 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DREAM: Efficient Dataset Distillation by Representative Matching
Mar 09, 2023
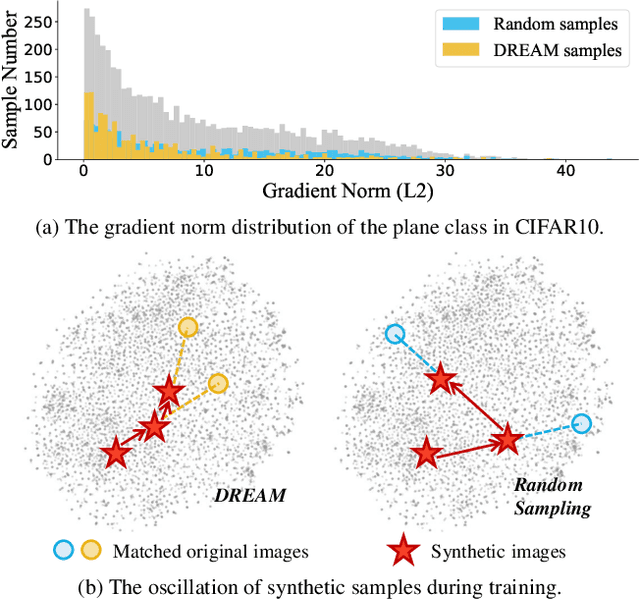
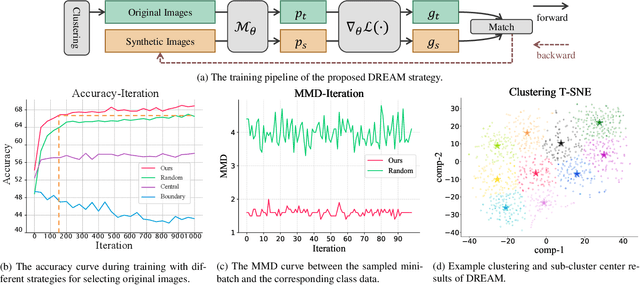
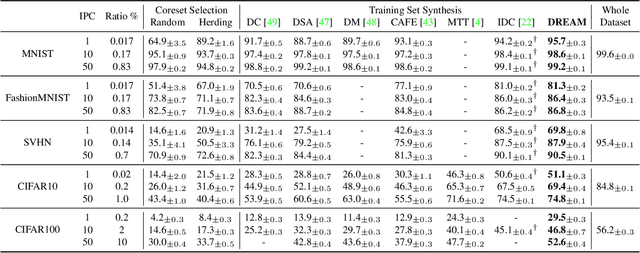
Dataset distillation aims to synthesize small datasets with little information loss from original large-scale ones for reducing storage and training costs. Recent state-of-the-art methods mainly constrain the sample synthesis process by matching synthetic images and the original ones regarding gradients, embedding distributions, or training trajectories. Although there are various matching objectives, currently the strategy for selecting original images is limited to naive random sampling. We argue that random sampling overlooks the evenness of the selected sample distribution, which may result in noisy or biased matching targets. Besides, the sample diversity is also not constrained by random sampling. These factors together lead to optimization instability in the distilling process and degrade the training efficiency. Accordingly, we propose a novel matching strategy named as \textbf{D}ataset distillation by \textbf{RE}present\textbf{A}tive \textbf{M}atching (DREAM), where only representative original images are selected for matching. DREAM is able to be easily plugged into popular dataset distillation frameworks and reduce the distilling iterations by more than 8 times without performance drop. Given sufficient training time, DREAM further provides significant improvements and achieves state-of-the-art performances.
Dominating Set Database Selection for Visual Place Recognition
Mar 09, 2023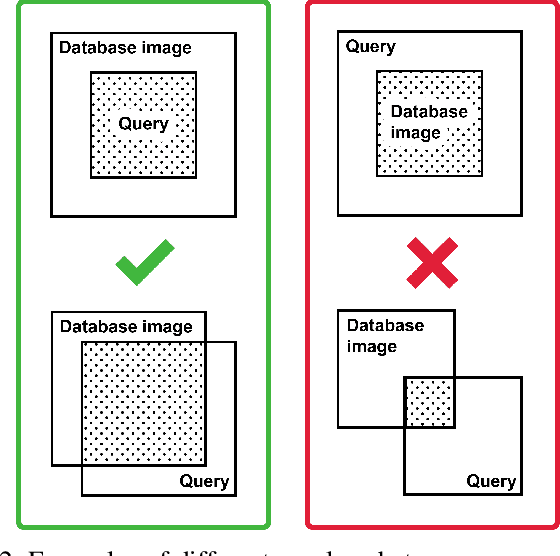


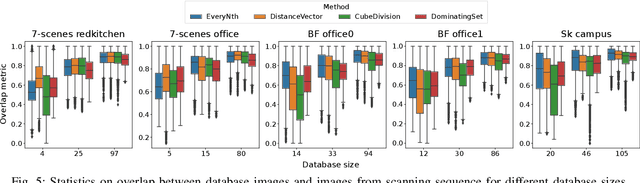
This paper presents an approach for creating a visual place recognition (VPR) database for localization in indoor environments from RGBD scanning sequences. The proposed approach is formulated as a minimization problem in terms of dominating set algorithm for graph, constructed from spatial information, and referred as DominatingSet. Our algorithm shows better scene coverage in comparison to other methodologies that are used for database creation. Also, we demonstrate that using DominatingSet, a database size could be up to 250-1400 times smaller than the original scanning sequence while maintaining a recall rate of more than 80% on testing sequences. We evaluated our algorithm on 7-scenes and BundleFusion datasets and an additionally recorded sequence in a highly repetitive office setting. In addition, the database selection can produce weakly-supervised labels for fine-tuning neural place recognition algorithms to particular settings, improving even more their accuracy. The paper also presents a fully automated pipeline for VPR database creation from RGBD scanning sequences, as well as a set of metrics for VPR database evaluation. The code and released data are available on our web-page~ -- https://prime-slam.github.io/place-recognition-db/
Data-dependent Generalization Bounds via Variable-Size Compressibility
Mar 09, 2023In this paper, we establish novel data-dependent upper bounds on the generalization error through the lens of a "variable-size compressibility" framework that we introduce newly here. In this framework, the generalization error of an algorithm is linked to a variable-size 'compression rate' of its input data. This is shown to yield bounds that depend on the empirical measure of the given input data at hand, rather than its unknown distribution. Our new generalization bounds that we establish are tail bounds, tail bounds on the expectation, and in-expectations bounds. Moreover, it is shown that our framework also allows to derive general bounds on any function of the input data and output hypothesis random variables. In particular, these general bounds are shown to subsume and possibly improve over several existing PAC-Bayes and data-dependent intrinsic dimension-based bounds that are recovered as special cases, thus unveiling a unifying character of our approach. For instance, a new data-dependent intrinsic dimension based bounds is established, which connects the generalization error to the optimization trajectories and reveals various interesting connections with rate-distortion dimension of process, R\'enyi information dimension of process, and metric mean dimension.
Multispectral Image Compression Based on HEVC Using Pel-Recursive Inter-Band Prediction
Mar 09, 2023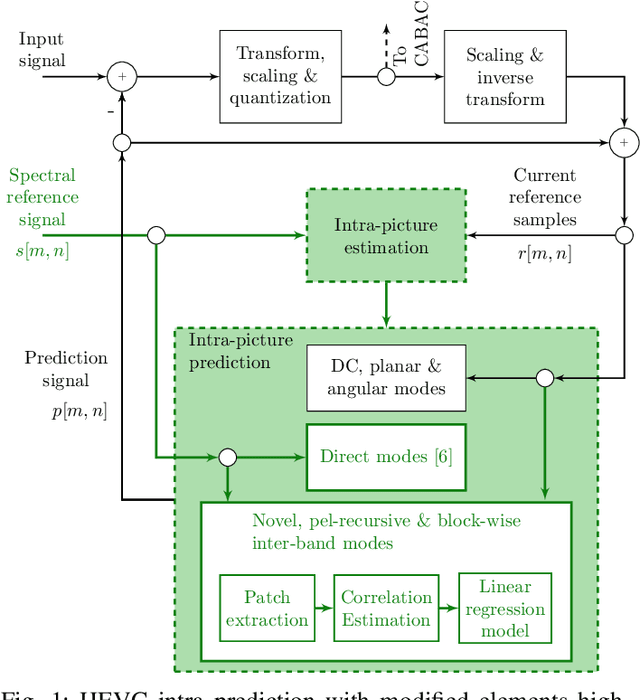
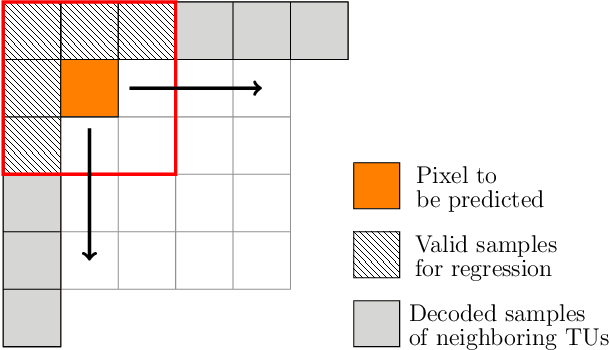
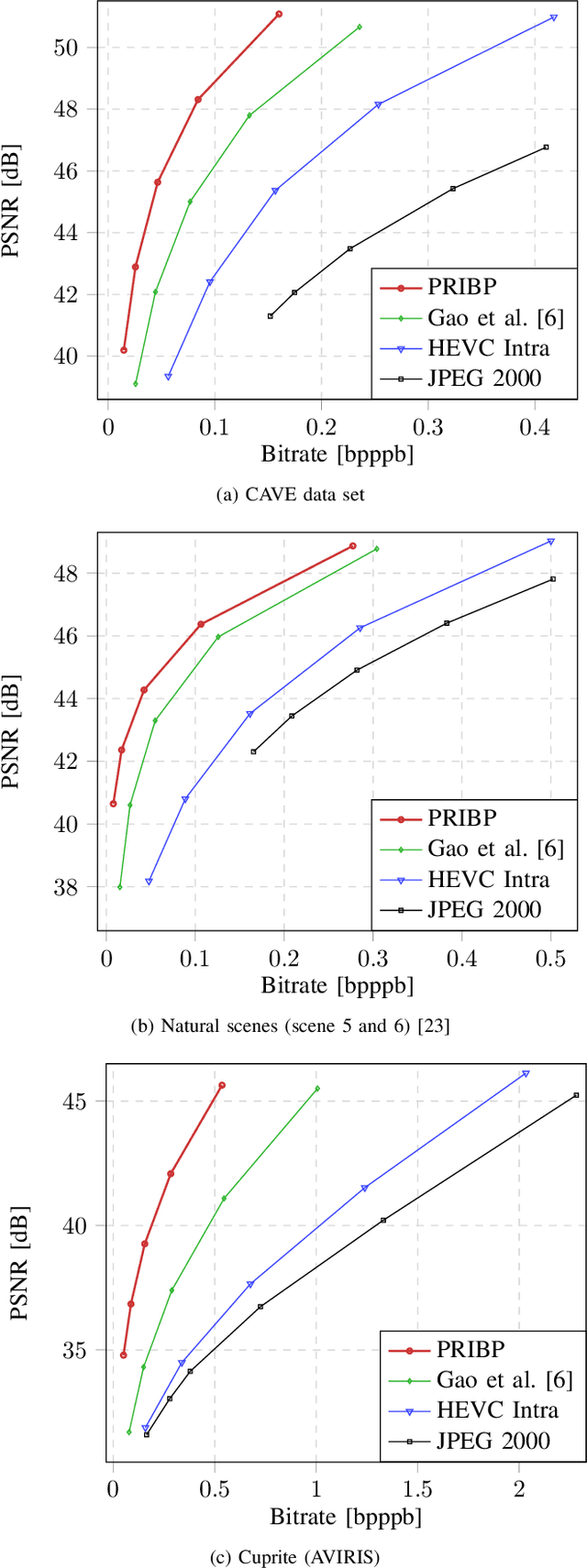

Recent developments in optical sensors enable a wide range of applications for multispectral imaging, e.g., in surveillance, optical sorting, and life-science instrumentation. Increasing spatial and spectral resolution allows creating higher quality products, however, it poses challenges in handling such large amounts of data. Consequently, specialized compression techniques for multispectral images are required. High Efficiency Video Coding (HEVC) is known to be the state of the art in efficiency for both video coding and still image coding. In this paper, we propose a cross-spectral compression scheme for efficiently coding multispectral data based on HEVC. Extending intra picture prediction by a novel inter-band predictor, spectral as well as spatial redundancies can be effectively exploited. Dependencies among the current band and further spectral references are considered jointly by adaptive linear regression modeling. The proposed backward prediction scheme does not require additional side information for decoding. We show that our novel approach is able to outperform state-of-the-art lossy compression techniques in terms of rate-distortion performance. On different data sets, average Bj{\o}ntegaard delta rate savings of 82 % and 55 % compared to HEVC and a reference method from literature are achieved, respectively.
* 6 pages, 4 figures, 1 table; Originally published as conference paper at IEEE MMSP 2020
NoiseCAM: Explainable AI for the Boundary Between Noise and Adversarial Attacks
Mar 09, 2023
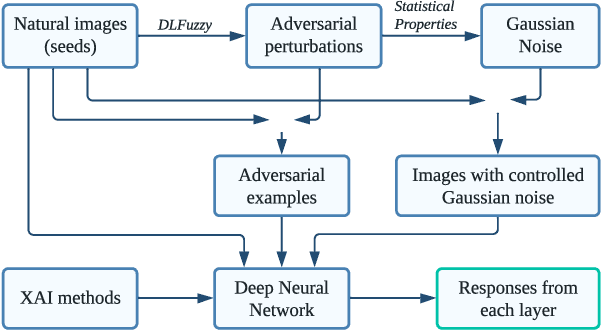
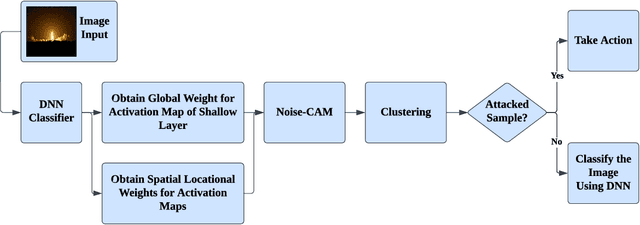
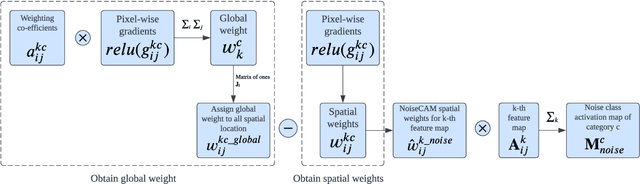
Deep Learning (DL) and Deep Neural Networks (DNNs) are widely used in various domains. However, adversarial attacks can easily mislead a neural network and lead to wrong decisions. Defense mechanisms are highly preferred in safety-critical applications. In this paper, firstly, we use the gradient class activation map (GradCAM) to analyze the behavior deviation of the VGG-16 network when its inputs are mixed with adversarial perturbation or Gaussian noise. In particular, our method can locate vulnerable layers that are sensitive to adversarial perturbation and Gaussian noise. We also show that the behavior deviation of vulnerable layers can be used to detect adversarial examples. Secondly, we propose a novel NoiseCAM algorithm that integrates information from globally and pixel-level weighted class activation maps. Our algorithm is susceptible to adversarial perturbations and will not respond to Gaussian random noise mixed in the inputs. Third, we compare detecting adversarial examples using both behavior deviation and NoiseCAM, and we show that NoiseCAM outperforms behavior deviation modeling in its overall performance. Our work could provide a useful tool to defend against certain adversarial attacks on deep neural networks.
Fitting Low-rank Models on Egocentrically Sampled Partial Networks
Mar 09, 2023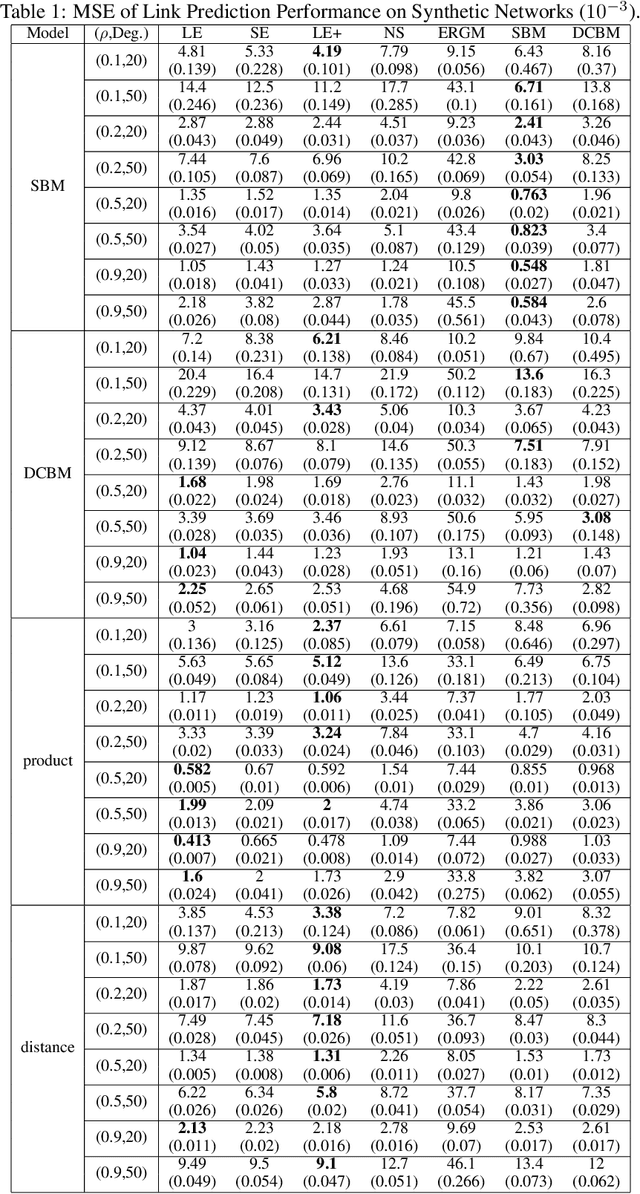
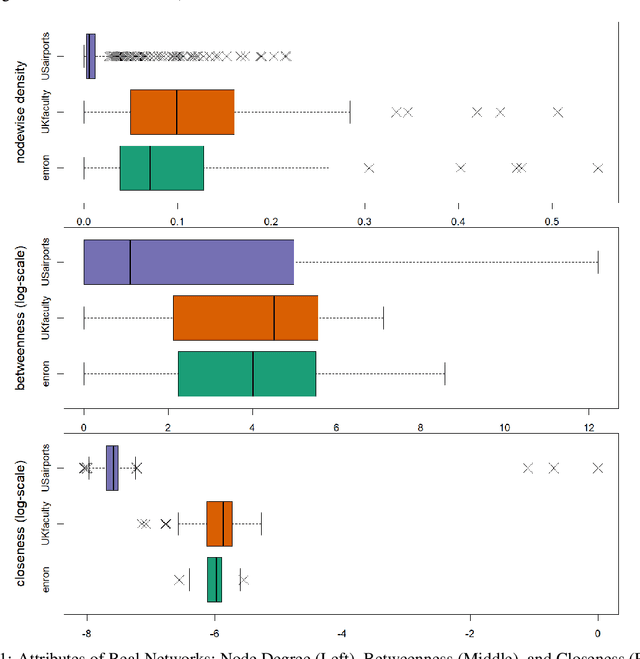
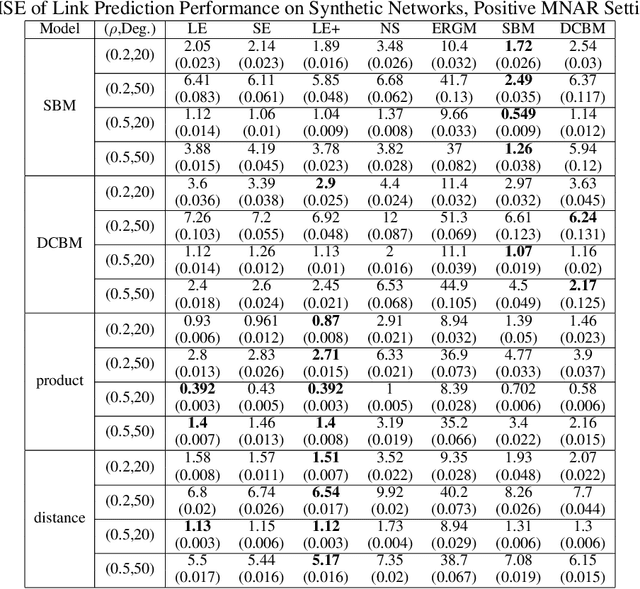
The statistical modeling of random networks has been widely used to uncover interaction mechanisms in complex systems and to predict unobserved links in real-world networks. In many applications, network connections are collected via egocentric sampling: a subset of nodes is sampled first, after which all links involving this subset are recorded; all other information is missing. Compared with the assumption of ``uniformly missing at random", egocentrically sampled partial networks require specially designed modeling strategies. Current statistical methods are either computationally infeasible or based on intuitive designs without theoretical justification. Here, we propose an approach to fit general low-rank models for egocentrically sampled networks, which include several popular network models. This method is based on graph spectral properties and is computationally efficient for large-scale networks. It results in consistent recovery of missing subnetworks due to egocentric sampling for sparse networks. To our knowledge, this method offers the first theoretical guarantee for egocentric partial network estimation in the scope of low-rank models. We evaluate the technique on several synthetic and real-world networks and show that it delivers competitive performance in link prediction tasks.
Sparse and Local Networks for Hypergraph Reasoning
Mar 09, 2023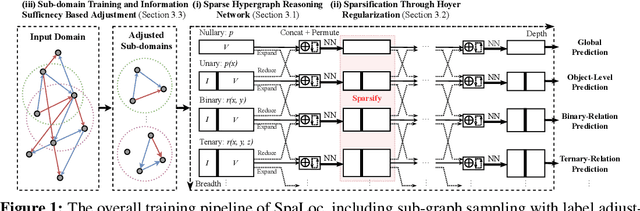
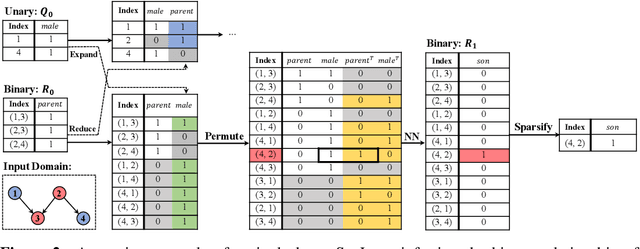
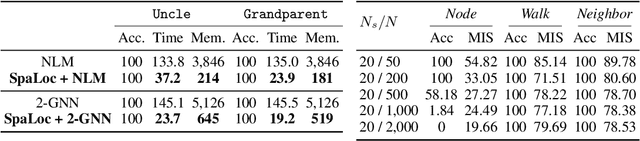
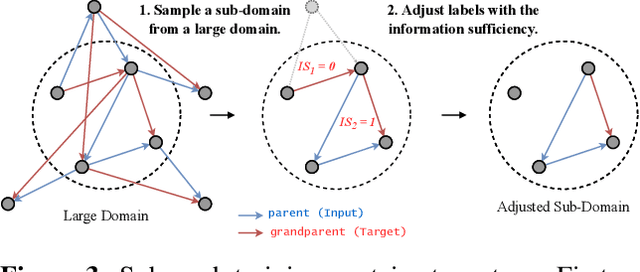
Reasoning about the relationships between entities from input facts (e.g., whether Ari is a grandparent of Charlie) generally requires explicit consideration of other entities that are not mentioned in the query (e.g., the parents of Charlie). In this paper, we present an approach for learning to solve problems of this kind in large, real-world domains, using sparse and local hypergraph neural networks (SpaLoc). SpaLoc is motivated by two observations from traditional logic-based reasoning: relational inferences usually apply locally (i.e., involve only a small number of individuals), and relations are usually sparse (i.e., only hold for a small percentage of tuples in a domain). We exploit these properties to make learning and inference efficient in very large domains by (1) using a sparse tensor representation for hypergraph neural networks, (2) applying a sparsification loss during training to encourage sparse representations, and (3) subsampling based on a novel information sufficiency-based sampling process during training. SpaLoc achieves state-of-the-art performance on several real-world, large-scale knowledge graph reasoning benchmarks, and is the first framework for applying hypergraph neural networks on real-world knowledge graphs with more than 10k nodes.
ALIST: Associative Logic for Inference, Storage and Transfer. A Lingua Franca for Inference on the Web
Mar 12, 2023
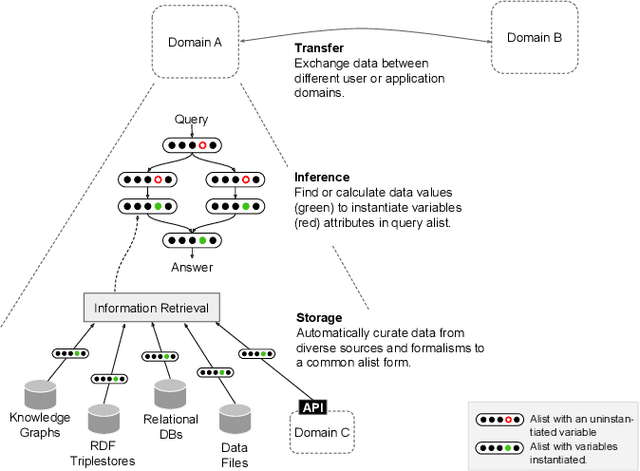
Recent developments in support for constructing knowledge graphs have led to a rapid rise in their creation both on the Web and within organisations. Added to existing sources of data, including relational databases, APIs, etc., there is a strong demand for techniques to query these diverse sources of knowledge. While formal query languages, such as SPARQL, exist for querying some knowledge graphs, users are required to know which knowledge graphs they need to query and the unique resource identifiers of the resources they need. Although alternative techniques in neural information retrieval embed the content of knowledge graphs in vector spaces, they fail to provide the representation and query expressivity needed (e.g. inability to handle non-trivial aggregation functions such as regression). We believe that a lingua franca, i.e. a formalism, that enables such representational flexibility will increase the ability of intelligent automated agents to combine diverse data sources by inference. Our work proposes a flexible representation (alists) to support intelligent federated querying of diverse knowledge sources. Our contribution includes (1) a formalism that abstracts the representation of queries from the specific query language of a knowledge graph; (2) a representation to dynamically curate data and functions (operations) to perform non-trivial inference over diverse knowledge sources; (3) a demonstration of the expressiveness of alists to represent the diversity of representational formalisms, including SPARQL queries, and more generally first-order logic expressions.
Large Language Models Can Be Easily Distracted by Irrelevant Context
Jan 31, 2023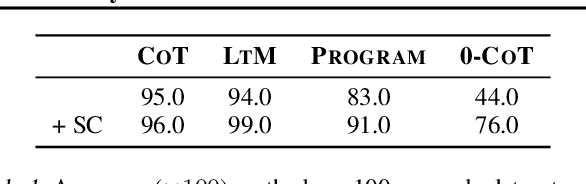
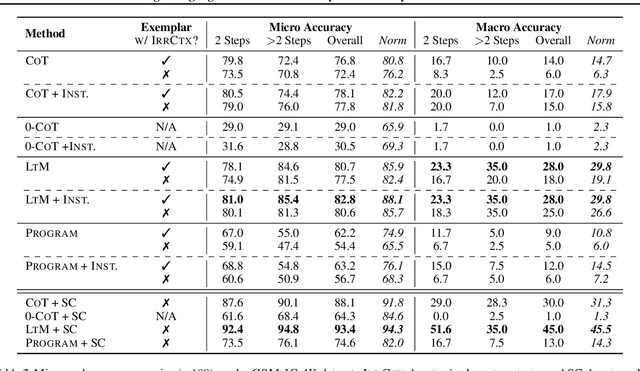

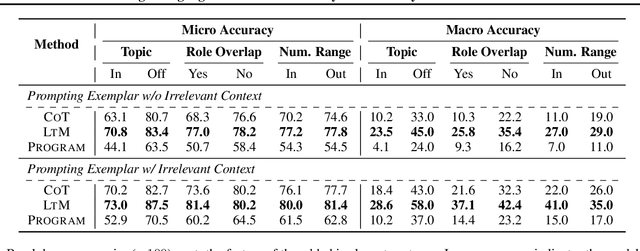
Large language models have achieved impressive performance on various natural language processing tasks. However, so far they have been evaluated primarily on benchmarks where all information in the input context is relevant for solving the task. In this work, we investigate the distractibility of large language models, i.e., how the model problem-solving accuracy can be influenced by irrelevant context. In particular, we introduce Grade-School Math with Irrelevant Context (GSM-IC), an arithmetic reasoning dataset with irrelevant information in the problem description. We use this benchmark to measure the distractibility of cutting-edge prompting techniques for large language models, and find that the model performance is dramatically decreased when irrelevant information is included. We also identify several approaches for mitigating this deficiency, such as decoding with self-consistency and adding to the prompt an instruction that tells the language model to ignore the irrelevant information.
AI model GPT-3 (dis)informs us better than humans
Jan 31, 2023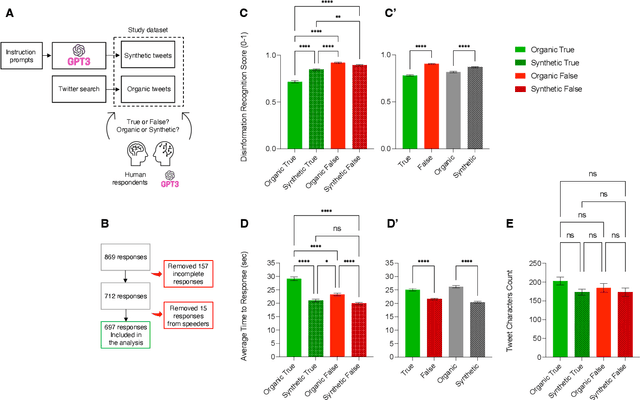
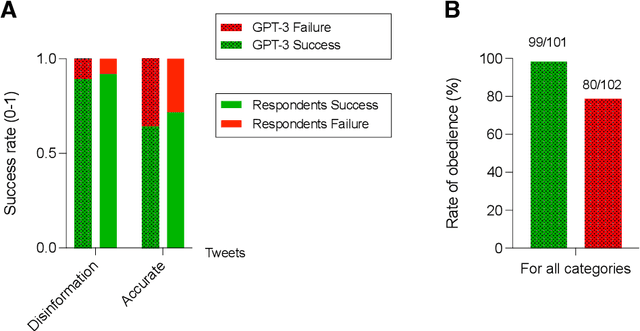
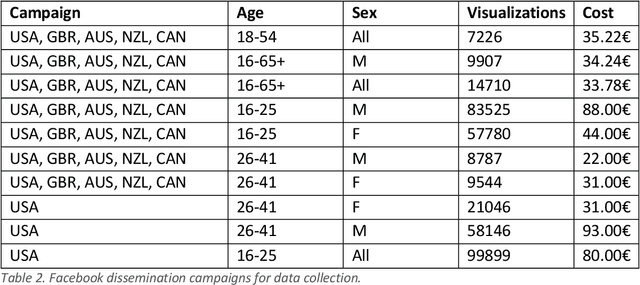
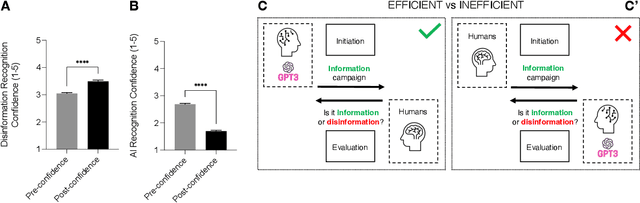
Artificial intelligence is changing the way we create and evaluate information, and this is happening during an infodemic, which has been having dramatic effects on global health. In this paper we evaluate whether recruited individuals can distinguish disinformation from accurate information, structured in the form of tweets, and determine whether a tweet is organic or synthetic, i.e., whether it has been written by a Twitter user or by the AI model GPT-3. Our results show that GPT-3 is a double-edge sword, which, in comparison with humans, can produce accurate information that is easier to understand, but can also produce more compelling disinformation. We also show that humans cannot distinguish tweets generated by GPT-3 from tweets written by human users. Starting from our results, we reflect on the dangers of AI for disinformation, and on how we can improve information campaigns to benefit global health.