 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
General, Single-shot, Target-less, and Automatic LiDAR-Camera Extrinsic Calibration Toolbox
Feb 10, 2023

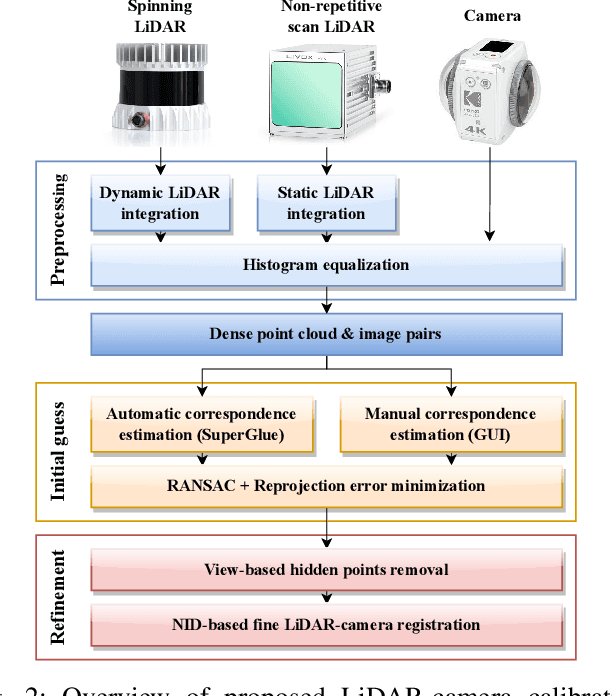


This paper presents an open source LiDAR-camera calibration toolbox that is general to LiDAR and camera projection models, requires only one pairing of LiDAR and camera data without a calibration target, and is fully automatic. For automatic initial guess estimation, we employ the SuperGlue image matching pipeline to find 2D-3D correspondences between LiDAR and camera data and estimate the LiDAR-camera transformation via RANSAC. Given the initial guess, we refine the transformation estimate with direct LiDAR-camera registration based on the normalized information distance, a mutual information-based cross-modal distance metric. For a handy calibration process, we also present several assistance capabilities (e.g., dynamic LiDAR data integration and user interface for making 2D-3D correspondence manually). The experimental results show that the proposed toolbox enables calibration of any combination of spinning and non-repetitive scan LiDARs and pinhole and omnidirectional cameras, and shows better calibration accuracy and robustness than those of the state-of-the-art edge-alignment-based calibration method.
Semi-supervised Clustering with Two Types of Background Knowledge: Fusing Pairwise Constraints and Monotonicity Constraints
Feb 25, 2023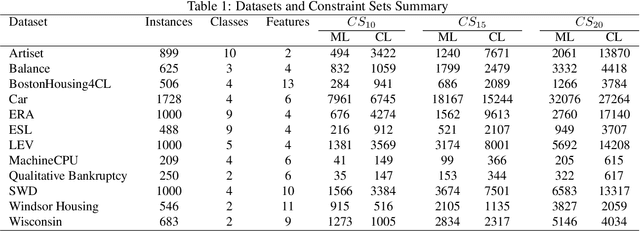
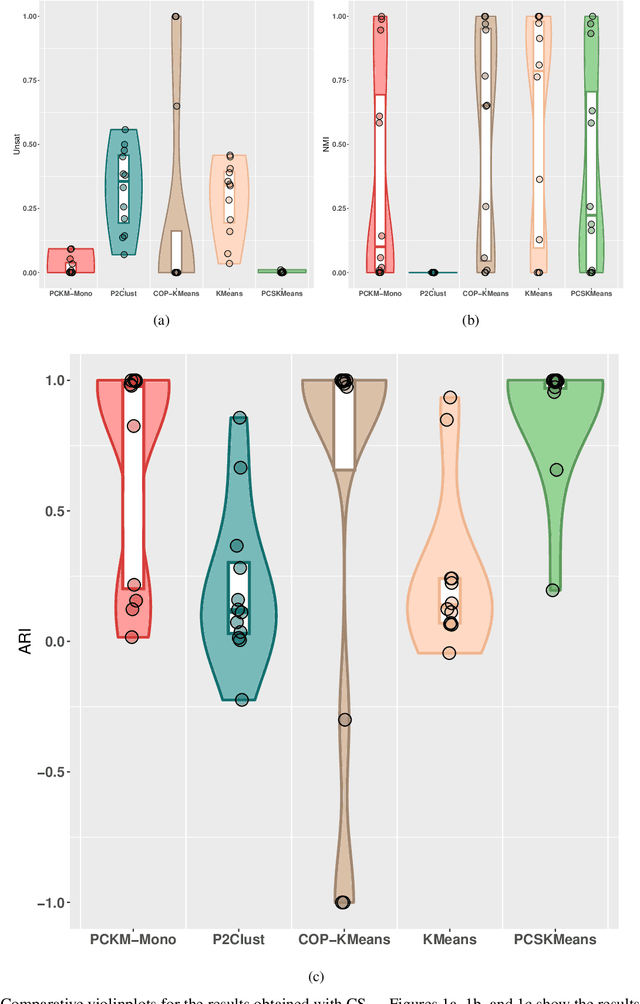
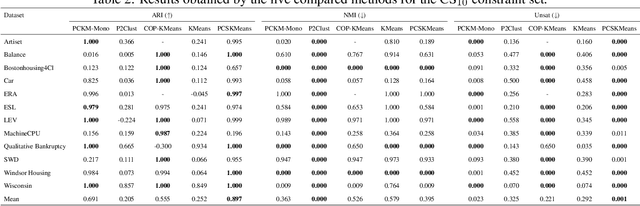
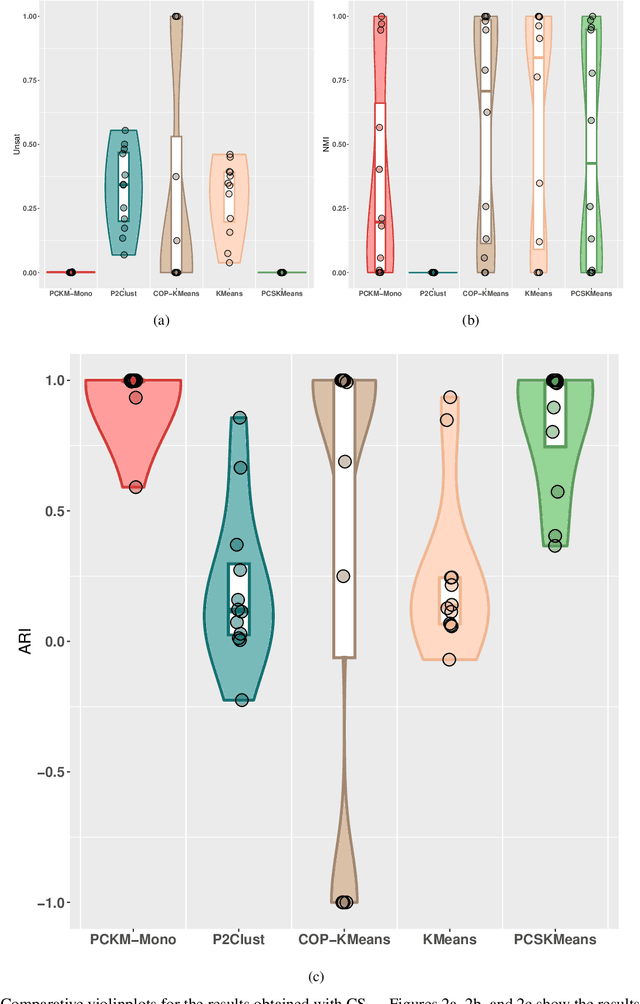
This study addresses the problem of performing clustering in the presence of two types of background knowledge: pairwise constraints and monotonicity constraints. To achieve this, the formal framework to perform clustering under monotonicity constraints is, firstly, defined, resulting in a specific distance measure. Pairwise constraints are integrated afterwards by designing an objective function which combines the proposed distance measure and a pairwise constraint-based penalty term, in order to fuse both types of information. This objective function can be optimized with an EM optimization scheme. The proposed method serves as the first approach to the problem it addresses, as it is the first method designed to work with the two types of background knowledge mentioned above. Our proposal is tested in a variety of benchmark datasets and in a real-world case of study.
AidUI: Toward Automated Recognition of Dark Patterns in User Interfaces
Mar 12, 2023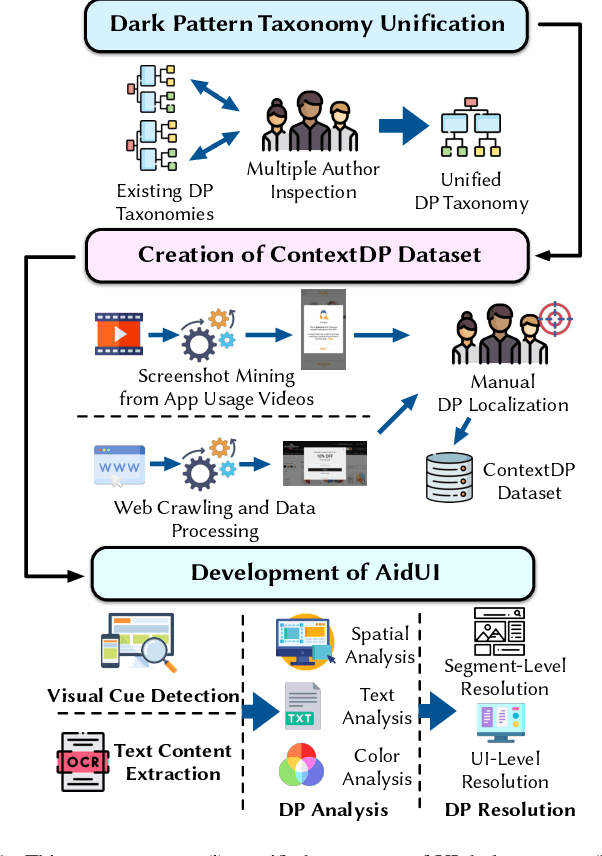
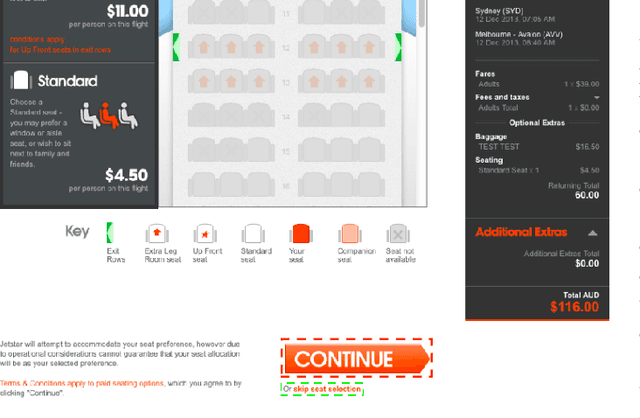
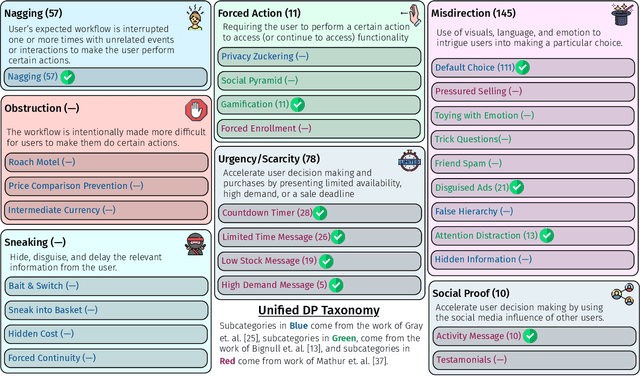
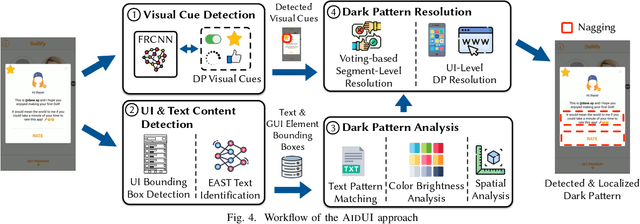
Past studies have illustrated the prevalence of UI dark patterns, or user interfaces that can lead end-users toward (unknowingly) taking actions that they may not have intended. Such deceptive UI designs can result in adverse effects on end users, such as oversharing personal information or financial loss. While significant research progress has been made toward the development of dark pattern taxonomies, developers and users currently lack guidance to help recognize, avoid, and navigate these often subtle design motifs. However, automated recognition of dark patterns is a challenging task, as the instantiation of a single type of pattern can take many forms, leading to significant variability. In this paper, we take the first step toward understanding the extent to which common UI dark patterns can be automatically recognized in modern software applications. To do this, we introduce AidUI, a novel automated approach that uses computer vision and natural language processing techniques to recognize a set of visual and textual cues in application screenshots that signify the presence of ten unique UI dark patterns, allowing for their detection, classification, and localization. To evaluate our approach, we have constructed ContextDP, the current largest dataset of fully-localized UI dark patterns that spans 175 mobile and 83 web UI screenshots containing 301 dark pattern instances. The results of our evaluation illustrate that \AidUI achieves an overall precision of 0.66, recall of 0.67, F1-score of 0.65 in detecting dark pattern instances, reports few false positives, and is able to localize detected patterns with an IoU score of ~0.84. Furthermore, a significant subset of our studied dark patterns can be detected quite reliably (F1 score of over 0.82), and future research directions may allow for improved detection of additional patterns.
How deep convolutional neural networks lose spatial information with training
Oct 04, 2022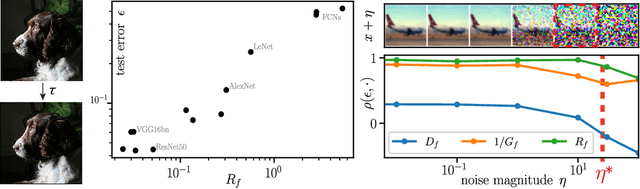
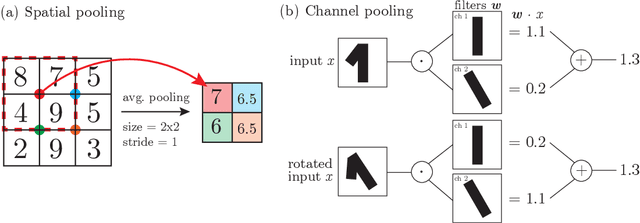
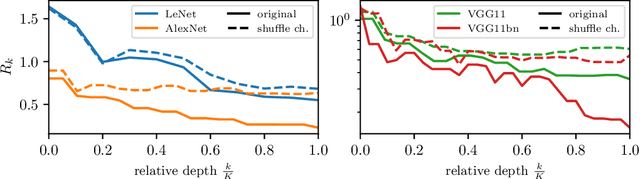
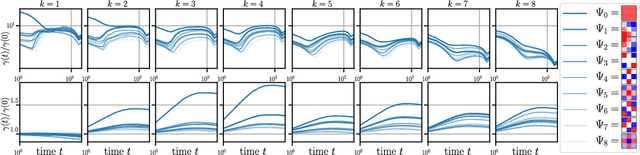
A central question of machine learning is how deep nets manage to learn tasks in high dimensions. An appealing hypothesis is that they achieve this feat by building a representation of the data where information irrelevant to the task is lost. For image datasets, this view is supported by the observation that after (and not before) training, the neural representation becomes less and less sensitive to diffeomorphisms acting on images as the signal propagates through the net. This loss of sensitivity correlates with performance, and surprisingly correlates with a gain of sensitivity to white noise acquired during training. These facts are unexplained, and as we demonstrate still hold when white noise is added to the images of the training set. Here, we (i) show empirically for various architectures that stability to image diffeomorphisms is achieved by spatial pooling in the first half of the net, and by channel pooling in the second half, (ii) introduce a scale-detection task for a simple model of data where pooling is learned during training, which captures all empirical observations above and (iii) compute in this model how stability to diffeomorphisms and noise scale with depth. The scalings are found to depend on the presence of strides in the net architecture. We find that the increased sensitivity to noise is due to the perturbing noise piling up during pooling, after being rectified by ReLU units.
Learning Enabled Fast Planning and Control in Dynamic Environments with Intermittent Information
Sep 09, 2022
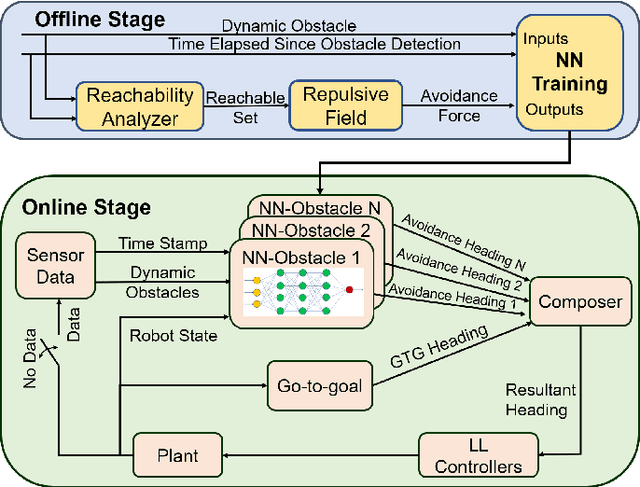
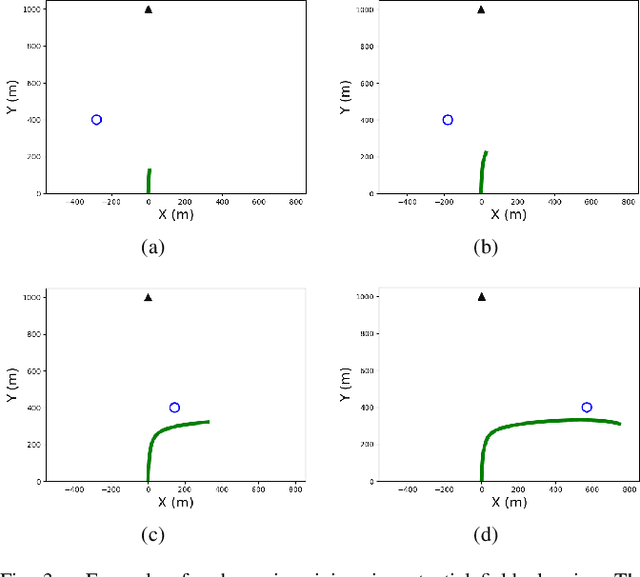
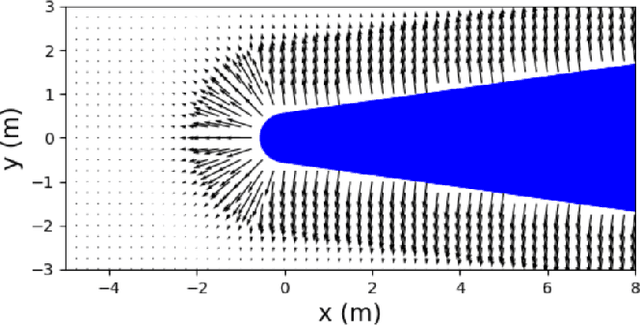
This paper addresses a safe planning and control problem for mobile robots operating in communication- and sensor-limited dynamic environments. In this case the robots cannot sense the objects around them and must instead rely on intermittent, external information about the environment, as e.g., in underwater applications. The challenge in this case is that the robots must plan using only this stale data, while accounting for any noise in the data or uncertainty in the environment. To address this challenge we propose a compositional technique which leverages neural networks to quickly plan and control a robot through crowded and dynamic environments using only intermittent information. Specifically, our tool uses reachability analysis and potential fields to train a neural network that is capable of generating safe control actions. We demonstrate our technique both in simulation with an underwater vehicle crossing a crowded shipping channel and with real experiments with ground vehicles in communication- and sensor-limited environments.
Visible and Near Infrared Image Fusion Based on Texture Information
Jul 22, 2022



Multi-sensor fusion is widely used in the environment perception system of the autonomous vehicle. It solves the interference caused by environmental changes and makes the whole driving system safer and more reliable. In this paper, a novel visible and near-infrared fusion method based on texture information is proposed to enhance unstructured environmental images. It aims at the problems of artifact, information loss and noise in traditional visible and near infrared image fusion methods. Firstly, the structure information of the visible image (RGB) and the near infrared image (NIR) after texture removal is obtained by relative total variation (RTV) calculation as the base layer of the fused image; secondly, a Bayesian classification model is established to calculate the noise weight and the noise information and the noise information in the visible image is adaptively filtered by joint bilateral filter; finally, the fused image is acquired by color space conversion. The experimental results demonstrate that the proposed algorithm can preserve the spectral characteristics and the unique information of visible and near-infrared images without artifacts and color distortion, and has good robustness as well as preserving the unique texture.
Like a Good Nearest Neighbor: Practical Content Moderation with Sentence Transformers
Mar 02, 2023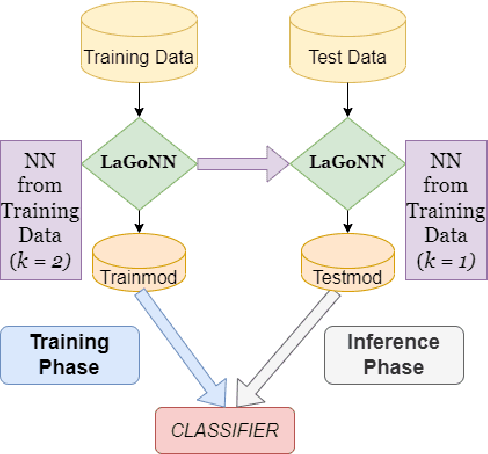
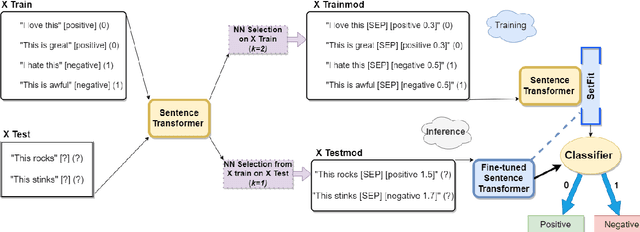
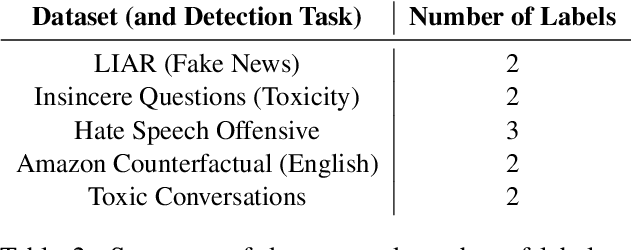
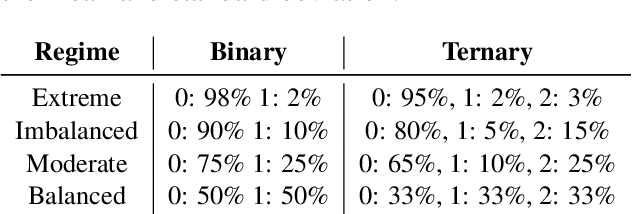
Modern text classification systems have impressive capabilities but are infeasible to deploy and use reliably due to their dependence on prompting and billion-parameter language models. SetFit (Tunstall et al., 2022) is a recent, practical approach that fine-tunes a Sentence Transformer under a contrastive learning paradigm and achieves similar results to more unwieldy systems. Text classification is important for addressing the problem of domain drift in detecting harmful content, which plagues all social media platforms. Here, we propose Like a Good Nearest Neighbor (LaGoNN), an inexpensive modification to SetFit that requires no additional parameters or hyperparameters but modifies input with information about its nearest neighbor, for example, the label and text, in the training data, making novel data appear similar to an instance on which the model was optimized. LaGoNN is effective at the task of detecting harmful content and generally improves performance compared to SetFit. To demonstrate the value of our system, we conduct a thorough study of text classification systems in the context of content moderation under four label distributions.
Learning to Detect Slip through Tactile Measures of the Contact Force Field and its Entropy
Mar 02, 2023



Detection of slip during object grasping and manipulation plays a vital role in object handling. Existing solutions largely depend on visual information to devise a strategy for grasping. Nonetheless, in order to achieve proficiency akin to humans and achieve consistent grasping and manipulation of unfamiliar objects, the incorporation of artificial tactile sensing has become a necessity in robotic systems. In this work, we propose a novel physics-informed, data-driven method to detect slip continuously in real time. The GelSight Mini, an optical tactile sensor, is mounted on custom grippers to acquire tactile readings. Our work leverages the inhomogeneity of tactile sensor readings during slip events to develop distinctive features and formulates slip detection as a classification problem. To evaluate our approach, we test multiple data-driven models on 10 common objects under different loading conditions, textures, and materials. Our results show that the best classification algorithm achieves an average accuracy of 99\%. We demonstrate the application of this work in a dynamic robotic manipulation task in which real-time slip detection and prevention algorithm is implemented.
GHQ: Grouped Hybrid Q Learning for Heterogeneous Cooperative Multi-agent Reinforcement Learning
Mar 02, 2023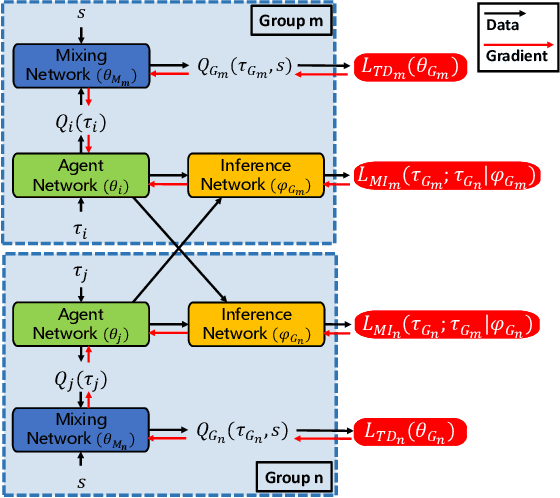
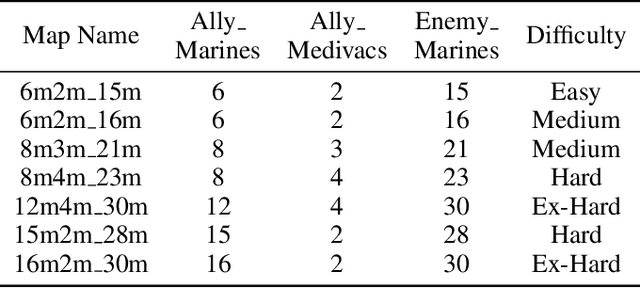

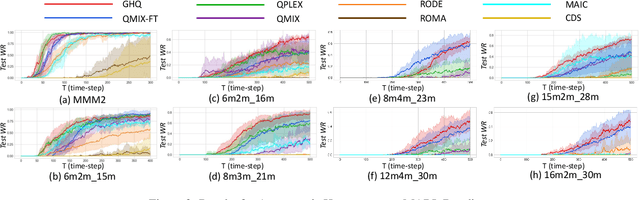
Previous deep multi-agent reinforcement learning (MARL) algorithms have achieved impressive results, typically in homogeneous scenarios. However, heterogeneous scenarios are also very common and usually harder to solve. In this paper, we mainly discuss cooperative heterogeneous MARL problems in Starcraft Multi-Agent Challenges (SMAC) environment. We firstly define and describe the heterogeneous problems in SMAC. In order to comprehensively reveal and study the problem, we make new maps added to the original SMAC maps. We find that baseline algorithms fail to perform well in those heterogeneous maps. To address this issue, we propose the Grouped Individual-Global-Max Consistency (GIGM) and a novel MARL algorithm, Grouped Hybrid Q Learning (GHQ). GHQ separates agents into several groups and keeps individual parameters for each group, along with a novel hybrid structure for factorization. To enhance coordination between groups, we maximize the Inter-group Mutual Information (IGMI) between groups' trajectories. Experiments on original and new heterogeneous maps show the fabulous performance of GHQ compared to other state-of-the-art algorithms.
Distributed Consistent Multi-robot Cooperative Localization: A Coordinate Transformation Approach
Mar 02, 2023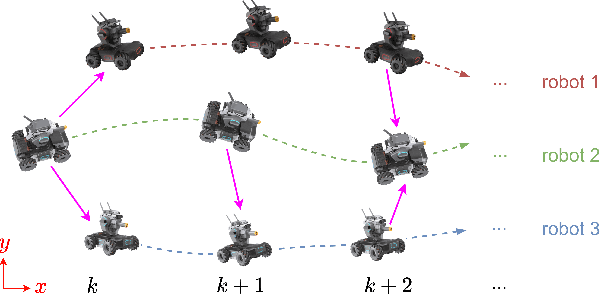
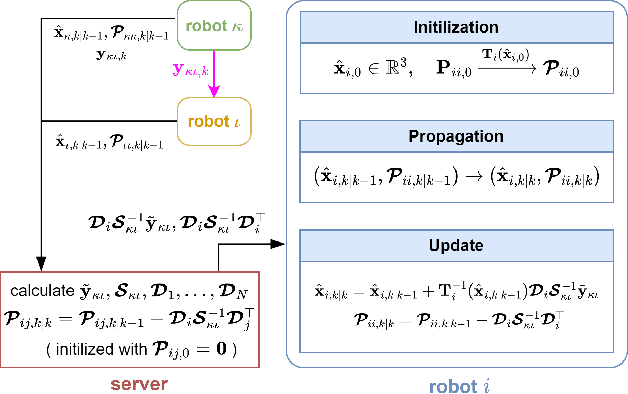
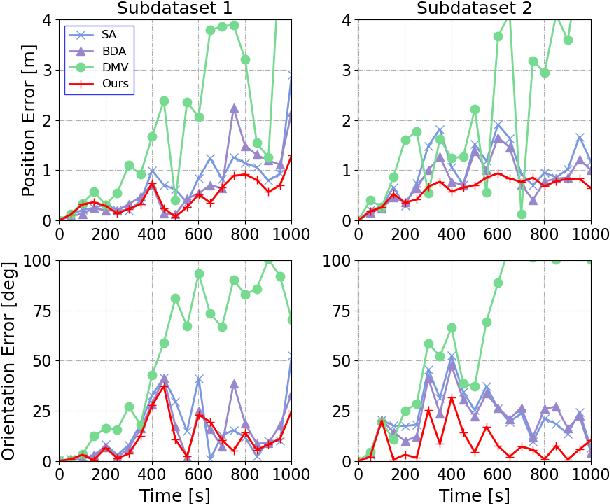

This paper considers the problem of distributed cooperative localization (CL) via robot-to-robot measurements for a multi-robot system. We propose a distributed consistent CL algorithm. The key idea is to perform the EKF-based state estimation in a transformed coordinate system. Specifically, a coordinate transformation is constructed by decomposing the state-propagation Jacobian by which the correct observability properties are guaranteed. Moreover, the transformed state-propagation Jacobian becomes an identity matrix which is more suitable for distribution. In the proposed algorithm, a server-based framework is adopted to distributely estimate the robot pose in which each robot propagates its pose estimations and the server maintains the correlations. To reduce communication costs, only when the multi-robot system takes a robot-to-robot relative measurement, the robots and the server exchange information to update the pose estimations and the correlations. In addition, no assumptions are made about the type of robots or relative measurements. The proposed algorithm has been validated by experiments and shown to outperform the state-of-art algorithms in terms of consistency and accuracy.