 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Planning with Large Language Models for Code Generation
Mar 09, 2023

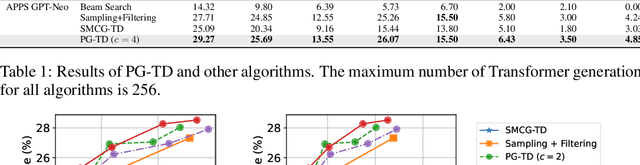
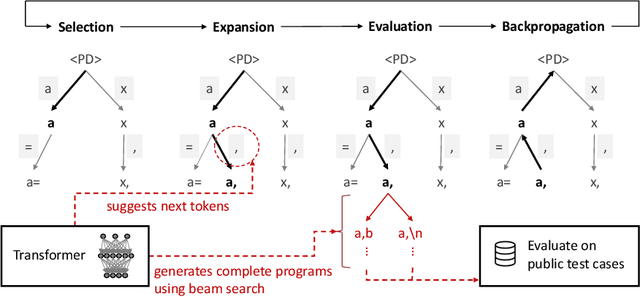
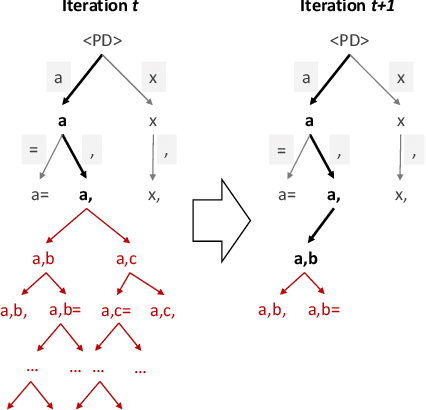
Existing large language model-based code generation pipelines typically use beam search or sampling algorithms during the decoding process. Although the programs they generate achieve high token-matching-based scores, they often fail to compile or generate incorrect outputs. The main reason is that conventional Transformer decoding algorithms may not be the best choice for code generation. In this work, we propose a novel Transformer decoding algorithm, Planning-Guided Transformer Decoding (PG-TD), that uses a planning algorithm to do lookahead search and guide the Transformer to generate better programs. Specifically, instead of simply optimizing the likelihood of the generated sequences, the Transformer makes use of a planner to generate candidate programs and test them on public test cases. The Transformer can therefore make more informed decisions and generate tokens that will eventually lead to higher-quality programs. We also design a mechanism that shares information between the Transformer and the planner to make our algorithm computationally efficient. We empirically evaluate our framework with several large language models as backbones on public coding challenge benchmarks, showing that 1) it can generate programs that consistently achieve higher performance compared with competing baseline methods; 2) it enables controllable code generation, such as concise codes and highly-commented codes by optimizing modified objective.
Human-Centric Multimodal Machine Learning: Recent Advances and Testbed on AI-based Recruitment
Feb 13, 2023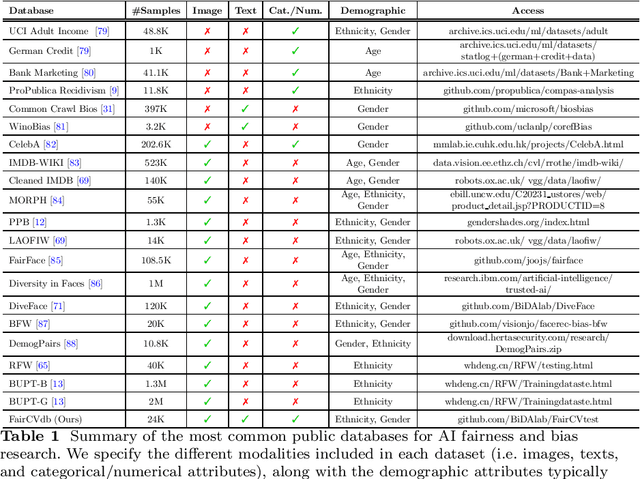
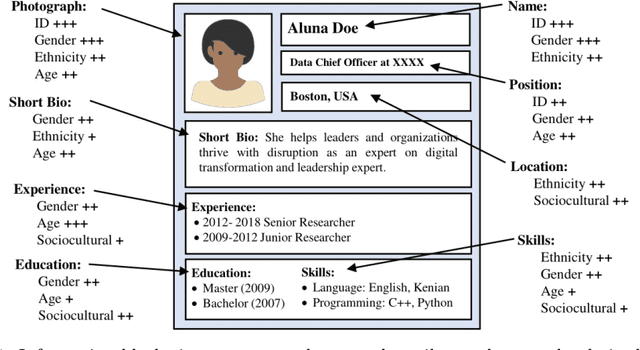
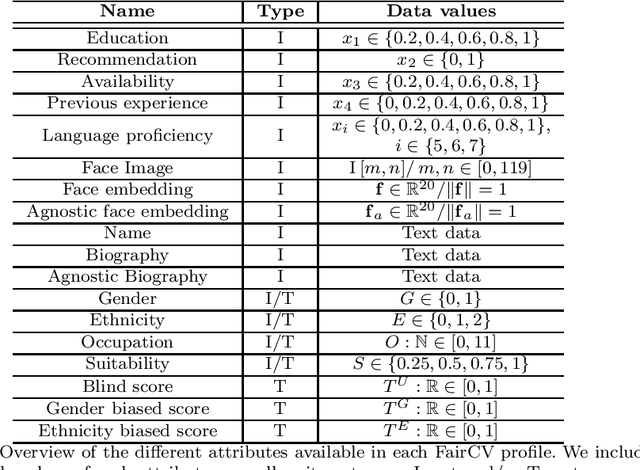

The presence of decision-making algorithms in society is rapidly increasing nowadays, while concerns about their transparency and the possibility of these algorithms becoming new sources of discrimination are arising. There is a certain consensus about the need to develop AI applications with a Human-Centric approach. Human-Centric Machine Learning needs to be developed based on four main requirements: (i) utility and social good; (ii) privacy and data ownership; (iii) transparency and accountability; and (iv) fairness in AI-driven decision-making processes. All these four Human-Centric requirements are closely related to each other. With the aim of studying how current multimodal algorithms based on heterogeneous sources of information are affected by sensitive elements and inner biases in the data, we propose a fictitious case study focused on automated recruitment: FairCVtest. We train automatic recruitment algorithms using a set of multimodal synthetic profiles including image, text, and structured data, which are consciously scored with gender and racial biases. FairCVtest shows the capacity of the Artificial Intelligence (AI) behind automatic recruitment tools built this way (a common practice in many other application scenarios beyond recruitment) to extract sensitive information from unstructured data and exploit it in combination to data biases in undesirable (unfair) ways. We present an overview of recent works developing techniques capable of removing sensitive information and biases from the decision-making process of deep learning architectures, as well as commonly used databases for fairness research in AI. We demonstrate how learning approaches developed to guarantee privacy in latent spaces can lead to unbiased and fair automatic decision-making process.
Puppeteer and Marionette: Learning Anticipatory Quadrupedal Locomotion Based on Interactions of a Central Pattern Generator and Supraspinal Drive
Feb 26, 2023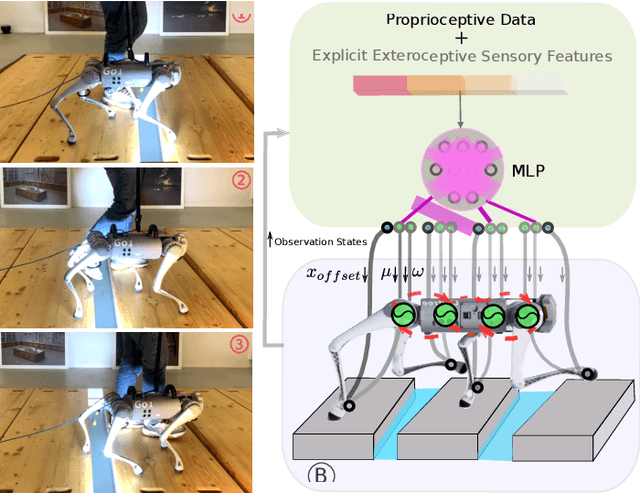
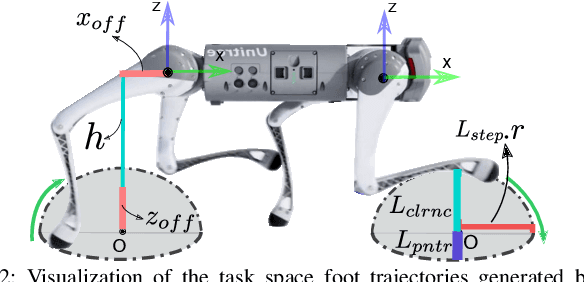
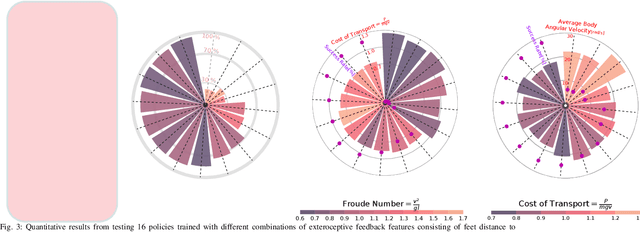
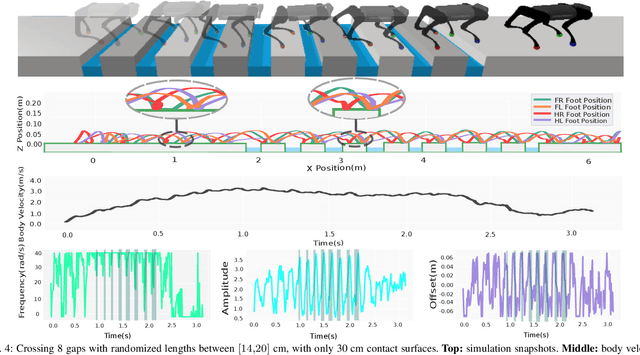
Quadruped animal locomotion emerges from the interactions between the spinal central pattern generator (CPG), sensory feedback, and supraspinal drive signals from the brain. Computational models of CPGs have been widely used for investigating the spinal cord contribution to animal locomotion control in computational neuroscience and in bio-inspired robotics. However, the contribution of supraspinal drive to anticipatory behavior, i.e. motor behavior that involves planning ahead of time (e.g. of footstep placements), is not yet properly understood. In particular, it is not clear whether the brain modulates CPG activity and/or directly modulates muscle activity (hence bypassing the CPG) for accurate foot placements. In this paper, we investigate the interaction of supraspinal drive and a CPG in an anticipatory locomotion scenario that involves stepping over gaps. By employing deep reinforcement learning (DRL), we train a neural network policy that replicates the supraspinal drive behavior. This policy can either modulate the CPG dynamics, or directly change actuation signals to bypass the CPG dynamics. Our results indicate that the direct supraspinal contribution to the actuation signal is a key component for a high gap crossing success rate. However, the CPG dynamics in the spinal cord are beneficial for gait smoothness and energy efficiency. Moreover, our investigation shows that sensing the front feet distances to the gap is the most important and sufficient sensory information for learning gap crossing. Our results support the biological hypothesis that cats and horses mainly control the front legs for obstacle avoidance, and that hind limbs follow an internal memory based on the front limbs' information. Our method enables the quadruped robot to cross gaps of up to 20 cm (50% of body-length) without any explicit dynamics modeling or Model Predictive Control (MPC).
Automated Vulnerability Detection in Source Code Using Quantum Natural Language Processing
Mar 13, 2023One of the most important challenges in the field of software code audit is the presence of vulnerabilities in software source code. These flaws are highly likely ex-ploited and lead to system compromise, data leakage, or denial of ser-vice. C and C++ open source code are now available in order to create a large-scale, classical machine-learning and quantum machine-learning system for function-level vulnerability identification. We assembled a siz-able dataset of millions of open-source functions that point to poten-tial exploits. We created an efficient and scalable vulnerability detection method based on a deep neural network model Long Short Term Memory (LSTM), and quantum machine learning model Long Short Term Memory (QLSTM), that can learn features extracted from the source codes. The source code is first converted into a minimal intermediate representation to remove the pointless components and shorten the de-pendency. Therefore, We keep the semantic and syntactic information using state of the art word embedding algorithms such as Glove and fastText. The embedded vectors are subsequently fed into the classical and quantum convolutional neural networks to classify the possible vulnerabilities. To measure the performance, we used evaluation metrics such as F1 score, precision, re-call, accuracy, and total execution time. We made a comparison between the results derived from the classical LSTM and quantum LSTM using basic feature representation as well as semantic and syntactic represen-tation. We found that the QLSTM with semantic and syntactic features detects significantly accurate vulnerability and runs faster than its classical counterpart.
SelfPromer: Self-Prompt Dehazing Transformers with Depth-Consistency
Mar 13, 2023

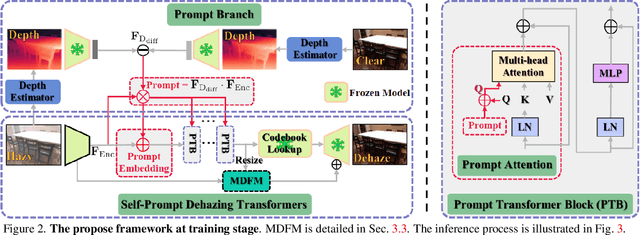
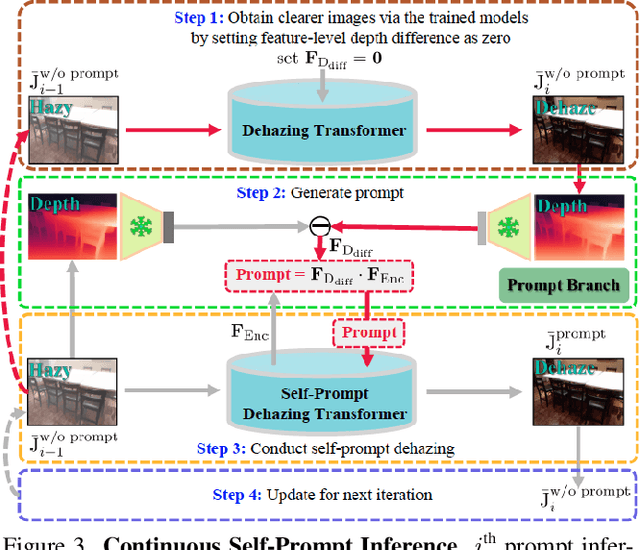
This work presents an effective depth-consistency self-prompt Transformer for image dehazing. It is motivated by an observation that the estimated depths of an image with haze residuals and its clear counterpart vary. Enforcing the depth consistency of dehazed images with clear ones, therefore, is essential for dehazing. For this purpose, we develop a prompt based on the features of depth differences between the hazy input images and corresponding clear counterparts that can guide dehazing models for better restoration. Specifically, we first apply deep features extracted from the input images to the depth difference features for generating the prompt that contains the haze residual information in the input. Then we propose a prompt embedding module that is designed to perceive the haze residuals, by linearly adding the prompt to the deep features. Further, we develop an effective prompt attention module to pay more attention to haze residuals for better removal. By incorporating the prompt, prompt embedding, and prompt attention into an encoder-decoder network based on VQGAN, we can achieve better perception quality. As the depths of clear images are not available at inference, and the dehazed images with one-time feed-forward execution may still contain a portion of haze residuals, we propose a new continuous self-prompt inference that can iteratively correct the dehazing model towards better haze-free image generation. Extensive experiments show that our method performs favorably against the state-of-the-art approaches on both synthetic and real-world datasets in terms of perception metrics including NIQE, PI, and PIQE.
Cross-device Federated Learning for Mobile Health Diagnostics: A First Study on COVID-19 Detection
Mar 13, 2023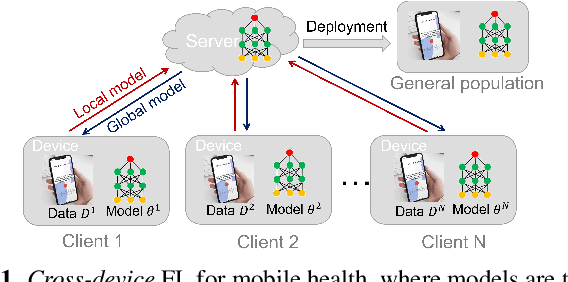
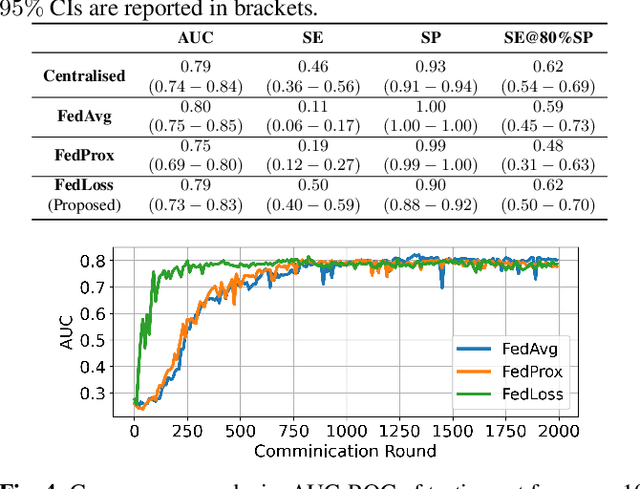
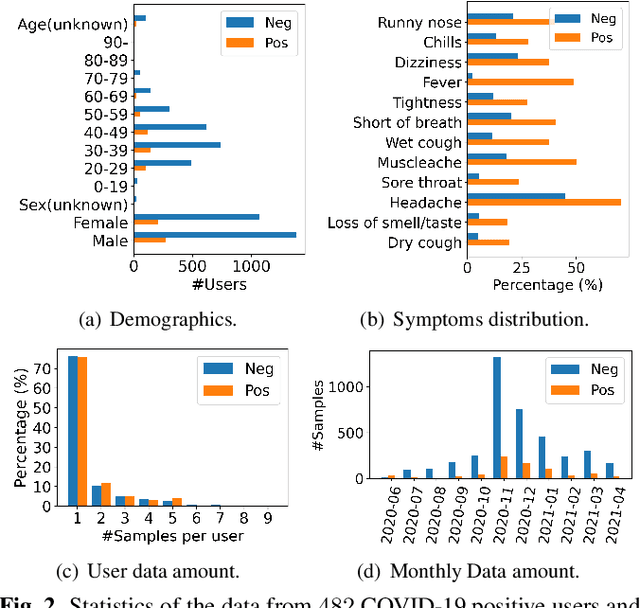
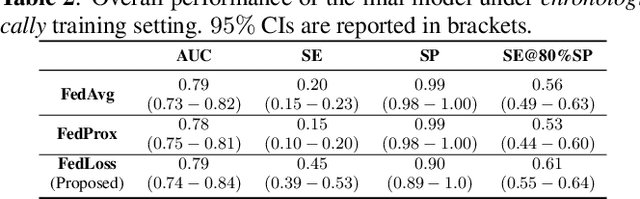
Federated learning (FL) aided health diagnostic models can incorporate data from a large number of personal edge devices (e.g., mobile phones) while keeping the data local to the originating devices, largely ensuring privacy. However, such a cross-device FL approach for health diagnostics still imposes many challenges due to both local data imbalance (as extreme as local data consists of a single disease class) and global data imbalance (the disease prevalence is generally low in a population). Since the federated server has no access to data distribution information, it is not trivial to solve the imbalance issue towards an unbiased model. In this paper, we propose FedLoss, a novel cross-device FL framework for health diagnostics. Here the federated server averages the models trained on edge devices according to the predictive loss on the local data, rather than using only the number of samples as weights. As the predictive loss better quantifies the data distribution at a device, FedLoss alleviates the impact of data imbalance. Through a real-world dataset on respiratory sound and symptom-based COVID-$19$ detection task, we validate the superiority of FedLoss. It achieves competitive COVID-$19$ detection performance compared to a centralised model with an AUC-ROC of $79\%$. It also outperforms the state-of-the-art FL baselines in sensitivity and convergence speed. Our work not only demonstrates the promise of federated COVID-$19$ detection but also paves the way to a plethora of mobile health model development in a privacy-preserving fashion.
A new methodology to predict the oncotype scores based on clinico-pathological data with similar tumor profiles
Mar 13, 2023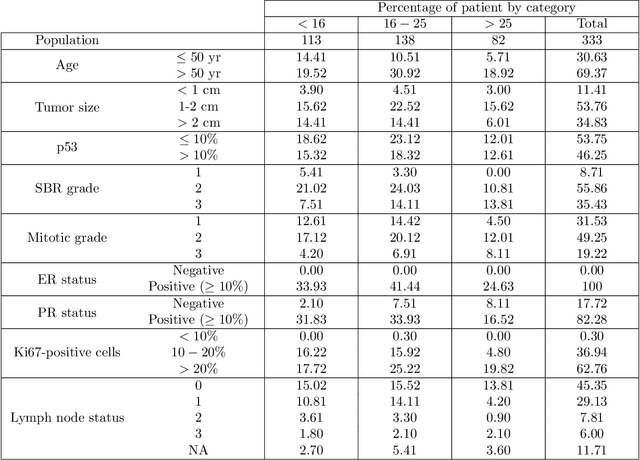
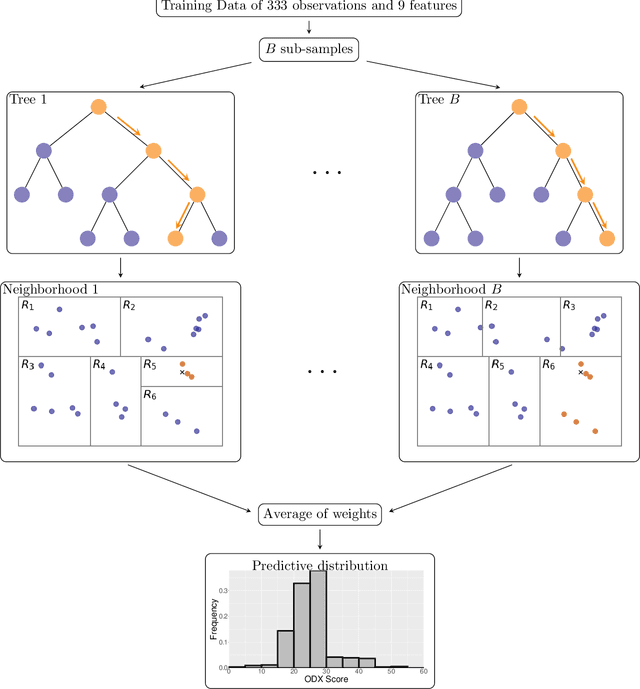
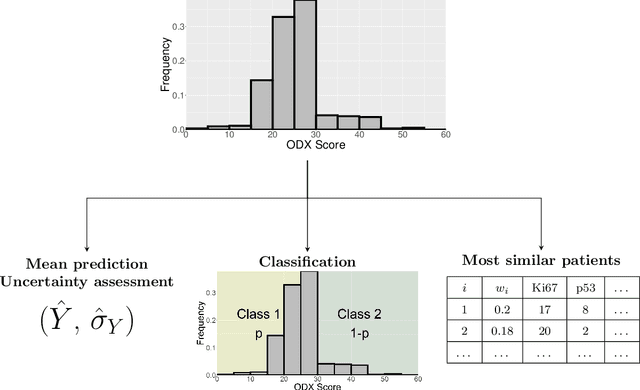

Introduction: The Oncotype DX (ODX) test is a commercially available molecular test for breast cancer assay that provides prognostic and predictive breast cancer recurrence information for hormone positive, HER2-negative patients. The aim of this study is to propose a novel methodology to assist physicians in their decision-making. Methods: A retrospective study between 2012 and 2020 with 333 cases that underwent an ODX assay from three hospitals in Bourgogne Franche-Comt{\'e} was conducted. Clinical and pathological reports were used to collect the data. A methodology based on distributional random forest was developed using 9 clinico-pathological characteristics. This methodology can be used particularly to identify the patients of the training cohort that share similarities with the new patient and to predict an estimate of the distribution of the ODX score. Results: The mean age of participants id 56.9 years old. We have correctly classified 92% of patients in low risk and 40.2% of patients in high risk. The overall accuracy is 79.3%. The proportion of low risk correct predicted value (PPV) is 82%. The percentage of high risk correct predicted value (NPV) is approximately 62.3%. The F1-score and the Area Under Curve (AUC) are of 0.87 and 0.759, respectively. Conclusion: The proposed methodology makes it possible to predict the distribution of the ODX score for a patient and provides an explanation of the predicted score. The use of the methodology with the pathologist's expertise on the different histological and immunohistochemical characteristics has a clinical impact to help oncologist in decision-making regarding breast cancer therapy.
Adaptive Data-Free Quantization
Mar 13, 2023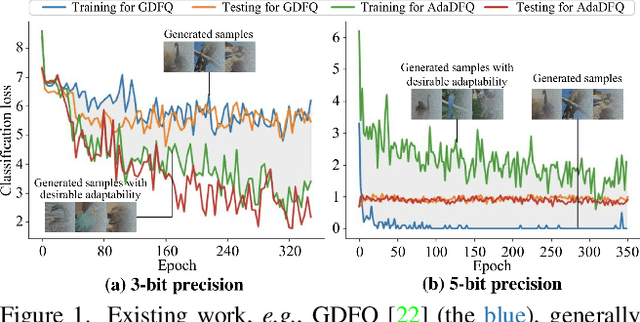
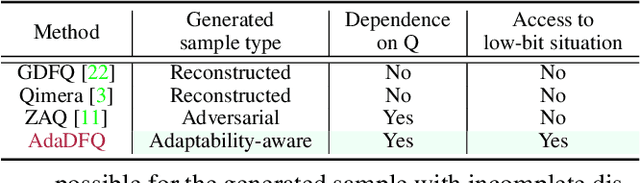
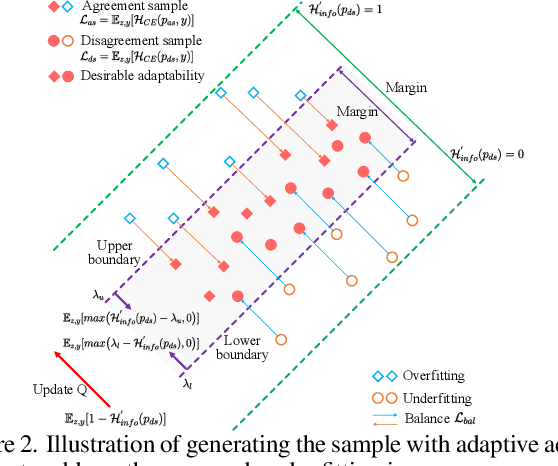
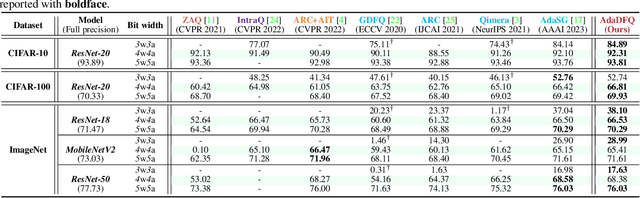
Data-free quantization (DFQ) recovers the performance of quantized network (Q) without accessing the real data, but generates the fake sample via a generator (G) by learning from full-precision network (P) instead. However, such sample generation process is totally independent of Q, overlooking the adaptability of the knowledge from generated samples, i.e., informative or not to the learning process of Q, resulting into the overflow of generalization error. Building on this, several critical questions -- how to measure the sample adaptability to Q under varied bit-width scenarios? how to generate the samples with large adaptability to improve Q's generalization? whether the largest adaptability is the best? To answer the above questions, in this paper, we propose an Adaptive Data-Free Quantization (AdaDFQ) method, which reformulates DFQ as a zero-sum game upon the sample adaptability between two players -- a generator and a quantized network. Following this viewpoint, we further define the disagreement and agreement samples to form two boundaries, where the margin is optimized to address the over-and-under fitting issues, so as to generate the samples with the desirable adaptability to Q. Our AdaDFQ reveals: 1) the largest adaptability is NOT the best for sample generation to benefit Q's generalization; 2) the knowledge of the generated sample should not be informative to Q only, but also related to the category and distribution information of the training data for P. The theoretical and empirical analysis validate the advantages of AdaDFQ over the state-of-the-arts. Our code is available at https: github.com/hfutqian/AdaDFQ.
Tagging before Alignment: Integrating Multi-Modal Tags for Video-Text Retrieval
Jan 30, 2023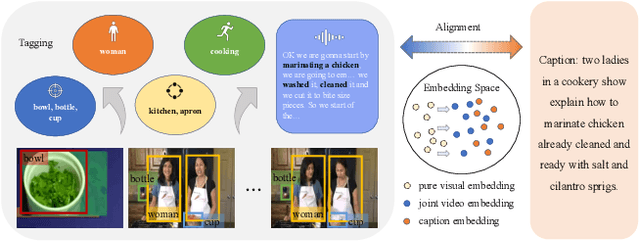
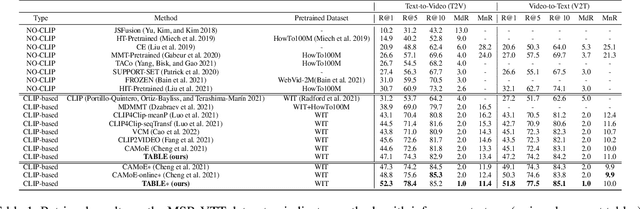
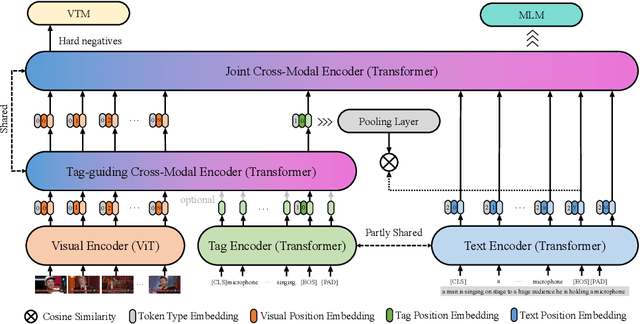
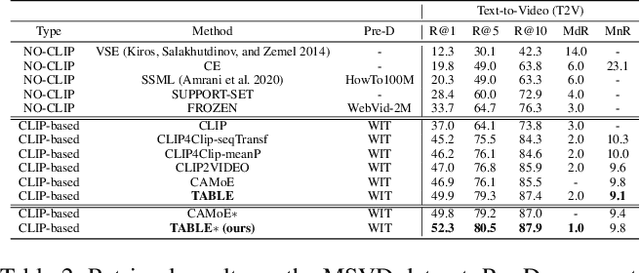
Vision-language alignment learning for video-text retrieval arouses a lot of attention in recent years. Most of the existing methods either transfer the knowledge of image-text pretraining model to video-text retrieval task without fully exploring the multi-modal information of videos, or simply fuse multi-modal features in a brute force manner without explicit guidance. In this paper, we integrate multi-modal information in an explicit manner by tagging, and use the tags as the anchors for better video-text alignment. Various pretrained experts are utilized for extracting the information of multiple modalities, including object, person, motion, audio, etc. To take full advantage of these information, we propose the TABLE (TAgging Before aLignmEnt) network, which consists of a visual encoder, a tag encoder, a text encoder, and a tag-guiding cross-modal encoder for jointly encoding multi-frame visual features and multi-modal tags information. Furthermore, to strengthen the interaction between video and text, we build a joint cross-modal encoder with the triplet input of [vision, tag, text] and perform two additional supervised tasks, Video Text Matching (VTM) and Masked Language Modeling (MLM). Extensive experimental results demonstrate that the TABLE model is capable of achieving State-Of-The-Art (SOTA) performance on various video-text retrieval benchmarks, including MSR-VTT, MSVD, LSMDC and DiDeMo.
TimeMAE: Self-Supervised Representations of Time Series with Decoupled Masked Autoencoders
Mar 14, 2023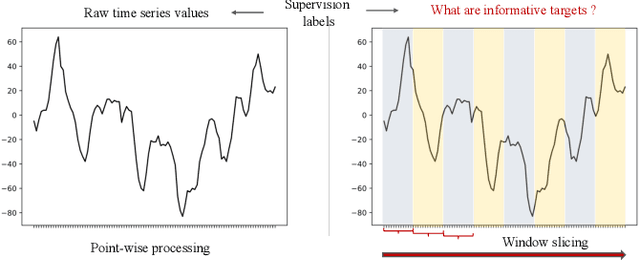

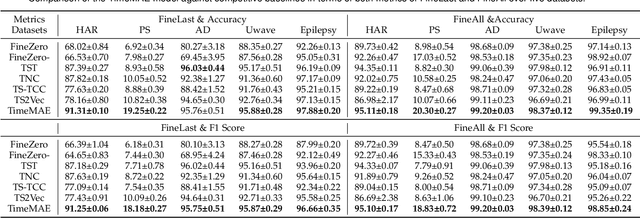
Enhancing the expressive capacity of deep learning-based time series models with self-supervised pre-training has become ever-increasingly prevalent in time series classification. Even though numerous efforts have been devoted to developing self-supervised models for time series data, we argue that the current methods are not sufficient to learn optimal time series representations due to solely unidirectional encoding over sparse point-wise input units. In this work, we propose TimeMAE, a novel self-supervised paradigm for learning transferrable time series representations based on transformer networks. The distinct characteristics of the TimeMAE lie in processing each time series into a sequence of non-overlapping sub-series via window-slicing partitioning, followed by random masking strategies over the semantic units of localized sub-series. Such a simple yet effective setting can help us achieve the goal of killing three birds with one stone, i.e., (1) learning enriched contextual representations of time series with a bidirectional encoding scheme; (2) increasing the information density of basic semantic units; (3) efficiently encoding representations of time series using transformer networks. Nevertheless, it is a non-trivial to perform reconstructing task over such a novel formulated modeling paradigm. To solve the discrepancy issue incurred by newly injected masked embeddings, we design a decoupled autoencoder architecture, which learns the representations of visible (unmasked) positions and masked ones with two different encoder modules, respectively. Furthermore, we construct two types of informative targets to accomplish the corresponding pretext tasks. One is to create a tokenizer module that assigns a codeword to each masked region, allowing the masked codeword classification (MCC) task to be completed effectively...