 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Humanoid Locomotion with Transformers
Mar 06, 2023
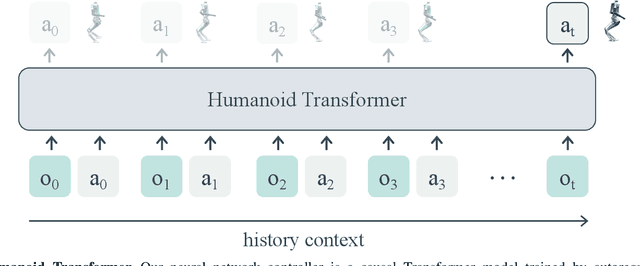



We present a sim-to-real learning-based approach for real-world humanoid locomotion. Our controller is a causal Transformer trained by autoregressive prediction of future actions from the history of observations and actions. We hypothesize that the observation-action history contains useful information about the world that a powerful Transformer model can use to adapt its behavior in-context, without updating its weights. We do not use state estimation, dynamics models, trajectory optimization, reference trajectories, or pre-computed gait libraries. Our controller is trained with large-scale model-free reinforcement learning on an ensemble of randomized environments in simulation and deployed to the real world in a zero-shot fashion. We evaluate our approach in high-fidelity simulation and successfully deploy it to the real robot as well. To the best of our knowledge, this is the first demonstration of a fully learning-based method for real-world full-sized humanoid locomotion.
Implementation of a noisy hyperlink removal system: A semantic and relatedness approach
Mar 06, 2023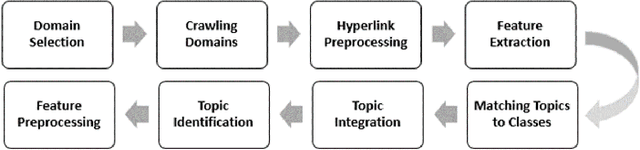
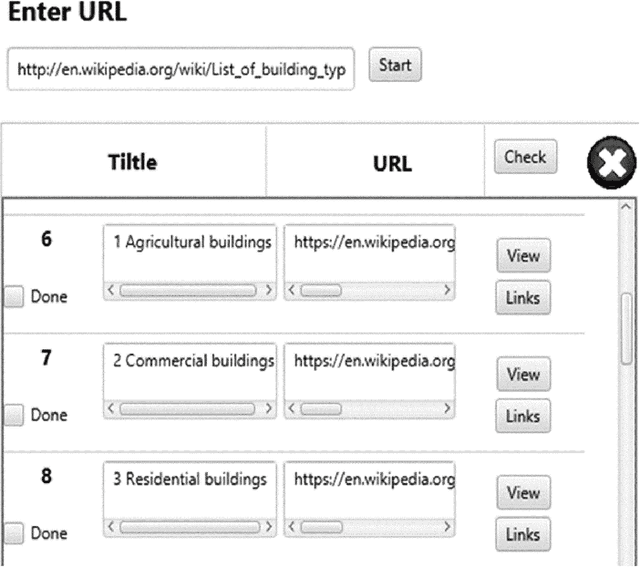
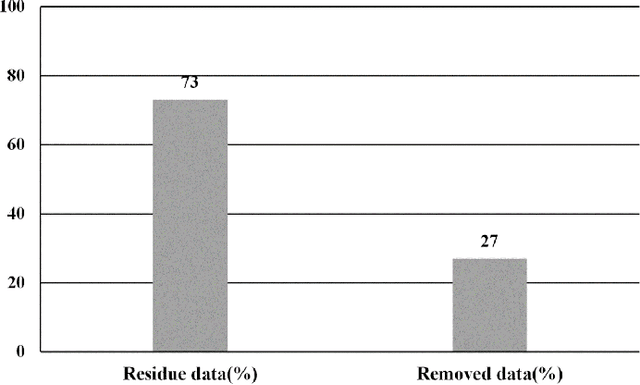
As the volume of data on the web grows, the web structure graph, which is a graph representation of the web, continues to evolve. The structure of this graph has gradually shifted from content-based to non-content-based. Furthermore, spam data, such as noisy hyperlinks, in the web structure graph adversely affect the speed and efficiency of information retrieval and link mining algorithms. Previous works in this area have focused on removing noisy hyperlinks using structural and string approaches. However, these approaches may incorrectly remove useful links or be unable to detect noisy hyperlinks in certain circumstances. In this paper, a data collection of hyperlinks is initially constructed using an interactive crawler. The semantic and relatedness structure of the hyperlinks is then studied through semantic web approaches and tools such as the DBpedia ontology. Finally, the removal process of noisy hyperlinks is carried out using a reasoner on the DBpedia ontology. Our experiments demonstrate the accuracy and ability of semantic web technologies to remove noisy hyperlinks
Scenario-Agnostic Zero-Trust Defense with Explainable Threshold Policy: A Meta-Learning Approach
Mar 06, 2023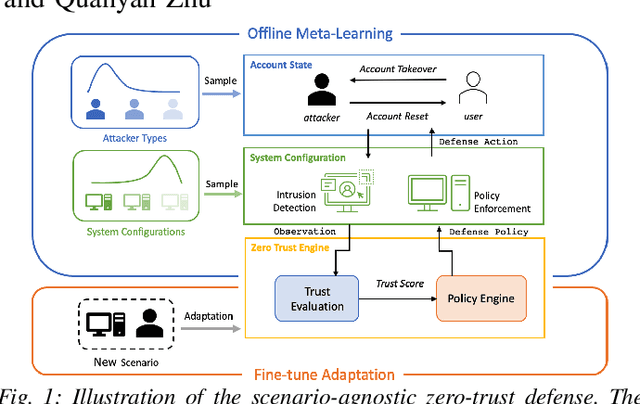
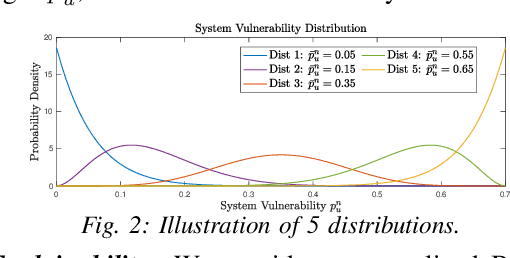
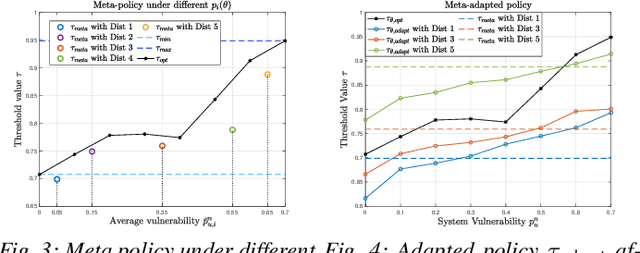
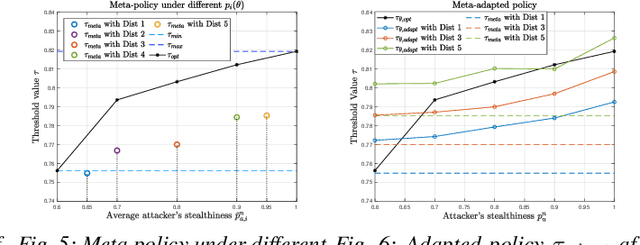
The increasing connectivity and intricate remote access environment have made traditional perimeter-based network defense vulnerable. Zero trust becomes a promising approach to provide defense policies based on agent-centric trust evaluation. However, the limited observations of the agent's trace bring information asymmetry in the decision-making. To facilitate the human understanding of the policy and the technology adoption, one needs to create a zero-trust defense that is explainable to humans and adaptable to different attack scenarios. To this end, we propose a scenario-agnostic zero-trust defense based on Partially Observable Markov Decision Processes (POMDP) and first-order Meta-Learning using only a handful of sample scenarios. The framework leads to an explainable and generalizable trust-threshold defense policy. To address the distribution shift between empirical security datasets and reality, we extend the model to a robust zero-trust defense minimizing the worst-case loss. We use case studies and real-world attacks to corroborate the results.
Learning Object Manipulation With Under-Actuated Impulse Generator Arrays
Mar 06, 2023

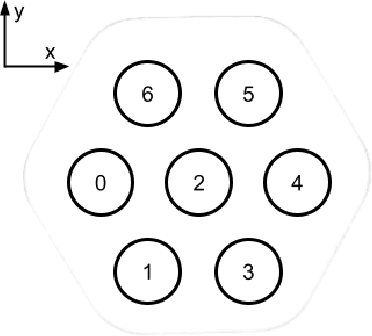
For more than half a century, vibratory bowl feeders have been the standard in automated assembly for singulation, orientation, and manipulation of small parts. Unfortunately, these feeders are expensive, noisy, and highly specialized on a single part design bases. We consider an alternative device and learning control method for singulation, orientation, and manipulation by means of seven fixed-position variable-energy solenoid impulse actuators located beneath a semi-rigid part supporting surface. Using computer vision to provide part pose information, we tested various machine learning (ML) algorithms to generate a control policy that selects the optimal actuator and actuation energy. Our manipulation test object is a 6-sided craps-style die. Using the most suitable ML algorithm, we were able to flip the die to any desired face 30.4\% of the time with a single impulse, and 51.3\% with two chosen impulses, versus a random policy succeeding 5.1\% of the time (that is, a randomly chosen impulse delivered by a randomly chosen solenoid).
Leveraging Scene Embeddings for Gradient-Based Motion Planning in Latent Space
Mar 06, 2023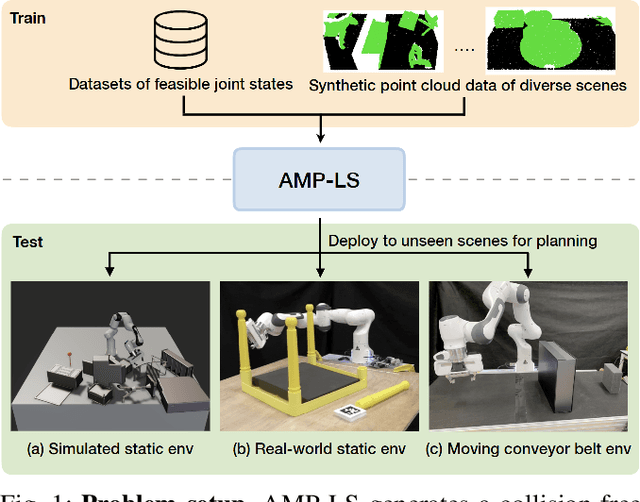
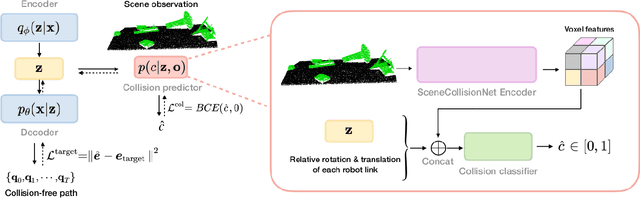

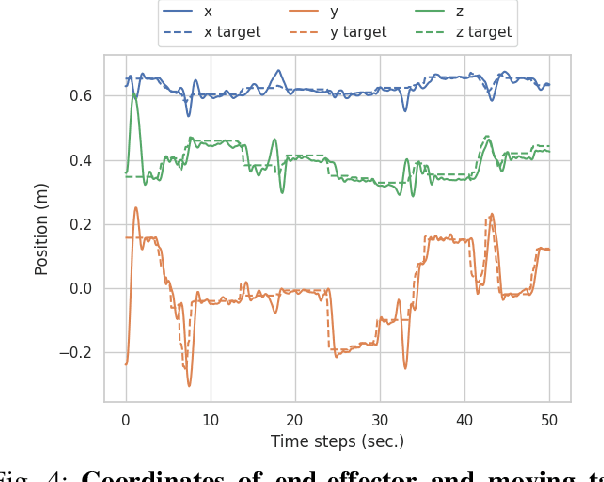
Motion planning framed as optimisation in structured latent spaces has recently emerged as competitive with traditional methods in terms of planning success while significantly outperforming them in terms of computational speed. However, the real-world applicability of recent work in this domain remains limited by the need to express obstacle information directly in state-space, involving simple geometric primitives. In this work we address this challenge by leveraging learned scene embeddings together with a generative model of the robot manipulator to drive the optimisation process. In addition, we introduce an approach for efficient collision checking which directly regularises the optimisation undertaken for planning. Using simulated as well as real-world experiments, we demonstrate that our approach, AMP-LS, is able to successfully plan in novel, complex scenes while outperforming traditional planning baselines in terms of computation speed by an order of magnitude. We show that the resulting system is fast enough to enable closed-loop planning in real-world dynamic scenes.
* Project website: https://amp-ls.github.io/
EvCenterNet: Uncertainty Estimation for Object Detection using Evidential Learning
Mar 06, 2023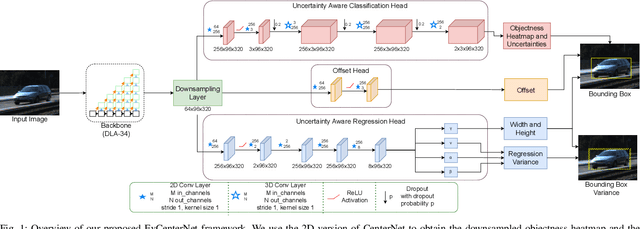

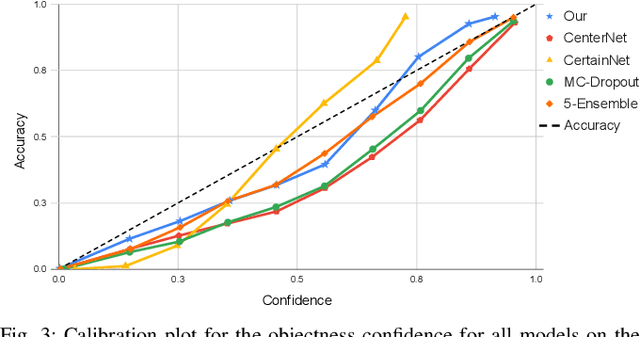
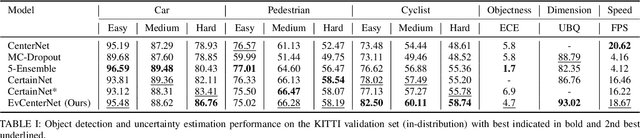
Uncertainty estimation is crucial in safety-critical settings such as automated driving as it provides valuable information for several downstream tasks including high-level decision-making and path planning. In this work, we propose EvCenterNet, a novel uncertainty-aware 2D object detection framework utilizing evidential learning to directly estimate both classification and regression uncertainties. To employ evidential learning for object detection, we devise a combination of evidential and focal loss functions for the sparse heatmap inputs. We introduce class-balanced weighting for regression and heatmap prediction to tackle the class imbalance encountered by evidential learning. Moreover, we propose a learning scheme to actively utilize the predicted heatmap uncertainties to improve the detection performance by focusing on the most uncertain points. We train our model on the KITTI dataset and evaluate it on challenging out-of-distribution datasets including BDD100K and nuImages. Our experiments demonstrate that our approach improves the precision and minimizes the execution time loss in relation to the base model.
Obfuscation of Human Micro-Doppler Signatures in Passive Wireless RADAR
Mar 06, 2023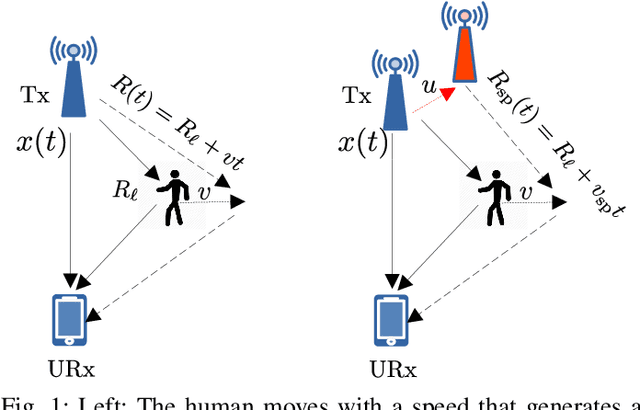
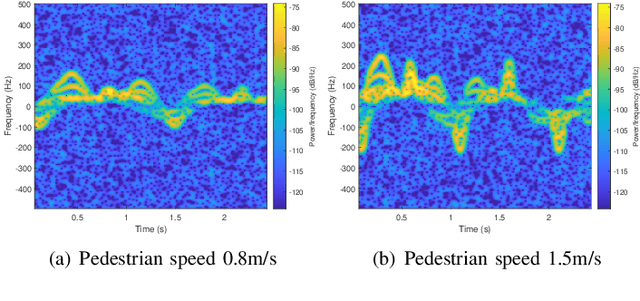
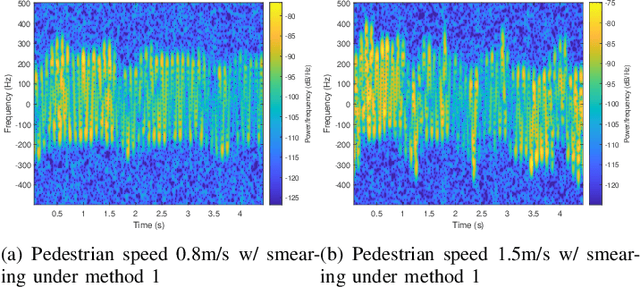
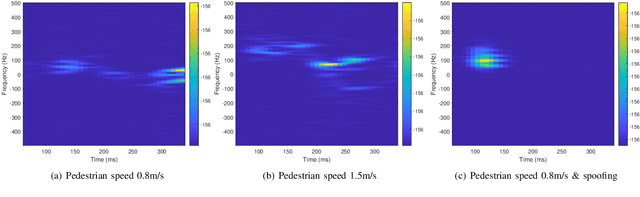
When wireless communication signals impinge on a moving human they are affected by micro-Doppler. A passive receiver of the resulting signals can calculate the spectrogram that produces different signatures depending on the human activity. This constitutes a significant privacy breach when the human is unaware of it. This paper presents a methodology for preventing this when we want to do so by injecting into the transmitted signal frequency variations that obfuscate the micro-Doppler signature. We assume a system that uses orthogonal frequency division multiplexing (OFDM) and a passive receiver that estimates the spectrogram based on the instantaneous channel state information (CSI). We analyze the impact of our approach on the received signal and we propose two strategies that do not affect the demodulation of the digital communication signal at the intended receiver. To evaluate the performance of our approach we use an IEEE 802.11-based OFDM system and realistic human signal reflection models.
Naming Objects for Vision-and-Language Manipulation
Mar 06, 2023
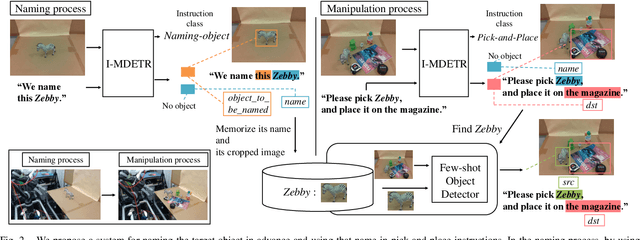
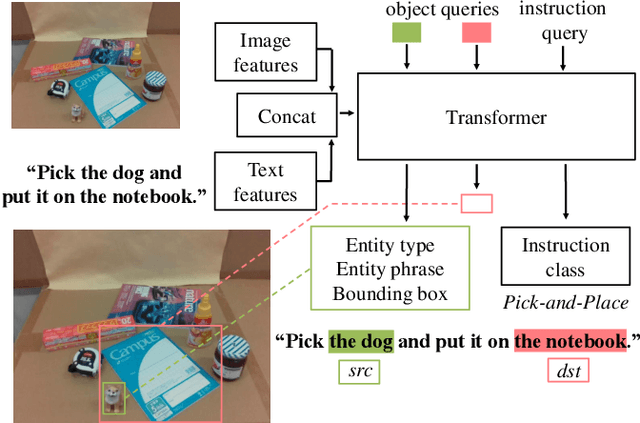
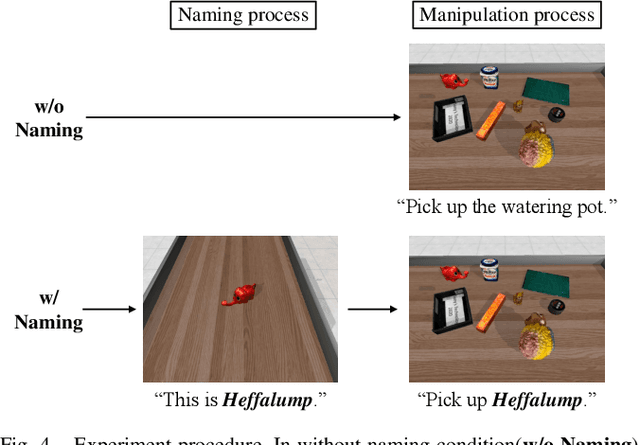
Robot manipulation tasks by natural language instructions need common understanding of the target object between human and the robot. However, the instructions often have an interpretation ambiguity, because the instruction lacks important information, or does not express the target object correctly to complete the task. To solve this ambiguity problem, we hypothesize that "naming" the target objects in advance will reduce the ambiguity of natural language instructions. We propose a robot system and method that incorporates naming with appearance of the objects in advance, so that in the later manipulation task, instruction can be performed with its unique name to disambiguate the objects easily. To demonstrate the effectiveness of our approach, we build a system that can memorize the target objects, and show that naming the objects facilitates detection of the target objects and improves the success rate of manipulation instructions. With this method, the success rate of object manipulation task increases by 31% in ambiguous instructions.
The DKU Post-Challenge Audio-Visual Wake Word Spotting System for the 2021 MISP Challenge: Deep Analysis
Mar 04, 2023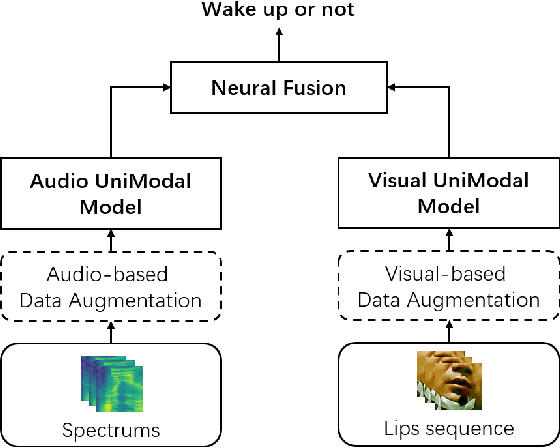
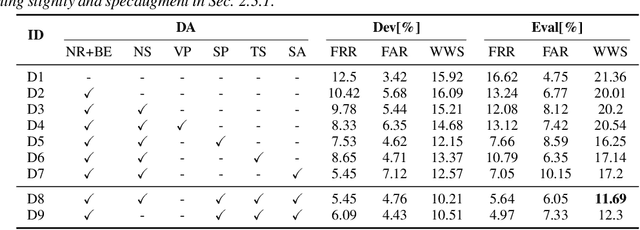
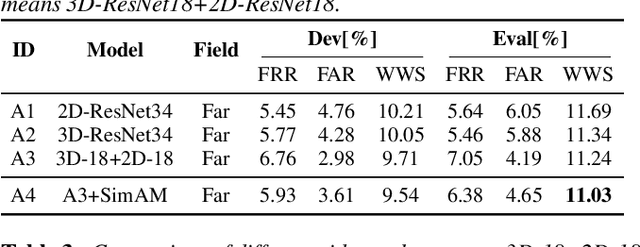
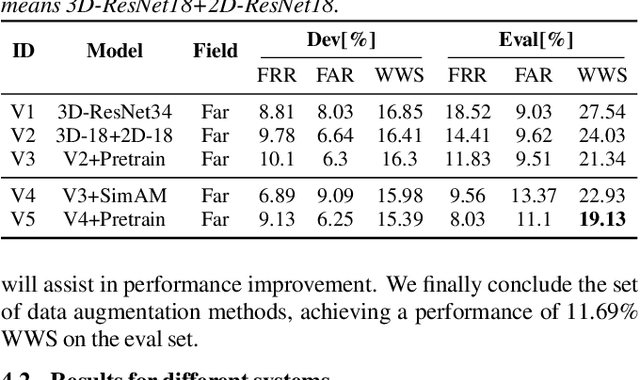
This paper further explores our previous wake word spotting system ranked 2-nd in Track 1 of the MISP Challenge 2021. First, we investigate a robust unimodal approach based on 3D and 2D convolution and adopt the simple attention module (SimAM) for our system to improve performance. Second, we explore different combinations of data augmentation methods for better performance. Finally, we study the fusion strategies, including score-level, cascaded and neural fusion. Our proposed multimodal system leverages multimodal features and uses the complementary visual information to mitigate the performance degradation of audio-only systems in complex acoustic scenarios. Our system obtains a false reject rate of 2.15% and a false alarm rate of 3.44% in the evaluation set of the competition database, which achieves the new state-of-the-art performance by 21% relative improvement compared to previous systems.
Cross-Layer Retrospective Retrieving via Layer Attention
Feb 20, 2023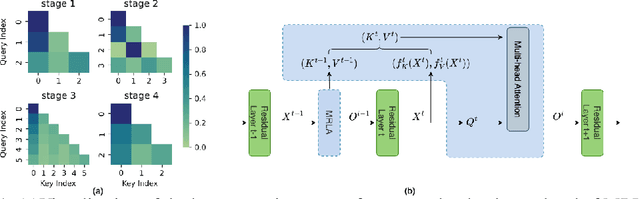
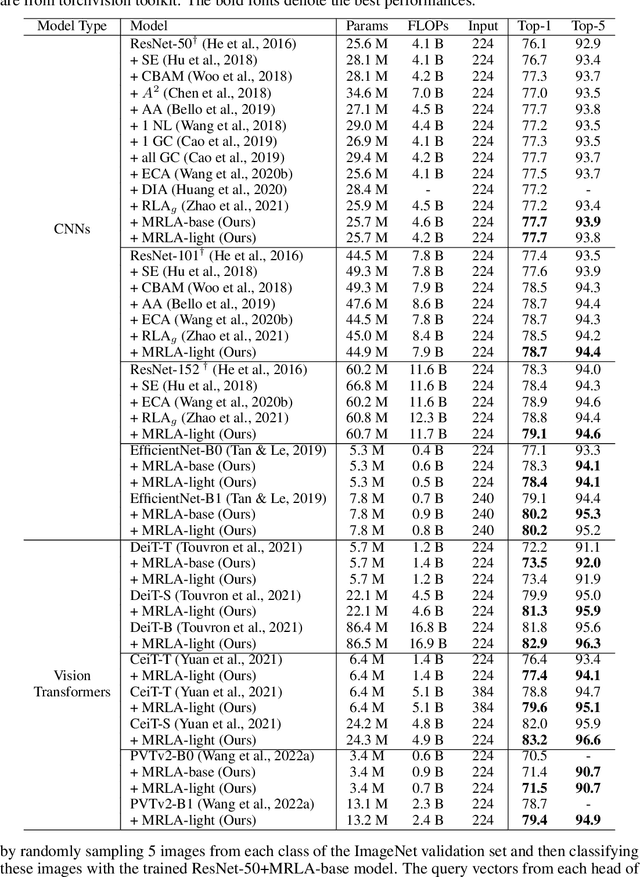
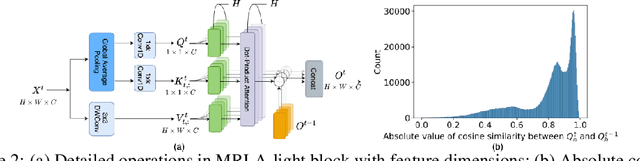
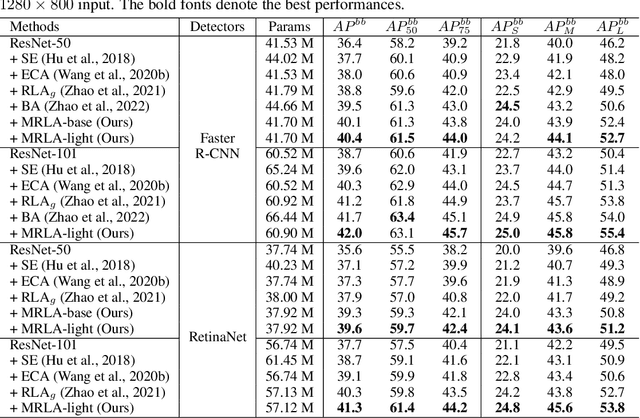
More and more evidence has shown that strengthening layer interactions can enhance the representation power of a deep neural network, while self-attention excels at learning interdependencies by retrieving query-activated information. Motivated by this, we devise a cross-layer attention mechanism, called multi-head recurrent layer attention (MRLA), that sends a query representation of the current layer to all previous layers to retrieve query-related information from different levels of receptive fields. A light-weighted version of MRLA is also proposed to reduce the quadratic computation cost. The proposed layer attention mechanism can enrich the representation power of many state-of-the-art vision networks, including CNNs and vision transformers. Its effectiveness has been extensively evaluated in image classification, object detection and instance segmentation tasks, where improvements can be consistently observed. For example, our MRLA can improve 1.6% Top-1 accuracy on ResNet-50, while only introducing 0.16M parameters and 0.07B FLOPs. Surprisingly, it can boost the performances by a large margin of 3-4% box AP and mask AP in dense prediction tasks. Our code is available at https://github.com/joyfang1106/MRLA.