 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CoLo-CAM: Class Activation Mapping for Object Co-Localization in Weakly-Labeled Unconstrained Videos
Mar 16, 2023
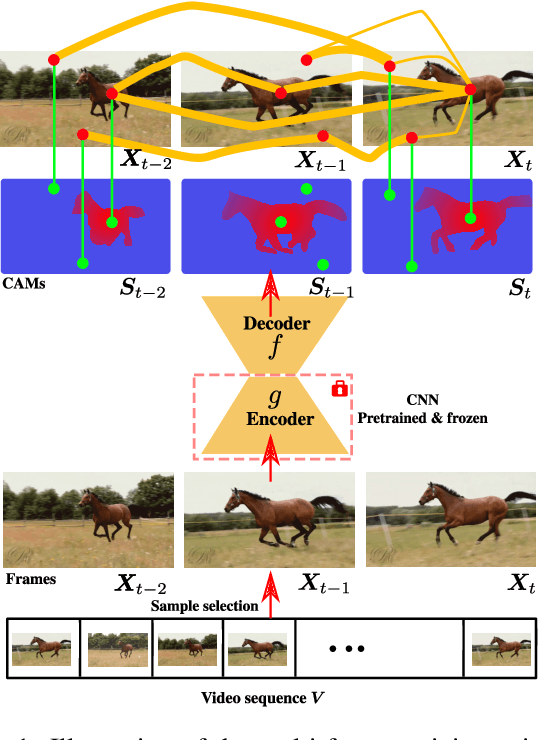
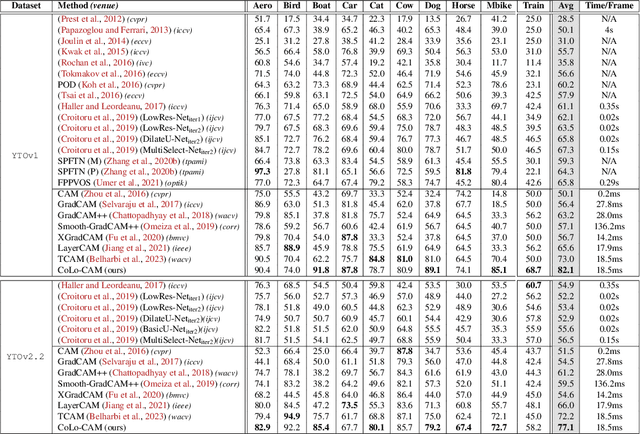
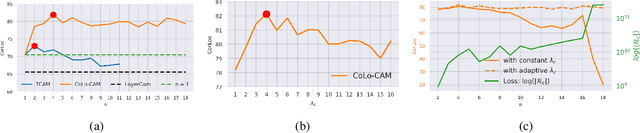

Weakly-supervised video object localization (WSVOL) methods often rely on visual and motion cues only, making them susceptible to inaccurate localization. Recently, discriminative models via a temporal class activation mapping (CAM) method have been explored. Although results are promising, objects are assumed to have minimal movement leading to degradation in performance for relatively long-term dependencies. In this paper, a novel CoLo-CAM method for object localization is proposed to leverage spatiotemporal information in activation maps without any assumptions about object movement. Over a given sequence of frames, explicit joint learning of localization is produced across these maps based on color cues, by assuming an object has similar color across frames. The CAMs' activations are constrained to activate similarly over pixels with similar colors, achieving co-localization. This joint learning creates direct communication among pixels across all image locations, and over all frames, allowing for transfer, aggregation, and correction of learned localization. This is achieved by minimizing a color term of a CRF loss over joint images/maps. In addition to our multi-frame constraint, we impose per-frame local constraints including pseudo-labels, and CRF loss in combination with a global size constraint to improve per-frame localization. Empirical experiments on two challenging datasets for unconstrained videos, YouTube-Objects, show the merits of our method, and its robustness to long-term dependencies, leading to new state-of-the-art localization performance. Public code: https://github.com/sbelharbi/colo-cam.
Web and Mobile Platforms for Managing Elections based on IoT And Machine Learning Algorithms
Mar 16, 2023The global pandemic situation has severely affected all countries. As a result, almost all countries had to adjust to online technologies to continue their processes. In addition, Sri Lanka is yearly spending ten billion on elections. We have examined a proper way of minimizing the cost of hosting these events online. To solve the existing problems and increase the time potency and cost reduction we have used IoT and ML-based technologies. IoT-based data will identify, register, and be used to secure from fraud, while ML algorithms manipulate the election data and produce winning predictions, weather-based voters attendance, and election violence. All the data will be saved in cloud computing and a standard database to store and access the data. This study mainly focuses on four aspects of an E-voting system. The most frequent problems across the world in E-voting are the security, accuracy, and reliability of the systems. E-government systems must be secured against various cyber-attacks and ensure that only authorized users can access valuable, and sometimes sensitive information. Being able to access a system without passwords but using biometric details has been there for a while now, however, our proposed system has a different approach to taking the credentials, processing, and combining the images, reformatting and producing the output, and tracking. In addition, we ensure to enhance e-voting safety. While ML-based algorithms use different data sets and provide predictions in advance.
Evaluation of distance-based approaches for forensic comparison: Application to hand odor evidence
Mar 16, 2023The issue of distinguishing between the same-source and different-source hypotheses based on various types of traces is a generic problem in forensic science. This problem is often tackled with Bayesian approaches, which are able to provide a likelihood ratio that quantifies the relative strengths of evidence supporting each of the two competing hypotheses. Here, we focus on distance-based approaches, whose robustness and specifically whose capacity to deal with high-dimensional evidence are very different, and need to be evaluated and optimized. A unified framework for direct methods based on estimating the likelihoods of the distance between traces under each of the two competing hypotheses, and indirect methods using logistic regression to discriminate between same-source and different-source distance distributions, is presented. Whilst direct methods are more flexible, indirect methods are more robust and quite natural in machine learning. Moreover, indirect methods also enable the use of a vectorial distance, thus preventing the severe information loss suffered by scalar distance approaches.Direct and indirect methods are compared in terms of sensitivity, specificity and robustness, with and without dimensionality reduction, with and without feature selection, on the example of hand odor profiles, a novel and challenging type of evidence in the field of forensics. Empirical evaluations on a large panel of 534 subjects and their 1690 odor traces show the significant superiority of the indirect methods, especially without dimensionality reduction, be it with or without feature selection.
A Preliminary Study on Pattern Reconstruction for Optimal Storage of Wearable Sensor Data
Feb 25, 2023
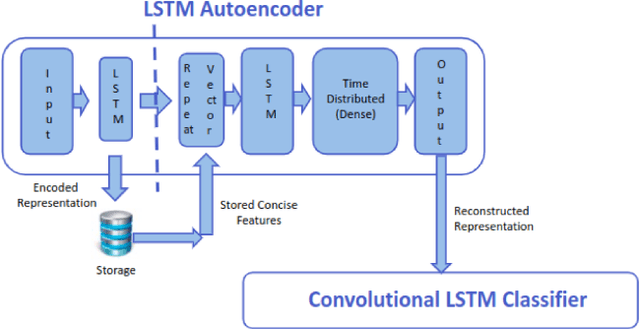
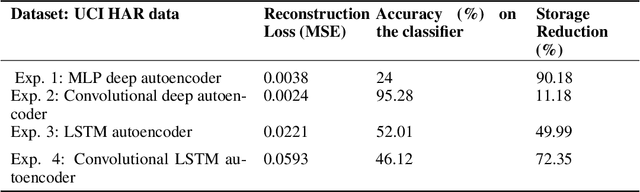
Efficient querying and retrieval of healthcare data is posing a critical challenge today with numerous connected devices continuously generating petabytes of images, text, and internet of things (IoT) sensor data. One approach to efficiently store the healthcare data is to extract the relevant and representative features and store only those features instead of the continuous streaming data. However, it raises a question as to the amount of information content we can retain from the data and if we can reconstruct the pseudo-original data when needed. By facilitating relevant and representative feature extraction, storage and reconstruction of near original pattern, we aim to address some of the challenges faced by the explosion of the streaming data. We present a preliminary study, where we explored multiple autoencoders for concise feature extraction and reconstruction for human activity recognition (HAR) sensor data. Our Multi-Layer Perceptron (MLP) deep autoencoder achieved a storage reduction of 90.18% compared to the three other implemented autoencoders namely convolutional autoencoder, Long-Short Term Memory (LSTM) autoencoder, and convolutional LSTM autoencoder which achieved storage reductions of 11.18%, 49.99%, and 72.35% respectively. Encoded features from the autoencoders have smaller size and dimensions which help to reduce the storage space. For higher dimensions of the representation, storage reduction was low. But retention of relevant information was high, which was validated by classification performed on the reconstructed data.
Query-Utterance Attention with Joint modeling for Query-Focused Meeting Summarization
Mar 08, 2023
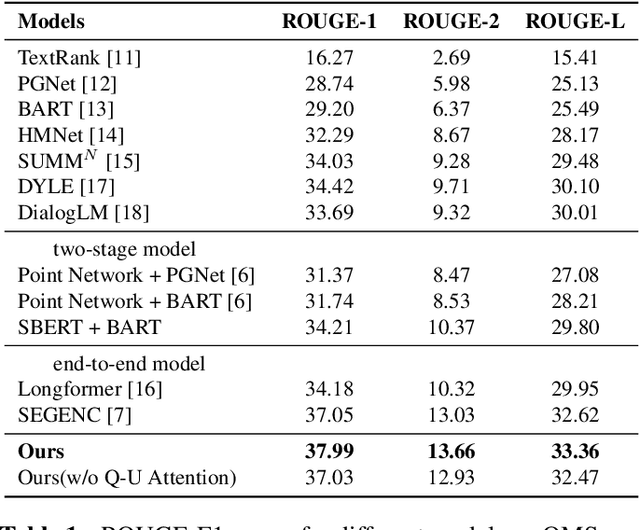
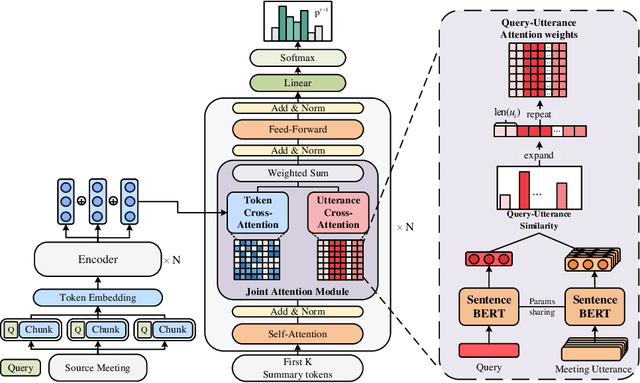

Query-focused meeting summarization (QFMS) aims to generate summaries from meeting transcripts in response to a given query. Previous works typically concatenate the query with meeting transcripts and implicitly model the query relevance only at the token level with attention mechanism. However, due to the dilution of key query-relevant information caused by long meeting transcripts, the original transformer-based model is insufficient to highlight the key parts related to the query. In this paper, we propose a query-aware framework with joint modeling token and utterance based on Query-Utterance Attention. It calculates the utterance-level relevance to the query with a dense retrieval module. Then both token-level query relevance and utterance-level query relevance are combined and incorporated into the generation process with attention mechanism explicitly. We show that the query relevance of different granularities contributes to generating a summary more related to the query. Experimental results on the QMSum dataset show that the proposed model achieves new state-of-the-art performance.
Can Membership Inferencing be Refuted?
Mar 08, 2023
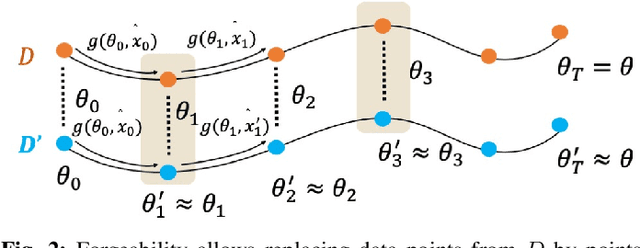
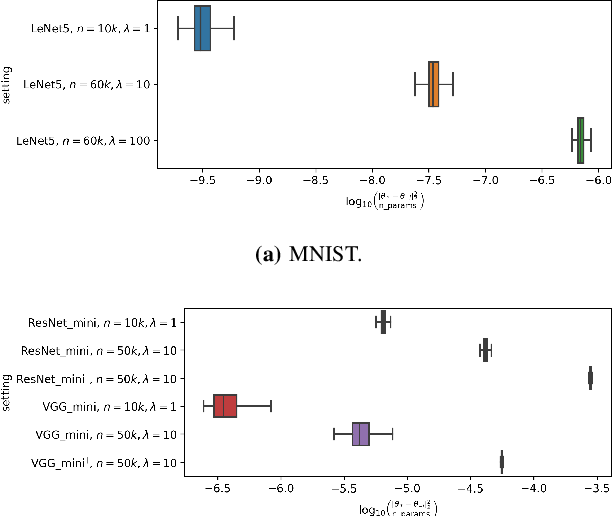

Membership inference (MI) attack is currently the most popular test for measuring privacy leakage in machine learning models. Given a machine learning model, a data point and some auxiliary information, the goal of an MI attack is to determine whether the data point was used to train the model. In this work, we study the reliability of membership inference attacks in practice. Specifically, we show that a model owner can plausibly refute the result of a membership inference test on a data point $x$ by constructing a proof of repudiation that proves that the model was trained without $x$. We design efficient algorithms to construct proofs of repudiation for all data points of the training dataset. Our empirical evaluation demonstrates the practical feasibility of our algorithm by constructing proofs of repudiation for popular machine learning models on MNIST and CIFAR-10. Consequently, our results call for a re-evaluation of the implications of membership inference attacks in practice.
Approach to Learning Generalized Audio Representation Through Batch Embedding Covariance Regularization and Constant-Q Transforms
Mar 07, 2023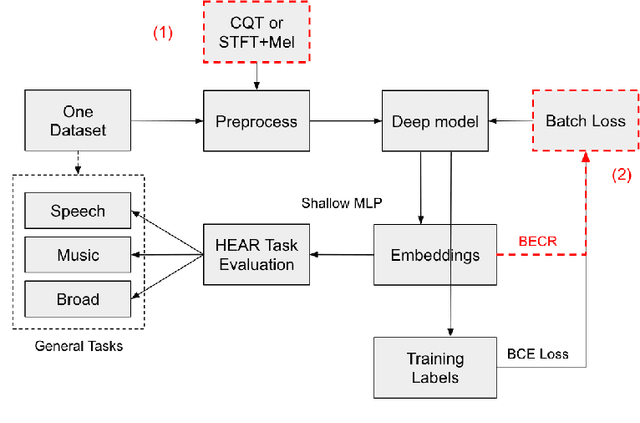
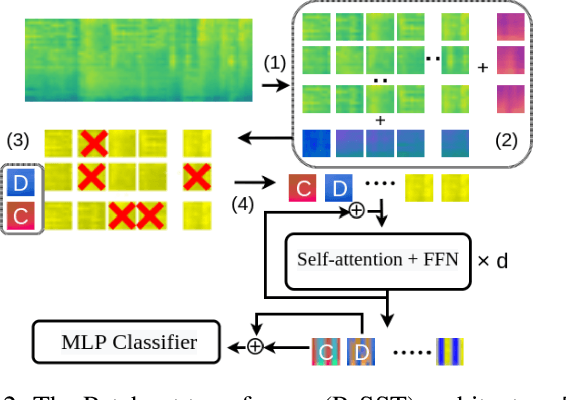
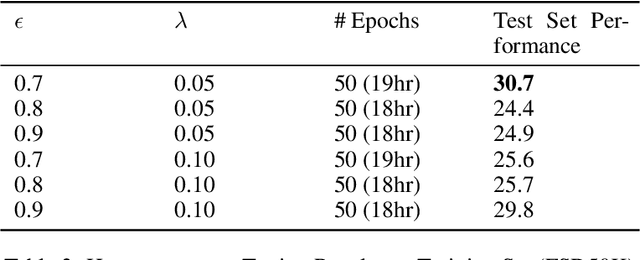
General-purpose embedding is highly desirable for few-shot even zero-shot learning in many application scenarios, including audio tasks. In order to understand representations better, we conducted a thorough error analysis and visualization of HEAR 2021 submission results. Inspired by the analysis, this work experiments with different front-end audio preprocessing methods, including Constant-Q Transform (CQT) and Short-time Fourier transform (STFT), and proposes a Batch Embedding Covariance Regularization (BECR) term to uncover a more holistic simulation of the frequency information received by the human auditory system. We tested the models on the suite of HEAR 2021 tasks, which encompass a broad category of tasks. Preliminary results show (1) the proposed BECR can incur a more dispersed embedding on the test set, (2) BECR improves the PaSST model without extra computation complexity, and (3) STFT preprocessing outperforms CQT in all tasks we tested. Github:https://github.com/ankitshah009/general_audio_embedding_hear_2021
A Multi-Stage Triple-Path Method for Speech Separation in Noisy and Reverberant Environments
Mar 07, 2023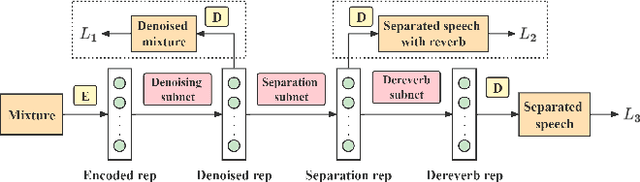
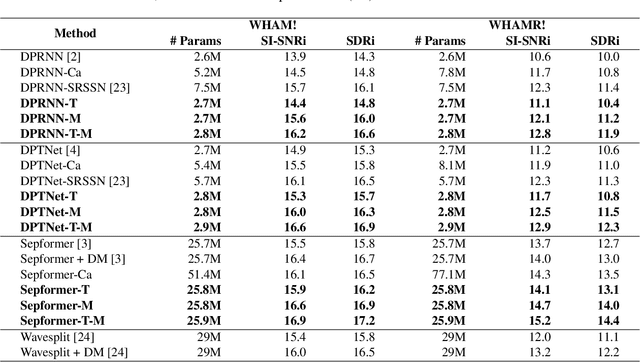
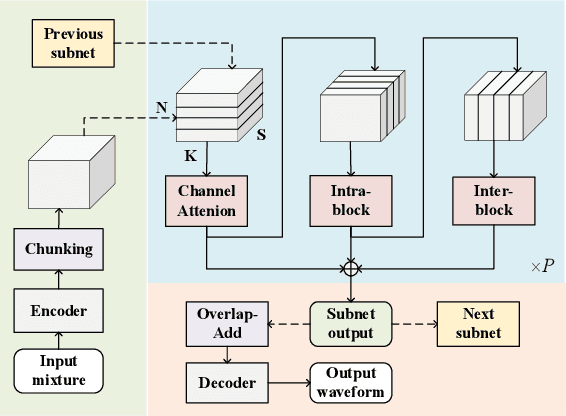
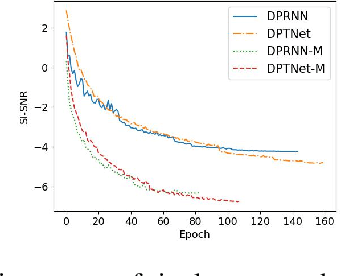
In noisy and reverberant environments, the performance of deep learning-based speech separation methods drops dramatically because previous methods are not designed and optimized for such situations. To address this issue, we propose a multi-stage end-to-end learning method that decouples the difficult speech separation problem in noisy and reverberant environments into three sub-problems: speech denoising, separation, and de-reverberation. The probability and speed of searching for the optimal solution of the speech separation model are improved by reducing the solution space. Moreover, since the channel information of the audio sequence in the time domain is crucial for speech separation, we propose a triple-path structure capable of modeling the channel dimension of audio sequences. Experimental results show that the proposed multi-stage triple-path method can improve the performance of speech separation models at the cost of little model parameter increment.
Building Shortcuts between Distant Nodes with Biaffine Mapping for Graph Convolutional Networks
Feb 20, 2023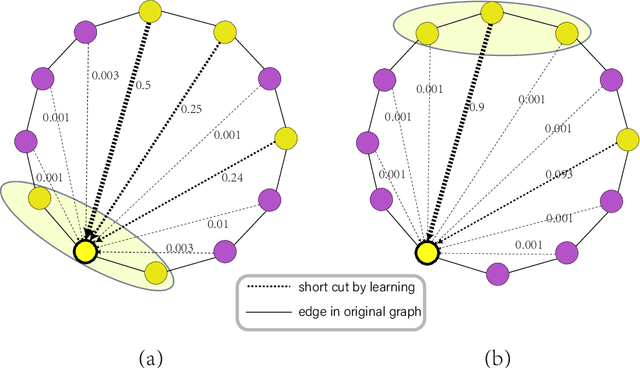
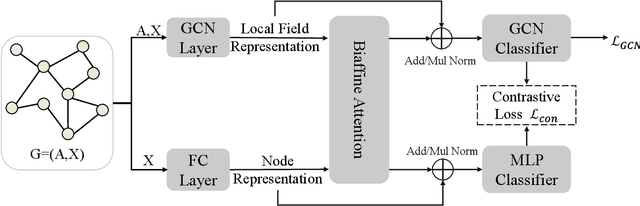
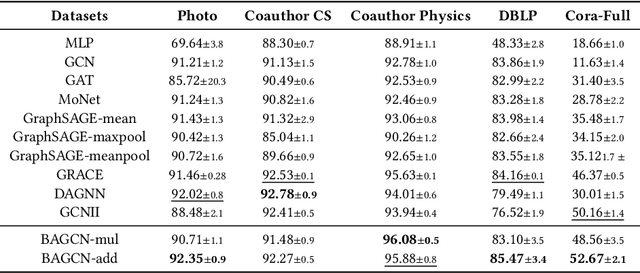
Multiple recent studies show a paradox in graph convolutional networks (GCNs), that is, shallow architectures limit the capability of learning information from high-order neighbors, while deep architectures suffer from over-smoothing or over-squashing. To enjoy the simplicity of shallow architectures and overcome their limits of neighborhood extension, in this work, we introduce Biaffine technique to improve the expressiveness of graph convolutional networks with a shallow architecture. The core design of our method is to learn direct dependency on long-distance neighbors for nodes, with which only one-hop message passing is capable of capturing rich information for node representation. Besides, we propose a multi-view contrastive learning method to exploit the representations learned from long-distance dependencies. Extensive experiments on nine graph benchmark datasets suggest that the shallow biaffine graph convolutional networks (BAGCN) significantly outperforms state-of-the-art GCNs (with deep or shallow architectures) on semi-supervised node classification. We further verify the effectiveness of biaffine design in node representation learning and the performance consistency on different sizes of training data.
CNTS: Cooperative Network for Time Series
Feb 20, 2023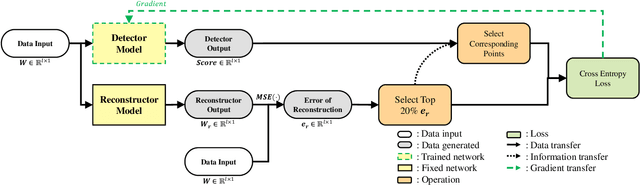
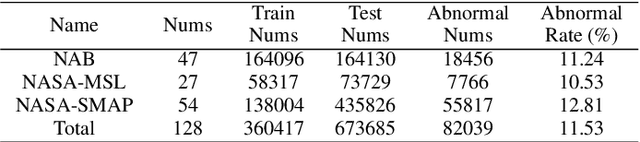
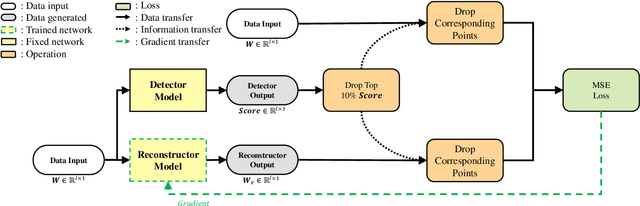
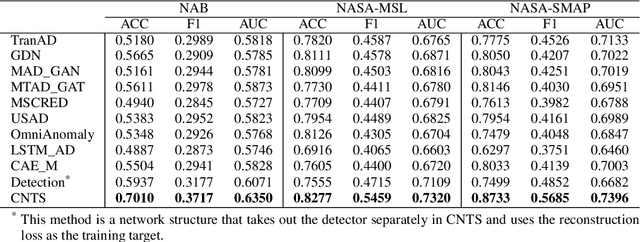
The use of deep learning techniques in detecting anomalies in time series data has been an active area of research with a long history of development and a variety of approaches. In particular, reconstruction-based unsupervised anomaly detection methods have gained popularity due to their intuitive assumptions and low computational requirements. However, these methods are often susceptible to outliers and do not effectively model anomalies, leading to suboptimal results. This paper presents a novel approach for unsupervised anomaly detection, called the Cooperative Network Time Series (CNTS) approach. The CNTS system consists of two components: a detector and a reconstructor. The detector is responsible for directly detecting anomalies, while the reconstructor provides reconstruction information to the detector and updates its learning based on anomalous information received from the detector. The central aspect of CNTS is a multi-objective optimization problem, which is solved through a cooperative solution strategy. Experiments on three real-world datasets demonstrate the state-of-the-art performance of CNTS and confirm the cooperative effectiveness of the detector and reconstructor. The source code for this study is publicly available on GitHub.