 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pixel-Level Explanation of Multiple Instance Learning Models in Biomedical Single Cell Images
Mar 15, 2023


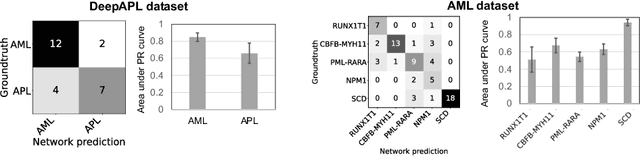
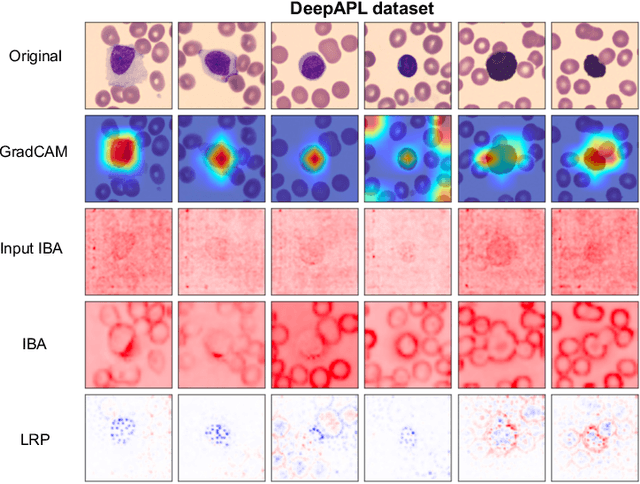
Explainability is a key requirement for computer-aided diagnosis systems in clinical decision-making. Multiple instance learning with attention pooling provides instance-level explainability, however for many clinical applications a deeper, pixel-level explanation is desirable, but missing so far. In this work, we investigate the use of four attribution methods to explain a multiple instance learning models: GradCAM, Layer-Wise Relevance Propagation (LRP), Information Bottleneck Attribution (IBA), and InputIBA. With this collection of methods, we can derive pixel-level explanations on for the task of diagnosing blood cancer from patients' blood smears. We study two datasets of acute myeloid leukemia with over 100 000 single cell images and observe how each attribution method performs on the multiple instance learning architecture focusing on different properties of the white blood single cells. Additionally, we compare attribution maps with the annotations of a medical expert to see how the model's decision-making differs from the human standard. Our study addresses the challenge of implementing pixel-level explainability in multiple instance learning models and provides insights for clinicians to better understand and trust decisions from computer-aided diagnosis systems.
DR2: Diffusion-based Robust Degradation Remover for Blind Face Restoration
Mar 15, 2023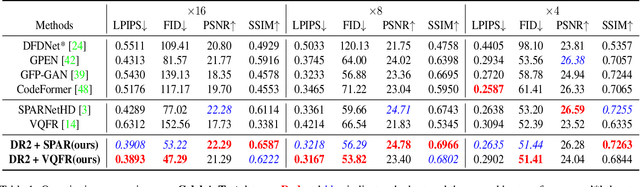
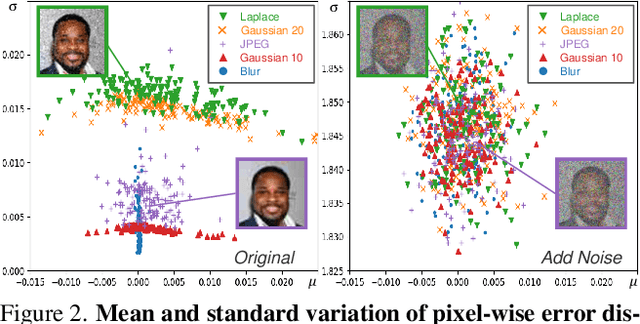
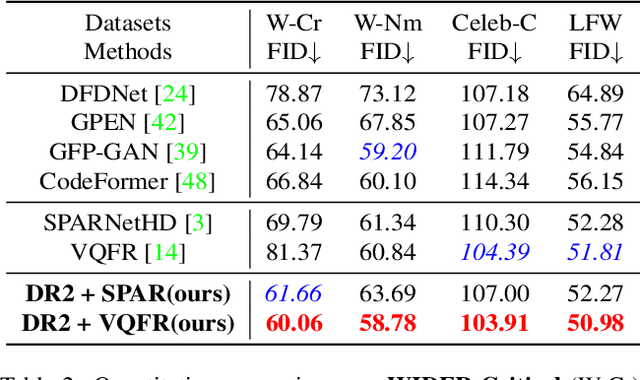
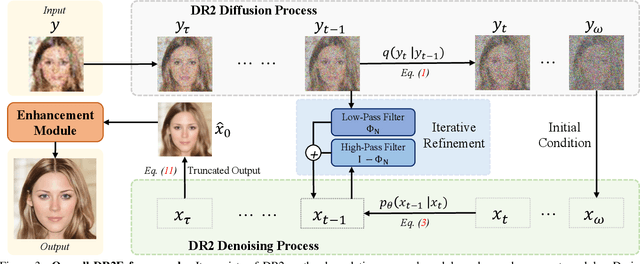
Blind face restoration usually synthesizes degraded low-quality data with a pre-defined degradation model for training, while more complex cases could happen in the real world. This gap between the assumed and actual degradation hurts the restoration performance where artifacts are often observed in the output. However, it is expensive and infeasible to include every type of degradation to cover real-world cases in the training data. To tackle this robustness issue, we propose Diffusion-based Robust Degradation Remover (DR2) to first transform the degraded image to a coarse but degradation-invariant prediction, then employ an enhancement module to restore the coarse prediction to a high-quality image. By leveraging a well-performing denoising diffusion probabilistic model, our DR2 diffuses input images to a noisy status where various types of degradation give way to Gaussian noise, and then captures semantic information through iterative denoising steps. As a result, DR2 is robust against common degradation (e.g. blur, resize, noise and compression) and compatible with different designs of enhancement modules. Experiments in various settings show that our framework outperforms state-of-the-art methods on heavily degraded synthetic and real-world datasets.
SpeechFormer++: A Hierarchical Efficient Framework for Paralinguistic Speech Processing
Feb 27, 2023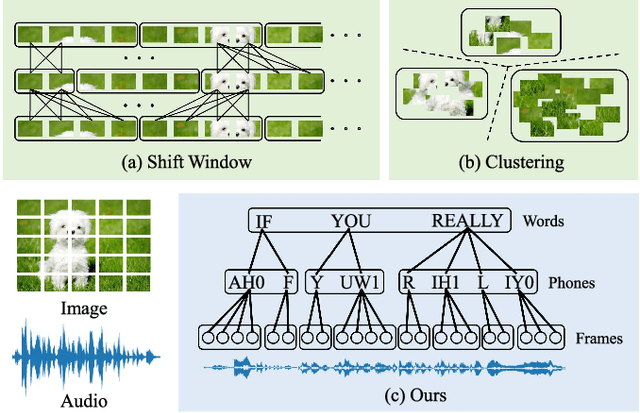
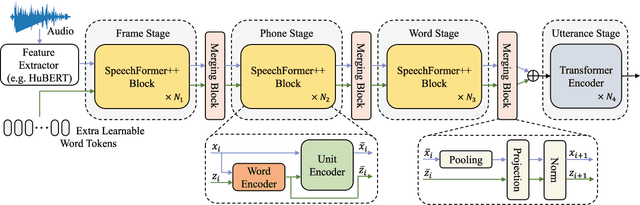
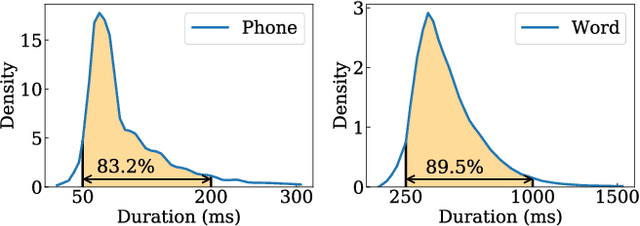
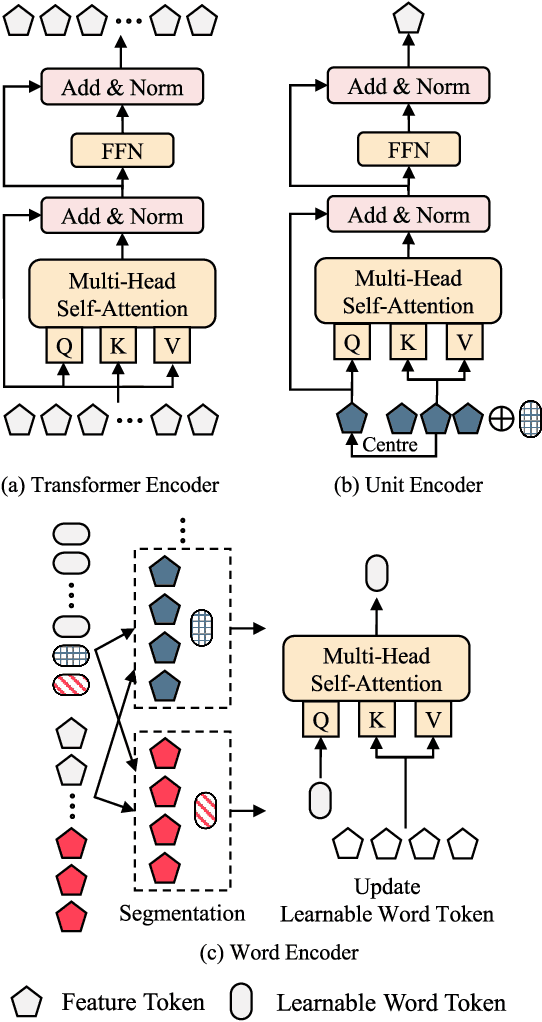
Paralinguistic speech processing is important in addressing many issues, such as sentiment and neurocognitive disorder analyses. Recently, Transformer has achieved remarkable success in the natural language processing field and has demonstrated its adaptation to speech. However, previous works on Transformer in the speech field have not incorporated the properties of speech, leaving the full potential of Transformer unexplored. In this paper, we consider the characteristics of speech and propose a general structure-based framework, called SpeechFormer++, for paralinguistic speech processing. More concretely, following the component relationship in the speech signal, we design a unit encoder to model the intra- and inter-unit information (i.e., frames, phones, and words) efficiently. According to the hierarchical relationship, we utilize merging blocks to generate features at different granularities, which is consistent with the structural pattern in the speech signal. Moreover, a word encoder is introduced to integrate word-grained features into each unit encoder, which effectively balances fine-grained and coarse-grained information. SpeechFormer++ is evaluated on the speech emotion recognition (IEMOCAP & MELD), depression classification (DAIC-WOZ) and Alzheimer's disease detection (Pitt) tasks. The results show that SpeechFormer++ outperforms the standard Transformer while greatly reducing the computational cost. Furthermore, it delivers superior results compared to the state-of-the-art approaches.
SLOTH: Structured Learning and Task-based Optimization for Time Series Forecasting on Hierarchies
Feb 27, 2023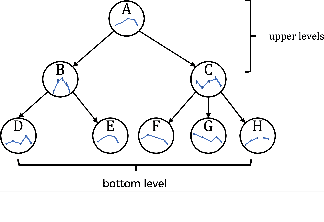
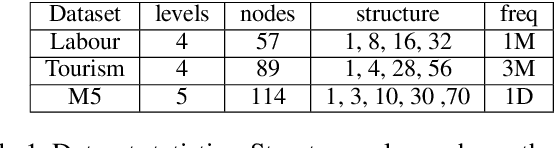
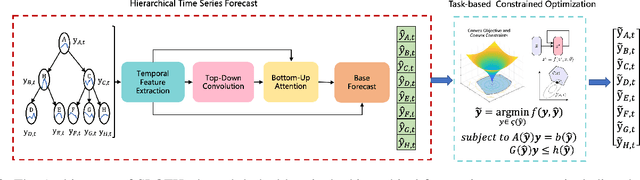
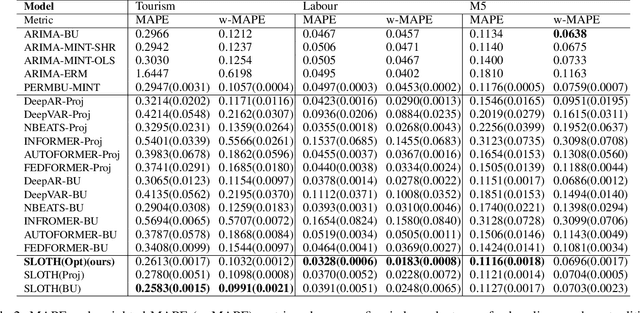
Multivariate time series forecasting with hierarchical structure is widely used in real-world applications, e.g., sales predictions for the geographical hierarchy formed by cities, states, and countries. The hierarchical time series (HTS) forecasting includes two sub-tasks, i.e., forecasting and reconciliation. In the previous works, hierarchical information is only integrated in the reconciliation step to maintain coherency, but not in forecasting step for accuracy improvement. In this paper, we propose two novel tree-based feature integration mechanisms, i.e., top-down convolution and bottom-up attention to leverage the information of the hierarchical structure to improve the forecasting performance. Moreover, unlike most previous reconciliation methods which either rely on strong assumptions or focus on coherent constraints only,we utilize deep neural optimization networks, which not only achieve coherency without any assumptions, but also allow more flexible and realistic constraints to achieve task-based targets, e.g., lower under-estimation penalty and meaningful decision-making loss to facilitate the subsequent downstream tasks. Experiments on real-world datasets demonstrate that our tree-based feature integration mechanism achieves superior performances on hierarchical forecasting tasks compared to the state-of-the-art methods, and our neural optimization networks can be applied to real-world tasks effectively without any additional effort under coherence and task-based constraints
Anatomical Invariance Modeling and Semantic Alignment for Self-supervised Learning in 3D Medical Image Segmentation
Feb 27, 2023
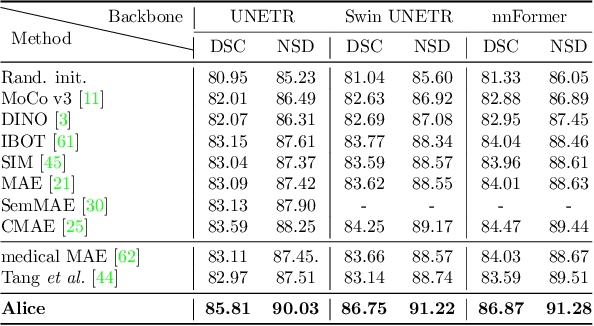
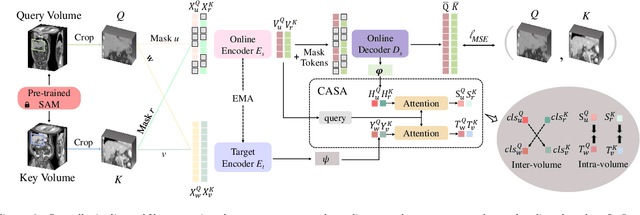
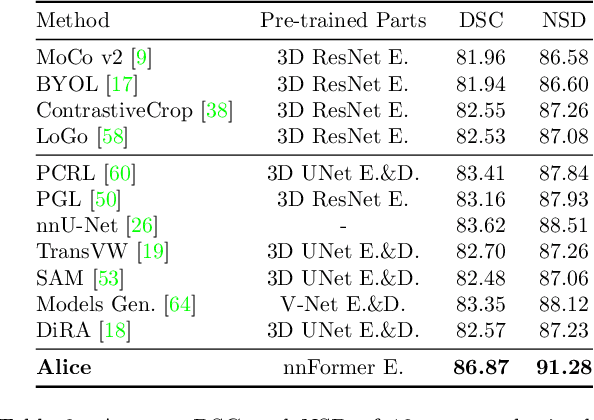
Self-supervised learning (SSL) has recently achieved promising performance for 3D medical image segmentation tasks. Most current methods follow existing SSL paradigm originally designed for photographic or natural images, which cannot explicitly and thoroughly exploit the intrinsic similar anatomical structures across varying medical images. This may in fact degrade the quality of learned deep representations by maximizing the similarity among features containing spatial misalignment information and different anatomical semantics. In this work, we propose a new self-supervised learning framework, namely Alice, that explicitly fulfills Anatomical invariance modeling and semantic alignment via elaborately combining discriminative and generative objectives. Alice introduces a new contrastive learning strategy which encourages the similarity between views that are diversely mined but with consistent high-level semantics, in order to learn invariant anatomical features. Moreover, we design a conditional anatomical feature alignment module to complement corrupted embeddings with globally matched semantics and inter-patch topology information, conditioned by the distribution of local image content, which permits to create better contrastive pairs. Our extensive quantitative experiments on two public 3D medical image segmentation benchmarks of FLARE 2022 and BTCV demonstrate and validate the performance superiority of Alice, surpassing the previous best SSL counterpart methods by 2.11% and 1.77% in Dice coefficients, respectively.
Spatial-Frequency Attention for Image Denoising
Feb 27, 2023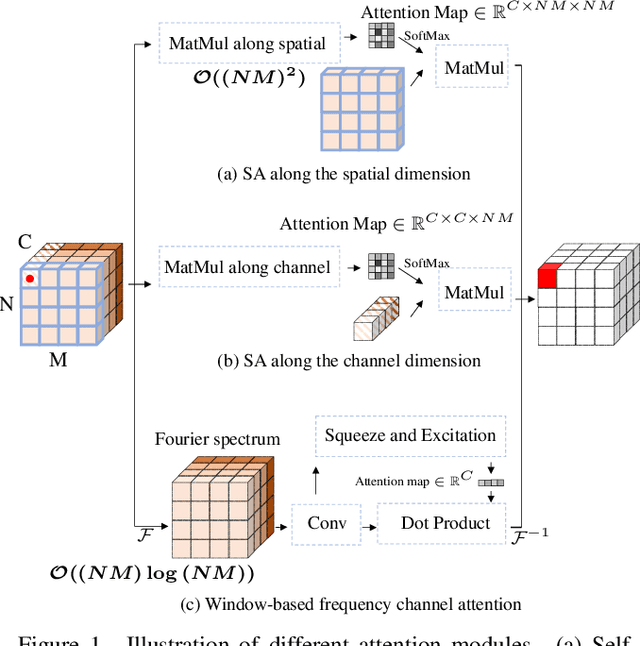
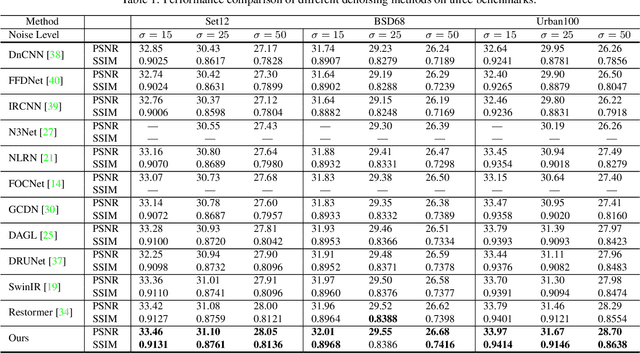
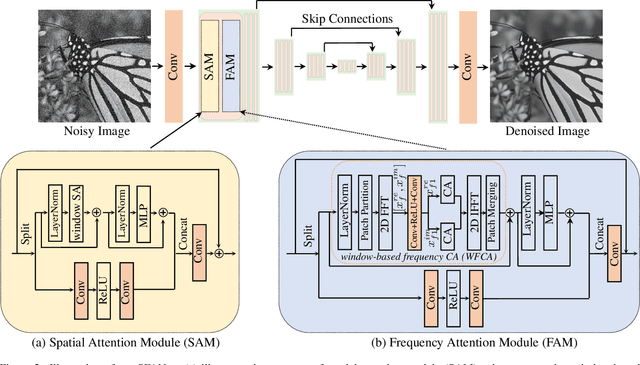
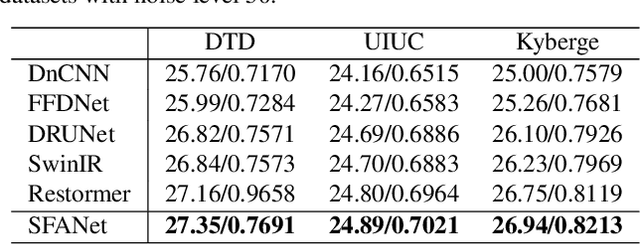
The recently developed transformer networks have achieved impressive performance in image denoising by exploiting the self-attention (SA) in images. However, the existing methods mostly use a relatively small window to compute SA due to the quadratic complexity of it, which limits the model's ability to model long-term image information. In this paper, we propose the spatial-frequency attention network (SFANet) to enhance the network's ability in exploiting long-range dependency. For spatial attention module (SAM), we adopt dilated SA to model long-range dependency. In the frequency attention module (FAM), we exploit more global information by using Fast Fourier Transform (FFT) by designing a window-based frequency channel attention (WFCA) block to effectively model deep frequency features and their dependencies. To make our module applicable to images of different sizes and keep the model consistency between training and inference, we apply window-based FFT with a set of fixed window sizes. In addition, channel attention is computed on both real and imaginary parts of the Fourier spectrum, which further improves restoration performance. The proposed WFCA block can effectively model image long-range dependency with acceptable complexity. Experiments on multiple denoising benchmarks demonstrate the leading performance of SFANet network.
Self Correspondence Distillation for End-to-End Weakly-Supervised Semantic Segmentation
Feb 27, 2023
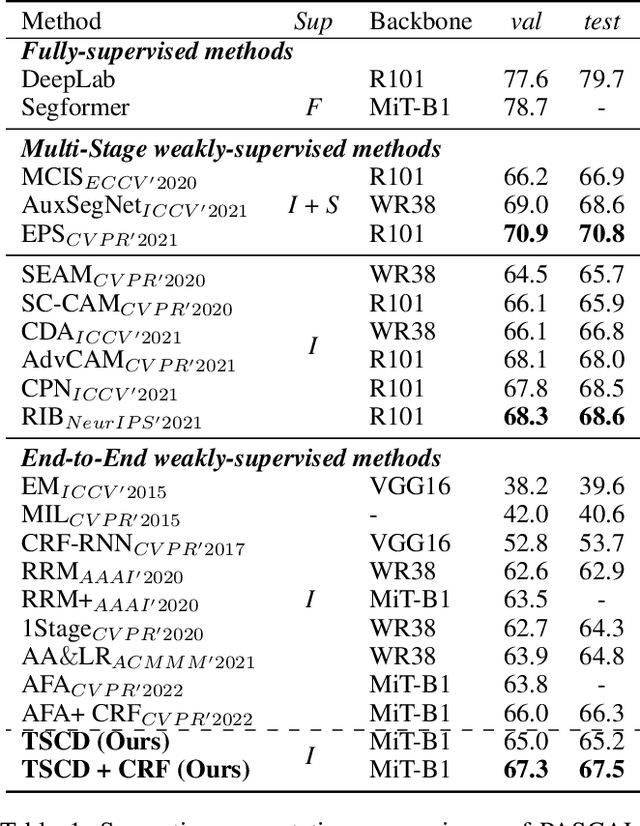
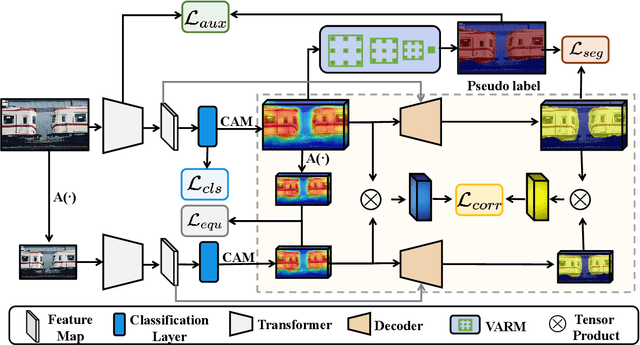
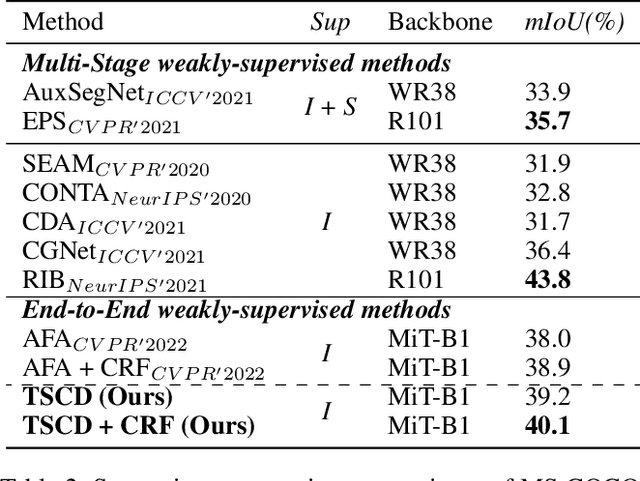
Efficiently training accurate deep models for weakly supervised semantic segmentation (WSSS) with image-level labels is challenging and important. Recently, end-to-end WSSS methods have become the focus of research due to their high training efficiency. However, current methods suffer from insufficient extraction of comprehensive semantic information, resulting in low-quality pseudo-labels and sub-optimal solutions for end-to-end WSSS. To this end, we propose a simple and novel Self Correspondence Distillation (SCD) method to refine pseudo-labels without introducing external supervision. Our SCD enables the network to utilize feature correspondence derived from itself as a distillation target, which can enhance the network's feature learning process by complementing semantic information. In addition, to further improve the segmentation accuracy, we design a Variation-aware Refine Module to enhance the local consistency of pseudo-labels by computing pixel-level variation. Finally, we present an efficient end-to-end Transformer-based framework (TSCD) via SCD and Variation-aware Refine Module for the accurate WSSS task. Extensive experiments on the PASCAL VOC 2012 and MS COCO 2014 datasets demonstrate that our method significantly outperforms other state-of-the-art methods. Our code is available at {https://github.com/Rongtao-Xu/RepresentationLearning/tree/main/SCD-AAAI2023}.
Crowd Counting with Online Knowledge Learning
Mar 18, 2023
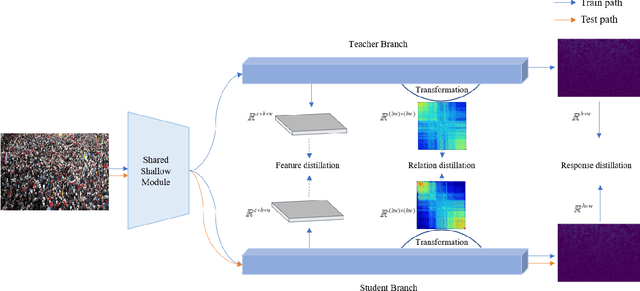

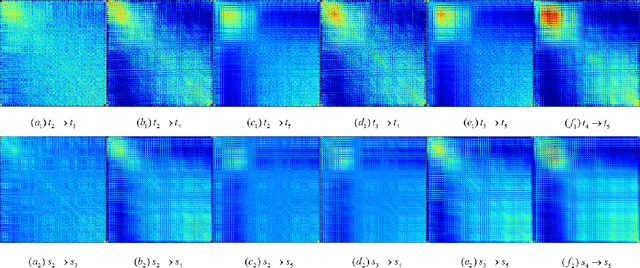
Efficient crowd counting models are urgently required for the applications in scenarios with limited computing resources, such as edge computing and mobile devices. A straightforward method to achieve this is knowledge distillation (KD), which involves using a trained teacher network to guide the training of a student network. However, this traditional two-phase training method can be time-consuming, particularly for large datasets, and it is also challenging for the student network to mimic the learning process of the teacher network. To overcome these challenges, we propose an online knowledge learning method for crowd counting. Our method builds an end-to-end training framework that integrates two independent networks into a single architecture, which consists of a shared shallow module, a teacher branch, and a student branch. This approach is more efficient than the two-stage training technique of traditional KD. Moreover, we propose a feature relation distillation method which allows the student branch to more effectively comprehend the evolution of inter-layer features by constructing a new inter-layer relationship matrix. It is combined with response distillation and feature internal distillation to enhance the transfer of mutually complementary information from the teacher branch to the student branch. Extensive experiments on four challenging crowd counting datasets demonstrate the effectiveness of our method which achieves comparable performance to state-of-the-art methods despite using far fewer parameters.
Predicting Molecule-Target Interaction by Learning Biomedical Network and Molecule Representations
Feb 02, 2023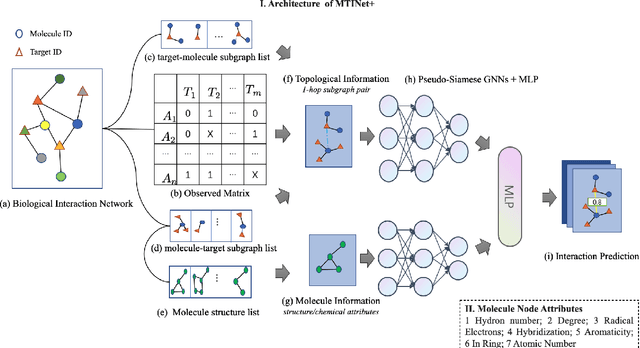

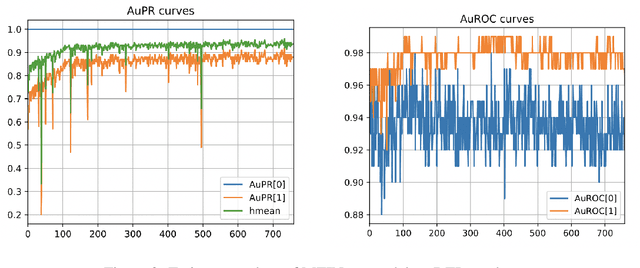
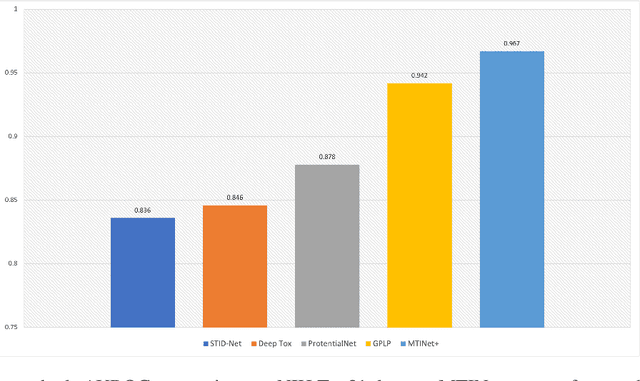
The study of molecule-target interaction is quite important for drug discovery in terms of target identification, pathway study, drug-drug interaction, etc. Most existing methodologies utilize either biomedical network information or molecule structural features to predict potential interaction link. However, the biomedical network information based methods usually suffer from cold start problem, while structure based methods often give limited performance due to the structure/interaction assumption and data quality. To address these issues, we propose a pseudo-siamese Graph Neural Network method, namely MTINet+, which learns both biomedical network topological and molecule structural/chemical information as representations to predict potential interaction of given molecule and target pair. In MTINet+, 1-hop subgraphs of given molecule and target pair are extracted from known interaction of biomedical network as topological information, meanwhile the molecule structural and chemical attributes are processed as molecule information. MTINet+ learns these two types of information as embedding features for predicting the pair link. In the experiments of different molecule-target interaction tasks, MTINet+ significantly outperforms over the state-of-the-art baselines. In addition, in our designed network sparsity experiments , MTINet+ shows strong robustness against different sparse biomedical networks.
Segmentation-based Information Extraction and Amalgamation in Fundus Images for Glaucoma Detection
Sep 23, 2022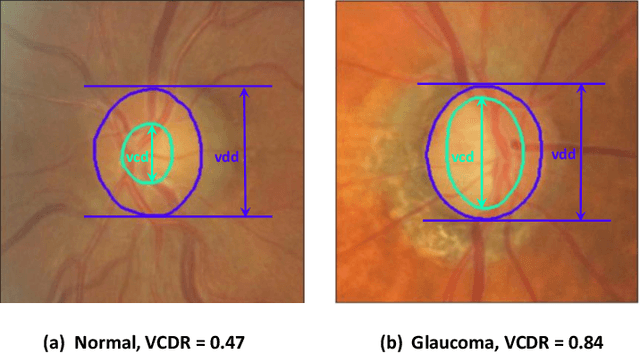

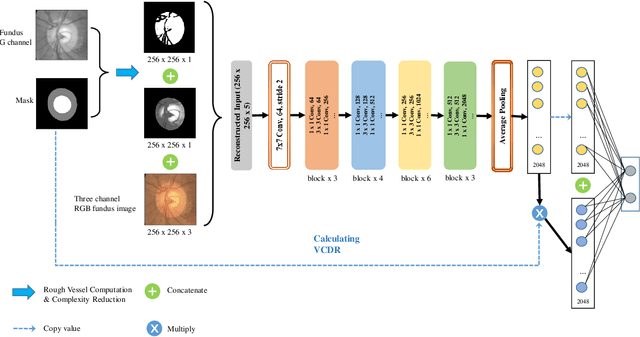

Glaucoma is a severe blinding disease, for which automatic detection methods are urgently needed to alleviate the scarcity of ophthalmologists. Many works have proposed to employ deep learning methods that involve the segmentation of optic disc and cup for glaucoma detection, in which the segmentation process is often considered merely as an upstream sub-task. The relationship between fundus images and segmentation masks in terms of joint decision-making in glaucoma assessment is rarely explored. We propose a novel segmentation-based information extraction and amalgamation method for the task of glaucoma detection, which leverages the robustness of segmentation masks without disregarding the rich information in the original fundus images. Experimental results on both private and public datasets demonstrate that our proposed method outperforms all models that utilize solely either fundus images or masks.