 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Nonlinear ill-posed problem in low-dose dental cone-beam computed tomography
Mar 03, 2023
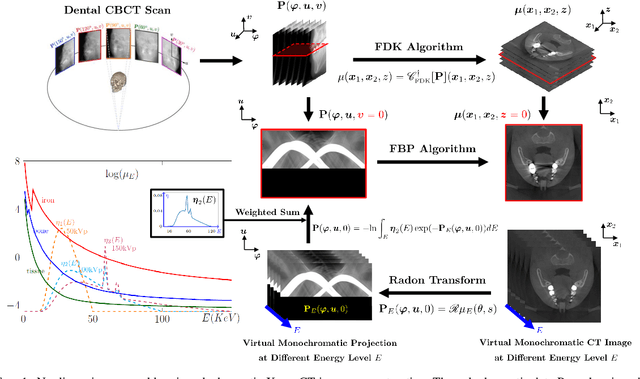
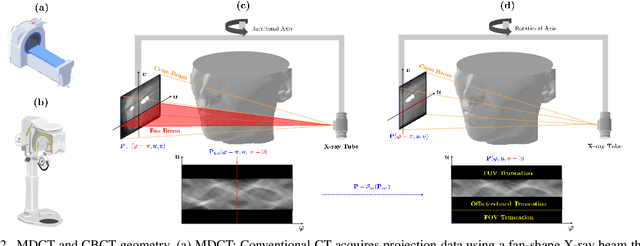
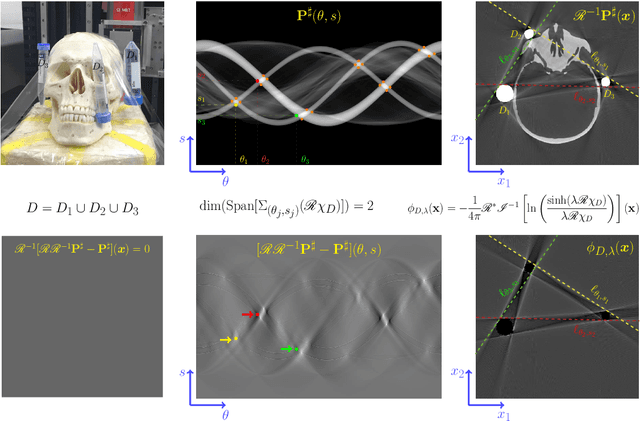
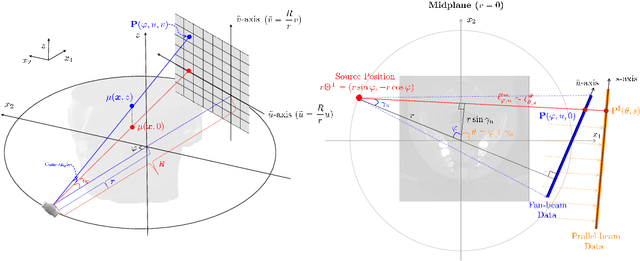
This paper describes the mathematical structure of the ill-posed nonlinear inverse problem of low-dose dental cone-beam computed tomography (CBCT) and explains the advantages of a deep learning-based approach to the reconstruction of computed tomography images over conventional regularization methods. This paper explains the underlying reasons why dental CBCT is more ill-posed than standard computed tomography. Despite this severe ill-posedness, the demand for dental CBCT systems is rapidly growing because of their cost competitiveness and low radiation dose. We then describe the limitations of existing methods in the accurate restoration of the morphological structures of teeth using dental CBCT data severely damaged by metal implants. We further discuss the usefulness of panoramic images generated from CBCT data for accurate tooth segmentation. We also discuss the possibility of utilizing radiation-free intra-oral scan data as prior information in CBCT image reconstruction to compensate for the damage to data caused by metal implants.
Fradulent User Detection Via Behavior Information Aggregation Network (BIAN) On Large-Scale Financial Social Network
Nov 04, 2022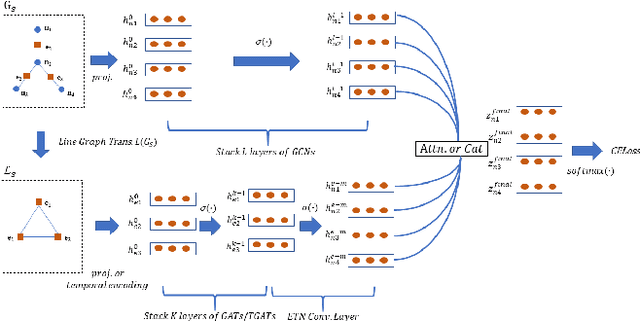
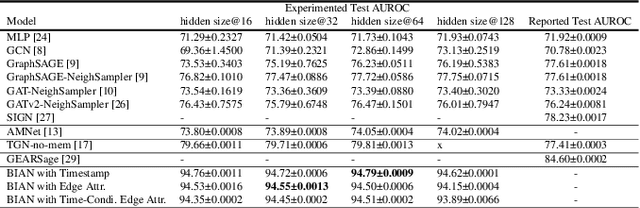
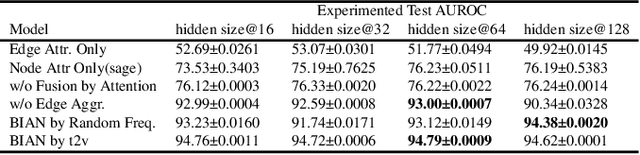
Financial frauds cause billions of losses annually and yet it lacks efficient approaches in detecting frauds considering user profile and their behaviors simultaneously in social network . A social network forms a graph structure whilst Graph neural networks (GNN), a promising research domain in Deep Learning, can seamlessly process non-Euclidean graph data . In financial fraud detection, the modus operandi of criminals can be identified by analyzing user profile and their behaviors such as transaction, loaning etc. as well as their social connectivity. Currently, most GNNs are incapable of selecting important neighbors since the neighbors' edge attributes (i.e., behaviors) are ignored. In this paper, we propose a novel behavior information aggregation network (BIAN) to combine the user behaviors with other user features. Different from its close "relatives" such as Graph Attention Networks (GAT) and Graph Transformer Networks (GTN), it aggregates neighbors based on neighboring edge attribute distribution, namely, user behaviors in financial social network. The experimental results on a real-world large-scale financial social network dataset, DGraph, show that BIAN obtains the 10.2% gain in AUROC comparing with the State-Of-The-Art models.
DECOMPL: Decompositional Learning with Attention Pooling for Group Activity Recognition from a Single Volleyball Image
Mar 11, 2023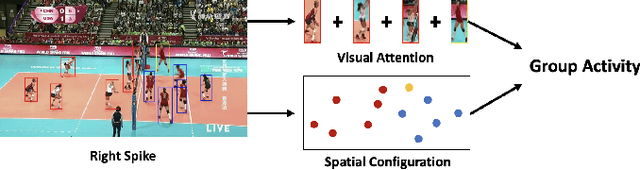
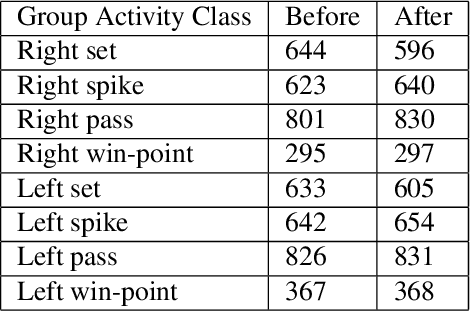
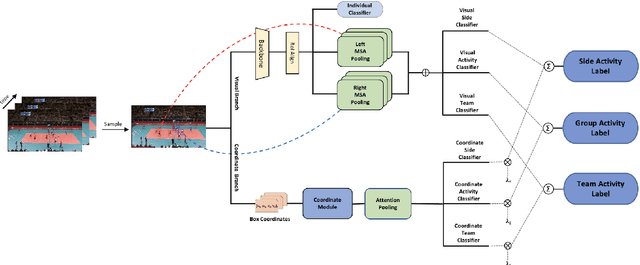
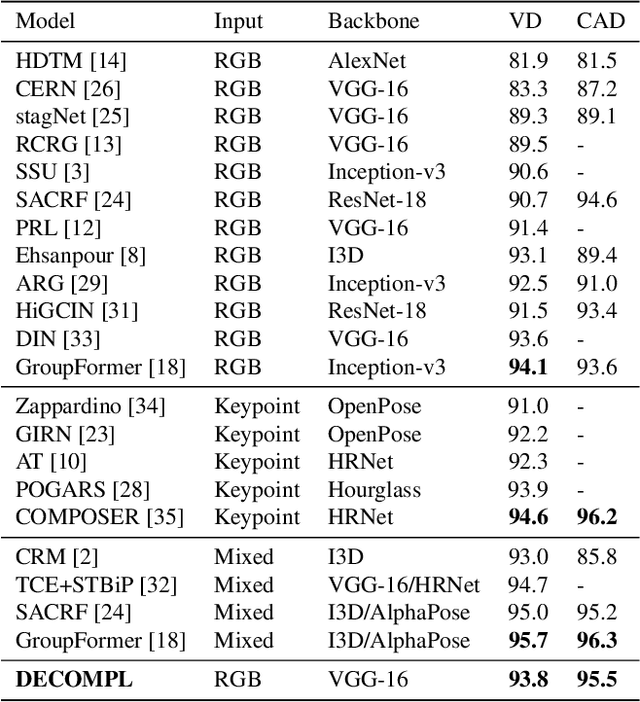
Group Activity Recognition (GAR) aims to detect the activity performed by multiple actors in a scene. Prior works model the spatio-temporal features based on the RGB, optical flow or keypoint data types. However, using both the temporality and these data types altogether increase the computational complexity significantly. Our hypothesis is that by only using the RGB data without temporality, the performance can be maintained with a negligible loss in accuracy. To that end, we propose a novel GAR technique for volleyball videos, DECOMPL, which consists of two complementary branches. In the visual branch, it extracts the features using attention pooling in a selective way. In the coordinate branch, it considers the current configuration of the actors and extracts the spatial information from the box coordinates. Moreover, we analyzed the Volleyball dataset that the recent literature is mostly based on, and realized that its labeling scheme degrades the group concept in the activities to the level of individual actors. We manually reannotated the dataset in a systematic manner for emphasizing the group concept. Experimental results on the Volleyball as well as Collective Activity (from another domain, i.e., not volleyball) datasets demonstrated the effectiveness of the proposed model DECOMPL, which delivered the best/second best GAR performance with the reannotations/original annotations among the comparable state-of-the-art techniques. Our code, results and new annotations will be made available through GitHub after the revision process.
Learning Grounded Vision-Language Representation for Versatile Understanding in Untrimmed Videos
Mar 11, 2023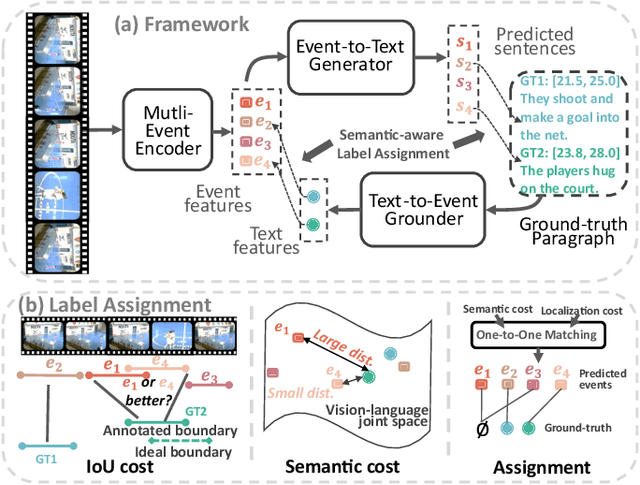
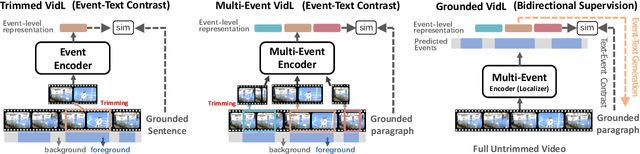
Joint video-language learning has received increasing attention in recent years. However, existing works mainly focus on single or multiple trimmed video clips (events), which makes human-annotated event boundaries necessary during inference. To break away from the ties, we propose a grounded vision-language learning framework for untrimmed videos, which automatically detects informative events and effectively excavates the alignments between multi-sentence descriptions and corresponding event segments. Instead of coarse-level video-language alignments, we present two dual pretext tasks to encourage fine-grained segment-level alignments, i.e., text-to-event grounding (TEG) and event-to-text generation (ETG). TEG learns to adaptively ground the possible event proposals given a set of sentences by estimating the cross-modal distance in a joint semantic space. Meanwhile, ETG aims to reconstruct (generate) the matched texts given event proposals, encouraging the event representation to retain meaningful semantic information. To encourage accurate label assignment between the event set and the text set, we propose a novel semantic-aware cost to mitigate the sub-optimal matching results caused by ambiguous boundary annotations. Our framework is easily extensible to tasks covering visually-grounded language understanding and generation. We achieve state-of-the-art dense video captioning performance on ActivityNet Captions, YouCook2 and YouMakeup, and competitive performance on several other language generation and understanding tasks. Our method also achieved 1st place in both the MTVG and MDVC tasks of the PIC 4th Challenge.
Deep Reinforcement Learning Based Power Allocation for Minimizing AoI and Energy Consumption in MIMO-NOMA IoT Systems
Mar 11, 2023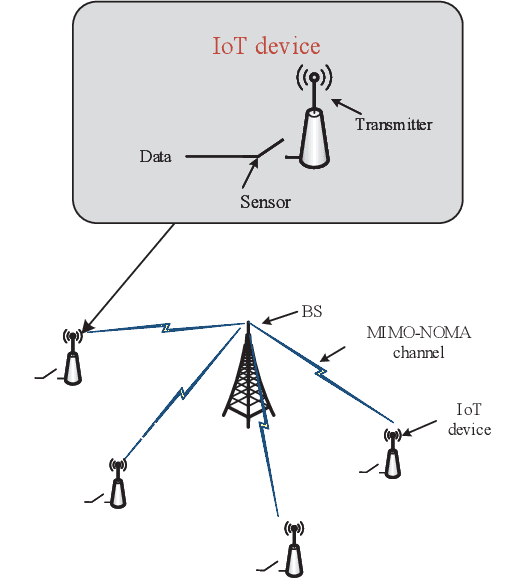
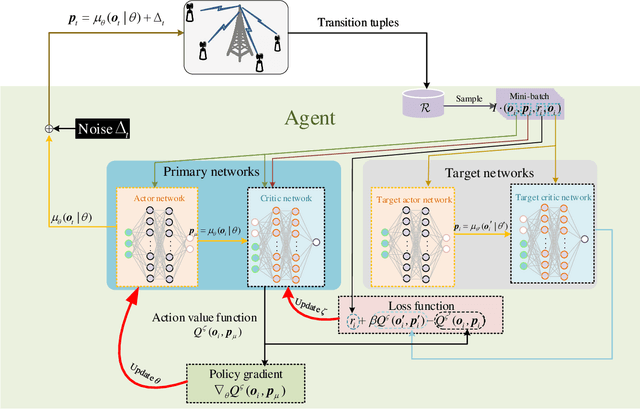
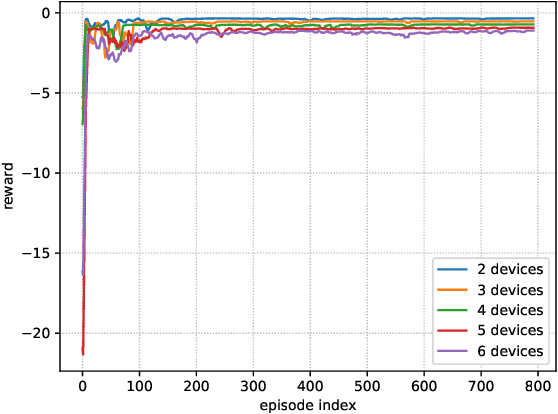
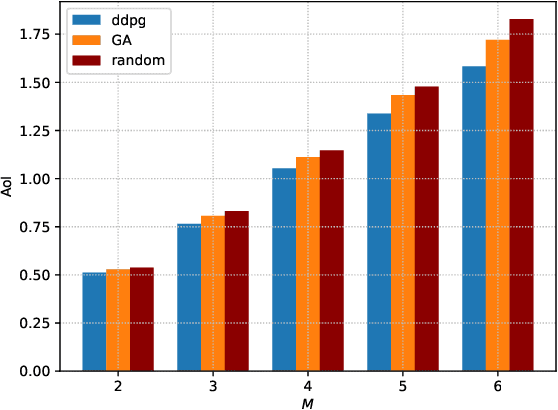
Multi-input multi-out and non-orthogonal multiple access (MIMO-NOMA) internet-of-things (IoT) systems can improve channel capacity and spectrum efficiency distinctly to support the real-time applications. Age of information (AoI) is an important metric for real-time application, but there is no literature have minimized AoI of the MIMO-NOMA IoT system, which motivates us to conduct this work. In MIMO-NOMA IoT system, the base station (BS) determines the sample collection requirements and allocates the transmission power for each IoT device. Each device determines whether to sample data according to the sample collection requirements and adopts the allocated power to transmit the sampled data to the BS over MIMO-NOMA channel. Afterwards, the BS employs successive interference cancelation (SIC) technique to decode the signal of the data transmitted by each device. The sample collection requirements and power allocation would affect AoI and energy consumption of the system. It is critical to determine the optimal policy including sample collection requirements and power allocation to minimize the AoI and energy consumption of MIMO-NOMA IoT system, where the transmission rate is not a constant in the SIC process and the noise is stochastic in the MIMO-NOMA channel. In this paper, we propose the optimal power allocation to minimize the AoI and energy consumption of MIMO- NOMA IoT system based on deep reinforcement learning (DRL). Extensive simulations are carried out to demonstrate the superiority of the optimal power allocation.
Skill Decision Transformer
Jan 31, 2023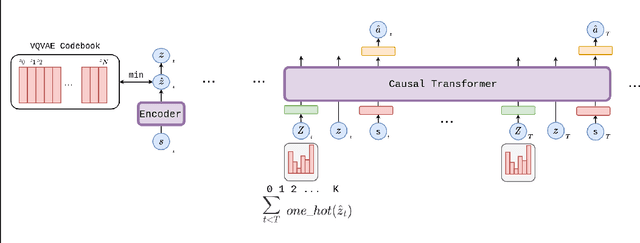
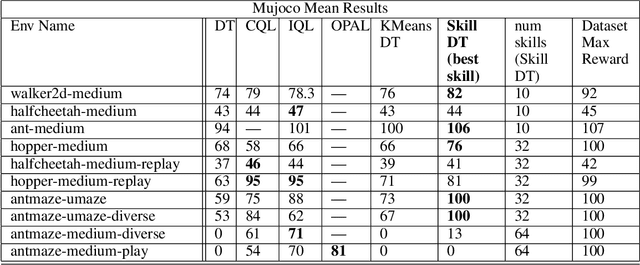
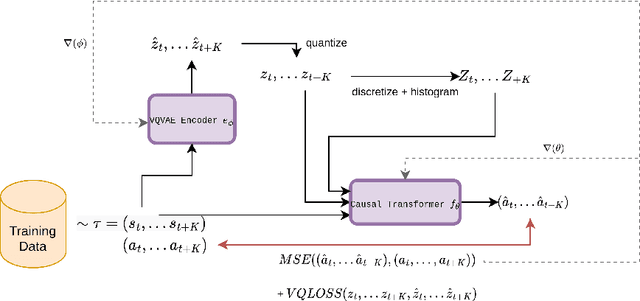
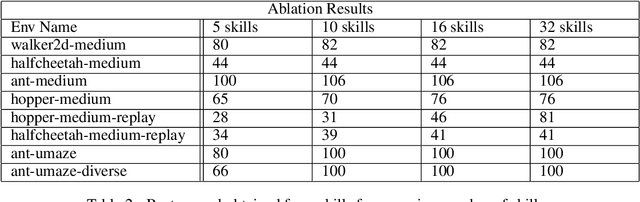
Recent work has shown that Large Language Models (LLMs) can be incredibly effective for offline reinforcement learning (RL) by representing the traditional RL problem as a sequence modelling problem (Chen et al., 2021; Janner et al., 2021). However many of these methods only optimize for high returns, and may not extract much information from a diverse dataset of trajectories. Generalized Decision Transformers (GDTs) (Furuta et al., 2021) have shown that utilizing future trajectory information, in the form of information statistics, can help extract more information from offline trajectory data. Building upon this, we propose Skill Decision Transformer (Skill DT). Skill DT draws inspiration from hindsight relabelling (Andrychowicz et al., 2017) and skill discovery methods to discover a diverse set of primitive behaviors, or skills. We show that Skill DT can not only perform offline state-marginal matching (SMM), but can discovery descriptive behaviors that can be easily sampled. Furthermore, we show that through purely reward-free optimization, Skill DT is still competitive with supervised offline RL approaches on the D4RL benchmark. The code and videos can be found on our project page: https://github.com/shyamsn97/skill-dt
M-SENSE: Modeling Narrative Structure in Short Personal Narratives Using Protagonist's Mental Representations
Feb 18, 2023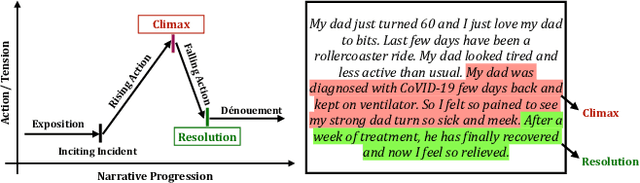
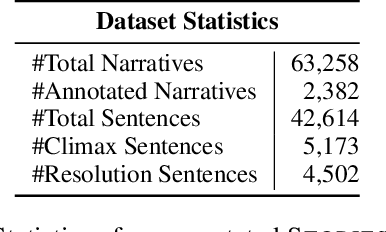

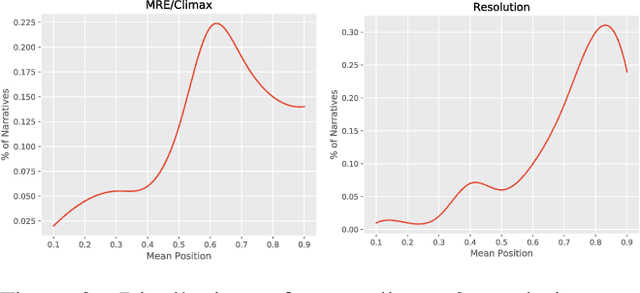
Narrative is a ubiquitous component of human communication. Understanding its structure plays a critical role in a wide variety of applications, ranging from simple comparative analyses to enhanced narrative retrieval, comprehension, or reasoning capabilities. Prior research in narratology has highlighted the importance of studying the links between cognitive and linguistic aspects of narratives for effective comprehension. This interdependence is related to the textual semantics and mental language in narratives, referring to characters' motivations, feelings or emotions, and beliefs. However, this interdependence is hardly explored for modeling narratives. In this work, we propose the task of automatically detecting prominent elements of the narrative structure by analyzing the role of characters' inferred mental state along with linguistic information at the syntactic and semantic levels. We introduce a STORIES dataset of short personal narratives containing manual annotations of key elements of narrative structure, specifically climax and resolution. To this end, we implement a computational model that leverages the protagonist's mental state information obtained from a pre-trained model trained on social commonsense knowledge and integrates their representations with contextual semantic embed-dings using a multi-feature fusion approach. Evaluating against prior zero-shot and supervised baselines, we find that our model is able to achieve significant improvements in the task of identifying climax and resolution.
Dimension-reduced KRnet maps for high-dimensional Bayesian inverse problems
Mar 08, 2023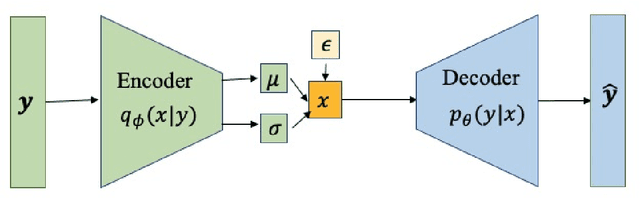
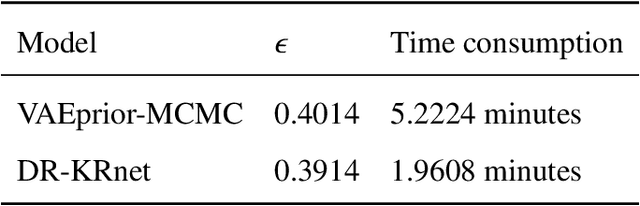
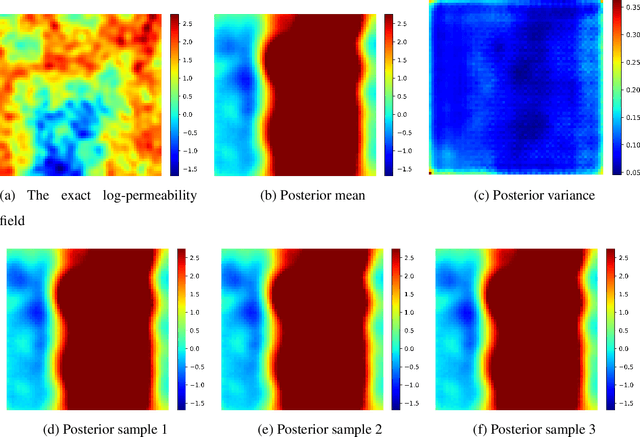
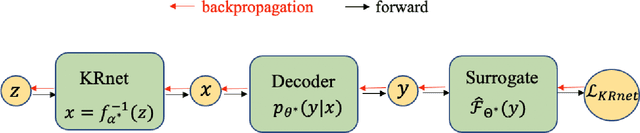
We present a dimension-reduced KRnet map approach (DR-KRnet) for high-dimensional Bayesian inverse problems, which is based on an explicit construction of a map that pushes forward the prior measure to the posterior measure in the latent space. Our approach consists of two main components: data-driven VAE prior and density approximation of the posterior of the latent variable. In reality, it may not be trivial to initialize a prior distribution that is consistent with available prior data; in other words, the complex prior information is often beyond simple hand-crafted priors. We employ variational autoencoder (VAE) to approximate the underlying distribution of the prior dataset, which is achieved through a latent variable and a decoder. Using the decoder provided by the VAE prior, we reformulate the problem in a low-dimensional latent space. In particular, we seek an invertible transport map given by KRnet to approximate the posterior distribution of the latent variable. Moreover, an efficient physics-constrained surrogate model without any labeled data is constructed to reduce the computational cost of solving both forward and adjoint problems involved in likelihood computation. With numerical experiments, we demonstrate the accuracy and efficiency of DR-KRnet for high-dimensional Bayesian inverse problems.
A Light Weight Model for Active Speaker Detection
Mar 08, 2023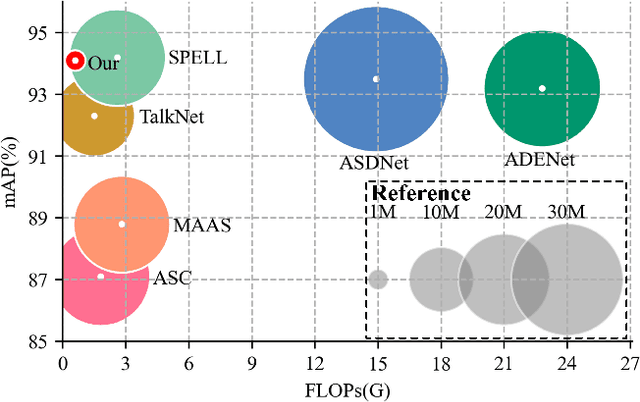
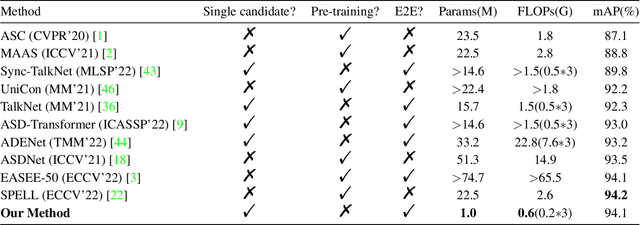
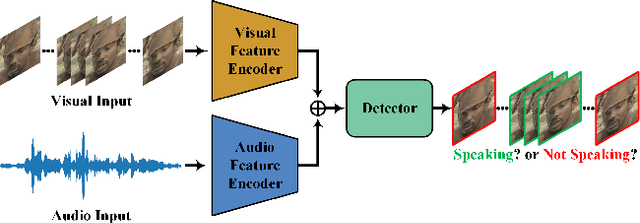
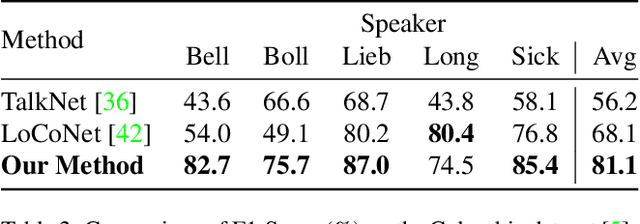
Active speaker detection is a challenging task in audio-visual scenario understanding, which aims to detect who is speaking in one or more speakers scenarios. This task has received extensive attention as it is crucial in applications such as speaker diarization, speaker tracking, and automatic video editing. The existing studies try to improve performance by inputting multiple candidate information and designing complex models. Although these methods achieved outstanding performance, their high consumption of memory and computational power make them difficult to be applied in resource-limited scenarios. Therefore, we construct a lightweight active speaker detection architecture by reducing input candidates, splitting 2D and 3D convolutions for audio-visual feature extraction, and applying gated recurrent unit (GRU) with low computational complexity for cross-modal modeling. Experimental results on the AVA-ActiveSpeaker dataset show that our framework achieves competitive mAP performance (94.1% vs. 94.2%), while the resource costs are significantly lower than the state-of-the-art method, especially in model parameters (1.0M vs. 22.5M, about 23x) and FLOPs (0.6G vs. 2.6G, about 4x). In addition, our framework also performs well on the Columbia dataset showing good robustness. The code and model weights are available at https://github.com/Junhua-Liao/Light-ASD.
A path in regression Random Forest looking for spatial dependence: a taxonomy and a systematic review
Mar 08, 2023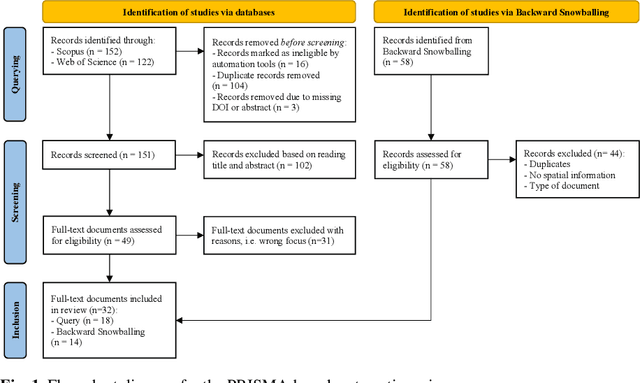
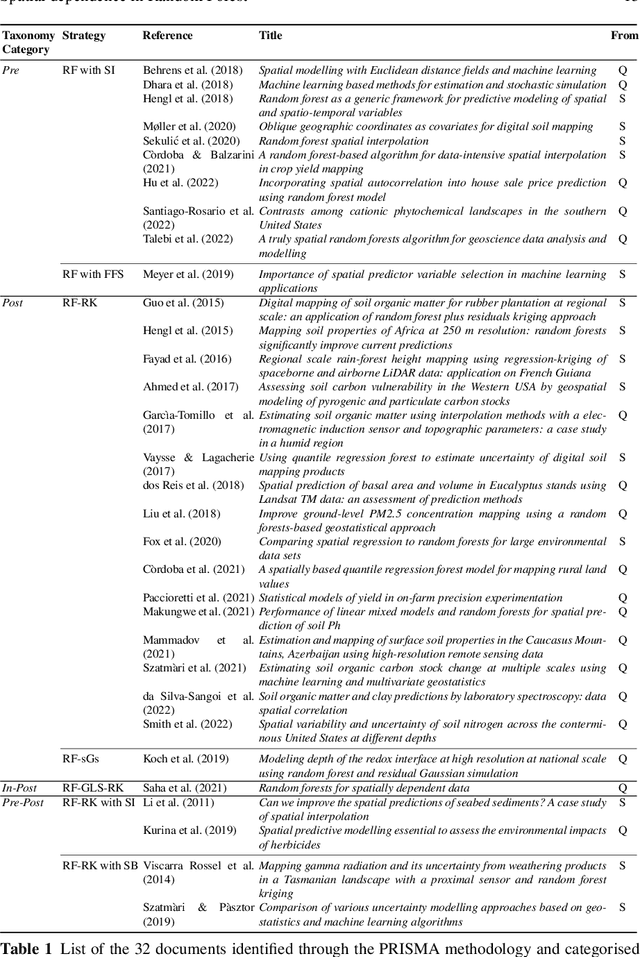
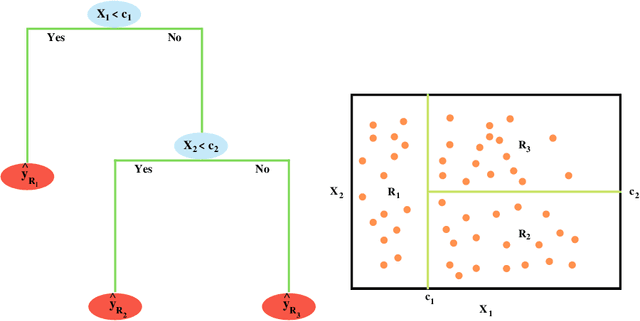
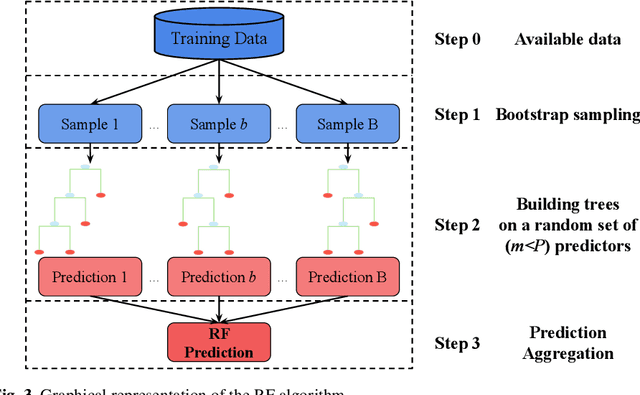
Random Forest (RF) is a well-known data-driven algorithm applied in several fields thanks to its flexibility in modeling the relationship between the response variable and the predictors, also in case of strong non-linearities. In environmental applications, it often occurs that the phenomenon of interest may present spatial and/or temporal dependence that is not taken explicitly into account by RF in its standard version. In this work, we propose a taxonomy to classify strategies according to when (Pre-, In- and/or Post-processing) they try to include the spatial information into regression RF. Moreover, we provide a systematic review and classify the most recent strategies adopted to "adjust" regression RF to spatially dependent data, based on the criteria provided by the Preferred Reporting Items for Systematic reviews and Meta-Analysis (PRISMA). The latter consists of a reproducible methodology for collecting and processing existing literature on a specified topic from different sources. PRISMA starts with a query and ends with a set of scientific documents to review: we performed an online query on the 25$^{th}$ October 2022 and, in the end, 32 documents were considered for review. The employed methodological strategies and the application fields considered in the 32 scientific documents are described and discussed.