 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hate Speech and Offensive Language Detection using an Emotion-aware Shared Encoder
Feb 17, 2023
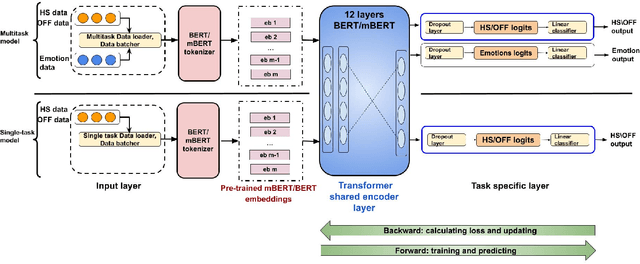
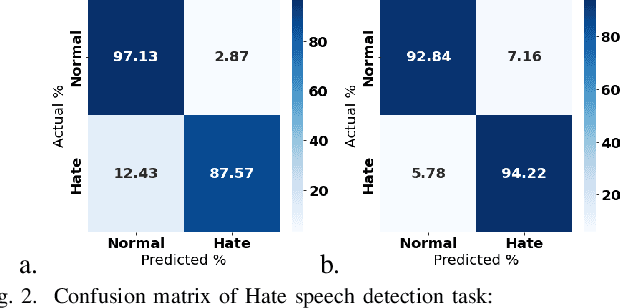
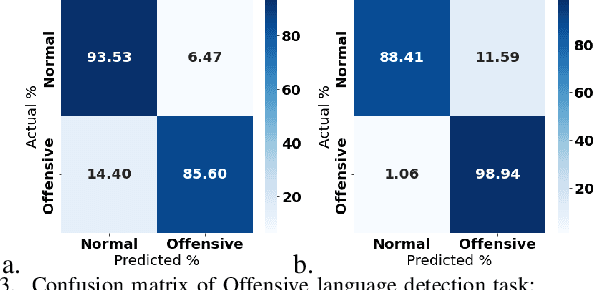
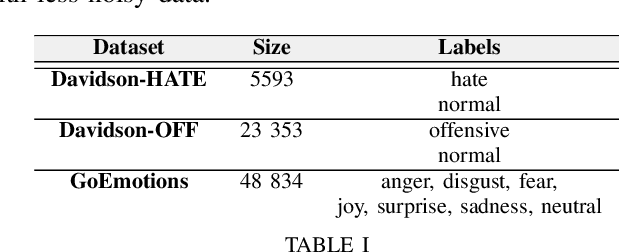
The rise of emergence of social media platforms has fundamentally altered how people communicate, and among the results of these developments is an increase in online use of abusive content. Therefore, automatically detecting this content is essential for banning inappropriate information, and reducing toxicity and violence on social media platforms. The existing works on hate speech and offensive language detection produce promising results based on pre-trained transformer models, however, they considered only the analysis of abusive content features generated through annotated datasets. This paper addresses a multi-task joint learning approach which combines external emotional features extracted from another corpora in dealing with the imbalanced and scarcity of labeled datasets. Our analysis are using two well-known Transformer-based models, BERT and mBERT, where the later is used to address abusive content detection in multi-lingual scenarios. Our model jointly learns abusive content detection with emotional features by sharing representations through transformers' shared encoder. This approach increases data efficiency, reduce overfitting via shared representations, and ensure fast learning by leveraging auxiliary information. Our findings demonstrate that emotional knowledge helps to more reliably identify hate speech and offensive language across datasets. Our hate speech detection Multi-task model exhibited 3% performance improvement over baseline models, but the performance of multi-task models were not significant for offensive language detection task. More interestingly, in both tasks, multi-task models exhibits less false positive errors compared to single task scenario.
Rapid Design of Top-Performing Metal-Organic Frameworks with Qualitative Representations of Building Blocks
Feb 17, 2023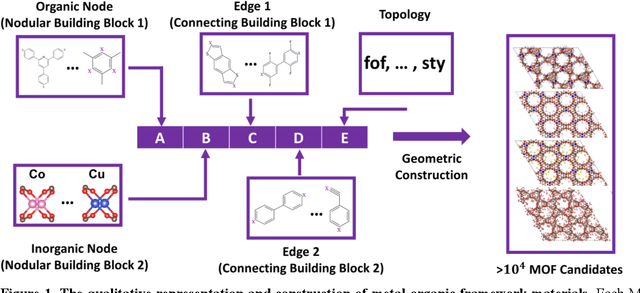
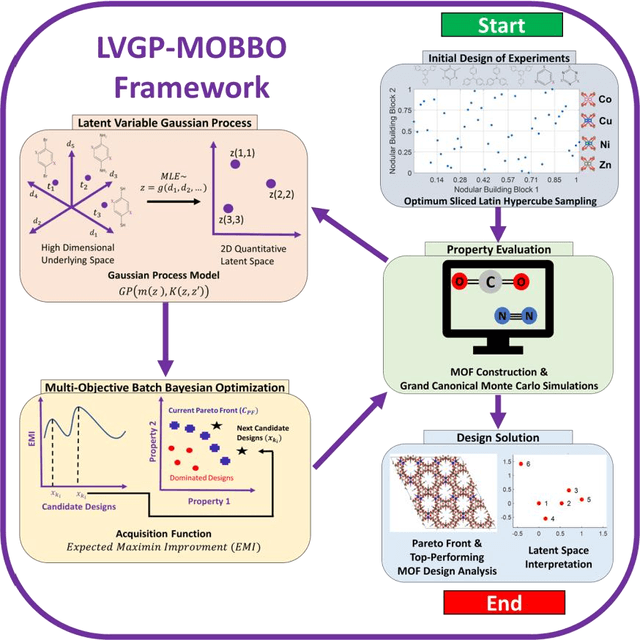
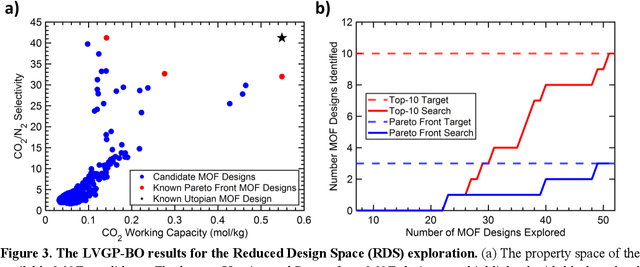
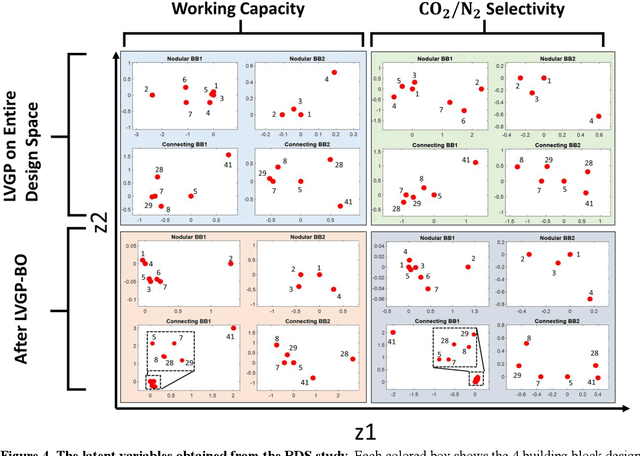
Data-driven materials design often encounters challenges where systems require or possess qualitative (categorical) information. Metal-organic frameworks (MOFs) are an example of such material systems. The representation of MOFs through different building blocks makes it a challenge for designers to incorporate qualitative information into design optimization. Furthermore, the large number of potential building blocks leads to a combinatorial challenge, with millions of possible MOFs that could be explored through time consuming physics-based approaches. In this work, we integrated Latent Variable Gaussian Process (LVGP) and Multi-Objective Batch-Bayesian Optimization (MOBBO) to identify top-performing MOFs adaptively, autonomously, and efficiently without any human intervention. Our approach provides three main advantages: (i) no specific physical descriptors are required and only building blocks that construct the MOFs are used in global optimization through qualitative representations, (ii) the method is application and property independent, and (iii) the latent variable approach provides an interpretable model of qualitative building blocks with physical justification. To demonstrate the effectiveness of our method, we considered a design space with more than 47,000 MOF candidates. By searching only ~1% of the design space, LVGP-MOBBO was able to identify all MOFs on the Pareto front and more than 97% of the 50 top-performing designs for the CO$_2$ working capacity and CO$_2$/N$_2$ selectivity properties. Finally, we compared our approach with the Random Forest algorithm and demonstrated its efficiency, interpretability, and robustness.
HumSet: Dataset of Multilingual Information Extraction and Classification for Humanitarian Crisis Response
Oct 10, 2022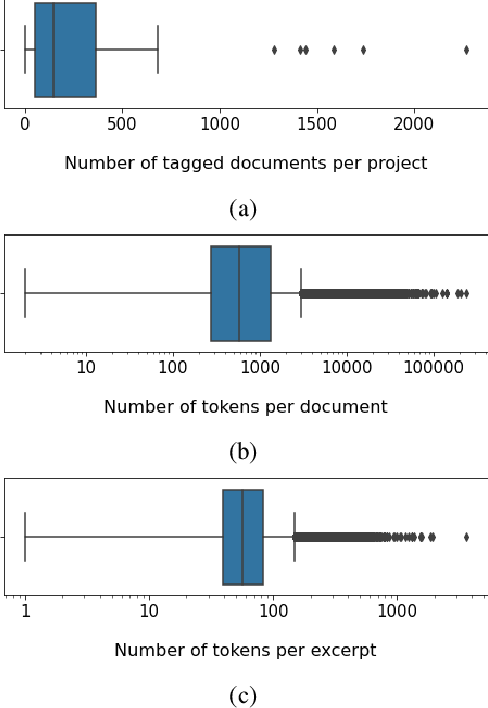

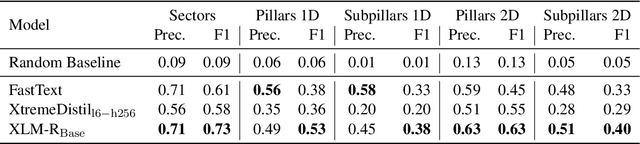
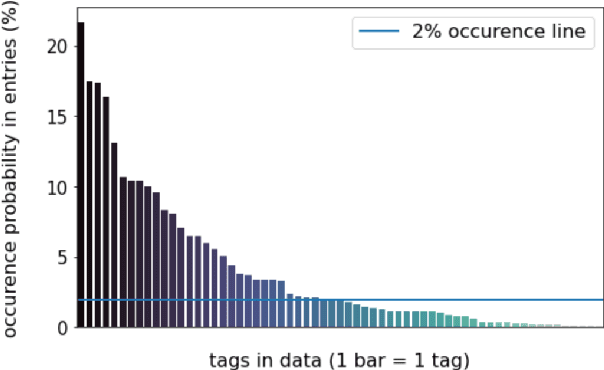
Timely and effective response to humanitarian crises requires quick and accurate analysis of large amounts of text data - a process that can highly benefit from expert - assisted NLP systems trained on validated and annotated data in the humanitarian response domain. To enable creation of such NLP systems, we introduce and release HumSet, a novel and rich multilingual dataset of humanitarian response documents annotated by experts in the humanitarian response community. The dataset provides documents in three languages (English, French, Spanish) and covers a variety of humanitarian crises from 2018 to 2021 across the globe. For each document, HumSet provides selected snippets (entries) as well as assigned classes to each entry annotated using common humanitarian information analysis frameworks. HumSet also provides novel and challenging entry extraction and multi-label entry classification tasks. In this paper, we take a first step towards approaching these tasks and conduct a set of experiments on Pre-trained Language Models (PLM) to establish strong baselines for future research in this domain. The dataset is available at The dataset is available at https: //blog.thedeep.io/humset/.
UT-Net: Combining U-Net and Transformer for Joint Optic Disc and Cup Segmentation and Glaucoma Detection
Mar 08, 2023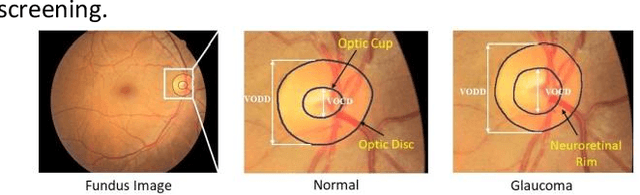
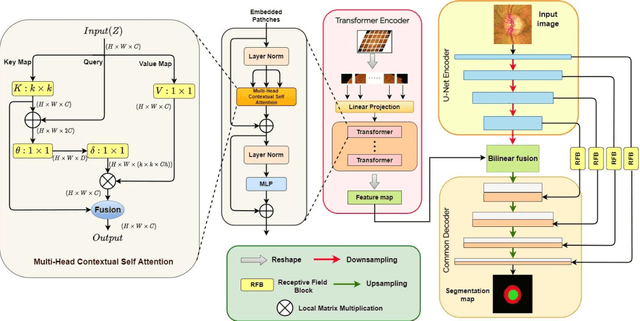
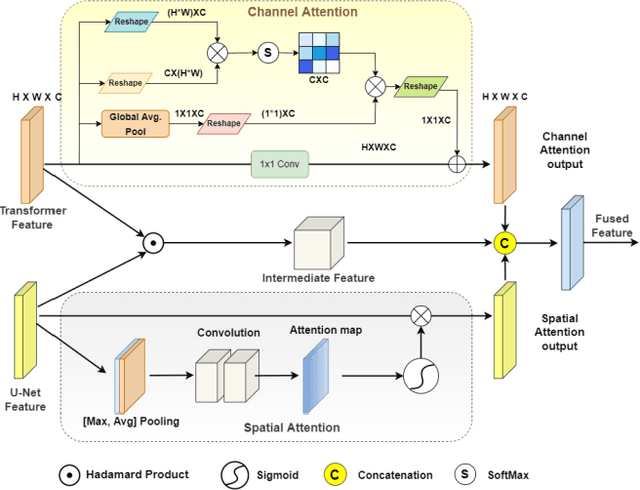
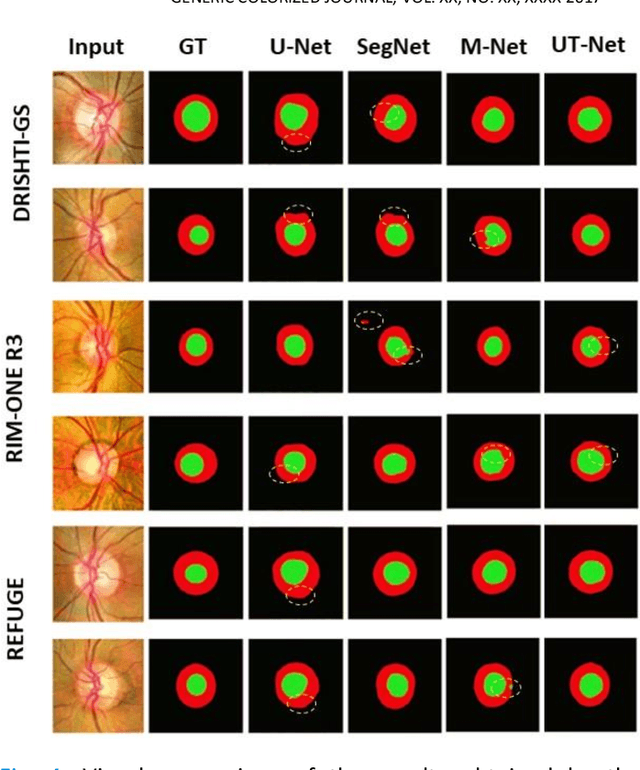
Glaucoma is a chronic visual disease that may cause permanent irreversible blindness. Measurement of the cup-to-disc ratio (CDR) plays a pivotal role in the detection of glaucoma in its early stage, preventing visual disparities. Therefore, accurate and automatic segmentation of optic disc (OD) and optic cup (OC) from retinal fundus images is a fundamental requirement. Existing CNN-based segmentation frameworks resort to building deep encoders with aggressive downsampling layers, which suffer from a general limitation on modeling explicit long-range dependency. To this end, in this paper, we propose a new segmentation pipeline, called UT-Net, availing the advantages of U-Net and transformer both in its encoding layer, followed by an attention-gated bilinear fusion scheme. In addition to this, we incorporate Multi-Head Contextual attention to enhance the regular self-attention used in traditional vision transformers. Thus low-level features along with global dependencies are captured in a shallow manner. Besides, we extract context information at multiple encoding layers for better exploration of receptive fields, and to aid the model to learn deep hierarchical representations. Finally, an enhanced mixing loss is proposed to tightly supervise the overall learning process. The proposed model has been implemented for joint OD and OC segmentation on three publicly available datasets: DRISHTI-GS, RIM-ONE R3, and REFUGE. Additionally, to validate our proposal, we have performed exhaustive experimentation on Glaucoma detection from all three datasets by measuring the Cup to Disc Ratio (CDR) value. Experimental results demonstrate the superiority of UT-Net as compared to the state-of-the-art methods.
A Threefold Review on Deep Semantic Segmentation: Efficiency-oriented, Temporal and Depth-aware design
Mar 08, 2023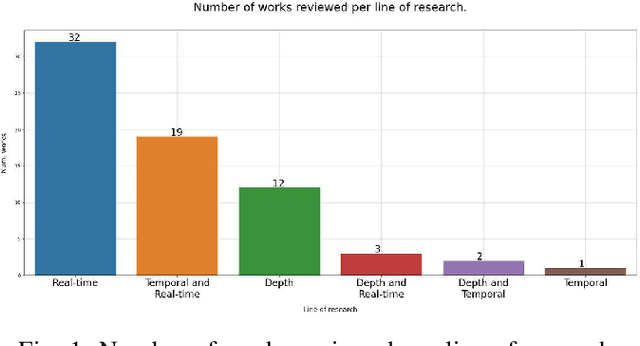
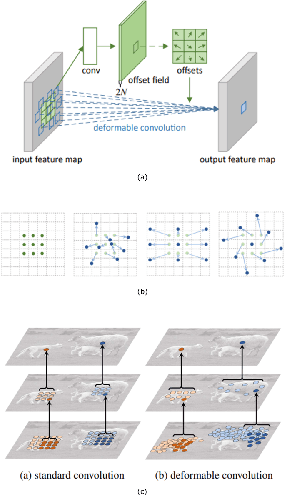
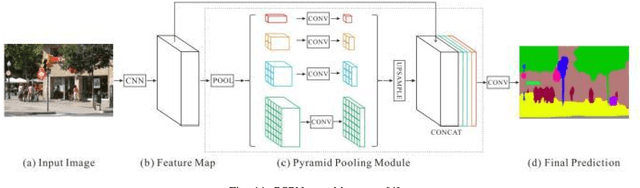
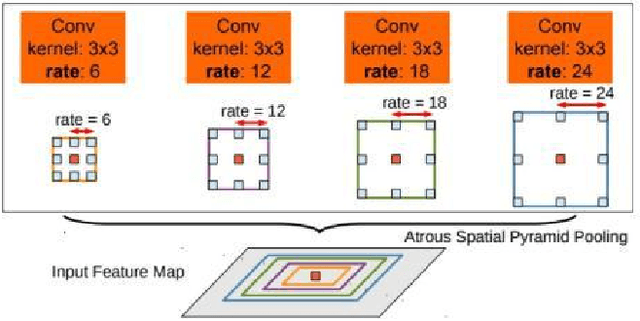
Semantic image and video segmentation stand among the most important tasks in computer vision nowadays, since they provide a complete and meaningful representation of the environment by means of a dense classification of the pixels in a given scene. Recently, Deep Learning, and more precisely Convolutional Neural Networks, have boosted semantic segmentation to a new level in terms of performance and generalization capabilities. However, designing Deep Semantic Segmentation models is a complex task, as it may involve application-dependent aspects. Particularly, when considering autonomous driving applications, the robustness-efficiency trade-off, as well as intrinsic limitations - computational/memory bounds and data-scarcity - and constraints - real-time inference - should be taken into consideration. In this respect, the use of additional data modalities, such as depth perception for reasoning on the geometry of a scene, and temporal cues from videos to explore redundancy and consistency, are promising directions yet not explored to their full potential in the literature. In this paper, we conduct a survey on the most relevant and recent advances in Deep Semantic Segmentation in the context of vision for autonomous vehicles, from three different perspectives: efficiency-oriented model development for real-time operation, RGB-Depth data integration (RGB-D semantic segmentation), and the use of temporal information from videos in temporally-aware models. Our main objective is to provide a comprehensive discussion on the main methods, advantages, limitations, results and challenges faced from each perspective, so that the reader can not only get started, but also be up to date in respect to recent advances in this exciting and challenging research field.
Predicting Cellular Responses with Variational Causal Inference and Refined Relational Information
Sep 30, 2022
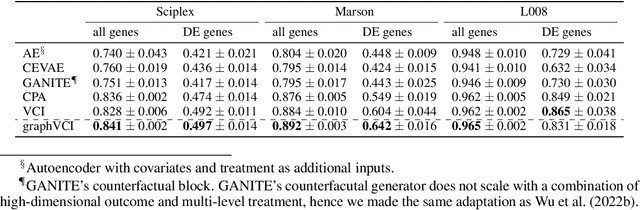

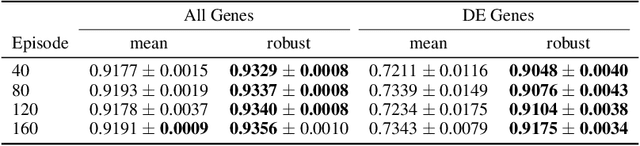
Predicting the responses of a cell under perturbations may bring important benefits to drug discovery and personalized therapeutics. In this work, we propose a novel graph variational Bayesian causal inference framework to predict a cell's gene expressions under counterfactual perturbations (perturbations that this cell did not factually receive), leveraging information representing biological knowledge in the form of gene regulatory networks (GRNs) to aid individualized cellular response predictions. Aiming at a data-adaptive GRN, we also developed an adjacency matrix updating technique for graph convolutional networks and used it to refine GRNs during pre-training, which generated more insights on gene relations and enhanced model performance. Additionally, we propose a robust estimator within our framework for the asymptotically efficient estimation of marginal perturbation effect, which is yet to be carried out in previous works. With extensive experiments, we exhibited the advantage of our approach over state-of-the-art deep learning models for individual response prediction.
Visible and Near Infrared Image Fusion Based on Texture Information
Jul 22, 2022



Multi-sensor fusion is widely used in the environment perception system of the autonomous vehicle. It solves the interference caused by environmental changes and makes the whole driving system safer and more reliable. In this paper, a novel visible and near-infrared fusion method based on texture information is proposed to enhance unstructured environmental images. It aims at the problems of artifact, information loss and noise in traditional visible and near infrared image fusion methods. Firstly, the structure information of the visible image (RGB) and the near infrared image (NIR) after texture removal is obtained by relative total variation (RTV) calculation as the base layer of the fused image; secondly, a Bayesian classification model is established to calculate the noise weight and the noise information and the noise information in the visible image is adaptively filtered by joint bilateral filter; finally, the fused image is acquired by color space conversion. The experimental results demonstrate that the proposed algorithm can preserve the spectral characteristics and the unique information of visible and near-infrared images without artifacts and color distortion, and has good robustness as well as preserving the unique texture.
Brain Topography Adaptive Network for Satisfaction Modeling in Interactive Information Access System
Aug 17, 2022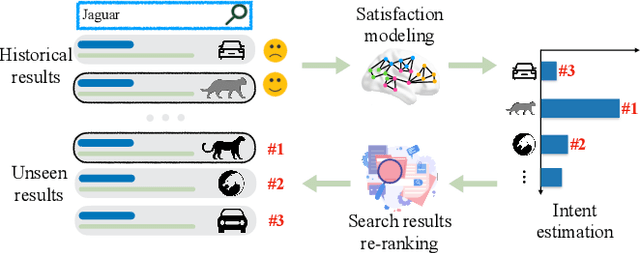
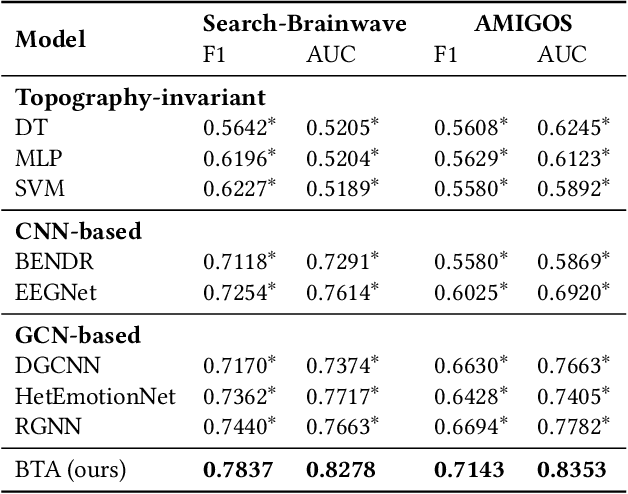
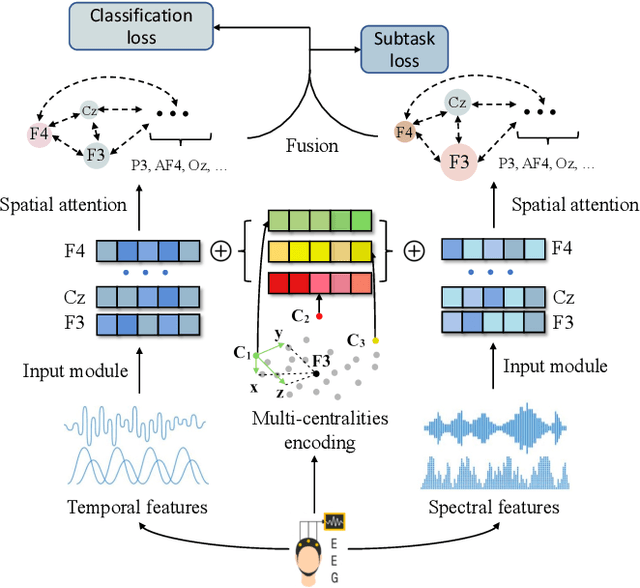

With the growth of information on the Web, most users heavily rely on information access systems (e.g., search engines, recommender systems, etc.) in their daily lives. During this procedure, modeling users' satisfaction status plays an essential part in improving their experiences with the systems. In this paper, we aim to explore the benefits of using Electroencephalography (EEG) signals for satisfaction modeling in interactive information access system design. Different from existing EEG classification tasks, the arisen of satisfaction involves multiple brain functions, such as arousal, prototypicality, and appraisals, which are related to different brain topographical areas. Thus modeling user satisfaction raises great challenges to existing solutions. To address this challenge, we propose BTA, a Brain Topography Adaptive network with a multi-centrality encoding module and a spatial attention mechanism module to capture cognitive connectivities in different spatial distances. We explore the effectiveness of BTA for satisfaction modeling in two popular information access scenarios, i.e., search and recommendation. Extensive experiments on two real-world datasets verify the effectiveness of introducing brain topography adaptive strategy in satisfaction modeling. Furthermore, we also conduct search result re-ranking task and video rating prediction task based on the satisfaction inferred from brain signals on search and recommendation scenarios, respectively. Experimental results show that brain signals extracted with BTA help improve the performance of interactive information access systems significantly.
MixFormer: End-to-End Tracking with Iterative Mixed Attention
Feb 09, 2023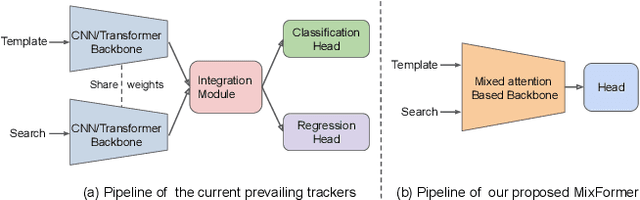

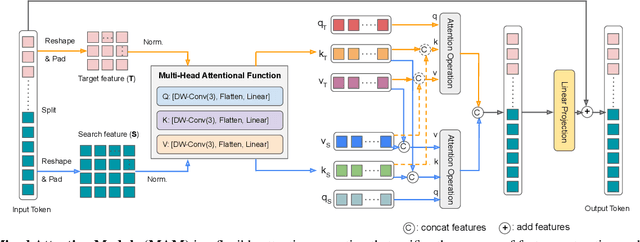
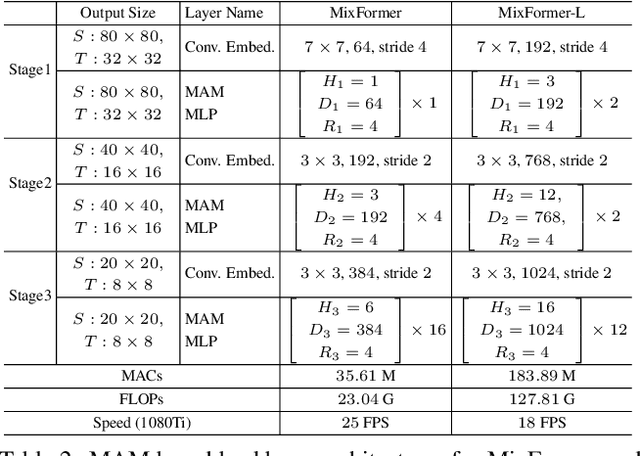
Visual object tracking often employs a multi-stage pipeline of feature extraction, target information integration, and bounding box estimation. To simplify this pipeline and unify the process of feature extraction and target information integration, in this paper, we present a compact tracking framework, termed as MixFormer, built upon transformers. Our core design is to utilize the flexibility of attention operations, and propose a Mixed Attention Module (MAM) for simultaneous feature extraction and target information integration. This synchronous modeling scheme allows to extract target-specific discriminative features and perform extensive communication between target and search area. Based on MAM, we build our MixFormer trackers simply by stacking multiple MAMs and placing a localization head on top. Specifically, we instantiate two types of MixFormer trackers, a hierarchical tracker MixCvT, and a non-hierarchical tracker MixViT. For these two trackers, we investigate a series of pre-training methods and uncover the different behaviors between supervised pre-training and self-supervised pre-training in our MixFormer trackers. We also extend the masked pre-training to our MixFormer trackers and design the competitive TrackMAE pre-training technique. Finally, to handle multiple target templates during online tracking, we devise an asymmetric attention scheme in MAM to reduce computational cost, and propose an effective score prediction module to select high-quality templates. Our MixFormer trackers set a new state-of-the-art performance on seven tracking benchmarks, including LaSOT, TrackingNet, VOT2020, GOT-10k, OTB100 and UAV123. In particular, our MixViT-L achieves AUC score of 73.3% on LaSOT, 86.1% on TrackingNet, EAO of 0.584 on VOT2020, and AO of 75.7% on GOT-10k. Code and trained models are publicly available at https://github.com/MCG-NJU/MixFormer.
Spatiotemporal Decouple-and-Squeeze Contrastive Learning for Semi-Supervised Skeleton-based Action Recognition
Feb 05, 2023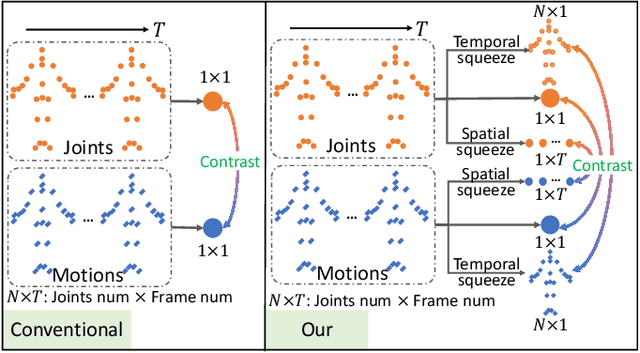
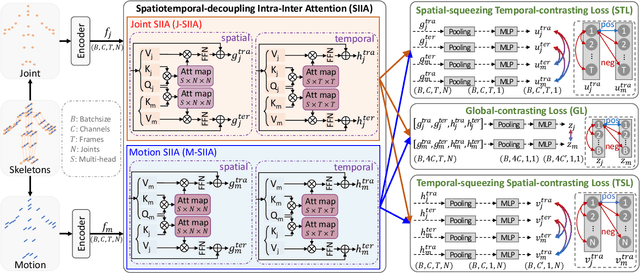
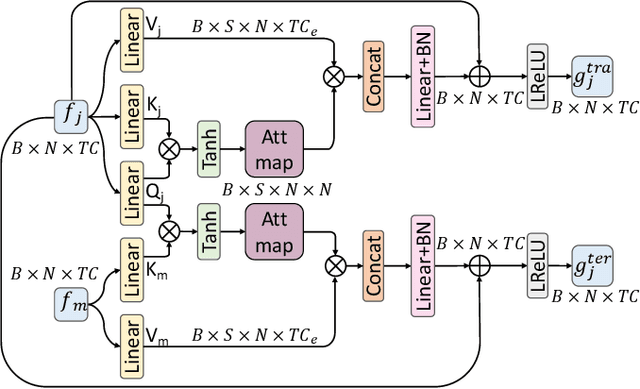
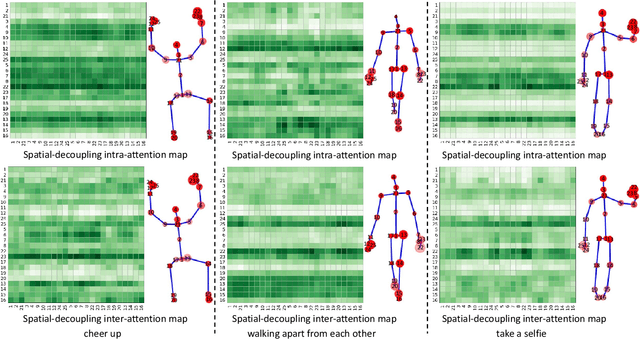
Contrastive learning has been successfully leveraged to learn action representations for addressing the problem of semi-supervised skeleton-based action recognition. However, most contrastive learning-based methods only contrast global features mixing spatiotemporal information, which confuses the spatial- and temporal-specific information reflecting different semantic at the frame level and joint level. Thus, we propose a novel Spatiotemporal Decouple-and-Squeeze Contrastive Learning (SDS-CL) framework to comprehensively learn more abundant representations of skeleton-based actions by jointly contrasting spatial-squeezing features, temporal-squeezing features, and global features. In SDS-CL, we design a new Spatiotemporal-decoupling Intra-Inter Attention (SIIA) mechanism to obtain the spatiotemporal-decoupling attentive features for capturing spatiotemporal specific information by calculating spatial- and temporal-decoupling intra-attention maps among joint/motion features, as well as spatial- and temporal-decoupling inter-attention maps between joint and motion features. Moreover, we present a new Spatial-squeezing Temporal-contrasting Loss (STL), a new Temporal-squeezing Spatial-contrasting Loss (TSL), and the Global-contrasting Loss (GL) to contrast the spatial-squeezing joint and motion features at the frame level, temporal-squeezing joint and motion features at the joint level, as well as global joint and motion features at the skeleton level. Extensive experimental results on four public datasets show that the proposed SDS-CL achieves performance gains compared with other competitive methods.