 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spherical Space Feature Decomposition for Guided Depth Map Super-Resolution
Mar 15, 2023
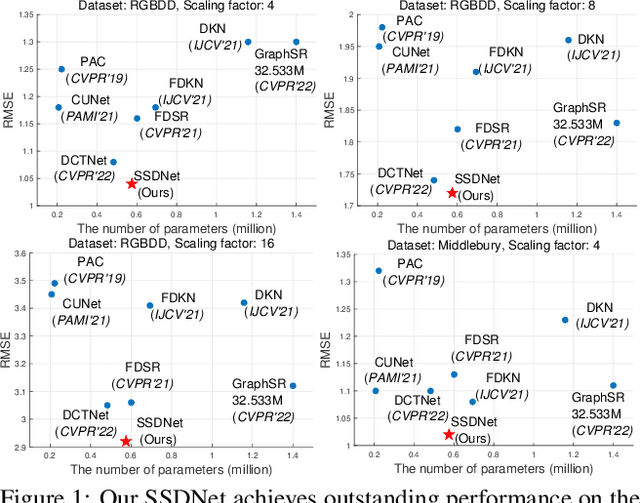
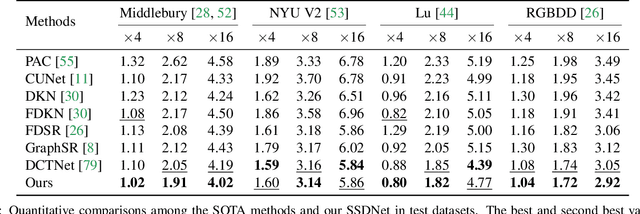
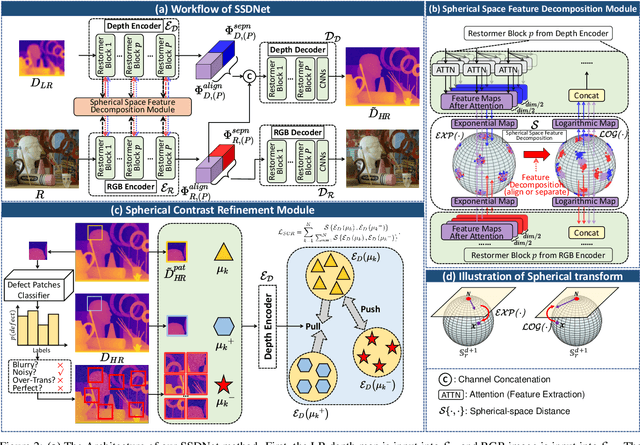

Guided depth map super-resolution (GDSR), as a hot topic in multi-modal image processing, aims to upsample low-resolution (LR) depth maps with additional information involved in high-resolution (HR) RGB images from the same scene. The critical step of this task is to effectively extract domain-shared and domain-private RGB/depth features. In addition, three detailed issues, namely blurry edges, noisy surfaces, and over-transferred RGB texture, need to be addressed. In this paper, we propose the Spherical Space feature Decomposition Network (SSDNet) to solve the above issues. To better model cross-modality features, Restormer block-based RGB/depth encoders are employed for extracting local-global features. Then, the extracted features are mapped to the spherical space to complete the separation of private features and the alignment of shared features. Shared features of RGB are fused with the depth features to complete the GDSR task. Subsequently, a spherical contrast refinement (SCR) module is proposed to further address the detail issues. Patches that are classified according to imperfect categories are input to the SCR module, where the patch features are pulled closer to the ground truth and pushed away from the corresponding imperfect samples in the spherical feature space via contrastive learning. Extensive experiments demonstrate that our method can achieve state-of-the-art results on four test datasets and can successfully generalize to real-world scenes. Code will be released.
A Triplet-loss Dilated Residual Network for High-Resolution Representation Learning in Image Retrieval
Mar 15, 2023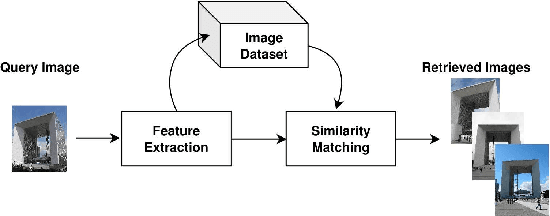
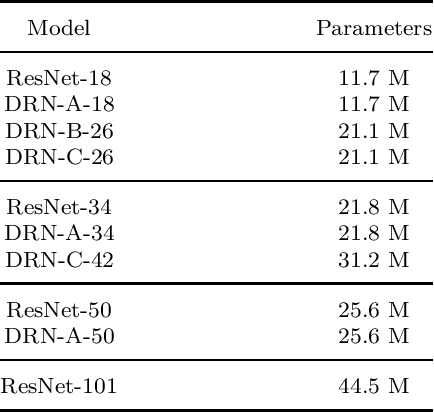
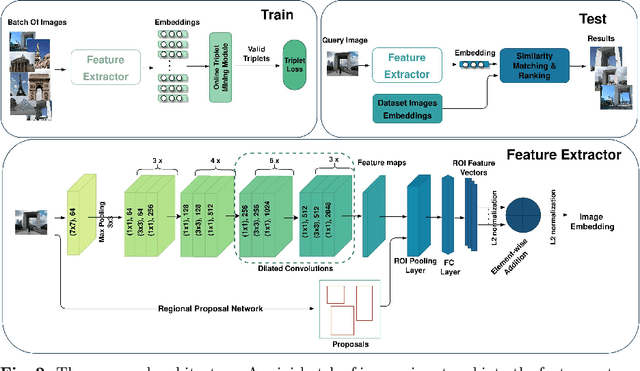

Content-based image retrieval is the process of retrieving a subset of images from an extensive image gallery based on visual contents, such as color, shape or spatial relations, and texture. In some applications, such as localization, image retrieval is employed as the initial step. In such cases, the accuracy of the top-retrieved images significantly affects the overall system accuracy. The current paper introduces a simple yet efficient image retrieval system with a fewer trainable parameters, which offers acceptable accuracy in top-retrieved images. The proposed method benefits from a dilated residual convolutional neural network with triplet loss. Experimental evaluations show that this model can extract richer information (i.e., high-resolution representations) by enlarging the receptive field, thus improving image retrieval accuracy without increasing the depth or complexity of the model. To enhance the extracted representations' robustness, the current research obtains candidate regions of interest from each feature map and applies Generalized-Mean pooling to the regions. As the choice of triplets in a triplet-based network affects the model training, we employ a triplet online mining method. We test the performance of the proposed method under various configurations on two of the challenging image-retrieval datasets, namely Revisited Paris6k (RPar) and UKBench. The experimental results show an accuracy of 94.54 and 80.23 (mean precision at rank 10) in the RPar medium and hard modes and 3.86 (recall at rank 4) in the UKBench dataset, respectively.
Lung Nodule Segmentation and Low-Confidence Region Prediction with Uncertainty-Aware Attention Mechanism
Mar 15, 2023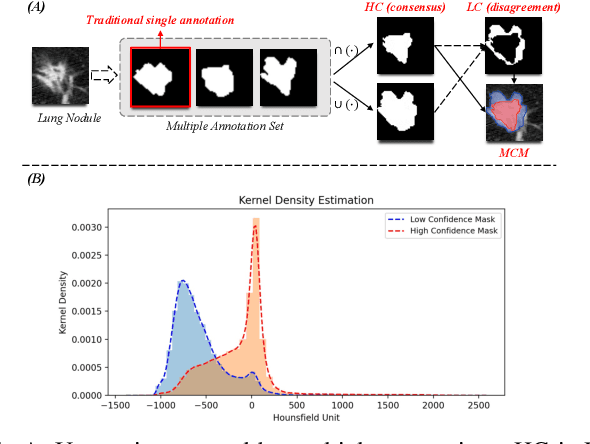

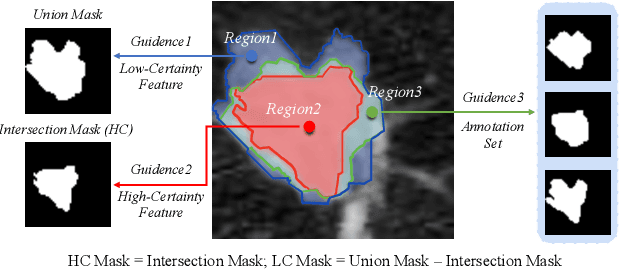
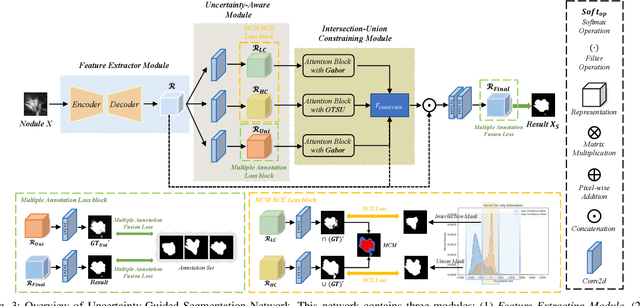
Radiologists have different training and clinical experiences, so they may provide various segmentation annotations for a lung nodule, which causes segmentation uncertainty among multiple annotations. Conventional methods usually chose a single annotation as the learning target or tried to learn a latent space of various annotations. Still, they wasted the valuable information of consensus or disagreements ingrained in the multiple annotations. This paper proposes an Uncertainty-Aware Attention Mechanism (UAAM), which utilizes consensus or disagreements among annotations to produce a better segmentation. In UAAM, we propose a Multi-Confidence Mask (MCM), which is a combination of a Low-Confidence (LC) Mask and a High-Confidence (HC) Mask. LC mask indicates regions with low segmentation confidence, which may cause different segmentation options among radiologists. Following UAAM, we further design an Uncertainty-Guide Segmentation Network (UGS-Net), which contains three modules:Feature Extracting Module captures a general feature of a lung nodule. Uncertainty-Aware Module produce three features for the annotations' union, intersection, and annotation set. Finally, Intersection-Union Constraining Module use distances between three features to balance the predictions of final segmentation, LC mask, and HC mask. To fully demonstrate the performance of our method, we propose a Complex Nodule Challenge on LIDC-IDRI, which tests UGS-Net's segmentation performance on the lung nodules that are difficult to segment by U-Net. Experimental results demonstrate that our method can significantly improve the segmentation performance on nodules with poor segmentation by U-Net.
SKGHOI: Spatial-Semantic Knowledge Graph for Human-Object Interaction Detection
Mar 15, 2023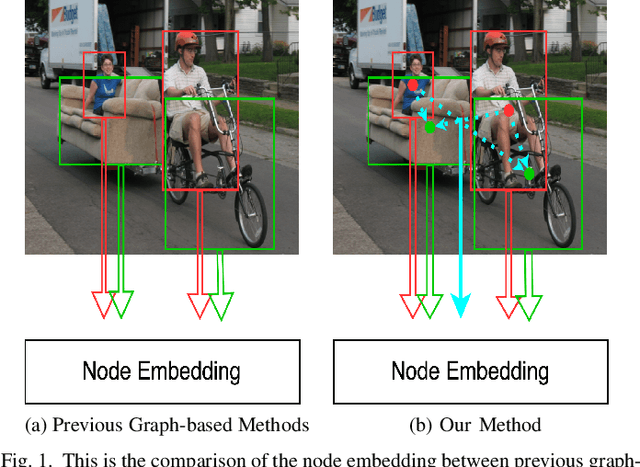
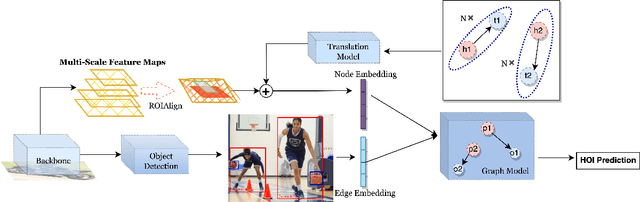
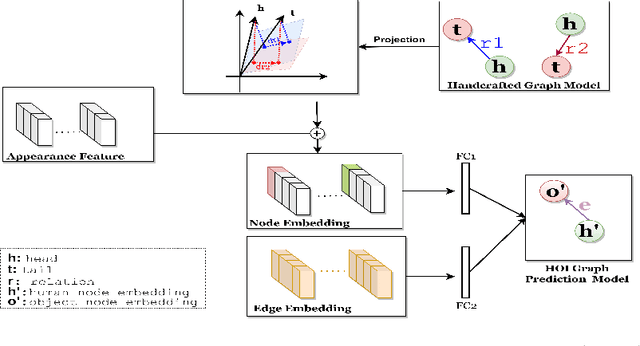
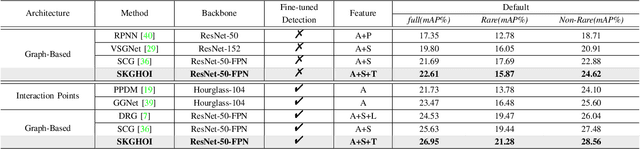
Detecting human-object interactions (HOIs) is a challenging problem in computer vision. Existing techniques for HOI detection heavily rely on appearance-based features, which may not capture other essential characteristics for accurate detection. Furthermore, the use of transformer-based models for sentiment representation of human-object pairs can be computationally expensive. To address these challenges, we propose a novel graph-based approach, SKGHOI (Spatial-Semantic Knowledge Graph for Human-Object Interaction Detection), that effectively captures the sentiment representation of HOIs by integrating both spatial and semantic knowledge. In a graph, SKGHOI takes the components of interaction as nodes, and the spatial relationships between them as edges. Our approach employs a spatial encoder and a semantic encoder to extract spatial and semantic information, respectively, and then combines these encodings to create a knowledge graph that captures the sentiment representation of HOIs. Compared to existing techniques, SKGHOI is computationally efficient and allows for the incorporation of prior knowledge, making it practical for use in real-world applications. We demonstrate the effectiveness of our proposed method on the widely-used HICO-DET datasets, where it outperforms existing state-of-the-art graph-based methods by a significant margin. Our results indicate that the SKGHOI approach has the potential to significantly improve the accuracy and efficiency of HOI detection, and we anticipate that it will be of great interest to researchers and practitioners working on this challenging task.
Efficient and Secure Federated Learning for Financial Applications
Mar 15, 2023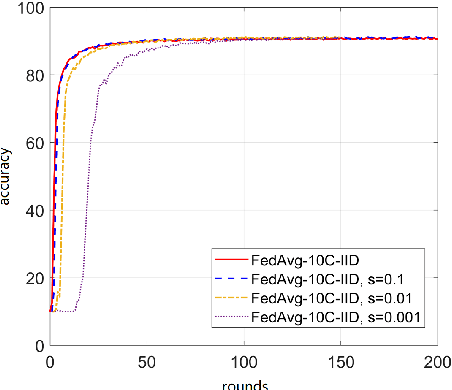

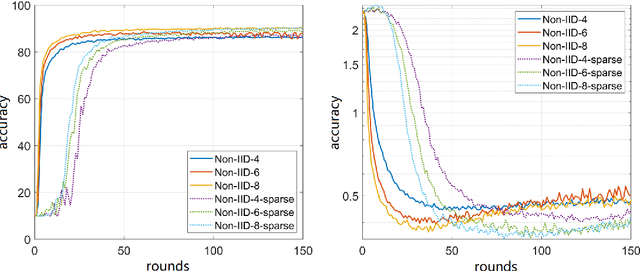
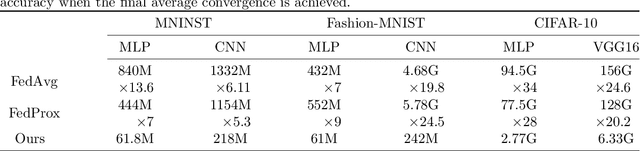
The conventional machine learning (ML) and deep learning approaches need to share customers' sensitive information with an external credit bureau to generate a prediction model that opens the door to privacy leakage. This leakage risk makes financial companies face an enormous challenge in their cooperation. Federated learning is a machine learning setting that can protect data privacy, but the high communication cost is often the bottleneck of the federated systems, especially for large neural networks. Limiting the number and size of communications is necessary for the practical training of large neural structures. Gradient sparsification has received increasing attention as a method to reduce communication cost, which only updates significant gradients and accumulates insignificant gradients locally. However, the secure aggregation framework cannot directly use gradient sparsification. This article proposes two sparsification methods to reduce communication cost in federated learning. One is a time-varying hierarchical sparsification method for model parameter update, which solves the problem of maintaining model accuracy after high ratio sparsity. It can significantly reduce the cost of a single communication. The other is to apply the sparsification method to the secure aggregation framework. We sparse the encryption mask matrix to reduce the cost of communication while protecting privacy. Experiments show that under different Non-IID experiment settings, our method can reduce the upload communication cost to about 2.9% to 18.9% of the conventional federated learning algorithm when the sparse rate is 0.01.
Sources of Richness and Ineffability for Phenomenally Conscious States
Feb 13, 2023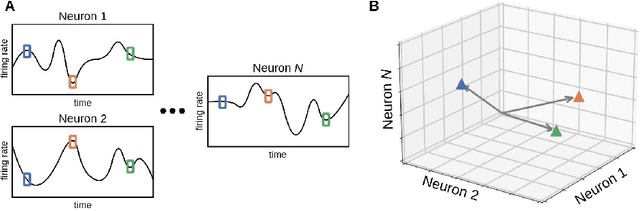
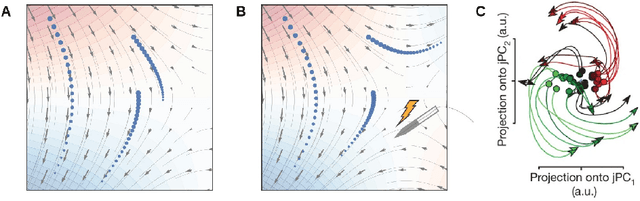
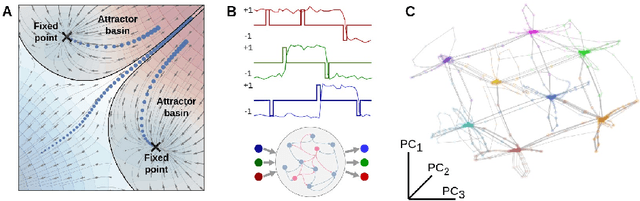
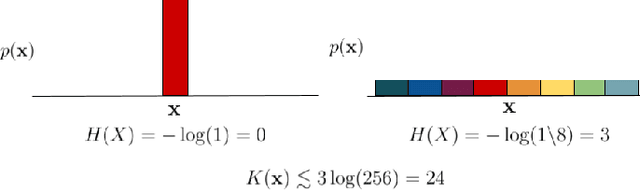
Conscious states (states that there is something it is like to be in) seem both rich or full of detail, and ineffable or hard to fully describe or recall. The problem of ineffability, in particular, is a longstanding issue in philosophy that partly motivates the explanatory gap: the belief that consciousness cannot be reduced to underlying physical processes. Here, we provide an information theoretic dynamical systems perspective on the richness and ineffability of consciousness. In our framework, the richness of conscious experience corresponds to the amount of information in a conscious state and ineffability corresponds to the amount of information lost at different stages of processing. We describe how attractor dynamics in working memory would induce impoverished recollections of our original experiences, how the discrete symbolic nature of language is insufficient for describing the rich and high-dimensional structure of experiences, and how similarity in the cognitive function of two individuals relates to improved communicability of their experiences to each other. While our model may not settle all questions relating to the explanatory gap, it makes progress toward a fully physicalist explanation of the richness and ineffability of conscious experience: two important aspects that seem to be part of what makes qualitative character so puzzling.
Vision-RADAR fusion for Robotics BEV Detections: A Survey
Feb 13, 2023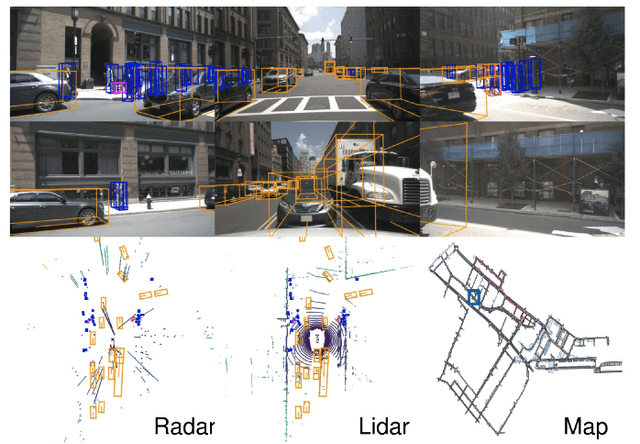
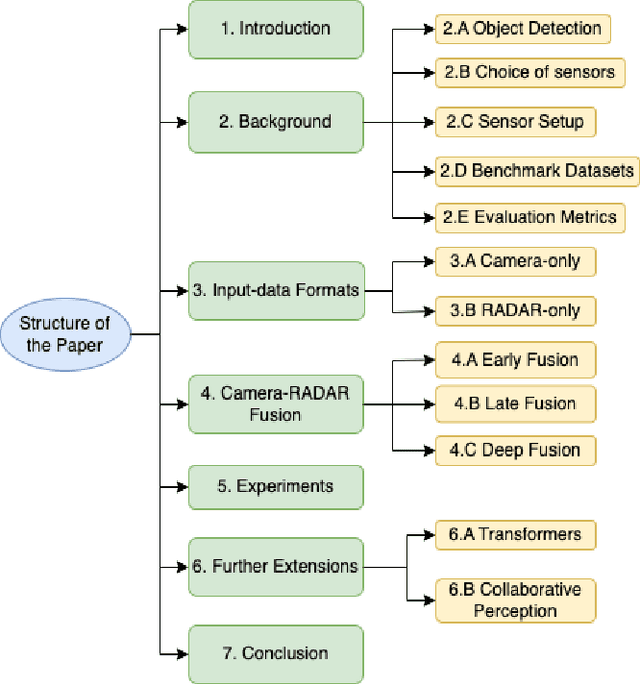
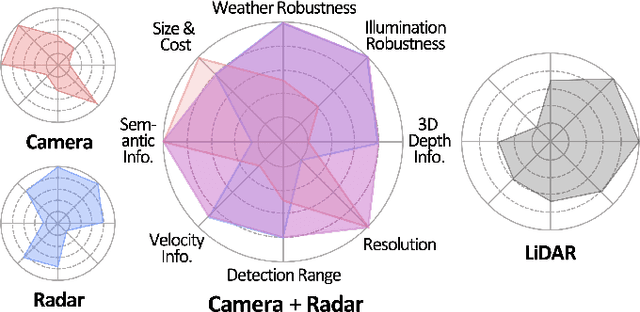

Due to the trending need of building autonomous robotic perception system, sensor fusion has attracted a lot of attention amongst researchers and engineers to make best use of cross-modality information. However, in order to build a robotic platform at scale we need to emphasize on autonomous robot platform bring-up cost as well. Cameras and radars, which inherently includes complementary perception information, has potential for developing autonomous robotic platform at scale. However, there is a limited work around radar fused with Vision, compared to LiDAR fused with vision work. In this paper, we tackle this gap with a survey on Vision-Radar fusion approaches for a BEV object detection system. First we go through the background information viz., object detection tasks, choice of sensors, sensor setup, benchmark datasets and evaluation metrics for a robotic perception system. Later, we cover per-modality (Camera and RADAR) data representation, then we go into detail about sensor fusion techniques based on sub-groups viz., early-fusion, deep-fusion, and late-fusion to easily understand the pros and cons of each method. Finally, we propose possible future trends for vision-radar fusion to enlighten future research. Regularly updated summary can be found at: https://github.com/ApoorvRoboticist/Vision-RADAR-Fusion-BEV-Survey
IMPORTANT-Net: Integrated MRI Multi-Parameter Reinforcement Fusion Generator with Attention Network for Synthesizing Absent Data
Feb 03, 2023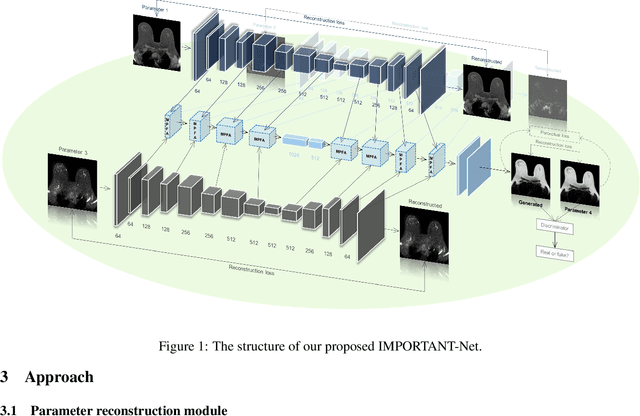
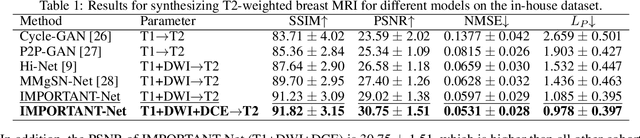
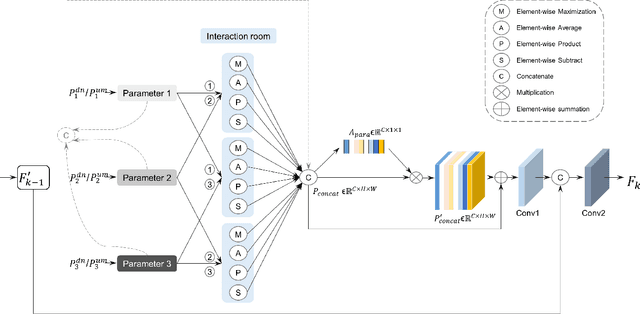
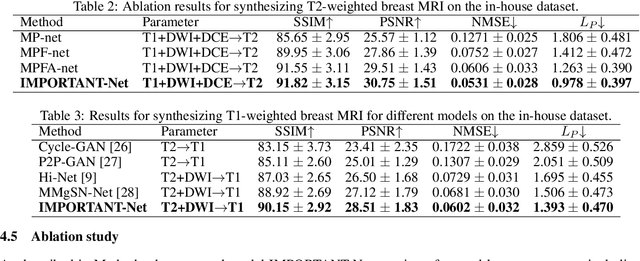
Magnetic resonance imaging (MRI) is highly sensitive for lesion detection in the breasts. Sequences obtained with different settings can capture the specific characteristics of lesions. Such multi-parameter MRI information has been shown to improve radiologist performance in lesion classification, as well as improving the performance of artificial intelligence models in various tasks. However, obtaining multi-parameter MRI makes the examination costly in both financial and time perspectives, and there may be safety concerns for special populations, thus making acquisition of the full spectrum of MRI sequences less durable. In this study, different than naive input fusion or feature concatenation from existing MRI parameters, a novel $\textbf{I}$ntegrated MRI $\textbf{M}$ulti-$\textbf{P}$arameter reinf$\textbf{O}$rcement fusion generato$\textbf{R}$ wi$\textbf{T}$h $\textbf{A}$tte$\textbf{NT}$ion Network (IMPORTANT-Net) is developed to generate missing parameters. First, the parameter reconstruction module is used to encode and restore the existing MRI parameters to obtain the corresponding latent representation information at any scale level. Then the multi-parameter fusion with attention module enables the interaction of the encoded information from different parameters through a set of algorithmic strategies, and applies different weights to the information through the attention mechanism after information fusion to obtain refined representation information. Finally, a reinforcement fusion scheme embedded in a $V^{-}$-shape generation module is used to combine the hierarchical representations to generate the missing MRI parameter. Results showed that our IMPORTANT-Net is capable of generating missing MRI parameters and outperforms comparable state-of-the-art networks. Our code is available at https://github.com/Netherlands-Cancer-Institute/MRI_IMPORTANT_NET.
Roadmap on Deep Learning for Microscopy
Mar 07, 2023
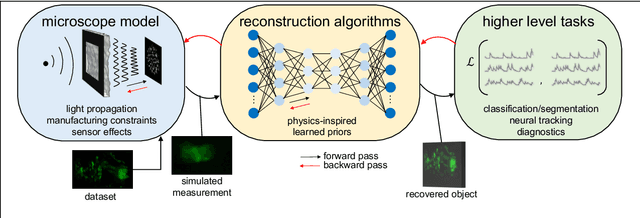

Through digital imaging, microscopy has evolved from primarily being a means for visual observation of life at the micro- and nano-scale, to a quantitative tool with ever-increasing resolution and throughput. Artificial intelligence, deep neural networks, and machine learning are all niche terms describing computational methods that have gained a pivotal role in microscopy-based research over the past decade. This Roadmap is written collectively by prominent researchers and encompasses selected aspects of how machine learning is applied to microscopy image data, with the aim of gaining scientific knowledge by improved image quality, automated detection, segmentation, classification and tracking of objects, and efficient merging of information from multiple imaging modalities. We aim to give the reader an overview of the key developments and an understanding of possibilities and limitations of machine learning for microscopy. It will be of interest to a wide cross-disciplinary audience in the physical sciences and life sciences.
Knowledge Restore and Transfer for Multi-label Class-Incremental Learning
Mar 07, 2023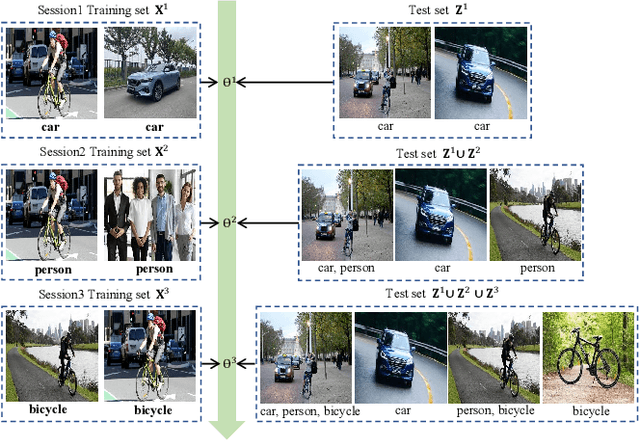
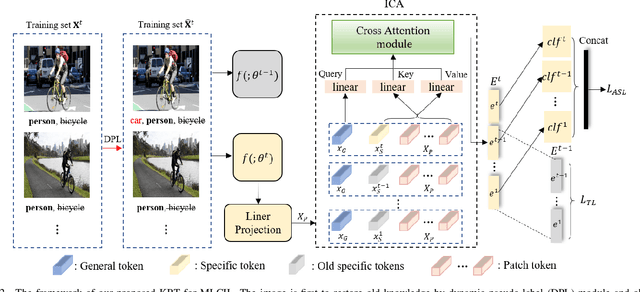
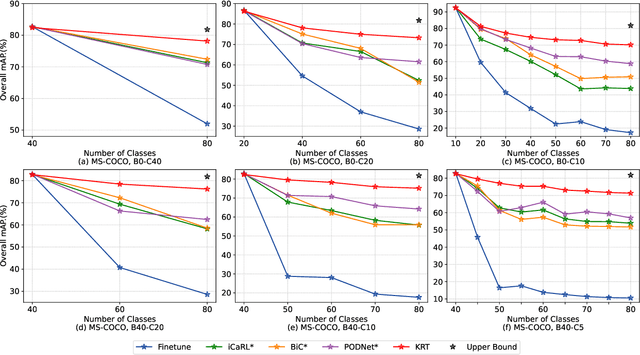
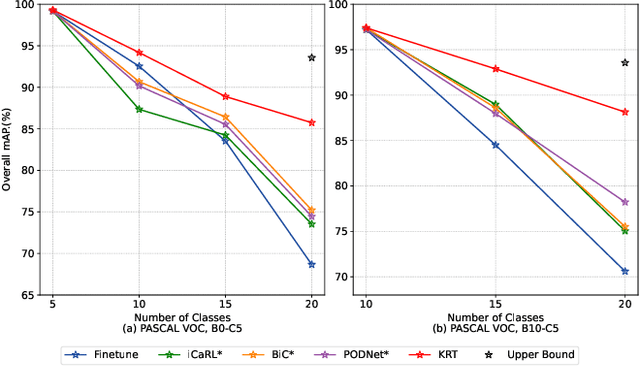
Current class-incremental learning research mainly focuses on single-label classification tasks while multi-label class-incremental learning (MLCIL) with more practical application scenarios is rarely studied. Although there have been many anti-forgetting methods to solve the problem of catastrophic forgetting in class-incremental learning, these methods have difficulty in solving the MLCIL problem due to label absence and information dilution. In this paper, we propose a knowledge restore and transfer (KRT) framework for MLCIL, which includes a dynamic pseudo-label (DPL) module to restore the old class knowledge and an incremental cross-attention(ICA) module to save session-specific knowledge and transfer old class knowledge to the new model sufficiently. Besides, we propose a token loss to jointly optimize the incremental cross-attention module. Experimental results on MS-COCO and PASCAL VOC datasets demonstrate the effectiveness of our method for improving recognition performance and mitigating forgetting on multi-label class-incremental learning tasks.