 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Transformer Encoder with Multiscale Deep Learning for Pain Classification Using Physiological Signals
Mar 13, 2023
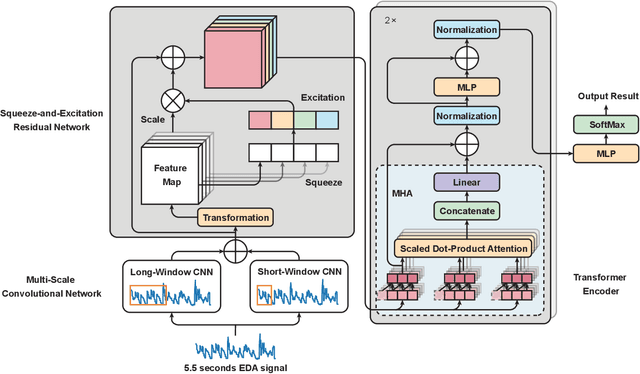

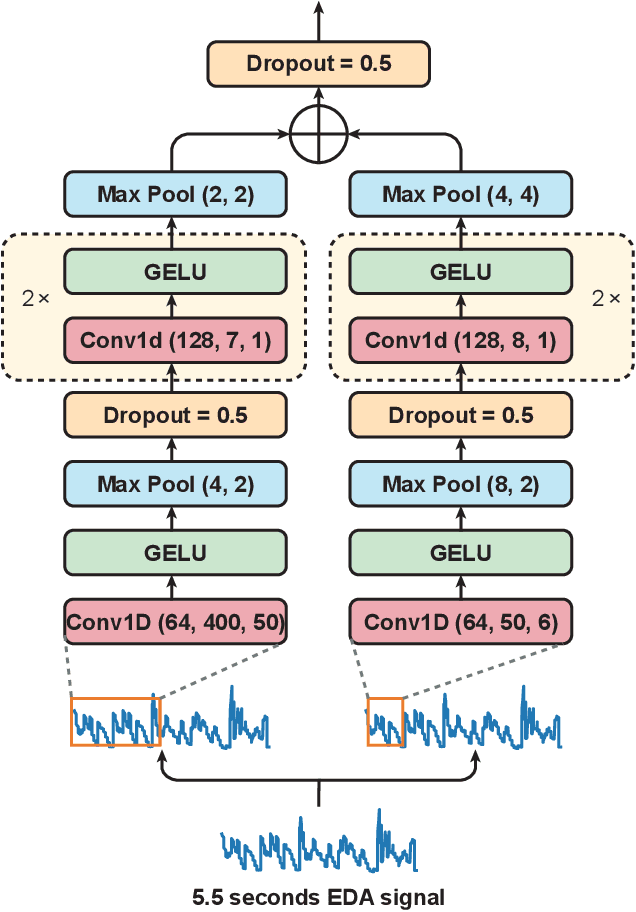
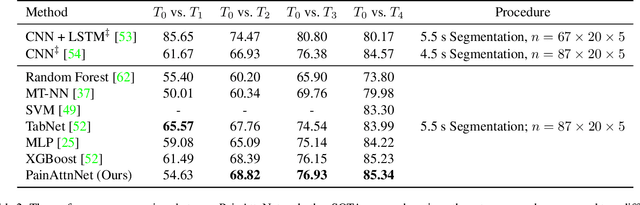
Pain is a serious worldwide health problem that affects a vast proportion of the population. For efficient pain management and treatment, accurate classification and evaluation of pain severity are necessary. However, this can be challenging as pain is a subjective sensation-driven experience. Traditional techniques for measuring pain intensity, e.g. self-report scales, are susceptible to bias and unreliable in some instances. Consequently, there is a need for more objective and automatic pain intensity assessment strategies. In this research, we develop PainAttnNet (PAN), a novel transfomer-encoder deep-learning framework for classifying pain intensities with physiological signals as input. The proposed approach is comprised of three feature extraction architectures: multiscale convolutional networks (MSCN), a squeeze-and-excitation residual network (SEResNet), and a transformer encoder block. On the basis of pain stimuli, MSCN extracts short- and long-window information as well as sequential features. SEResNet highlights relevant extracted features by mapping the interdependencies among features. The third architecture employs a transformer encoder consisting of three temporal convolutional networks (TCN) with three multi-head attention (MHA) layers to extract temporal dependencies from the features. Using the publicly available BioVid pain dataset, we test the proposed PainAttnNet model and demonstrate that our outcomes outperform state-of-the-art models. These results confirm that our approach can be utilized for automated classification of pain intensity using physiological signals to improve pain management and treatment.
DeepVigor: Vulnerability Value Ranges and Factors for DNNs' Reliability Assessment
Mar 13, 2023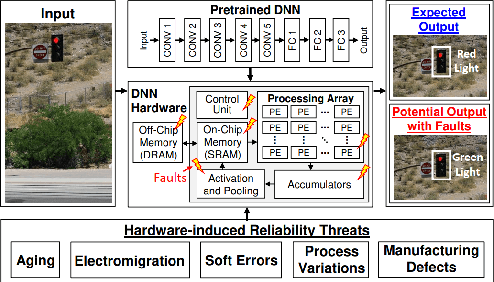
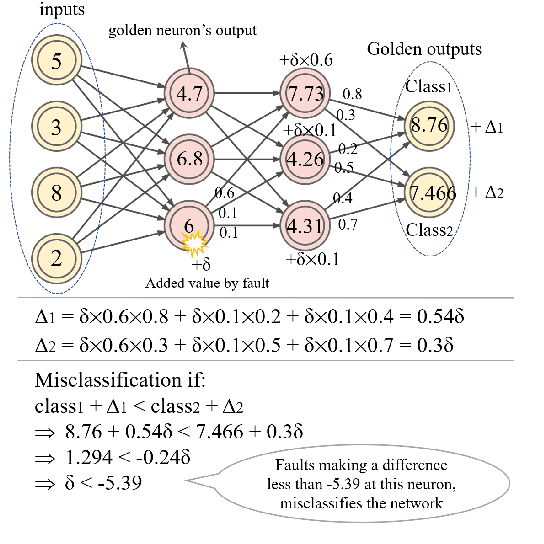
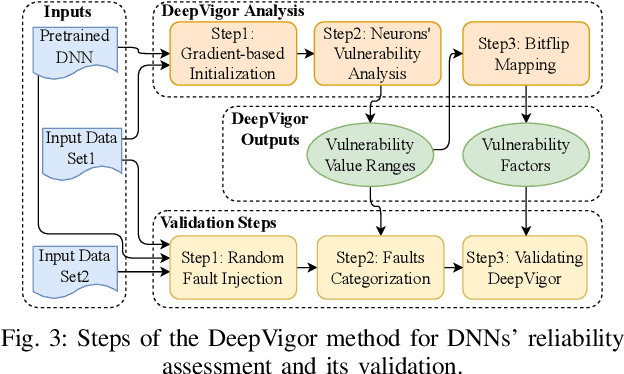
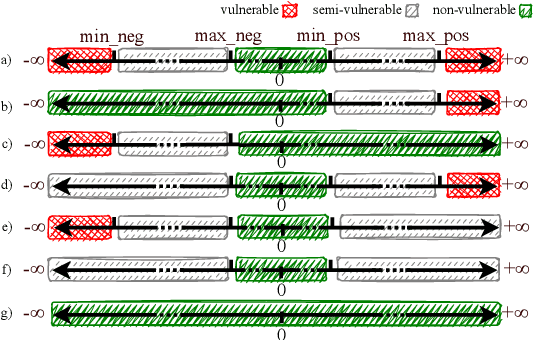
Deep Neural Networks (DNNs) and their accelerators are being deployed ever more frequently in safety-critical applications leading to increasing reliability concerns. A traditional and accurate method for assessing DNNs' reliability has been resorting to fault injection, which, however, suffers from prohibitive time complexity. While analytical and hybrid fault injection-/analytical-based methods have been proposed, they are either inaccurate or specific to particular accelerator architectures. In this work, we propose a novel accurate, fine-grain, metric-oriented, and accelerator-agnostic method called DeepVigor that provides vulnerability value ranges for DNN neurons' outputs. An outcome of DeepVigor is an analytical model representing vulnerable and non-vulnerable ranges for each neuron that can be exploited to develop different techniques for improving DNNs' reliability. Moreover, DeepVigor provides reliability assessment metrics based on vulnerability factors for bits, neurons, and layers using the vulnerability ranges. The proposed method is not only faster than fault injection but also provides extensive and accurate information about the reliability of DNNs, independent from the accelerator. The experimental evaluations in the paper indicate that the proposed vulnerability ranges are 99.9% to 100% accurate even when evaluated on previously unseen test data. Also, it is shown that the obtained vulnerability factors represent the criticality of bits, neurons, and layers proficiently. DeepVigor is implemented in the PyTorch framework and validated on complex DNN benchmarks.
Improving Table Structure Recognition with Visual-Alignment Sequential Coordinate Modeling
Mar 13, 2023
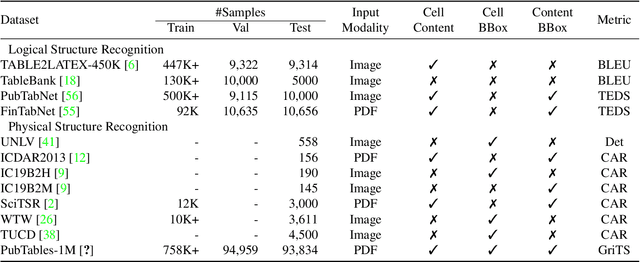
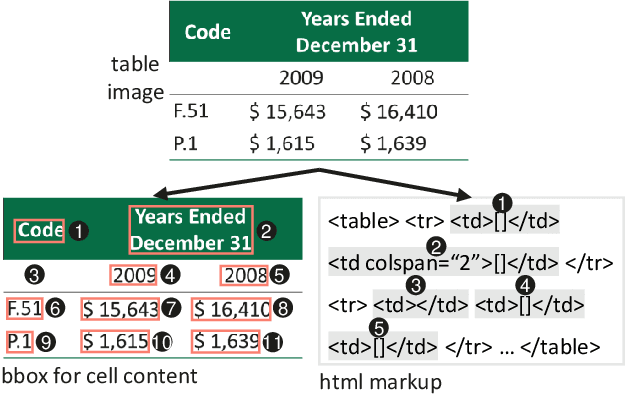
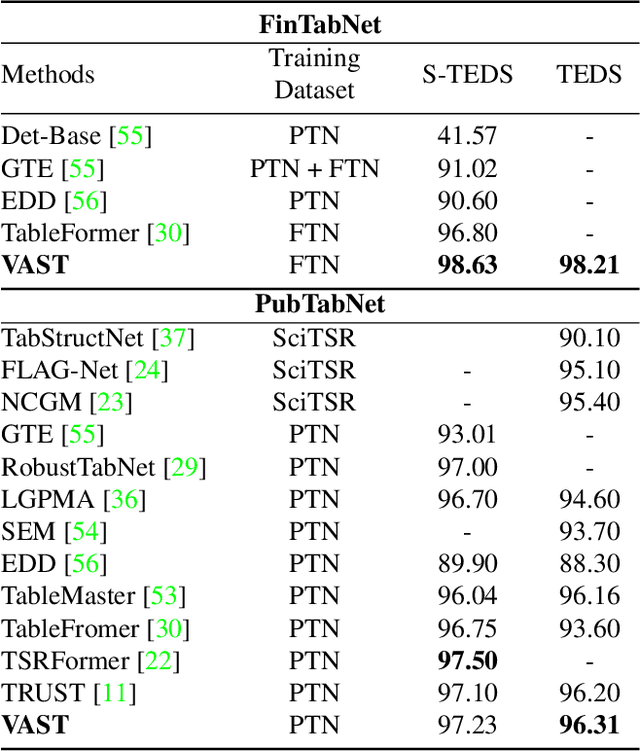
Table structure recognition aims to extract the logical and physical structure of unstructured table images into a machine-readable format. The latest end-to-end image-to-text approaches simultaneously predict the two structures by two decoders, where the prediction of the physical structure (the bounding boxes of the cells) is based on the representation of the logical structure. However, the previous methods struggle with imprecise bounding boxes as the logical representation lacks local visual information. To address this issue, we propose an end-to-end sequential modeling framework for table structure recognition called VAST. It contains a novel coordinate sequence decoder triggered by the representation of the non-empty cell from the logical structure decoder. In the coordinate sequence decoder, we model the bounding box coordinates as a language sequence, where the left, top, right and bottom coordinates are decoded sequentially to leverage the inter-coordinate dependency. Furthermore, we propose an auxiliary visual-alignment loss to enforce the logical representation of the non-empty cells to contain more local visual details, which helps produce better cell bounding boxes. Extensive experiments demonstrate that our proposed method can achieve state-of-the-art results in both logical and physical structure recognition. The ablation study also validates that the proposed coordinate sequence decoder and the visual-alignment loss are the keys to the success of our method.
Learning not to Regret
Mar 02, 2023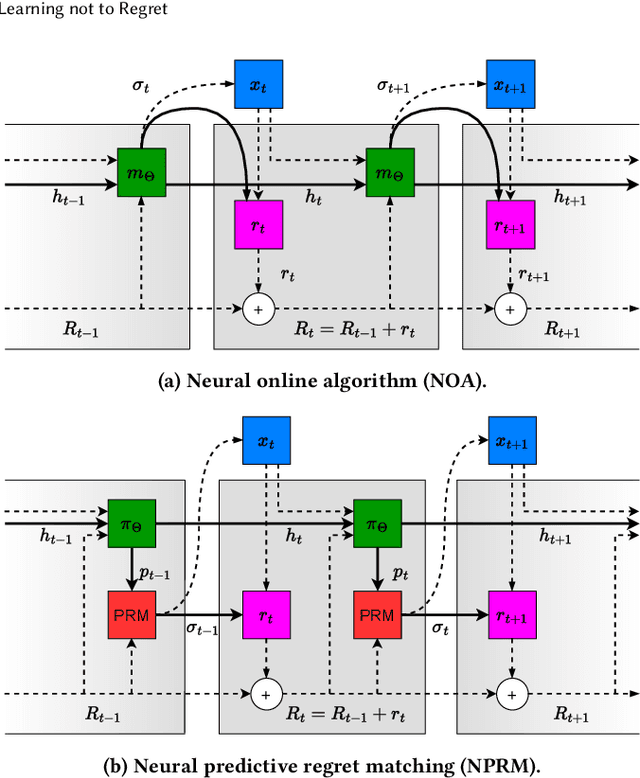
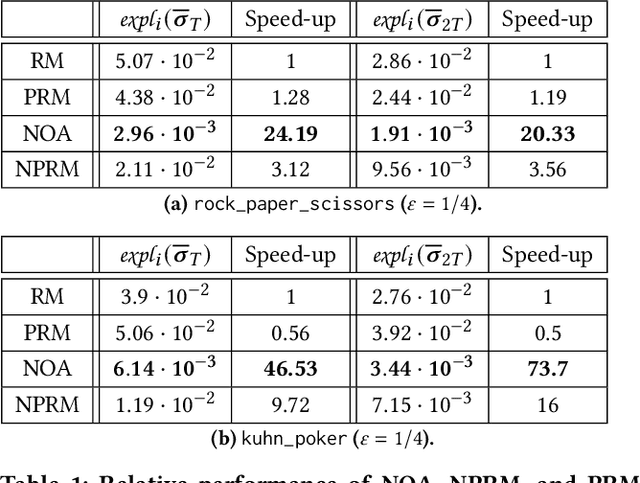
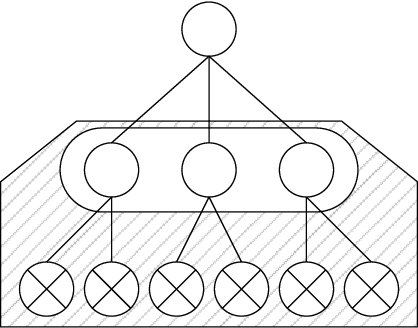
Regret minimization is a key component of many algorithms for finding Nash equilibria in imperfect-information games. To scale to games that cannot fit in memory, we can use search with value functions. However, calling the value functions repeatedly in search can be expensive. Therefore, it is desirable to minimize regret in the search tree as fast as possible. We propose to accelerate the regret minimization by introducing a general ``learning not to regret'' framework, where we meta-learn the regret minimizer. The resulting algorithm is guaranteed to minimize regret in arbitrary settings and is (meta)-learned to converge fast on a selected distribution of games. Our experiments show that meta-learned algorithms converge substantially faster than prior regret minimization algorithms.
A Human-Centered Safe Robot Reinforcement Learning Framework with Interactive Behaviors
Mar 02, 2023
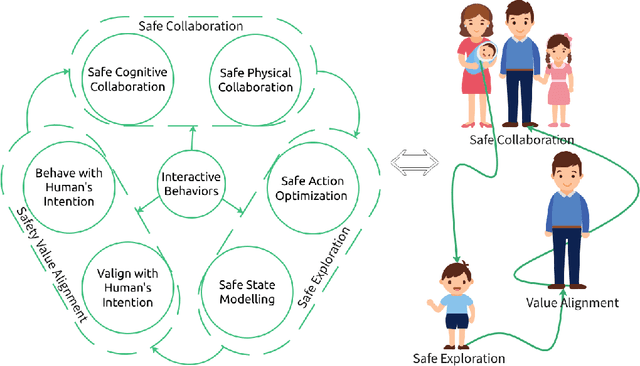
Deployment of reinforcement learning algorithms for robotics applications in the real world requires ensuring the safety of the robot and its environment. Safe robot reinforcement learning (SRRL) is a crucial step towards achieving human-robot coexistence. In this paper, we envision a human-centered SRRL framework consisting of three stages: safe exploration, safety value alignment, and safe collaboration. We examine the research gaps in these areas and propose to leverage interactive behaviors for SRRL. Interactive behaviors enable bi-directional information transfer between humans and robots, such as conversational robot ChatGPT. We argue that interactive behaviors need further attention from the SRRL community. We discuss four open challenges related to the robustness, efficiency, transparency, and adaptability of SRRL with interactive behaviors.
Cross-Layer Retrospective Retrieving via Layer Attention
Feb 20, 2023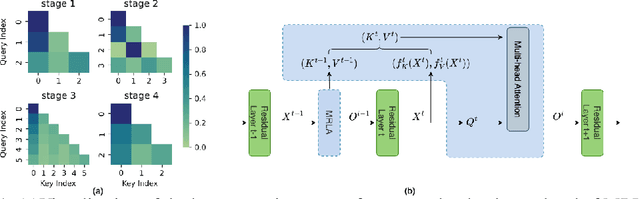
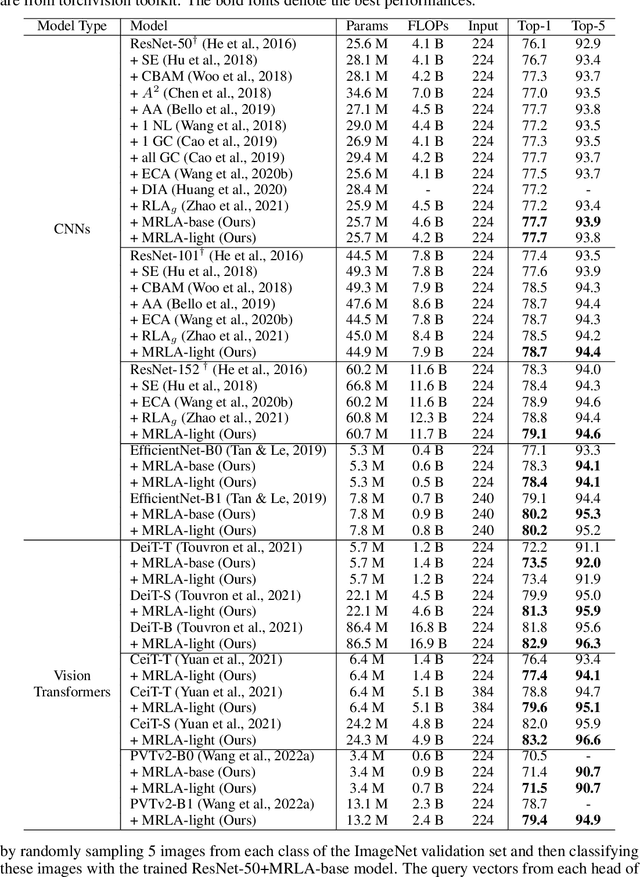
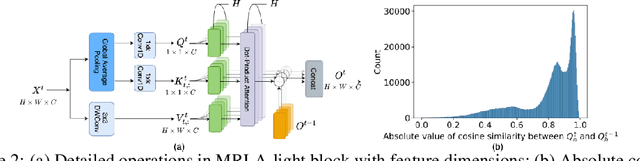
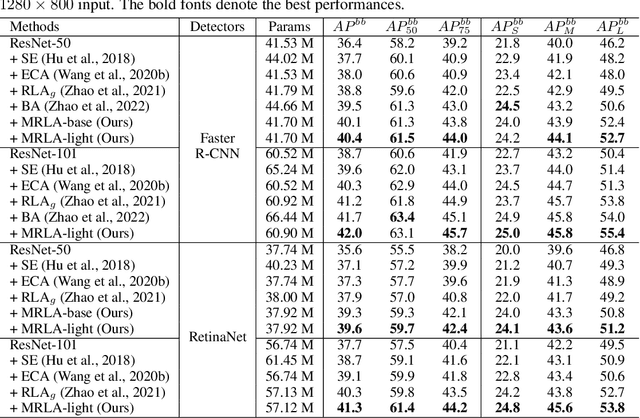
More and more evidence has shown that strengthening layer interactions can enhance the representation power of a deep neural network, while self-attention excels at learning interdependencies by retrieving query-activated information. Motivated by this, we devise a cross-layer attention mechanism, called multi-head recurrent layer attention (MRLA), that sends a query representation of the current layer to all previous layers to retrieve query-related information from different levels of receptive fields. A light-weighted version of MRLA is also proposed to reduce the quadratic computation cost. The proposed layer attention mechanism can enrich the representation power of many state-of-the-art vision networks, including CNNs and vision transformers. Its effectiveness has been extensively evaluated in image classification, object detection and instance segmentation tasks, where improvements can be consistently observed. For example, our MRLA can improve 1.6% Top-1 accuracy on ResNet-50, while only introducing 0.16M parameters and 0.07B FLOPs. Surprisingly, it can boost the performances by a large margin of 3-4% box AP and mask AP in dense prediction tasks. Our code is available at https://github.com/joyfang1106/MRLA.
PresSim: An End-to-end Framework for Dynamic Ground Pressure Profile Generation from Monocular Videos Using Physics-based 3D Simulation
Feb 01, 2023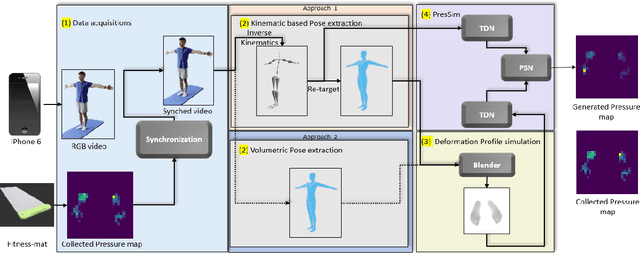
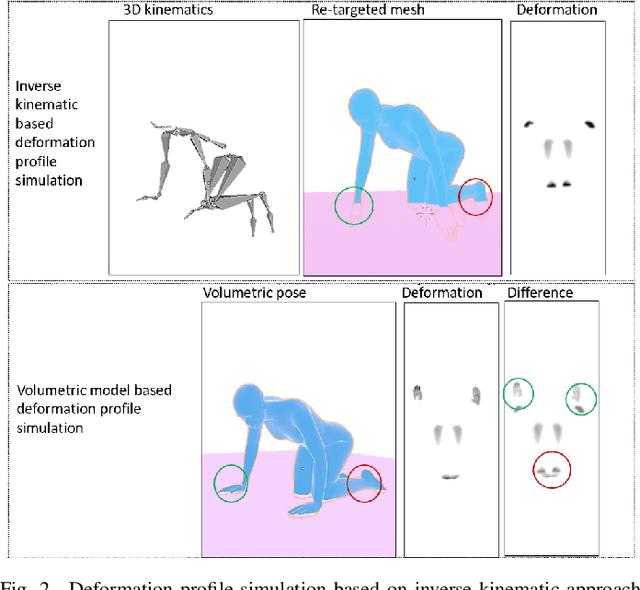
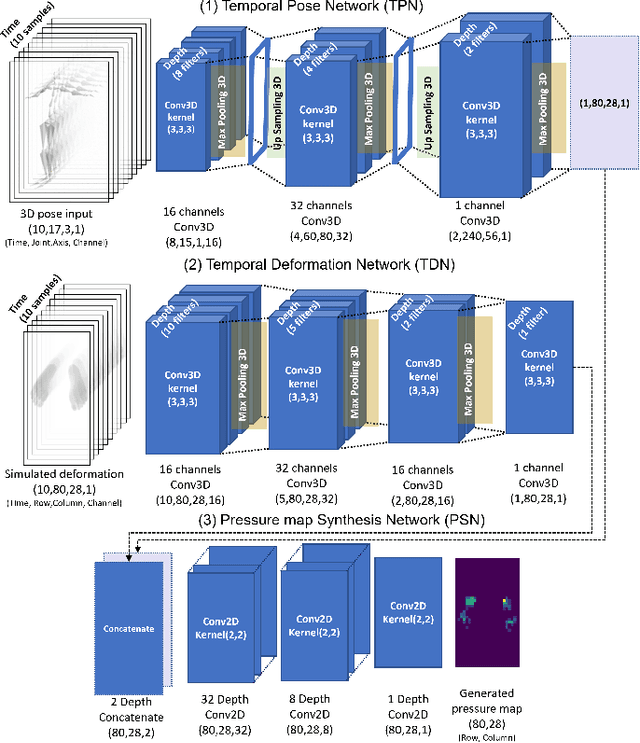
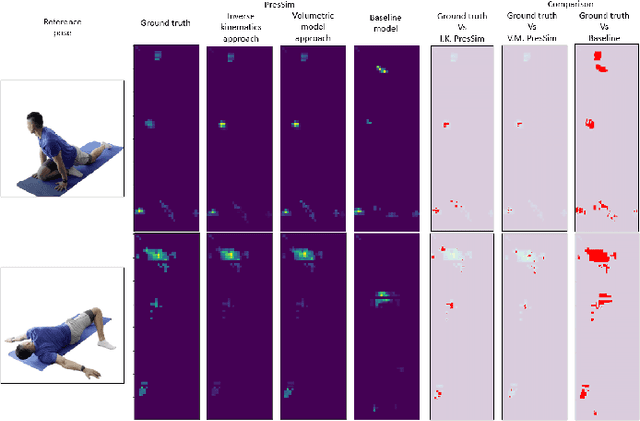
Ground pressure exerted by the human body is a valuable source of information for human activity recognition (HAR) in unobtrusive pervasive sensing. While data collection from pressure sensors to develop HAR solutions requires significant resources and effort, we present a novel end-to-end framework, PresSim, to synthesize sensor data from videos of human activities to reduce such effort significantly. PresSim adopts a 3-stage process: first, extract the 3D activity information from videos with computer vision architectures; then simulate the floor mesh deformation profiles based on the 3D activity information and gravity-included physics simulation; lastly, generate the simulated pressure sensor data with deep learning models. We explored two approaches for the 3D activity information: inverse kinematics with mesh re-targeting, and volumetric pose and shape estimation. We validated PresSim with an experimental setup with a monocular camera to provide input and a pressure-sensing fitness mat (80x28 spatial resolution) to provide the sensor ground truth, where nine participants performed a set of predefined yoga sequences.
DMODE: Differential Monocular Object Distance Estimation Module without Class Specific Information
Oct 23, 2022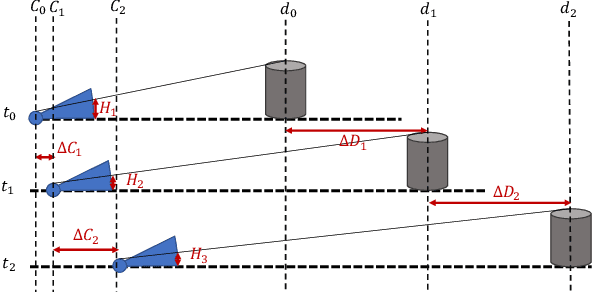
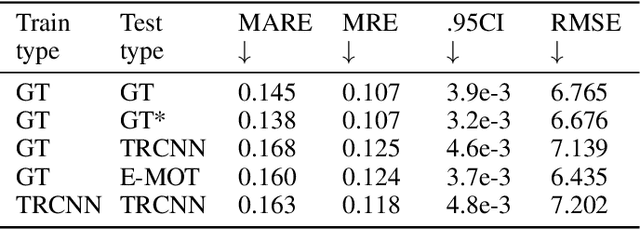
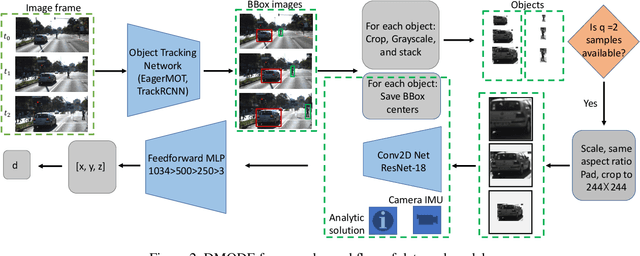
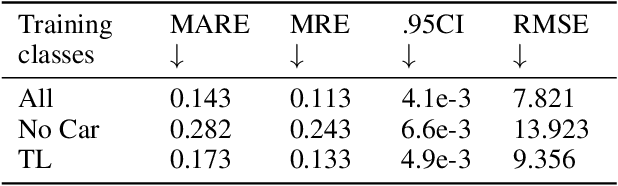
Using a single camera to estimate the distances of objects reduces costs compared to stereo-vision and LiDAR. Although monocular distance estimation has been studied in the literature, previous methods mostly rely on knowing an object's class in some way. This can result in deteriorated performance for dataset with multi-class objects and objects with an undefined class. In this paper, we aim to overcome the potential downsides of class-specific approaches, and provide an alternative technique called DMODE that does not require any information relating to its class. Using differential approaches, we combine the changes in an object's size over time together with the camera's motion to estimate the object's distance. Since DMODE is class agnostic method, it is easily adaptable to new environments. Therefore, it is able to maintain performance across different object detectors, and be easily adapted to new object classes. We tested our model across different scenarios of training and testing on the KITTI MOTS dataset's ground-truth bounding box annotations, and bounding box outputs of TrackRCNN and EagerMOT. The instantaneous change of bounding box sizes and camera position are then used to obtain an object's position in 3D without measuring its detection source or class properties. Our results show that we are able to outperform traditional alternatives methods e.g. IPM \cite{TuohyIPM}, SVR \cite{svr}, and \cite{zhu2019learning} in test environments with multi-class object distance detections.
Point Cloud Classification Using Content-based Transformer via Clustering in Feature Space
Mar 08, 2023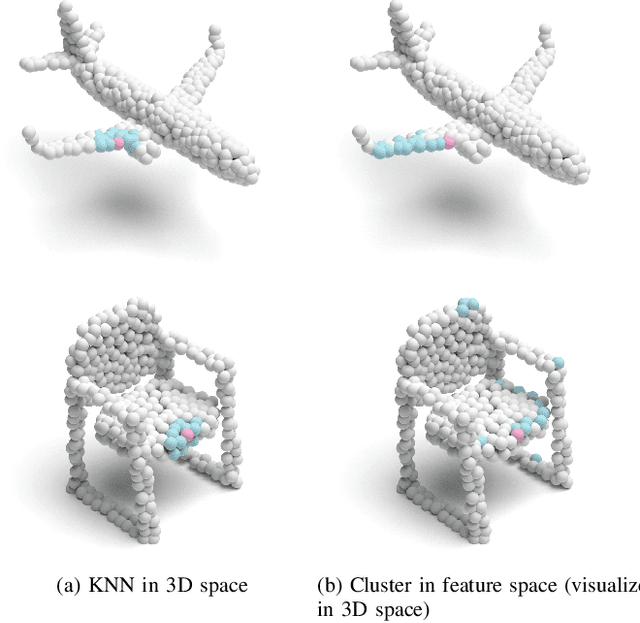
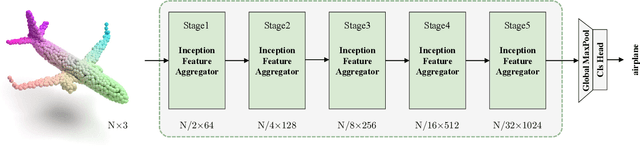
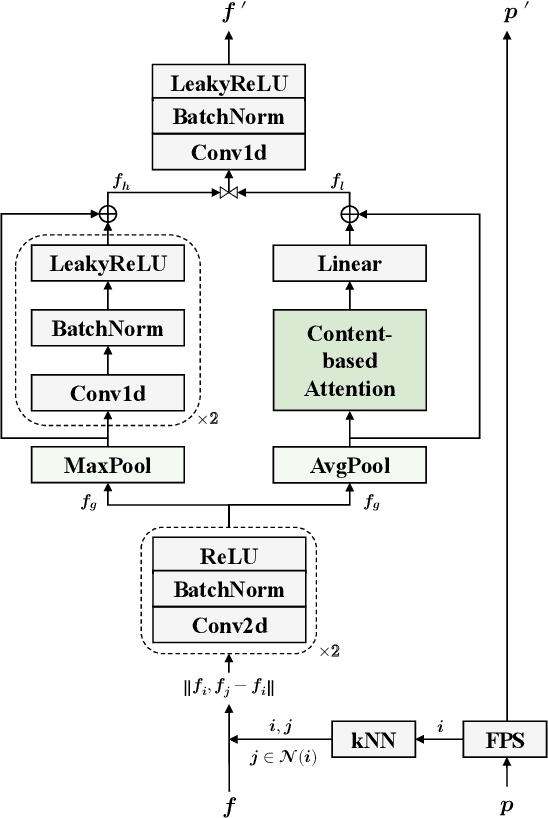
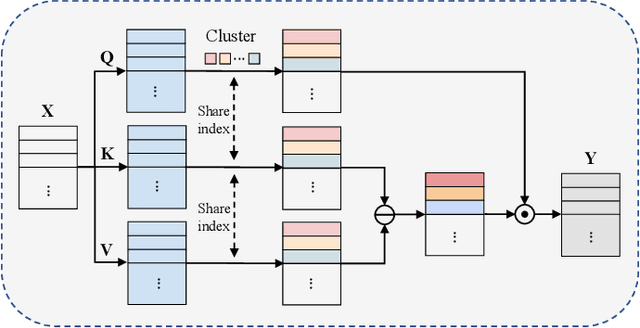
Recently, there have been some attempts of Transformer in 3D point cloud classification. In order to reduce computations, most existing methods focus on local spatial attention, but ignore their content and fail to establish relationships between distant but relevant points. To overcome the limitation of local spatial attention, we propose a point content-based Transformer architecture, called PointConT for short. It exploits the locality of points in the feature space (content-based), which clusters the sampled points with similar features into the same class and computes the self-attention within each class, thus enabling an effective trade-off between capturing long-range dependencies and computational complexity. We further introduce an Inception feature aggregator for point cloud classification, which uses parallel structures to aggregate high-frequency and low-frequency information in each branch separately. Extensive experiments show that our PointConT model achieves a remarkable performance on point cloud shape classification. Especially, our method exhibits 90.3% Top-1 accuracy on the hardest setting of ScanObjectNN. Source code of this paper is available at https://github.com/yahuiliu99/PointConT.
Comprehensive Event Representations using Event Knowledge Graphs and Natural Language Processing
Mar 08, 2023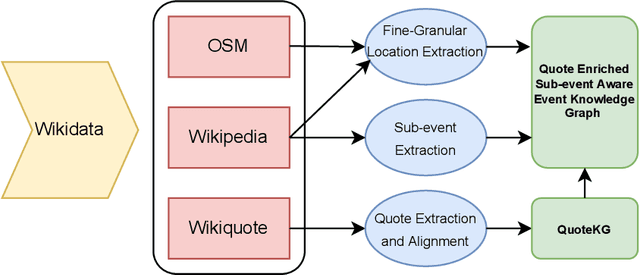
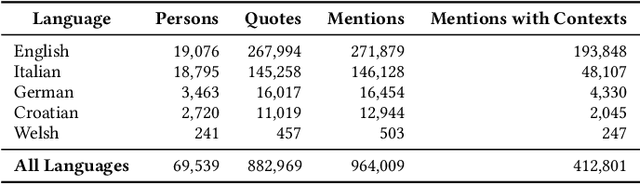

Recent work has utilised knowledge-aware approaches to natural language understanding, question answering, recommendation systems, and other tasks. These approaches rely on well-constructed and large-scale knowledge graphs that can be useful for many downstream applications and empower knowledge-aware models with commonsense reasoning. Such knowledge graphs are constructed through knowledge acquisition tasks such as relation extraction and knowledge graph completion. This work seeks to utilise and build on the growing body of work that uses findings from the field of natural language processing (NLP) to extract knowledge from text and build knowledge graphs. The focus of this research project is on how we can use transformer-based approaches to extract and contextualise event information, matching it to existing ontologies, to build a comprehensive knowledge of graph-based event representations. Specifically, sub-event extraction is used as a way of creating sub-event-aware event representations. These event representations are then further enriched through fine-grained location extraction and contextualised through the alignment of historically relevant quotes.