 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fairness-aware Multi-view Clustering
Feb 11, 2023
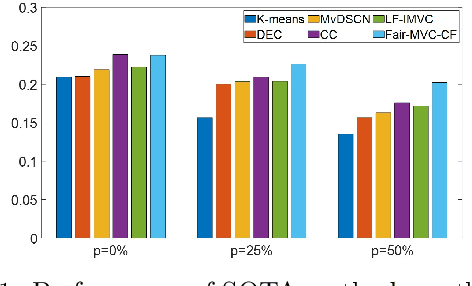

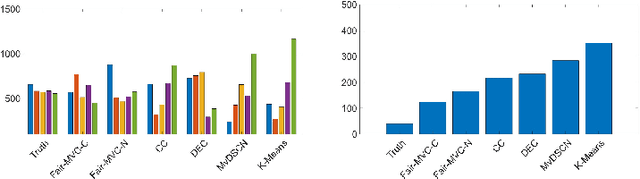

In the era of big data, we are often facing the challenge of data heterogeneity and the lack of label information simultaneously. In the financial domain (e.g., fraud detection), the heterogeneous data may include not only numerical data (e.g., total debt and yearly income), but also text and images (e.g., financial statement and invoice images). At the same time, the label information (e.g., fraud transactions) may be missing for building predictive models. To address these challenges, many state-of-the-art multi-view clustering methods have been proposed and achieved outstanding performance. However, these methods typically do not take into consideration the fairness aspect and are likely to generate biased results using sensitive information such as race and gender. Therefore, in this paper, we propose a fairness-aware multi-view clustering method named FairMVC. It incorporates the group fairness constraint into the soft membership assignment for each cluster to ensure that the fraction of different groups in each cluster is approximately identical to the entire data set. Meanwhile, we adopt the idea of both contrastive learning and non-contrastive learning and propose novel regularizers to handle heterogeneous data in complex scenarios with missing data or noisy features. Experimental results on real-world data sets demonstrate the effectiveness and efficiency of the proposed framework. We also derive insights regarding the relative performance of the proposed regularizers in various scenarios.
A General Visual Representation Guided Framework with Global Affinity for Weakly Supervised Salient Object Detection
Feb 21, 2023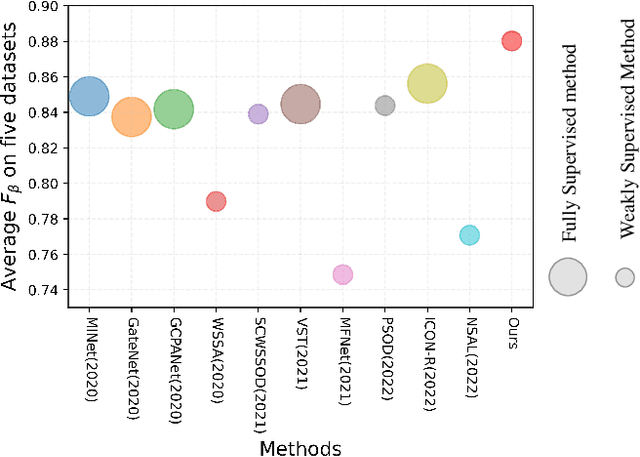
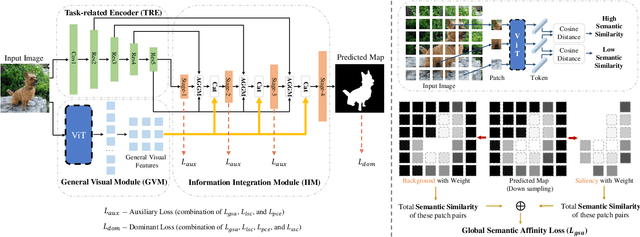
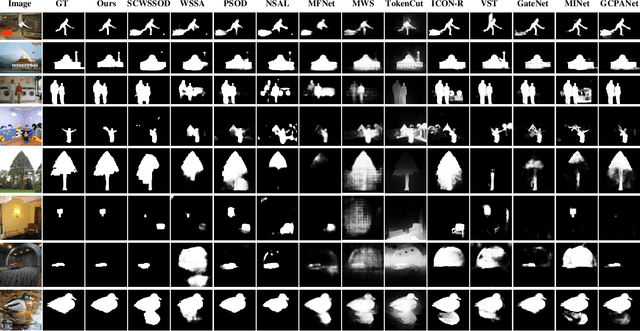

Fully supervised salient object detection (SOD) methods have made considerable progress in performance, yet these models rely heavily on expensive pixel-wise labels. Recently, to achieve a trade-off between labeling burden and performance, scribble-based SOD methods have attracted increasing attention. Previous models directly implement the SOD task only based on small-scale SOD training data. Due to the limited information provided by the weakly scribble tags and such small-scale training data, it is extremely difficult for them to understand the image and further achieve a superior SOD task. In this paper, we propose a simple yet effective framework guided by general visual representations that simulate the general cognition of humans for scribble-based SOD. It consists of a task-related encoder, a general visual module, and an information integration module to combine efficiently the general visual representations learned from large-scale unlabeled datasets with task-related features to perform the SOD task based on understanding the contextual connections of images. Meanwhile, we propose a novel global semantic affinity loss to guide the model to perceive the global structure of the salient objects. Experimental results on five public benchmark datasets demonstrate that our method that only utilizes scribble annotations without introducing any extra label outperforms the state-of-the-art weakly supervised SOD methods and is comparable or even superior to the state-of-the-art fully supervised models.
Multi-task learning of speech and speaker recognition
Feb 24, 2023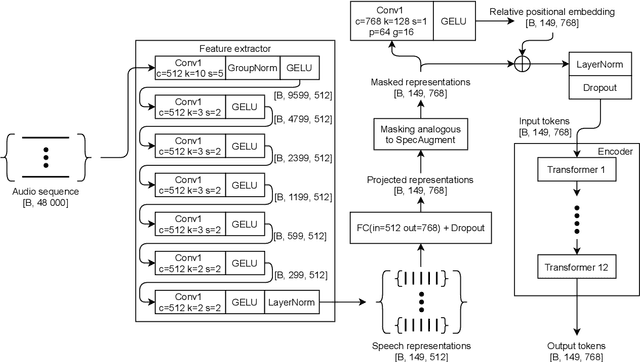
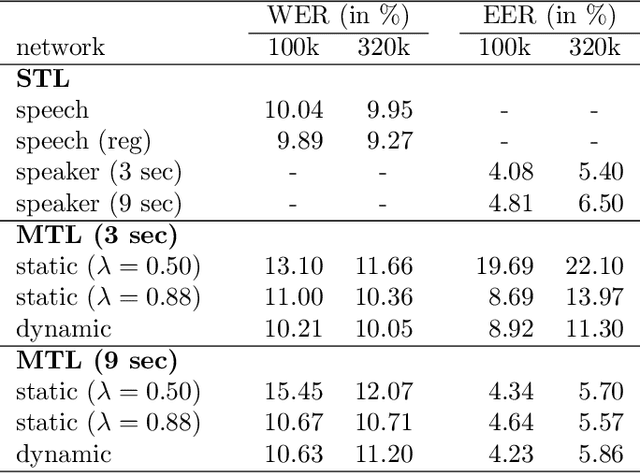
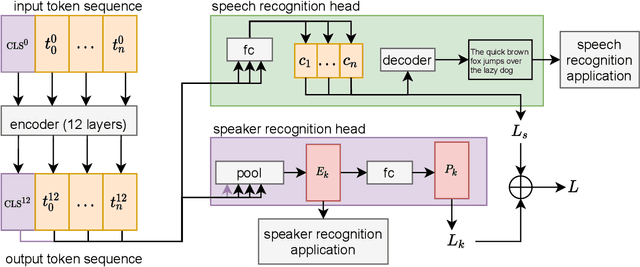
We study multi-task learning for two orthogonal speech technology tasks: speech and speaker recognition. We use wav2vec2 as a base architecture with two task-specific output heads. We experiment with different methods to mix speaker and speech information in the output embedding sequence, and propose a simple dynamic approach to balance the speech and speaker recognition loss functions. Our multi-task learning networks can produce a shared speaker and speech embedding, which are evaluated on the LibriSpeech and VoxCeleb test sets, and achieve a performance comparable to separate single-task models. Code is available at https://github.com/nikvaessen/2022-repo-mt-w2v2.
Exploring the Feasibility of ChatGPT for Event Extraction
Mar 09, 2023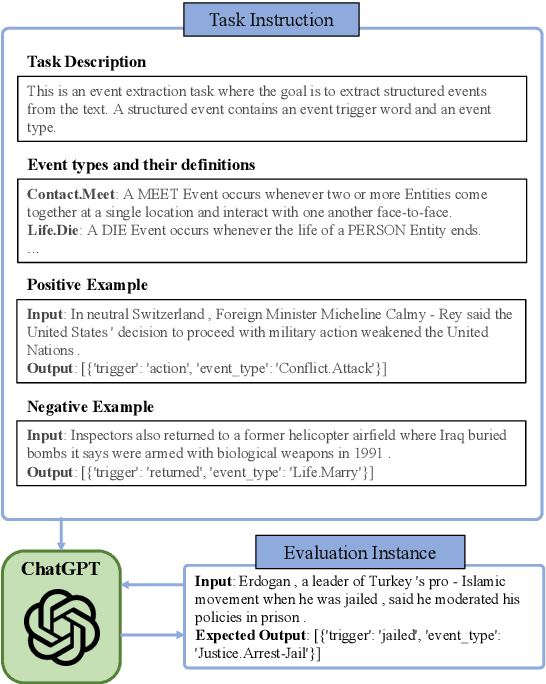
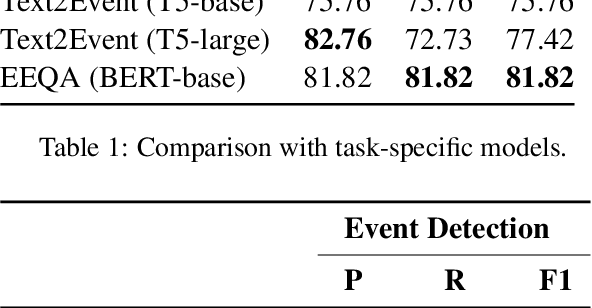
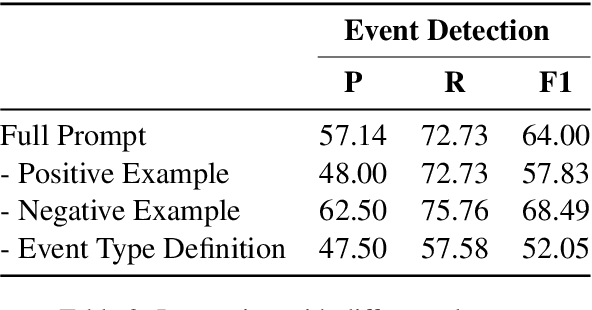
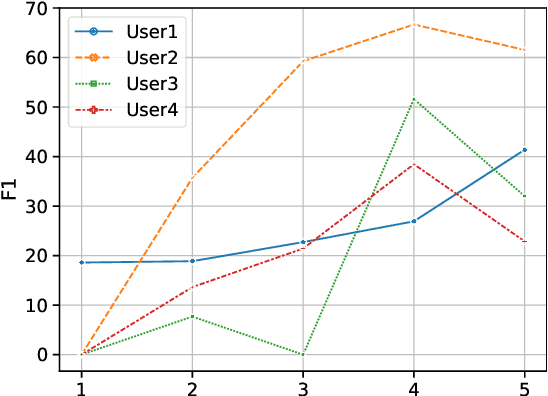
Event extraction is a fundamental task in natural language processing that involves identifying and extracting information about events mentioned in text. However, it is a challenging task due to the lack of annotated data, which is expensive and time-consuming to obtain. The emergence of large language models (LLMs) such as ChatGPT provides an opportunity to solve language tasks with simple prompts without the need for task-specific datasets and fine-tuning. While ChatGPT has demonstrated impressive results in tasks like machine translation, text summarization, and question answering, it presents challenges when used for complex tasks like event extraction. Unlike other tasks, event extraction requires the model to be provided with a complex set of instructions defining all event types and their schemas. To explore the feasibility of ChatGPT for event extraction and the challenges it poses, we conducted a series of experiments. Our results show that ChatGPT has, on average, only 51.04% of the performance of a task-specific model such as EEQA in long-tail and complex scenarios. Our usability testing experiments indicate that ChatGPT is not robust enough, and continuous refinement of the prompt does not lead to stable performance improvements, which can result in a poor user experience. Besides, ChatGPT is highly sensitive to different prompt styles.
GPGait: Generalized Pose-based Gait Recognition
Mar 09, 2023
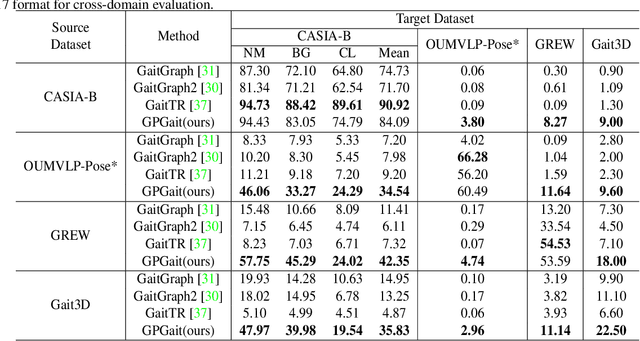
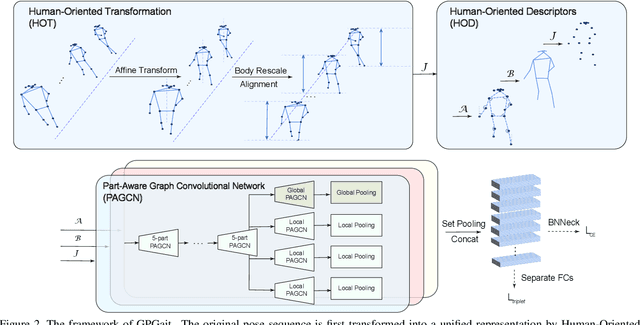
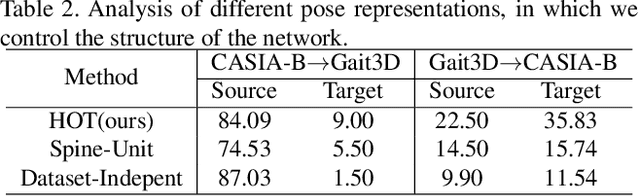
Recent works on pose-based gait recognition have demonstrated the potential of using such simple information to achieve results comparable to silhouette-based methods. However, the generalization ability of pose-based methods on different datasets is undesirably inferior to that of silhouette-based ones, which has received little attention but hinders the application of these methods in real-world scenarios. To improve the generalization ability of pose-based methods across datasets, we propose a Generalized Pose-based Gait recognition (GPGait) framework. First, a Human-Oriented Transformation (HOT) and a series of Human-Oriented Descriptors (HOD) are proposed to obtain a unified pose representation with discriminative multi-features. Then, given the slight variations in the unified representation after HOT and HOD, it becomes crucial for the network to extract local-global relationships between the keypoints. To this end, a Part-Aware Graph Convolutional Network (PAGCN) is proposed to enable efficient graph partition and local-global spatial feature extraction. Experiments on four public gait recognition datasets, CASIA-B, OUMVLP-Pose, Gait3D and GREW, show that our model demonstrates better and more stable cross-domain capabilities compared to existing skeleton-based methods, achieving comparable recognition results to silhouette-based ones. The code will be released.
Planning with Large Language Models for Code Generation
Mar 09, 2023
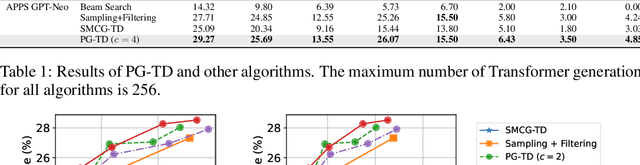
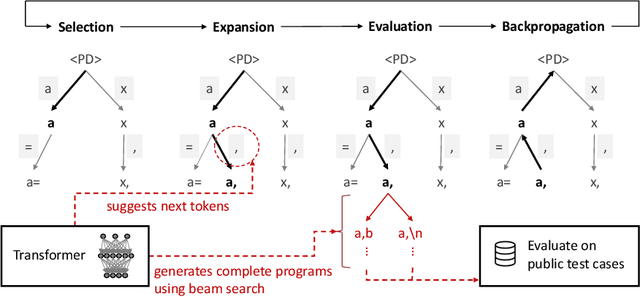
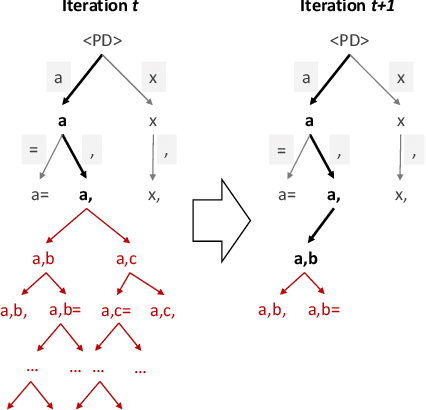
Existing large language model-based code generation pipelines typically use beam search or sampling algorithms during the decoding process. Although the programs they generate achieve high token-matching-based scores, they often fail to compile or generate incorrect outputs. The main reason is that conventional Transformer decoding algorithms may not be the best choice for code generation. In this work, we propose a novel Transformer decoding algorithm, Planning-Guided Transformer Decoding (PG-TD), that uses a planning algorithm to do lookahead search and guide the Transformer to generate better programs. Specifically, instead of simply optimizing the likelihood of the generated sequences, the Transformer makes use of a planner to generate candidate programs and test them on public test cases. The Transformer can therefore make more informed decisions and generate tokens that will eventually lead to higher-quality programs. We also design a mechanism that shares information between the Transformer and the planner to make our algorithm computationally efficient. We empirically evaluate our framework with several large language models as backbones on public coding challenge benchmarks, showing that 1) it can generate programs that consistently achieve higher performance compared with competing baseline methods; 2) it enables controllable code generation, such as concise codes and highly-commented codes by optimizing modified objective.
SelfPromer: Self-Prompt Dehazing Transformers with Depth-Consistency
Mar 13, 2023

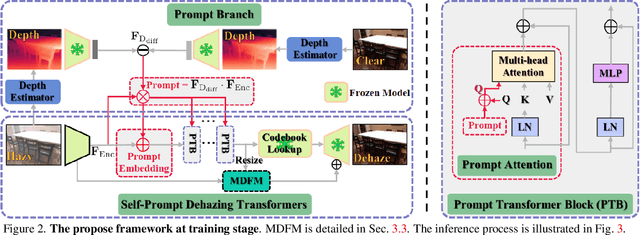
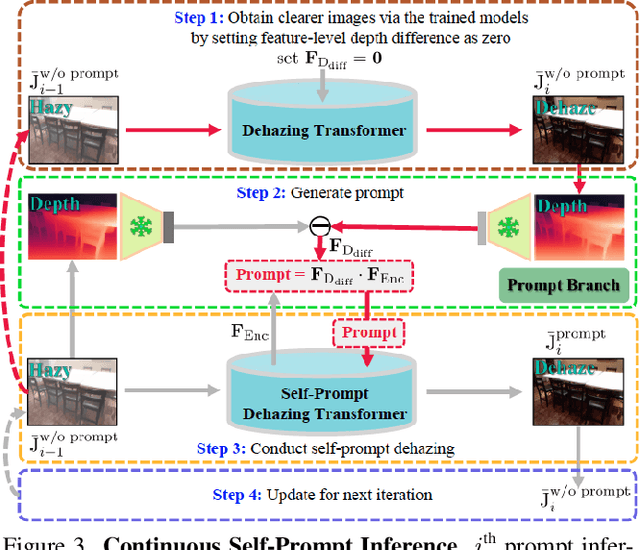
This work presents an effective depth-consistency self-prompt Transformer for image dehazing. It is motivated by an observation that the estimated depths of an image with haze residuals and its clear counterpart vary. Enforcing the depth consistency of dehazed images with clear ones, therefore, is essential for dehazing. For this purpose, we develop a prompt based on the features of depth differences between the hazy input images and corresponding clear counterparts that can guide dehazing models for better restoration. Specifically, we first apply deep features extracted from the input images to the depth difference features for generating the prompt that contains the haze residual information in the input. Then we propose a prompt embedding module that is designed to perceive the haze residuals, by linearly adding the prompt to the deep features. Further, we develop an effective prompt attention module to pay more attention to haze residuals for better removal. By incorporating the prompt, prompt embedding, and prompt attention into an encoder-decoder network based on VQGAN, we can achieve better perception quality. As the depths of clear images are not available at inference, and the dehazed images with one-time feed-forward execution may still contain a portion of haze residuals, we propose a new continuous self-prompt inference that can iteratively correct the dehazing model towards better haze-free image generation. Extensive experiments show that our method performs favorably against the state-of-the-art approaches on both synthetic and real-world datasets in terms of perception metrics including NIQE, PI, and PIQE.
Cross-device Federated Learning for Mobile Health Diagnostics: A First Study on COVID-19 Detection
Mar 13, 2023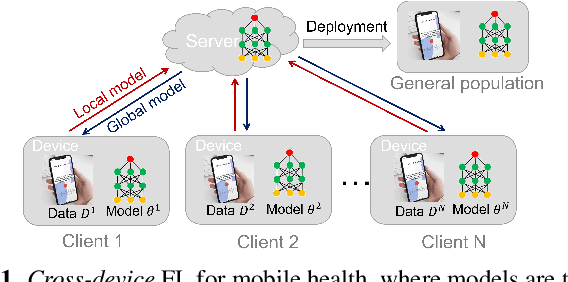
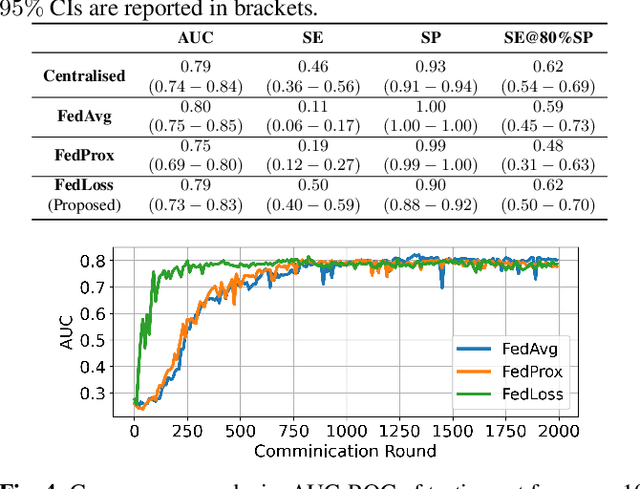
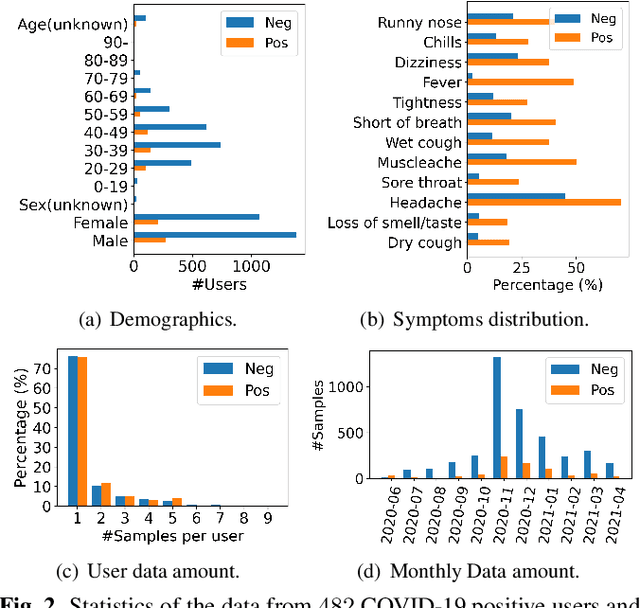
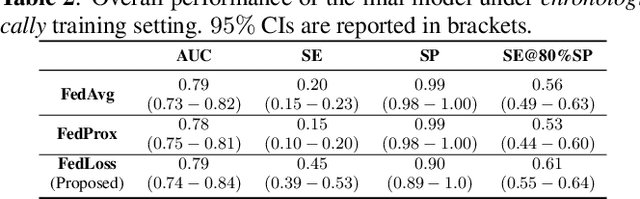
Federated learning (FL) aided health diagnostic models can incorporate data from a large number of personal edge devices (e.g., mobile phones) while keeping the data local to the originating devices, largely ensuring privacy. However, such a cross-device FL approach for health diagnostics still imposes many challenges due to both local data imbalance (as extreme as local data consists of a single disease class) and global data imbalance (the disease prevalence is generally low in a population). Since the federated server has no access to data distribution information, it is not trivial to solve the imbalance issue towards an unbiased model. In this paper, we propose FedLoss, a novel cross-device FL framework for health diagnostics. Here the federated server averages the models trained on edge devices according to the predictive loss on the local data, rather than using only the number of samples as weights. As the predictive loss better quantifies the data distribution at a device, FedLoss alleviates the impact of data imbalance. Through a real-world dataset on respiratory sound and symptom-based COVID-$19$ detection task, we validate the superiority of FedLoss. It achieves competitive COVID-$19$ detection performance compared to a centralised model with an AUC-ROC of $79\%$. It also outperforms the state-of-the-art FL baselines in sensitivity and convergence speed. Our work not only demonstrates the promise of federated COVID-$19$ detection but also paves the way to a plethora of mobile health model development in a privacy-preserving fashion.
Automated Vulnerability Detection in Source Code Using Quantum Natural Language Processing
Mar 13, 2023One of the most important challenges in the field of software code audit is the presence of vulnerabilities in software source code. These flaws are highly likely ex-ploited and lead to system compromise, data leakage, or denial of ser-vice. C and C++ open source code are now available in order to create a large-scale, classical machine-learning and quantum machine-learning system for function-level vulnerability identification. We assembled a siz-able dataset of millions of open-source functions that point to poten-tial exploits. We created an efficient and scalable vulnerability detection method based on a deep neural network model Long Short Term Memory (LSTM), and quantum machine learning model Long Short Term Memory (QLSTM), that can learn features extracted from the source codes. The source code is first converted into a minimal intermediate representation to remove the pointless components and shorten the de-pendency. Therefore, We keep the semantic and syntactic information using state of the art word embedding algorithms such as Glove and fastText. The embedded vectors are subsequently fed into the classical and quantum convolutional neural networks to classify the possible vulnerabilities. To measure the performance, we used evaluation metrics such as F1 score, precision, re-call, accuracy, and total execution time. We made a comparison between the results derived from the classical LSTM and quantum LSTM using basic feature representation as well as semantic and syntactic represen-tation. We found that the QLSTM with semantic and syntactic features detects significantly accurate vulnerability and runs faster than its classical counterpart.
Adaptive Data-Free Quantization
Mar 13, 2023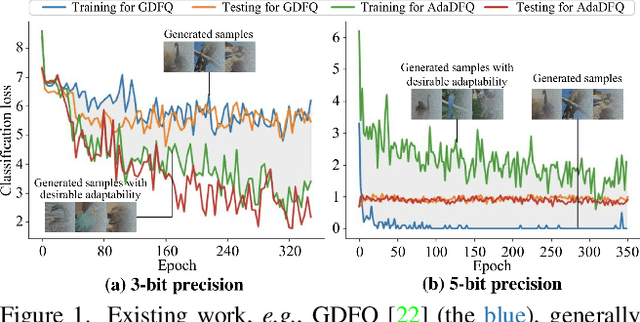
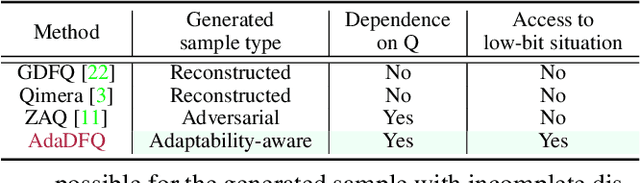
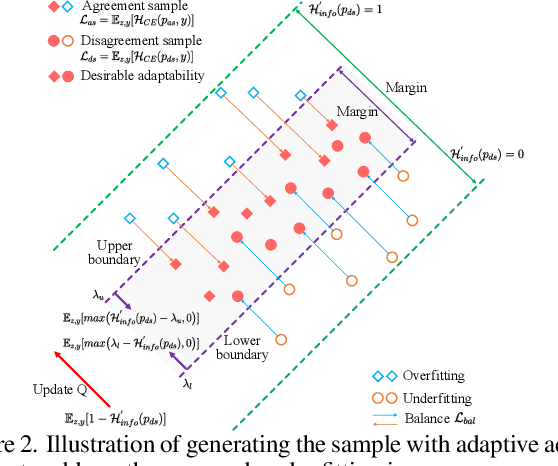
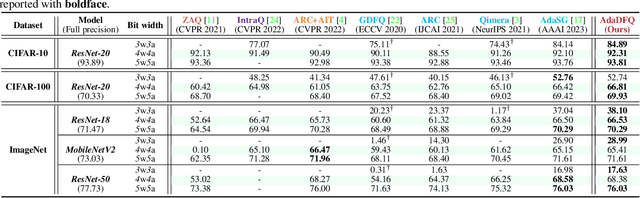
Data-free quantization (DFQ) recovers the performance of quantized network (Q) without accessing the real data, but generates the fake sample via a generator (G) by learning from full-precision network (P) instead. However, such sample generation process is totally independent of Q, overlooking the adaptability of the knowledge from generated samples, i.e., informative or not to the learning process of Q, resulting into the overflow of generalization error. Building on this, several critical questions -- how to measure the sample adaptability to Q under varied bit-width scenarios? how to generate the samples with large adaptability to improve Q's generalization? whether the largest adaptability is the best? To answer the above questions, in this paper, we propose an Adaptive Data-Free Quantization (AdaDFQ) method, which reformulates DFQ as a zero-sum game upon the sample adaptability between two players -- a generator and a quantized network. Following this viewpoint, we further define the disagreement and agreement samples to form two boundaries, where the margin is optimized to address the over-and-under fitting issues, so as to generate the samples with the desirable adaptability to Q. Our AdaDFQ reveals: 1) the largest adaptability is NOT the best for sample generation to benefit Q's generalization; 2) the knowledge of the generated sample should not be informative to Q only, but also related to the category and distribution information of the training data for P. The theoretical and empirical analysis validate the advantages of AdaDFQ over the state-of-the-arts. Our code is available at https: github.com/hfutqian/AdaDFQ.