 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Personalized Graph Signal Processing for Collaborative Filtering
Feb 04, 2023


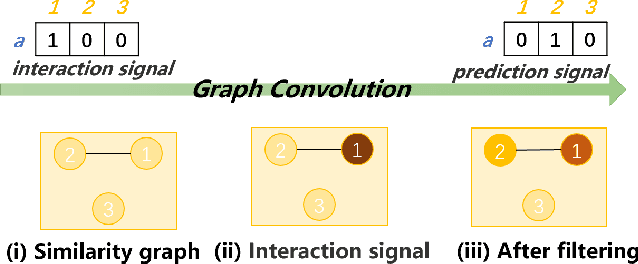
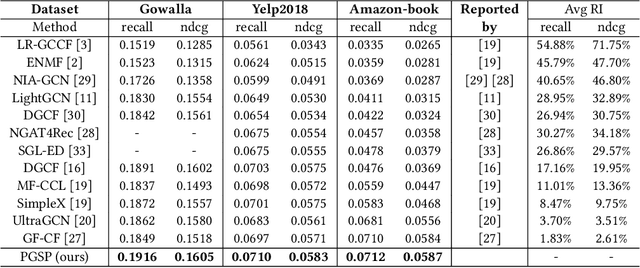
The collaborative filtering (CF) problem with only user-item interaction information can be solved by graph signal processing (GSP), which uses low-pass filters to smooth the observed interaction signals on the similarity graph to obtain the prediction signals. However, the interaction signal may not be sufficient to accurately characterize user interests and the low-pass filters may ignore the useful information contained in the high-frequency component of the observed signals, resulting in suboptimal accuracy. To this end, we propose a personalized graph signal processing (PGSP) method for collaborative filtering. Firstly, we design the personalized graph signal containing richer user information and construct an augmented similarity graph containing more graph topology information, to more effectively characterize user interests. Secondly, we devise a mixed-frequency graph filter to introduce useful information in the high-frequency components of the observed signals by combining an ideal low-pass filter that smooths signals globally and a linear low-pass filter that smooths signals locally. Finally, we combine the personalized graph signal, the augmented similarity graph and the mixed-frequency graph filter by proposing a pipeline consisting of three key steps: pre-processing, graph convolution and post-processing. Extensive experiments show that PGSP can achieve superior accuracy compared with state-of-the-art CF methods and, as a nonparametric method, PGSP has very high training efficiency.
Hatemongers ride on echo chambers to escalate hate speech diffusion
Feb 05, 2023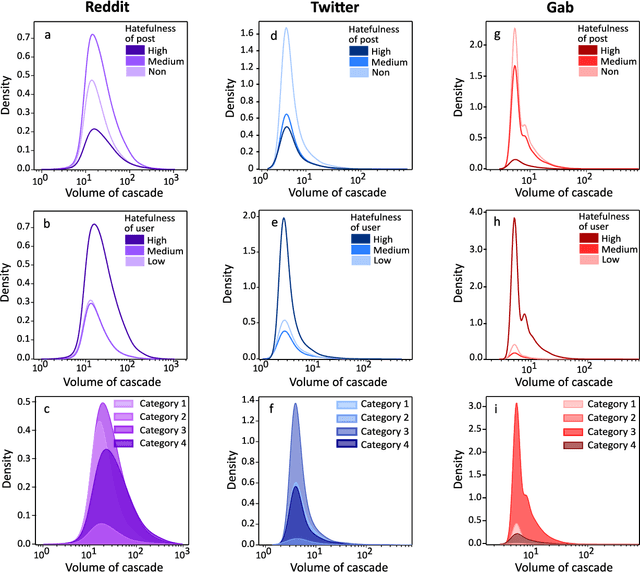

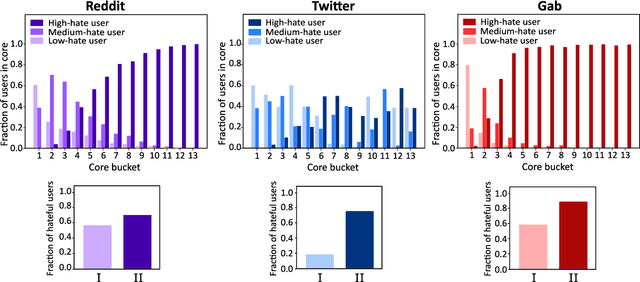
Recent years have witnessed a swelling rise of hateful and abusive content over online social networks. While detection and moderation of hate speech have been the early go-to countermeasures, the solution requires a deeper exploration of the dynamics of hate generation and propagation. We analyze more than 32 million posts from over 6.8 million users across three popular online social networks to investigate the interrelations between hateful behavior, information dissemination, and polarised organization mediated by echo chambers. We find that hatemongers play a more crucial role in governing the spread of information compared to singled-out hateful content. This observation holds for both the growth of information cascades as well as the conglomeration of hateful actors. Dissection of the core-wise distribution of these networks points towards the fact that hateful users acquire a more well-connected position in the social network and often flock together to build up information cascades. We observe that this cohesion is far from mere organized behavior; instead, in these networks, hatemongers dominate the echo chambers -- groups of users actively align themselves to specific ideological positions. The observed dominance of hateful users to inflate information cascades is primarily via user interactions amplified within these echo chambers. We conclude our study with a cautionary note that popularity-based recommendation of content is susceptible to be exploited by hatemongers given their potential to escalate content popularity via echo-chambered interactions.
Importance of Aligning Training Strategy with Evaluation for Diffusion Models in 3D Multiclass Segmentation
Mar 10, 2023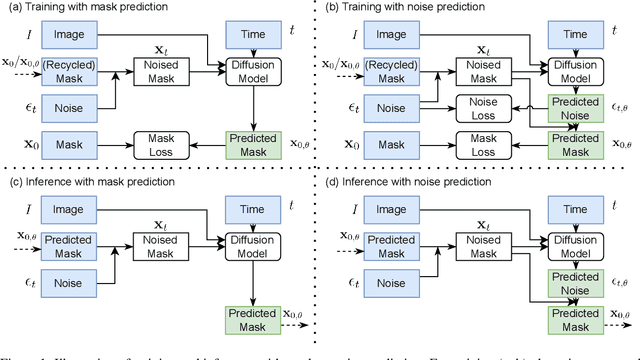
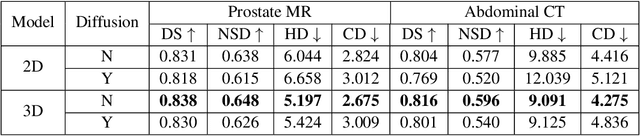
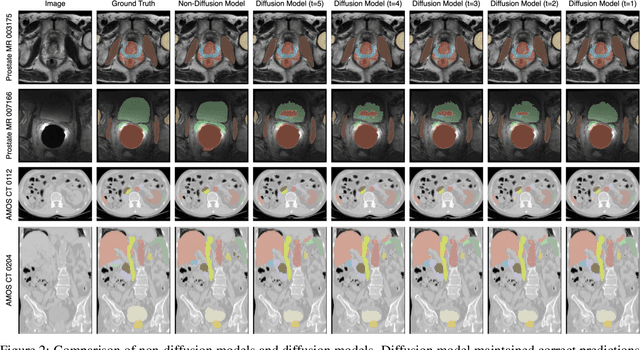
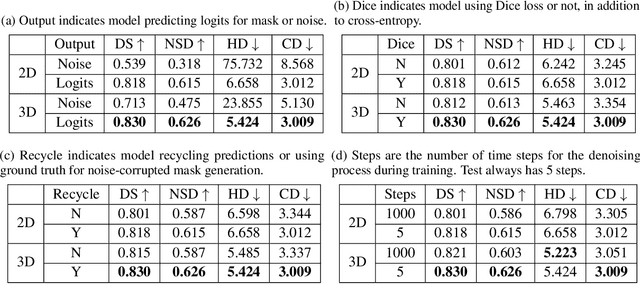
Recently, denoising diffusion probabilistic models (DDPM) have been applied to image segmentation by generating segmentation masks conditioned on images, while the applications were mainly limited to 2D networks without exploiting potential benefits from the 3D formulation. In this work, for the first time, DDPMs are used for 3D multiclass image segmentation. We make three key contributions that all focus on aligning the training strategy with the evaluation methodology, and improving efficiency. Firstly, the model predicts segmentation masks instead of sampled noise and is optimised directly via Dice loss. Secondly, the predicted mask in the previous time step is recycled to generate noise-corrupted masks to reduce information leakage. Finally, the diffusion process during training was reduced to five steps, the same as the evaluation. Through studies on two large multiclass data sets (prostate MR and abdominal CT), we demonstrated significantly improved performance compared to existing DDPMs, and reached competitive performance with non-diffusion segmentation models, based on U-net, within the same compute budget. The JAX-based diffusion framework has been released on https://github.com/mathpluscode/ImgX-DiffSeg.
CHGNN: A Semi-Supervised Contrastive Hypergraph Learning Network
Mar 10, 2023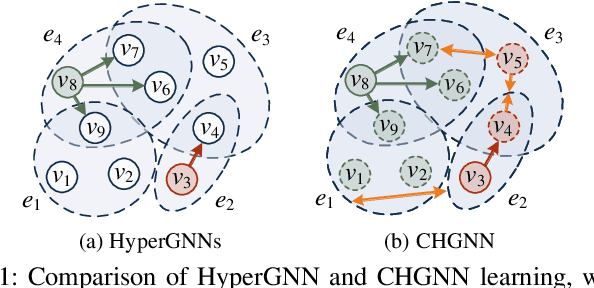
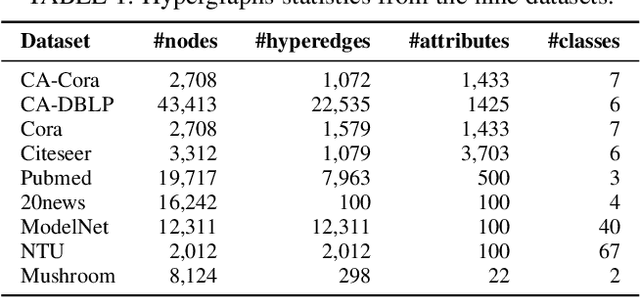
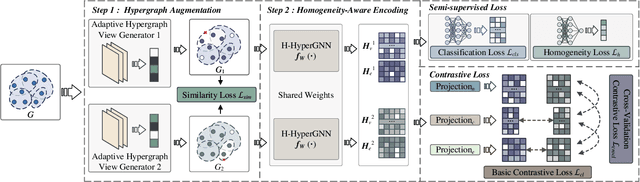
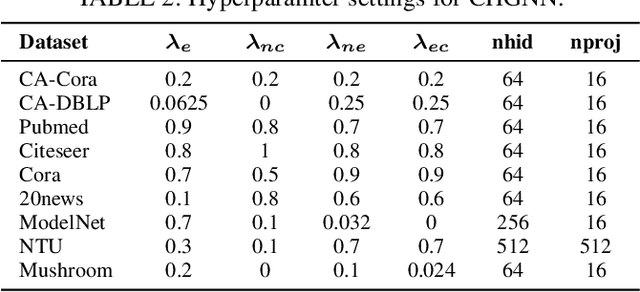
Hypergraphs can model higher-order relationships among data objects that are found in applications such as social networks and bioinformatics. However, recent studies on hypergraph learning that extend graph convolutional networks to hypergraphs cannot learn effectively from features of unlabeled data. To such learning, we propose a contrastive hypergraph neural network, CHGNN, that exploits self-supervised contrastive learning techniques to learn from labeled and unlabeled data. First, CHGNN includes an adaptive hypergraph view generator that adopts an auto-augmentation strategy and learns a perturbed probability distribution of minimal sufficient views. Second, CHGNN encompasses an improved hypergraph encoder that considers hyperedge homogeneity to fuse information effectively. Third, CHGNN is equipped with a joint loss function that combines a similarity loss for the view generator, a node classification loss, and a hyperedge homogeneity loss to inject supervision signals. It also includes basic and cross-validation contrastive losses, associated with an enhanced contrastive loss training process. Experimental results on nine real datasets offer insight into the effectiveness of CHGNN, showing that it outperforms 13 competitors in terms of classification accuracy consistently.
On Hybrid Radar Fusion for Integrated Sensing and Communication
Mar 10, 2023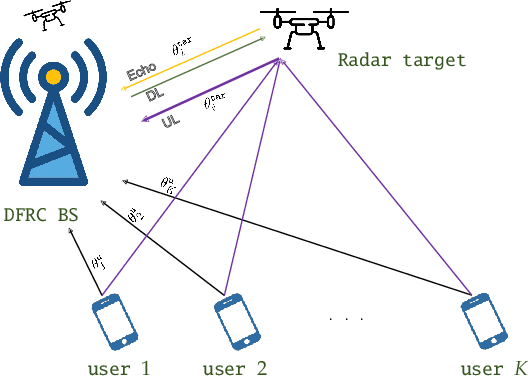
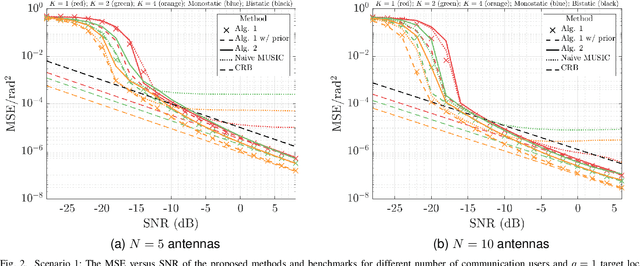
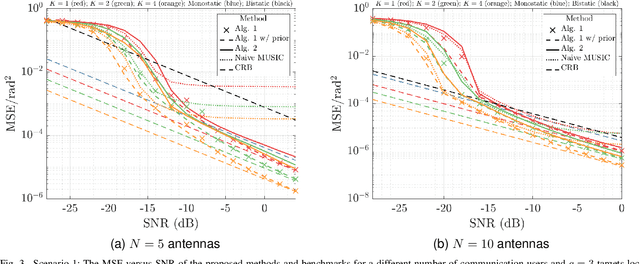
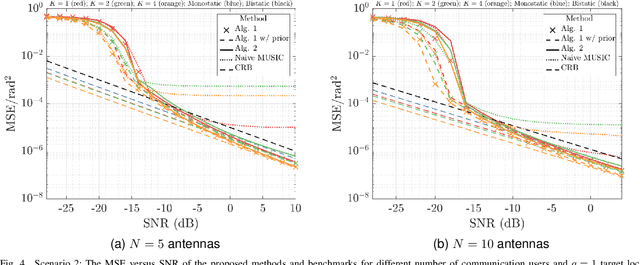
The following paper introduces a novel integrated sensing and communication (ISAC) scenario termed hybrid radar fusion. In this setting, the dual-functional radar and communications (DFRC) base station (BS) acts as a mono-static radar in the downlink (DL), for sensing purposes, while performing its DL communication tasks. Meanwhile, the communication users act as distributed bi-static radar nodes in the uplink (UL) following a frequency-division duplex protocol. The DFRC BS fuses the information available at different DL and UL resource bands to estimate the angles-of-arrival (AoAs) of the multiple targets existing in the scene. In this work, we derive the maximum likelihood (ML) criterion for the hybrid radar fusion problem at hand. Additionally, we design efficient estimators; the first algorithm is based on an alternating optimization approach to solve the ML criterion, while the second one designs an optimization framework that leads to an alternating subspace approach to estimate AoAs for both the target and users. Finally, we demonstrate the superior performance of both algorithms in different scenarios, and the gains offered by these proposed methods through numerical simulations.
Attention does not guarantee best performance in speech enhancement
Feb 11, 2023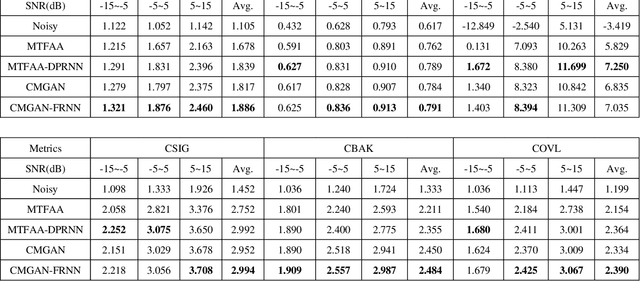
Attention mechanism has been widely utilized in speech enhancement (SE) because theoretically it can effectively model the long-term inherent connection of signal both in time domain and spectrum domain. However, the generally used global attention mechanism might not be the best choice since the adjacent information naturally imposes more influence than the far-apart information in speech enhancement. In this paper, we validate this conjecture by replacing attention with RNN in two typical state-of-the-art (SOTA) models, multi-scale temporal frequency convolutional network (MTFAA) with axial attention and conformer-based metric-GAN network (CMGAN).
Wind Turbine Gearbox Fault Detection Based on Sparse Filtering and Graph Neural Networks
Mar 06, 2023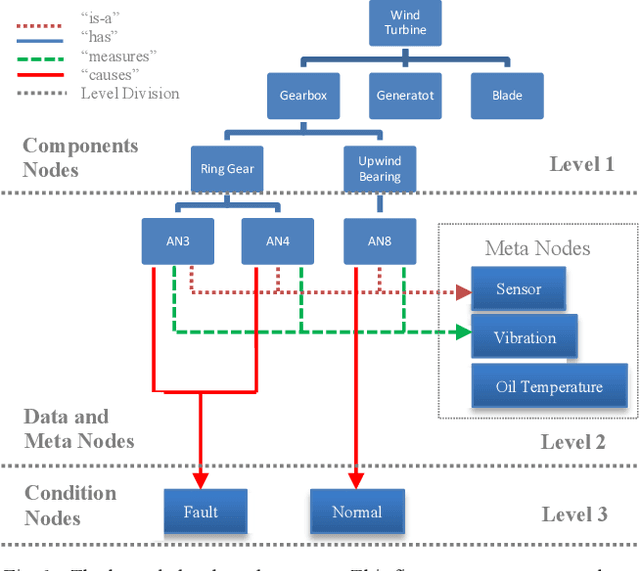
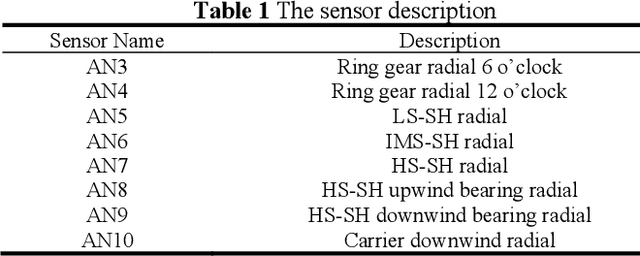
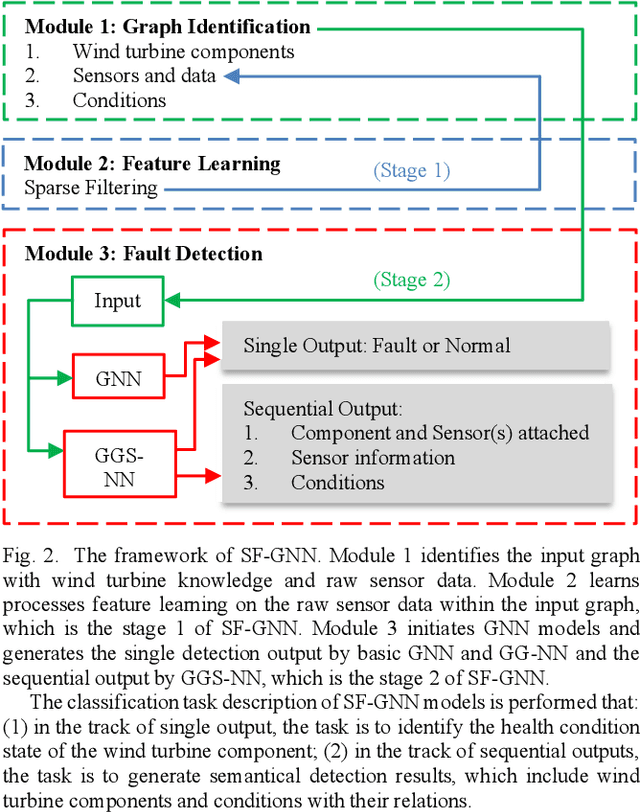
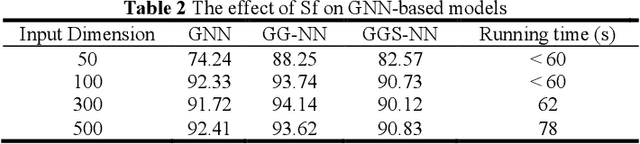
The wind energy industry has been experiencing tremendous growth and confronting the failures of wind turbine components. Wind turbine gearbox malfunctions are particularly prevalent and lead to the most prolonged downtime and highest cost. This paper presents a data-driven gearbox fault detection algorithm base on high frequency vibration data using graph neural network (GNN) models and sparse filtering (SF). The approach can take advantage of the comprehensive data sources and the complicated sensing networks. The GNN models, including basic graph neural networks, gated graph neural networks, and gated graph sequential neural networks, are used to detect gearbox condition from knowledge-based graphs formed using wind turbine information. Sparse filtering is used as an unsupervised feature learning method to accelerate the training of the GNN models. The effectiveness of the proposed method was verified on practical experimental data.
A Preliminary Study on Pattern Reconstruction for Optimal Storage of Wearable Sensor Data
Feb 25, 2023
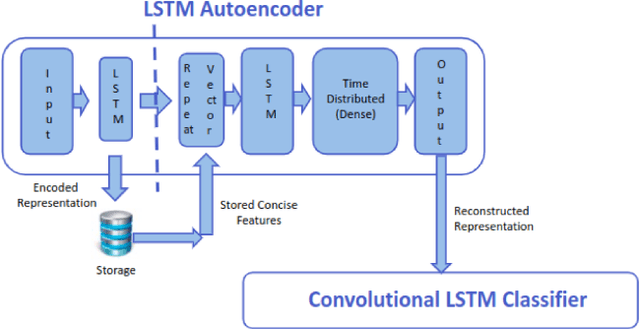
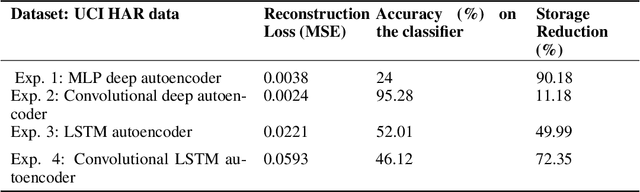
Efficient querying and retrieval of healthcare data is posing a critical challenge today with numerous connected devices continuously generating petabytes of images, text, and internet of things (IoT) sensor data. One approach to efficiently store the healthcare data is to extract the relevant and representative features and store only those features instead of the continuous streaming data. However, it raises a question as to the amount of information content we can retain from the data and if we can reconstruct the pseudo-original data when needed. By facilitating relevant and representative feature extraction, storage and reconstruction of near original pattern, we aim to address some of the challenges faced by the explosion of the streaming data. We present a preliminary study, where we explored multiple autoencoders for concise feature extraction and reconstruction for human activity recognition (HAR) sensor data. Our Multi-Layer Perceptron (MLP) deep autoencoder achieved a storage reduction of 90.18% compared to the three other implemented autoencoders namely convolutional autoencoder, Long-Short Term Memory (LSTM) autoencoder, and convolutional LSTM autoencoder which achieved storage reductions of 11.18%, 49.99%, and 72.35% respectively. Encoded features from the autoencoders have smaller size and dimensions which help to reduce the storage space. For higher dimensions of the representation, storage reduction was low. But retention of relevant information was high, which was validated by classification performed on the reconstructed data.
Information-Gathering in Latent Bandits
Jul 08, 2022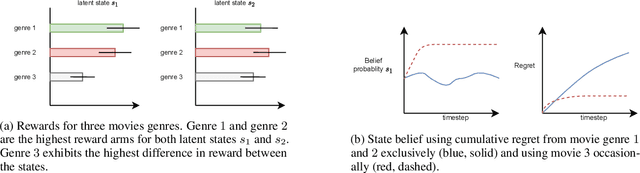
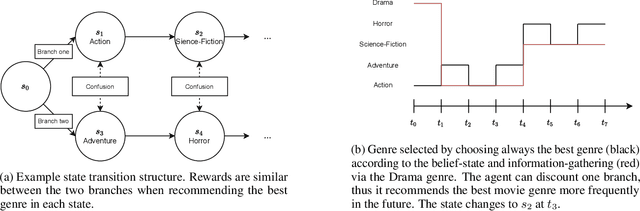
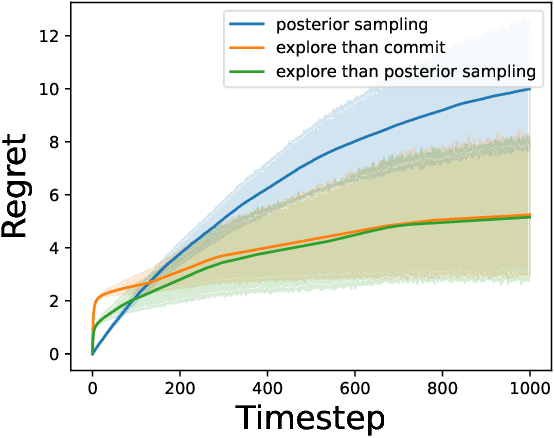
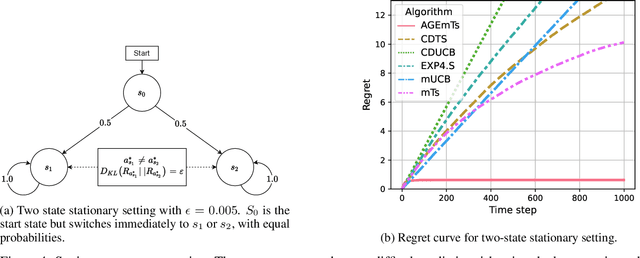
In the latent bandit problem, the learner has access to reward distributions and -- for the non-stationary variant -- transition models of the environment. The reward distributions are conditioned on the arm and unknown latent states. The goal is to use the reward history to identify the latent state, allowing for the optimal choice of arms in the future. The latent bandit setting lends itself to many practical applications, such as recommender and decision support systems, where rich data allows the offline estimation of environment models with online learning remaining a critical component. Previous solutions in this setting always choose the highest reward arm according to the agent's beliefs about the state, not explicitly considering the value of information-gathering arms. Such information-gathering arms do not necessarily provide the highest reward, thus may never be chosen by an agent that chooses the highest reward arms at all times. In this paper, we present a method for information-gathering in latent bandits. Given particular reward structures and transition matrices, we show that choosing the best arm given the agent's beliefs about the states incurs higher regret. Furthermore, we show that by choosing arms carefully, we obtain an improved estimation of the state distribution, and thus lower the cumulative regret through better arm choices in the future. We evaluate our method on both synthetic and real-world data sets, showing significant improvement in regret over state-of-the-art methods.
A Novel Filter Approach for Band Selection and Classification of Hyperspectral Remotely Sensed Images Using Normalized Mutual Information and Support Vector Machines
Oct 27, 2022Band selection is a great challenging task in the classification of hyperspectral remotely sensed images HSI. This is resulting from its high spectral resolution, the many class outputs and the limited number of training samples. For this purpose, this paper introduces a new filter approach for dimension reduction and classification of hyperspectral images using information theoretic (normalized mutual information) and support vector machines SVM. This method consists to select a minimal subset of the most informative and relevant bands from the input datasets for better classification efficiency. We applied our proposed algorithm on two well-known benchmark datasets gathered by the NASA's AVIRIS sensor over Indiana and Salinas valley in USA. The experimental results were assessed based on different evaluation metrics widely used in this area. The comparison with the state of the art methods proves that our method could produce good performance with reduced number of selected bands in a good timing. Keywords: Dimension reduction, Hyperspectral images, Band selection, Normalized mutual information, Classification, Support vector machines
* http://www.scopus.com/inward/record.url?eid=2-s2.0-85056469155&partnerID=MN8TOARS