 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-Supervised Video Desmoking for Laparoscopic Surgery
Mar 17, 2024

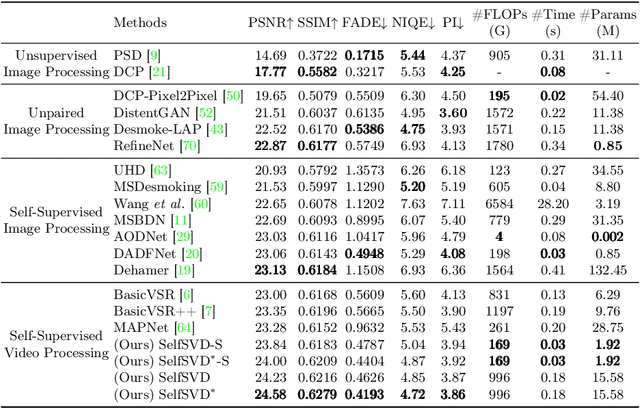
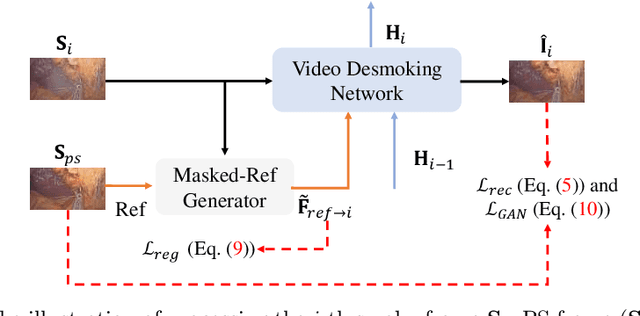
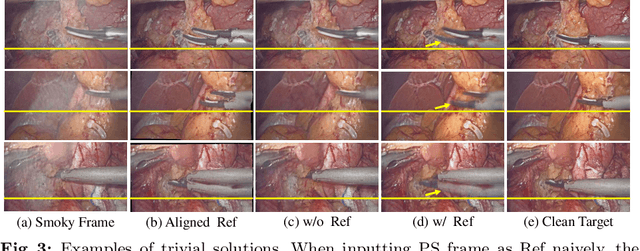
Due to the difficulty of collecting real paired data, most existing desmoking methods train the models by synthesizing smoke, generalizing poorly to real surgical scenarios. Although a few works have explored single-image real-world desmoking in unpaired learning manners, they still encounter challenges in handling dense smoke. In this work, we address these issues together by introducing the self-supervised surgery video desmoking (SelfSVD). On the one hand, we observe that the frame captured before the activation of high-energy devices is generally clear (named pre-smoke frame, PS frame), thus it can serve as supervision for other smoky frames, making real-world self-supervised video desmoking practically feasible. On the other hand, in order to enhance the desmoking performance, we further feed the valuable information from PS frame into models, where a masking strategy and a regularization term are presented to avoid trivial solutions. In addition, we construct a real surgery video dataset for desmoking, which covers a variety of smoky scenes. Extensive experiments on the dataset show that our SelfSVD can remove smoke more effectively and efficiently while recovering more photo-realistic details than the state-of-the-art methods. The dataset, codes, and pre-trained models are available at \url{https://github.com/ZcsrenlongZ/SelfSVD}.
IGANN Sparse: Bridging Sparsity and Interpretability with Non-linear Insight
Mar 17, 2024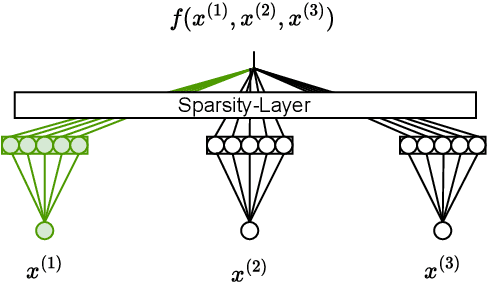
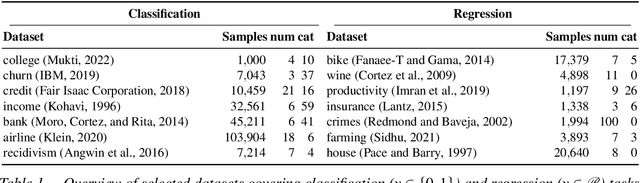
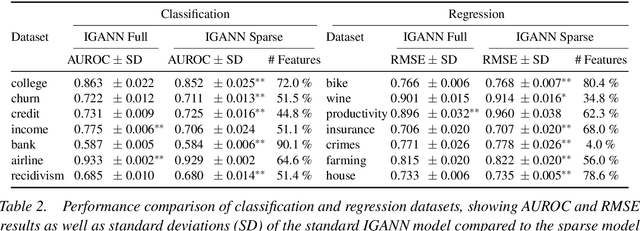
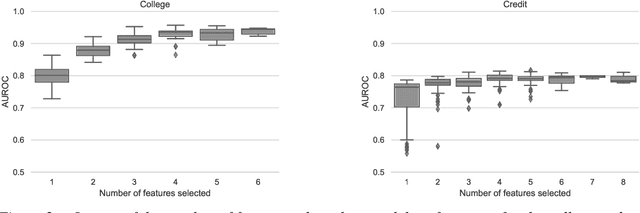
Feature selection is a critical component in predictive analytics that significantly affects the prediction accuracy and interpretability of models. Intrinsic methods for feature selection are built directly into model learning, providing a fast and attractive option for large amounts of data. Machine learning algorithms, such as penalized regression models (e.g., lasso) are the most common choice when it comes to in-built feature selection. However, they fail to capture non-linear relationships, which ultimately affects their ability to predict outcomes in intricate datasets. In this paper, we propose IGANN Sparse, a novel machine learning model from the family of generalized additive models, which promotes sparsity through a non-linear feature selection process during training. This ensures interpretability through improved model sparsity without sacrificing predictive performance. Moreover, IGANN Sparse serves as an exploratory tool for information systems researchers to unveil important non-linear relationships in domains that are characterized by complex patterns. Our ongoing research is directed at a thorough evaluation of the IGANN Sparse model, including user studies that allow to assess how well users of the model can benefit from the reduced number of features. This will allow for a deeper understanding of the interactions between linear vs. non-linear modeling, number of selected features, and predictive performance.
HarmPot: An Annotation Framework for Evaluating Offline Harm Potential of Social Media Text
Mar 17, 2024
In this paper, we discuss the development of an annotation schema to build datasets for evaluating the offline harm potential of social media texts. We define "harm potential" as the potential for an online public post to cause real-world physical harm (i.e., violence). Understanding that real-world violence is often spurred by a web of triggers, often combining several online tactics and pre-existing intersectional fissures in the social milieu, to result in targeted physical violence, we do not focus on any single divisive aspect (i.e., caste, gender, religion, or other identities of the victim and perpetrators) nor do we focus on just hate speech or mis/dis-information. Rather, our understanding of the intersectional causes of such triggers focuses our attempt at measuring the harm potential of online content, irrespective of whether it is hateful or not. In this paper, we discuss the development of a framework/annotation schema that allows annotating the data with different aspects of the text including its socio-political grounding and intent of the speaker (as expressed through mood and modality) that together contribute to it being a trigger for offline harm. We also give a comparative analysis and mapping of our framework with some of the existing frameworks.
SQ-LLaVA: Self-Questioning for Large Vision-Language Assistant
Mar 17, 2024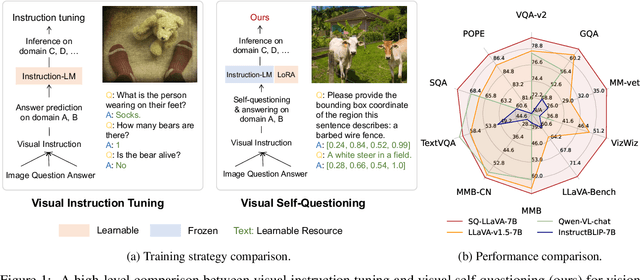
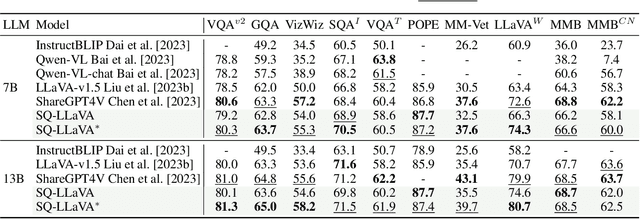
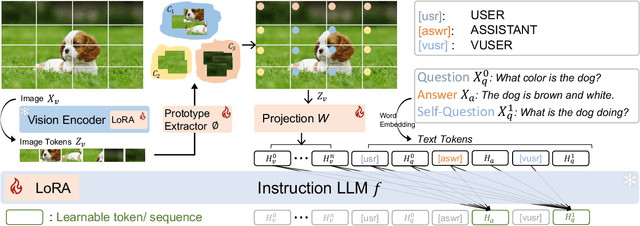
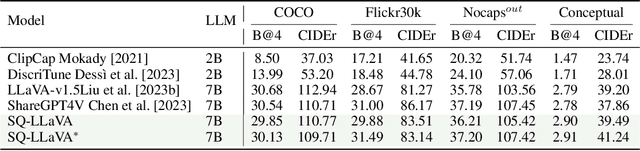
Recent advancements in the vision-language model have shown notable generalization in vision-language tasks after visual instruction tuning. However, bridging the gap between the pre-trained vision encoder and the large language models becomes the whole network's bottleneck. To improve cross-modality alignment, existing works usually consider more visual instruction data covering a broader range of vision tasks to fine-tune the model for question-answering, which are costly to obtain. However, the image contains rich contextual information that has been largely under-explored. This paper first attempts to harness this overlooked context within visual instruction data, training the model to self-supervised `learning' how to ask high-quality questions. In this way, we introduce a novel framework named SQ-LLaVA: Self-Questioning for Large Vision-Language Assistant. SQ-LLaVA exhibits proficiency in generating flexible and meaningful image-related questions while analyzing the visual clue and prior language knowledge, signifying an advanced level of generalized visual understanding. Moreover, fine-tuning SQ-LLaVA on higher-quality instruction data shows a consistent performance improvement compared with traditional visual-instruction tuning methods. This improvement highlights the efficacy of self-questioning techniques in achieving a deeper and more nuanced comprehension of visual content across various contexts.
Learning Time Slot Preferences via Mobility Tree for Next POI Recommendation
Mar 17, 2024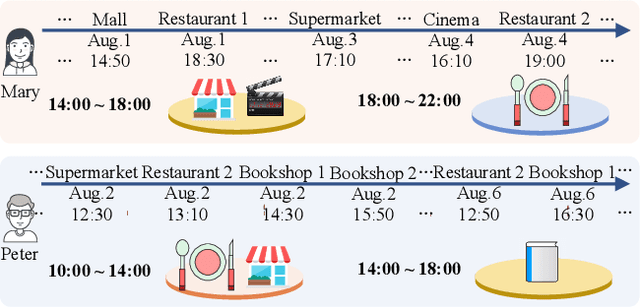
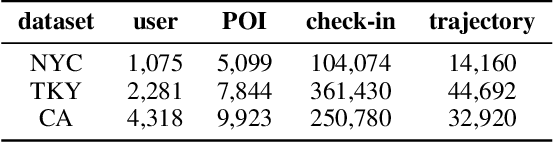
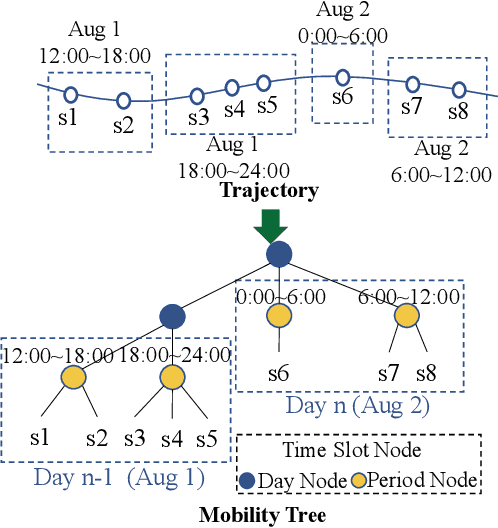
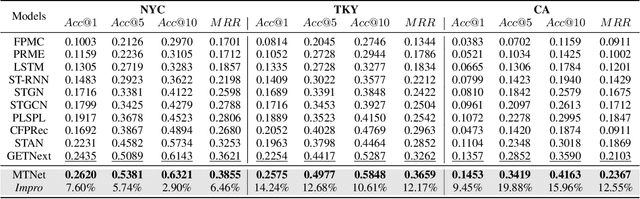
Next Point-of-Interests (POIs) recommendation task aims to provide a dynamic ranking of POIs based on users' current check-in trajectories. The recommendation performance of this task is contingent upon a comprehensive understanding of users' personalized behavioral patterns through Location-based Social Networks (LBSNs) data. While prior studies have adeptly captured sequential patterns and transitional relationships within users' check-in trajectories, a noticeable gap persists in devising a mechanism for discerning specialized behavioral patterns during distinct time slots, such as noon, afternoon, or evening. In this paper, we introduce an innovative data structure termed the ``Mobility Tree'', tailored for hierarchically describing users' check-in records. The Mobility Tree encompasses multi-granularity time slot nodes to learn user preferences across varying temporal periods. Meanwhile, we propose the Mobility Tree Network (MTNet), a multitask framework for personalized preference learning based on Mobility Trees. We develop a four-step node interaction operation to propagate feature information from the leaf nodes to the root node. Additionally, we adopt a multitask training strategy to push the model towards learning a robust representation. The comprehensive experimental results demonstrate the superiority of MTNet over ten state-of-the-art next POI recommendation models across three real-world LBSN datasets, substantiating the efficacy of time slot preference learning facilitated by Mobility Tree.
Vision-based Vehicle Re-identification in Bridge Scenario using Flock Similarity
Mar 12, 2024


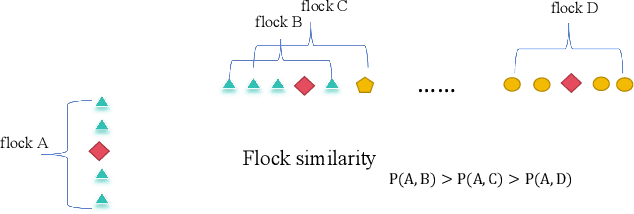
Due to the needs of road traffic flow monitoring and public safety management, video surveillance cameras are widely distributed in urban roads. However, the information captured directly by each camera is siloed, making it difficult to use it effectively. Vehicle re-identification refers to finding a vehicle that appears under one camera in another camera, which can correlate the information captured by multiple cameras. While license plate recognition plays an important role in some applications, there are some scenarios where re-identification method based on vehicle appearance are more suitable. The main challenge is that the data of vehicle appearance has the characteristics of high inter-class similarity and large intra-class differences. Therefore, it is difficult to accurately distinguish between different vehicles by relying only on vehicle appearance information. At this time, it is often necessary to introduce some extra information, such as spatio-temporal information. Nevertheless, the relative position of the vehicles rarely changes when passing through two adjacent cameras in the bridge scenario. In this paper, we present a vehicle re-identification method based on flock similarity, which improves the accuracy of vehicle re-identification by utilizing vehicle information adjacent to the target vehicle. When the relative position of the vehicles remains unchanged and flock size is appropriate, we obtain an average relative improvement of 204% on VeRi dataset in our experiments. Then, the effect of the magnitude of the relative position change of the vehicles as they pass through two cameras is discussed. We present two metrics that can be used to quantify the difference and establish a connection between them. Although this assumption is based on the bridge scenario, it is often true in other scenarios due to driving safety and camera location.
Exploring Challenges in Deep Learning of Single-Station Ground Motion Records
Mar 12, 2024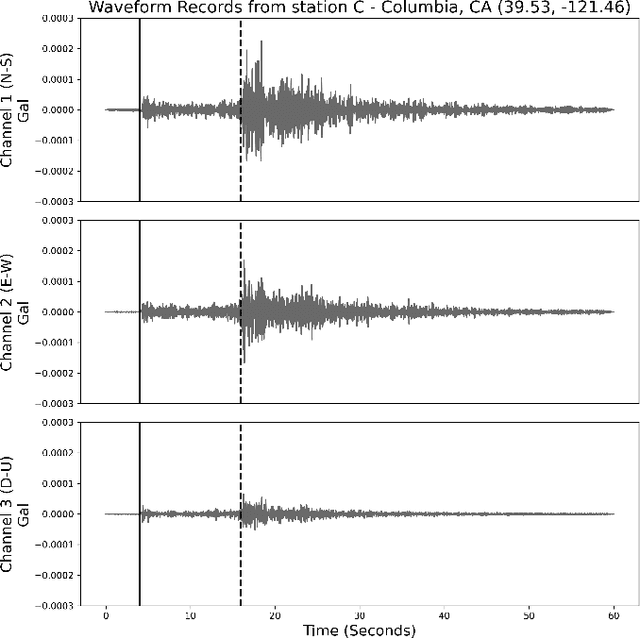
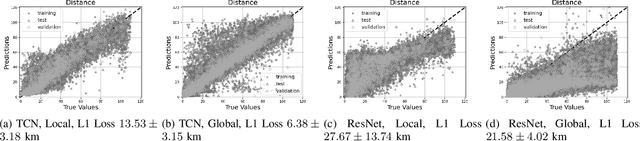
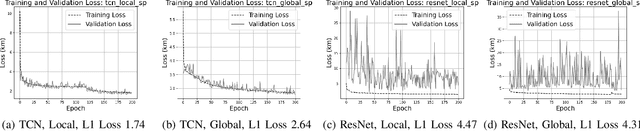
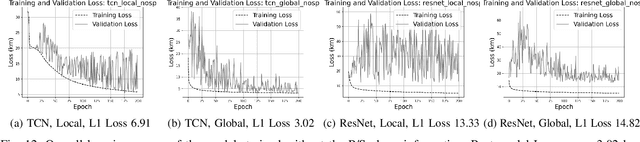
Contemporary deep learning models have demonstrated promising results across various applications within seismology and earthquake engineering. These models rely primarily on utilizing ground motion records for tasks such as earthquake event classification, localization, earthquake early warning systems, and structural health monitoring. However, the extent to which these models effectively learn from these complex time-series signals has not been thoroughly analyzed. In this study, our objective is to evaluate the degree to which auxiliary information, such as seismic phase arrival times or seismic station distribution within a network, dominates the process of deep learning from ground motion records, potentially hindering its effectiveness. We perform a hyperparameter search on two deep learning models to assess their effectiveness in deep learning from ground motion records while also examining the impact of auxiliary information on model performance. Experimental results reveal a strong reliance on the highly correlated P and S phase arrival information. Our observations highlight a potential gap in the field, indicating an absence of robust methodologies for deep learning of single-station ground motion recordings independent of any auxiliary information.
Kernel Alignment for Unsupervised Feature Selection via Matrix Factorization
Mar 13, 2024By removing irrelevant and redundant features, feature selection aims to find a good representation of the original features. With the prevalence of unlabeled data, unsupervised feature selection has been proven effective in alleviating the so-called curse of dimensionality. Most existing matrix factorization-based unsupervised feature selection methods are built upon subspace learning, but they have limitations in capturing nonlinear structural information among features. It is well-known that kernel techniques can capture nonlinear structural information. In this paper, we construct a model by integrating kernel functions and kernel alignment, which can be equivalently characterized as a matrix factorization problem. However, such an extension raises another issue: the algorithm performance heavily depends on the choice of kernel, which is often unknown a priori. Therefore, we further propose a multiple kernel-based learning method. By doing so, our model can learn both linear and nonlinear similarity information and automatically generate the most appropriate kernel. Experimental analysis on real-world data demonstrates that the two proposed methods outperform other classic and state-of-the-art unsupervised feature selection methods in terms of clustering results and redundancy reduction in almost all datasets tested.
Is Context Helpful for Chat Translation Evaluation?
Mar 13, 2024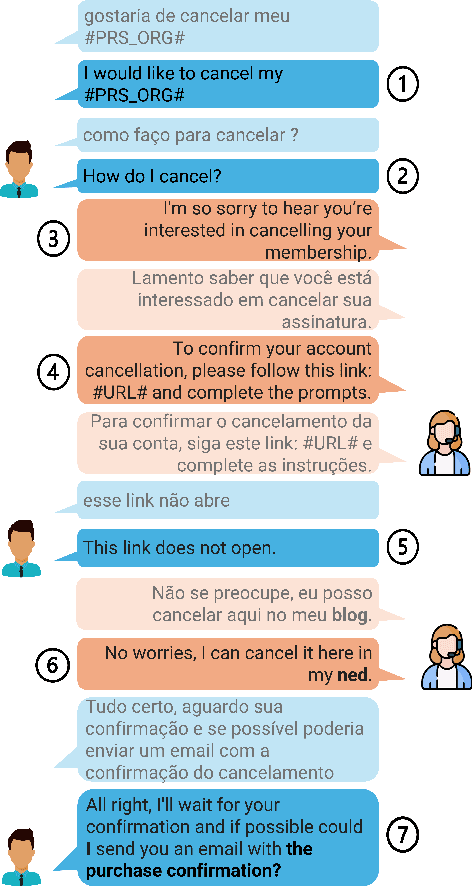
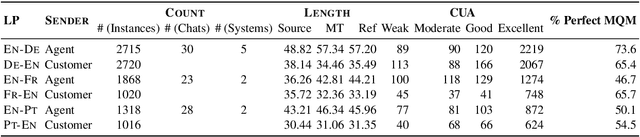
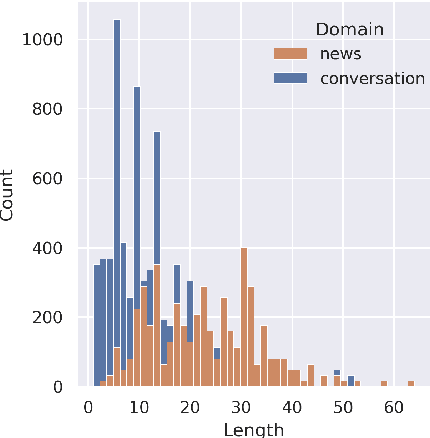
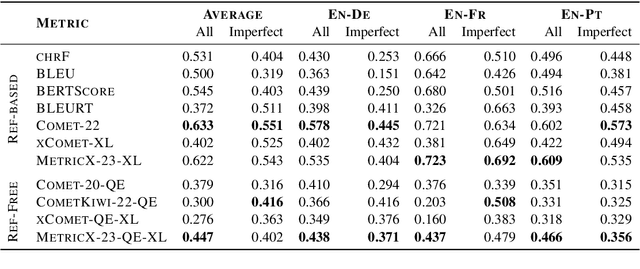
Despite the recent success of automatic metrics for assessing translation quality, their application in evaluating the quality of machine-translated chats has been limited. Unlike more structured texts like news, chat conversations are often unstructured, short, and heavily reliant on contextual information. This poses questions about the reliability of existing sentence-level metrics in this domain as well as the role of context in assessing the translation quality. Motivated by this, we conduct a meta-evaluation of existing sentence-level automatic metrics, primarily designed for structured domains such as news, to assess the quality of machine-translated chats. We find that reference-free metrics lag behind reference-based ones, especially when evaluating translation quality in out-of-English settings. We then investigate how incorporating conversational contextual information in these metrics affects their performance. Our findings show that augmenting neural learned metrics with contextual information helps improve correlation with human judgments in the reference-free scenario and when evaluating translations in out-of-English settings. Finally, we propose a new evaluation metric, Context-MQM, that utilizes bilingual context with a large language model (LLM) and further validate that adding context helps even for LLM-based evaluation metrics.
Natural Language Processing Methods for Symbolic Music Generation and Information Retrieval: a Survey
Feb 27, 2024Several adaptations of Transformers models have been developed in various domains since its breakthrough in Natural Language Processing (NLP). This trend has spread into the field of Music Information Retrieval (MIR), including studies processing music data. However, the practice of leveraging NLP tools for symbolic music data is not novel in MIR. Music has been frequently compared to language, as they share several similarities, including sequential representations of text and music. These analogies are also reflected through similar tasks in MIR and NLP. This survey reviews NLP methods applied to symbolic music generation and information retrieval studies following two axes. We first propose an overview of representations of symbolic music adapted from natural language sequential representations. Such representations are designed by considering the specificities of symbolic music. These representations are then processed by models. Such models, possibly originally developed for text and adapted for symbolic music, are trained on various tasks. We describe these models, in particular deep learning models, through different prisms, highlighting music-specialized mechanisms. We finally present a discussion surrounding the effective use of NLP tools for symbolic music data. This includes technical issues regarding NLP methods and fundamental differences between text and music, which may open several doors for further research into more effectively adapting NLP tools to symbolic MIR.