 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Vision-RADAR fusion for Robotics BEV Detections: A Survey
Feb 13, 2023
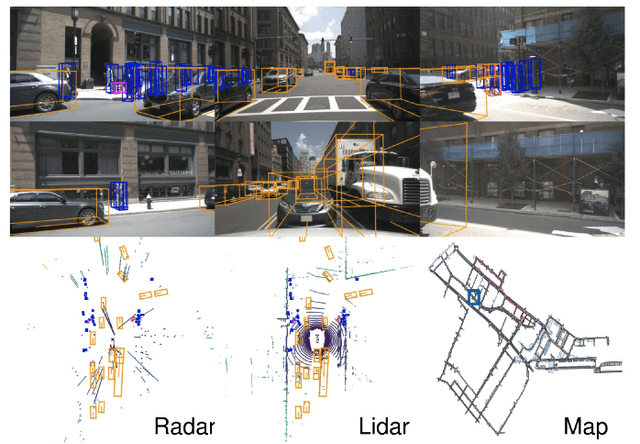
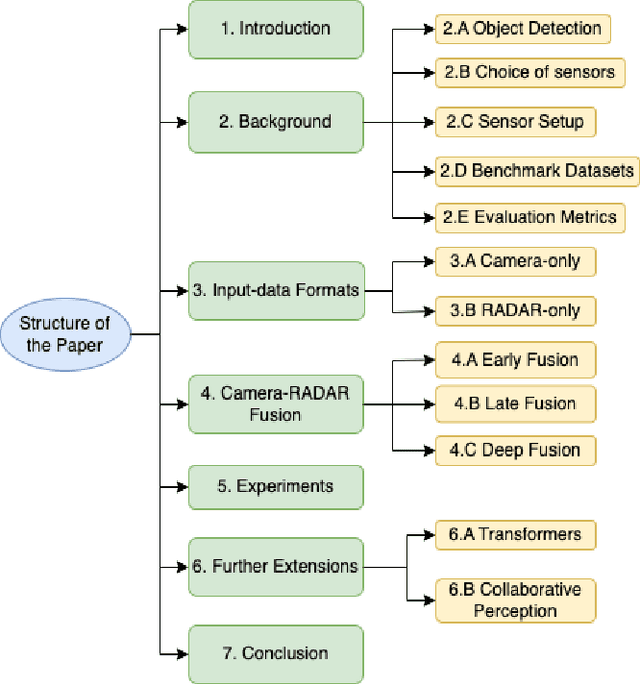
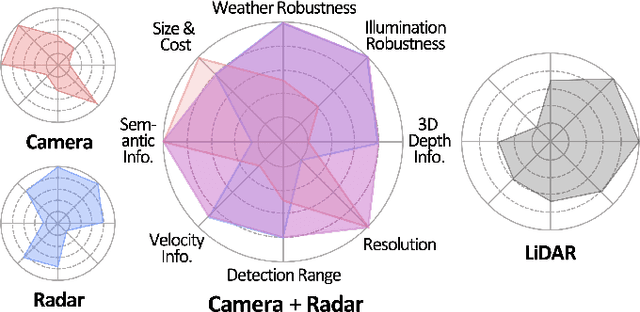

Due to the trending need of building autonomous robotic perception system, sensor fusion has attracted a lot of attention amongst researchers and engineers to make best use of cross-modality information. However, in order to build a robotic platform at scale we need to emphasize on autonomous robot platform bring-up cost as well. Cameras and radars, which inherently includes complementary perception information, has potential for developing autonomous robotic platform at scale. However, there is a limited work around radar fused with Vision, compared to LiDAR fused with vision work. In this paper, we tackle this gap with a survey on Vision-Radar fusion approaches for a BEV object detection system. First we go through the background information viz., object detection tasks, choice of sensors, sensor setup, benchmark datasets and evaluation metrics for a robotic perception system. Later, we cover per-modality (Camera and RADAR) data representation, then we go into detail about sensor fusion techniques based on sub-groups viz., early-fusion, deep-fusion, and late-fusion to easily understand the pros and cons of each method. Finally, we propose possible future trends for vision-radar fusion to enlighten future research. Regularly updated summary can be found at: https://github.com/ApoorvRoboticist/Vision-RADAR-Fusion-BEV-Survey
Multi label classification of Artificial Intelligence related patents using Modified D2SBERT and Sentence Attention mechanism
Mar 03, 2023
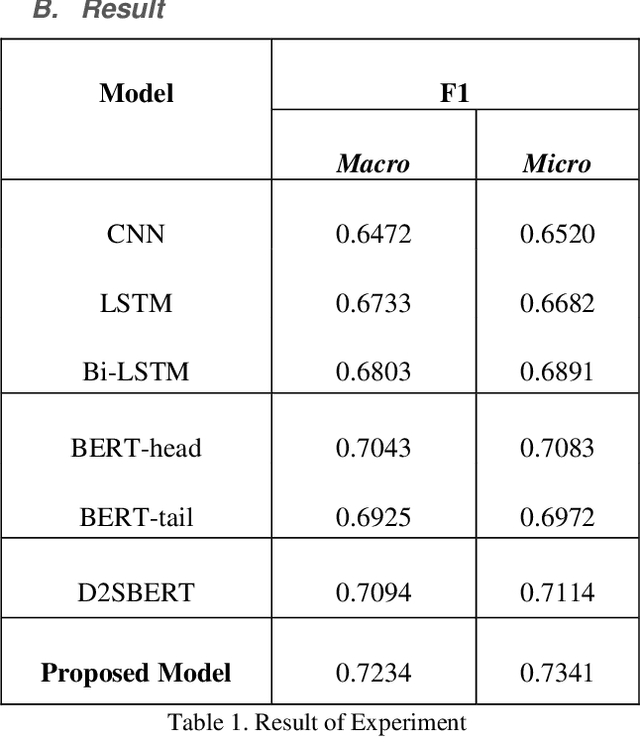
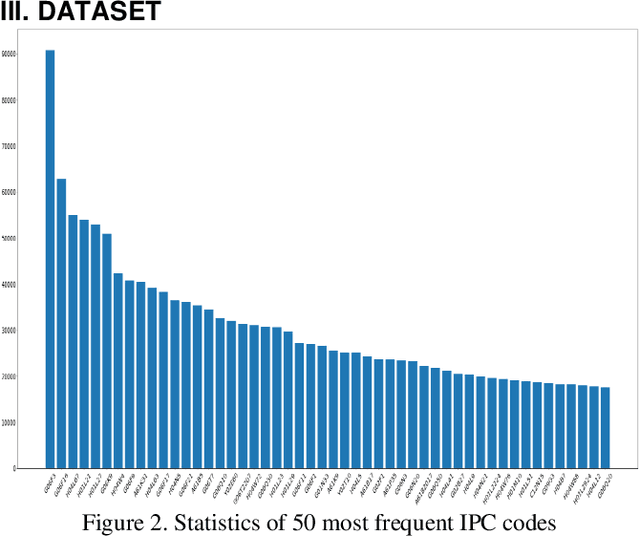
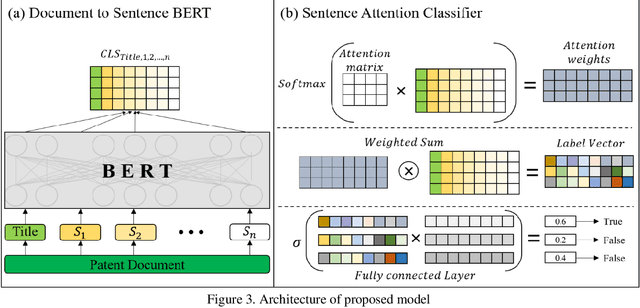
Patent classification is an essential task in patent information management and patent knowledge mining. It is very important to classify patents related to artificial intelligence, which is the biggest topic these days. However, artificial intelligence-related patents are very difficult to classify because it is a mixture of complex technologies and legal terms. Moreover, due to the unsatisfactory performance of current algorithms, it is still mostly done manually, wasting a lot of time and money. Therefore, we present a method for classifying artificial intelligence-related patents published by the USPTO using natural language processing technique and deep learning methodology. We use deformed BERT and sentence attention overcome the limitations of BERT. Our experiment result is highest performance compared to other deep learning methods.
A Few-shot Approach to Resume Information Extraction via Prompts
Sep 20, 2022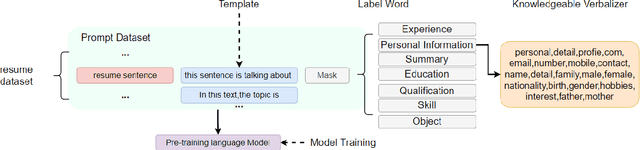

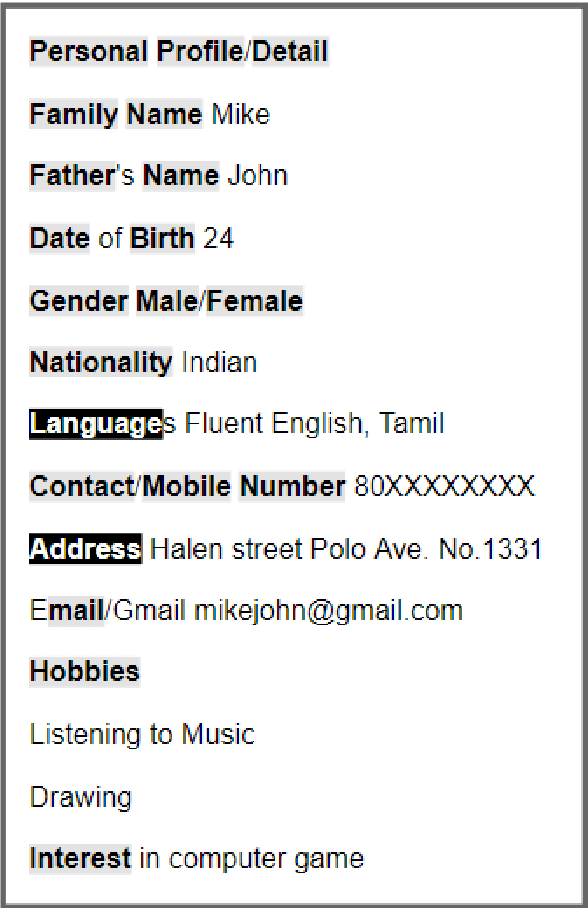

Prompt learning has been shown to achieve near-Fine-tune performance in most text classification tasks with very few training examples. It is advantageous for NLP tasks where samples are scarce. In this paper, we attempt to apply it to a practical scenario, i.e resume information extraction, and to enhance the existing method to make it more applicable to the resume information extraction task. In particular, we created multiple sets of manual templates and verbalizers based on the textual characteristics of resumes. In addition, we compared the performance of Masked Language Model (MLM) pre-training language models (PLMs) and Seq2Seq PLMs on this task. Furthermore, we improve the design method of verbalizer for Knowledgeable Prompt-tuning in order to provide a example for the design of Prompt templates and verbalizer for other application-based NLP tasks. In this case, we propose the concept of Manual Knowledgeable Verbalizer(MKV). A rule for constructing the Knowledgeable Verbalizer corresponding to the application scenario. Experiments demonstrate that templates and verbalizers designed based on our rules are more effective and robust than existing manual templates and automatically generated prompt methods. It is established that the currently available automatic prompt methods cannot compete with manually designed prompt templates for some realistic task scenarios. The results of the final confusion matrix indicate that our proposed MKV significantly resolved the sample imbalance issue.
IMPORTANT-Net: Integrated MRI Multi-Parameter Reinforcement Fusion Generator with Attention Network for Synthesizing Absent Data
Feb 03, 2023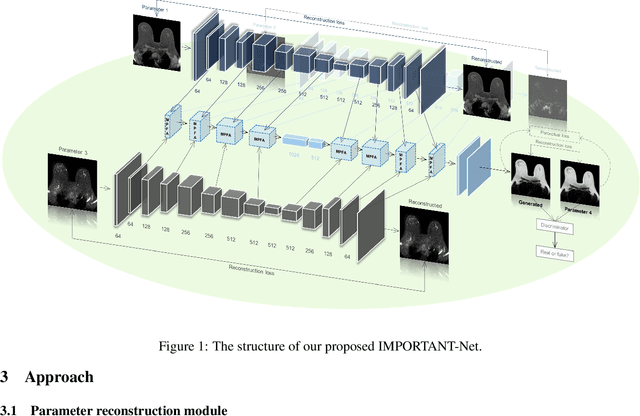
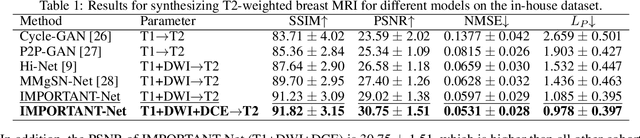
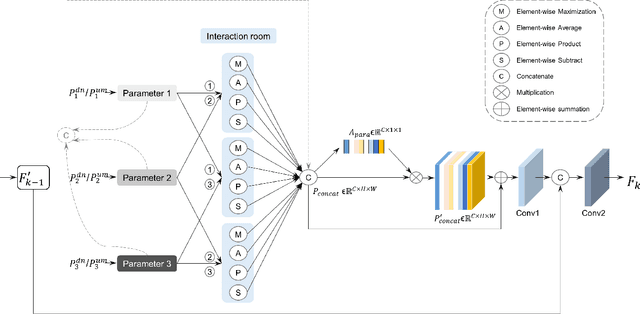
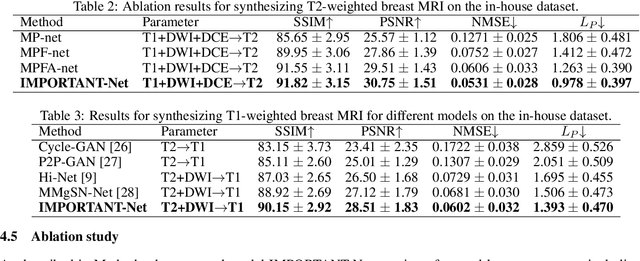
Magnetic resonance imaging (MRI) is highly sensitive for lesion detection in the breasts. Sequences obtained with different settings can capture the specific characteristics of lesions. Such multi-parameter MRI information has been shown to improve radiologist performance in lesion classification, as well as improving the performance of artificial intelligence models in various tasks. However, obtaining multi-parameter MRI makes the examination costly in both financial and time perspectives, and there may be safety concerns for special populations, thus making acquisition of the full spectrum of MRI sequences less durable. In this study, different than naive input fusion or feature concatenation from existing MRI parameters, a novel $\textbf{I}$ntegrated MRI $\textbf{M}$ulti-$\textbf{P}$arameter reinf$\textbf{O}$rcement fusion generato$\textbf{R}$ wi$\textbf{T}$h $\textbf{A}$tte$\textbf{NT}$ion Network (IMPORTANT-Net) is developed to generate missing parameters. First, the parameter reconstruction module is used to encode and restore the existing MRI parameters to obtain the corresponding latent representation information at any scale level. Then the multi-parameter fusion with attention module enables the interaction of the encoded information from different parameters through a set of algorithmic strategies, and applies different weights to the information through the attention mechanism after information fusion to obtain refined representation information. Finally, a reinforcement fusion scheme embedded in a $V^{-}$-shape generation module is used to combine the hierarchical representations to generate the missing MRI parameter. Results showed that our IMPORTANT-Net is capable of generating missing MRI parameters and outperforms comparable state-of-the-art networks. Our code is available at https://github.com/Netherlands-Cancer-Institute/MRI_IMPORTANT_NET.
Privacy-Preserving Data Synthetisation for Secure Information Sharing
Dec 01, 2022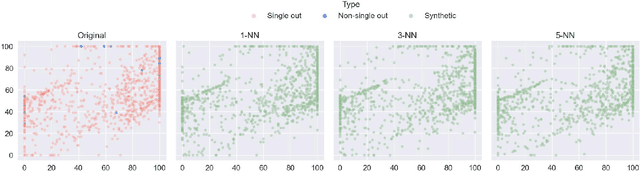
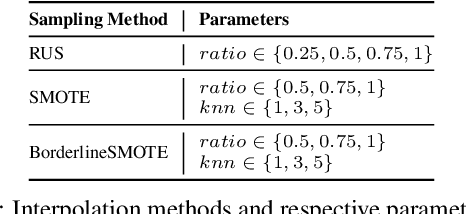
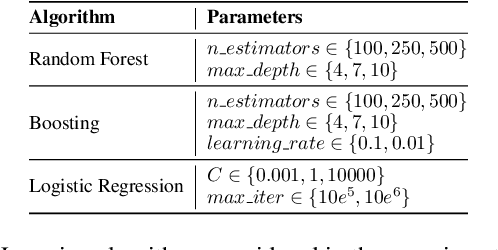
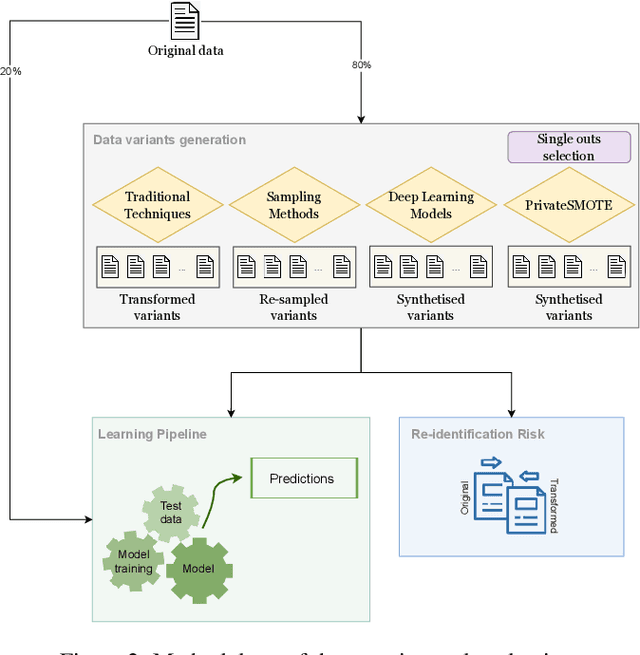
We can protect user data privacy via many approaches, such as statistical transformation or generative models. However, each of them has critical drawbacks. On the one hand, creating a transformed data set using conventional techniques is highly time-consuming. On the other hand, in addition to long training phases, recent deep learning-based solutions require significant computational resources. In this paper, we propose PrivateSMOTE, a technique designed for competitive effectiveness in protecting cases at maximum risk of re-identification while requiring much less time and computational resources. It works by synthetic data generation via interpolation to obfuscate high-risk cases while minimizing data utility loss of the original data. Compared to multiple conventional and state-of-the-art privacy-preservation methods on 20 data sets, PrivateSMOTE demonstrates competitive results in re-identification risk. Also, it presents similar or higher predictive performance than the baselines, including generative adversarial networks and variational autoencoders, reducing their energy consumption and time requirements by a minimum factor of 9 and 12, respectively.
Understanding the Challenges and Opportunities of Pose-based Anomaly Detection
Mar 09, 2023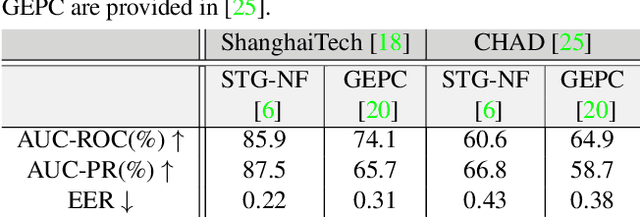
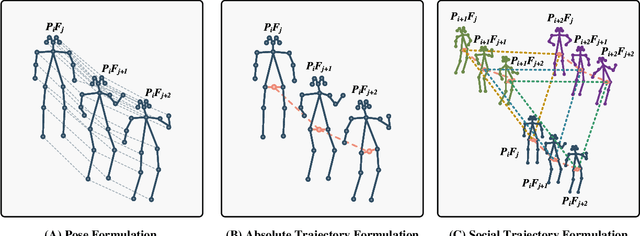
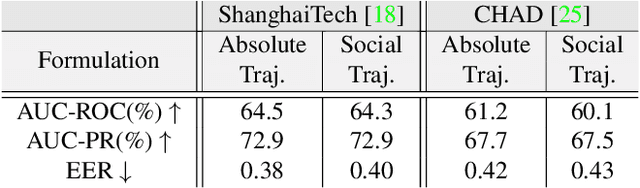
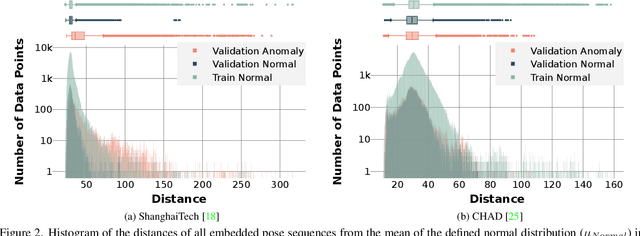
Pose-based anomaly detection is a video-analysis technique for detecting anomalous events or behaviors by examining human pose extracted from the video frames. Utilizing pose data alleviates privacy and ethical issues. Also, computation-wise, the complexity of pose-based models is lower than pixel-based approaches. However, it introduces more challenges, such as noisy skeleton data, losing important pixel information, and not having enriched enough features. These problems are exacerbated by a lack of anomaly detection datasets that are good enough representatives of real-world scenarios. In this work, we analyze and quantify the characteristics of two well-known video anomaly datasets to better understand the difficulties of pose-based anomaly detection. We take a step forward, exploring the discriminating power of pose and trajectory for video anomaly detection and their effectiveness based on context. We believe these experiments are beneficial for a better comprehension of pose-based anomaly detection and the datasets currently available. This will aid researchers in tackling the task of anomaly detection with a more lucid perspective, accelerating the development of robust models with better performance.
KGNv2: Separating Scale and Pose Prediction for Keypoint-based 6-DoF Grasp Pose Synthesis on RGB-D input
Mar 09, 2023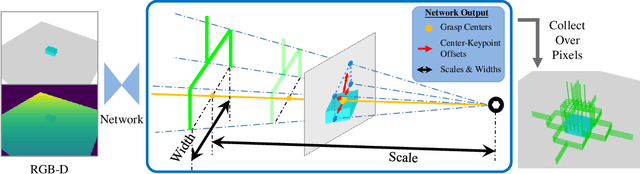
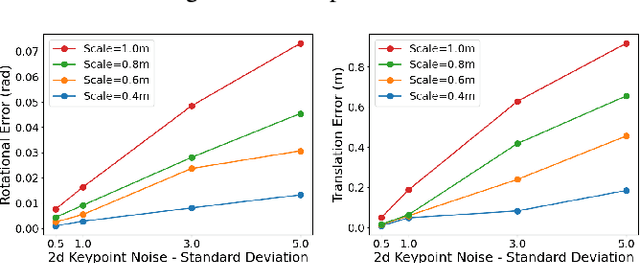
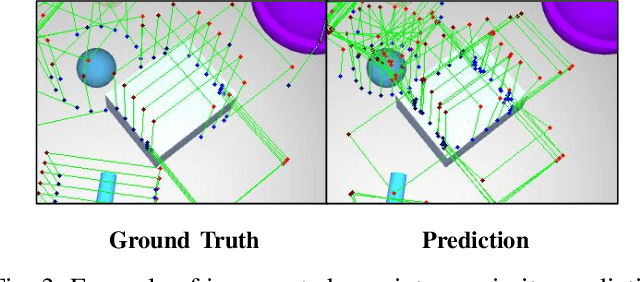

We propose a new 6-DoF grasp pose synthesis approach from 2D/2.5D input based on keypoints. Keypoint-based grasp detector from image input has demonstrated promising results in the previous study, where the additional visual information provided by color images compensates for the noisy depth perception. However, it relies heavily on accurately predicting the location of keypoints in the image space. In this paper, we devise a new grasp generation network that reduces the dependency on precise keypoint estimation. Given an RGB-D input, our network estimates both the grasp pose from keypoint detection as well as scale towards the camera. We further re-design the keypoint output space in order to mitigate the negative impact of keypoint prediction noise to Perspective-n-Point (PnP) algorithm. Experiments show that the proposed method outperforms the baseline by a large margin, validating the efficacy of our approach. Finally, despite trained on simple synthetic objects, our method demonstrate sim-to-real capacity by showing competitive results in real-world robot experiments.
Smooth and Stepwise Self-Distillation for Object Detection
Mar 09, 2023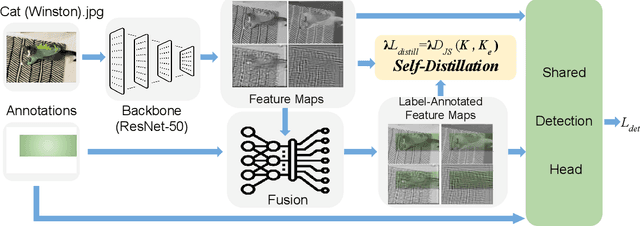
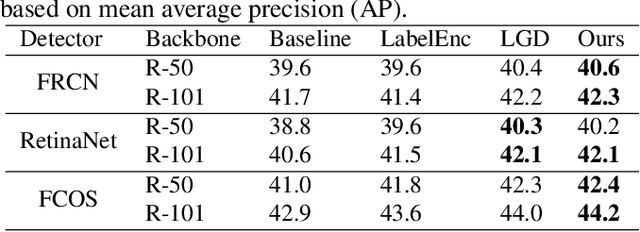
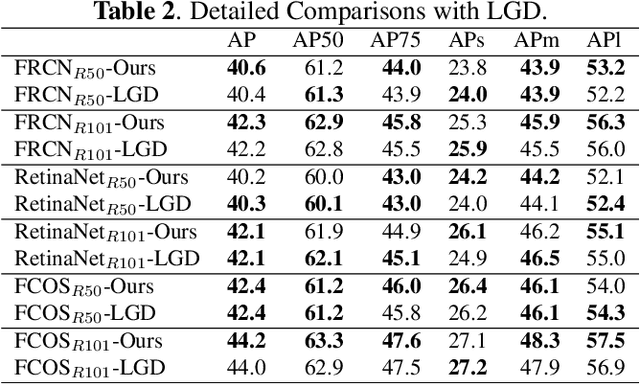
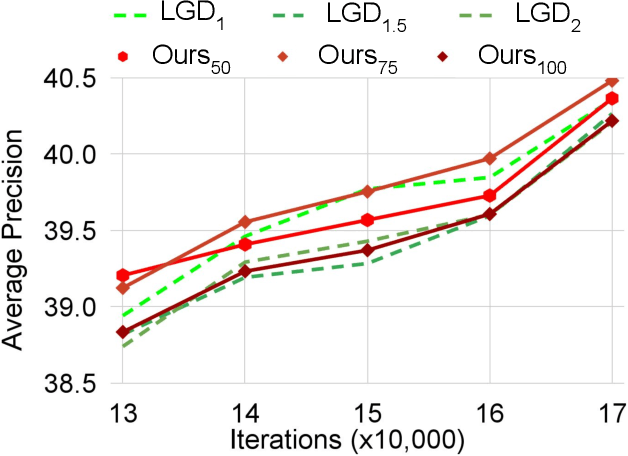
Distilling the structured information captured in feature maps has contributed to improved results for object detection tasks, but requires careful selection of baseline architectures and substantial pre-training. Self-distillation addresses these limitations and has recently achieved state-of-the-art performance for object detection despite making several simplifying architectural assumptions. Building on this work, we propose Smooth and Stepwise Self-Distillation (SSSD) for object detection. Our SSSD architecture forms an implicit teacher from object labels and a feature pyramid network backbone to distill label-annotated feature maps using Jensen-Shannon distance, which is smoother than distillation losses used in prior work. We additionally add a distillation coefficient that is adaptively configured based on the learning rate. We extensively benchmark SSSD against a baseline and two state-of-the-art object detector architectures on the COCO dataset by varying the coefficients and backbone and detector networks. We demonstrate that SSSD achieves higher average precision in most experimental settings, is robust to a wide range of coefficients, and benefits from our stepwise distillation procedure.
Multi-level Memory-augmented Appearance-Motion Correspondence Framework for Video Anomaly Detection
Mar 09, 2023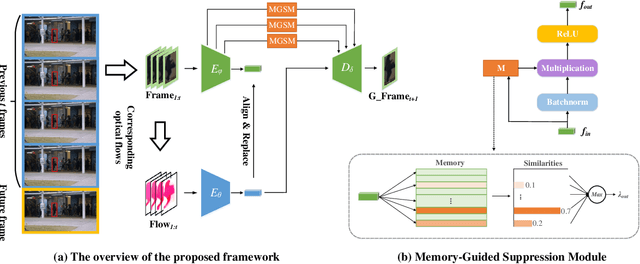
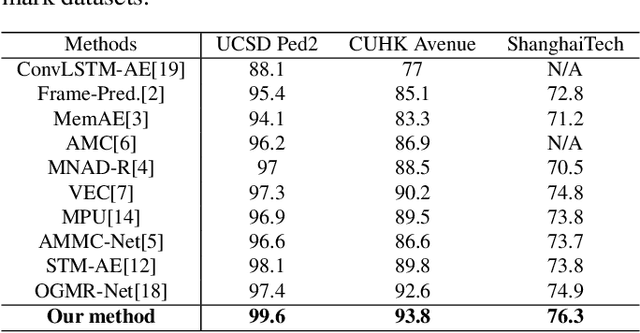
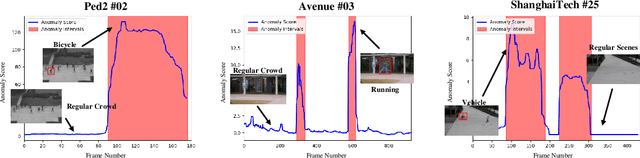

Frame prediction based on AutoEncoder plays a significant role in unsupervised video anomaly detection. Ideally, the models trained on the normal data could generate larger prediction errors of anomalies. However, the correlation between appearance and motion information is underutilized, which makes the models lack an understanding of normal patterns. Moreover, the models do not work well due to the uncontrollable generalizability of deep AutoEncoder. To tackle these problems, we propose a multi-level memory-augmented appearance-motion correspondence framework. The latent correspondence between appearance and motion is explored via appearance-motion semantics alignment and semantics replacement training. Besides, we also introduce a Memory-Guided Suppression Module, which utilizes the difference from normal prototype features to suppress the reconstruction capacity caused by skip-connection, achieving the tradeoff between the good reconstruction of normal data and the poor reconstruction of abnormal data. Experimental results show that our framework outperforms the state-of-the-art methods, achieving AUCs of 99.6\%, 93.8\%, and 76.3\% on UCSD Ped2, CUHK Avenue, and ShanghaiTech datasets.
Let's Get Personal: Personal Questions Improve SocialBot Performance in the Alexa Prize
Mar 09, 2023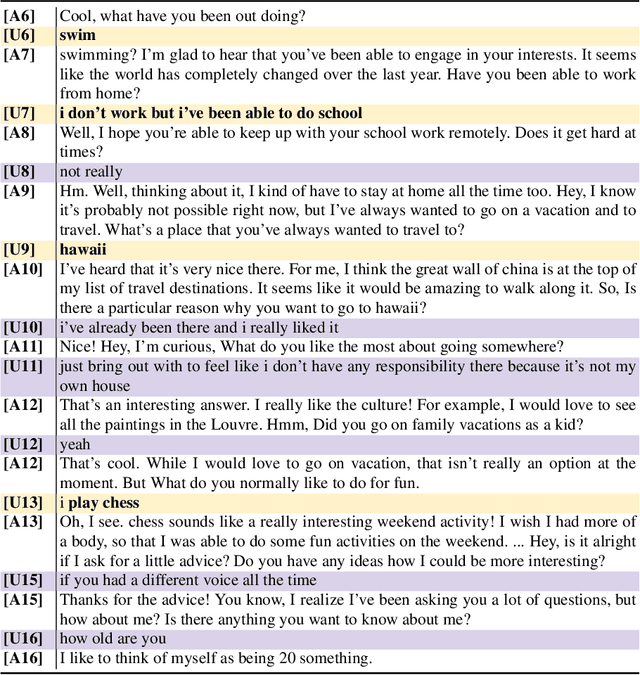
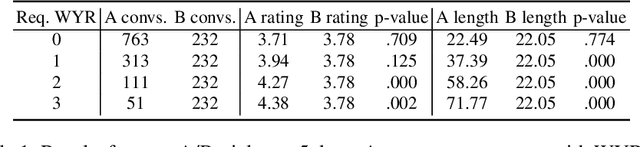
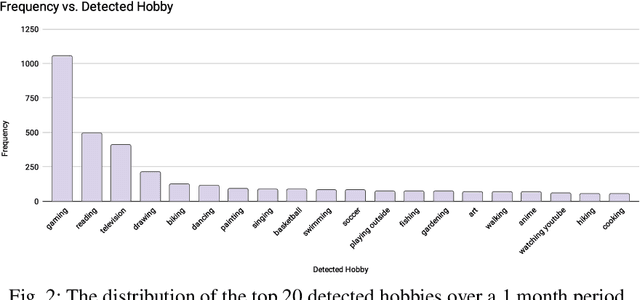

There has been an increased focus on creating conversational open-domain dialogue systems in the spoken dialogue community. Unlike traditional dialogue systems, these conversational systems cannot assume any specific information need or domain restrictions, i.e., the only inherent goal is to converse with the user on an unknown set of topics. While massive improvements in Natural Language Understanding (NLU) and the growth of available knowledge resources can partially support a robust conversation, these conversations generally lack the rapport between two humans that know each other. We developed a robust open-domain conversational system, Athena, that real Amazon Echo users access and evaluate at scale in the context of the Alexa Prize competition. We experiment with methods intended to increase intimacy between Athena and the user by heuristically developing a rule-based user model that personalizes both the current and subsequent conversations and evaluating specific personal opinion question strategies in A/B studies. Our results show a statistically significant positive impact on perceived conversation quality and length when employing these strategies.