 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Anatomical Federated Network (Dafne): an open client/server framework for the continuous collaborative improvement of deep-learning-based medical image segmentation
Feb 14, 2023
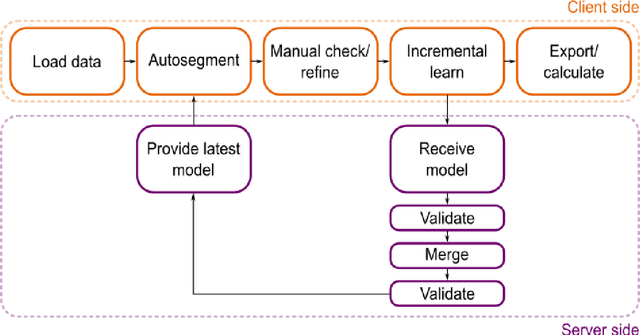
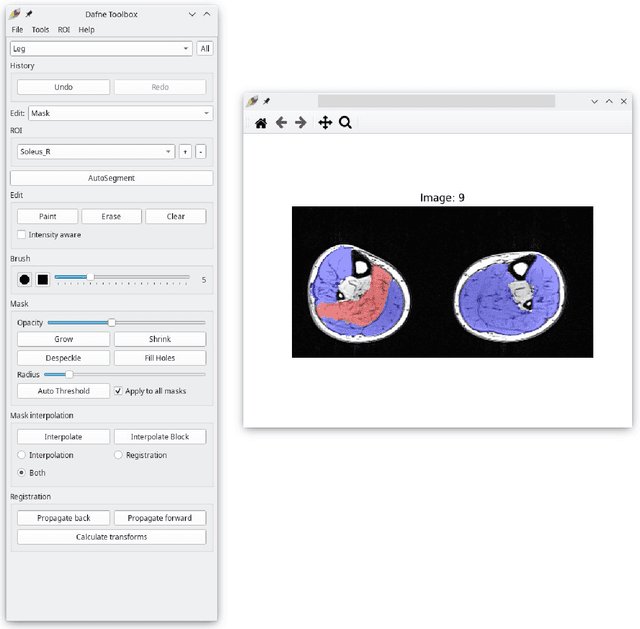
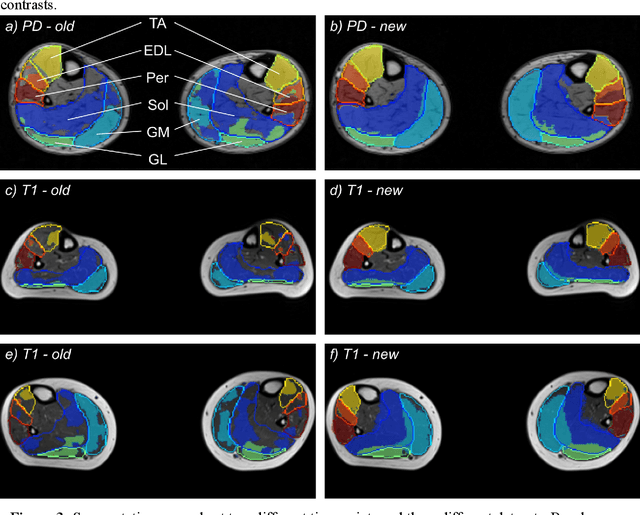
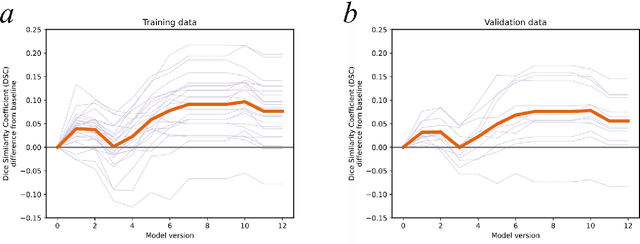
Semantic segmentation is a crucial step to extract quantitative information from medical (and, specifically, radiological) images to aid the diagnostic process, clinical follow-up. and to generate biomarkers for clinical research. In recent years, machine learning algorithms have become the primary tool for this task. However, its real-world performance is heavily reliant on the comprehensiveness of training data. Dafne is the first decentralized, collaborative solution that implements continuously evolving deep learning models exploiting the collective knowledge of the users of the system. In the Dafne workflow, the result of each automated segmentation is refined by the user through an integrated interface, so that the new information is used to continuously expand the training pool via federated incremental learning. The models deployed through Dafne are able to improve their performance over time and to generalize to data types not seen in the training sets, thus becoming a viable and practical solution for real-life medical segmentation tasks.
Automated Vulnerability Detection in Source Code Using Quantum Natural Language Processing
Mar 13, 2023One of the most important challenges in the field of software code audit is the presence of vulnerabilities in software source code. These flaws are highly likely ex-ploited and lead to system compromise, data leakage, or denial of ser-vice. C and C++ open source code are now available in order to create a large-scale, classical machine-learning and quantum machine-learning system for function-level vulnerability identification. We assembled a siz-able dataset of millions of open-source functions that point to poten-tial exploits. We created an efficient and scalable vulnerability detection method based on a deep neural network model Long Short Term Memory (LSTM), and quantum machine learning model Long Short Term Memory (QLSTM), that can learn features extracted from the source codes. The source code is first converted into a minimal intermediate representation to remove the pointless components and shorten the de-pendency. Therefore, We keep the semantic and syntactic information using state of the art word embedding algorithms such as Glove and fastText. The embedded vectors are subsequently fed into the classical and quantum convolutional neural networks to classify the possible vulnerabilities. To measure the performance, we used evaluation metrics such as F1 score, precision, re-call, accuracy, and total execution time. We made a comparison between the results derived from the classical LSTM and quantum LSTM using basic feature representation as well as semantic and syntactic represen-tation. We found that the QLSTM with semantic and syntactic features detects significantly accurate vulnerability and runs faster than its classical counterpart.
SelfPromer: Self-Prompt Dehazing Transformers with Depth-Consistency
Mar 13, 2023

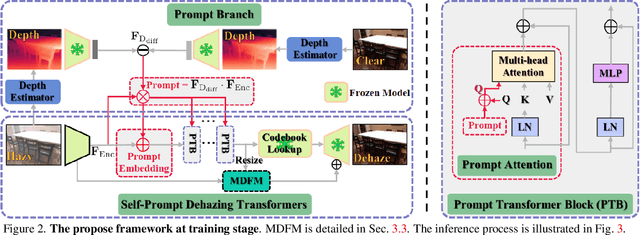
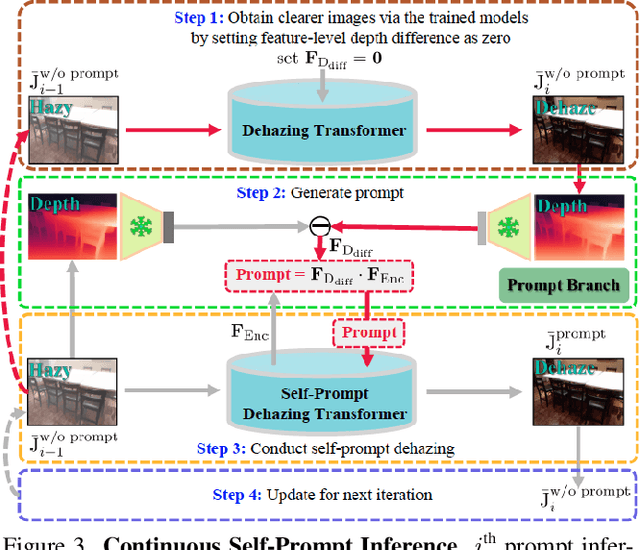
This work presents an effective depth-consistency self-prompt Transformer for image dehazing. It is motivated by an observation that the estimated depths of an image with haze residuals and its clear counterpart vary. Enforcing the depth consistency of dehazed images with clear ones, therefore, is essential for dehazing. For this purpose, we develop a prompt based on the features of depth differences between the hazy input images and corresponding clear counterparts that can guide dehazing models for better restoration. Specifically, we first apply deep features extracted from the input images to the depth difference features for generating the prompt that contains the haze residual information in the input. Then we propose a prompt embedding module that is designed to perceive the haze residuals, by linearly adding the prompt to the deep features. Further, we develop an effective prompt attention module to pay more attention to haze residuals for better removal. By incorporating the prompt, prompt embedding, and prompt attention into an encoder-decoder network based on VQGAN, we can achieve better perception quality. As the depths of clear images are not available at inference, and the dehazed images with one-time feed-forward execution may still contain a portion of haze residuals, we propose a new continuous self-prompt inference that can iteratively correct the dehazing model towards better haze-free image generation. Extensive experiments show that our method performs favorably against the state-of-the-art approaches on both synthetic and real-world datasets in terms of perception metrics including NIQE, PI, and PIQE.
Cross-device Federated Learning for Mobile Health Diagnostics: A First Study on COVID-19 Detection
Mar 13, 2023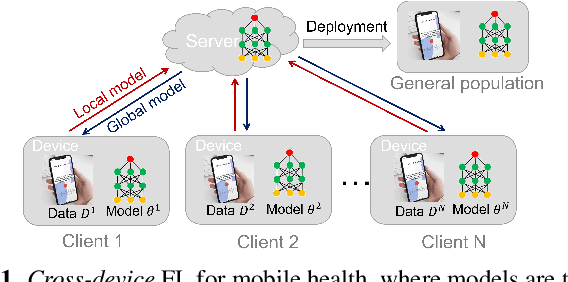
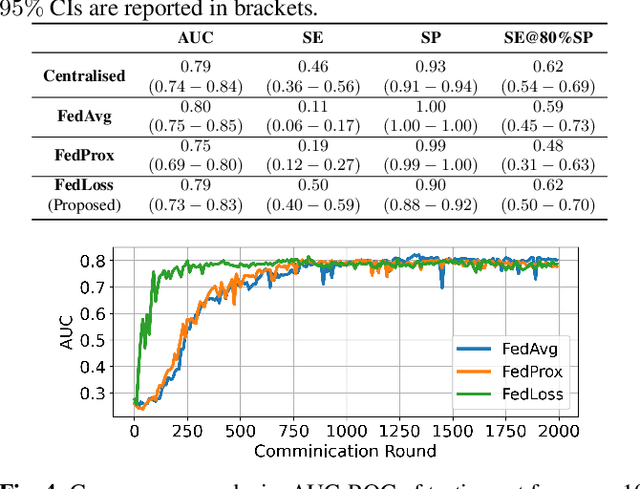
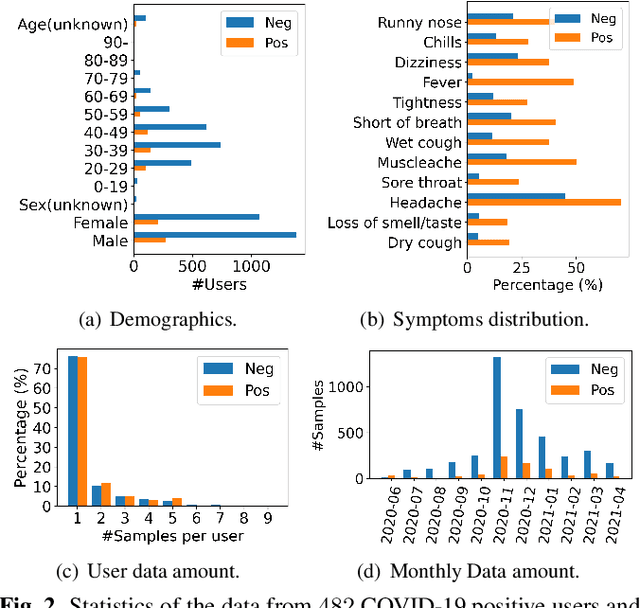
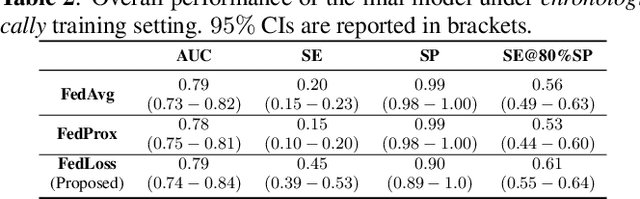
Federated learning (FL) aided health diagnostic models can incorporate data from a large number of personal edge devices (e.g., mobile phones) while keeping the data local to the originating devices, largely ensuring privacy. However, such a cross-device FL approach for health diagnostics still imposes many challenges due to both local data imbalance (as extreme as local data consists of a single disease class) and global data imbalance (the disease prevalence is generally low in a population). Since the federated server has no access to data distribution information, it is not trivial to solve the imbalance issue towards an unbiased model. In this paper, we propose FedLoss, a novel cross-device FL framework for health diagnostics. Here the federated server averages the models trained on edge devices according to the predictive loss on the local data, rather than using only the number of samples as weights. As the predictive loss better quantifies the data distribution at a device, FedLoss alleviates the impact of data imbalance. Through a real-world dataset on respiratory sound and symptom-based COVID-$19$ detection task, we validate the superiority of FedLoss. It achieves competitive COVID-$19$ detection performance compared to a centralised model with an AUC-ROC of $79\%$. It also outperforms the state-of-the-art FL baselines in sensitivity and convergence speed. Our work not only demonstrates the promise of federated COVID-$19$ detection but also paves the way to a plethora of mobile health model development in a privacy-preserving fashion.
A new methodology to predict the oncotype scores based on clinico-pathological data with similar tumor profiles
Mar 13, 2023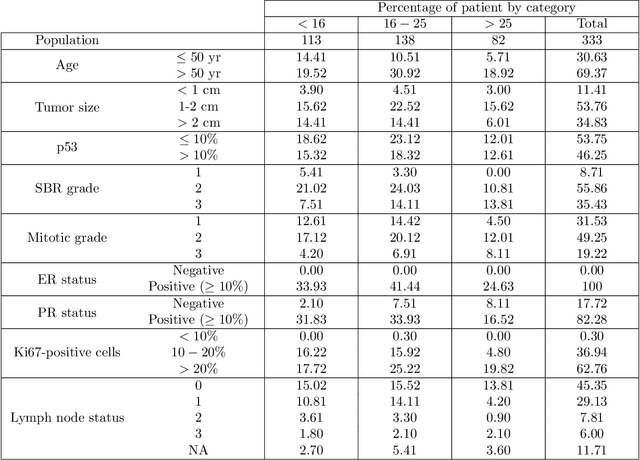
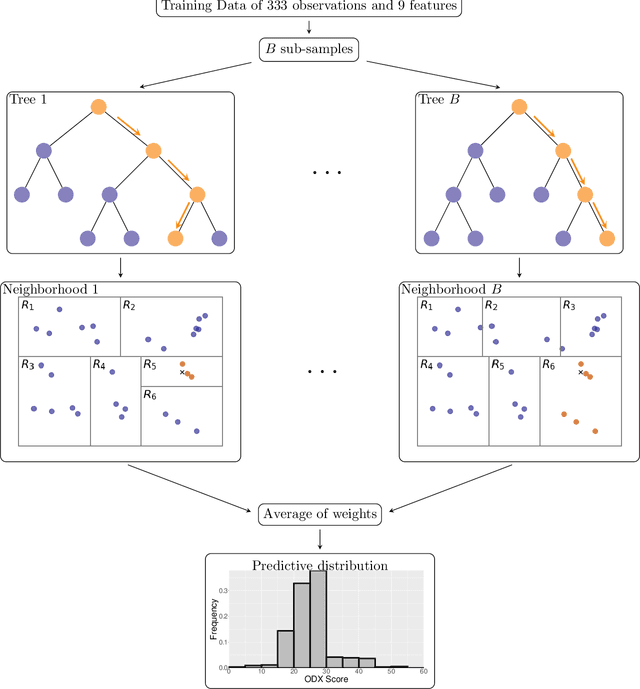
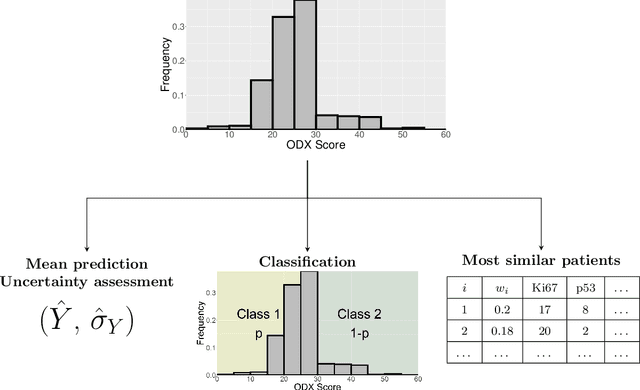

Introduction: The Oncotype DX (ODX) test is a commercially available molecular test for breast cancer assay that provides prognostic and predictive breast cancer recurrence information for hormone positive, HER2-negative patients. The aim of this study is to propose a novel methodology to assist physicians in their decision-making. Methods: A retrospective study between 2012 and 2020 with 333 cases that underwent an ODX assay from three hospitals in Bourgogne Franche-Comt{\'e} was conducted. Clinical and pathological reports were used to collect the data. A methodology based on distributional random forest was developed using 9 clinico-pathological characteristics. This methodology can be used particularly to identify the patients of the training cohort that share similarities with the new patient and to predict an estimate of the distribution of the ODX score. Results: The mean age of participants id 56.9 years old. We have correctly classified 92% of patients in low risk and 40.2% of patients in high risk. The overall accuracy is 79.3%. The proportion of low risk correct predicted value (PPV) is 82%. The percentage of high risk correct predicted value (NPV) is approximately 62.3%. The F1-score and the Area Under Curve (AUC) are of 0.87 and 0.759, respectively. Conclusion: The proposed methodology makes it possible to predict the distribution of the ODX score for a patient and provides an explanation of the predicted score. The use of the methodology with the pathologist's expertise on the different histological and immunohistochemical characteristics has a clinical impact to help oncologist in decision-making regarding breast cancer therapy.
Adaptive Data-Free Quantization
Mar 13, 2023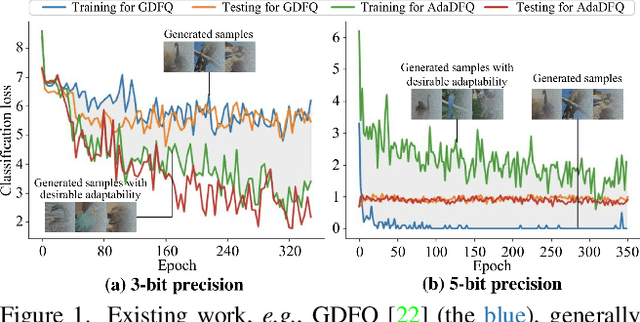
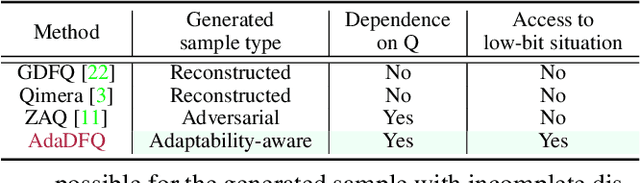
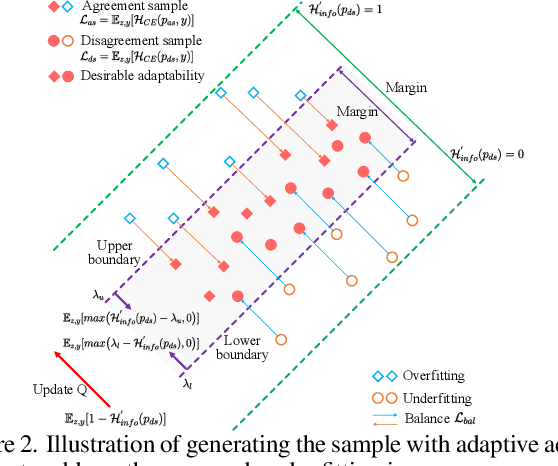
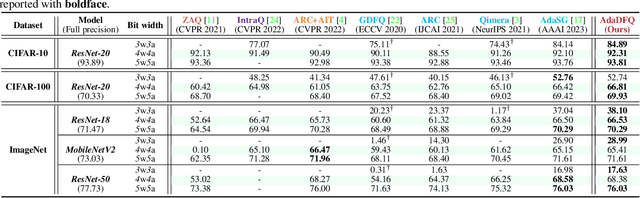
Data-free quantization (DFQ) recovers the performance of quantized network (Q) without accessing the real data, but generates the fake sample via a generator (G) by learning from full-precision network (P) instead. However, such sample generation process is totally independent of Q, overlooking the adaptability of the knowledge from generated samples, i.e., informative or not to the learning process of Q, resulting into the overflow of generalization error. Building on this, several critical questions -- how to measure the sample adaptability to Q under varied bit-width scenarios? how to generate the samples with large adaptability to improve Q's generalization? whether the largest adaptability is the best? To answer the above questions, in this paper, we propose an Adaptive Data-Free Quantization (AdaDFQ) method, which reformulates DFQ as a zero-sum game upon the sample adaptability between two players -- a generator and a quantized network. Following this viewpoint, we further define the disagreement and agreement samples to form two boundaries, where the margin is optimized to address the over-and-under fitting issues, so as to generate the samples with the desirable adaptability to Q. Our AdaDFQ reveals: 1) the largest adaptability is NOT the best for sample generation to benefit Q's generalization; 2) the knowledge of the generated sample should not be informative to Q only, but also related to the category and distribution information of the training data for P. The theoretical and empirical analysis validate the advantages of AdaDFQ over the state-of-the-arts. Our code is available at https: github.com/hfutqian/AdaDFQ.
Relatedly: Scaffolding Literature Reviews with Existing Related Work Sections
Feb 13, 2023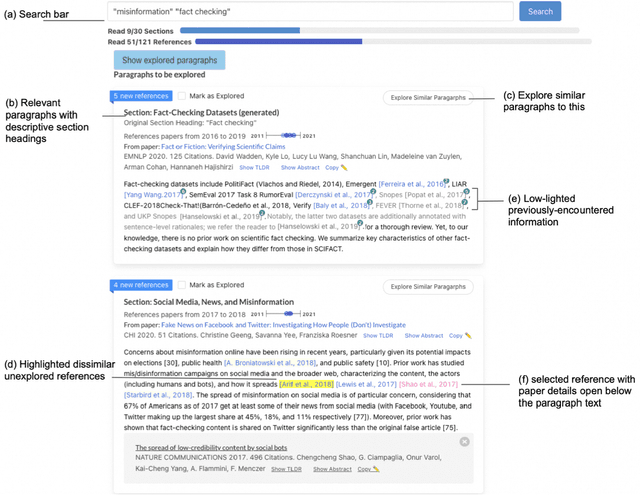

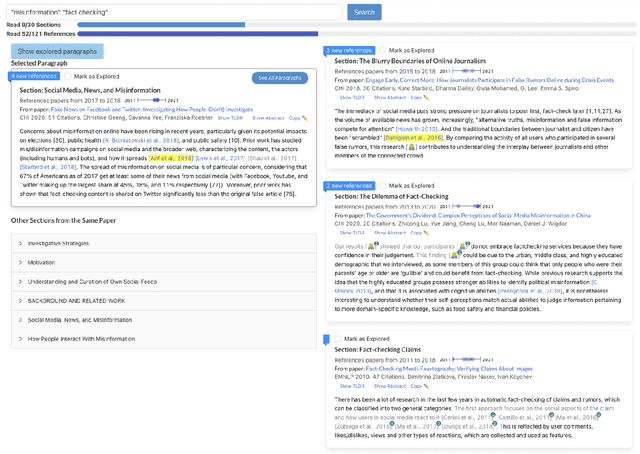
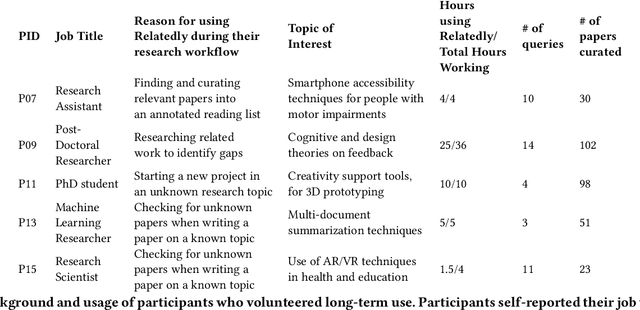
Scholars who want to research a scientific topic must take time to read, extract meaning, and identify connections across many papers. As scientific literature grows, this becomes increasingly challenging. Meanwhile, authors summarize prior research in papers' related work sections, though this is scoped to support a single paper. A formative study found that while reading multiple related work paragraphs helps overview a topic, it is hard to navigate overlapping and diverging references and research foci. In this work, we design a system, Relatedly, that scaffolds exploring and reading multiple related work paragraphs on a topic, with features including dynamic re-ranking and highlighting to spotlight unexplored dissimilar information, auto-generated descriptive paragraph headings, and low-lighting of redundant information. From a within-subjects user study (n=15), we found that scholars generate more coherent, insightful, and comprehensive topic outlines using Relatedly compared to a baseline paper list.
Dataset of Natural Language Queries for E-Commerce
Feb 13, 2023
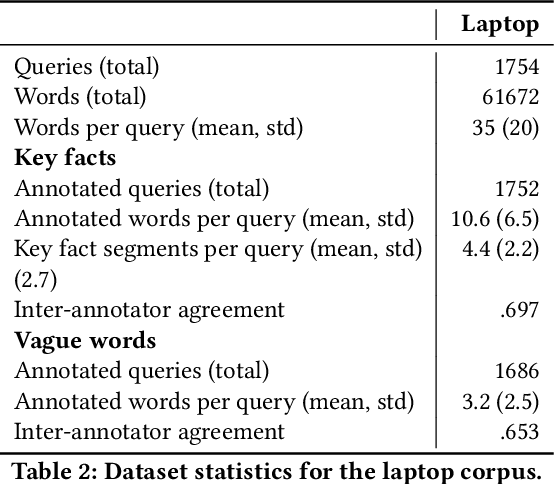
Shopping online is more and more frequent in our everyday life. For e-commerce search systems, understanding natural language coming through voice assistants, chatbots or from conversational search is an essential ability to understand what the user really wants. However, evaluation datasets with natural and detailed information needs of product-seekers which could be used for research do not exist. Due to privacy issues and competitive consequences, only few datasets with real user search queries from logs are openly available. In this paper, we present a dataset of 3,540 natural language queries in two domains that describe what users want when searching for a laptop or a jacket of their choice. The dataset contains annotations of vague terms and key facts of 1,754 laptop queries. This dataset opens up a range of research opportunities in the fields of natural language processing and (interactive) information retrieval for product search.
Personalized Privacy Auditing and Optimization at Test Time
Jan 31, 2023
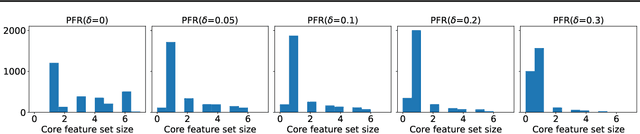
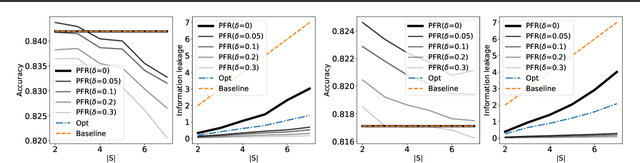

A number of learning models used in consequential domains, such as to assist in legal, banking, hiring, and healthcare decisions, make use of potentially sensitive users' information to carry out inference. Further, the complete set of features is typically required to perform inference. This not only poses severe privacy risks for the individuals using the learning systems, but also requires companies and organizations massive human efforts to verify the correctness of the released information. This paper asks whether it is necessary to require \emph{all} input features for a model to return accurate predictions at test time and shows that, under a personalized setting, each individual may need to release only a small subset of these features without impacting the final decisions. The paper also provides an efficient sequential algorithm that chooses which attributes should be provided by each individual. Evaluation over several learning tasks shows that individuals may be able to report as little as 10\% of their information to ensure the same level of accuracy of a model that uses the complete users' information.
Generating Evidential BEV Maps in Continuous Driving Space
Feb 06, 2023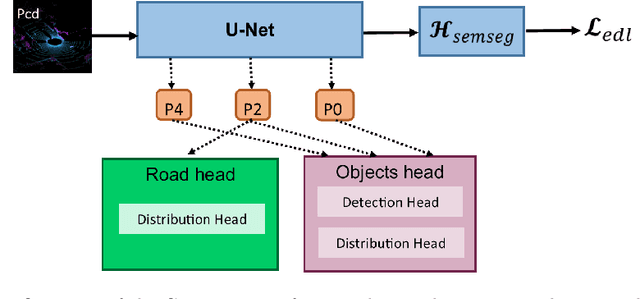


Safety is critical for autonomous driving, and one aspect of improving safety is to accurately capture the uncertainties of the perception system, especially knowing the unknown. Different from only providing deterministic or probabilistic results, e.g., probabilistic object detection, that only provide partial information for the perception scenario, we propose a complete probabilistic model named GevBEV. It interprets the 2D driving space as a probabilistic Bird's Eye View (BEV) map with point-based spatial Gaussian distributions, from which one can draw evidence as the parameters for the categorical Dirichlet distribution of any new sample point in the continuous driving space. The experimental results show that GevBEV not only provides more reliable uncertainty quantification but also outperforms the previous works on the benchmark OPV2V of BEV map interpretation for cooperative perception. A critical factor in cooperative perception is the data transmission size through the communication channels. GevBEV helps reduce communication overhead by selecting only the most important information to share from the learned uncertainty, reducing the average information communicated by 80% with a slight performance drop.