 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generating Evidential BEV Maps in Continuous Driving Space
Feb 06, 2023
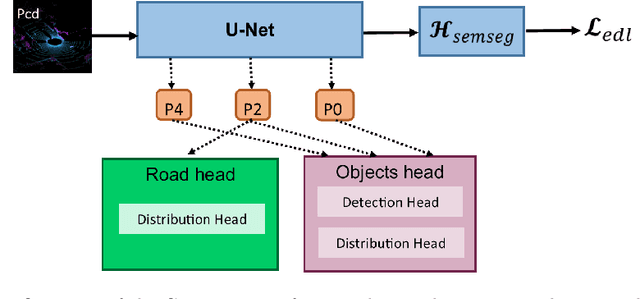

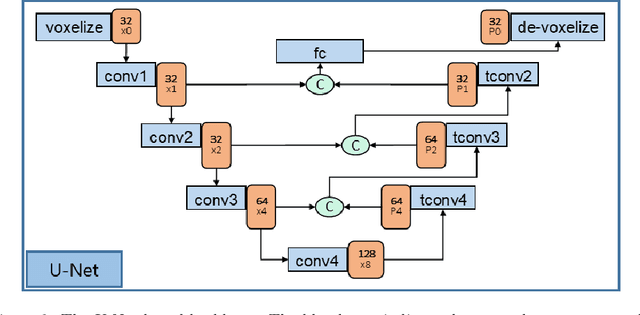

Safety is critical for autonomous driving, and one aspect of improving safety is to accurately capture the uncertainties of the perception system, especially knowing the unknown. Different from only providing deterministic or probabilistic results, e.g., probabilistic object detection, that only provide partial information for the perception scenario, we propose a complete probabilistic model named GevBEV. It interprets the 2D driving space as a probabilistic Bird's Eye View (BEV) map with point-based spatial Gaussian distributions, from which one can draw evidence as the parameters for the categorical Dirichlet distribution of any new sample point in the continuous driving space. The experimental results show that GevBEV not only provides more reliable uncertainty quantification but also outperforms the previous works on the benchmark OPV2V of BEV map interpretation for cooperative perception. A critical factor in cooperative perception is the data transmission size through the communication channels. GevBEV helps reduce communication overhead by selecting only the most important information to share from the learned uncertainty, reducing the average information communicated by 80% with a slight performance drop.
TrafficBots: Towards World Models for Autonomous Driving Simulation and Motion Prediction
Mar 07, 2023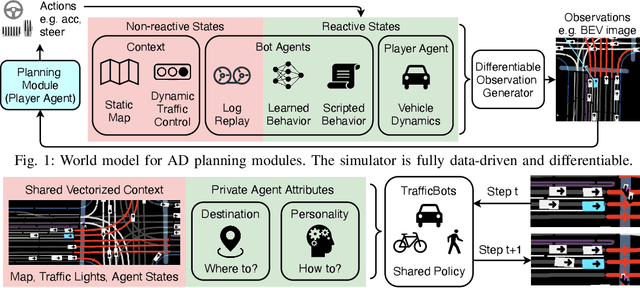
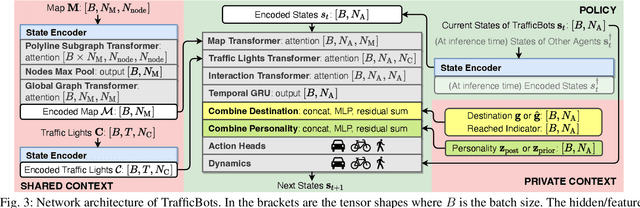
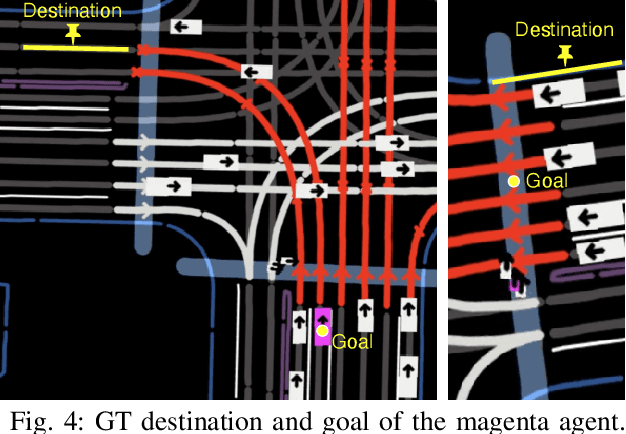
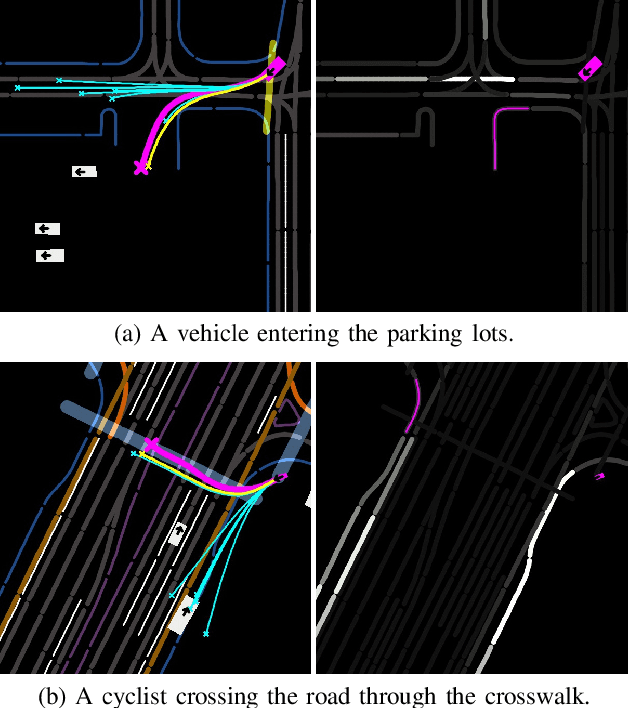
Data-driven simulation has become a favorable way to train and test autonomous driving algorithms. The idea of replacing the actual environment with a learned simulator has also been explored in model-based reinforcement learning in the context of world models. In this work, we show data-driven traffic simulation can be formulated as a world model. We present TrafficBots, a multi-agent policy built upon motion prediction and end-to-end driving, and based on TrafficBots we obtain a world model tailored for the planning module of autonomous vehicles. Existing data-driven traffic simulators are lacking configurability and scalability. To generate configurable behaviors, for each agent we introduce a destination as navigational information, and a time-invariant latent personality that specifies the behavioral style. To improve the scalability, we present a new scheme of positional encoding for angles, allowing all agents to share the same vectorized context and the use of an architecture based on dot-product attention. As a result, we can simulate all traffic participants seen in dense urban scenarios. Experiments on the Waymo open motion dataset show TrafficBots can simulate realistic multi-agent behaviors and achieve good performance on the motion prediction task.
Gradient-Guided Knowledge Distillation for Object Detectors
Mar 07, 2023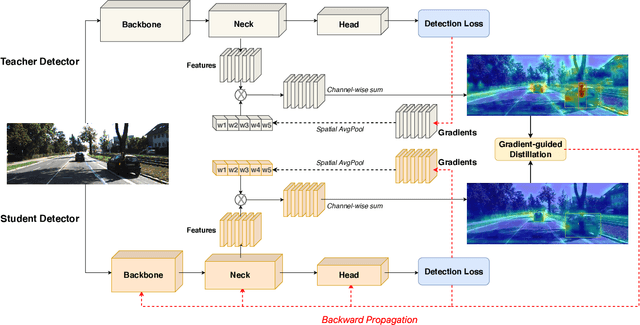
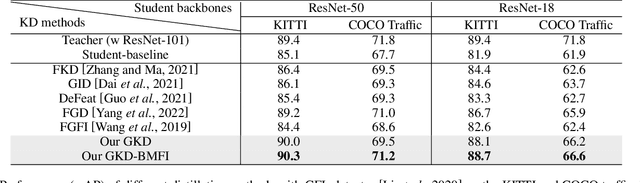

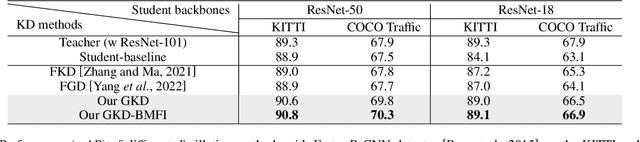
Deep learning models have demonstrated remarkable success in object detection, yet their complexity and computational intensity pose a barrier to deploying them in real-world applications (e.g., self-driving perception). Knowledge Distillation (KD) is an effective way to derive efficient models. However, only a small number of KD methods tackle object detection. Also, most of them focus on mimicking the plain features of the teacher model but rarely consider how the features contribute to the final detection. In this paper, we propose a novel approach for knowledge distillation in object detection, named Gradient-guided Knowledge Distillation (GKD). Our GKD uses gradient information to identify and assign more weights to features that significantly impact the detection loss, allowing the student to learn the most relevant features from the teacher. Furthermore, we present bounding-box-aware multi-grained feature imitation (BMFI) to further improve the KD performance. Experiments on the KITTI and COCO-Traffic datasets demonstrate our method's efficacy in knowledge distillation for object detection. On one-stage and two-stage detectors, our GKD-BMFI leads to an average of 5.1% and 3.8% mAP improvement, respectively, beating various state-of-the-art KD methods.
Robotic Applications of Pre-Trained Vision-Language Models to Various Recognition Behaviors
Mar 10, 2023
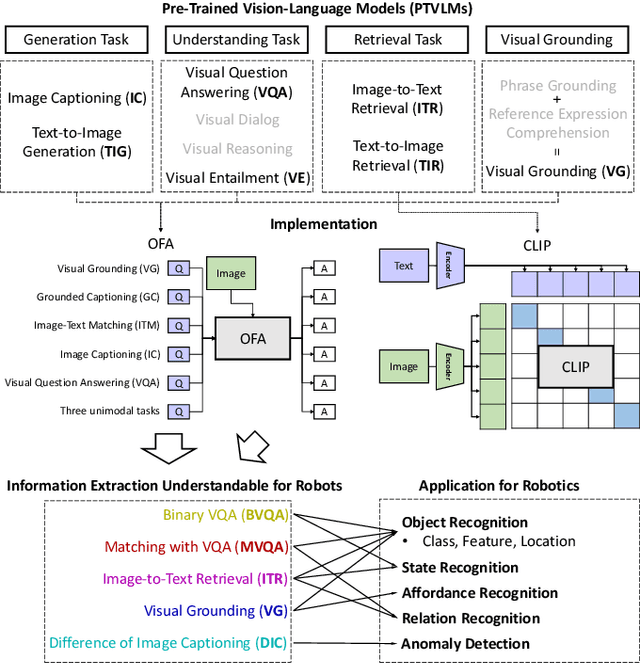
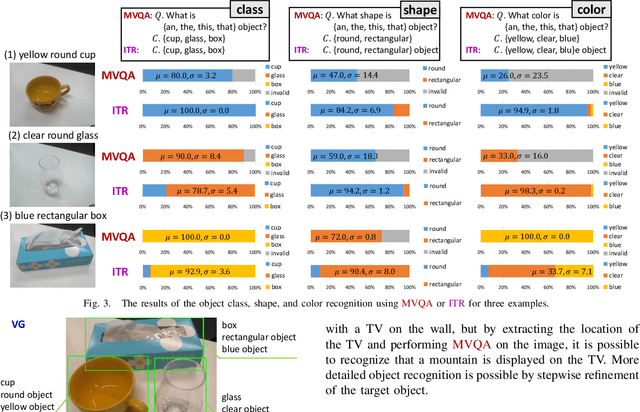

In recent years, a number of models that learn the relations between vision and language from large datasets have been released. These models perform a variety of tasks, such as answering questions about images, retrieving sentences that best correspond to images, and finding regions in images that correspond to phrases. Although there are some examples, the connection between these pre-trained vision-language models and robotics is still weak. If they are directly connected to robot motions, they lose their versatility due to the embodiment of the robot and the difficulty of data collection, and become inapplicable to a wide range of bodies and situations. Therefore, in this study, we categorize and summarize the methods to utilize the pre-trained vision-language models flexibly and easily in a way that the robot can understand, without directly connecting them to robot motions. We discuss how to use these models for robot motion selection and motion planning without re-training the models. We consider five types of methods to extract information understandable for robots, and show the results of state recognition, object recognition, affordance recognition, relation recognition, and anomaly detection based on the combination of these five methods. We expect that this study will add flexibility and ease-of-use, as well as new applications, to the recognition behavior of existing robots.
Material Identification From Radiographs Without Energy Resolution
Mar 10, 2023
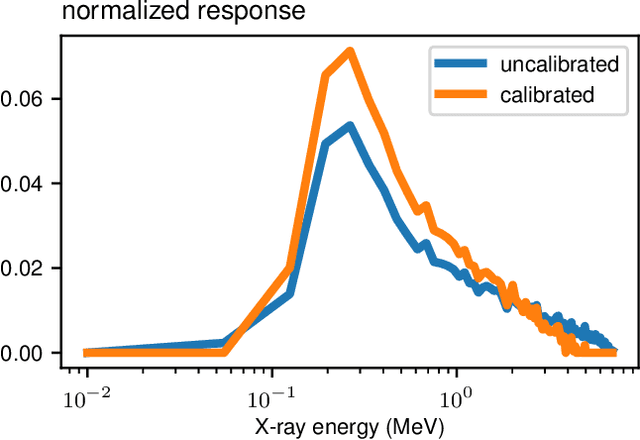
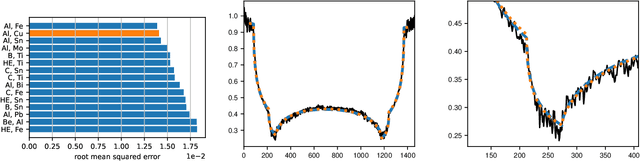
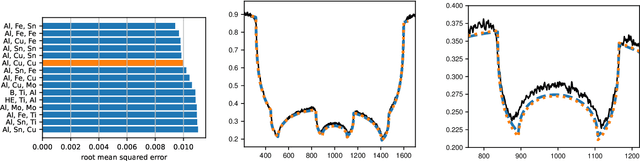
We propose a method for performing material identification from radiographs without energy-resolved measurements. Material identification has a wide variety of applications, including in biomedical imaging, nondestructive testing, and security. While existing techniques for radiographic material identification make use of dual energy sources, energy-resolving detectors, or additional (e.g., neutron) measurements, such setups are not always practical-requiring additional hardware and complicating imaging. We tackle material identification without energy resolution, allowing standard X-ray systems to provide material identification information without requiring additional hardware. Assuming a setting where the geometry of each object in the scene is known and the materials come from a known set of possible materials, we pose the problem as a combinatorial optimization with a loss function that accounts for the presence of scatter and an unknown gain and propose a branch and bound algorithm to efficiently solve it. We present experiments on both synthetic data and real, experimental data with relevance to security applications-thick, dense objects imaged with MeV X-rays. We show that material identification can be efficient and accurate, for example, in a scene with three shells (two copper, one aluminum), our algorithm ran in six minutes on a consumer-level laptop and identified the correct materials as being among the top 10 best matches out of 8,000 possibilities.
Human-Centric Multimodal Machine Learning: Recent Advances and Testbed on AI-based Recruitment
Feb 13, 2023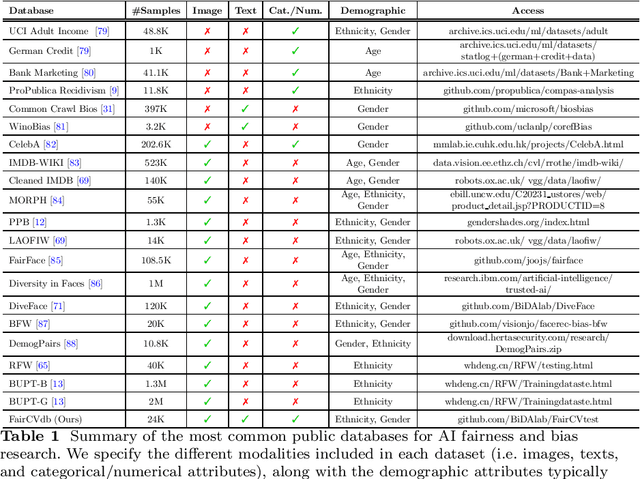
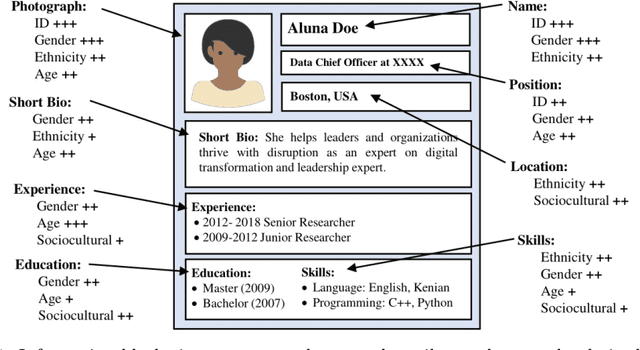
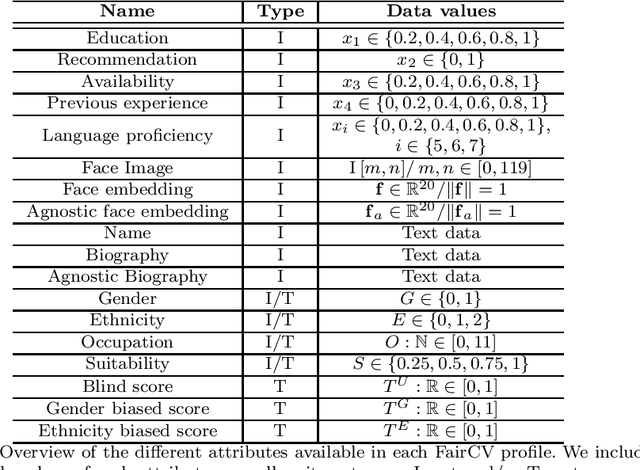

The presence of decision-making algorithms in society is rapidly increasing nowadays, while concerns about their transparency and the possibility of these algorithms becoming new sources of discrimination are arising. There is a certain consensus about the need to develop AI applications with a Human-Centric approach. Human-Centric Machine Learning needs to be developed based on four main requirements: (i) utility and social good; (ii) privacy and data ownership; (iii) transparency and accountability; and (iv) fairness in AI-driven decision-making processes. All these four Human-Centric requirements are closely related to each other. With the aim of studying how current multimodal algorithms based on heterogeneous sources of information are affected by sensitive elements and inner biases in the data, we propose a fictitious case study focused on automated recruitment: FairCVtest. We train automatic recruitment algorithms using a set of multimodal synthetic profiles including image, text, and structured data, which are consciously scored with gender and racial biases. FairCVtest shows the capacity of the Artificial Intelligence (AI) behind automatic recruitment tools built this way (a common practice in many other application scenarios beyond recruitment) to extract sensitive information from unstructured data and exploit it in combination to data biases in undesirable (unfair) ways. We present an overview of recent works developing techniques capable of removing sensitive information and biases from the decision-making process of deep learning architectures, as well as commonly used databases for fairness research in AI. We demonstrate how learning approaches developed to guarantee privacy in latent spaces can lead to unbiased and fair automatic decision-making process.
Inseq: An Interpretability Toolkit for Sequence Generation Models
Feb 27, 2023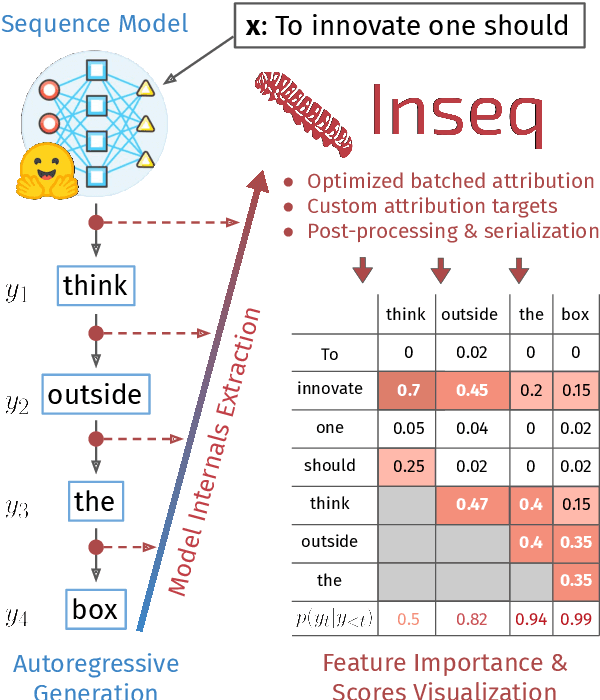
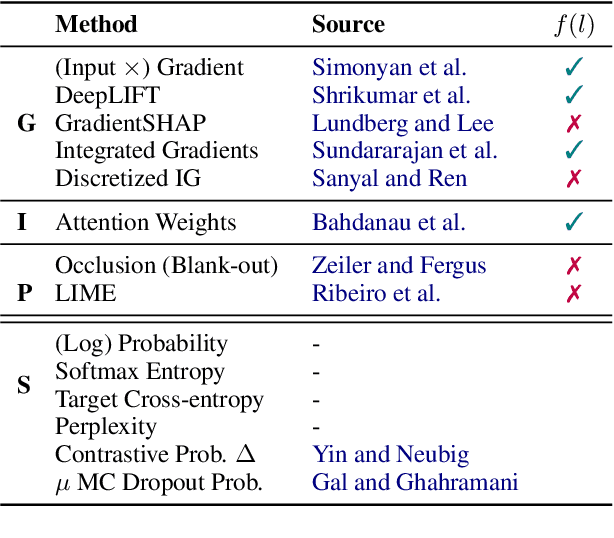
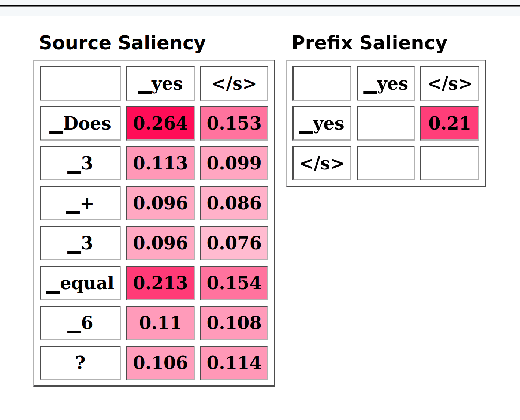
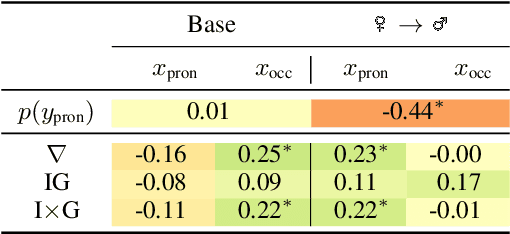
Past work in natural language processing interpretability focused mainly on popular classification tasks while largely overlooking generation settings, partly due to a lack of dedicated tools. In this work, we introduce Inseq, a Python library to democratize access to interpretability analyses of sequence generation models. Inseq enables intuitive and optimized extraction of models' internal information and feature importance scores for popular decoder-only and encoder-decoder Transformers architectures. We showcase its potential by adopting it to highlight gender biases in machine translation models and locate factual knowledge inside GPT-2. Thanks to its extensible interface supporting cutting-edge techniques such as contrastive feature attribution, Inseq can drive future advances in explainable natural language generation, centralizing good practices and enabling fair and reproducible model evaluations.
On Differentially Private Online Predictions
Feb 27, 2023In this work we introduce an interactive variant of joint differential privacy towards handling online processes in which existing privacy definitions seem too restrictive. We study basic properties of this definition and demonstrate that it satisfies (suitable variants) of group privacy, composition, and post processing. We then study the cost of interactive joint privacy in the basic setting of online classification. We show that any (possibly non-private) learning rule can be effectively transformed to a private learning rule with only a polynomial overhead in the mistake bound. This demonstrates a stark difference with more restrictive notions of privacy such as the one studied by Golowich and Livni (2021), where only a double exponential overhead on the mistake bound is known (via an information theoretic upper bound).
Finetuning Pretrained Vision-Language Models with Correlation Information Bottleneck for Robust Visual Question Answering
Sep 14, 2022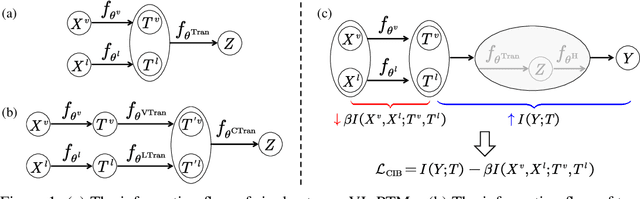
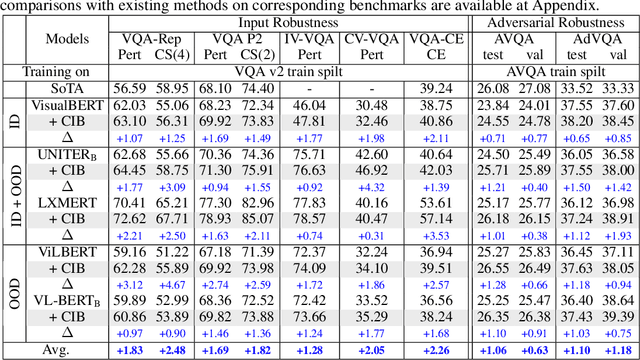
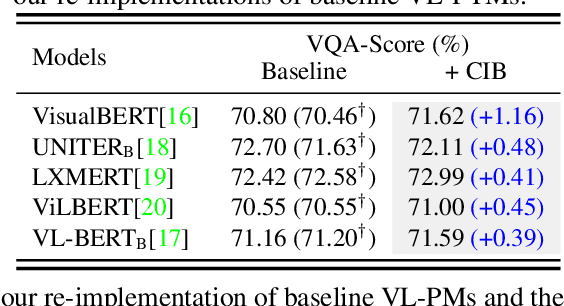

Benefiting from large-scale Pretrained Vision-Language Models (VL-PMs), the performance of Visual Question Answering (VQA) has started to approach human oracle performance. However, finetuning large-scale VL-PMs with limited data for VQA usually faces overfitting and poor generalization issues, leading to a lack of robustness. In this paper, we aim to improve the robustness of VQA systems (ie, the ability of the systems to defend against input variations and human-adversarial attacks) from the perspective of Information Bottleneck when finetuning VL-PMs for VQA. Generally, internal representations obtained by VL-PMs inevitably contain irrelevant and redundant information for the downstream VQA task, resulting in statistically spurious correlations and insensitivity to input variations. To encourage representations to converge to a minimal sufficient statistic in vision-language learning, we propose the Correlation Information Bottleneck (CIB) principle, which seeks a tradeoff between representation compression and redundancy by minimizing the mutual information (MI) between the inputs and internal representations while maximizing the MI between the outputs and the representations. Meanwhile, CIB measures the internal correlations among visual and linguistic inputs and representations by a symmetrized joint MI estimation. Extensive experiments on five VQA benchmarks of input robustness and two VQA benchmarks of human-adversarial robustness demonstrate the effectiveness and superiority of the proposed CIB in improving the robustness of VQA systems.
Time Associated Meta Learning for Clinical Prediction
Mar 05, 2023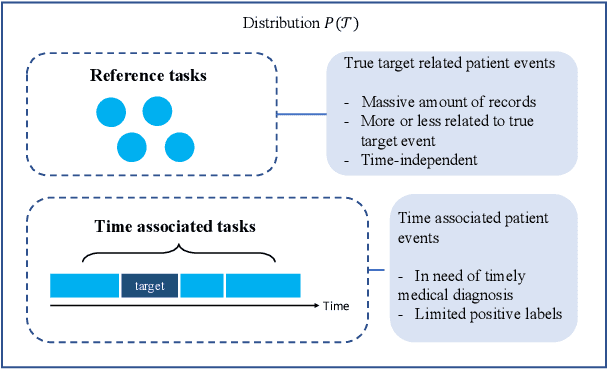
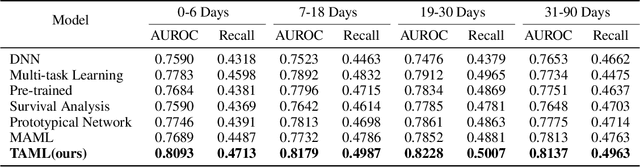
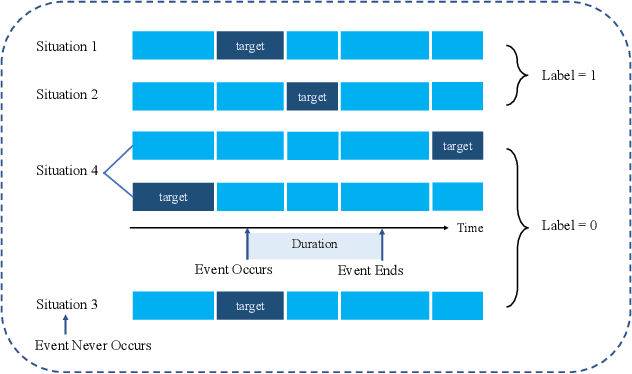
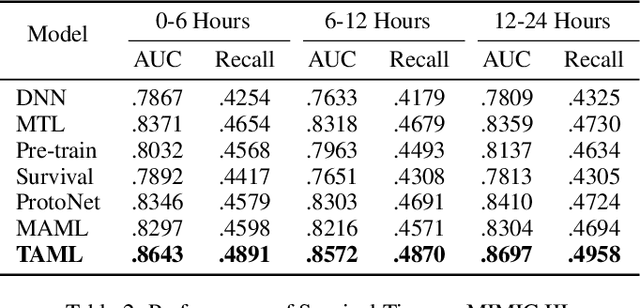
Rich Electronic Health Records (EHR), have created opportunities to improve clinical processes using machine learning methods. Prediction of the same patient events at different time horizons can have very different applications and interpretations; however, limited number of events in each potential time window hurts the effectiveness of conventional machine learning algorithms. We propose a novel time associated meta learning (TAML) method to make effective predictions at multiple future time points. We view time-associated disease prediction as classification tasks at multiple time points. Such closely-related classification tasks are an excellent candidate for model-based meta learning. To address the sparsity problem after task splitting, TAML employs a temporal information sharing strategy to augment the number of positive samples and include the prediction of related phenotypes or events in the meta-training phase. We demonstrate the effectiveness of TAML on multiple clinical datasets, where it consistently outperforms a range of strong baselines. We also develop a MetaEHR package for implementing both time-associated and time-independent few-shot prediction on EHR data.