 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
NeuSE: Neural SE(3)-Equivariant Embedding for Consistent Spatial Understanding with Objects
Mar 13, 2023
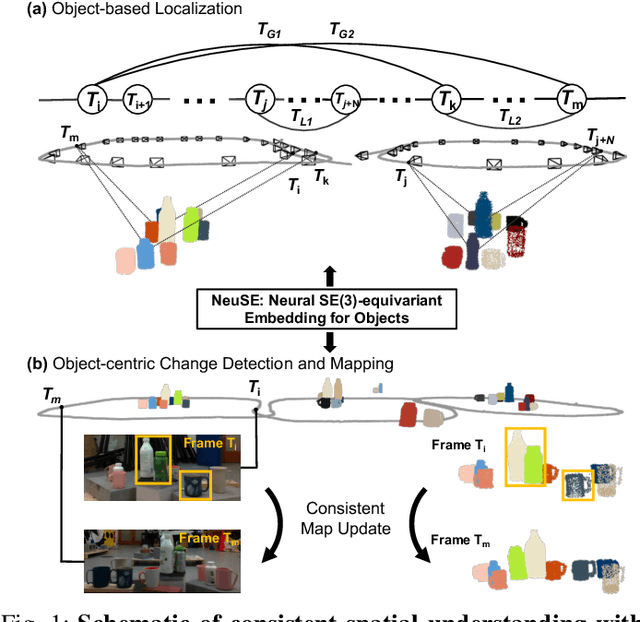
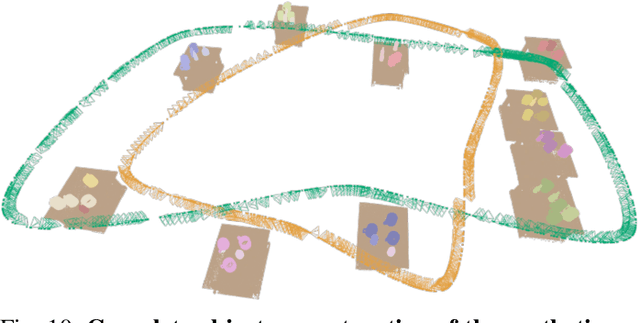
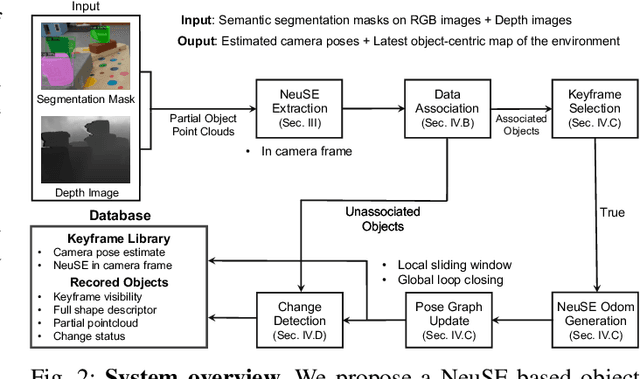
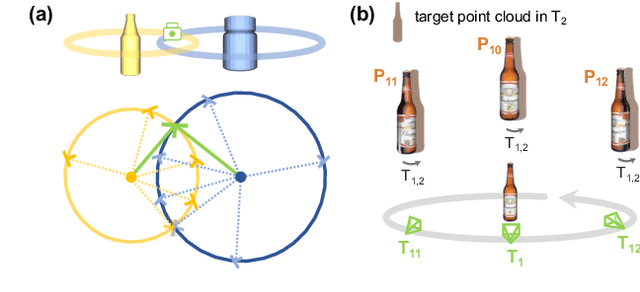
We present NeuSE, a novel Neural SE(3)-Equivariant Embedding for objects, and illustrate how it supports object SLAM for consistent spatial understanding with long-term scene changes. NeuSE is a set of latent object embeddings created from partial object observations. It serves as a compact point cloud surrogate for complete object models, encoding full shape information while transforming SE(3)-equivariantly in tandem with the object in the physical world. With NeuSE, relative frame transforms can be directly derived from inferred latent codes. Our proposed SLAM paradigm, using NeuSE for object shape and pose characterization, can operate independently or in conjunction with typical SLAM systems. It directly infers SE(3) camera pose constraints that are compatible with general SLAM pose graph optimization, while also maintaining a lightweight object-centric map that adapts to real-world changes. Our approach is evaluated on synthetic and real-world sequences featuring changed objects and shows improved localization accuracy and change-aware mapping capability, when working either standalone or jointly with a common SLAM pipeline.
An ASR-free Fluency Scoring Approach with Self-Supervised Learning
Mar 13, 2023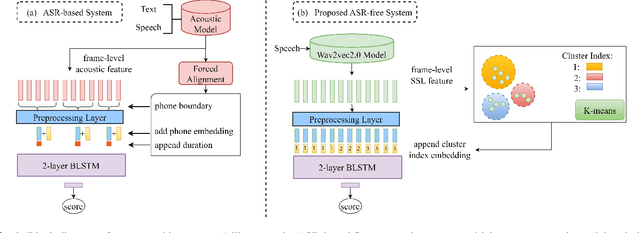
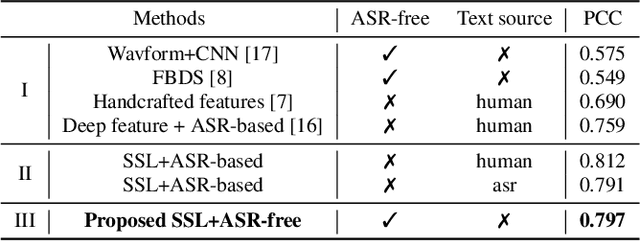
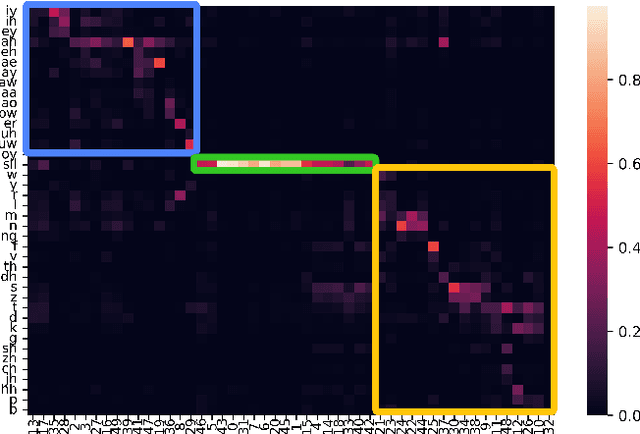
A typical fluency scoring system generally relies on an automatic speech recognition (ASR) system to obtain time stamps in input speech for either the subsequent calculation of fluency-related features or directly modeling speech fluency with an end-to-end approach. This paper describes a novel ASR-free approach for automatic fluency assessment using self-supervised learning (SSL). Specifically, wav2vec2.0 is used to extract frame-level speech features, followed by K-means clustering to assign a pseudo label (cluster index) to each frame. A BLSTM-based model is trained to predict an utterance-level fluency score from frame-level SSL features and the corresponding cluster indexes. Neither speech transcription nor time stamp information is required in the proposed system. It is ASR-free and can potentially avoid the ASR errors effect in practice. Experimental results carried out on non-native English databases show that the proposed approach significantly improves the performance in the "open response" scenario as compared to previous methods and matches the recently reported performance in the "read aloud" scenario.
NeRFLiX: High-Quality Neural View Synthesis by Learning a Degradation-Driven Inter-viewpoint MiXer
Mar 13, 2023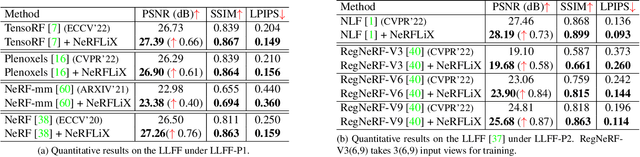
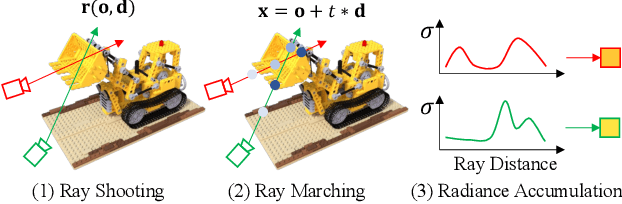
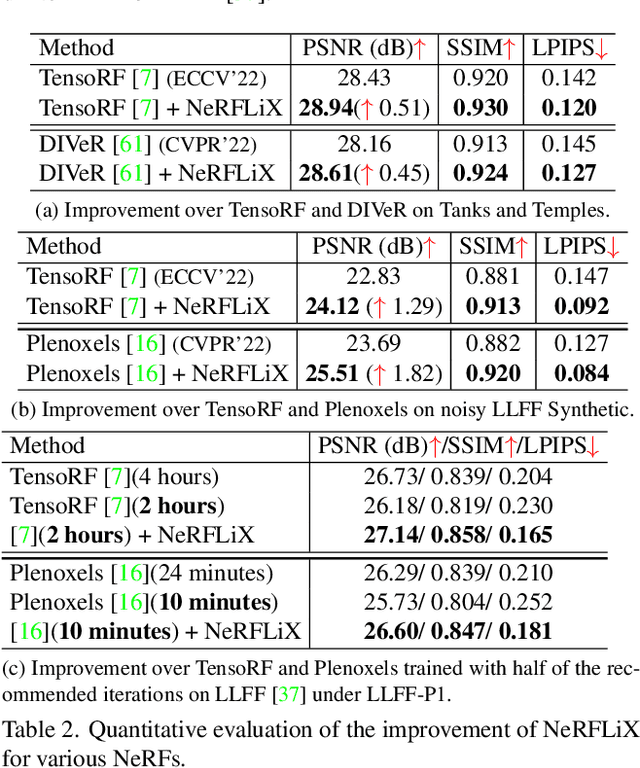
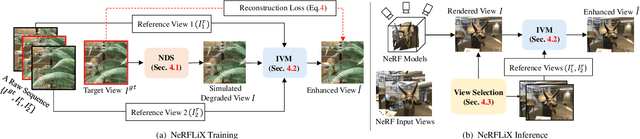
Neural radiance fields (NeRF) show great success in novel view synthesis. However, in real-world scenes, recovering high-quality details from the source images is still challenging for the existing NeRF-based approaches, due to the potential imperfect calibration information and scene representation inaccuracy. Even with high-quality training frames, the synthetic novel views produced by NeRF models still suffer from notable rendering artifacts, such as noise, blur, etc. Towards to improve the synthesis quality of NeRF-based approaches, we propose NeRFLiX, a general NeRF-agnostic restorer paradigm by learning a degradation-driven inter-viewpoint mixer. Specially, we design a NeRF-style degradation modeling approach and construct large-scale training data, enabling the possibility of effectively removing NeRF-native rendering artifacts for existing deep neural networks. Moreover, beyond the degradation removal, we propose an inter-viewpoint aggregation framework that is able to fuse highly related high-quality training images, pushing the performance of cutting-edge NeRF models to entirely new levels and producing highly photo-realistic synthetic views.
Synergizing Beyond Diagonal Reconfigurable Intelligent Surface and Rate-Splitting Multiple Access
Mar 13, 2023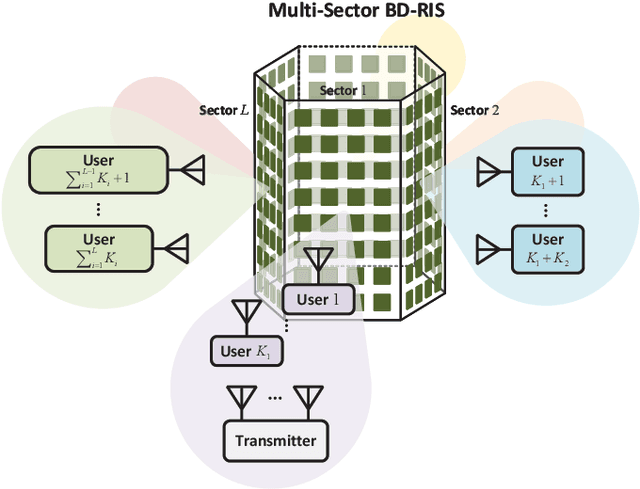
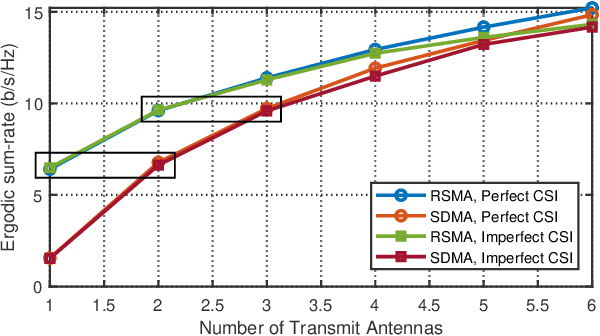
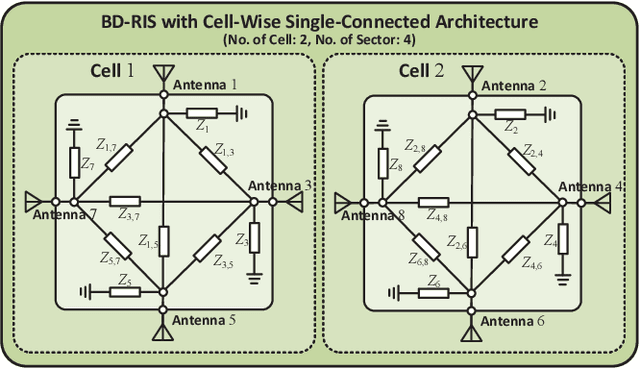
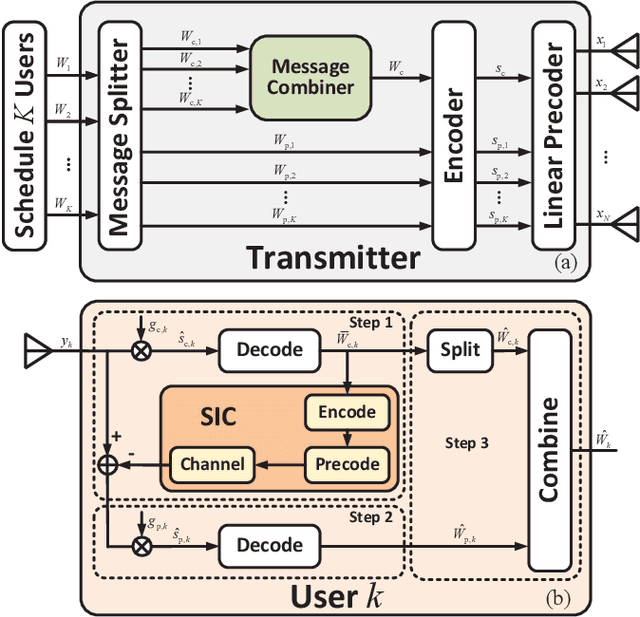
This work focuses on the synergy of rate-splitting multiple access (RSMA) and beyond diagonal reconfigurable intelligent surface (BD-RIS) to enlarge the coverage, improve the performance, and save on antennas. Specifically, we employ a multi-sector BD-RIS modeled as a prism, which can achieve highly directional full-space coverage, in a multiuser multiple input single output communication system. With the multi-sector BD-RIS aided RSMA model, we jointly design the transmit precoder and BD-RIS matrix under the imperfect channel state information (CSI) conditions. The robust design is performed by solving a stochastic average sum-rate maximization problem. With sample average approximation and weighted minimum mean square error-rate relationship, the stochastic problem is transformed into a deterministic one with multiple blocks, each of which is iteratively designed. Simulation results show that multi-sector BD-RIS aided RSMA outperforms space division multiple access schemes. More importantly, synergizing multi-sector BD-RIS with RSMA is an efficient strategy to reduce the number of active antennas at the transmitter and the number of passive antennas in BD-RIS.
Molecular Property Prediction by Semantic-invariant Contrastive Learning
Mar 13, 2023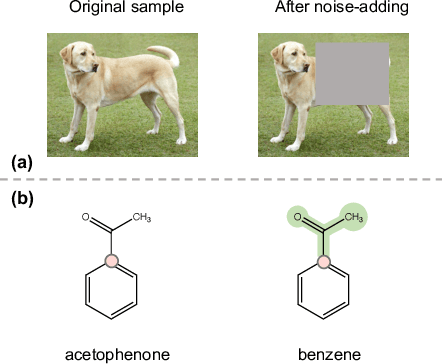

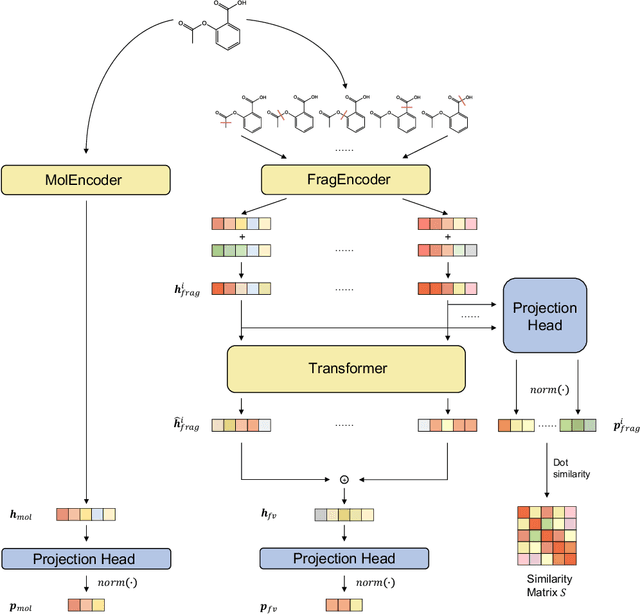
Contrastive learning have been widely used as pretext tasks for self-supervised pre-trained molecular representation learning models in AI-aided drug design and discovery. However, exiting methods that generate molecular views by noise-adding operations for contrastive learning may face the semantic inconsistency problem, which leads to false positive pairs and consequently poor prediction performance. To address this problem, in this paper we first propose a semantic-invariant view generation method by properly breaking molecular graphs into fragment pairs. Then, we develop a Fragment-based Semantic-Invariant Contrastive Learning (FraSICL) model based on this view generation method for molecular property prediction. The FraSICL model consists of two branches to generate representations of views for contrastive learning, meanwhile a multi-view fusion and an auxiliary similarity loss are introduced to make better use of the information contained in different fragment-pair views. Extensive experiments on various benchmark datasets show that with the least number of pre-training samples, FraSICL can achieve state-of-the-art performance, compared with major existing counterpart models.
Graph Learning from Gaussian and Stationary Graph Signals
Mar 13, 2023
Graphs have become pervasive tools to represent information and datasets with irregular support. However, in many cases, the underlying graph is either unavailable or naively obtained, calling for more advanced methods to its estimation. Indeed, graph topology inference methods that estimate the network structure from a set of signal observations have a long and well established history. By assuming that the observations are both Gaussian and stationary in the sought graph, this paper proposes a new scheme to learn the network from nodal observations. Consideration of graph stationarity overcomes some of the limitations of the classical Graphical Lasso algorithm, which is constrained to a more specific class of graphical models. On the other hand, Gaussianity allows us to regularize the estimation, requiring less samples than in existing graph stationarity-based approaches. While the resultant estimation (optimization) problem is more complex and non-convex, we design an alternating convex approach able to find a stationary solution. Numerical tests with synthetic and real data are presented, and the performance of our approach is compared with existing alternatives.
Depth-based 6DoF Object Pose Estimation using Swin Transformer
Mar 03, 2023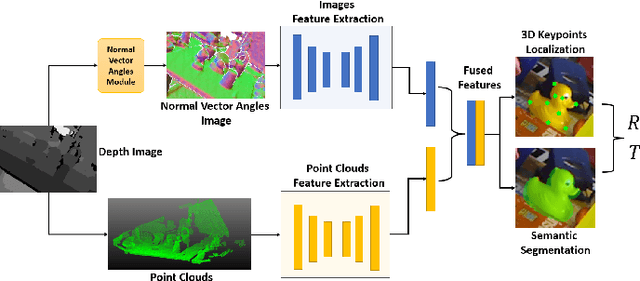
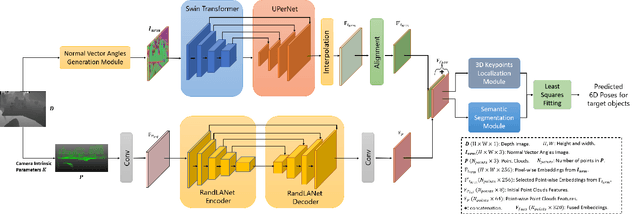
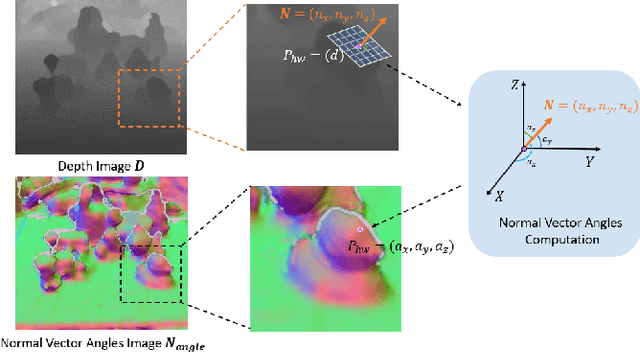
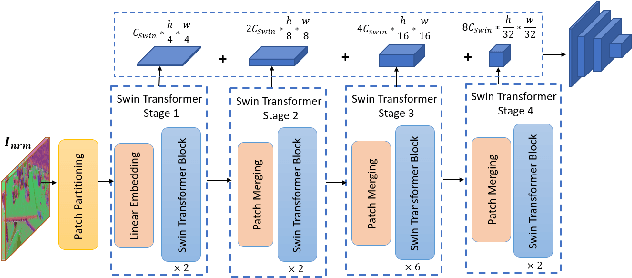
Accurately estimating the 6D pose of objects is crucial for many applications, such as robotic grasping, autonomous driving, and augmented reality. However, this task becomes more challenging in poor lighting conditions or when dealing with textureless objects. To address this issue, depth images are becoming an increasingly popular choice due to their invariance to a scene's appearance and the implicit incorporation of essential geometric characteristics. However, fully leveraging depth information to improve the performance of pose estimation remains a difficult and under-investigated problem. To tackle this challenge, we propose a novel framework called SwinDePose, that uses only geometric information from depth images to achieve accurate 6D pose estimation. SwinDePose first calculates the angles between each normal vector defined in a depth image and the three coordinate axes in the camera coordinate system. The resulting angles are then formed into an image, which is encoded using Swin Transformer. Additionally, we apply RandLA-Net to learn the representations from point clouds. The resulting image and point clouds embeddings are concatenated and fed into a semantic segmentation module and a 3D keypoints localization module. Finally, we estimate 6D poses using a least-square fitting approach based on the target object's predicted semantic mask and 3D keypoints. In experiments on the LineMod and Occlusion LineMod datasets, SwinDePose outperforms existing state-of-the-art methods for 6D object pose estimation using depth images. This demonstrates the effectiveness of our approach and highlights its potential for improving performance in real-world scenarios. Our code is at https://github.com/zhujunli1993/SwinDePose.
Sparse Bayesian Learning-Based 3D Spectrum Environment Map Construction-Sampling Optimization, Scenario-Dependent Dictionary Construction and Sparse Recovery
Feb 25, 2023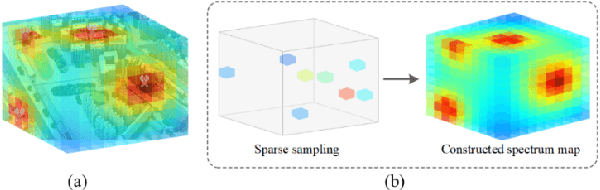
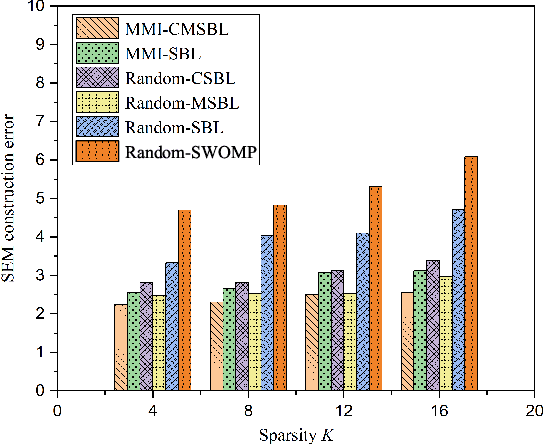
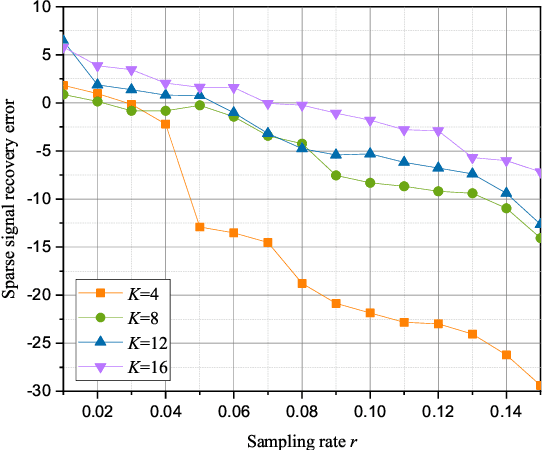

The spectrum environment map (SEM), which can visualize the information of invisible electromagnetic spectrum, is vital for monitoring, management, and security of spectrum resources in cognitive radio (CR) networks. In view of a limited number of spectrum sensors and constrained sampling time, this paper presents a new three-dimensional (3D) SEM construction scheme based on sparse Bayesian learning (SBL). Firstly, we construct a scenario-dependent channel dictionary matrix by considering the propagation characteristic of the interested scenario. To improve sampling efficiency, a maximum mutual information (MMI)-based optimization algorithm is developed for the layout of sampling sensors. Then, a maximum and minimum distance (MMD) clustering-based SBL algorithm is proposed to recover the spectrum data at the unsampled positions and construct the whole 3D SEM. We finally use the simulation data of the campus scenario to construct the 3D SEMs and compare the proposed method with the state-of-the-art. The recovery performance and the impact of different sparsity on the constructed SEMs are also analyzed. Numerical results show that the proposed scheme can reduce the required spectrum sensor number and has higher accuracy under the low sampling rate.
Lung Nodule Segmentation and Low-Confidence Region Prediction with Uncertainty-Aware Attention Mechanism
Mar 19, 2023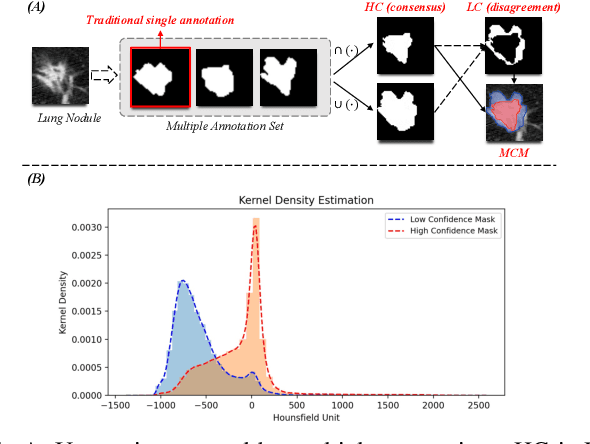

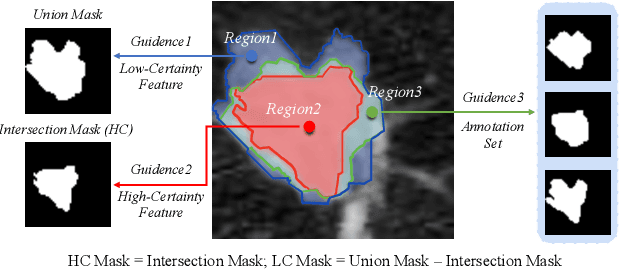
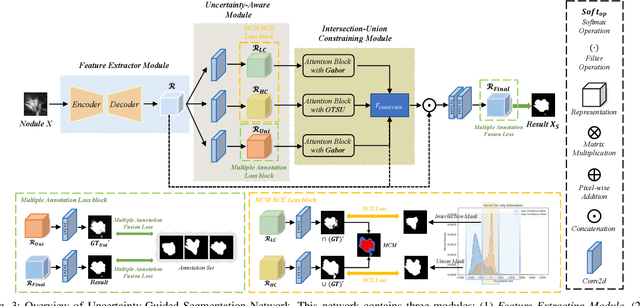
Radiologists have different training and clinical experiences, so they may provide various segmentation annotations for a lung nodule, which causes segmentation uncertainty among multiple annotations. Conventional methods usually chose a single annotation as the learning target or tried to learn a latent space of various annotations. Still, they wasted the valuable information of consensus or disagreements ingrained in the multiple annotations. This paper proposes an Uncertainty-Aware Attention Mechanism (UAAM), which utilizes consensus or disagreements among annotations to produce a better segmentation. In UAAM, we propose a Multi-Confidence Mask (MCM), which is a combination of a Low-Confidence (LC) Mask and a High-Confidence (HC) Mask. LC mask indicates regions with low segmentation confidence, which may cause different segmentation options among radiologists. Following UAAM, we further design an Uncertainty-Guide Segmentation Network (UGS-Net), which contains three modules:Feature Extracting Module captures a general feature of a lung nodule. Uncertainty-Aware Module produce three features for the annotations' union, intersection, and annotation set. Finally, Intersection-Union Constraining Module use distances between three features to balance the predictions of final segmentation, LC mask, and HC mask. To fully demonstrate the performance of our method, we propose a Complex Nodule Challenge on LIDC-IDRI, which tests UGS-Net's segmentation performance on the lung nodules that are difficult to segment by U-Net. Experimental results demonstrate that our method can significantly improve the segmentation performance on nodules with poor segmentation by U-Net.
Multi-Channel Attentive Feature Fusion for Radio Frequency Fingerprinting
Mar 19, 2023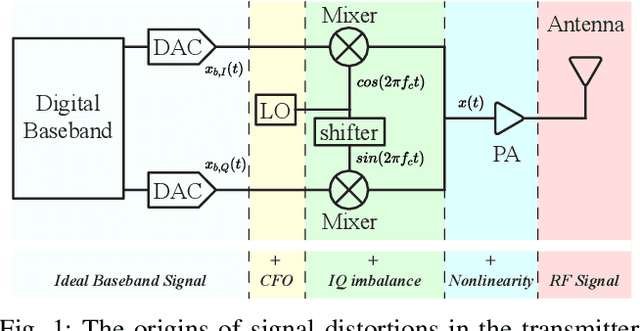
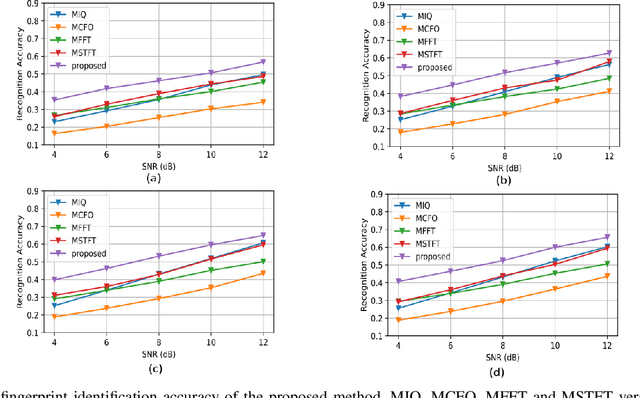
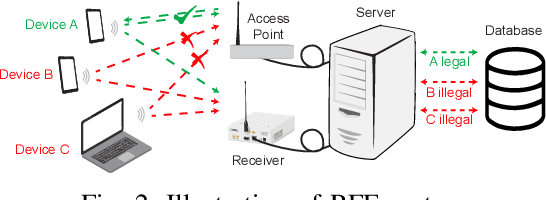
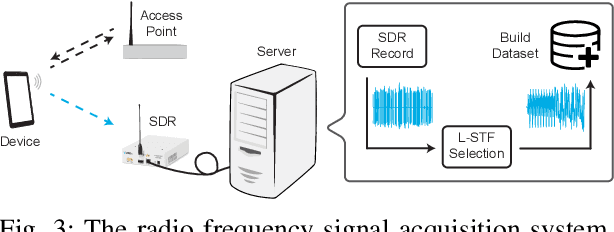
Radio frequency fingerprinting (RFF) is a promising device authentication technique for securing the Internet of things. It exploits the intrinsic and unique hardware impairments of the transmitters for RF device identification. In real-world communication systems, hardware impairments across transmitters are subtle, which are difficult to model explicitly. Recently, due to the superior performance of deep learning (DL)-based classification models on real-world datasets, DL networks have been explored for RFF. Most existing DL-based RFF models use a single representation of radio signals as the input. Multi-channel input model can leverage information from different representations of radio signals and improve the identification accuracy of the RF fingerprint. In this work, we propose a novel multi-channel attentive feature fusion (McAFF) method for RFF. It utilizes multi-channel neural features extracted from multiple representations of radio signals, including IQ samples, carrier frequency offset, fast Fourier transform coefficients and short-time Fourier transform coefficients, for better RF fingerprint identification. The features extracted from different channels are fused adaptively using a shared attention module, where the weights of neural features from multiple channels are learned during training the McAFF model. In addition, we design a signal identification module using a convolution-based ResNeXt block to map the fused features to device identities. To evaluate the identification performance of the proposed method, we construct a WiFi dataset, named WFDI, using commercial WiFi end-devices as the transmitters and a Universal Software Radio Peripheral (USRP) as the receiver. ...