 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
QoS prediction in radio vehicular environments via prior user information
Feb 27, 2024
Reliable wireless communications play an important role in the automotive industry as it helps to enhance current use cases and enable new ones such as connected autonomous driving, platooning, cooperative maneuvering, teleoperated driving, and smart navigation. These and other use cases often rely on specific quality of service (QoS) levels for communication. Recently, the area of predictive quality of service (QoS) has received a great deal of attention as a key enabler to forecast communication quality well enough in advance. However, predicting QoS in a reliable manner is a notoriously difficult task. In this paper, we evaluate ML tree-ensemble methods to predict QoS in the range of minutes with data collected from a cellular test network. We discuss radio environment characteristics and we showcase how these can be used to improve ML performance and further support the uptake of ML in commercial networks. Specifically, we use the correlations of the measurements coming from the radio environment by including information of prior vehicles to enhance the prediction of the target vehicles. Moreover, we are extending prior art by showing how longer prediction horizons can be supported.
The future of document indexing: GPT and Donut revolutionize table of content processing
Mar 12, 2024

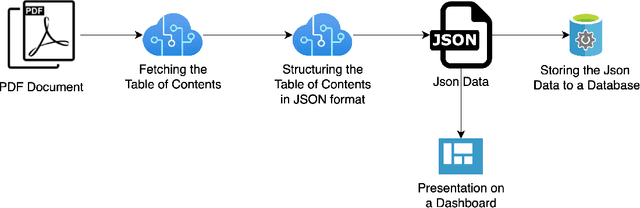
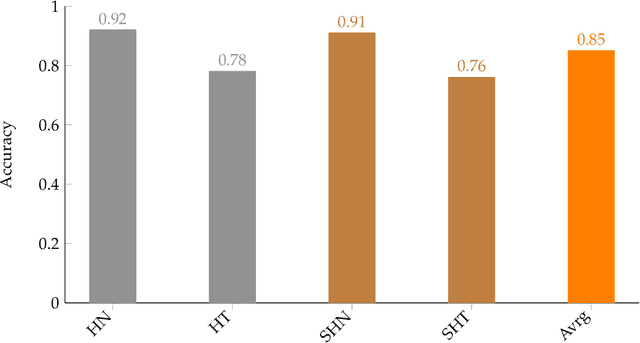
Industrial projects rely heavily on lengthy, complex specification documents, making tedious manual extraction of structured information a major bottleneck. This paper introduces an innovative approach to automate this process, leveraging the capabilities of two cutting-edge AI models: Donut, a model that extracts information directly from scanned documents without OCR, and OpenAI GPT-3.5 Turbo, a robust large language model. The proposed methodology is initiated by acquiring the table of contents (ToCs) from construction specification documents and subsequently structuring the ToCs text into JSON data. Remarkable accuracy is achieved, with Donut reaching 85% and GPT-3.5 Turbo reaching 89% in effectively organizing the ToCs. This landmark achievement represents a significant leap forward in document indexing, demonstrating the immense potential of AI to automate information extraction tasks across diverse document types, boosting efficiency and liberating critical resources in various industries.
Spiking Wavelet Transformer
Mar 17, 2024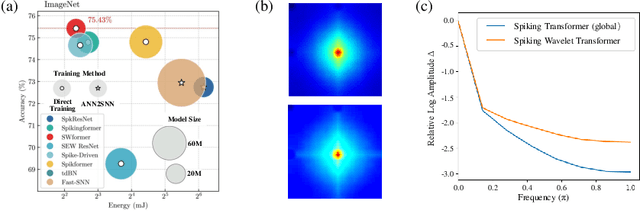
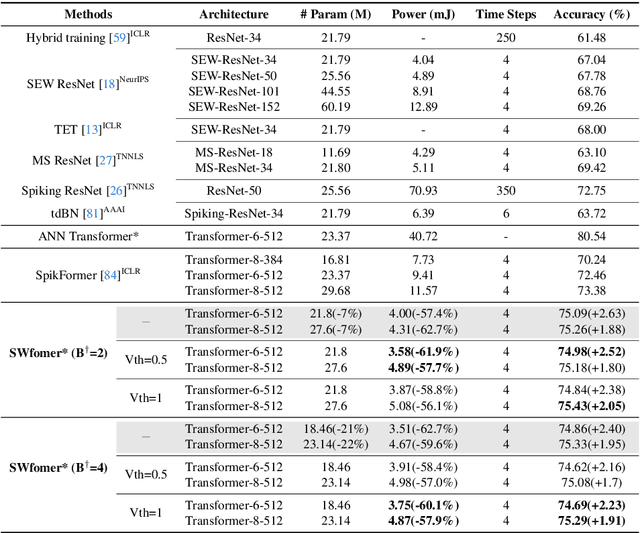
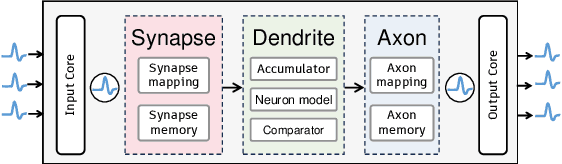
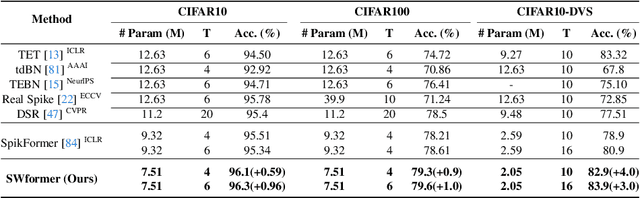
Spiking neural networks (SNNs) offer an energy-efficient alternative to conventional deep learning by mimicking the event-driven processing of the brain. Incorporating the Transformers with SNNs has shown promise for accuracy, yet it is incompetent to capture high-frequency patterns like moving edge and pixel-level brightness changes due to their reliance on global self-attention operations. Porting frequency representations in SNN is challenging yet crucial for event-driven vision. To address this issue, we propose the Spiking Wavelet Transformer (SWformer), an attention-free architecture that effectively learns comprehensive spatial-frequency features in a spike-driven manner by leveraging the sparse wavelet transform. The critical component is a Frequency-Aware Token Mixer (FATM) with three branches: 1) spiking wavelet learner for spatial-frequency domain learning, 2) convolution-based learner for spatial feature extraction, and 3) spiking pointwise convolution for cross-channel information aggregation. We also adopt negative spike dynamics to strengthen the frequency representation further. This enables the SWformer to outperform vanilla Spiking Transformers in capturing high-frequency visual components, as evidenced by our empirical results. Experiments on both static and neuromorphic datasets demonstrate SWformer's effectiveness in capturing spatial-frequency patterns in a multiplication-free, event-driven fashion, outperforming state-of-the-art SNNs. SWformer achieves an over 50% reduction in energy consumption, a 21.1% reduction in parameter count, and a 2.40% performance improvement on the ImageNet dataset compared to vanilla Spiking Transformers.
Boosting Semi-Supervised Temporal Action Localization by Learning from Non-Target Classes
Mar 17, 2024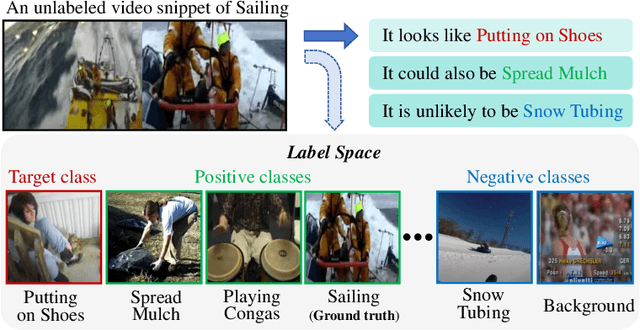
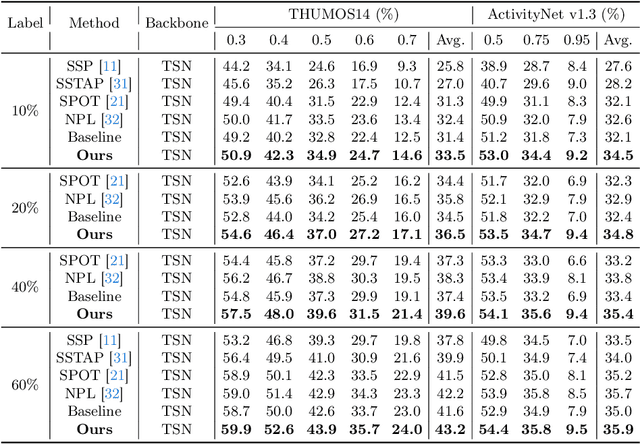
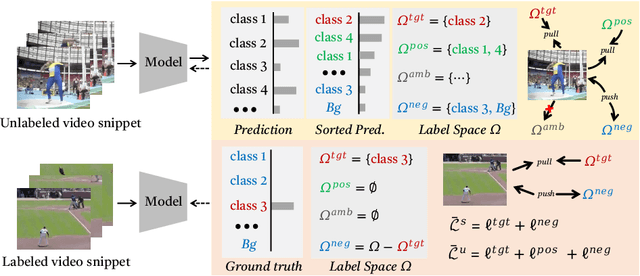
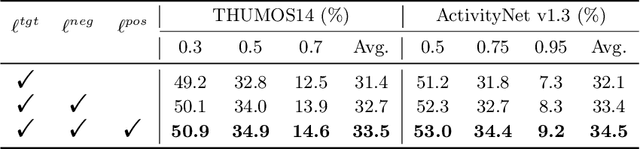
The crux of semi-supervised temporal action localization (SS-TAL) lies in excavating valuable information from abundant unlabeled videos. However, current approaches predominantly focus on building models that are robust to the error-prone target class (i.e, the predicted class with the highest confidence) while ignoring informative semantics within non-target classes. This paper approaches SS-TAL from a novel perspective by advocating for learning from non-target classes, transcending the conventional focus solely on the target class. The proposed approach involves partitioning the label space of the predicted class distribution into distinct subspaces: target class, positive classes, negative classes, and ambiguous classes, aiming to mine both positive and negative semantics that are absent in the target class, while excluding ambiguous classes. To this end, we first devise innovative strategies to adaptively select high-quality positive and negative classes from the label space, by modeling both the confidence and rank of a class in relation to those of the target class. Then, we introduce novel positive and negative losses designed to guide the learning process, pushing predictions closer to positive classes and away from negative classes. Finally, the positive and negative processes are integrated into a hybrid positive-negative learning framework, facilitating the utilization of non-target classes in both labeled and unlabeled videos. Experimental results on THUMOS14 and ActivityNet v1.3 demonstrate the superiority of the proposed method over prior state-of-the-art approaches.
Identification of important nodes in the information propagation network based on the artificial intelligence method
Feb 29, 2024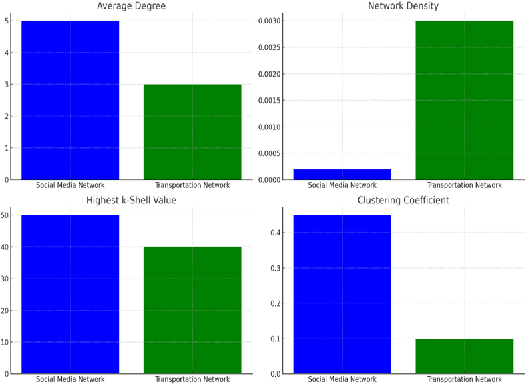
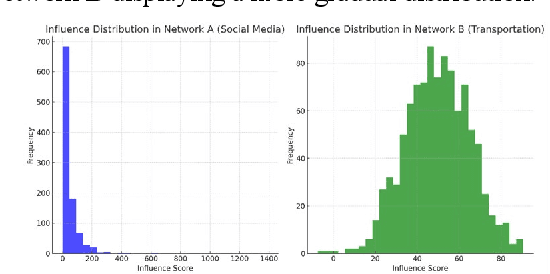
This study presents an integrated approach for identifying key nodes in information propagation networks using advanced artificial intelligence methods. We introduce a novel technique that combines the Decision-making Trial and Evaluation Laboratory (DEMATEL) method with the Global Structure Model (GSM), creating a synergistic model that effectively captures both local and global influences within a network. This method is applied across various complex networks, such as social, transportation, and communication systems, utilizing the Global Network Influence Dataset (GNID). Our analysis highlights the structural dynamics and resilience of these networks, revealing insights into node connectivity and community formation. The findings demonstrate the effectiveness of our AI-based approach in offering a comprehensive understanding of network behavior, contributing significantly to strategic network analysis and optimization.
Decentralizing Coherent Joint Transmission Precoding via Deterministic Equivalents
Mar 15, 2024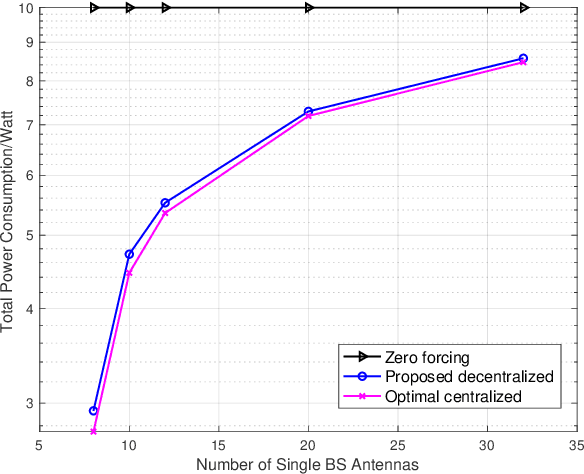
In order to control the inter-cell interference for a multi-cell multi-user multiple-input multiple-output network, we consider the precoder design for coordinated multi-point with downlink coherent joint transmission. To avoid costly information exchange among the cooperating base stations in a centralized precoding scheme, we propose a decentralized one by considering the power minimization problem. By approximating the inter-cell interference using the deterministic equivalents, this problem is decoupled to sub-problems which are solved in a decentralized manner at different base stations. Simulation results demonstrate the effectiveness of our proposed decentralized precoding scheme, where only 2 ~ 7% more transmit power is needed compared with the optimal centralized precoder.
Fisher Mask Nodes for Language Model Merging
Mar 14, 2024
Fine-tuning pre-trained models provides significant advantages in downstream performance. The ubiquitous nature of pre-trained models such as BERT and its derivatives in natural language processing has also led to a proliferation of task-specific fine-tuned models. As these models typically only perform one task well, additional training or ensembling is required in multi-task scenarios. The growing field of model merging provides a solution, dealing with the challenge of combining multiple task-specific models into a single multi-task model. In this study, we introduce a novel model merging method for Transformers, combining insights from previous work in Fisher-weighted averaging and the use of Fisher information in model pruning. Utilizing the Fisher information of mask nodes within the Transformer architecture, we devise a computationally efficient weighted-averaging scheme. Our method exhibits a regular and significant performance increase across various models in the BERT family, outperforming full-scale Fisher-weighted averaging in a fraction of the computational cost, with baseline performance improvements of up to +6.5 and a speedup of 57.4x. Our results prove the potential of our method in current multi-task learning environments and suggest its scalability and adaptability to new model architectures and learning scenarios.
PoIFusion: Multi-Modal 3D Object Detection via Fusion at Points of Interest
Mar 14, 2024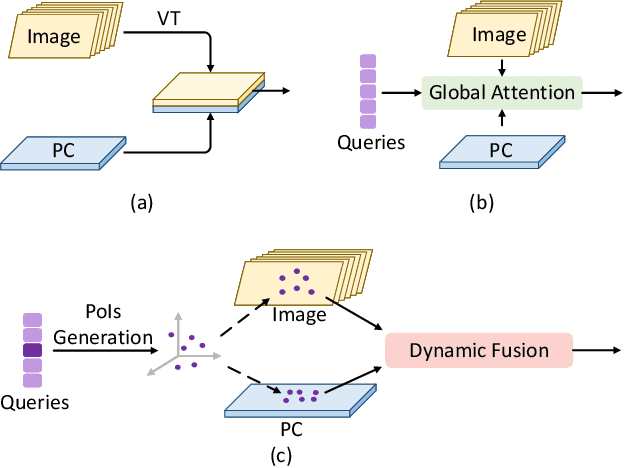
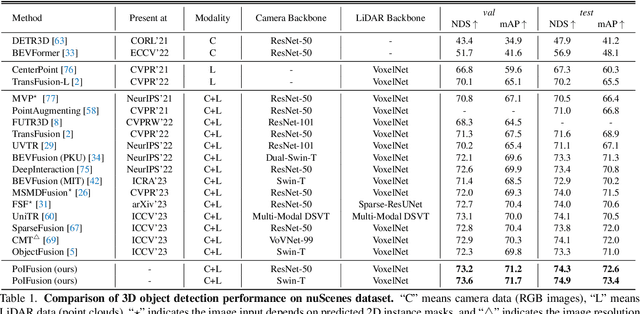
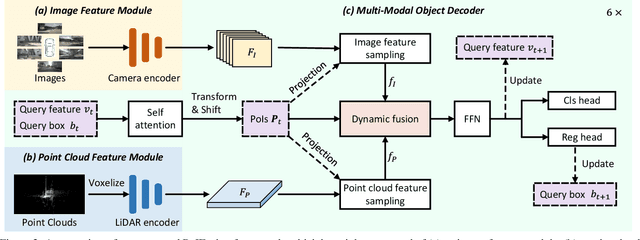
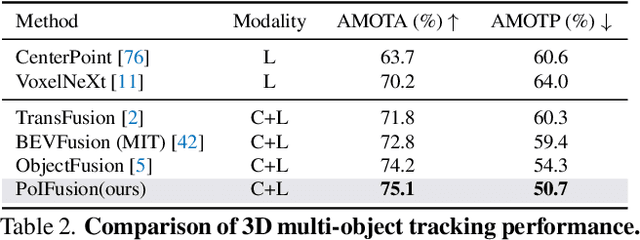
In this work, we present PoIFusion, a simple yet effective multi-modal 3D object detection framework to fuse the information of RGB images and LiDAR point clouds at the point of interest (abbreviated as PoI). Technically, our PoIFusion follows the paradigm of query-based object detection, formulating object queries as dynamic 3D boxes. The PoIs are adaptively generated from each query box on the fly, serving as the keypoints to represent a 3D object and play the role of basic units in multi-modal fusion. Specifically, we project PoIs into the view of each modality to sample the corresponding feature and integrate the multi-modal features at each PoI through a dynamic fusion block. Furthermore, the features of PoIs derived from the same query box are aggregated together to update the query feature. Our approach prevents information loss caused by view transformation and eliminates the computation-intensive global attention, making the multi-modal 3D object detector more applicable. We conducted extensive experiments on the nuScenes dataset to evaluate our approach. Remarkably, our PoIFusion achieves 74.9\% NDS and 73.4\% mAP, setting a state-of-the-art record on the multi-modal 3D object detection benchmark. Codes will be made available via \url{https://djiajunustc.github.io/projects/poifusion}.
Zero-shot and Few-shot Generation Strategies for Artificial Clinical Records
Mar 14, 2024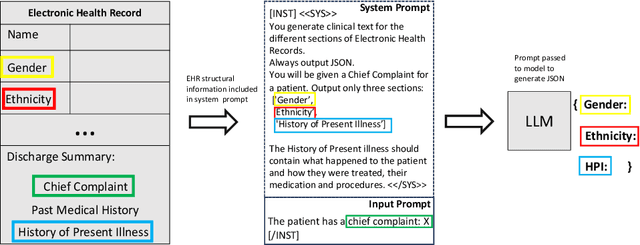

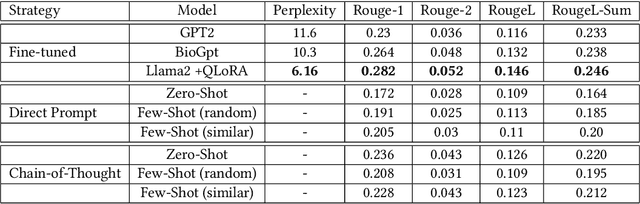
The challenge of accessing historical patient data for clinical research, while adhering to privacy regulations, is a significant obstacle in medical science. An innovative approach to circumvent this issue involves utilising synthetic medical records that mirror real patient data without compromising individual privacy. The creation of these synthetic datasets, particularly without using actual patient data to train Large Language Models (LLMs), presents a novel solution as gaining access to sensitive patient information to train models is also a challenge. This study assesses the capability of the Llama 2 LLM to create synthetic medical records that accurately reflect real patient information, employing zero-shot and few-shot prompting strategies for comparison against fine-tuned methodologies that do require sensitive patient data during training. We focus on generating synthetic narratives for the History of Present Illness section, utilising data from the MIMIC-IV dataset for comparison. In this work introduce a novel prompting technique that leverages a chain-of-thought approach, enhancing the model's ability to generate more accurate and contextually relevant medical narratives without prior fine-tuning. Our findings suggest that this chain-of-thought prompted approach allows the zero-shot model to achieve results on par with those of fine-tuned models, based on Rouge metrics evaluation.
Silico-centric Theory of Mind
Mar 14, 2024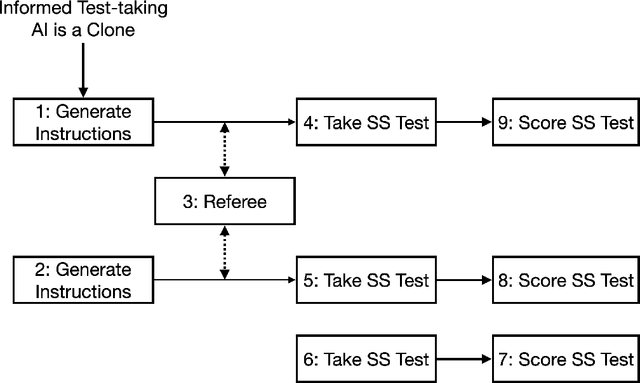
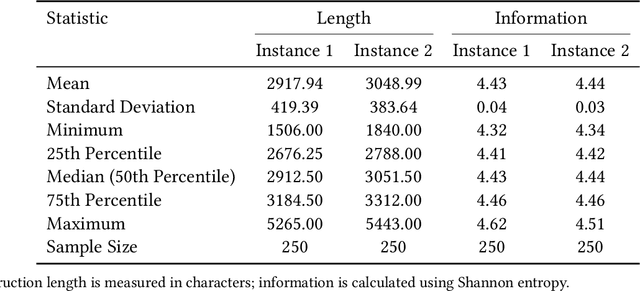
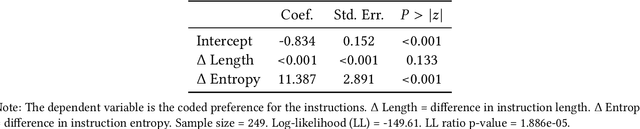
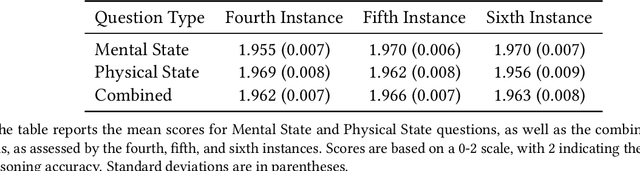
Theory of Mind (ToM) refers to the ability to attribute mental states, such as beliefs, desires, intentions, and knowledge, to oneself and others, and to understand that these mental states can differ from one's own and from reality. We investigate ToM in environments with multiple, distinct, independent AI agents, each possessing unique internal states, information, and objectives. Inspired by human false-belief experiments, we present an AI ('focal AI') with a scenario where its clone undergoes a human-centric ToM assessment. We prompt the focal AI to assess whether its clone would benefit from additional instructions. Concurrently, we give its clones the ToM assessment, both with and without the instructions, thereby engaging the focal AI in higher-order counterfactual reasoning akin to human mentalizing--with respect to humans in one test and to other AI in another. We uncover a discrepancy: Contemporary AI demonstrates near-perfect accuracy on human-centric ToM assessments. Since information embedded in one AI is identically embedded in its clone, additional instructions are redundant. Yet, we observe AI crafting elaborate instructions for their clones, erroneously anticipating a need for assistance. An independent referee AI agrees with these unsupported expectations. Neither the focal AI nor the referee demonstrates ToM in our 'silico-centric' test.