 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
IMCI: Integrate Multi-view Contextual Information for Fact Extraction and Verification
Aug 30, 2022


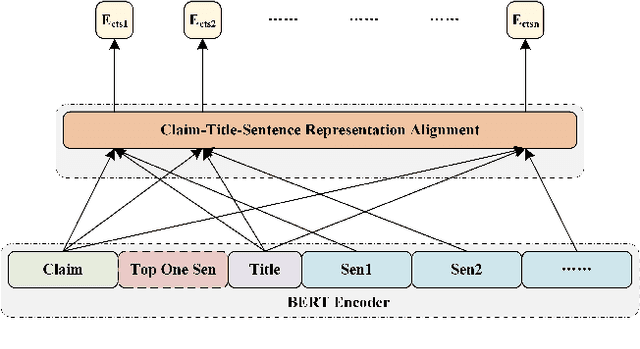

With the rapid development of automatic fake news detection technology, fact extraction and verification (FEVER) has been attracting more attention. The task aims to extract the most related fact evidences from millions of open-domain Wikipedia documents and then verify the credibility of corresponding claims. Although several strong models have been proposed for the task and they have made great progress, we argue that they fail to utilize multi-view contextual information and thus cannot obtain better performance. In this paper, we propose to integrate multi-view contextual information (IMCI) for fact extraction and verification. For each evidence sentence, we define two kinds of context, i.e. intra-document context and inter-document context}. Intra-document context consists of the document title and all the other sentences from the same document. Inter-document context consists of all other evidences which may come from different documents. Then we integrate the multi-view contextual information to encode the evidence sentences to handle the task. Our experimental results on FEVER 1.0 shared task show that our IMCI framework makes great progress on both fact extraction and verification, and achieves state-of-the-art performance with a winning FEVER score of 72.97% and label accuracy of 75.84% on the online blind test set. We also conduct ablation study to detect the impact of multi-view contextual information. Our codes will be released at https://github.com/phoenixsecularbird/IMCI.
Mining compact high utility sequential patterns
Feb 22, 2023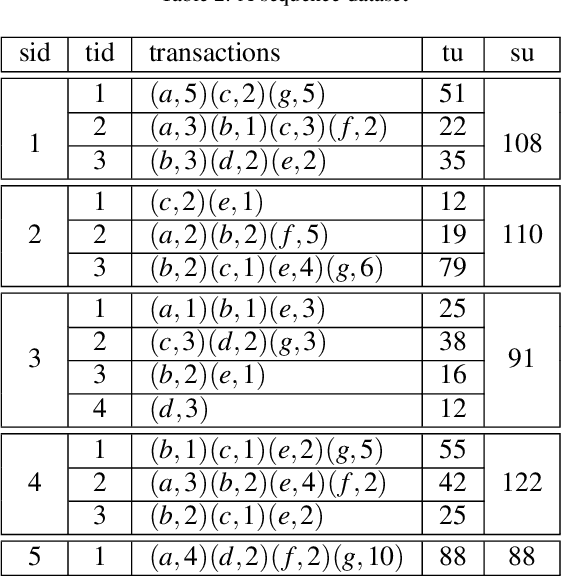
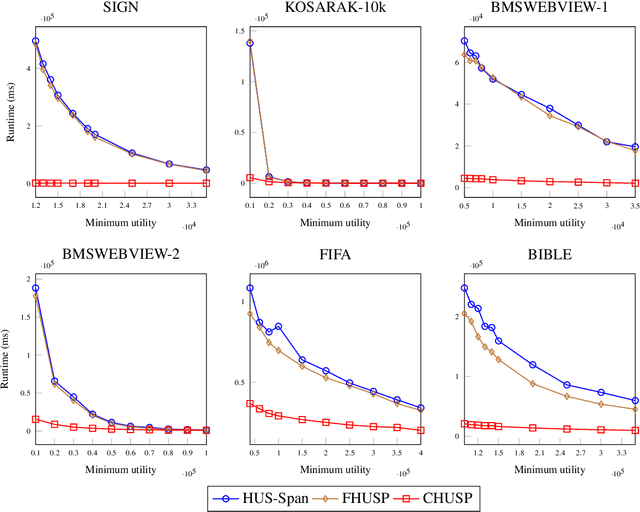
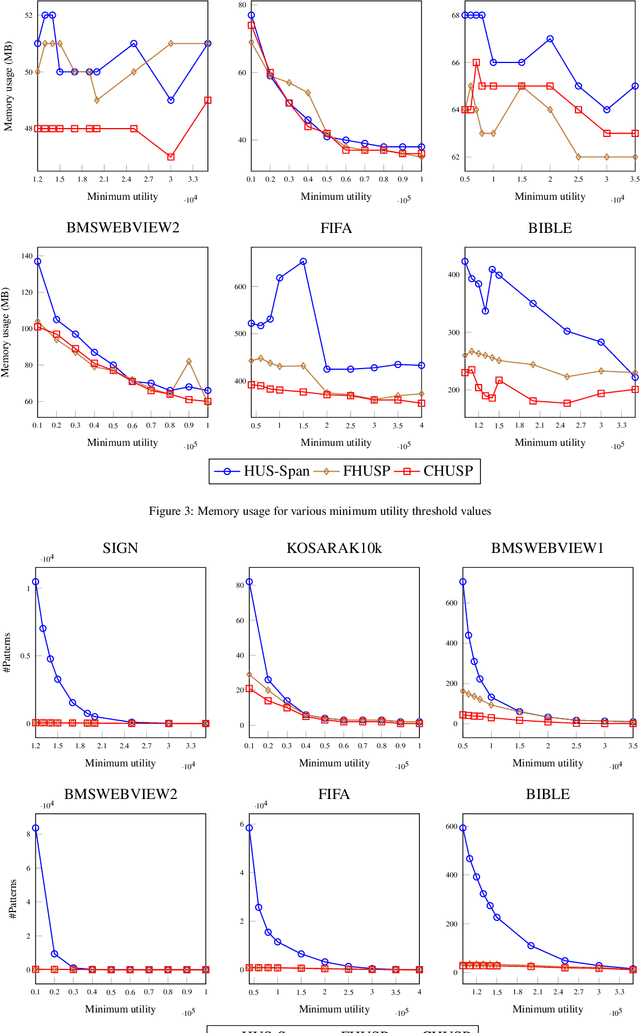
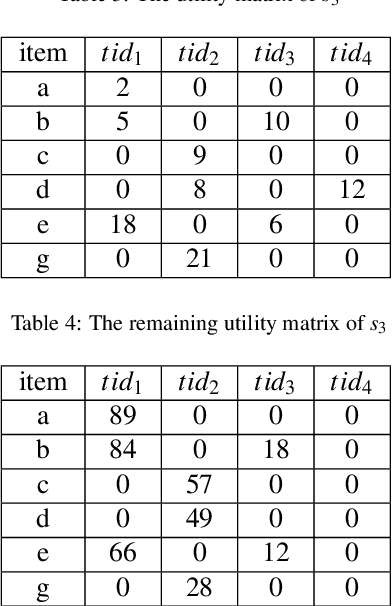
High utility sequential pattern mining (HUSPM) aims to mine all patterns that yield a high utility (profit) in a sequence dataset. HUSPM is useful for several applications such as market basket analysis, marketing, and website clickstream analysis. In these applications, users may also consider high utility patterns frequently appearing in the dataset to obtain more fruitful information. However, this task is high computation since algorithms may generate a combinatorial explosive number of candidates that may be redundant or of low importance. To reduce complexity and obtain a compact set of frequent high utility sequential patterns (FHUSPs), this paper proposes an algorithm named CHUSP for mining closed frequent high utility sequential patterns (CHUSPs). Such patterns keep a concise representation while preserving the same expressive power of the complete set of FHUSPs. The proposed algorithm relies on a CHUS data structure to maintain information during mining. It uses three pruning strategies to eliminate early low-utility and non-frequent patterns, thereby reducing the search space. An extensive experimental evaluation was performed on six real-life datasets to evaluate the performance of CHUSP in terms of execution time, memory usage, and the number of generated patterns. Experimental results show that CHUSP can efficiently discover the compact set of CHUSPs under different user-defined thresholds.
Capturing the motion of every joint: 3D human pose and shape estimation with independent tokens
Mar 01, 2023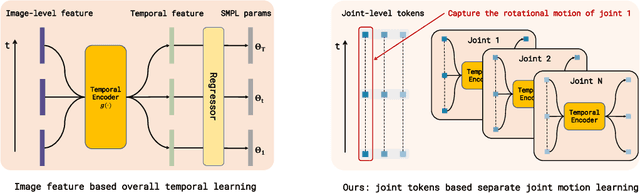
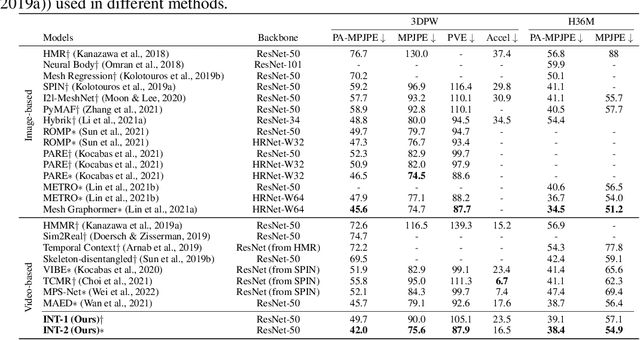
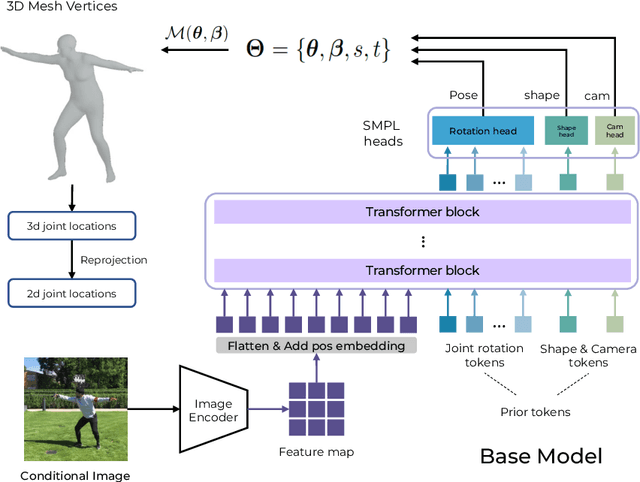

In this paper we present a novel method to estimate 3D human pose and shape from monocular videos. This task requires directly recovering pixel-alignment 3D human pose and body shape from monocular images or videos, which is challenging due to its inherent ambiguity. To improve precision, existing methods highly rely on the initialized mean pose and shape as prior estimates and parameter regression with an iterative error feedback manner. In addition, video-based approaches model the overall change over the image-level features to temporally enhance the single-frame feature, but fail to capture the rotational motion at the joint level, and cannot guarantee local temporal consistency. To address these issues, we propose a novel Transformer-based model with a design of independent tokens. First, we introduce three types of tokens independent of the image feature: \textit{joint rotation tokens, shape token, and camera token}. By progressively interacting with image features through Transformer layers, these tokens learn to encode the prior knowledge of human 3D joint rotations, body shape, and position information from large-scale data, and are updated to estimate SMPL parameters conditioned on a given image. Second, benefiting from the proposed token-based representation, we further use a temporal model to focus on capturing the rotational temporal information of each joint, which is empirically conducive to preventing large jitters in local parts. Despite being conceptually simple, the proposed method attains superior performances on the 3DPW and Human3.6M datasets. Using ResNet-50 and Transformer architectures, it obtains 42.0 mm error on the PA-MPJPE metric of the challenging 3DPW, outperforming state-of-the-art counterparts by a large margin. Code will be publicly available at https://github.com/yangsenius/INT_HMR_Model
DMODE: Differential Monocular Object Distance Estimation Module without Class Specific Information
Oct 23, 2022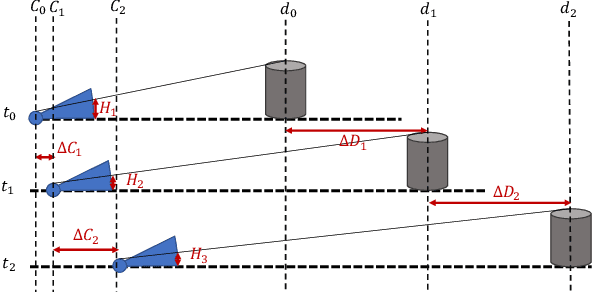
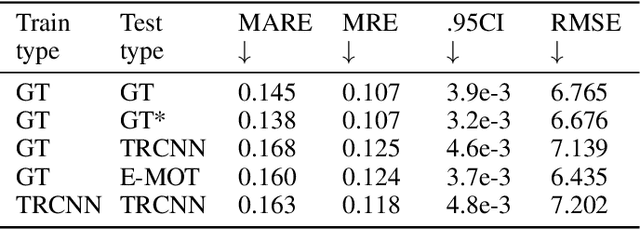
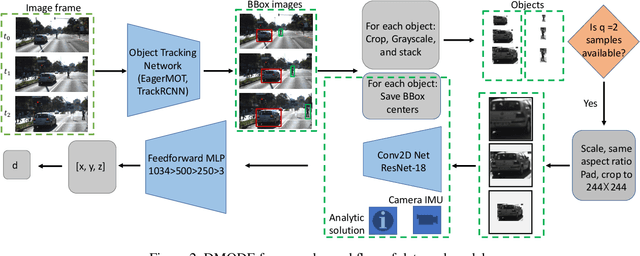
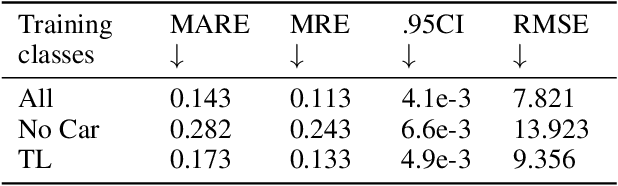
Using a single camera to estimate the distances of objects reduces costs compared to stereo-vision and LiDAR. Although monocular distance estimation has been studied in the literature, previous methods mostly rely on knowing an object's class in some way. This can result in deteriorated performance for dataset with multi-class objects and objects with an undefined class. In this paper, we aim to overcome the potential downsides of class-specific approaches, and provide an alternative technique called DMODE that does not require any information relating to its class. Using differential approaches, we combine the changes in an object's size over time together with the camera's motion to estimate the object's distance. Since DMODE is class agnostic method, it is easily adaptable to new environments. Therefore, it is able to maintain performance across different object detectors, and be easily adapted to new object classes. We tested our model across different scenarios of training and testing on the KITTI MOTS dataset's ground-truth bounding box annotations, and bounding box outputs of TrackRCNN and EagerMOT. The instantaneous change of bounding box sizes and camera position are then used to obtain an object's position in 3D without measuring its detection source or class properties. Our results show that we are able to outperform traditional alternatives methods e.g. IPM \cite{TuohyIPM}, SVR \cite{svr}, and \cite{zhu2019learning} in test environments with multi-class object distance detections.
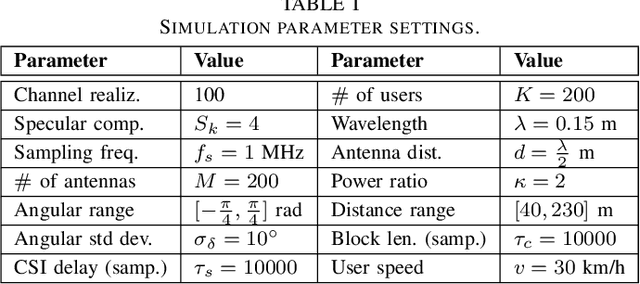
Sensing aided Channel Estimation in Wideband Millimeter-Wave MIMO Systems
Feb 04, 2023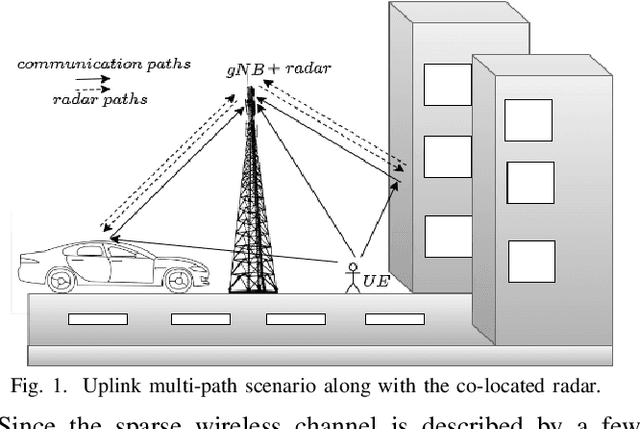
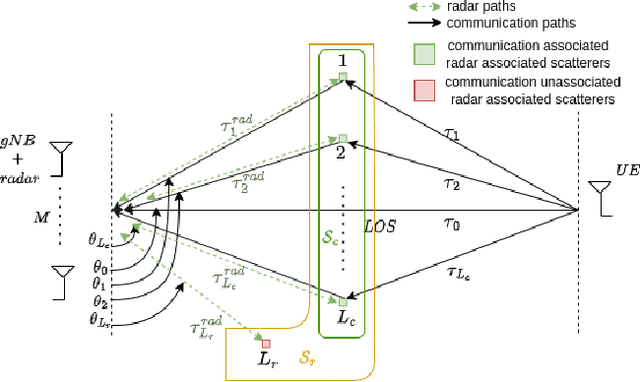
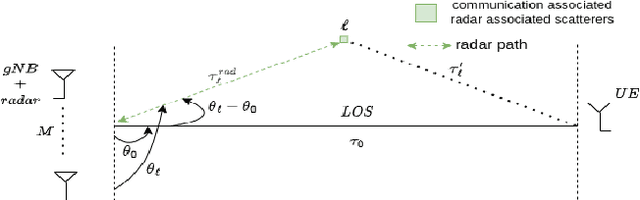
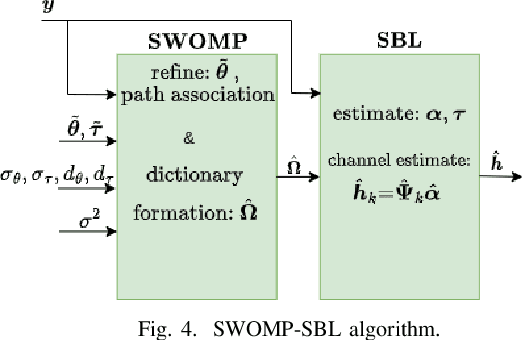
In this work, the uplink channel estimation problem is considered for a millimeter wave (mmWave) multi-input multi-output (MIMO) system. It is well known that pilot overhead and computation complexity in estimating the channel increases with the number of antennas and the bandwidth. To overcome this, the proposed approach allows the channel estimation at the base station to be aided by the sensing information. The sensing information contains an estimate of scatterers locations in an environment. A simultaneous weighting orthogonal matching pursuit (SWOMP) - sparse Bayesian learning (SBL) algorithm is proposed that efficiently incorporates this sensing information in the communication channel estimation procedure. The proposed framework can cope with scenarios where a) scatterers present in the sensing information are not associated with the communication channel and b) imperfections in the scatterers' location. Simulation results show that the proposed sensing aided channel estimation algorithm can obtain good wideband performance only at the cost of fractional pilot overhead. Finally, the Cramer-Rao Bound (CRB) for the angle estimation and multipath channel gains in the SBL is derived, providing valuable insights into the local identifiability of the proposed algorithms.
Exorcising ''Wraith'': Protecting LiDAR-based Object Detector in Automated Driving System from Appearing Attacks
Mar 17, 2023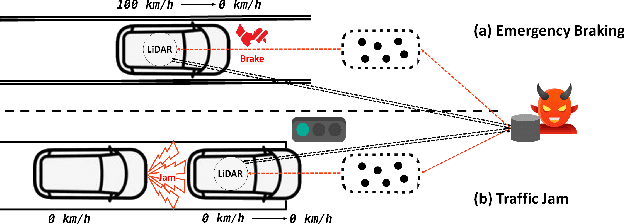

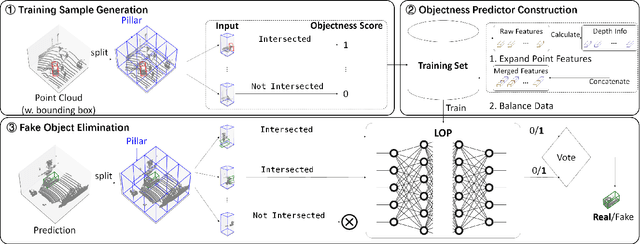
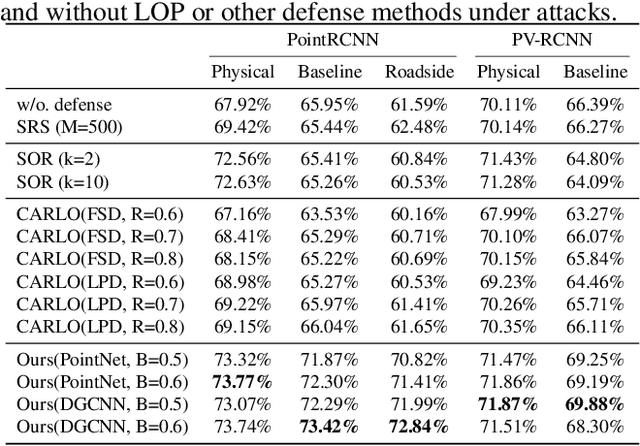
Automated driving systems rely on 3D object detectors to recognize possible obstacles from LiDAR point clouds. However, recent works show the adversary can forge non-existent cars in the prediction results with a few fake points (i.e., appearing attack). By removing statistical outliers, existing defenses are however designed for specific attacks or biased by predefined heuristic rules. Towards more comprehensive mitigation, we first systematically inspect the mechanism of recent appearing attacks: Their common weaknesses are observed in crafting fake obstacles which (i) have obvious differences in the local parts compared with real obstacles and (ii) violate the physical relation between depth and point density. In this paper, we propose a novel plug-and-play defensive module which works by side of a trained LiDAR-based object detector to eliminate forged obstacles where a major proportion of local parts have low objectness, i.e., to what degree it belongs to a real object. At the core of our module is a local objectness predictor, which explicitly incorporates the depth information to model the relation between depth and point density, and predicts each local part of an obstacle with an objectness score. Extensive experiments show, our proposed defense eliminates at least 70% cars forged by three known appearing attacks in most cases, while, for the best previous defense, less than 30% forged cars are eliminated. Meanwhile, under the same circumstance, our defense incurs less overhead for AP/precision on cars compared with existing defenses. Furthermore, We validate the effectiveness of our proposed defense on simulation-based closed-loop control driving tests in the open-source system of Baidu's Apollo.
BanglaCoNER: Towards Robust Bangla Complex Named Entity Recognition
Mar 17, 2023
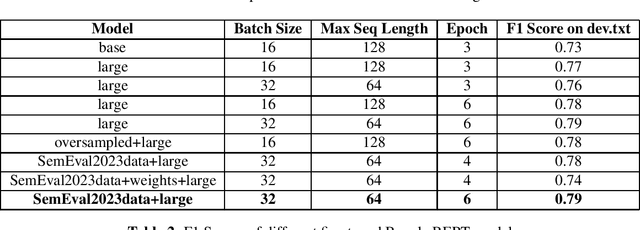
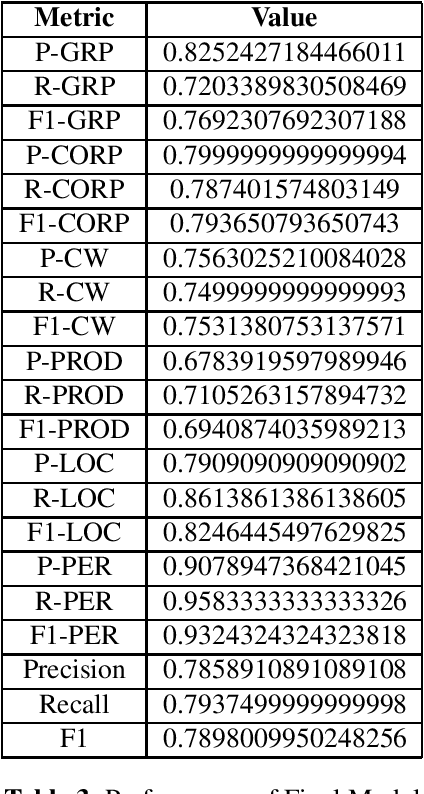
Named Entity Recognition (NER) is a fundamental task in natural language processing that involves identifying and classifying named entities in text. But much work hasn't been done for complex named entity recognition in Bangla, despite being the seventh most spoken language globally. CNER is a more challenging task than traditional NER as it involves identifying and classifying complex and compound entities, which are not common in Bangla language. In this paper, we present the winning solution of Bangla Complex Named Entity Recognition Challenge - addressing the CNER task on BanglaCoNER dataset using two different approaches, namely Conditional Random Fields (CRF) and finetuning transformer based Deep Learning models such as BanglaBERT. The dataset consisted of 15300 sentences for training and 800 sentences for validation, in the .conll format. Exploratory Data Analysis (EDA) on the dataset revealed that the dataset had 7 different NER tags, with notable presence of English words, suggesting that the dataset is synthetic and likely a product of translation. We experimented with a variety of feature combinations including Part of Speech (POS) tags, word suffixes, Gazetteers, and cluster information from embeddings, while also finetuning the BanglaBERT (large) model for NER. We found that not all linguistic patterns are immediately apparent or even intuitive to humans, which is why Deep Learning based models has proved to be the more effective model in NLP, including CNER task. Our fine tuned BanglaBERT (large) model achieves an F1 Score of 0.79 on the validation set. Overall, our study highlights the importance of Bangla Complex Named Entity Recognition, particularly in the context of synthetic datasets. Our findings also demonstrate the efficacy of Deep Learning models such as BanglaBERT for NER in Bangla language.
HDformer: A Higher Dimensional Transformer for Diabetes Detection Utilizing Long Range Vascular Signals
Mar 17, 2023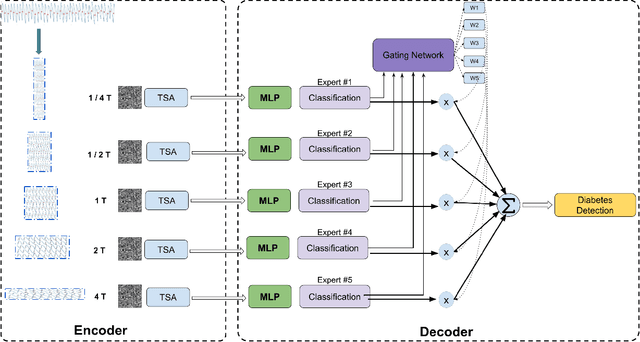
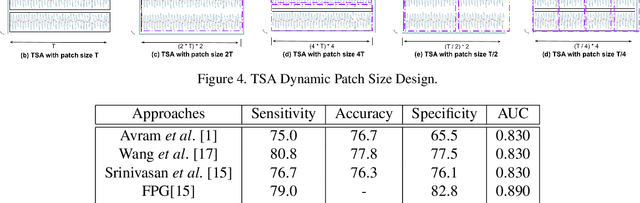
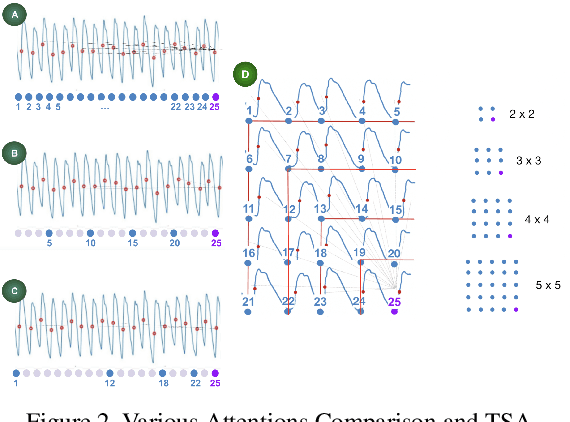
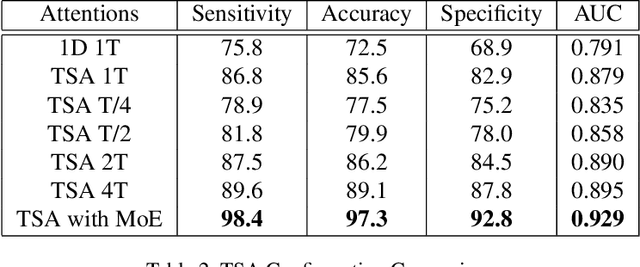
Diabetes mellitus is a worldwide concern, and early detection can help to prevent serious complications. Low-cost, non-invasive detection methods, which take cardiovascular signals into deep learning models, have emerged. However, limited accuracy constrains their clinical usage. In this paper, we present a new Transformer-based architecture, Higher Dimensional Transformer (HDformer), which takes long-range photoplethysmography (PPG) signals to detect diabetes. The long-range PPG contains broader and deeper signal contextual information compared to the less-than-one-minute PPG signals commonly utilized in existing research. To increase the capability and efficiency of processing the long range data, we propose a new attention module Time Square Attention (TSA), reducing the volume of the tokens by more than 10x, while retaining the local/global dependencies. It converts the 1-dimensional inputs into 2-dimensional representations and groups adjacent points into a single 2D token, using the 2D Transformer models as the backbone of the encoder. It generates the dynamic patch sizes into a gated mixture-of-experts (MoE) network as decoder, which optimizes the learning on different attention areas. Extensive experimentations show that HDformer results in the state-of-the-art performance (sensitivity 98.4, accuracy 97.3, specificity 92.8, and AUC 0.929) on the standard MIMIC-III dataset, surpassing existing studies. This work is the first time to take long-range, non-invasive PPG signals via Transformer for diabetes detection, achieving a more scalable and convenient solution compared to traditional invasive approaches. The proposed HDformer can also be scaled to analyze general long-range biomedical waveforms. A wearable prototype finger-ring is designed as a proof of concept.
Joint User Scheduling and Precoding for XL-MIMO Systems with Imperfect CSI
Feb 25, 2023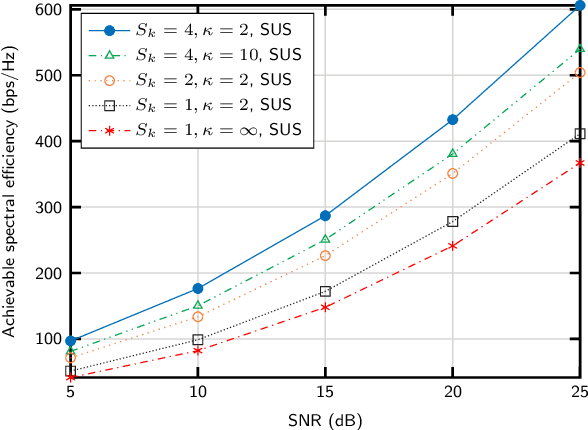
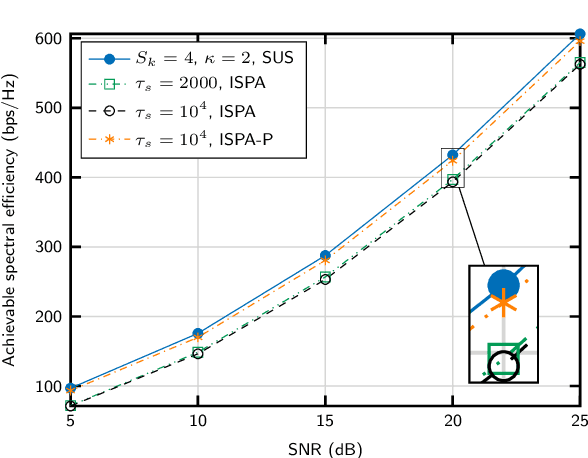
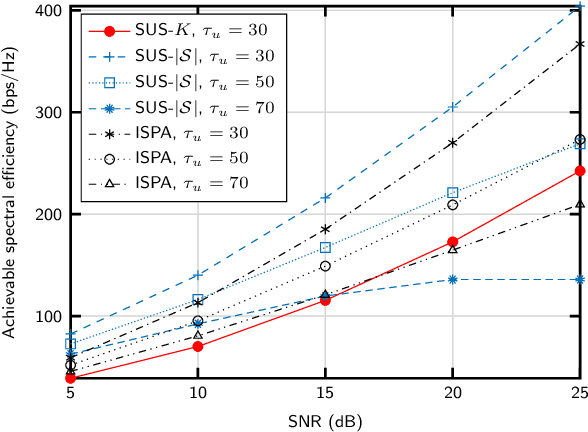
We propose an algorithm for joint precoding and user selection in multiple-input multiple-output systems with extremely-large aperture arrays, assuming realistic channel conditions and imperfect channel estimates. The use of long-term channel state information (CSI) for user scheduling, and a proper selection of the set of users for which CSI is updated allow for obtaining an improved achievable sum spectral efficiency. We also confirm that the effect of imperfect CSI in the precoding vector design and the cost of training must be taken into consideration for realistic performance prediction.
EHRDiff: Exploring Realistic EHR Synthesis with Diffusion Models
Mar 10, 2023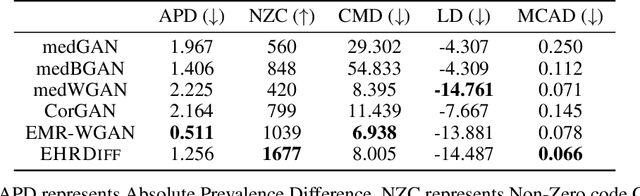
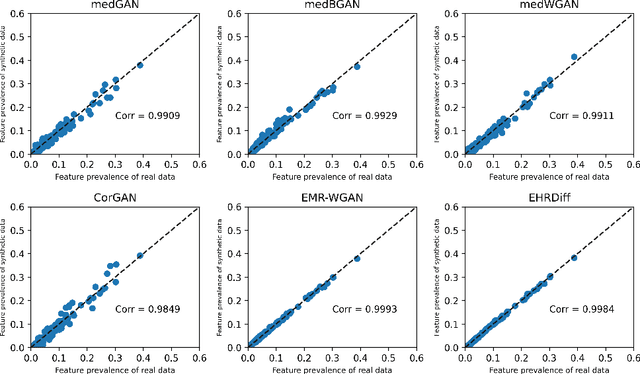
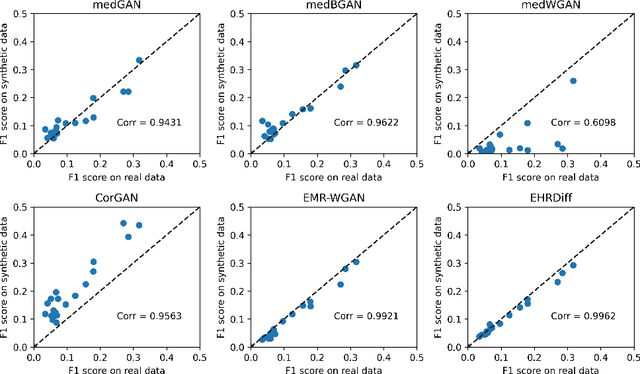
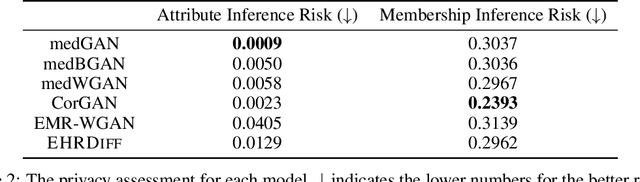
Electronic health records (EHR) contain vast biomedical knowledge and are rich resources for developing precise medicine systems. However, due to privacy concerns, there are limited high-quality EHR data accessible to researchers hence hindering the advancement of methodologies. Recent research has explored using generative modelling methods to synthesize realistic EHR data, and most proposed methods are based on the generative adversarial network (GAN) and its variants for EHR synthesis. Although GAN-style methods achieved state-of-the-art performance in generating high-quality EHR data, such methods are hard to train and prone to mode collapse. Diffusion models are recently proposed generative modelling methods and set cutting-edge performance in image generation. The performance of diffusion models in realistic EHR synthesis is rarely explored. In this work, we explore whether the superior performance of diffusion models can translate to the domain of EHR synthesis and propose a novel EHR synthesis method named EHRDiff. Through comprehensive experiments, EHRDiff achieves new state-of-the-art performance for the quality of synthetic EHR data and can better protect private information in real training EHRs in the meanwhile.