 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Progressive Content-aware Coded Hyperspectral Compressive Imaging
Mar 17, 2023
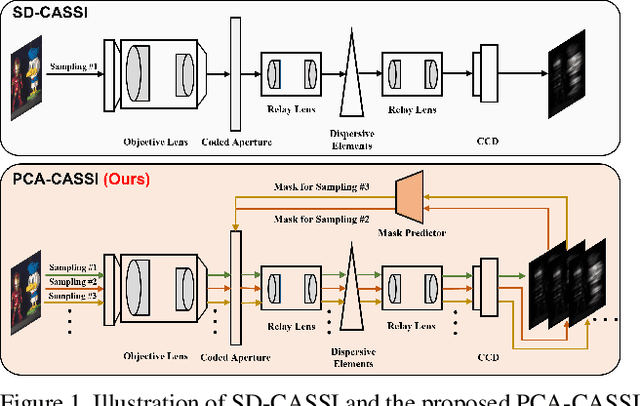

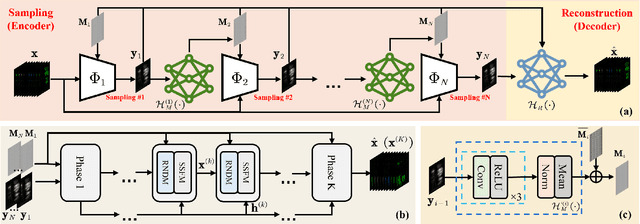
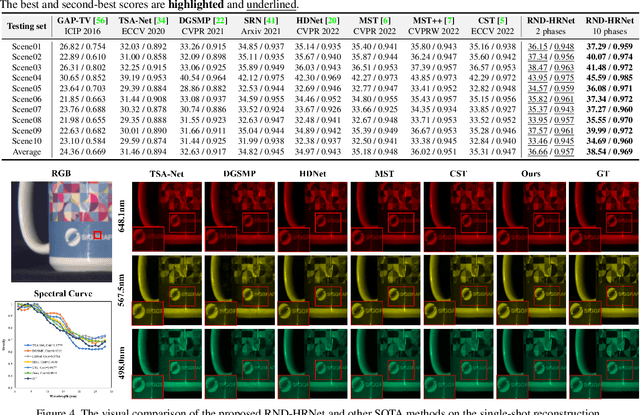
Hyperspectral imaging plays a pivotal role in a wide range of applications, like remote sensing, medicine, and cytology. By acquiring 3D hyperspectral images (HSIs) via 2D sensors, the coded aperture snapshot spectral imaging (CASSI) has achieved great success due to its hardware-friendly implementation and fast imaging speed. However, for some less spectrally sparse scenes, single snapshot and unreasonable coded aperture design tend to make HSI recovery more ill-posed and yield poor spatial and spectral fidelity. In this paper, we propose a novel Progressive Content-Aware CASSI framework, dubbed PCA-CASSI, which captures HSIs with multiple optimized content-aware coded apertures and fuses all the snapshots for reconstruction progressively. Simultaneously, by mapping the Range-Null space Decomposition (RND) into a deep network with several phases, an RND-HRNet is proposed for HSI recovery. Each recovery phase can fully exploit the hidden physical information in the coded apertures via explicit $\mathcal{R}$$-$$\mathcal{N}$ decomposition and explore the spatial-spectral correlation by dual transformer blocks. Our method is validated to surpass other state-of-the-art methods on both multiple- and single-shot HSI imaging tasks by large margins.
Self-Correctable and Adaptable Inference for Generalizable Human Pose Estimation
Mar 20, 2023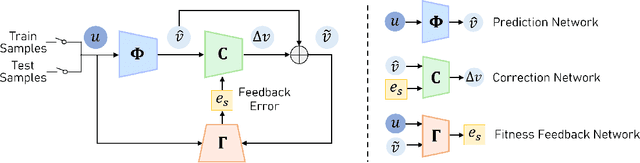
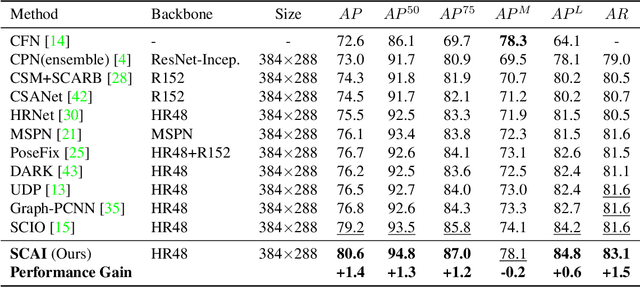
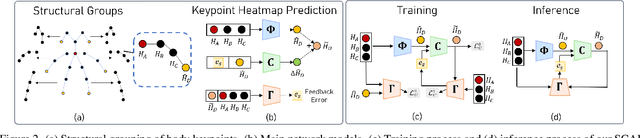
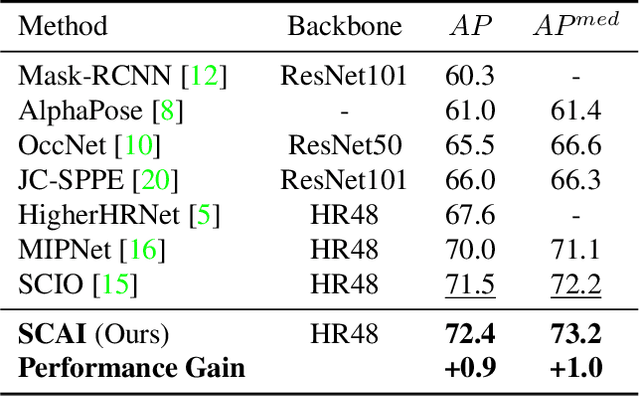
A central challenge in human pose estimation, as well as in many other machine learning and prediction tasks, is the generalization problem. The learned network does not have the capability to characterize the prediction error, generate feedback information from the test sample, and correct the prediction error on the fly for each individual test sample, which results in degraded performance in generalization. In this work, we introduce a self-correctable and adaptable inference (SCAI) method to address the generalization challenge of network prediction and use human pose estimation as an example to demonstrate its effectiveness and performance. We learn a correction network to correct the prediction result conditioned by a fitness feedback error. This feedback error is generated by a learned fitness feedback network which maps the prediction result to the original input domain and compares it against the original input. Interestingly, we find that this self-referential feedback error is highly correlated with the actual prediction error. This strong correlation suggests that we can use this error as feedback to guide the correction process. It can be also used as a loss function to quickly adapt and optimize the correction network during the inference process. Our extensive experimental results on human pose estimation demonstrate that the proposed SCAI method is able to significantly improve the generalization capability and performance of human pose estimation.
Improving Table Structure Recognition with Visual-Alignment Sequential Coordinate Modeling
Mar 20, 2023
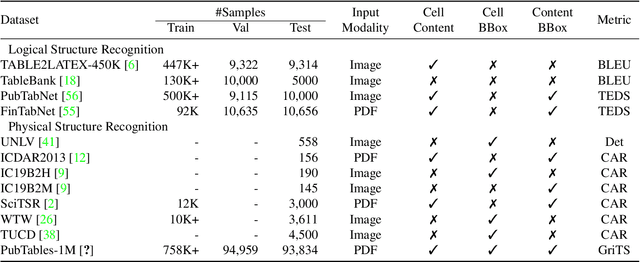
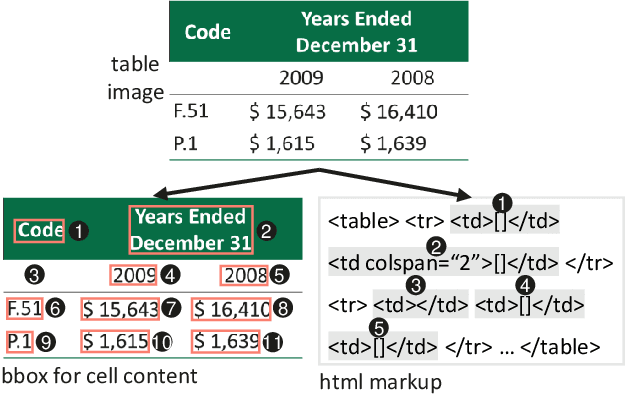
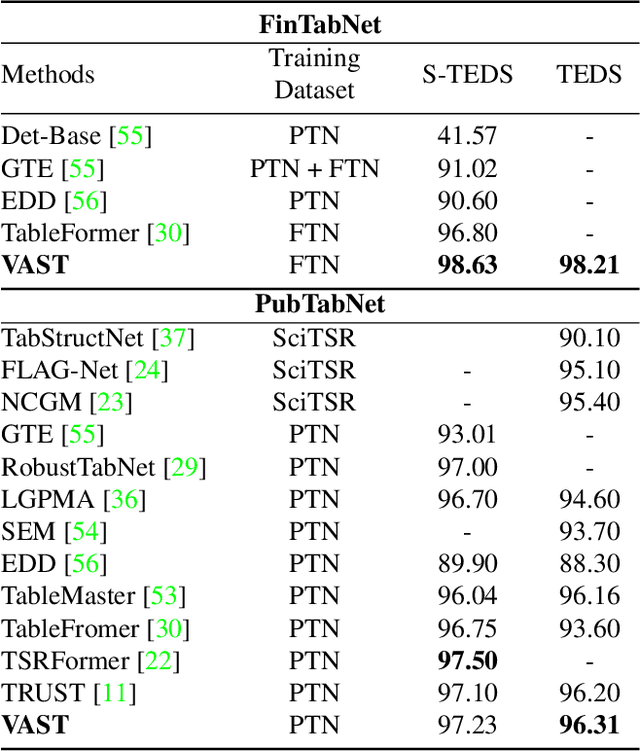
Table structure recognition aims to extract the logical and physical structure of unstructured table images into a machine-readable format. The latest end-to-end image-to-text approaches simultaneously predict the two structures by two decoders, where the prediction of the physical structure (the bounding boxes of the cells) is based on the representation of the logical structure. However, the previous methods struggle with imprecise bounding boxes as the logical representation lacks local visual information. To address this issue, we propose an end-to-end sequential modeling framework for table structure recognition called VAST. It contains a novel coordinate sequence decoder triggered by the representation of the non-empty cell from the logical structure decoder. In the coordinate sequence decoder, we model the bounding box coordinates as a language sequence, where the left, top, right and bottom coordinates are decoded sequentially to leverage the inter-coordinate dependency. Furthermore, we propose an auxiliary visual-alignment loss to enforce the logical representation of the non-empty cells to contain more local visual details, which helps produce better cell bounding boxes. Extensive experiments demonstrate that our proposed method can achieve state-of-the-art results in both logical and physical structure recognition. The ablation study also validates that the proposed coordinate sequence decoder and the visual-alignment loss are the keys to the success of our method.
Computing Functions Over-the-Air Using Digital Modulations
Mar 20, 2023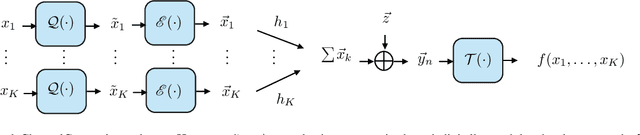
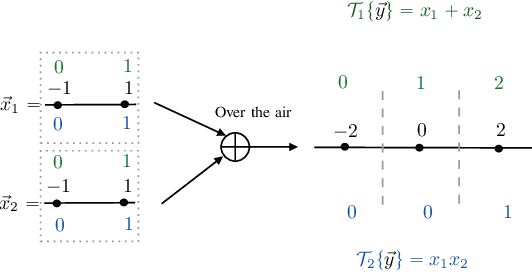
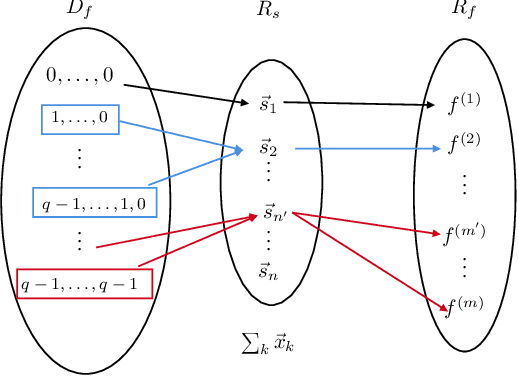
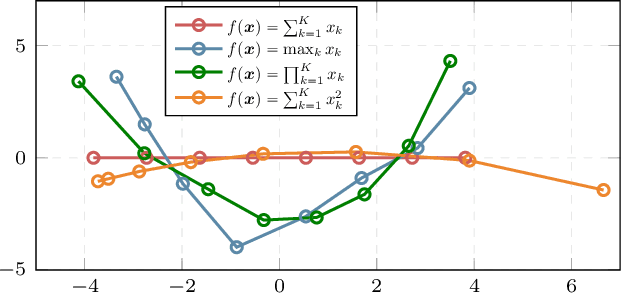
Over-the-air computation (AirComp) is a known technique in which wireless devices transmit values by analog amplitude modulation so that a function of these values is computed over the communication channel at a common receiver. The physical reason is the superposition properties of the electromagnetic waves, which naturally return sums of analog values. Consequently, the applications of AirComp are almost entirely restricted to analog communication systems. However, the use of digital communications for over-the-air computations would have several benefits, such as error correction, synchronization, acquisition of channel state information, and easier adoption by current digital communication systems. Nevertheless, a common belief is that digital modulations are generally unfeasible for computation tasks because the overlapping of digitally modulated signals returns signals that seem to be meaningless for these tasks. This paper breaks through such a belief and proposes a fundamentally new computing method, named ChannelComp, for performing over-the-air computations by any digital modulation. In particular, we propose digital modulation formats that allow us to compute a wider class of functions than AirComp can compute, and we propose a feasibility optimization problem that ascertains the optimal digital modulation for computing functions over-the-air. The simulation results verify the superior performance of ChannelComp in comparison to AirComp, particularly for the product functions, with around 10 dB improvement of the computation error.
Offline-Online Class-incremental Continual Learning via Dual-prototype Self-augment and Refinement
Mar 20, 2023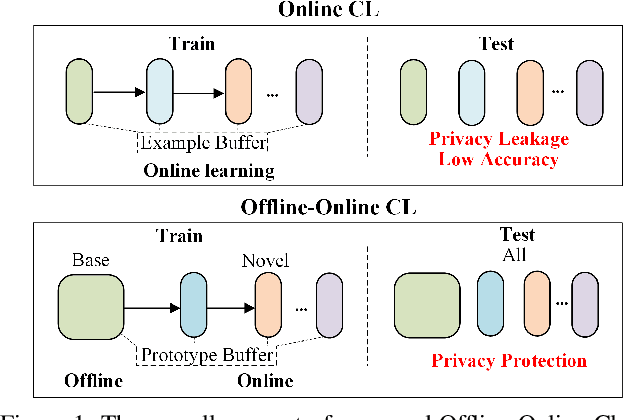
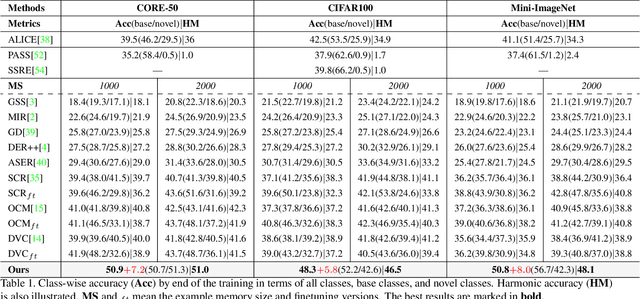
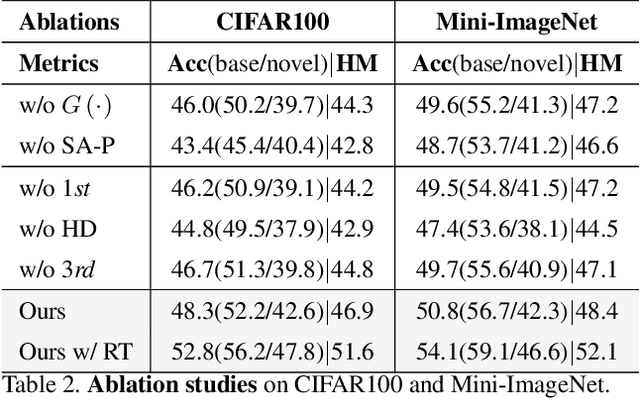
This paper investigates a new, practical, but challenging problem named Offline-Online Class-incremental Continual Learning (O$^2$CL), which aims to preserve the discernibility of pre-trained (i.e., offline) base classes without buffering data examples, and efficiently learn novel classes continuously in a single-pass (i.e., online) data stream. The challenges of this task are mainly two-fold: 1) Both base and novel classes suffer from severe catastrophic forgetting as no previous samples are available for replay. 2) As the online data can only be observed once, there is no way to fully re-train the whole model, e.g., re-calibrate the decision boundaries via prototype alignment or feature distillation. In this paper, we propose a novel Dual-prototype Self-augment and Refinement method (DSR) for O$^2$CL problem, which consists of two strategies: 1) Dual class prototypes: Inner and hyper-dimensional prototypes are exploited to utilize the pre-trained information and obtain robust quasi-orthogonal representations rather than example buffers for both privacy preservation and memory reduction. 2) Self-augment and refinement: Instead of updating the whole network, we jointly optimize the extra projection module with the self-augment inner prototypes from base and novel classes, gradually refining the hyper-dimensional prototypes to obtain accurate decision boundaries for learned classes. Extensive experiments demonstrate the effectiveness and superiority of the proposed DSR in O$^2$CL.
Tracker Meets Night: A Transformer Enhancer for UAV Tracking
Mar 20, 2023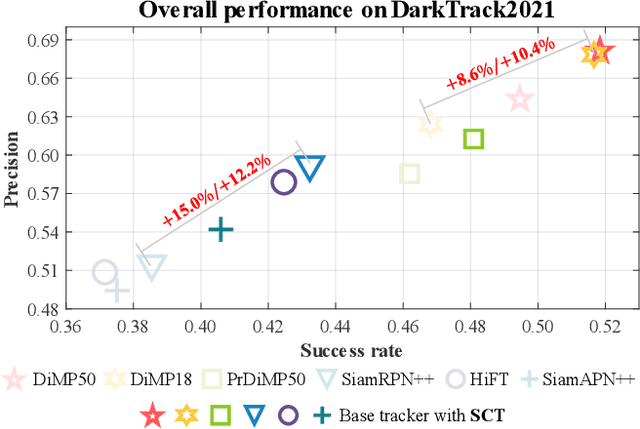
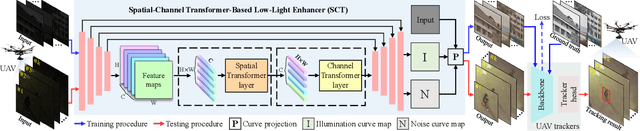
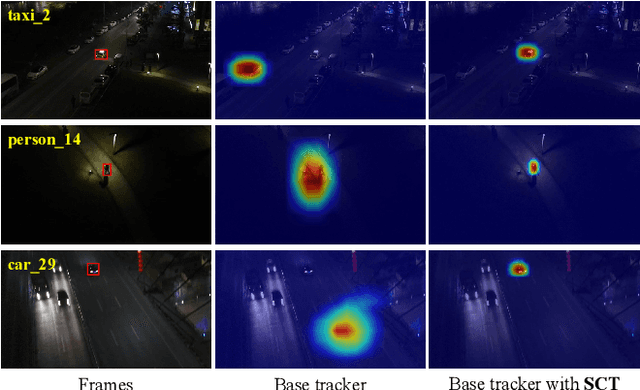
Most previous progress in object tracking is realized in daytime scenes with favorable illumination. State-of-the-arts can hardly carry on their superiority at night so far, thereby considerably blocking the broadening of visual tracking-related unmanned aerial vehicle (UAV) applications. To realize reliable UAV tracking at night, a spatial-channel Transformer-based low-light enhancer (namely SCT), which is trained in a novel task-inspired manner, is proposed and plugged prior to tracking approaches. To achieve semantic-level low-light enhancement targeting the high-level task, the novel spatial-channel attention module is proposed to model global information while preserving local context. In the enhancement process, SCT denoises and illuminates nighttime images simultaneously through a robust non-linear curve projection. Moreover, to provide a comprehensive evaluation, we construct a challenging nighttime tracking benchmark, namely DarkTrack2021, which contains 110 challenging sequences with over 100 K frames in total. Evaluations on both the public UAVDark135 benchmark and the newly constructed DarkTrack2021 benchmark show that the task-inspired design enables SCT with significant performance gains for nighttime UAV tracking compared with other top-ranked low-light enhancers. Real-world tests on a typical UAV platform further verify the practicability of the proposed approach. The DarkTrack2021 benchmark and the code of the proposed approach are publicly available at https://github.com/vision4robotics/SCT.
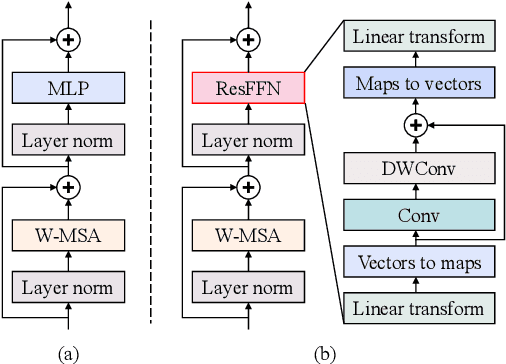
EmotionIC: Emotional Inertia and Contagion-driven Dependency Modelling for Emotion Recognition in Conversation
Mar 20, 2023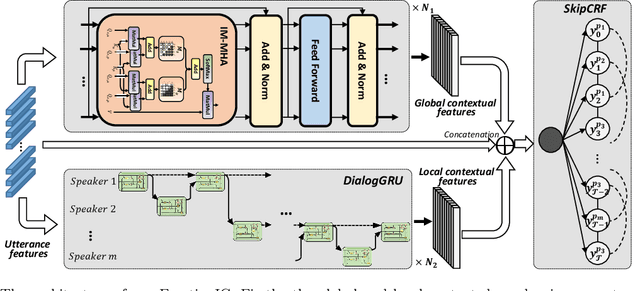
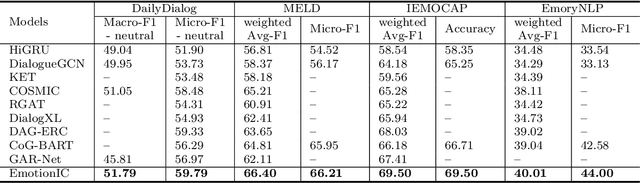
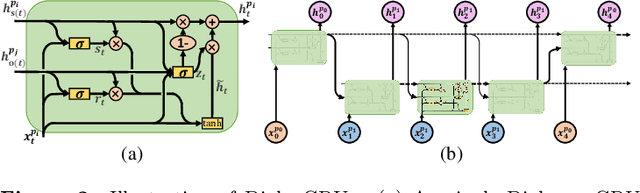

Emotion Recognition in Conversation (ERC) has attracted growing attention in recent years as a result of the advancement and implementation of human-computer interface technologies. However, previous approaches to modeling global and local context dependencies lost the diversity of dependency information and do not take the context dependency into account at the classification level. In this paper, we propose a novel approach to dependency modeling driven by Emotional Inertia and Contagion (EmotionIC) for conversational emotion recognition at the feature extraction and classification levels. At the feature extraction level, our designed Identity Masked Multi-head Attention (IM-MHA) captures the identity-based long-distant context in the dialogue to contain the diverse influence of different participants and construct the global emotional atmosphere, while the devised Dialogue-based Gate Recurrent Unit (DialogGRU) that aggregates the emotional tendencies of dyadic dialogue is applied to refine the contextual features with inter- and intra-speaker dependencies. At the classification level, by introducing skip connections in Conditional Random Field (CRF), we elaborate the Skip-chain CRF (SkipCRF) to capture the high-order dependencies within and between speakers, and to emulate the emotional flow of distant participants. Experimental results show that our method can significantly outperform the state-of-the-art models on four benchmark datasets. The ablation studies confirm that our modules can effectively model emotional inertia and contagion.
A Multi-Task Deep Learning Approach for Sensor-based Human Activity Recognition and Segmentation
Mar 20, 2023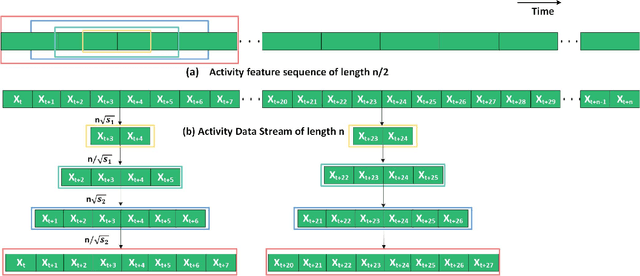
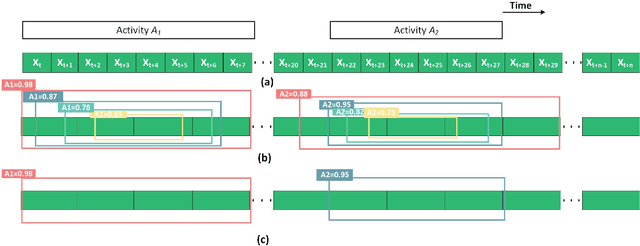
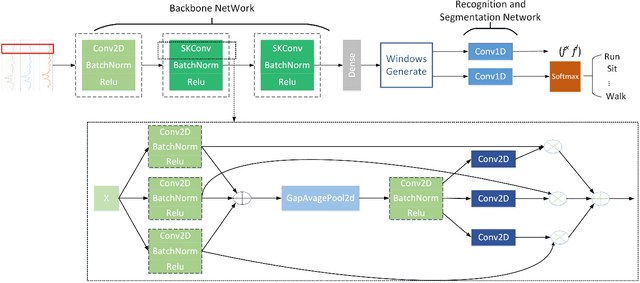
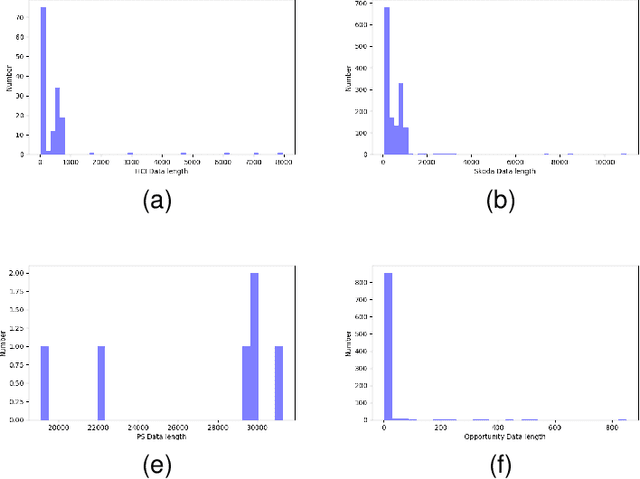
Sensor-based human activity segmentation and recognition are two important and challenging problems in many real-world applications and they have drawn increasing attention from the deep learning community in recent years. Most of the existing deep learning works were designed based on pre-segmented sensor streams and they have treated activity segmentation and recognition as two separate tasks. In practice, performing data stream segmentation is very challenging. We believe that both activity segmentation and recognition may convey unique information which can complement each other to improve the performance of the two tasks. In this paper, we firstly proposes a new multitask deep neural network to solve the two tasks simultaneously. The proposed neural network adopts selective convolution and features multiscale windows to segment activities of long or short time durations. First, multiple windows of different scales are generated to center on each unit of the feature sequence. Then, the model is trained to predict, for each window, the activity class and the offset to the true activity boundaries. Finally, overlapping windows are filtered out by non-maximum suppression, and adjacent windows of the same activity are concatenated to complete the segmentation task. Extensive experiments were conducted on eight popular benchmarking datasets, and the results show that our proposed method outperforms the state-of-the-art methods both for activity recognition and segmentation.
Improved Sample Complexity for Reward-free Reinforcement Learning under Low-rank MDPs
Mar 20, 2023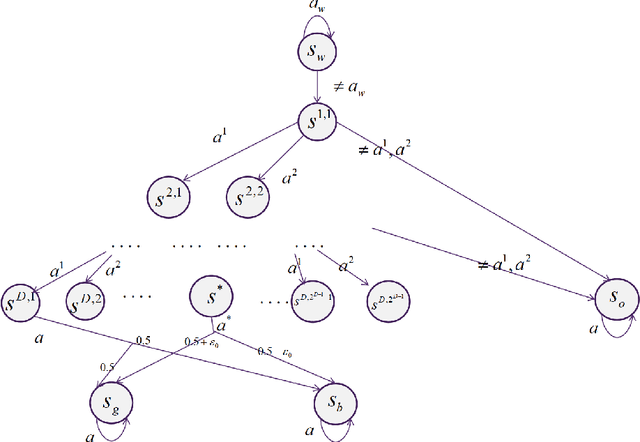
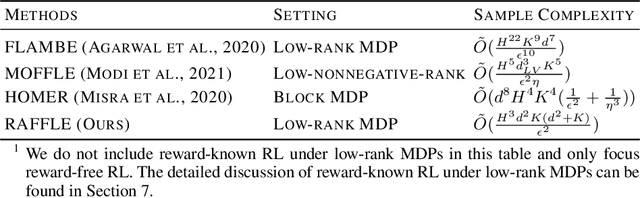
In reward-free reinforcement learning (RL), an agent explores the environment first without any reward information, in order to achieve certain learning goals afterwards for any given reward. In this paper we focus on reward-free RL under low-rank MDP models, in which both the representation and linear weight vectors are unknown. Although various algorithms have been proposed for reward-free low-rank MDPs, the corresponding sample complexity is still far from being satisfactory. In this work, we first provide the first known sample complexity lower bound that holds for any algorithm under low-rank MDPs. This lower bound implies it is strictly harder to find a near-optimal policy under low-rank MDPs than under linear MDPs. We then propose a novel model-based algorithm, coined RAFFLE, and show it can both find an $\epsilon$-optimal policy and achieve an $\epsilon$-accurate system identification via reward-free exploration, with a sample complexity significantly improving the previous results. Such a sample complexity matches our lower bound in the dependence on $\epsilon$, as well as on $K$ in the large $d$ regime, where $d$ and $K$ respectively denote the representation dimension and action space cardinality. Finally, we provide a planning algorithm (without further interaction with true environment) for RAFFLE to learn a near-accurate representation, which is the first known representation learning guarantee under the same setting.
Average Age of Information Penalty of Short-Packet Communications with Packet Management
Oct 26, 2022
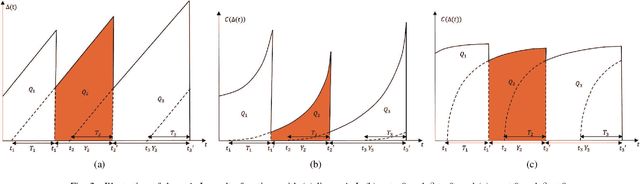
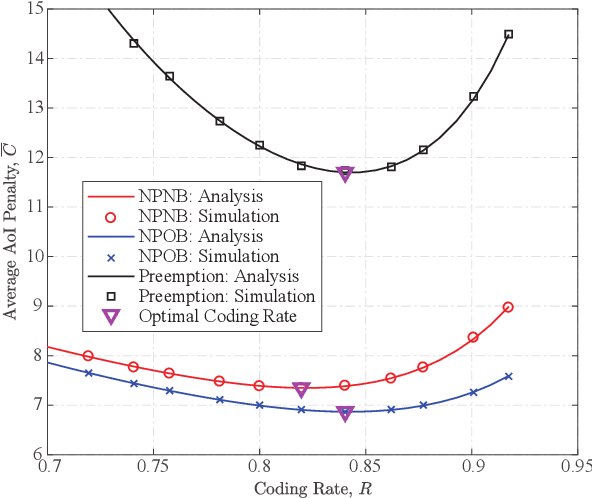
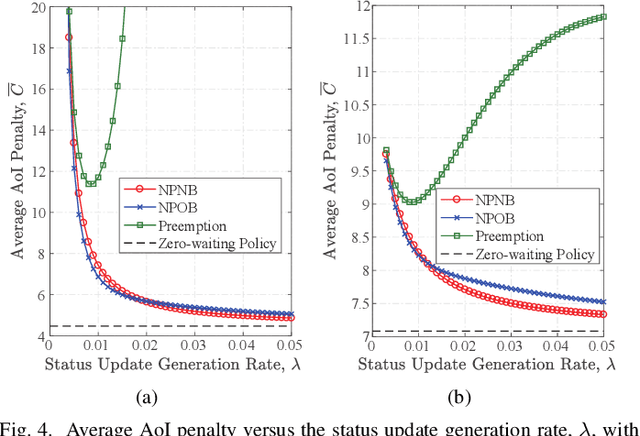
In this paper, we analyze the non-linear age of information (AoI) performance in a point-to-point short packet communication system, where a transmitter generates packets based on status updates and transmits the packets to a receiver. Specifically, we investigate three packet management strategies, namely, the non-preemption with no buffer strategy, the non-preemption with one buffer strategy, and the preemption strategy. To characterize the level of the receiver's dissatisfaction on outdated data, we adopt a generalized \alpha-\beta AoI penalty function into the analysis and derive closed-form expressions for the average AoI penalty achieved by the three packet management strategies. Simulation results are used to corroborate our analysis and explicitly evaluate the impact of various system parameters, such as the coding rate and status update generation rate, on the AoI performance. Additionally, we find that the value of \alpha reflects the system transmission reliability.