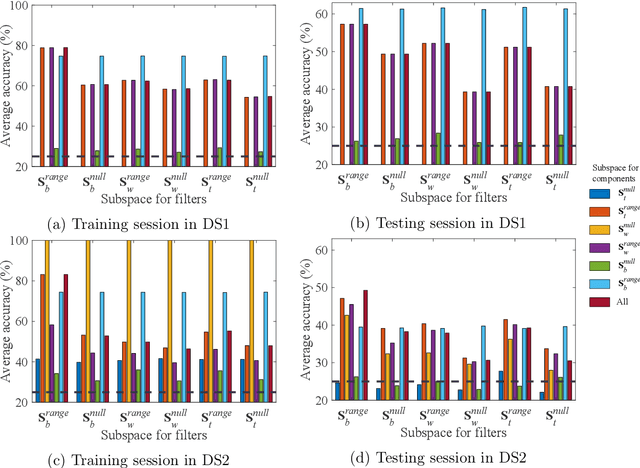
The common spatial pattern (CSP) approach is known as one of the most popular spatial filtering techniques for EEG classification in motor imagery (MI) based brain-computer interfaces (BCIs). However, it still suffers some drawbacks such as sensitivity to noise, non-stationarity, and limitation to binary classification.Therefore, we propose a novel spatial filtering framework called scaCSP based on the scatter matrices of spatial covariances of EEG signals, which works generally in both binary and multi-class problems whereas CSP can be cast into our framework as a special case when only the range space of the between-class scatter matrix is used in binary cases.We further propose subspace enhanced scaCSP algorithms which easily permit incorporating more discriminative information contained in other range spaces and null spaces of the between-class and within-class scatter matrices in two scenarios: a nullspace components reduction scenario and an additional spatial filter learning scenario.The proposed algorithms are evaluated on two data sets including 4 MI tasks. The classification performance is compared against state-of-the-art competing algorithms: CSP, Tikhonov regularized CSP (TRCSP), stationary CSP (sCSP) and stationary TRCSP (sTRCSP) in the binary problems whilst multi-class extensions of CSP based on pair-wise and one-versus-rest techniques in the multi-class problems. The results show that the proposed framework outperforms all the competing algorithms in terms of average classification accuracy and computational efficiency in both binary and multi-class problems.The proposed scsCSP works as a unified framework for general multi-class problems and is promising for improving the performance of MI-BCIs.
A Computer Vision Enabled damage detection model with improved YOLOv5 based on Transformer Prediction Head
Mar 07, 2023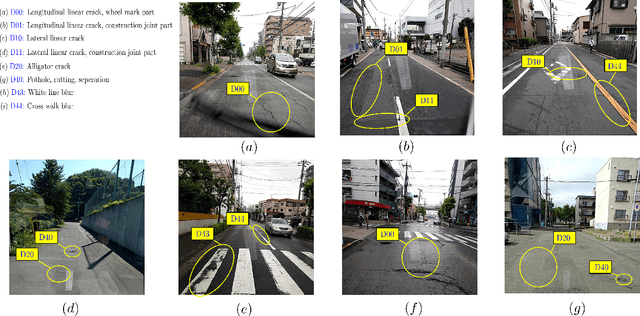
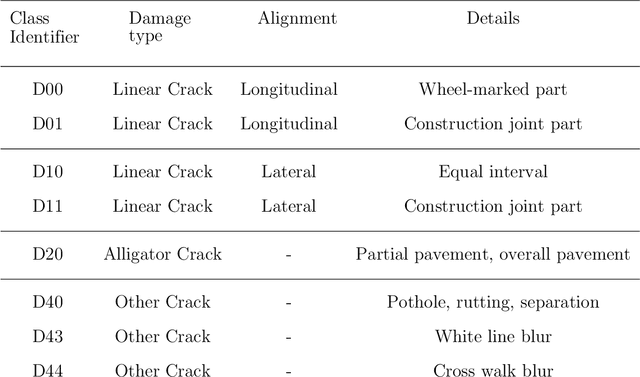
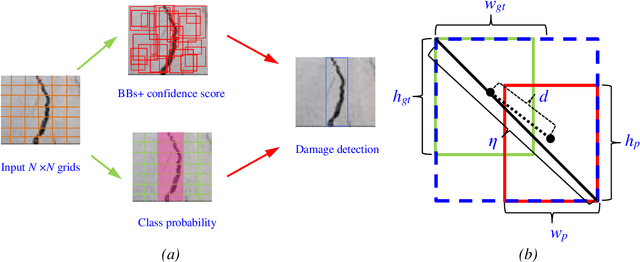
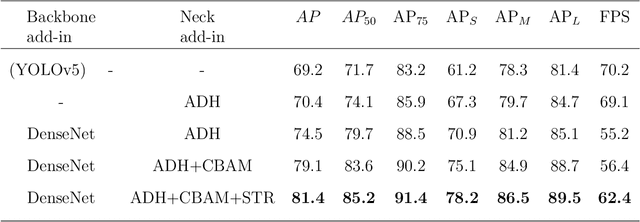
Objective:Computer vision-based up-to-date accurate damage classification and localization are of decisive importance for infrastructure monitoring, safety, and the serviceability of civil infrastructure. Current state-of-the-art deep learning (DL)-based damage detection models, however, often lack superior feature extraction capability in complex and noisy environments, limiting the development of accurate and reliable object distinction. Method: To this end, we present DenseSPH-YOLOv5, a real-time DL-based high-performance damage detection model where DenseNet blocks have been integrated with the backbone to improve in preserving and reusing critical feature information. Additionally, convolutional block attention modules (CBAM) have been implemented to improve attention performance mechanisms for strong and discriminating deep spatial feature extraction that results in superior detection under various challenging environments. Moreover, additional feature fusion layers and a Swin-Transformer Prediction Head (SPH) have been added leveraging advanced self-attention mechanism for more efficient detection of multiscale object sizes and simultaneously reducing the computational complexity. Results: Evaluating the model performance in large-scale Road Damage Dataset (RDD-2018), at a detection rate of 62.4 FPS, DenseSPH-YOLOv5 obtains a mean average precision (mAP) value of 85.25 %, F1-score of 81.18 %, and precision (P) value of 89.51 % outperforming current state-of-the-art models. Significance: The present research provides an effective and efficient damage localization model addressing the shortcoming of existing DL-based damage detection models by providing highly accurate localized bounding box prediction. Current work constitutes a step towards an accurate and robust automated damage detection system in real-time in-field applications.