 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
À-la-carte Prompt Tuning (APT): Combining Distinct Data Via Composable Prompting
Feb 15, 2023
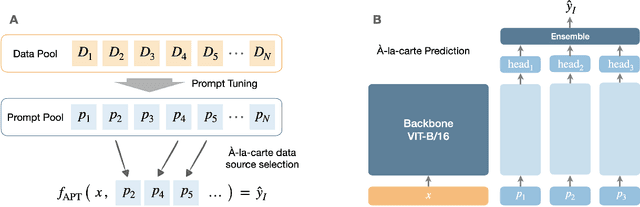


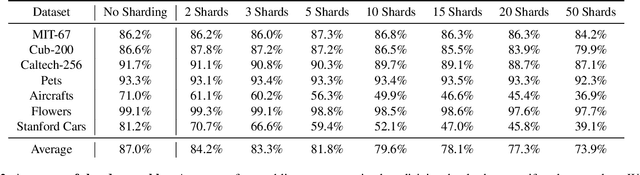
We introduce \`A-la-carte Prompt Tuning (APT), a transformer-based scheme to tune prompts on distinct data so that they can be arbitrarily composed at inference time. The individual prompts can be trained in isolation, possibly on different devices, at different times, and on different distributions or domains. Furthermore each prompt only contains information about the subset of data it was exposed to during training. During inference, models can be assembled based on arbitrary selections of data sources, which we call "\`a-la-carte learning". \`A-la-carte learning enables constructing bespoke models specific to each user's individual access rights and preferences. We can add or remove information from the model by simply adding or removing the corresponding prompts without retraining from scratch. We demonstrate that \`a-la-carte built models achieve accuracy within $5\%$ of models trained on the union of the respective sources, with comparable cost in terms of training and inference time. For the continual learning benchmarks Split CIFAR-100 and CORe50, we achieve state-of-the-art performance.
Time Associated Meta Learning for Clinical Prediction
Mar 05, 2023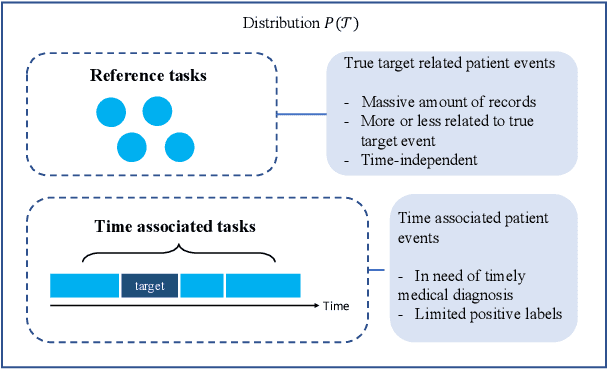
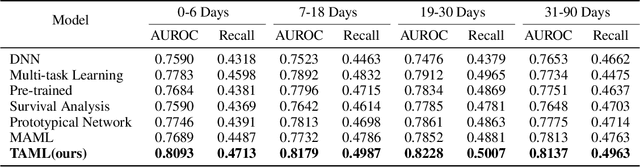
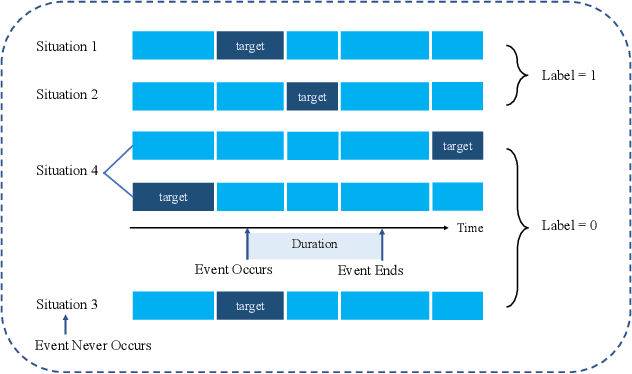
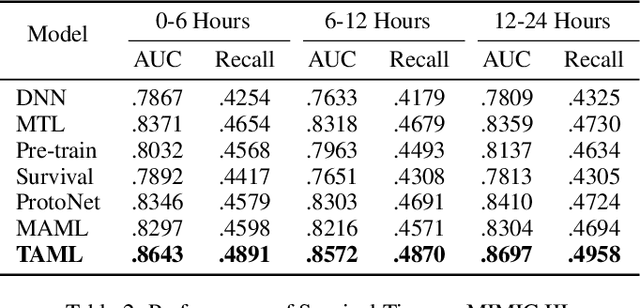
Rich Electronic Health Records (EHR), have created opportunities to improve clinical processes using machine learning methods. Prediction of the same patient events at different time horizons can have very different applications and interpretations; however, limited number of events in each potential time window hurts the effectiveness of conventional machine learning algorithms. We propose a novel time associated meta learning (TAML) method to make effective predictions at multiple future time points. We view time-associated disease prediction as classification tasks at multiple time points. Such closely-related classification tasks are an excellent candidate for model-based meta learning. To address the sparsity problem after task splitting, TAML employs a temporal information sharing strategy to augment the number of positive samples and include the prediction of related phenotypes or events in the meta-training phase. We demonstrate the effectiveness of TAML on multiple clinical datasets, where it consistently outperforms a range of strong baselines. We also develop a MetaEHR package for implementing both time-associated and time-independent few-shot prediction on EHR data.
Semantic-aware Occlusion Filtering Neural Radiance Fields in the Wild
Mar 05, 2023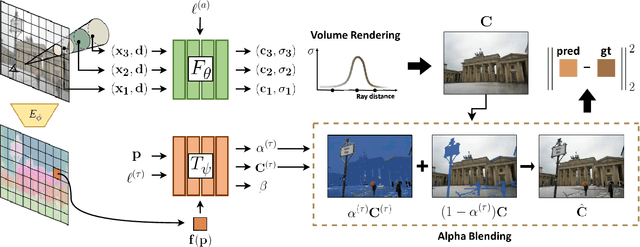
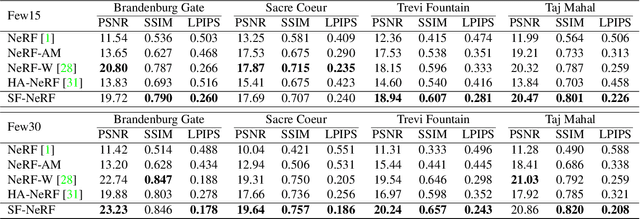

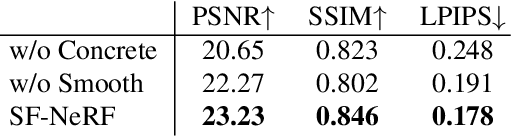
We present a learning framework for reconstructing neural scene representations from a small number of unconstrained tourist photos. Since each image contains transient occluders, decomposing the static and transient components is necessary to construct radiance fields with such in-the-wild photographs where existing methods require a lot of training data. We introduce SF-NeRF, aiming to disentangle those two components with only a few images given, which exploits semantic information without any supervision. The proposed method contains an occlusion filtering module that predicts the transient color and its opacity for each pixel, which enables the NeRF model to solely learn the static scene representation. This filtering module learns the transient phenomena guided by pixel-wise semantic features obtained by a trainable image encoder that can be trained across multiple scenes to learn the prior of transient objects. Furthermore, we present two techniques to prevent ambiguous decomposition and noisy results of the filtering module. We demonstrate that our method outperforms state-of-the-art novel view synthesis methods on Phototourism dataset in a few-shot setting.
Multi-View Ensemble Learning With Missing Data: Computational Framework and Evaluations using Novel Data from the Safe Autonomous Driving Domain
Jan 30, 2023

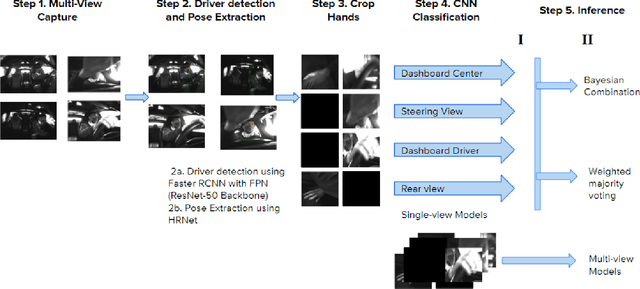
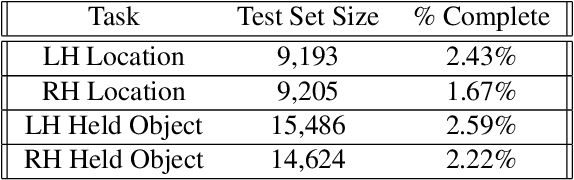
Real-world applications with multiple sensors observing an event are expected to make continuously-available predictions, even in cases where information may be intermittently missing. We explore methods in ensemble learning and sensor fusion to make use of redundancy and information shared between four camera views, applied to the task of hand activity classification for autonomous driving. In particular, we show that a late-fusion approach between parallel convolutional neural networks can outperform even the best-placed single camera model. To enable this approach, we propose a scheme for handling missing information, and then provide comparative analysis of this late-fusion approach to additional methods such as weighted majority voting and model combination schemes.
Neural Intrinsic Embedding for Non-rigid Point Cloud Matching
Mar 02, 2023
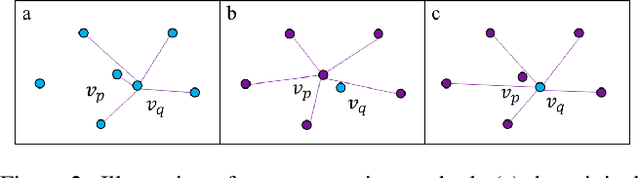
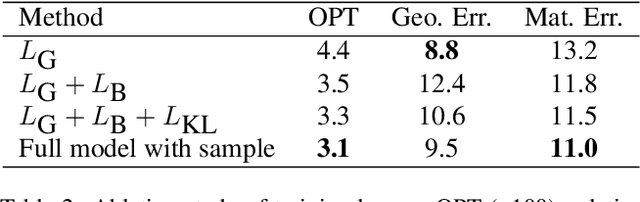
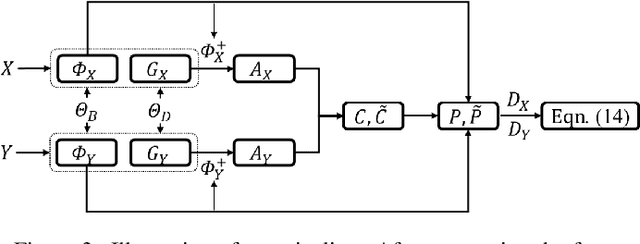
As a primitive 3D data representation, point clouds are prevailing in 3D sensing, yet short of intrinsic structural information of the underlying objects. Such discrepancy poses great challenges on directly establishing correspondences between point clouds sampled from deformable shapes. In light of this, we propose Neural Intrinsic Embedding (NIE) to embed each vertex into a high-dimensional space in a way that respects the intrinsic structure. Based upon NIE, we further present a weakly-supervised learning framework for non-rigid point cloud registration. Unlike the prior works, we do not require expansive and sensitive off-line basis construction (e.g., eigen-decomposition of Laplacians), nor do we require ground-truth correspondence labels for supervision. We empirically show that our framework performs on par with or even better than the state-of-the-art baselines, which generally require more supervision and/or more structural geometric input.
CAM++: A Fast and Efficient Network for Speaker Verification Using Context-Aware Masking
Mar 02, 2023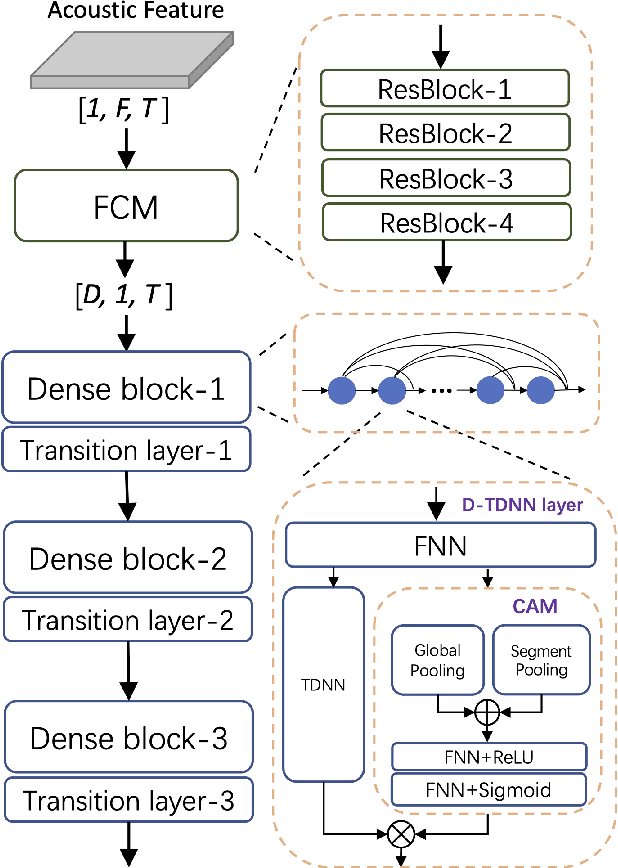
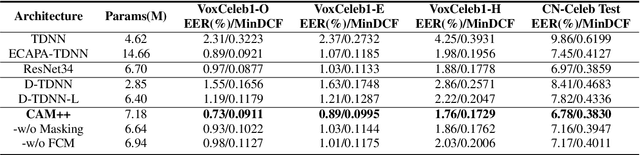
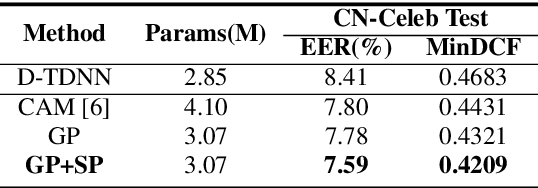

Time delay neural network (TDNN) has been proven to be efficient for speaker verification. One of its successful variants, ECAPA-TDNN, achieved state-of-the-art performance at the cost of much higher computational complexity and slower inference speed. This makes it inadequate for scenarios with demanding inference rate and limited computational resources. We are thus interested in finding an architecture that can achieve the performance of ECAPA-TDNN and the efficiency of vanilla TDNN. In this paper, we propose an efficient network based on context-aware masking, namely CAM++, which uses densely connected time delay neural network (D-TDNN) as backbone and adopts a novel multi-granularity pooling to capture contextual information at different levels. Extensive experiments on two public benchmarks, VoxCeleb and CN-Celeb, demonstrate that the proposed architecture outperforms other mainstream speaker verification systems with lower computational cost and faster inference speed.
Attention-based Graph Convolution Fusing Latent Structures and Multiple Features for Graph Neural Networks
Mar 02, 2023
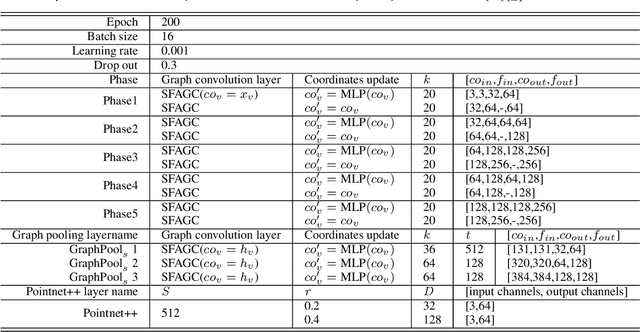
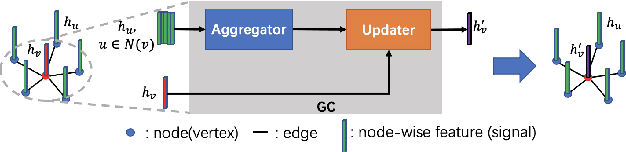
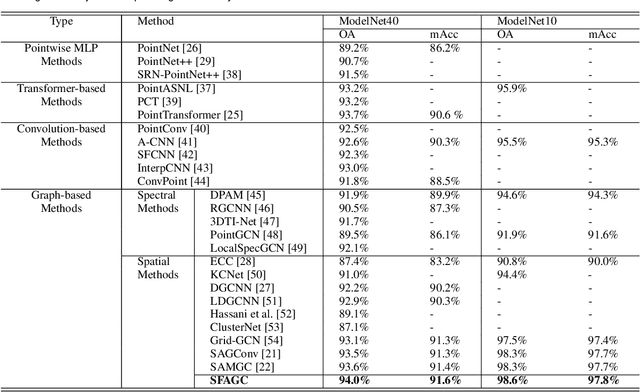
We present an attention-based spatial graph convolution (AGC) for graph neural networks (GNNs). Existing AGCs focus on only using node-wise features and utilizing one type of attention function when calculating attention weights. Instead, we propose two methods to improve the representational power of AGCs by utilizing 1) structural information in a high-dimensional space and 2) multiple attention functions when calculating their weights. The first method computes a local structure representation of a graph in a high-dimensional space. The second method utilizes multiple attention functions simultaneously in one AGC. Both approaches can be combined. We also propose a GNN for the classification of point clouds and that for the prediction of point labels in a point cloud based on the proposed AGC. According to experiments, the proposed GNNs perform better than existing methods. Our codes open at https://github.com/liyang-tuat/SFAGC.
Distilling Multi-Level X-vector Knowledge for Small-footprint Speaker Verification
Mar 02, 2023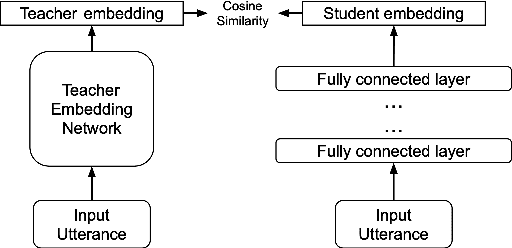
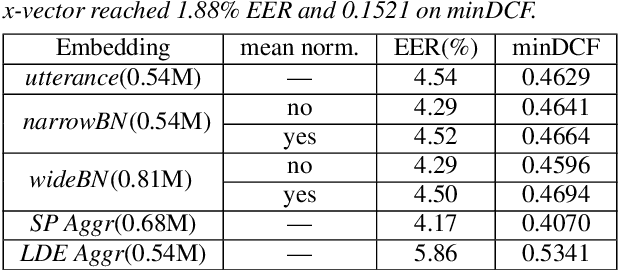
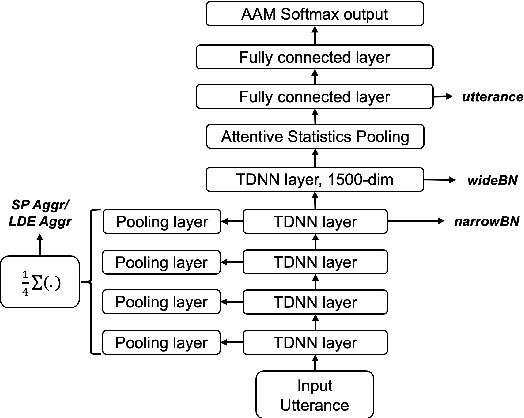

Deep speaker models yield low error rates in speaker verification. Nonetheless, the high performance tends to be exchanged for model size and computation time, making these models challenging to run under limited conditions. We focus on small-footprint deep speaker embedding extraction, leveraging knowledge distillation. While prior work on this topic has addressed speaker embedding extraction at the utterance level, we propose to combine embeddings from various levels of the x-vector model (teacher network) to train small-footprint student networks. Results indicate the usefulness of frame-level information, with the student models being 85%-91% smaller than their teacher, depending on the size of the teacher embeddings. Concatenation of teacher embeddings results in student networks that reach comparable performance along with the teacher while utilizing a 75% relative size reduction from the teacher. The findings and analogies are furthered to other x-vector variants.
AZTR: Aerial Video Action Recognition with Auto Zoom and Temporal Reasoning
Mar 02, 2023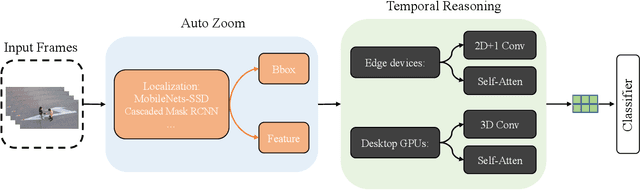
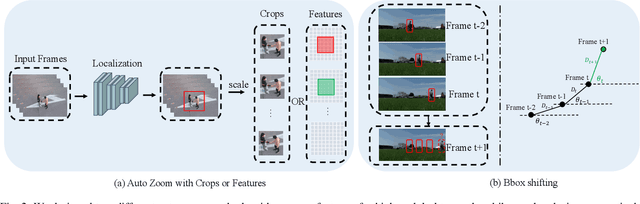
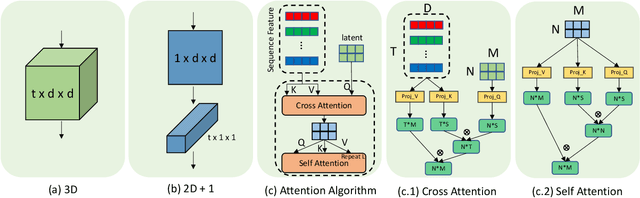

We propose a novel approach for aerial video action recognition. Our method is designed for videos captured using UAVs and can run on edge or mobile devices. We present a learning-based approach that uses customized auto zoom to automatically identify the human target and scale it appropriately. This makes it easier to extract the key features and reduces the computational overhead. We also present an efficient temporal reasoning algorithm to capture the action information along the spatial and temporal domains within a controllable computational cost. Our approach has been implemented and evaluated both on the desktop with high-end GPUs and on the low power Robotics RB5 Platform for robots and drones. In practice, we achieve 6.1-7.4% improvement over SOTA in Top-1 accuracy on the RoCoG-v2 dataset, 8.3-10.4% improvement on the UAV-Human dataset and 3.2% improvement on the Drone Action dataset.
Contrastive Hierarchical Clustering
Mar 03, 2023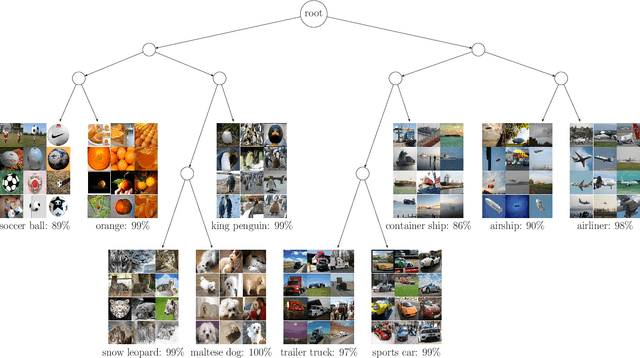
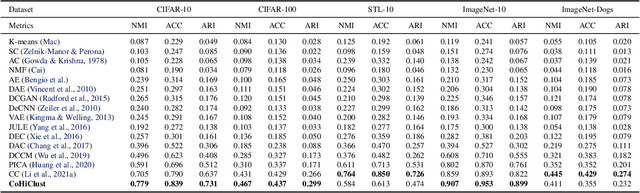
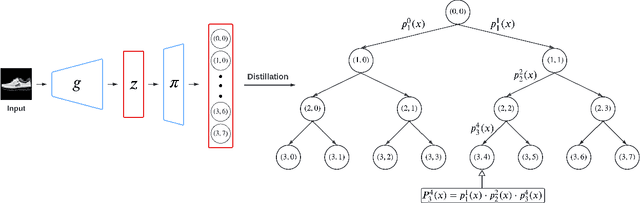
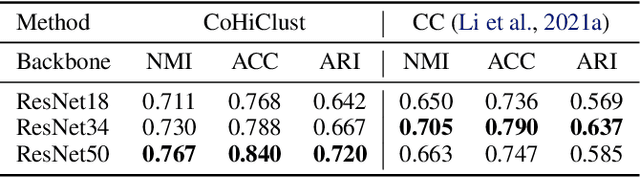
Deep clustering has been dominated by flat models, which split a dataset into a predefined number of groups. Although recent methods achieve an extremely high similarity with the ground truth on popular benchmarks, the information contained in the flat partition is limited. In this paper, we introduce CoHiClust, a Contrastive Hierarchical Clustering model based on deep neural networks, which can be applied to typical image data. By employing a self-supervised learning approach, CoHiClust distills the base network into a binary tree without access to any labeled data. The hierarchical clustering structure can be used to analyze the relationship between clusters, as well as to measure the similarity between data points. Experiments demonstrate that CoHiClust generates a reasonable structure of clusters, which is consistent with our intuition and image semantics. Moreover, it obtains superior clustering accuracy on most of the image datasets compared to the state-of-the-art flat clustering models.