 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Computational-Statistical Gaps in Gaussian Single-Index Models
Mar 12, 2024
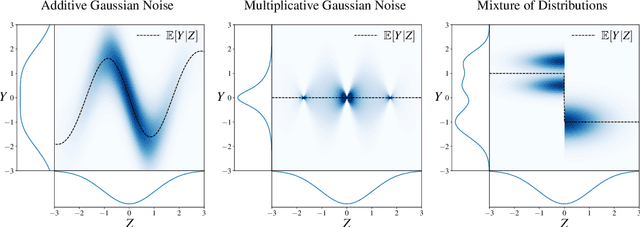
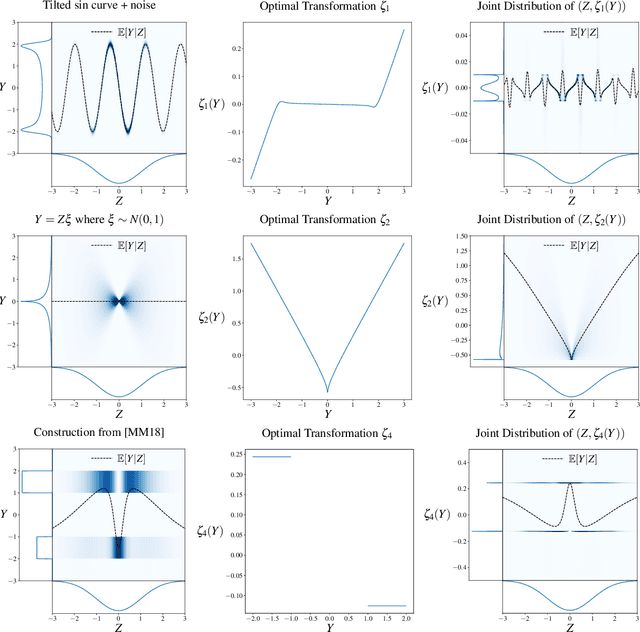
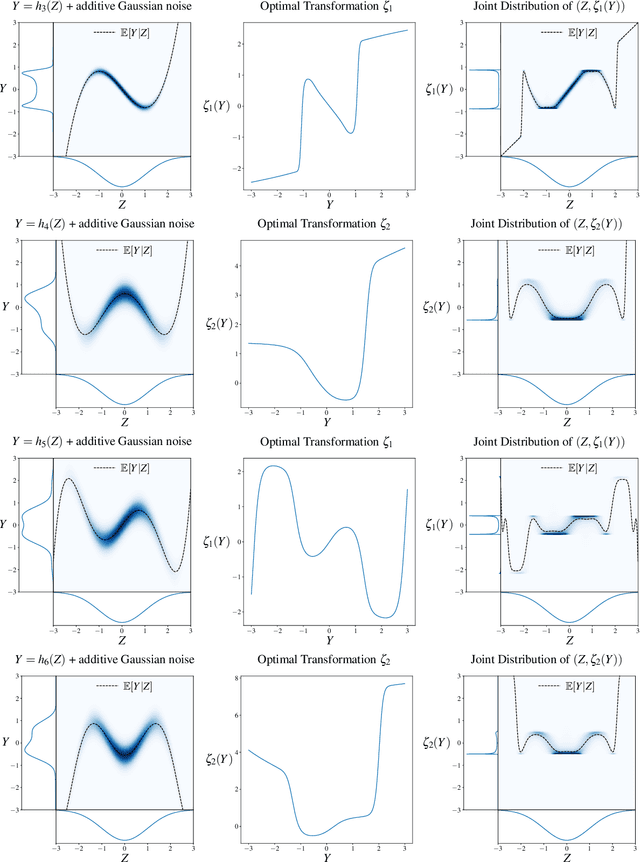
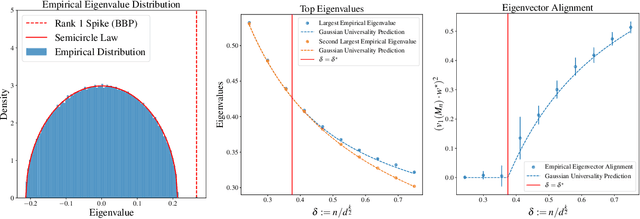
Single-Index Models are high-dimensional regression problems with planted structure, whereby labels depend on an unknown one-dimensional projection of the input via a generic, non-linear, and potentially non-deterministic transformation. As such, they encompass a broad class of statistical inference tasks, and provide a rich template to study statistical and computational trade-offs in the high-dimensional regime. While the information-theoretic sample complexity to recover the hidden direction is linear in the dimension $d$, we show that computationally efficient algorithms, both within the Statistical Query (SQ) and the Low-Degree Polynomial (LDP) framework, necessarily require $\Omega(d^{k^\star/2})$ samples, where $k^\star$ is a "generative" exponent associated with the model that we explicitly characterize. Moreover, we show that this sample complexity is also sufficient, by establishing matching upper bounds using a partial-trace algorithm. Therefore, our results provide evidence of a sharp computational-to-statistical gap (under both the SQ and LDP class) whenever $k^\star>2$. To complete the study, we provide examples of smooth and Lipschitz deterministic target functions with arbitrarily large generative exponents $k^\star$.
The 6th Affective Behavior Analysis in-the-wild (ABAW) Competition
Mar 12, 2024This paper describes the 6th Affective Behavior Analysis in-the-wild (ABAW) Competition, which is part of the respective Workshop held in conjunction with IEEE CVPR 2024. The 6th ABAW Competition addresses contemporary challenges in understanding human emotions and behaviors, crucial for the development of human-centered technologies. In more detail, the Competition focuses on affect related benchmarking tasks and comprises of five sub-challenges: i) Valence-Arousal Estimation (the target is to estimate two continuous affect dimensions, valence and arousal), ii) Expression Recognition (the target is to recognise between the mutually exclusive classes of the 7 basic expressions and 'other'), iii) Action Unit Detection (the target is to detect 12 action units), iv) Compound Expression Recognition (the target is to recognise between the 7 mutually exclusive compound expression classes), and v) Emotional Mimicry Intensity Estimation (the target is to estimate six continuous emotion dimensions). In the paper, we present these Challenges, describe their respective datasets and challenge protocols (we outline the evaluation metrics) and present the baseline systems as well as their obtained performance. More information for the Competition can be found in: https://affective-behavior-analysis-in-the-wild.github.io/6th.
Physics-Inspired Deep Learning Anti-Aliasing Framework in Efficient Channel State Feedback
Mar 12, 2024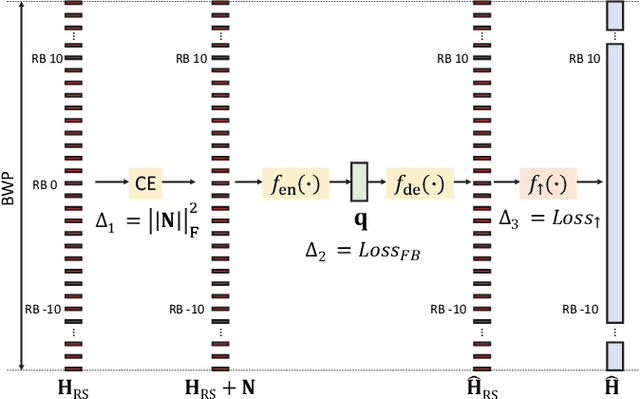
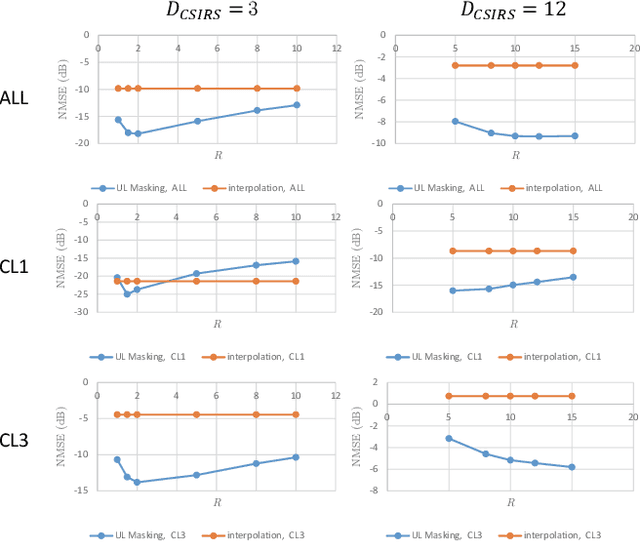
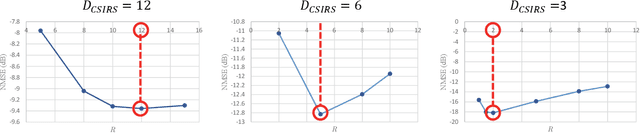
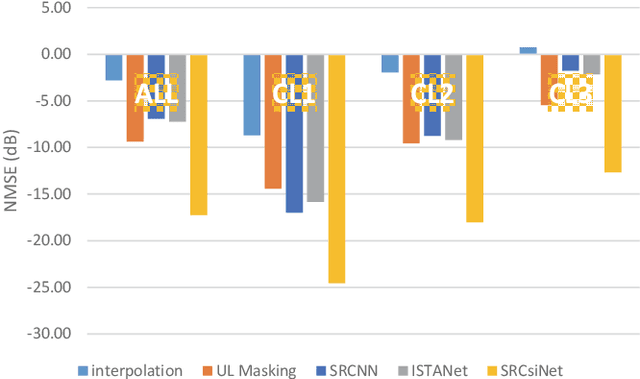
Acquiring downlink channel state information (CSI) at the base station is vital for optimizing performance in massive Multiple input multiple output (MIMO) Frequency-Division Duplexing (FDD) systems. While deep learning architectures have been successful in facilitating UE-side CSI feedback and gNB-side recovery, the undersampling issue prior to CSI feedback is often overlooked. This issue, which arises from low density pilot placement in current standards, results in significant aliasing effects in outdoor channels and consequently limits CSI recovery performance. To this end, this work introduces a new CSI upsampling framework at the gNB as a post-processing solution to address the gaps caused by undersampling. Leveraging the physical principles of discrete Fourier transform shifting theorem and multipath reciprocity, our framework effectively uses uplink CSI to mitigate aliasing effects. We further develop a learning-based method that integrates the proposed algorithm with the Iterative Shrinkage-Thresholding Algorithm Net (ISTA-Net) architecture, enhancing our approach for non-uniform sampling recovery. Our numerical results show that both our rule-based and deep learning methods significantly outperform traditional interpolation techniques and current state-of-the-art approaches in terms of performance.
Robust Synthetic-to-Real Transfer for Stereo Matching
Mar 12, 2024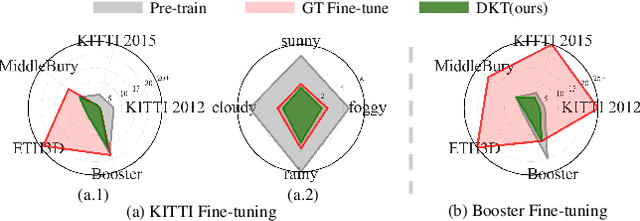
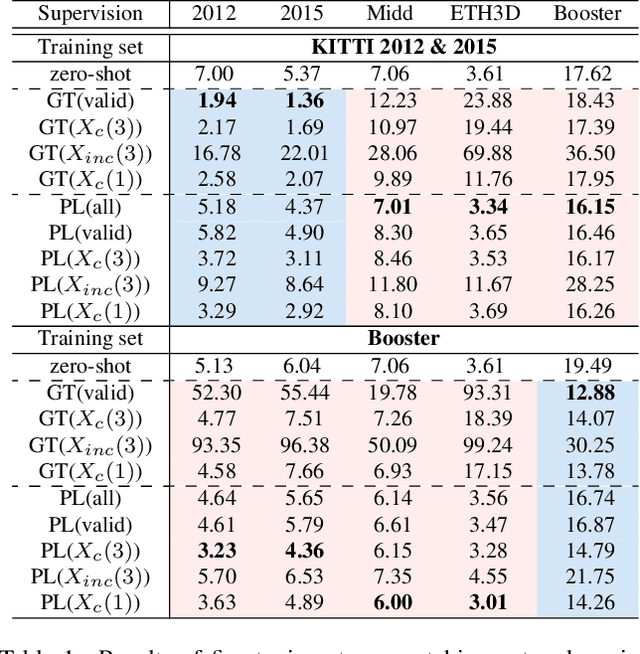
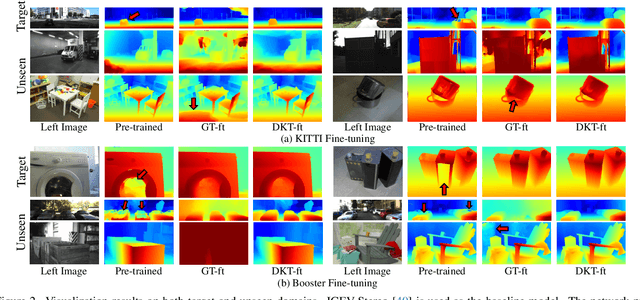
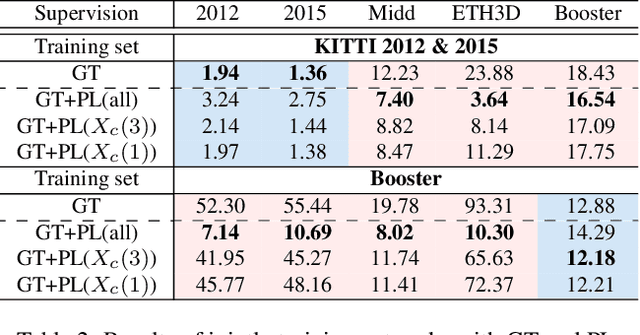
With advancements in domain generalized stereo matching networks, models pre-trained on synthetic data demonstrate strong robustness to unseen domains. However, few studies have investigated the robustness after fine-tuning them in real-world scenarios, during which the domain generalization ability can be seriously degraded. In this paper, we explore fine-tuning stereo matching networks without compromising their robustness to unseen domains. Our motivation stems from comparing Ground Truth (GT) versus Pseudo Label (PL) for fine-tuning: GT degrades, but PL preserves the domain generalization ability. Empirically, we find the difference between GT and PL implies valuable information that can regularize networks during fine-tuning. We also propose a framework to utilize this difference for fine-tuning, consisting of a frozen Teacher, an exponential moving average (EMA) Teacher, and a Student network. The core idea is to utilize the EMA Teacher to measure what the Student has learned and dynamically improve GT and PL for fine-tuning. We integrate our framework with state-of-the-art networks and evaluate its effectiveness on several real-world datasets. Extensive experiments show that our method effectively preserves the domain generalization ability during fine-tuning.
ClaimVer: Explainable Claim-Level Verification and Evidence Attribution of Text Through Knowledge Graphs
Mar 12, 2024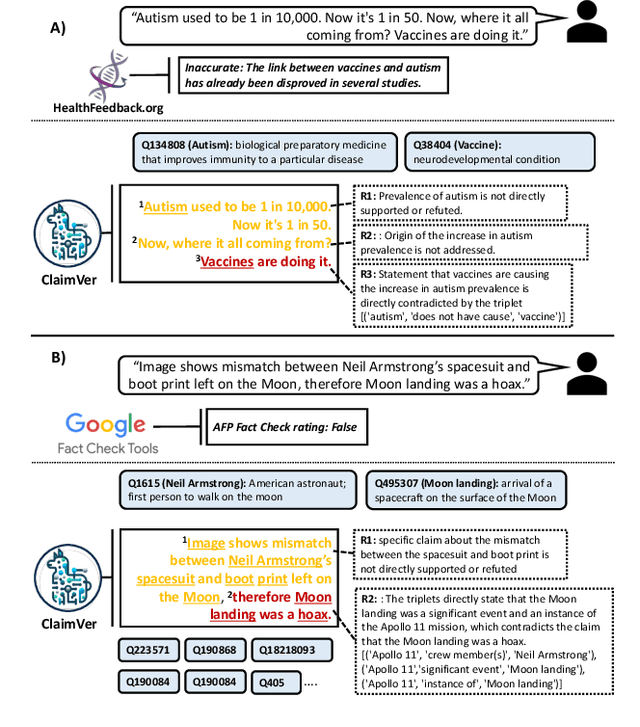
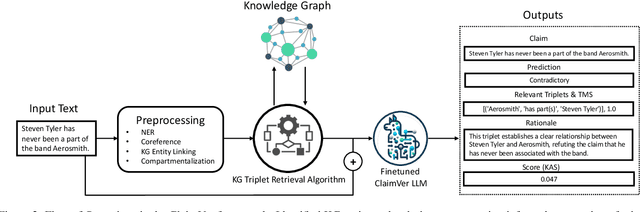
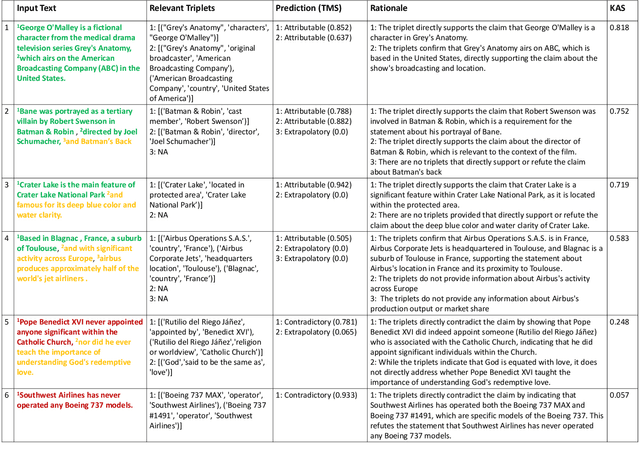
In the midst of widespread misinformation and disinformation through social media and the proliferation of AI-generated texts, it has become increasingly difficult for people to validate and trust information they encounter. Many fact-checking approaches and tools have been developed, but they often lack appropriate explainability or granularity to be useful in various contexts. A text validation method that is easy to use, accessible, and can perform fine-grained evidence attribution has become crucial. More importantly, building user trust in such a method requires presenting the rationale behind each prediction, as research shows this significantly influences people's belief in automated systems. It is also paramount to localize and bring users' attention to the specific problematic content, instead of providing simple blanket labels. In this paper, we present $\textit{ClaimVer, a human-centric framework}$ tailored to meet users' informational and verification needs by generating rich annotations and thereby reducing cognitive load. Designed to deliver comprehensive evaluations of texts, it highlights each claim, verifies it against a trusted knowledge graph (KG), presents the evidence, and provides succinct, clear explanations for each claim prediction. Finally, our framework introduces an attribution score, enhancing applicability across a wide range of downstream tasks.
Time-Efficient and Identity-Consistent Virtual Try-On Using A Variant of Altered Diffusion Models
Mar 12, 2024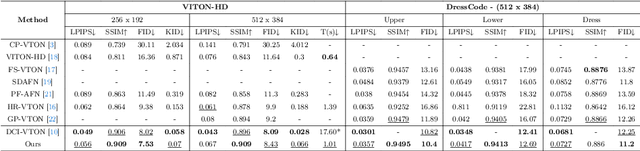
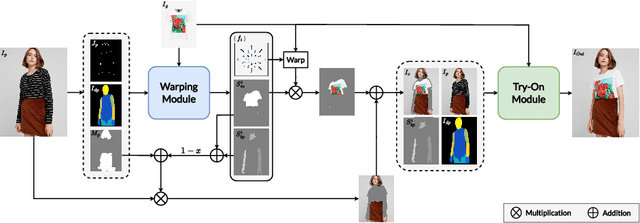
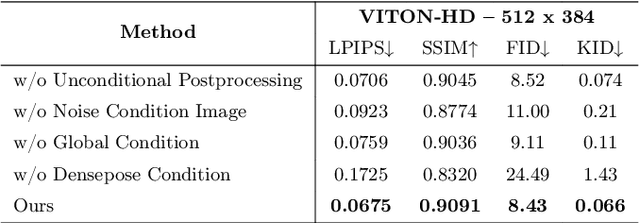
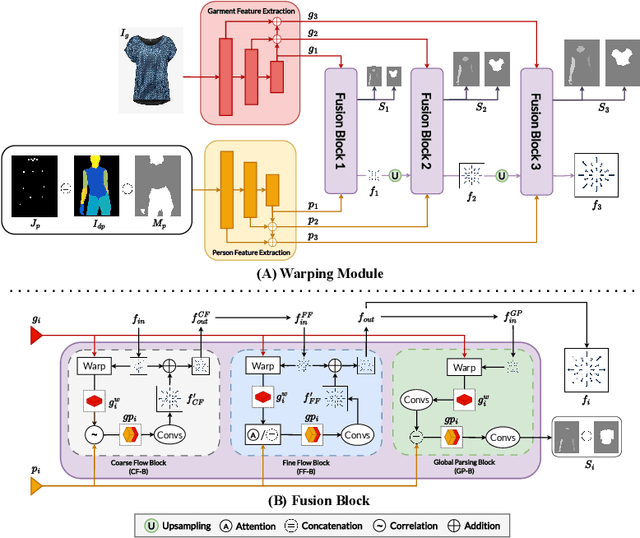
This study discusses the critical issues of Virtual Try-On in contemporary e-commerce and the prospective metaverse, emphasizing the challenges of preserving intricate texture details and distinctive features of the target person and the clothes in various scenarios, such as clothing texture and identity characteristics like tattoos or accessories. In addition to the fidelity of the synthesized images, the efficiency of the synthesis process presents a significant hurdle. Various existing approaches are explored, highlighting the limitations and unresolved aspects, e.g., identity information omission, uncontrollable artifacts, and low synthesis speed. It then proposes a novel diffusion-based solution that addresses garment texture preservation and user identity retention during virtual try-on. The proposed network comprises two primary modules - a warping module aligning clothing with individual features and a try-on module refining the attire and generating missing parts integrated with a mask-aware post-processing technique ensuring the integrity of the individual's identity. It demonstrates impressive results, surpassing the state-of-the-art in speed by nearly 20 times during inference, with superior fidelity in qualitative assessments. Quantitative evaluations confirm comparable performance with the recent SOTA method on the VITON-HD and Dresscode datasets.
Learning Correction Errors via Frequency-Self Attention for Blind Image Super-Resolution
Mar 12, 2024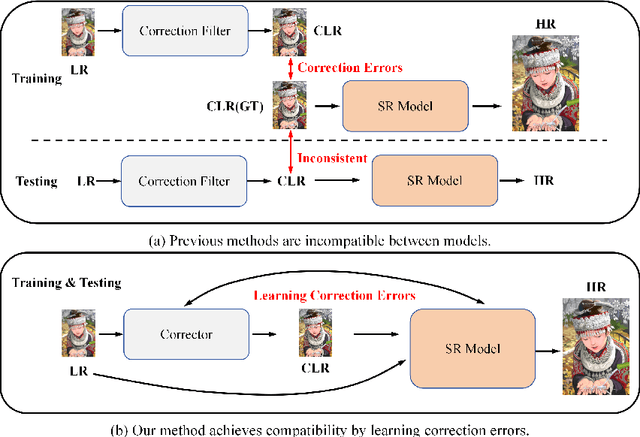

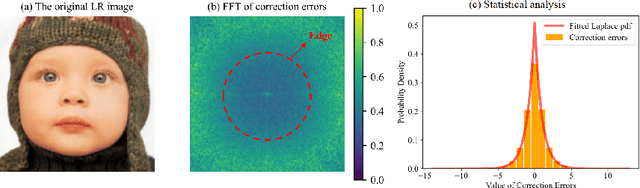
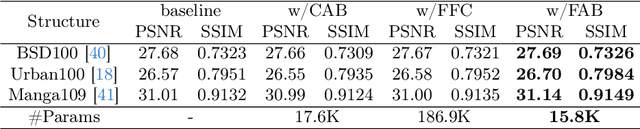
Previous approaches for blind image super-resolution (SR) have relied on degradation estimation to restore high-resolution (HR) images from their low-resolution (LR) counterparts. However, accurate degradation estimation poses significant challenges. The SR model's incompatibility with degradation estimation methods, particularly the Correction Filter, may significantly impair performance as a result of correction errors. In this paper, we introduce a novel blind SR approach that focuses on Learning Correction Errors (LCE). Our method employs a lightweight Corrector to obtain a corrected low-resolution (CLR) image. Subsequently, within an SR network, we jointly optimize SR performance by utilizing both the original LR image and the frequency learning of the CLR image. Additionally, we propose a new Frequency-Self Attention block (FSAB) that enhances the global information utilization ability of Transformer. This block integrates both self-attention and frequency spatial attention mechanisms. Extensive ablation and comparison experiments conducted across various settings demonstrate the superiority of our method in terms of visual quality and accuracy. Our approach effectively addresses the challenges associated with degradation estimation and correction errors, paving the way for more accurate blind image SR.
A Semantic Mention Graph Augmented Model for Document-Level Event Argument Extraction
Mar 12, 2024
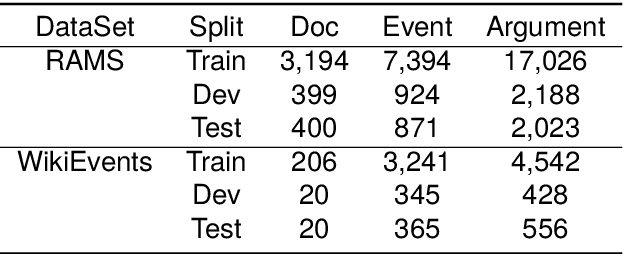

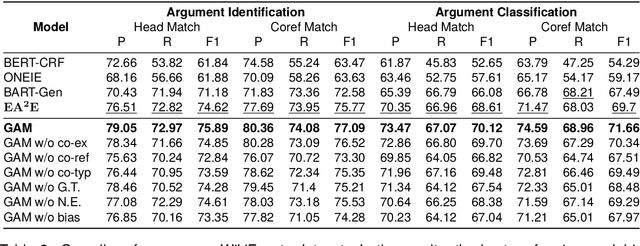
Document-level Event Argument Extraction (DEAE) aims to identify arguments and their specific roles from an unstructured document. The advanced approaches on DEAE utilize prompt-based methods to guide pre-trained language models (PLMs) in extracting arguments from input documents. They mainly concentrate on establishing relations between triggers and entity mentions within documents, leaving two unresolved problems: a) independent modeling of entity mentions; b) document-prompt isolation. To this end, we propose a semantic mention Graph Augmented Model (GAM) to address these two problems in this paper. Firstly, GAM constructs a semantic mention graph that captures relations within and between documents and prompts, encompassing co-existence, co-reference and co-type relations. Furthermore, we introduce an ensembled graph transformer module to address mentions and their three semantic relations effectively. Later, the graph-augmented encoder-decoder module incorporates the relation-specific graph into the input embedding of PLMs and optimizes the encoder section with topology information, enhancing the relations comprehensively. Extensive experiments on the RAMS and WikiEvents datasets demonstrate the effectiveness of our approach, surpassing baseline methods and achieving a new state-of-the-art performance.
Stable-Makeup: When Real-World Makeup Transfer Meets Diffusion Model
Mar 12, 2024Current makeup transfer methods are limited to simple makeup styles, making them difficult to apply in real-world scenarios. In this paper, we introduce Stable-Makeup, a novel diffusion-based makeup transfer method capable of robustly transferring a wide range of real-world makeup, onto user-provided faces. Stable-Makeup is based on a pre-trained diffusion model and utilizes a Detail-Preserving (D-P) makeup encoder to encode makeup details. It also employs content and structural control modules to preserve the content and structural information of the source image. With the aid of our newly added makeup cross-attention layers in U-Net, we can accurately transfer the detailed makeup to the corresponding position in the source image. After content-structure decoupling training, Stable-Makeup can maintain content and the facial structure of the source image. Moreover, our method has demonstrated strong robustness and generalizability, making it applicable to varioustasks such as cross-domain makeup transfer, makeup-guided text-to-image generation and so on. Extensive experiments have demonstrated that our approach delivers state-of-the-art (SOTA) results among existing makeup transfer methods and exhibits a highly promising with broad potential applications in various related fields.
Large Window-based Mamba UNet for Medical Image Segmentation: Beyond Convolution and Self-attention
Mar 12, 2024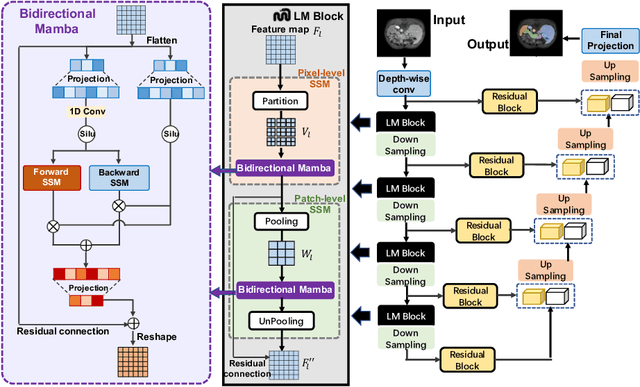
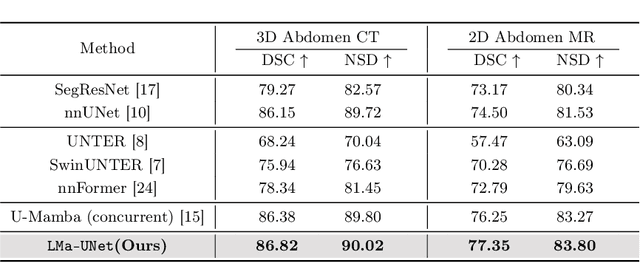
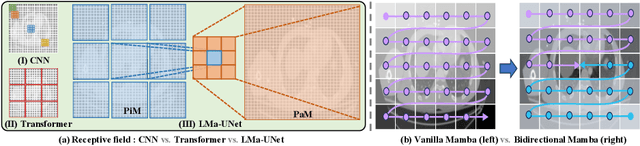

In clinical practice, medical image segmentation provides useful information on the contours and dimensions of target organs or tissues, facilitating improved diagnosis, analysis, and treatment. In the past few years, convolutional neural networks (CNNs) and Transformers have dominated this area, but they still suffer from either limited receptive fields or costly long-range modeling. Mamba, a State Space Sequence Model (SSM), recently emerged as a promising paradigm for long-range dependency modeling with linear complexity. In this paper, we introduce a Large Window-based Mamba U}-shape Network, or LMa-UNet, for 2D and 3D medical image segmentation. A distinguishing feature of our LMa-UNet is its utilization of large windows, excelling in locally spatial modeling compared to small kernel-based CNNs and small window-based Transformers, while maintaining superior efficiency in global modeling compared to self-attention with quadratic complexity. Additionally, we design a novel hierarchical and bidirectional Mamba block to further enhance the global and neighborhood spatial modeling capability of Mamba. Comprehensive experiments demonstrate the effectiveness and efficiency of our method and the feasibility of using large window size to achieve large receptive fields. Codes are available at https://github.com/wjh892521292/LMa-UNet.