 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Building Shortcuts between Distant Nodes with Biaffine Mapping for Graph Convolutional Networks
Feb 17, 2023
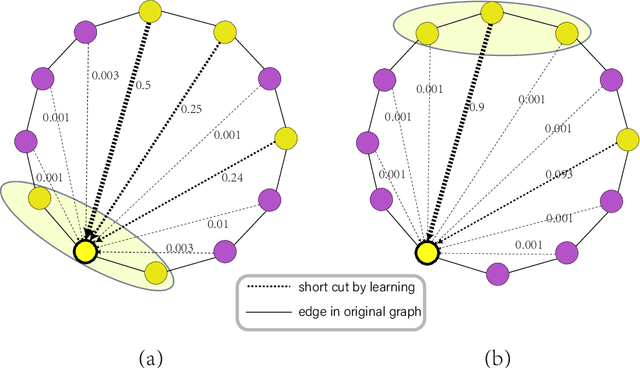
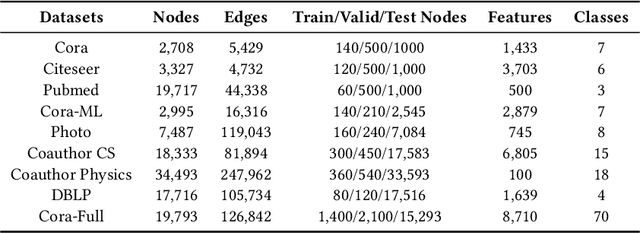
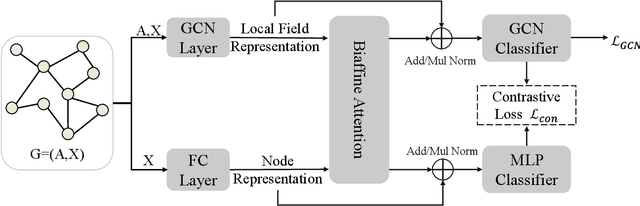
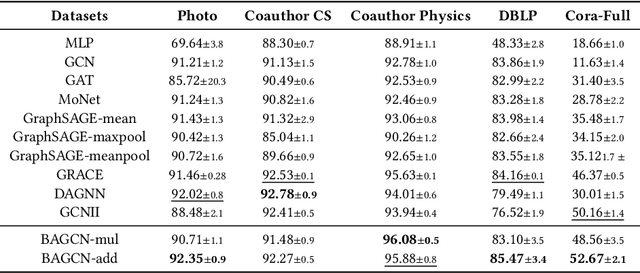
Multiple recent studies show a paradox in graph convolutional networks (GCNs), that is, shallow architectures limit the capability of learning information from high-order neighbors, while deep architectures suffer from over-smoothing or over-squashing. To enjoy the simplicity of shallow architectures and overcome their limits of neighborhood extension, in this work, we introduce Biaffine technique to improve the expressiveness of graph convolutional networks with a shallow architecture. The core design of our method is to learn direct dependency on long-distance neighbors for nodes, with which only one-hop message passing is capable of capturing rich information for node representation. Besides, we propose a multi-view contrastive learning method to exploit the representations learned from long-distance dependencies. Extensive experiments on nine graph benchmark datasets suggest that the shallow biaffine graph convolutional networks (BAGCN) significantly outperforms state-of-the-art GCNs (with deep or shallow architectures) on semi-supervised node classification. We further verify the effectiveness of biaffine design in node representation learning and the performance consistency on different sizes of training data.
Copula-based synthetic population generation
Feb 17, 2023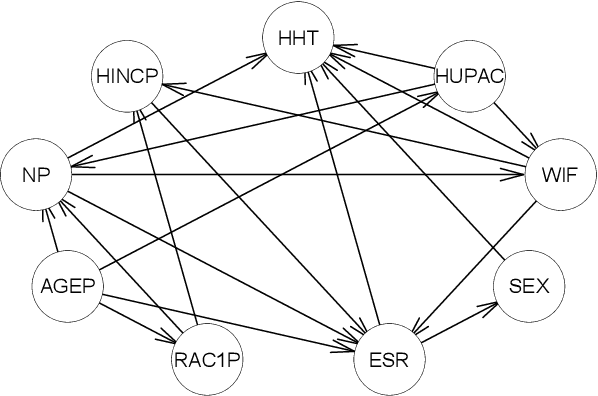
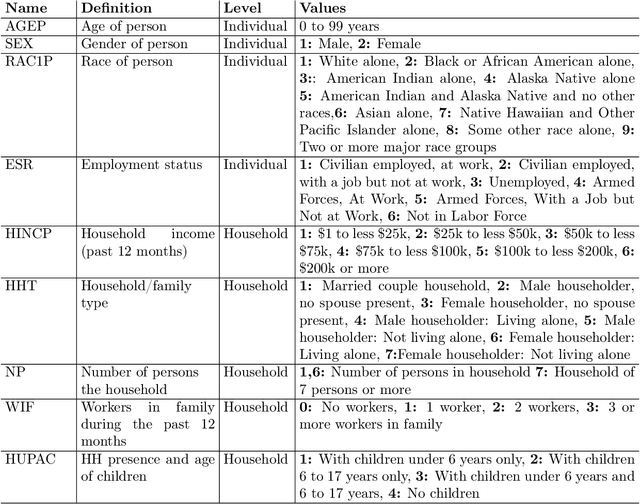
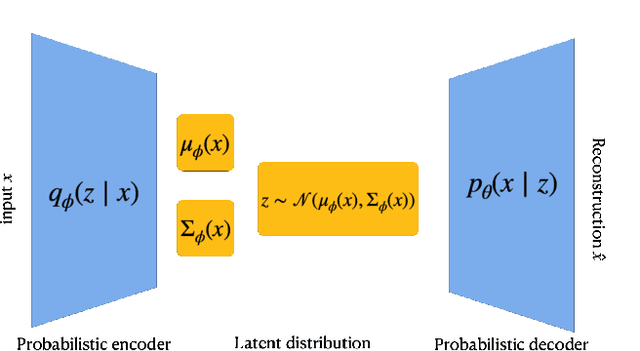
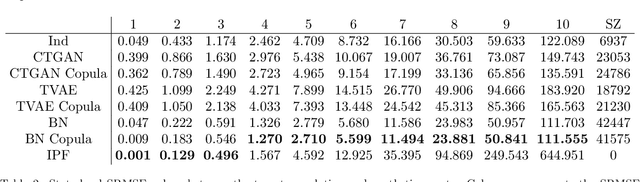
Population synthesis consists of generating synthetic but realistic representations of a target population of micro-agents for the purpose of behavioral modeling and simulation. We introduce a new framework based on copulas to generate synthetic data for a target population of which only the empirical marginal distributions are known by using a sample from another population sharing similar marginal dependencies. This makes it possible to include a spatial component in the generation of population synthesis and to combine various sources of information to obtain more realistic population generators. Specifically, we normalize the data and treat them as realizations of a given copula, and train a generative model on the normalized data before injecting the information on the marginals. We compare the copulas framework to IPF and to modern probabilistic approaches such as Bayesian networks, variational auto-encoders, and generative adversarial networks. We also illustrate on American Community Survey data that the method proposed allows to study the structure of the data at different geographical levels in a way that is robust to the peculiarities of the marginal distributions.
A Laplace-inspired Distribution on SO(3) for Probabilistic Rotation Estimation
Mar 03, 2023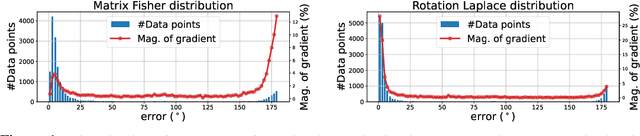
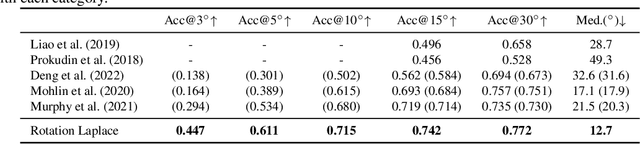
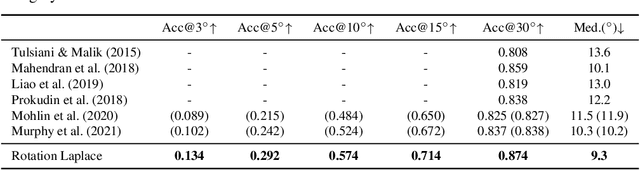
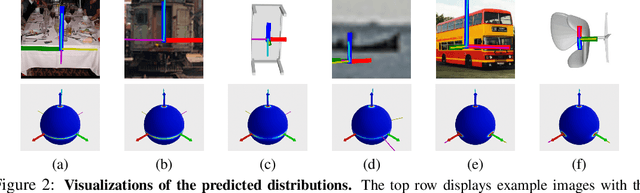
Estimating the 3DoF rotation from a single RGB image is an important yet challenging problem. Probabilistic rotation regression has raised more and more attention with the benefit of expressing uncertainty information along with the prediction. Though modeling noise using Gaussian-resembling Bingham distribution and matrix Fisher distribution is natural, they are shown to be sensitive to outliers for the nature of quadratic punishment to deviations. In this paper, we draw inspiration from multivariate Laplace distribution and propose a novel Rotation Laplace distribution on SO(3). Rotation Laplace distribution is robust to the disturbance of outliers and enforces much gradient to the low-error region, resulting in a better convergence. Our extensive experiments show that our proposed distribution achieves state-of-the-art performance for rotation regression tasks over both probabilistic and non-probabilistic baselines. Our project page is at https://pku-epic.github.io/RotationLaplace.
Exploring Long & Short Range Temporal Information for Learned Video Compression
Aug 07, 2022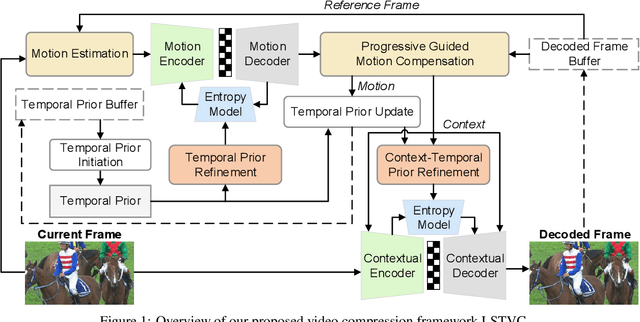
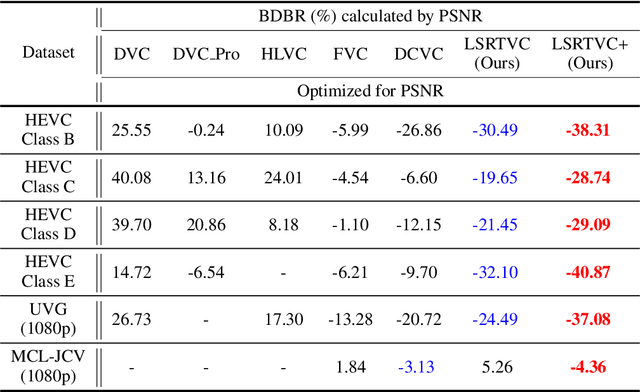
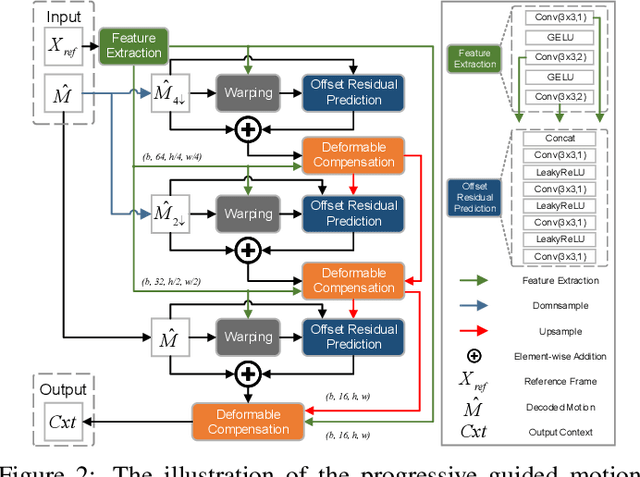
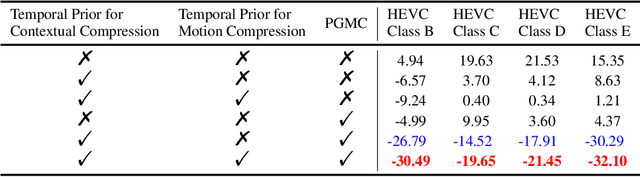
Learned video compression methods have gained a variety of interest in the video coding community since they have matched or even exceeded the rate-distortion (RD) performance of traditional video codecs. However, many current learning-based methods are dedicated to utilizing short-range temporal information, thus limiting their performance. In this paper, we focus on exploiting the unique characteristics of video content and further exploring temporal information to enhance compression performance. Specifically, for long-range temporal information exploitation, we propose temporal prior that can update continuously within the group of pictures (GOP) during inference. In that case temporal prior contains valuable temporal information of all decoded images within the current GOP. As for short-range temporal information, we propose a progressive guided motion compensation to achieve robust and effective compensation. In detail, we design a hierarchical structure to achieve multi-scale compensation. More importantly, we use optical flow guidance to generate pixel offsets between feature maps at each scale, and the compensation results at each scale will be used to guide the following scale's compensation. Sufficient experimental results demonstrate that our method can obtain better RD performance than state-of-the-art video compression approaches. The code is publicly available on: https://github.com/Huairui/LSTVC.
Vision based Virtual Guidance for Navigation
Mar 05, 2023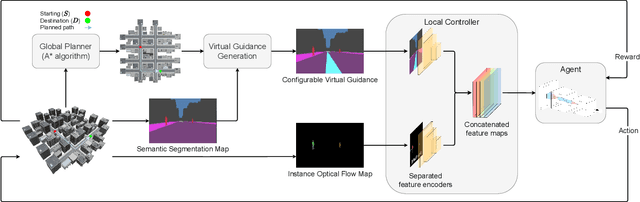

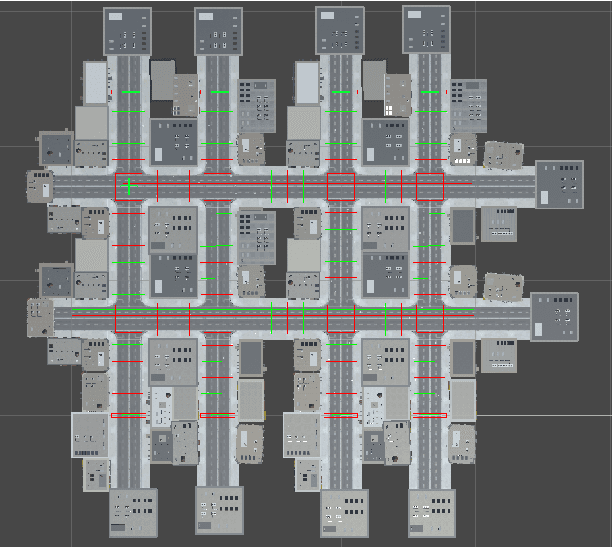
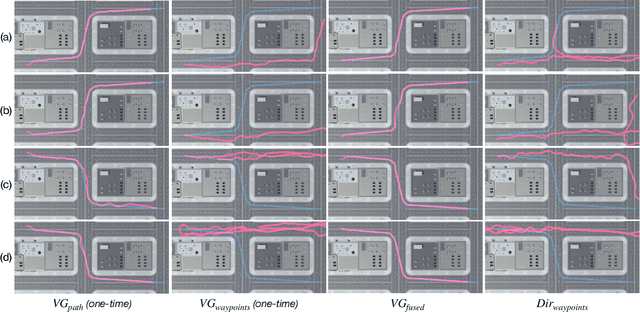
This paper explores the impact of virtual guidance on mid-level representation-based navigation, where an agent performs navigation tasks based solely on visual observations. Instead of providing distance measures or numerical directions to guide the agent, which may be difficult for it to interpret visually, the paper investigates the potential of different forms of virtual guidance schemes on navigation performance. Three schemes of virtual guidance signals are explored: virtual navigation path, virtual waypoints, and a combination of both. The experiments were conducted using a virtual city built with the Unity engine to train the agents while avoiding obstacles. The results show that virtual guidance provides the agent with more meaningful navigation information and achieves better performance in terms of path completion rates and navigation efficiency. In addition, a set of analyses were provided to investigate the failure cases and the navigated trajectories, and a pilot study was conducted for the real-world scenarios.
Rank and Condition Number Analysis for UAV MIMO Channels Using Ray Tracing
Mar 05, 2023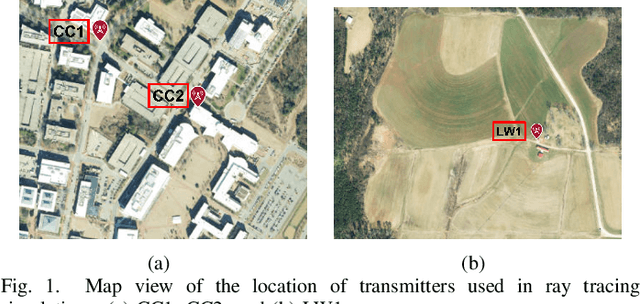
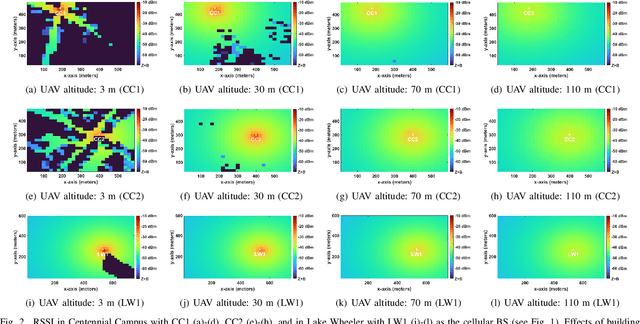
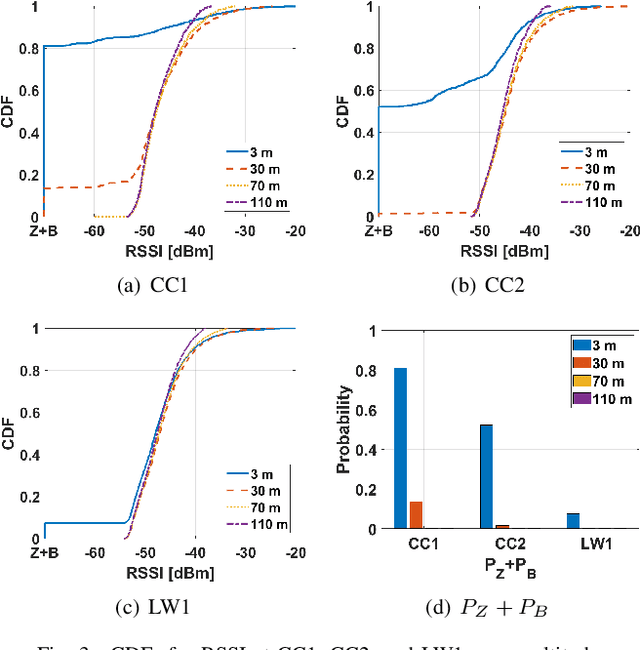
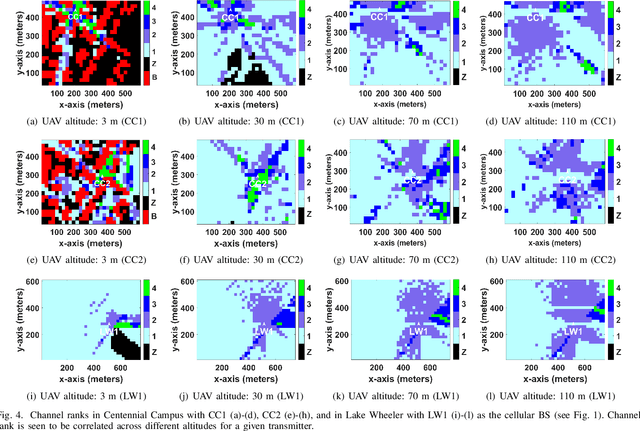
Channel rank and condition number of multi-input multi-output (MIMO) channels can be effective indicators of achievable rates with spatial multiplexing in mobile networks. In this paper, we use extensive ray tracing simulations to investigate channel rank, condition number, and signal coverage distribution for air-to-ground MIMO channels. We consider UAV-based user equipment (UE) at altitudes of 3 m, 30 m, 70 m, and 110 m from the ground. Moreover, we also consider their communication link with a cellular base station in urban and rural areas. In particular, Centennial Campus and Lake Wheeler Road Field Labs of NC State University are considered, and their geographical information extracted from the open street map (OSM) database is incorporated into ray tracing simulations. Our results characterize how the channel rank tends to reduce as a function of UAV altitude, while also providing insights into the effects of geography, building distribution, and threshold parameters on channel rank and condition number.
Model Extraction Attacks on Split Federated Learning
Mar 13, 2023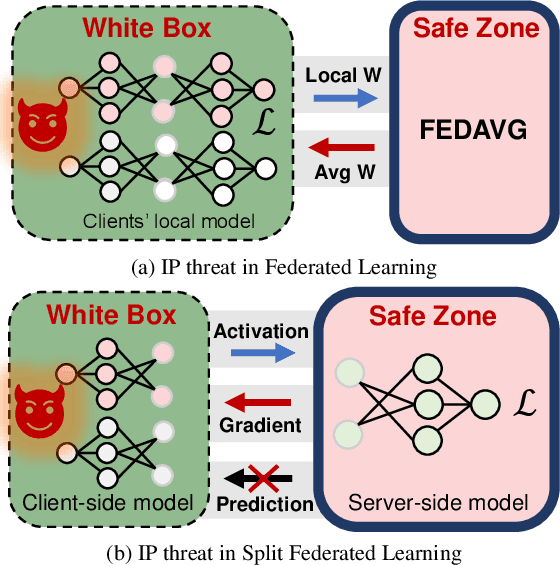
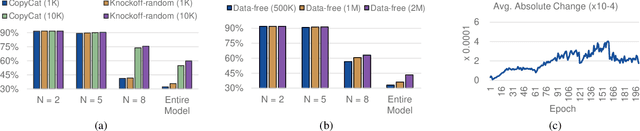
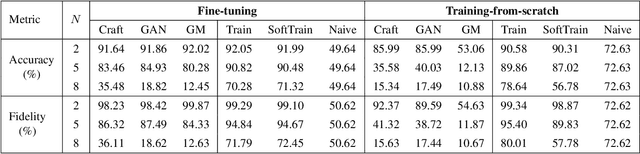
Federated Learning (FL) is a popular collaborative learning scheme involving multiple clients and a server. FL focuses on protecting clients' data but turns out to be highly vulnerable to Intellectual Property (IP) threats. Since FL periodically collects and distributes the model parameters, a free-rider can download the latest model and thus steal model IP. Split Federated Learning (SFL), a recent variant of FL that supports training with resource-constrained clients, splits the model into two, giving one part of the model to clients (client-side model), and the remaining part to the server (server-side model). Thus SFL prevents model leakage by design. Moreover, by blocking prediction queries, it can be made resistant to advanced IP threats such as traditional Model Extraction (ME) attacks. While SFL is better than FL in terms of providing IP protection, it is still vulnerable. In this paper, we expose the vulnerability of SFL and show how malicious clients can launch ME attacks by querying the gradient information from the server side. We propose five variants of ME attack which differs in the gradient usage as well as in the data assumptions. We show that under practical cases, the proposed ME attacks work exceptionally well for SFL. For instance, when the server-side model has five layers, our proposed ME attack can achieve over 90% accuracy with less than 2% accuracy degradation with VGG-11 on CIFAR-10.
Ultrafast single-channel machine vision based on neuro-inspired photonic computing
Feb 15, 2023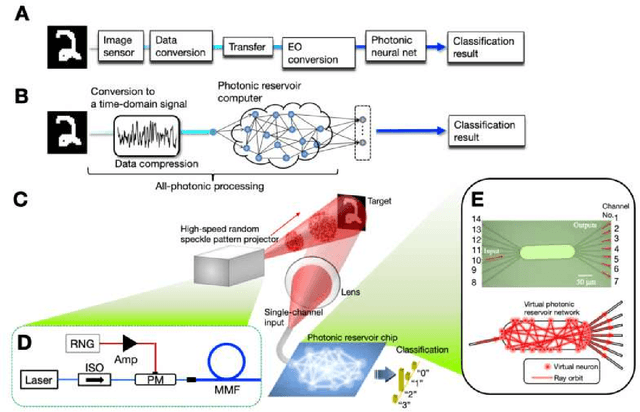
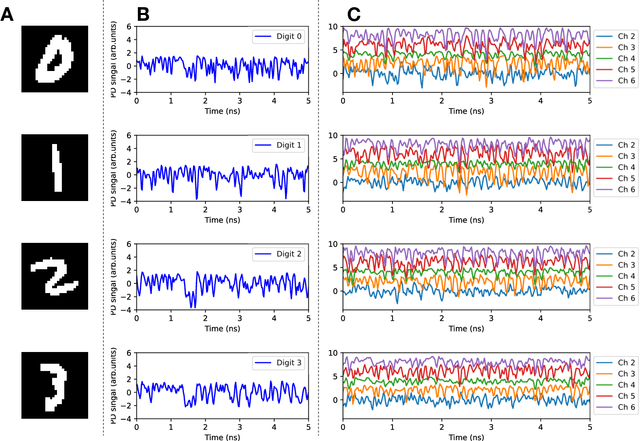
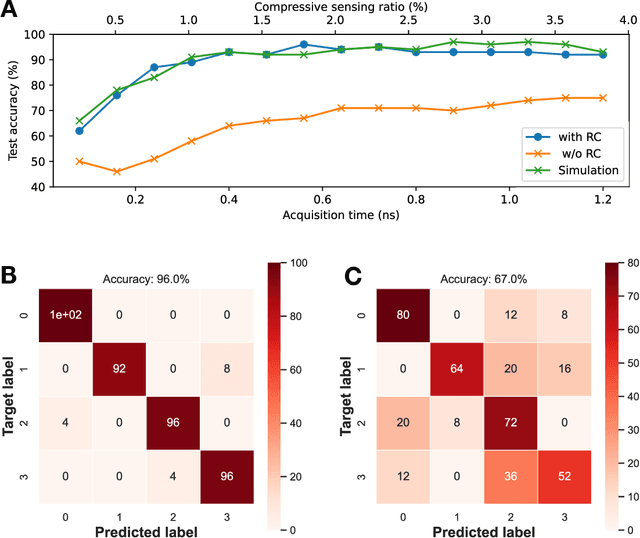
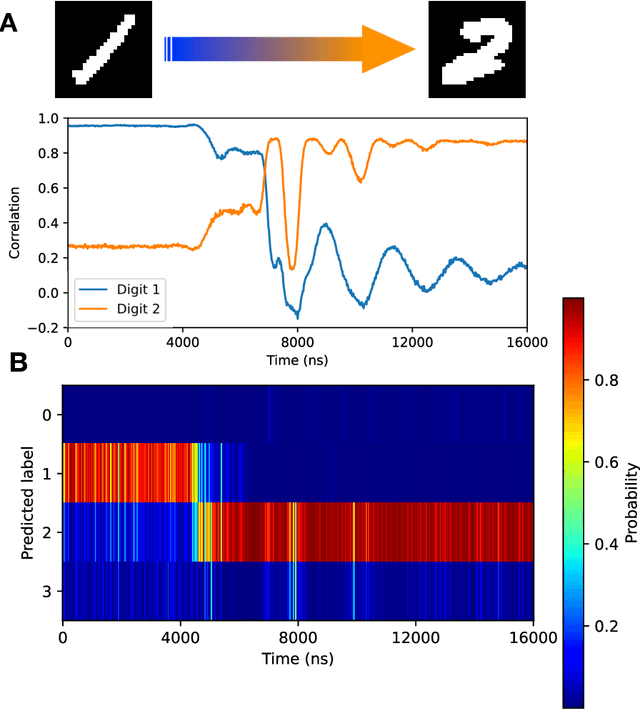
High-speed machine vision is increasing its importance in both scientific and technological applications. Neuro-inspired photonic computing is a promising approach to speed-up machine vision processing with ultralow latency. However, the processing rate is fundamentally limited by the low frame rate of image sensors, typically operating at tens of hertz. Here, we propose an image-sensor-free machine vision framework, which optically processes real-world visual information with only a single input channel, based on a random temporal encoding technique. This approach allows for compressive acquisitions of visual information with a single channel at gigahertz rates, outperforming conventional approaches, and enables its direct photonic processing using a photonic reservoir computer in a time domain. We experimentally demonstrate that the proposed approach is capable of high-speed image recognition and anomaly detection, and furthermore, it can be used for high-speed imaging. The proposed approach is multipurpose and can be extended for a wide range of applications, including tracking, controlling, and capturing sub-nanosecond phenomena.
Adaptive incentive for cross-silo federated learning: A multi-agent reinforcement learning approach
Feb 15, 2023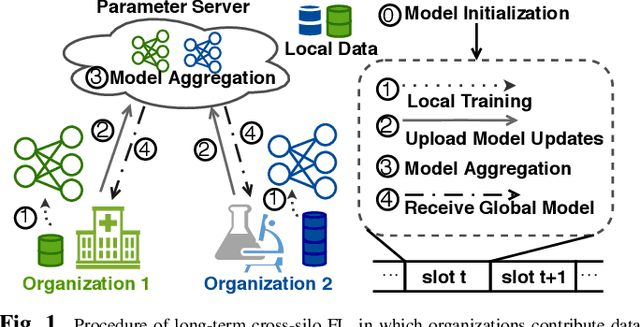
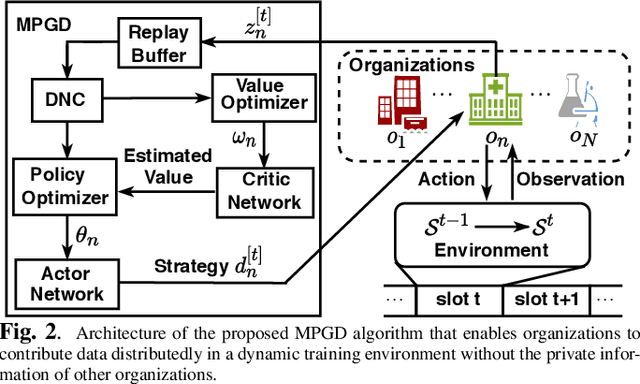
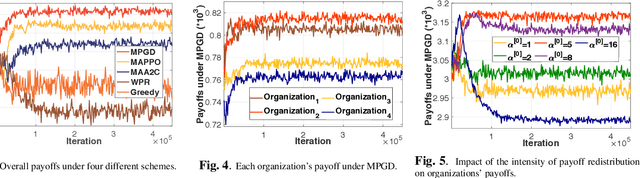
Cross-silo federated learning (FL) is a typical FL that enables organizations(e.g., financial or medical entities) to train global models on isolated data. Reasonable incentive is key to encouraging organizations to contribute data. However, existing works on incentivizing cross-silo FL lack consideration of the environmental dynamics (e.g., precision of the trained global model and data owned by uncertain clients during the training processes). Moreover, most of them assume that organizations share private information, which is unrealistic. To overcome these limitations, we propose a novel adaptive mechanism for cross-silo FL, towards incentivizing organizations to contribute data to maximize their long-term payoffs in a real dynamic training environment. The mechanism is based on multi-agent reinforcement learning, which learns near-optimal data contribution strategy from the history of potential games without organizations' private information. Experiments demonstrate that our mechanism achieves adaptive incentive and effectively improves the long-term payoffs for organizations.
Streamlining models with explanations in the learning loop
Feb 15, 2023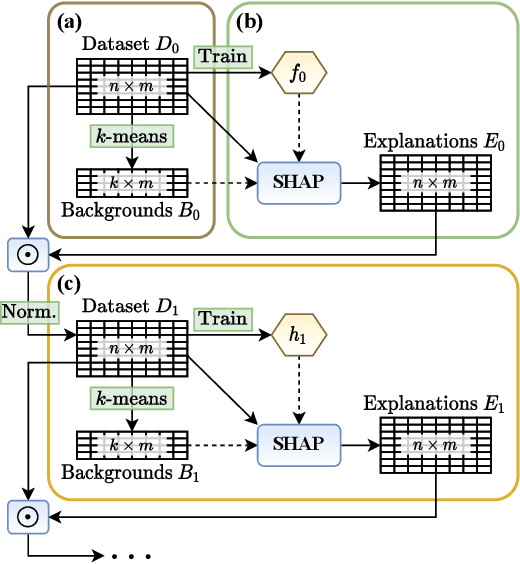
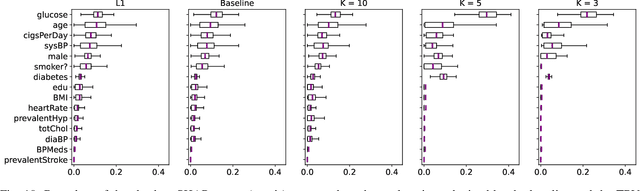
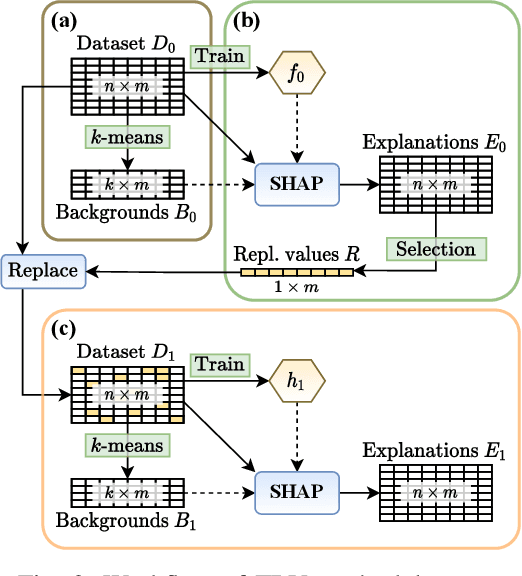
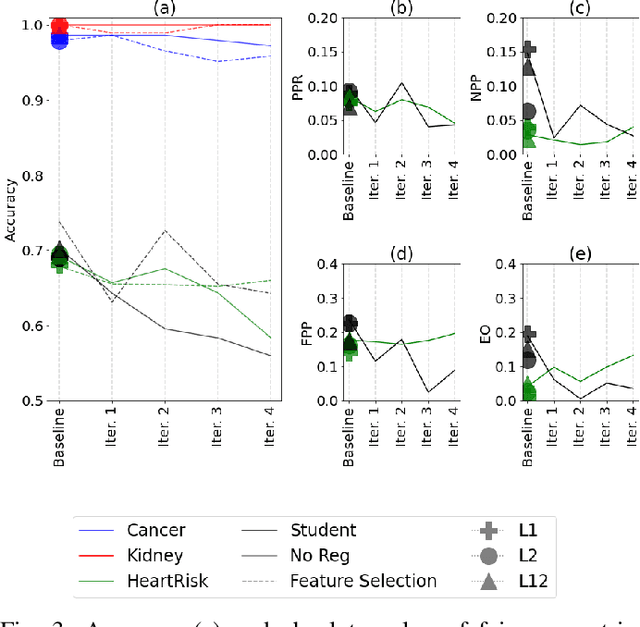
Several explainable AI methods allow a Machine Learning user to get insights on the classification process of a black-box model in the form of local linear explanations. With such information, the user can judge which features are locally relevant for the classification outcome, and get an understanding of how the model reasons. Standard supervised learning processes are purely driven by the original features and target labels, without any feedback loop informed by the local relevance of the features identified by the post-hoc explanations. In this paper, we exploit this newly obtained information to design a feature engineering phase, where we combine explanations with feature values. To do so, we develop two different strategies, named Iterative Dataset Weighting and Targeted Replacement Values, which generate streamlined models that better mimic the explanation process presented to the user. We show how these streamlined models compare to the original black-box classifiers, in terms of accuracy and compactness of the newly produced explanations.
* 16 pages, 10 figures, available repository