 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
F2BEV: Bird's Eye View Generation from Surround-View Fisheye Camera Images for Automated Driving
Mar 07, 2023
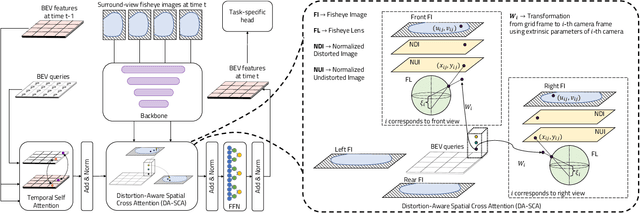



Bird's Eye View (BEV) representations are tremendously useful for perception-related automated driving tasks. However, generating BEVs from surround-view fisheye camera images is challenging due to the strong distortions introduced by such wide-angle lenses. We take the first step in addressing this challenge and introduce a baseline, F2BEV, to generate BEV height maps and semantic segmentation maps from fisheye images. F2BEV consists of a distortion-aware spatial cross attention module for querying and consolidating spatial information from fisheye image features in a transformer-style architecture followed by a task-specific head. We evaluate single-task and multi-task variants of F2BEV on our synthetic FB-SSEM dataset, all of which generate better BEV height and segmentation maps (in terms of the IoU) than a state-of-the-art BEV generation method operating on undistorted fisheye images. We also demonstrate height map generation from real-world fisheye images using F2BEV. An initial sample of our dataset is publicly available at https://tinyurl.com/58jvnscy
Spherical Space Feature Decomposition for Guided Depth Map Super-Resolution
Mar 15, 2023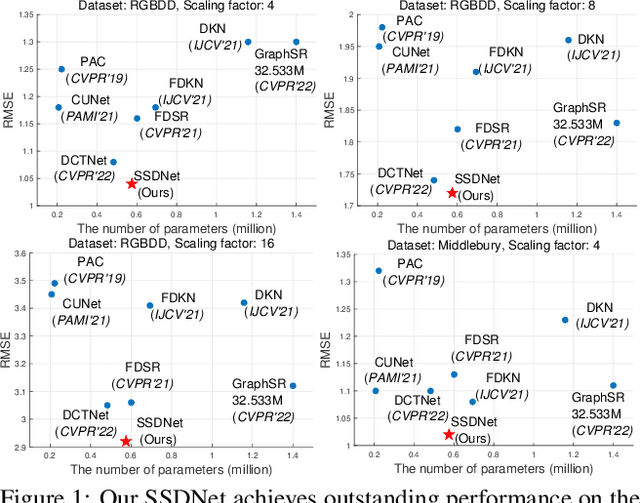
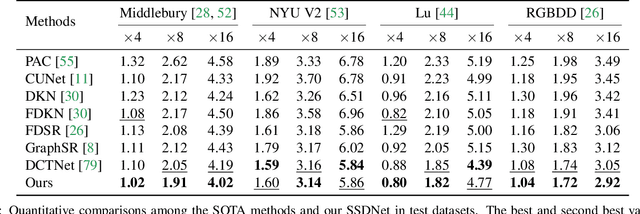
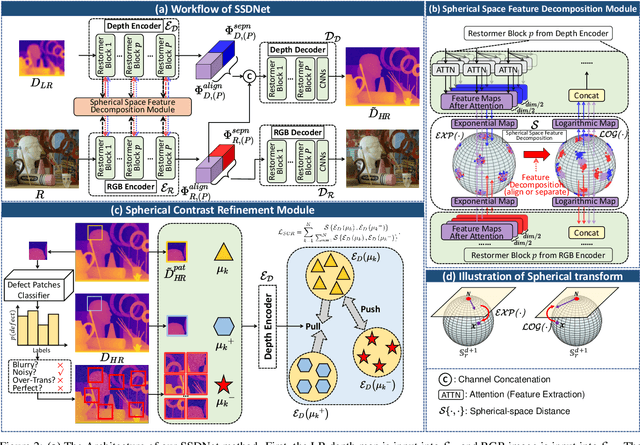

Guided depth map super-resolution (GDSR), as a hot topic in multi-modal image processing, aims to upsample low-resolution (LR) depth maps with additional information involved in high-resolution (HR) RGB images from the same scene. The critical step of this task is to effectively extract domain-shared and domain-private RGB/depth features. In addition, three detailed issues, namely blurry edges, noisy surfaces, and over-transferred RGB texture, need to be addressed. In this paper, we propose the Spherical Space feature Decomposition Network (SSDNet) to solve the above issues. To better model cross-modality features, Restormer block-based RGB/depth encoders are employed for extracting local-global features. Then, the extracted features are mapped to the spherical space to complete the separation of private features and the alignment of shared features. Shared features of RGB are fused with the depth features to complete the GDSR task. Subsequently, a spherical contrast refinement (SCR) module is proposed to further address the detail issues. Patches that are classified according to imperfect categories are input to the SCR module, where the patch features are pulled closer to the ground truth and pushed away from the corresponding imperfect samples in the spherical feature space via contrastive learning. Extensive experiments demonstrate that our method can achieve state-of-the-art results on four test datasets and can successfully generalize to real-world scenes. Code will be released.
A Triplet-loss Dilated Residual Network for High-Resolution Representation Learning in Image Retrieval
Mar 15, 2023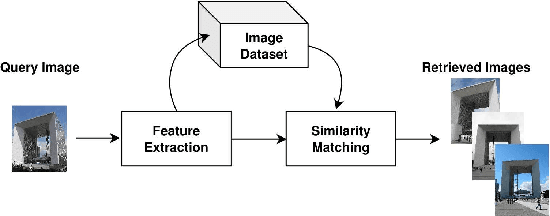
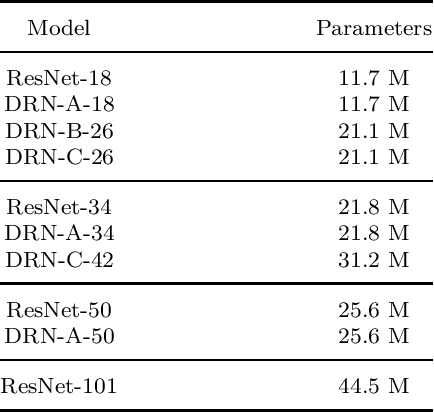
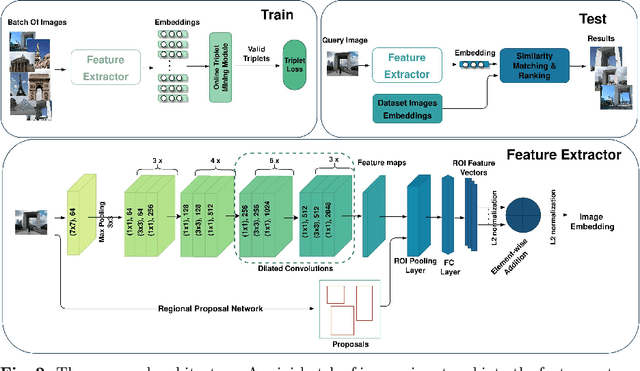

Content-based image retrieval is the process of retrieving a subset of images from an extensive image gallery based on visual contents, such as color, shape or spatial relations, and texture. In some applications, such as localization, image retrieval is employed as the initial step. In such cases, the accuracy of the top-retrieved images significantly affects the overall system accuracy. The current paper introduces a simple yet efficient image retrieval system with a fewer trainable parameters, which offers acceptable accuracy in top-retrieved images. The proposed method benefits from a dilated residual convolutional neural network with triplet loss. Experimental evaluations show that this model can extract richer information (i.e., high-resolution representations) by enlarging the receptive field, thus improving image retrieval accuracy without increasing the depth or complexity of the model. To enhance the extracted representations' robustness, the current research obtains candidate regions of interest from each feature map and applies Generalized-Mean pooling to the regions. As the choice of triplets in a triplet-based network affects the model training, we employ a triplet online mining method. We test the performance of the proposed method under various configurations on two of the challenging image-retrieval datasets, namely Revisited Paris6k (RPar) and UKBench. The experimental results show an accuracy of 94.54 and 80.23 (mean precision at rank 10) in the RPar medium and hard modes and 3.86 (recall at rank 4) in the UKBench dataset, respectively.
Efficient and Secure Federated Learning for Financial Applications
Mar 15, 2023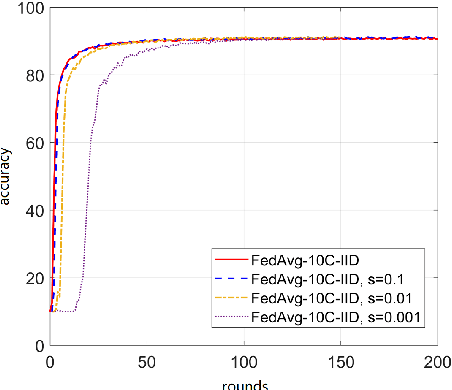

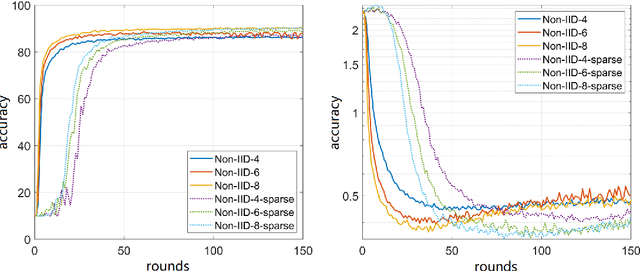
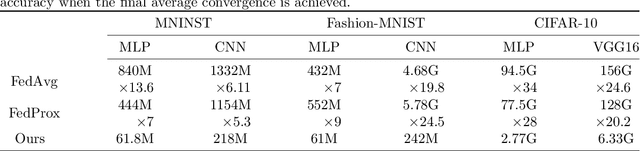
The conventional machine learning (ML) and deep learning approaches need to share customers' sensitive information with an external credit bureau to generate a prediction model that opens the door to privacy leakage. This leakage risk makes financial companies face an enormous challenge in their cooperation. Federated learning is a machine learning setting that can protect data privacy, but the high communication cost is often the bottleneck of the federated systems, especially for large neural networks. Limiting the number and size of communications is necessary for the practical training of large neural structures. Gradient sparsification has received increasing attention as a method to reduce communication cost, which only updates significant gradients and accumulates insignificant gradients locally. However, the secure aggregation framework cannot directly use gradient sparsification. This article proposes two sparsification methods to reduce communication cost in federated learning. One is a time-varying hierarchical sparsification method for model parameter update, which solves the problem of maintaining model accuracy after high ratio sparsity. It can significantly reduce the cost of a single communication. The other is to apply the sparsification method to the secure aggregation framework. We sparse the encryption mask matrix to reduce the cost of communication while protecting privacy. Experiments show that under different Non-IID experiment settings, our method can reduce the upload communication cost to about 2.9% to 18.9% of the conventional federated learning algorithm when the sparse rate is 0.01.
SKGHOI: Spatial-Semantic Knowledge Graph for Human-Object Interaction Detection
Mar 15, 2023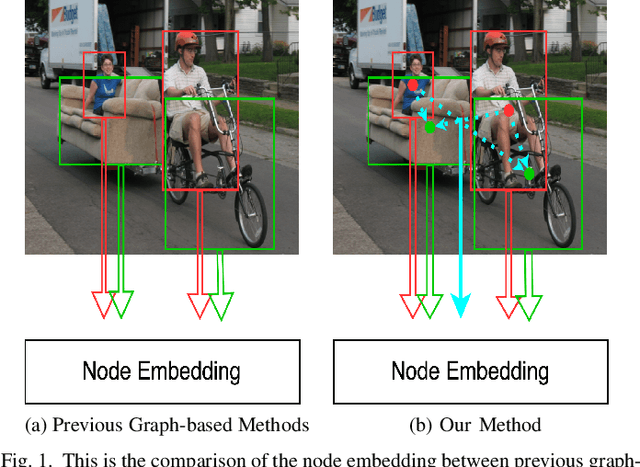
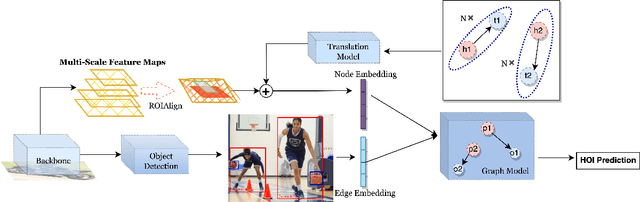
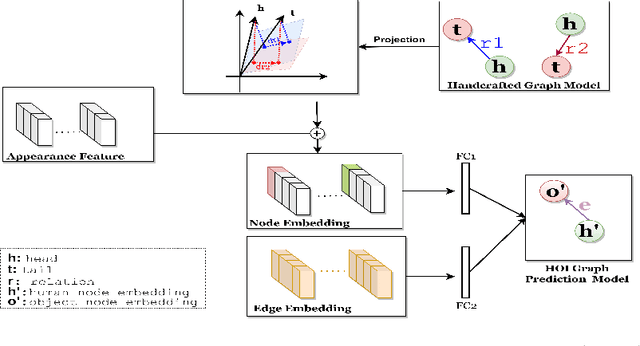
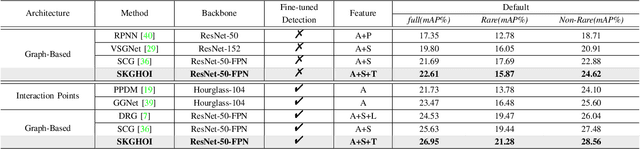
Detecting human-object interactions (HOIs) is a challenging problem in computer vision. Existing techniques for HOI detection heavily rely on appearance-based features, which may not capture other essential characteristics for accurate detection. Furthermore, the use of transformer-based models for sentiment representation of human-object pairs can be computationally expensive. To address these challenges, we propose a novel graph-based approach, SKGHOI (Spatial-Semantic Knowledge Graph for Human-Object Interaction Detection), that effectively captures the sentiment representation of HOIs by integrating both spatial and semantic knowledge. In a graph, SKGHOI takes the components of interaction as nodes, and the spatial relationships between them as edges. Our approach employs a spatial encoder and a semantic encoder to extract spatial and semantic information, respectively, and then combines these encodings to create a knowledge graph that captures the sentiment representation of HOIs. Compared to existing techniques, SKGHOI is computationally efficient and allows for the incorporation of prior knowledge, making it practical for use in real-world applications. We demonstrate the effectiveness of our proposed method on the widely-used HICO-DET datasets, where it outperforms existing state-of-the-art graph-based methods by a significant margin. Our results indicate that the SKGHOI approach has the potential to significantly improve the accuracy and efficiency of HOI detection, and we anticipate that it will be of great interest to researchers and practitioners working on this challenging task.
Lung Nodule Segmentation and Low-Confidence Region Prediction with Uncertainty-Aware Attention Mechanism
Mar 15, 2023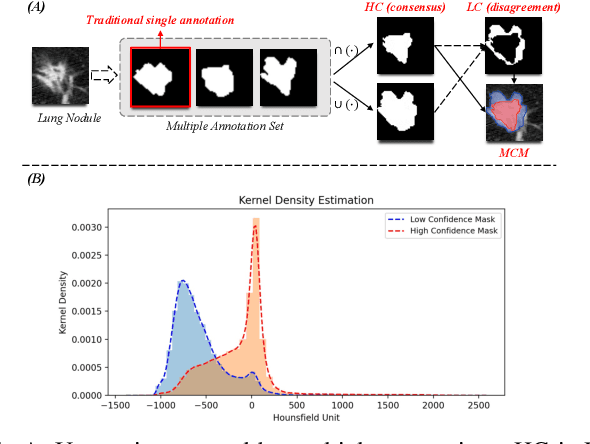

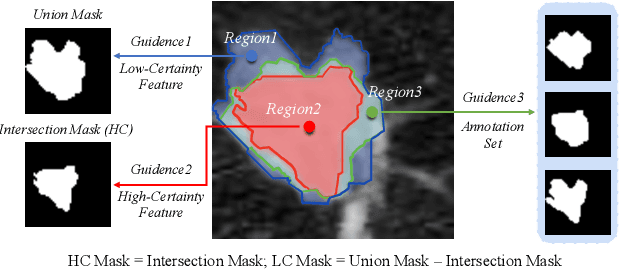
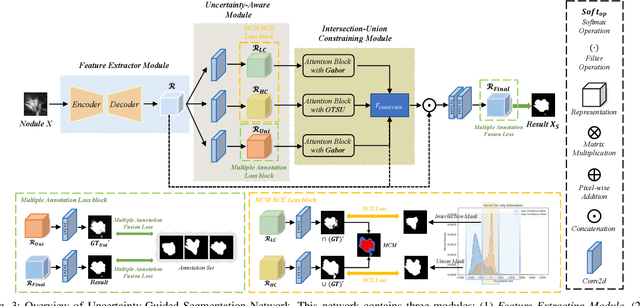
Radiologists have different training and clinical experiences, so they may provide various segmentation annotations for a lung nodule, which causes segmentation uncertainty among multiple annotations. Conventional methods usually chose a single annotation as the learning target or tried to learn a latent space of various annotations. Still, they wasted the valuable information of consensus or disagreements ingrained in the multiple annotations. This paper proposes an Uncertainty-Aware Attention Mechanism (UAAM), which utilizes consensus or disagreements among annotations to produce a better segmentation. In UAAM, we propose a Multi-Confidence Mask (MCM), which is a combination of a Low-Confidence (LC) Mask and a High-Confidence (HC) Mask. LC mask indicates regions with low segmentation confidence, which may cause different segmentation options among radiologists. Following UAAM, we further design an Uncertainty-Guide Segmentation Network (UGS-Net), which contains three modules:Feature Extracting Module captures a general feature of a lung nodule. Uncertainty-Aware Module produce three features for the annotations' union, intersection, and annotation set. Finally, Intersection-Union Constraining Module use distances between three features to balance the predictions of final segmentation, LC mask, and HC mask. To fully demonstrate the performance of our method, we propose a Complex Nodule Challenge on LIDC-IDRI, which tests UGS-Net's segmentation performance on the lung nodules that are difficult to segment by U-Net. Experimental results demonstrate that our method can significantly improve the segmentation performance on nodules with poor segmentation by U-Net.
Robust Dominant Periodicity Detection for Time Series with Missing Data
Mar 06, 2023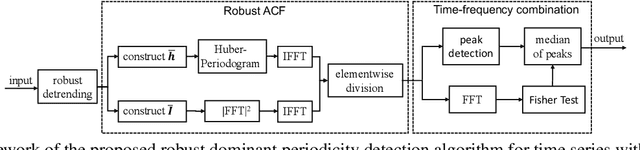
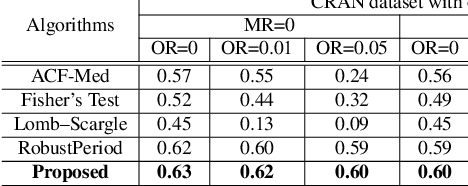
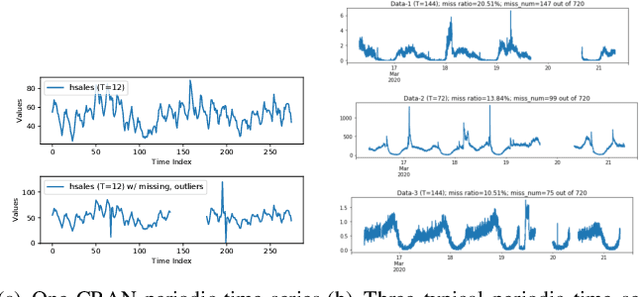
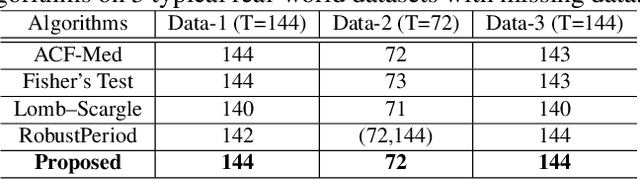
Periodicity detection is an important task in time series analysis, but still a challenging problem due to the diverse characteristics of time series data like abrupt trend change, outlier, noise, and especially block missing data. In this paper, we propose a robust and effective periodicity detection algorithm for time series with block missing data. We first design a robust trend filter to remove the interference of complicated trend patterns under missing data. Then, we propose a robust autocorrelation function (ACF) that can handle missing values and outliers effectively. We rigorously prove that the proposed robust ACF can still work well when the length of the missing block is less than $1/3$ of the period length. Last, by combining the time-frequency information, our algorithm can generate the period length accurately. The experimental results demonstrate that our algorithm outperforms existing periodicity detection algorithms on real-world time series datasets.
* Accepted by 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2023)
A unified scalable framework for causal sweeping strategies for Physics-Informed Neural Networks (PINNs) and their temporal decompositions
Feb 28, 2023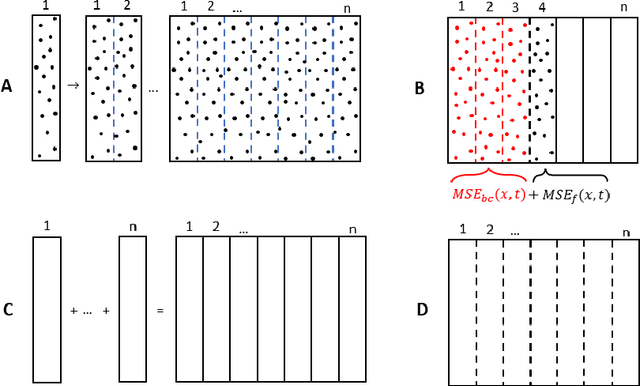

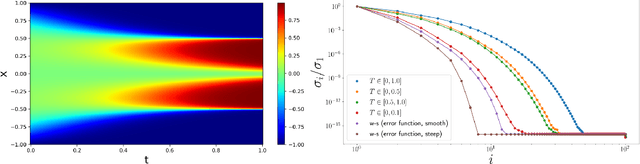
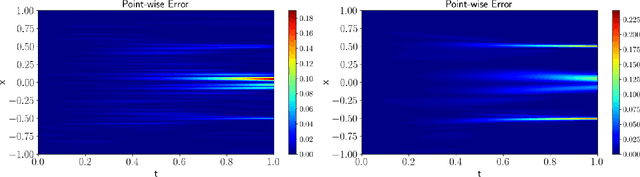
Physics-informed neural networks (PINNs) as a means of solving partial differential equations (PDE) have garnered much attention in Computational Science and Engineering (CS&E). However, a recent topic of interest is exploring various training (i.e., optimization) challenges - in particular, arriving at poor local minima in the optimization landscape results in a PINN approximation giving an inferior, and sometimes trivial, solution when solving forward time-dependent PDEs with no data. This problem is also found in, and in some sense more difficult, with domain decomposition strategies such as temporal decomposition using XPINNs. To address this problem, we first enable a general categorization for previous causality methods, from which we identify a gap in the previous approaches. We then furnish examples and explanations for different training challenges, their cause, and how they relate to information propagation and temporal decomposition. We propose a solution to fill this gap by reframing these causality concepts into a generalized information propagation framework in which any prior method or combination of methods can be described. Our unified framework moves toward reducing the number of PINN methods to consider and the implementation and retuning cost for thorough comparisons. We propose a new stacked-decomposition method that bridges the gap between time-marching PINNs and XPINNs. We also introduce significant computational speed-ups by using transfer learning concepts to initialize subnetworks in the domain and loss tolerance-based propagation for the subdomains. We formulate a new time-sweeping collocation point algorithm inspired by the previous PINNs causality literature, which our framework can still describe, and provides a significant computational speed-up via reduced-cost collocation point segmentation. Finally, we provide numerical results on baseline PDE problems.
Towards Diverse Temporal Grounding under Single Positive Labels
Mar 12, 2023
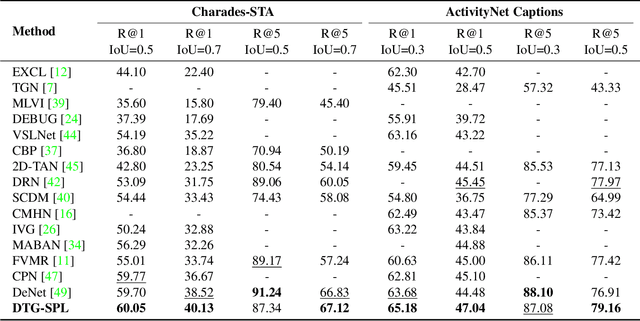
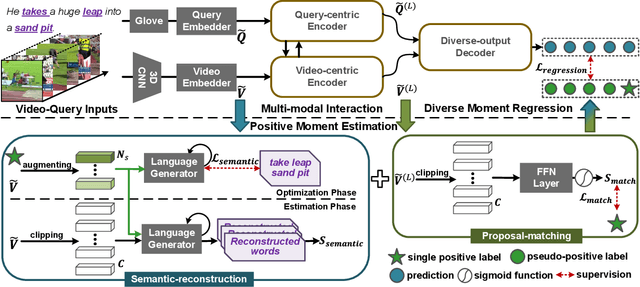
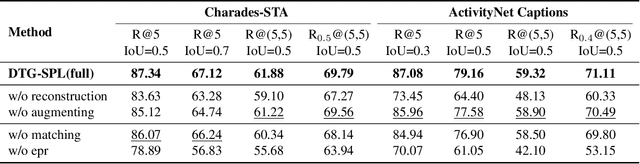
Temporal grounding aims to retrieve moments of the described event within an untrimmed video by a language query. Typically, existing methods assume annotations are precise and unique, yet one query may describe multiple moments in many cases. Hence, simply taking it as a one-vs-one mapping task and striving to match single-label annotations will inevitably introduce false negatives during optimization. In this study, we reformulate this task as a one-vs-many optimization problem under the condition of single positive labels. The unlabeled moments are considered unobserved rather than negative, and we explore mining potential positive moments to assist in multiple moment retrieval. In this setting, we propose a novel Diverse Temporal Grounding framework, termed DTG-SPL, which mainly consists of a positive moment estimation (PME) module and a diverse moment regression (DMR) module. PME leverages semantic reconstruction information and an expected positive regularization to uncover potential positive moments in an online fashion. Under the supervision of these pseudo positives, DMR is able to localize diverse moments in parallel that meet different users. The entire framework allows for end-to-end optimization as well as fast inference. Extensive experiments on Charades-STA and ActivityNet Captions show that our method achieves superior performance in terms of both single-label and multi-label metrics.
IFF: A Super-resolution Algorithm for Multiple Measurements
Mar 12, 2023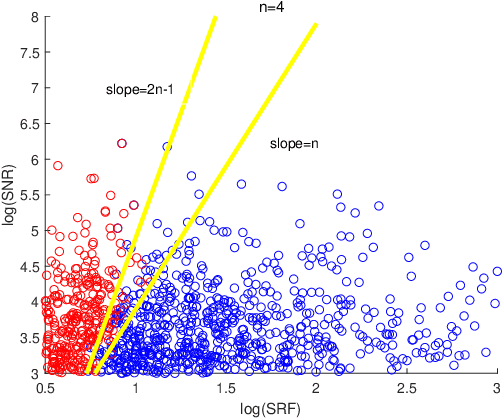
We consider the problem of reconstructing one-dimensional point sources from their Fourier measurements in a bounded interval $[-\Omega, \Omega]$. This problem is known to be challenging in the regime where the spacing of the sources is below the Rayleigh length $\frac{\pi}{\Omega}$. In this paper, we propose a super-resolution algorithm, called Iterative Focusing-localization and Filtering (IFF), to resolve closely spaced point sources from their multiple measurements that are obtained by using multiple unknown illumination patterns. The new proposed algorithm has a distinct feature in that it reconstructs the point sources one by one in an iterative manner and hence requires no prior information about the source numbers. The new feature also allows for a subsampling strategy that can circumvent the computation of singular-value decomposition for large matrices as in the usual subspace methods. A theoretical analysis of the methods behind the algorithm is also provided. The derived results imply a phase transition phenomenon in the reconstruction of source locations which is confirmed in numerical experiments. Numerical results show that the algorithm can achieve a stable reconstruction for point sources with a minimum separation distance that is close to the theoretical limit. The algorithm can be generalized to higher dimensions.