 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Quantifying Context Mixing in Transformers
Jan 30, 2023

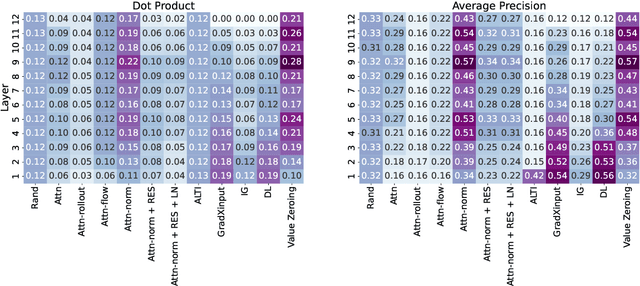
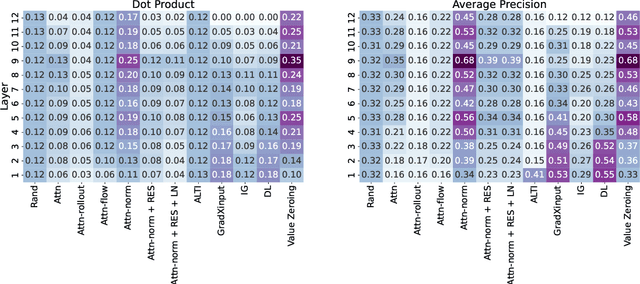
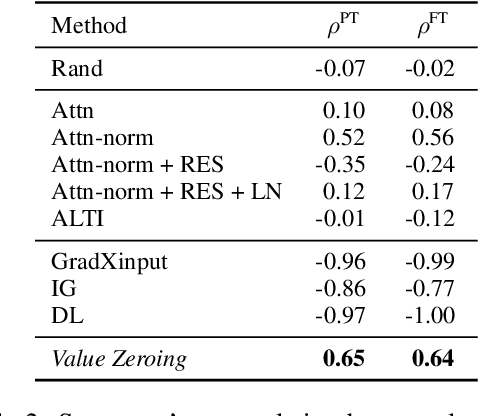
Self-attention weights and their transformed variants have been the main source of information for analyzing token-to-token interactions in Transformer-based models. But despite their ease of interpretation, these weights are not faithful to the models' decisions as they are only one part of an encoder, and other components in the encoder layer can have considerable impact on information mixing in the output representations. In this work, by expanding the scope of analysis to the whole encoder block, we propose Value Zeroing, a novel context mixing score customized for Transformers that provides us with a deeper understanding of how information is mixed at each encoder layer. We demonstrate the superiority of our context mixing score over other analysis methods through a series of complementary evaluations with different viewpoints based on linguistically informed rationales, probing, and faithfulness analysis.
Finding the Law: Enhancing Statutory Article Retrieval via Graph Neural Networks
Jan 30, 2023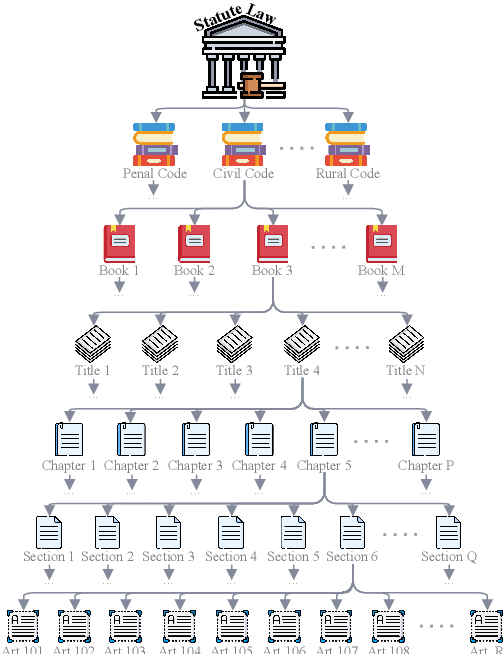
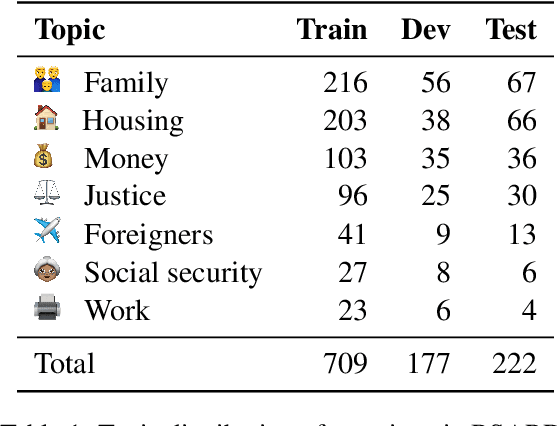
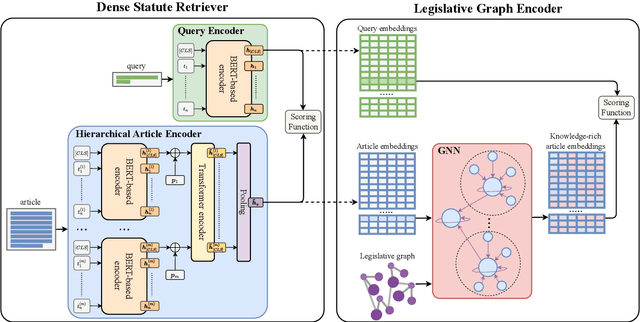
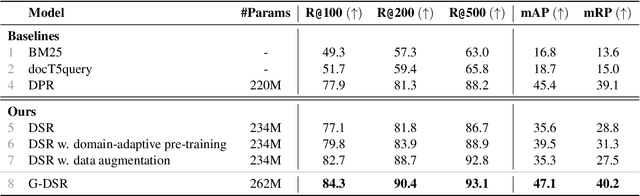
Statutory article retrieval (SAR), the task of retrieving statute law articles relevant to a legal question, is a promising application of legal text processing. In particular, high-quality SAR systems can improve the work efficiency of legal professionals and provide basic legal assistance to citizens in need at no cost. Unlike traditional ad-hoc information retrieval, where each document is considered a complete source of information, SAR deals with texts whose full sense depends on complementary information from the topological organization of statute law. While existing works ignore these domain-specific dependencies, we propose a novel graph-augmented dense statute retriever (G-DSR) model that incorporates the structure of legislation via a graph neural network to improve dense retrieval performance. Experimental results show that our approach outperforms strong retrieval baselines on a real-world expert-annotated SAR dataset.
Non-Stationary Dynamic Pricing Via Actor-Critic Information-Directed Pricing
Aug 19, 2022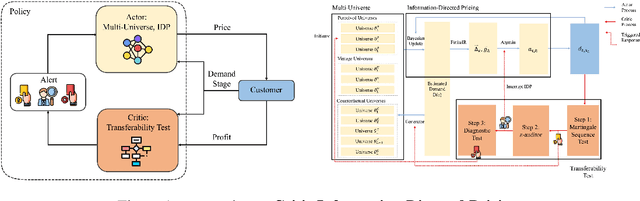
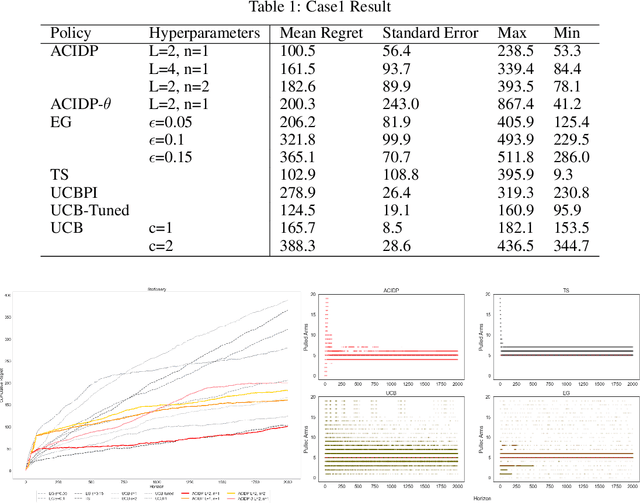
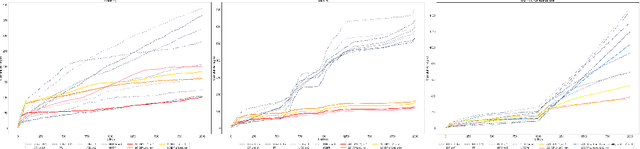
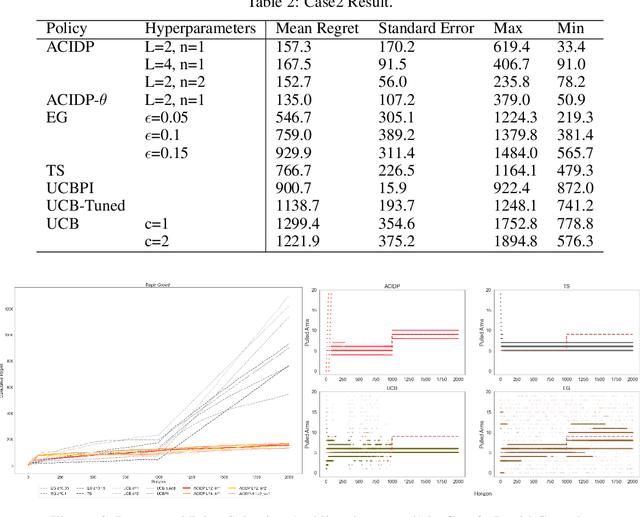
This paper presents a novel non-stationary dynamic pricing algorithm design, where pricing agents face incomplete demand information and market environment shifts. The agents run price experiments to learn about each product's demand curve and the profit-maximizing price, while being aware of market environment shifts to avoid high opportunity costs from offering sub-optimal prices. The proposed ACIDP extends information-directed sampling (IDS) algorithms from statistical machine learning to include microeconomic choice theory, with a novel pricing strategy auditing procedure to escape sub-optimal pricing after market environment shift. The proposed ACIDP outperforms competing bandit algorithms including Upper Confidence Bound (UCB) and Thompson sampling (TS) in a series of market environment shifts.
Flow-guided Semi-supervised Video Object Segmentation
Jan 25, 2023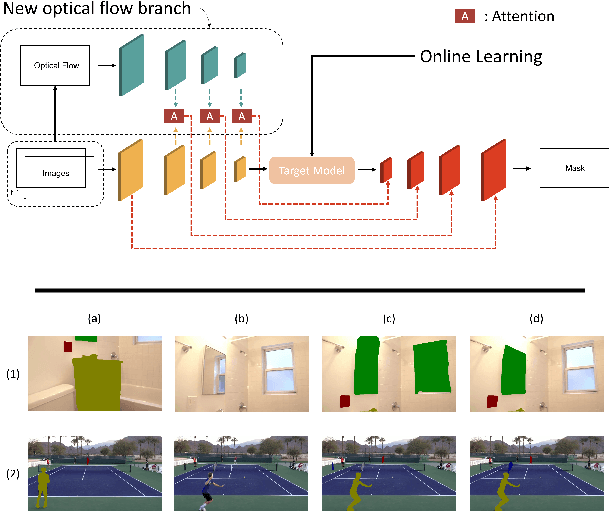
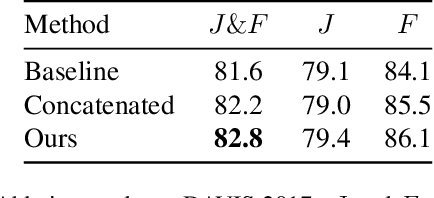
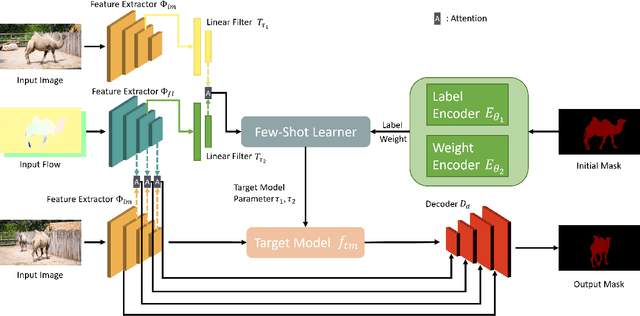
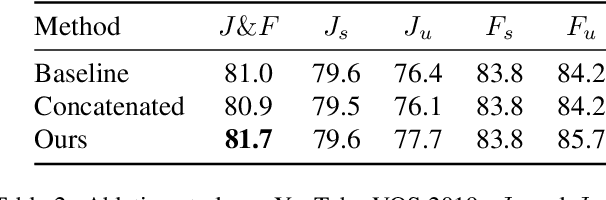
We propose an optical flow-guided approach for semi-supervised video object segmentation. Optical flow is usually exploited as additional guidance information in unsupervised video object segmentation. However, its relevance in semi-supervised video object segmentation has not been fully explored. In this work, we follow an encoder-decoder approach to address the segmentation task. A model to extract the combined information from optical flow and the image is proposed, which is then used as input to the target model and the decoder network. Unlike previous methods where concatenation is used to integrate information from image data and optical flow, a simple yet effective attention mechanism is exploited in our work. Experiments on DAVIS 2017 and YouTube-VOS 2019 show that by integrating the information extracted from optical flow into the original image branch results in a strong performance gain and our method achieves state-of-the-art performance.
Super-Resolution Neural Operator
Mar 05, 2023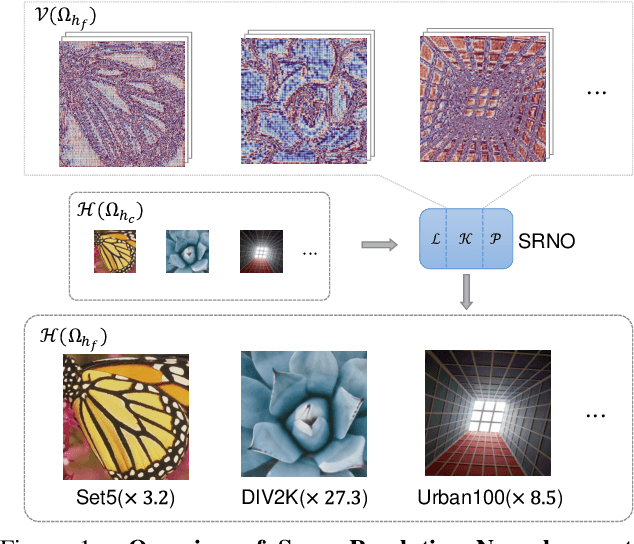
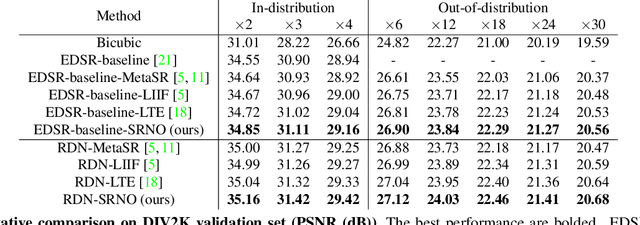

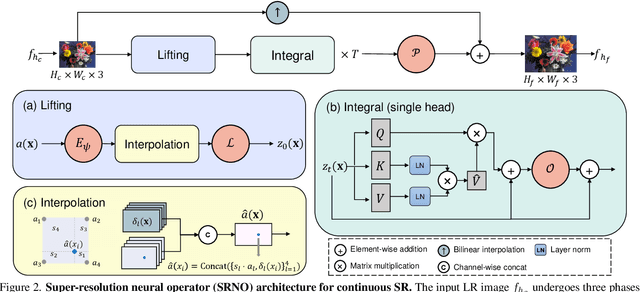
We propose Super-resolution Neural Operator (SRNO), a deep operator learning framework that can resolve high-resolution (HR) images at arbitrary scales from the low-resolution (LR) counterparts. Treating the LR-HR image pairs as continuous functions approximated with different grid sizes, SRNO learns the mapping between the corresponding function spaces. From the perspective of approximation theory, SRNO first embeds the LR input into a higher-dimensional latent representation space, trying to capture sufficient basis functions, and then iteratively approximates the implicit image function with a kernel integral mechanism, followed by a final dimensionality reduction step to generate the RGB representation at the target coordinates. The key characteristics distinguishing SRNO from prior continuous SR works are: 1) the kernel integral in each layer is efficiently implemented via the Galerkin-type attention, which possesses non-local properties in the spatial domain and therefore benefits the grid-free continuum; and 2) the multilayer attention architecture allows for the dynamic latent basis update, which is crucial for SR problems to "hallucinate" high-frequency information from the LR image. Experiments show that SRNO outperforms existing continuous SR methods in terms of both accuracy and running time. Our code is at https://github.com/2y7c3/Super-Resolution-Neural-Operator
Human-Art: A Versatile Human-Centric Dataset Bridging Natural and Artificial Scenes
Mar 05, 2023
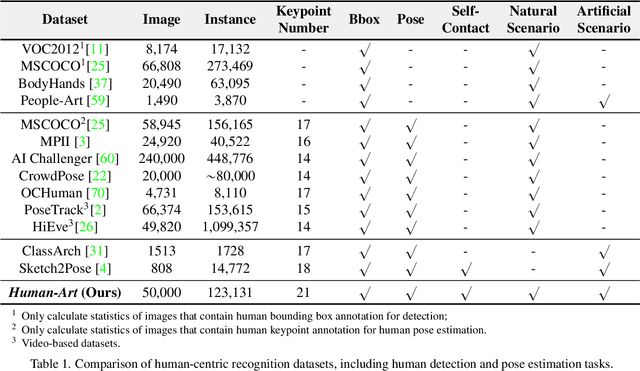
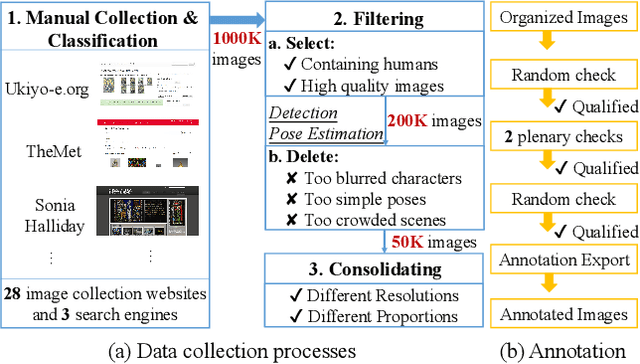
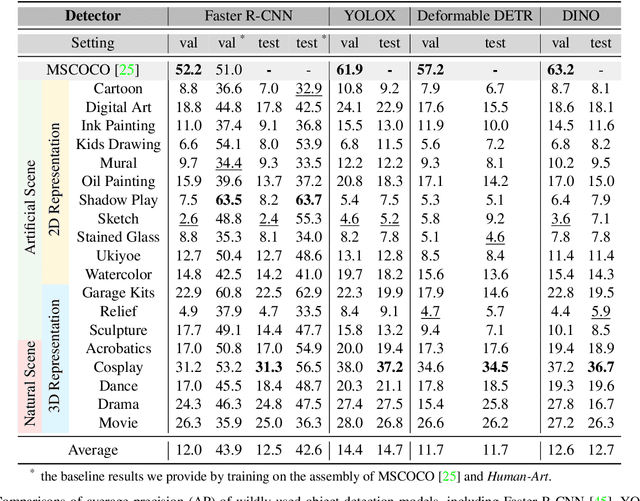
Humans have long been recorded in a variety of forms since antiquity. For example, sculptures and paintings were the primary media for depicting human beings before the invention of cameras. However, most current human-centric computer vision tasks like human pose estimation and human image generation focus exclusively on natural images in the real world. Artificial humans, such as those in sculptures, paintings, and cartoons, are commonly neglected, making existing models fail in these scenarios. As an abstraction of life, art incorporates humans in both natural and artificial scenes. We take advantage of it and introduce the Human-Art dataset to bridge related tasks in natural and artificial scenarios. Specifically, Human-Art contains 50k high-quality images with over 123k person instances from 5 natural and 15 artificial scenarios, which are annotated with bounding boxes, keypoints, self-contact points, and text information for humans represented in both 2D and 3D. It is, therefore, comprehensive and versatile for various downstream tasks. We also provide a rich set of baseline results and detailed analyses for related tasks, including human detection, 2D and 3D human pose estimation, image generation, and motion transfer. As a challenging dataset, we hope Human-Art can provide insights for relevant research and open up new research questions.
General, Single-shot, Target-less, and Automatic LiDAR-Camera Extrinsic Calibration Toolbox
Feb 10, 2023
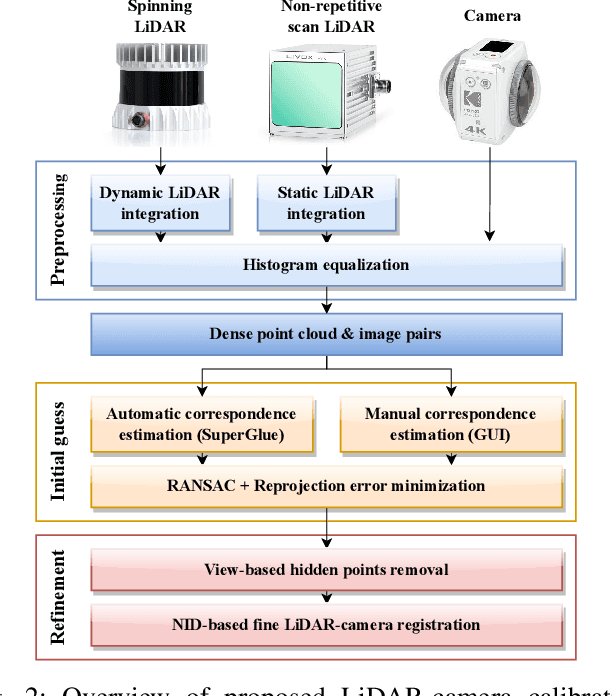


This paper presents an open source LiDAR-camera calibration toolbox that is general to LiDAR and camera projection models, requires only one pairing of LiDAR and camera data without a calibration target, and is fully automatic. For automatic initial guess estimation, we employ the SuperGlue image matching pipeline to find 2D-3D correspondences between LiDAR and camera data and estimate the LiDAR-camera transformation via RANSAC. Given the initial guess, we refine the transformation estimate with direct LiDAR-camera registration based on the normalized information distance, a mutual information-based cross-modal distance metric. For a handy calibration process, we also present several assistance capabilities (e.g., dynamic LiDAR data integration and user interface for making 2D-3D correspondence manually). The experimental results show that the proposed toolbox enables calibration of any combination of spinning and non-repetitive scan LiDARs and pinhole and omnidirectional cameras, and shows better calibration accuracy and robustness than those of the state-of-the-art edge-alignment-based calibration method.
M3AE: Multimodal Representation Learning for Brain Tumor Segmentation with Missing Modalities
Mar 09, 2023
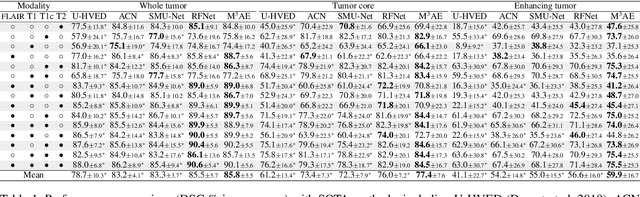
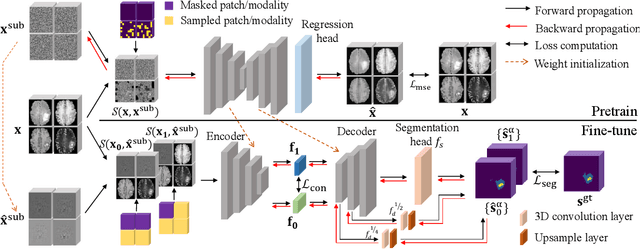
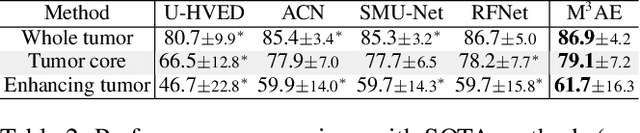
Multimodal magnetic resonance imaging (MRI) provides complementary information for sub-region analysis of brain tumors. Plenty of methods have been proposed for automatic brain tumor segmentation using four common MRI modalities and achieved remarkable performance. In practice, however, it is common to have one or more modalities missing due to image corruption, artifacts, acquisition protocols, allergy to contrast agents, or simply cost. In this work, we propose a novel two-stage framework for brain tumor segmentation with missing modalities. In the first stage, a multimodal masked autoencoder (M3AE) is proposed, where both random modalities (i.e., modality dropout) and random patches of the remaining modalities are masked for a reconstruction task, for self-supervised learning of robust multimodal representations against missing modalities. To this end, we name our framework M3AE. Meanwhile, we employ model inversion to optimize a representative full-modal image at marginal extra cost, which will be used to substitute for the missing modalities and boost performance during inference. Then in the second stage, a memory-efficient self distillation is proposed to distill knowledge between heterogenous missing-modal situations while fine-tuning the model for supervised segmentation. Our M3AE belongs to the 'catch-all' genre where a single model can be applied to all possible subsets of modalities, thus is economic for both training and deployment. Extensive experiments on BraTS 2018 and 2020 datasets demonstrate its superior performance to existing state-of-the-art methods with missing modalities, as well as the efficacy of its components. Our code is available at: https://github.com/ccarliu/m3ae.
Cooperative Saliency-based Obstacle Detection and AR Rendering for Increased Situational Awareness
Feb 02, 2023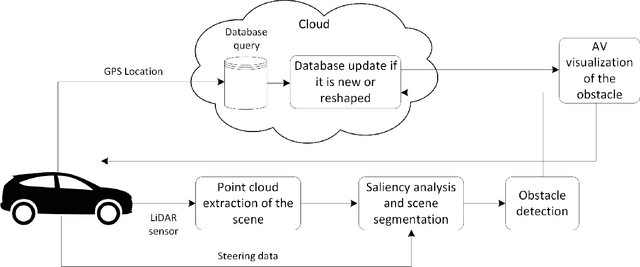

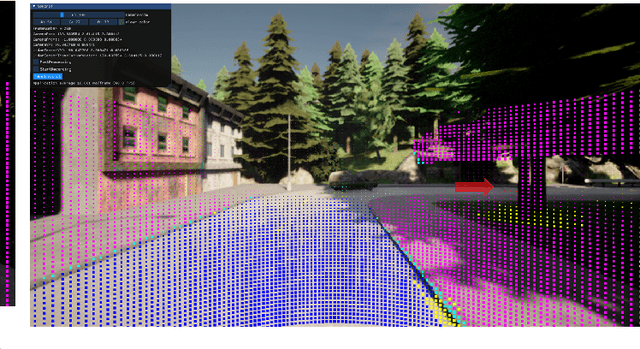

Autonomous vehicles are expected to operate safely in real-life road conditions in the next years. Nevertheless, unanticipated events such as the existence of unexpected objects in the range of the road, can put safety at risk. The advancement of sensing and communication technologies and Internet of Things may facilitate the recognition of hazardous situations and information exchange in a cooperative driving scheme, providing new opportunities for the increase of collaborative situational awareness. Safe and unobtrusive visualization of the obtained information may nowadays be enabled through the adoption of novel Augmented Reality (AR) interfaces in the form of windshields. Motivated by these technological opportunities, we propose in this work a saliency-based distributed, cooperative obstacle detection and rendering scheme for increasing the driver's situational awareness through (i) automated obstacle detection, (ii) AR visualization and (iii) information sharing (upcoming potential dangers) with other connected vehicles or road infrastructure. An extensive evaluation study using a variety of real datasets for pothole detection showed that the proposed method provides favorable results and features compared to other recent and relevant approaches.
Shortcut Learning Through the Lens of Early Training Dynamics
Feb 18, 2023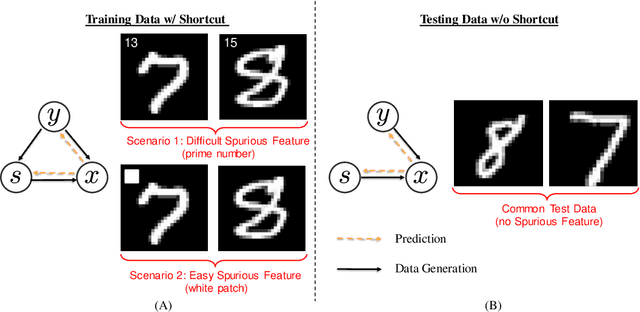

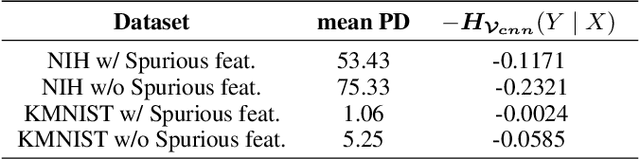
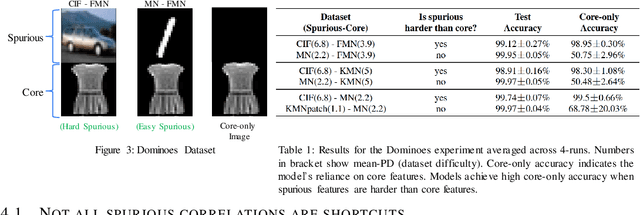
Deep Neural Networks (DNNs) are prone to learn shortcut patterns that damage the generalization of the DNN during deployment. Shortcut Learning is concerning, particularly when the DNNs are applied to safety-critical domains. This paper aims to better understand shortcut learning through the lens of the learning dynamics of the internal neurons during the training process. More specifically, we make the following observations: (1) While previous works treat shortcuts as synonymous with spurious correlations, we emphasize that not all spurious correlations are shortcuts. We show that shortcuts are only those spurious features that are "easier" than the core features. (2) We build upon this premise and use instance difficulty methods (like Prediction Depth) to quantify "easy" and to identify this behavior during the training phase. (3) We empirically show that shortcut learning can be detected by observing the learning dynamics of the DNN's early layers, irrespective of the network architecture used. In other words, easy features learned by the initial layers of a DNN early during the training are potential shortcuts. We verify our claims on simulated and real medical imaging data and justify the empirical success of our hypothesis by showing the theoretical connections between Prediction Depth and information-theoretic concepts like V-usable information. Lastly, our experiments show the insufficiency of monitoring only accuracy plots during training (as is common in machine learning pipelines), and we highlight the need for monitoring early training dynamics using example difficulty metrics.