 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MedLocker: A Transferable Adversarial Watermarking for Preventing Unauthorized Analysis of Medical Image Dataset
Mar 20, 2023
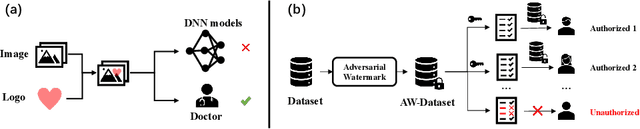
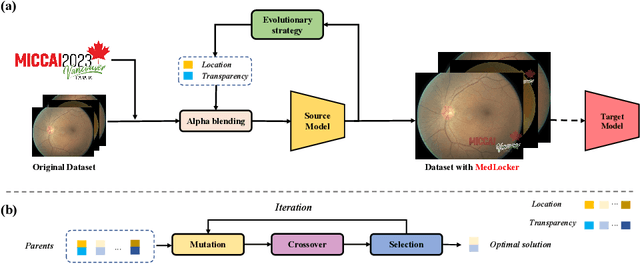
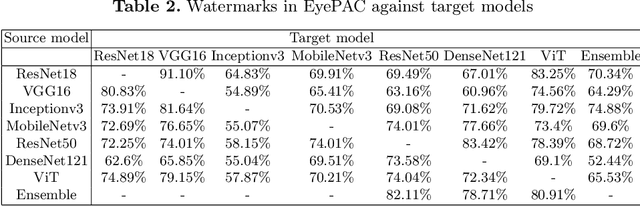

The collection of medical image datasets is a demanding and laborious process that requires significant resources. Furthermore, these medical datasets may contain personally identifiable information, necessitating measures to ensure that unauthorized access is prevented. Failure to do so could violate the intellectual property rights of the dataset owner and potentially compromise the privacy of patients. As a result, safeguarding medical datasets and preventing unauthorized usage by AI diagnostic models is a pressing challenge. To address this challenge, we propose a novel visible adversarial watermarking method for medical image copyright protection, called MedLocker. Our approach involves continuously optimizing the position and transparency of a watermark logo, which reduces the performance of the target model, leading to incorrect predictions. Importantly, we ensure that our method minimizes the impact on clinical visualization by constraining watermark positions using semantical masks (WSM), which are bounding boxes of lesion regions based on semantic segmentation. To ensure the transferability of the watermark across different models, we verify the cross-model transferability of the watermark generated on a single model. Additionally, we generate a unique watermark parameter list each time, which can be used as a certification to verify the authorization. We evaluate the performance of MedLocker on various mainstream backbones and validate the feasibility of adversarial watermarking for copyright protection on two widely-used diabetic retinopathy detection datasets. Our results demonstrate that MedLocker can effectively protect the copyright of medical datasets and prevent unauthorized users from analyzing medical images with AI diagnostic models.
Induced Feature Selection by Structured Pruning
Mar 20, 2023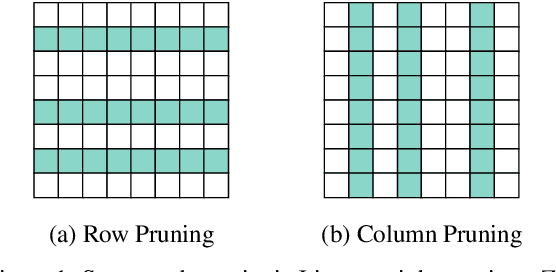
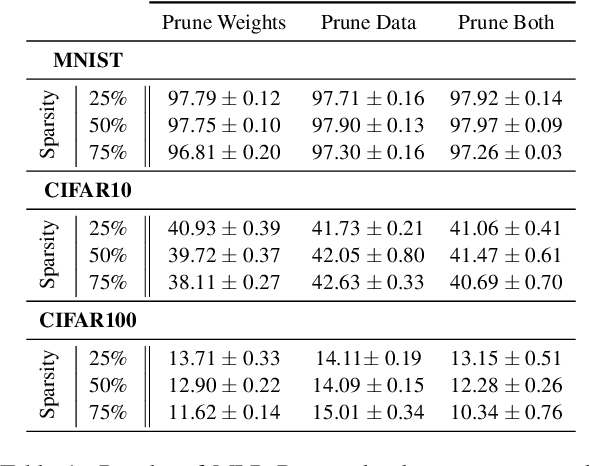
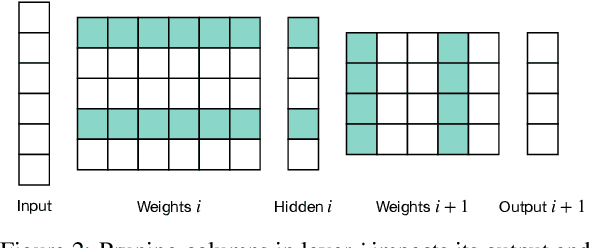
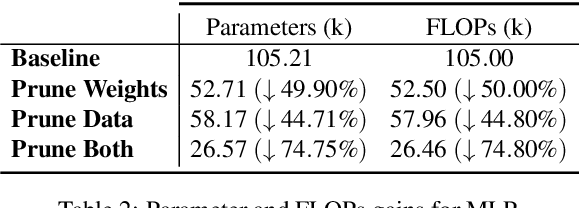
The advent of sparsity inducing techniques in neural networks has been of a great help in the last few years. Indeed, those methods allowed to find lighter and faster networks, able to perform more efficiently in resource-constrained environment such as mobile devices or highly requested servers. Such a sparsity is generally imposed on the weights of neural networks, reducing the footprint of the architecture. In this work, we go one step further by imposing sparsity jointly on the weights and on the input data. This can be achieved following a three-step process: 1) impose a certain structured sparsity on the weights of the network; 2) track back input features corresponding to zeroed blocks of weight; 3) remove useless weights and input features and retrain the network. Performing pruning both on the network and on input data not only allows for extreme reduction in terms of parameters and operations but can also serve as an interpretation process. Indeed, with the help of data pruning, we now have information about which input feature is useful for the network to keep its performance. Experiments conducted on a variety of architectures and datasets: MLP validated on MNIST, CIFAR10/100 and ConvNets (VGG16 and ResNet18), validated on CIFAR10/100 and CALTECH101 respectively, show that it is possible to achieve additional gains in terms of total parameters and in FLOPs by performing pruning on input data, while also increasing accuracy.
Learning Behavior Recognition in Smart Classroom with Multiple Students Based on YOLOv5
Mar 20, 2023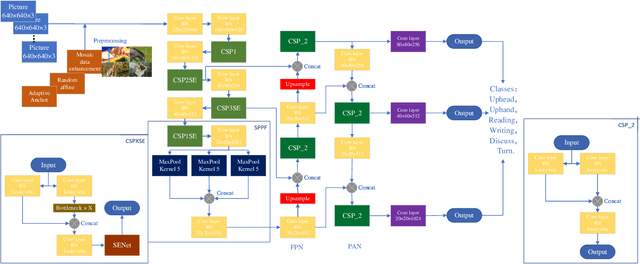
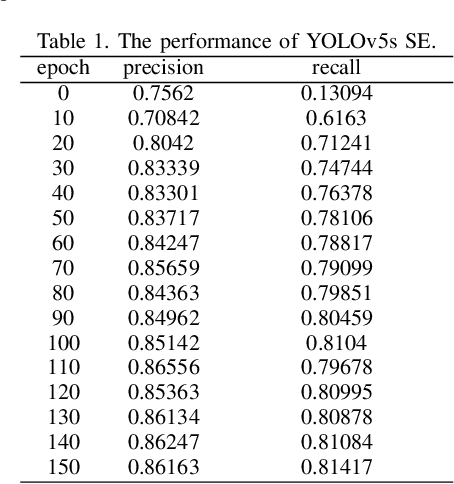
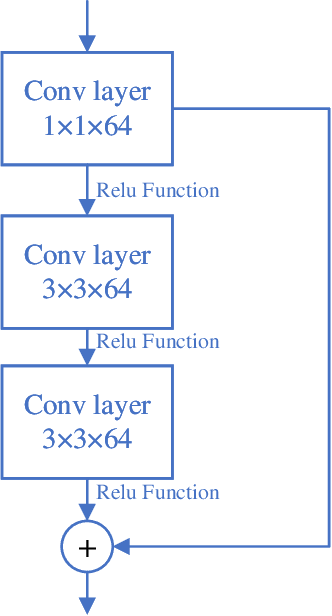
Deep learning-based computer vision technology has grown stronger in recent years, and cross-fertilization using computer vision technology has been a popular direction in recent years. The use of computer vision technology to identify students' learning behavior in the classroom can reduce the workload of traditional teachers in supervising students in the classroom, and ensure greater accuracy and comprehensiveness. However, existing student learning behavior detection systems are unable to track and detect multiple targets precisely, and the accuracy of learning behavior recognition is not high enough to meet the existing needs for the accurate recognition of student behavior in the classroom. To solve this problem, we propose a YOLOv5s network structure based on you only look once (YOLO) algorithm to recognize and analyze students' classroom behavior in this paper. Firstly, the input images taken in the smart classroom are pre-processed. Then, the pre-processed image is fed into the designed YOLOv5 networks to extract deep features through convolutional layers, and the Squeeze-and-Excitation (SE) attention detection mechanism is applied to reduce the weight of background information in the recognition process. Finally, the extracted features are classified by the Feature Pyramid Networks (FPN) and Path Aggregation Network (PAN) structures. Multiple groups of experiments were performed to compare with traditional learning behavior recognition methods to validate the effectiveness of the proposed method. When compared with YOLOv4, the proposed method is able to improve the mAP performance by 11%.
Uncertainty-aware deep learning for digital twin-driven monitoring: Application to fault detection in power lines
Mar 20, 2023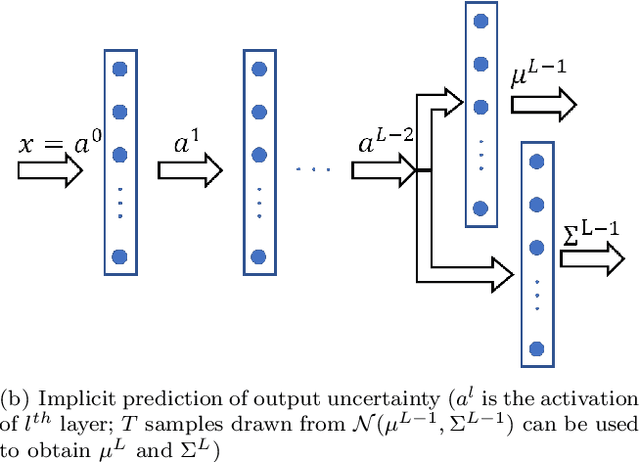
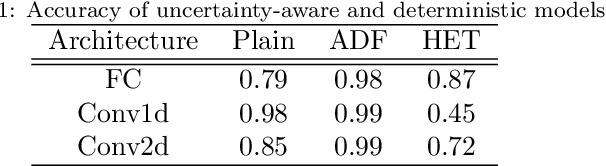
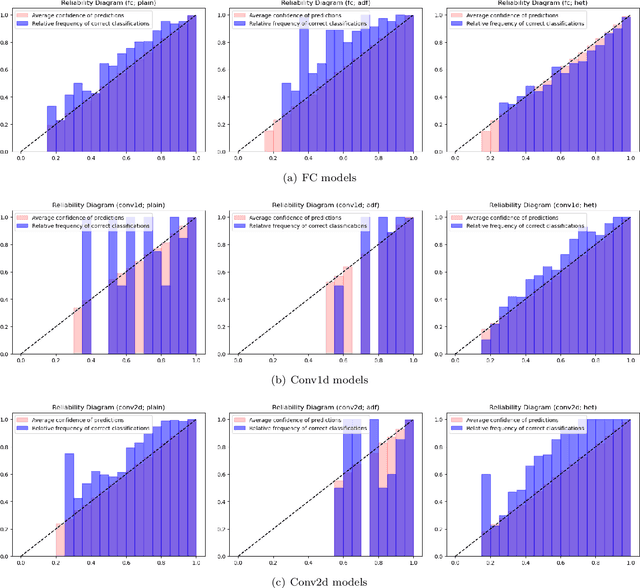
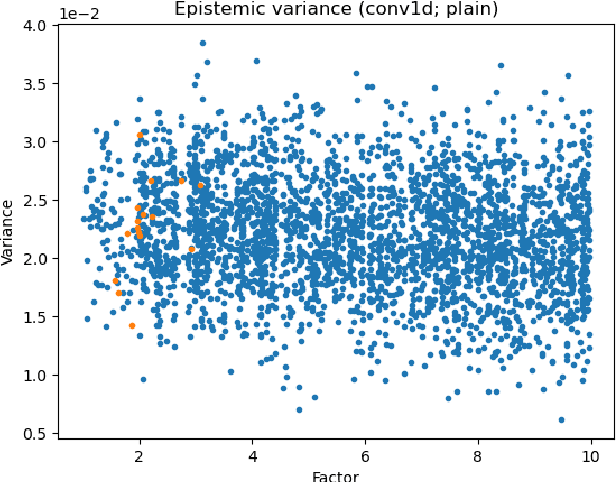
Deep neural networks (DNNs) are often coupled with physics-based models or data-driven surrogate models to perform fault detection and health monitoring of systems in the low data regime. These models serve as digital twins to generate large quantities of data to train DNNs which would otherwise be difficult to obtain from the real-life system. However, such models can exhibit parametric uncertainty that propagates to the generated data. In addition, DNNs exhibit uncertainty in the parameters learnt during training. In such a scenario, the performance of the DNN model will be influenced by the uncertainty in the physics-based model as well as the parameters of the DNN. In this article, we quantify the impact of both these sources of uncertainty on the performance of the DNN. We perform explicit propagation of uncertainty in input data through all layers of the DNN, as well as implicit prediction of output uncertainty to capture the former. Furthermore, we adopt Monte Carlo dropout to capture uncertainty in DNN parameters. We demonstrate the approach for fault detection of power lines with a physics-based model, two types of input data and three different neural network architectures. We compare the performance of such uncertainty-aware probabilistic models with their deterministic counterparts. The results show that the probabilistic models provide important information regarding the confidence of predictions, while also delivering an improvement in performance over deterministic models.
Two-Stream Joint-Training for Speaker Independent Acoustic-to-Articulatory Inversion
Feb 26, 2023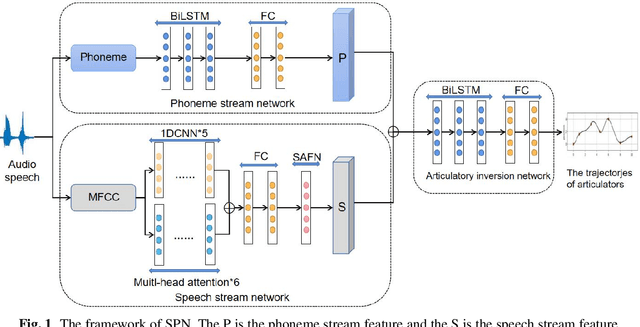
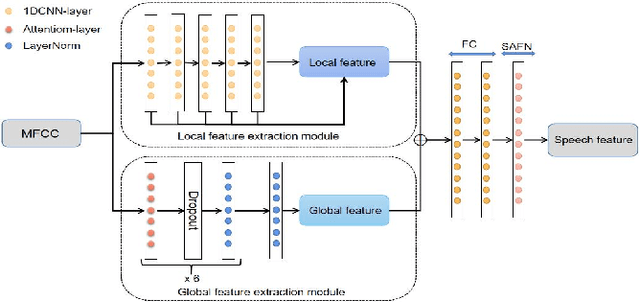
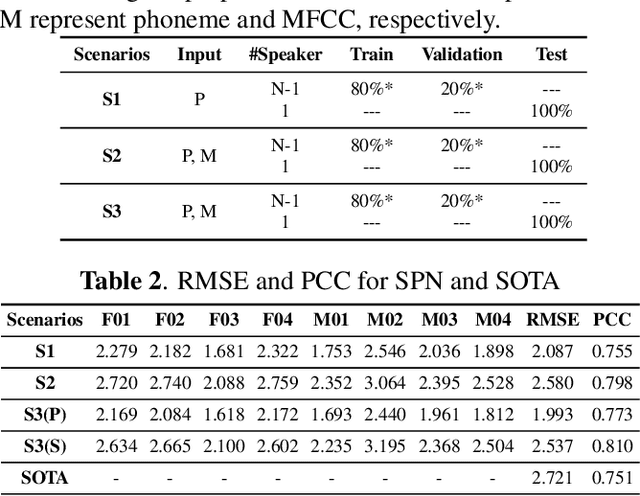
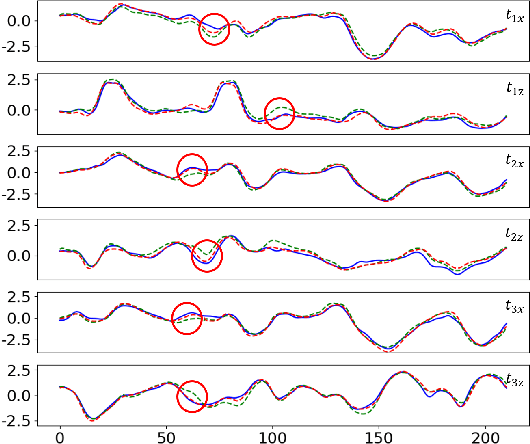
Acoustic-to-articulatory inversion (AAI) aims to estimate the parameters of articulators from speech audio. There are two common challenges in AAI, which are the limited data and the unsatisfactory performance in speaker independent scenario. Most current works focus on extracting features directly from speech and ignoring the importance of phoneme information which may limit the performance of AAI. To this end, we propose a novel network called SPN that uses two different streams to carry out the AAI task. Firstly, to improve the performance of speaker-independent experiment, we propose a new phoneme stream network to estimate the articulatory parameters as the phoneme features. To the best of our knowledge, this is the first work that extracts the speaker-independent features from phonemes to improve the performance of AAI. Secondly, in order to better represent the speech information, we train a speech stream network to combine the local features and the global features. Compared with state-of-the-art (SOTA), the proposed method reduces 0.18mm on RMSE and increases 6.0% on Pearson correlation coefficient in the speaker-independent experiment. The code has been released at https://github.com/liujinyu123/AAINetwork-SPN.
Invariant Representations of Embedded Simplicial Complexes
Feb 27, 2023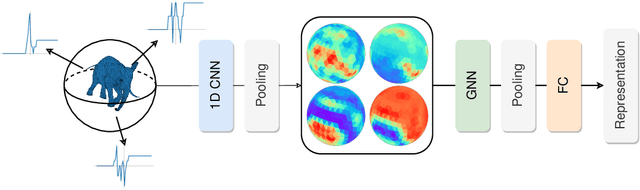

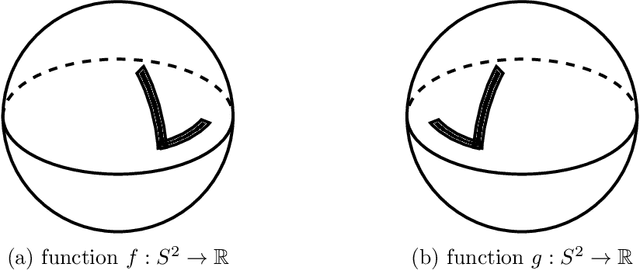

Analyzing embedded simplicial complexes, such as triangular meshes and graphs, is an important problem in many fields. We propose a new approach for analyzing embedded simplicial complexes in a subdivision-invariant and isometry-invariant way using only topological and geometric information. Our approach is based on creating and analyzing sufficient statistics and uses a graph neural network. We demonstrate the effectiveness of our approach using a synthetic mesh data set.
Data Dependent Regret Guarantees Against General Comparators for Full or Bandit Feedback
Mar 12, 2023We study the adversarial online learning problem and create a completely online algorithmic framework that has data dependent regret guarantees in both full expert feedback and bandit feedback settings. We study the expected performance of our algorithm against general comparators, which makes it applicable for a wide variety of problem scenarios. Our algorithm works from a universal prediction perspective and the performance measure used is the expected regret against arbitrary comparator sequences, which is the difference between our losses and a competing loss sequence. The competition class can be designed to include fixed arm selections, switching bandits, contextual bandits, periodic bandits or any other competition of interest. The sequences in the competition class are generally determined by the specific application at hand and should be designed accordingly. Our algorithm neither uses nor needs any preliminary information about the loss sequences and is completely online. Its performance bounds are data dependent, where any affine transform of the losses has no effect on the normalized regret.
A lightweight network for photovoltaic cell defect detection in electroluminescence images based on neural architecture search and knowledge distillation
Feb 15, 2023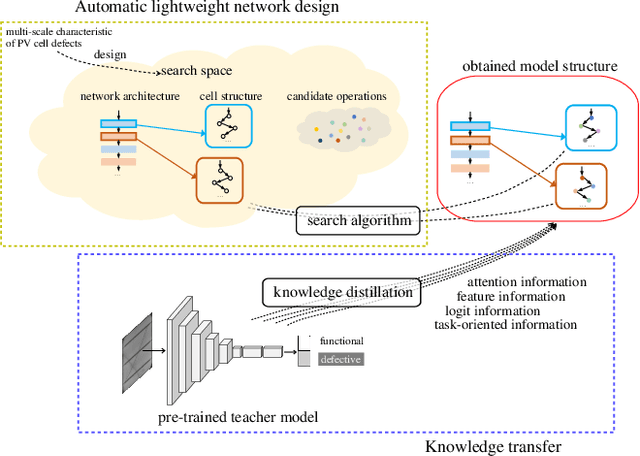
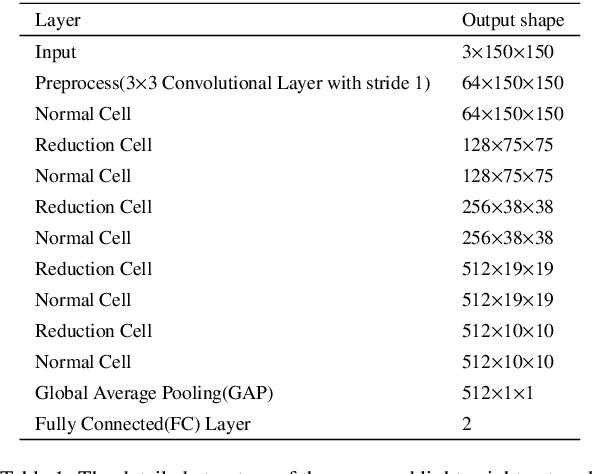
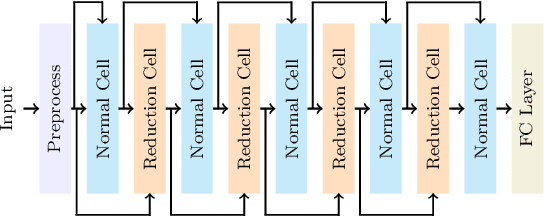
Nowadays, the rapid development of photovoltaic(PV) power stations requires increasingly reliable maintenance and fault diagnosis of PV modules in the field. Due to the effectiveness, convolutional neural network (CNN) has been widely used in the existing automatic defect detection of PV cells. However, the parameters of these CNN-based models are very large, which require stringent hardware resources and it is difficult to be applied in actual industrial projects. To solve these problems, we propose a novel lightweight high-performance model for automatic defect detection of PV cells in electroluminescence(EL) images based on neural architecture search and knowledge distillation. To auto-design an effective lightweight model, we introduce neural architecture search to the field of PV cell defect classification for the first time. Since the defect can be any size, we design a proper search structure of network to better exploit the multi-scale characteristic. To improve the overall performance of the searched lightweight model, we further transfer the knowledge learned by the existing pre-trained large-scale model based on knowledge distillation. Different kinds of knowledge are exploited and transferred, including attention information, feature information, logit information and task-oriented information. Experiments have demonstrated that the proposed model achieves the state-of-the-art performance on the public PV cell dataset of EL images under online data augmentation with accuracy of 91.74% and the parameters of 1.85M. The proposed lightweight high-performance model can be easily deployed to the end devices of the actual industrial projects and retain the accuracy.
Multistage Stochastic Optimization via Kernels
Mar 11, 2023
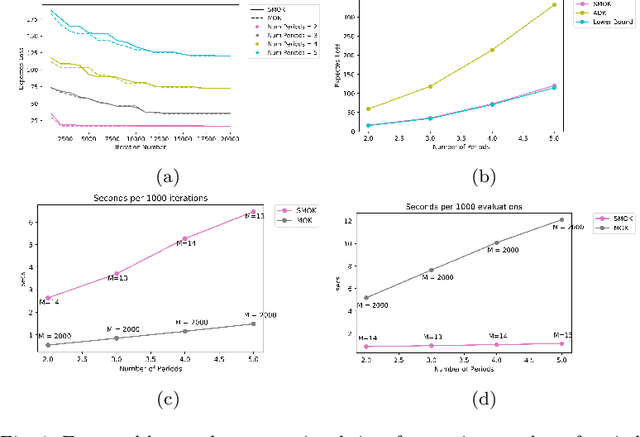
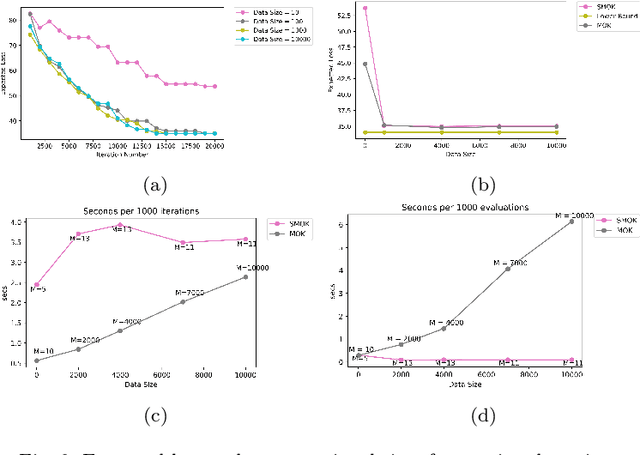

We develop a non-parametric, data-driven, tractable approach for solving multistage stochastic optimization problems in which decisions do not affect the uncertainty. The proposed framework represents the decision variables as elements of a reproducing kernel Hilbert space and performs functional stochastic gradient descent to minimize the empirical regularized loss. By incorporating sparsification techniques based on function subspace projections we are able to overcome the computational complexity that standard kernel methods introduce as the data size increases. We prove that the proposed approach is asymptotically optimal for multistage stochastic optimization with side information. Across various computational experiments on stochastic inventory management problems, {our method performs well in multidimensional settings} and remains tractable when the data size is large. Lastly, by computing lower bounds for the optimal loss of the inventory control problem, we show that the proposed method produces decision rules with near-optimal average performance.
Learning interpretable causal networks from very large datasets, application to 400,000 medical records of breast cancer patients
Mar 11, 2023Discovering causal effects is at the core of scientific investigation but remains challenging when only observational data is available. In practice, causal networks are difficult to learn and interpret, and limited to relatively small datasets. We report a more reliable and scalable causal discovery method (iMIIC), based on a general mutual information supremum principle, which greatly improves the precision of inferred causal relations while distinguishing genuine causes from putative and latent causal effects. We showcase iMIIC on synthetic and real-life healthcare data from 396,179 breast cancer patients from the US Surveillance, Epidemiology, and End Results program. More than 90\% of predicted causal effects appear correct, while the remaining unexpected direct and indirect causal effects can be interpreted in terms of diagnostic procedures, therapeutic timing, patient preference or socio-economic disparity. iMIIC's unique capabilities open up new avenues to discover reliable and interpretable causal networks across a range of research fields.