 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Direct Motif Extraction from High Resolution Crystalline STEM Images
Mar 13, 2023
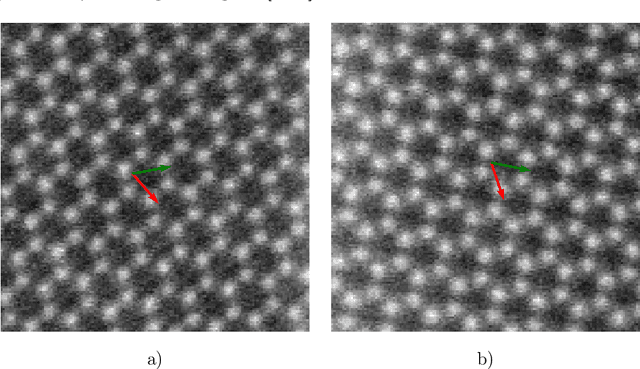
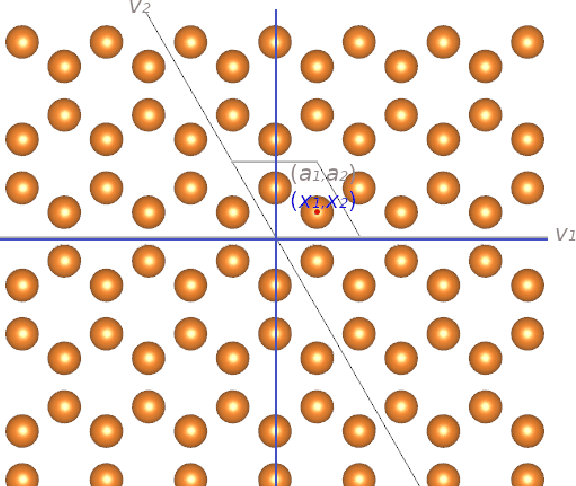

During the last decade, automatic data analysis methods concerning different aspects of crystal analysis have been developed, e.g., unsupervised primitive unit cell extraction and automated crystal distortion and defects detection. However, an automatic, unsupervised motif extraction method is still not widely available yet. Here, we propose and demonstrate a novel method for the automatic motif extraction in real space from crystalline images based on a variational approach involving the unit cell projection operator. Due to the non-convex nature of the resulting minimization problem, a multi-stage algorithm is used. First, we determine the primitive unit cell in form of two lattice vectors. Second, a motif image is estimated using the unit cell information. Finally, the motif is determined in terms of atom positions inside the unit cell. The method was tested on various synthetic and experimental HAADF STEM images. The results are a representation of the motif in form of an image, atomic positions, primitive unit cell vectors, and a denoised and a modeled reconstruction of the input image. The method was applied to extract the primitive cells of complex $\mu$-phase structures Nb$_\text{6.4}$Co$_\text{6.6}$ and Nb$_\text{7}$Co$_\text{6}$, where subtle differences between their interplanar spacings were determined.
Prototype-based Embedding Network for Scene Graph Generation
Mar 13, 2023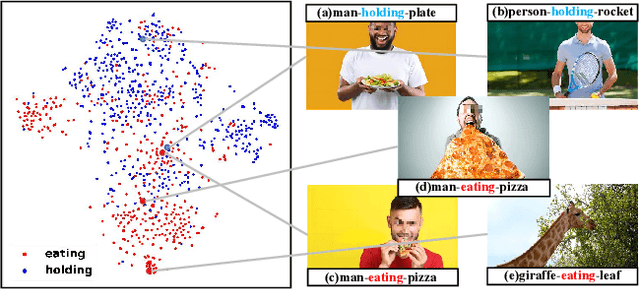
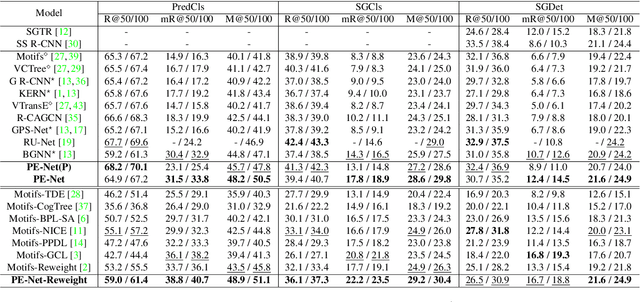
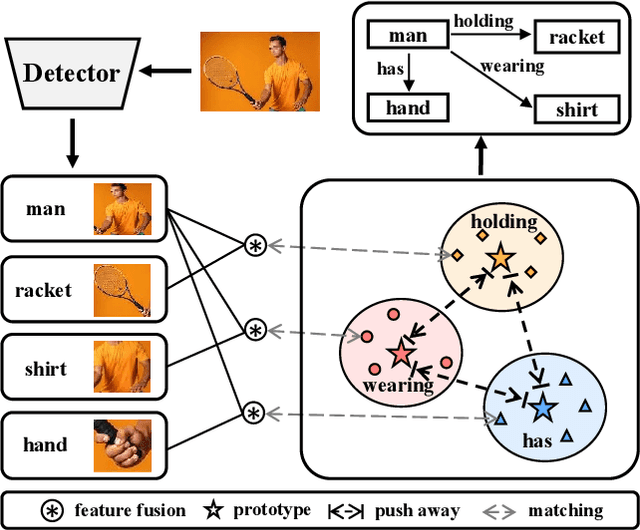
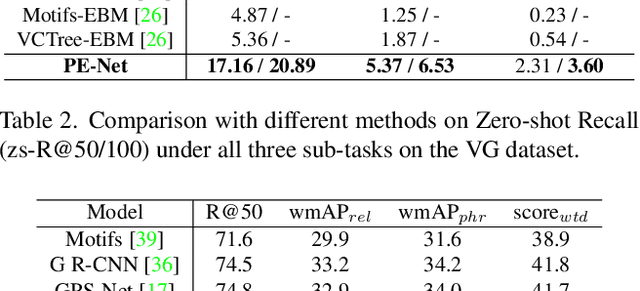
Current Scene Graph Generation (SGG) methods explore contextual information to predict relationships among entity pairs. However, due to the diverse visual appearance of numerous possible subject-object combinations, there is a large intra-class variation within each predicate category, e.g., "man-eating-pizza, giraffe-eating-leaf", and the severe inter-class similarity between different classes, e.g., "man-holding-plate, man-eating-pizza", in model's latent space. The above challenges prevent current SGG methods from acquiring robust features for reliable relation prediction. In this paper, we claim that the predicate's category-inherent semantics can serve as class-wise prototypes in the semantic space for relieving the challenges. To the end, we propose the Prototype-based Embedding Network (PE-Net), which models entities/predicates with prototype-aligned compact and distinctive representations and thereby establishes matching between entity pairs and predicates in a common embedding space for relation recognition. Moreover, Prototype-guided Learning (PL) is introduced to help PE-Net efficiently learn such entitypredicate matching, and Prototype Regularization (PR) is devised to relieve the ambiguous entity-predicate matching caused by the predicate's semantic overlap. Extensive experiments demonstrate that our method gains superior relation recognition capability on SGG, achieving new state-of-the-art performances on both Visual Genome and Open Images datasets.
Effect of Variable Physical Numerologies on Link-Level Performance of 5G NR V2X
Mar 17, 2023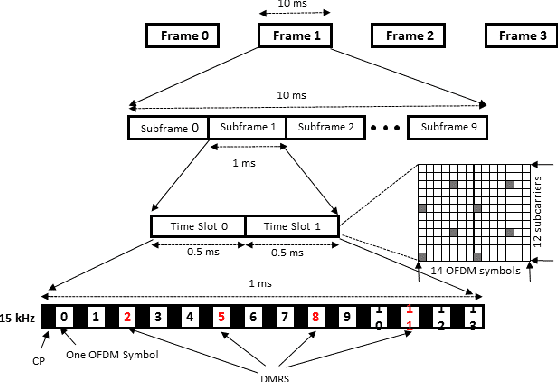
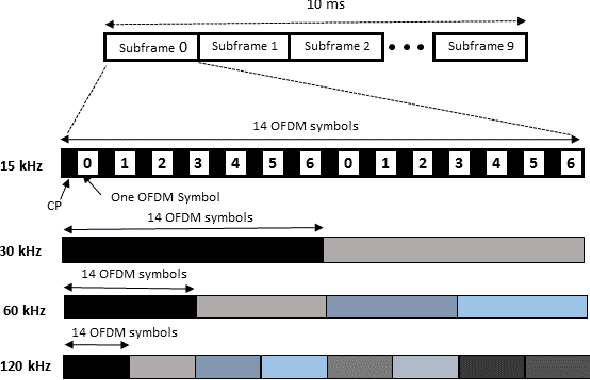
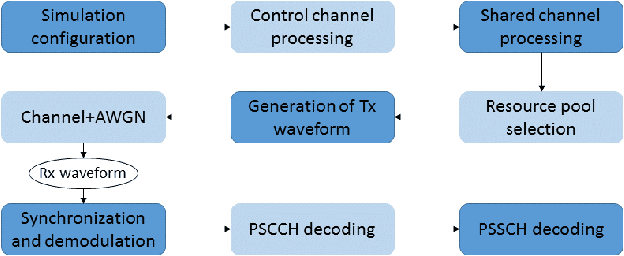
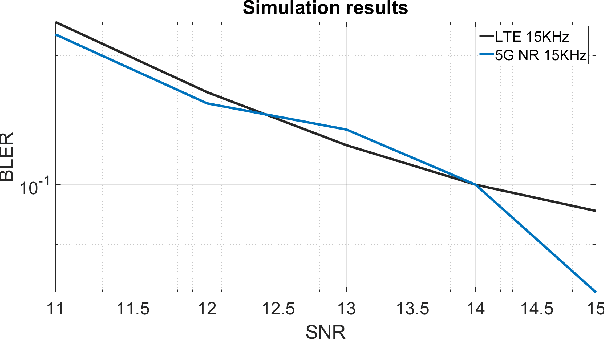
With technology and societal development, the 5th generation wireless communication (5G) contributes significantly to different societies like industries or academies. Vehicle-to-Everything (V2X) communication technology has been one of the leading services for 5G which has been applied in vehicles. It is used to exchange their status information with other traffic and traffic participants to increase traffic safety and efficiency. Cellular-V2X (C-V2X) is one of the emerging technologies to enable V2X communications. The first Long-Term Evolution (LTE) based C-V2X was released on the 3rd Generation Partnership Project (3GPP) standard. 3GPP is working towards the development of New Radio (NR) systems that it is called 5G NR V2X. One single numerology in LTE cannot satisfy most performance requirements because of the variety of deployment options and scenarios. For this reason, in order to meet the diverse requirements, the 5G NR Physical Layer (PHY) is designed to provide a highly flexible framework. Scalable Orthogonal Frequency-Division Multiplexing (OFDM) numerologies make flexibility possible. The term numerology refers to the PHY waveform parametrization and allows different Subcarrier Spacings (SCSs), symbols, and slot duration. This paper implements the Link-Level (LL) simulations of LTE C-V2X communication and 5G NR V2X communication where simulation results are used to compare similarities and differences between LTE and 5G NR. We detect the effect of variable PHY Numerologies of 5G NR on the LL performance of V2X. The simulation results show that the performance of 5G NR improved by using variable numerologies.
XVoxel-Based Parametric Design Optimization of Feature Models
Mar 17, 2023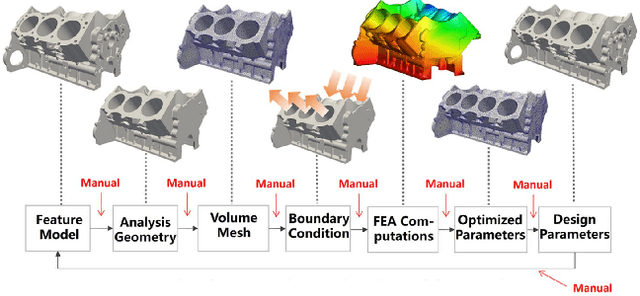
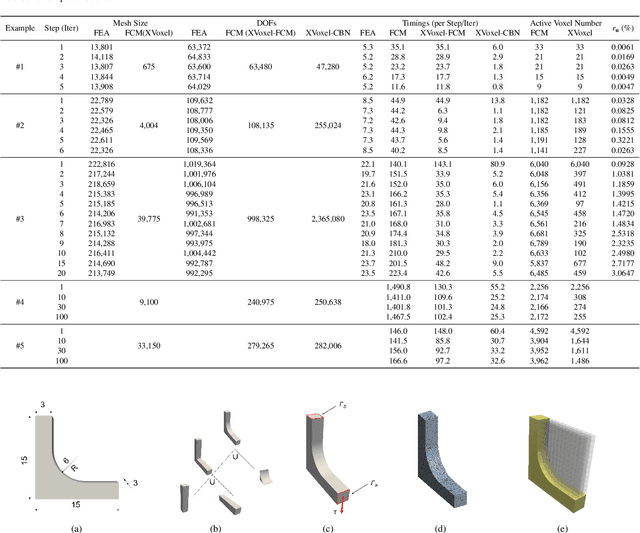
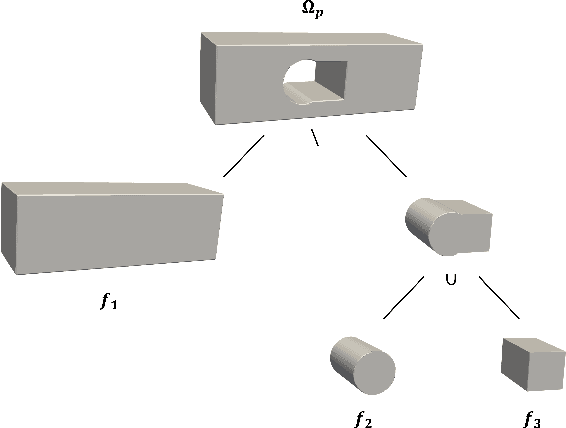

Parametric optimization is an important product design technique, especially in the context of the modern parametric feature-based CAD paradigm. Realizing its full potential, however, requires a closed loop between CAD and CAE (i.e., CAD/CAE integration) with automatic design modifications and simulation updates. Conventionally the approach of model conversion is often employed to form the loop, but this way of working is hard to automate and requires manual inputs. As a result, the overall optimization process is too laborious to be acceptable. To address this issue, a new method for parametric optimization is introduced in this paper, based on a unified model representation scheme called eXtended Voxels (XVoxels). This scheme hybridizes feature models and voxel models into a new concept of semantic voxels, where the voxel part is responsible for FEM solving, and the semantic part is responsible for high-level information to capture both design and simulation intents. As such, it can establish a direct mapping between design models and analysis models, which in turn enables automatic updates on simulation results for design modifications, and vice versa -- effectively a closed loop between CAD and CAE. In addition, robust and efficient geometric algorithms for manipulating XVoxel models and efficient numerical methods (based on the recent finite cell method) for simulating XVoxel models are provided. The presented method has been validated by a series of case studies of increasing complexity to demonstrate its effectiveness. In particular, a computational efficiency improvement of up to 55.8 times the existing FCM method has been seen.
Stat-weight: Improving the Estimator of Interleaved Methods Outcomes with Statistical Hypothesis Testing
Mar 17, 2023Interleaving is an online evaluation approach for information retrieval systems that compares the effectiveness of ranking functions in interpreting the users' implicit feedback. Previous work such as Hofmann et al (2011) has evaluated the most promising interleaved methods at the time, on uniform distributions of queries. In the real world, ordinarily, there is an unbalanced distribution of repeated queries that follows a long-tailed users' search demand curve. The more a query is executed, by different users (or in different sessions), the higher the probability of collecting implicit feedback (interactions/clicks) on the related search results. This paper first aims to replicate the Team Draft Interleaving accuracy evaluation on uniform query distributions and then focuses on assessing how this method generalizes to long-tailed real-world scenarios. The reproducibility work raised interesting considerations on how the winning ranking function for each query should impact the overall winner for the entire evaluation. Based on what was observed, we propose that not all the queries should contribute to the final decision in equal proportion. As a result of these insights, we designed two variations of the $\Delta_{AB}$ score winner estimator that assign to each query a credit based on statistical hypothesis testing. To replicate, reproduce and extend the original work, we have developed from scratch a system that simulates a search engine and users' interactions from datasets from the industry. Our experiments confirm our intuition and show that our methods are promising in terms of accuracy, sensitivity, and robustness to noise.
* This preprint has not undergone peer review (when applicable) or any post-submission improvements or corrections. The Version of Record of this contribution is published in Advances in Information Retrieval 45th European Conference on Information Retrieval, ECIR 2023, Dublin, Ireland, April, 2023, Proceedings, Part III, and is available online at https://doi.org/10.1007/978-3-031-28241-6_2
Approach to Learning Generalized Audio Representation Through Batch Embedding Covariance Regularization and Constant-Q Transforms
Mar 07, 2023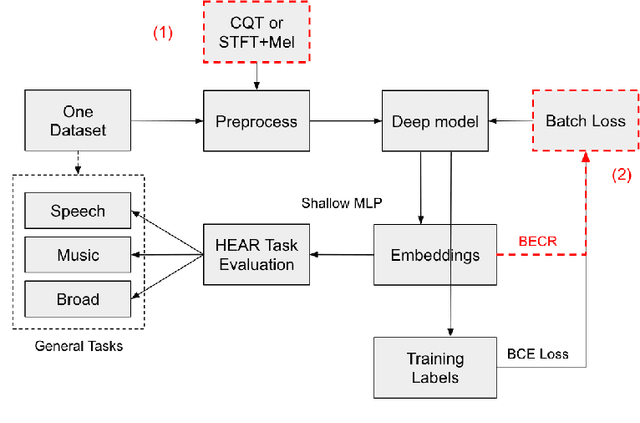
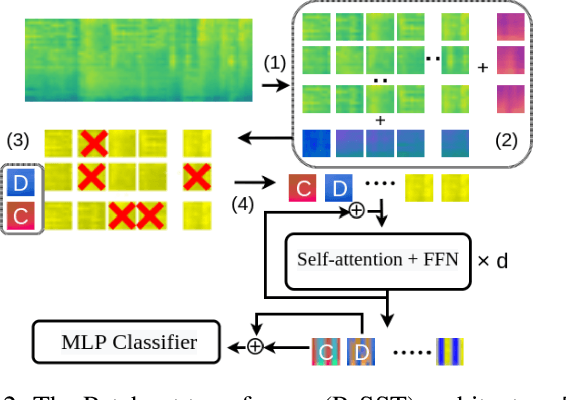
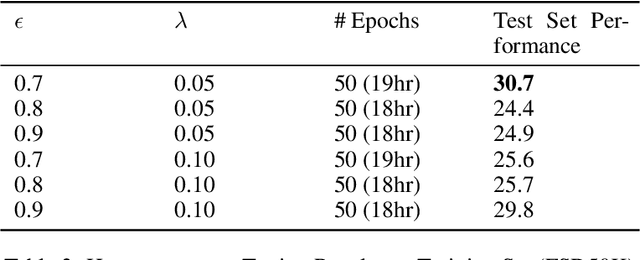
General-purpose embedding is highly desirable for few-shot even zero-shot learning in many application scenarios, including audio tasks. In order to understand representations better, we conducted a thorough error analysis and visualization of HEAR 2021 submission results. Inspired by the analysis, this work experiments with different front-end audio preprocessing methods, including Constant-Q Transform (CQT) and Short-time Fourier transform (STFT), and proposes a Batch Embedding Covariance Regularization (BECR) term to uncover a more holistic simulation of the frequency information received by the human auditory system. We tested the models on the suite of HEAR 2021 tasks, which encompass a broad category of tasks. Preliminary results show (1) the proposed BECR can incur a more dispersed embedding on the test set, (2) BECR improves the PaSST model without extra computation complexity, and (3) STFT preprocessing outperforms CQT in all tasks we tested. Github:https://github.com/ankitshah009/general_audio_embedding_hear_2021
A Multi-Stage Triple-Path Method for Speech Separation in Noisy and Reverberant Environments
Mar 07, 2023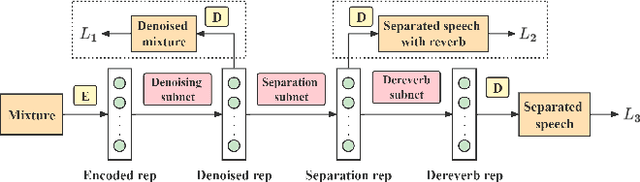
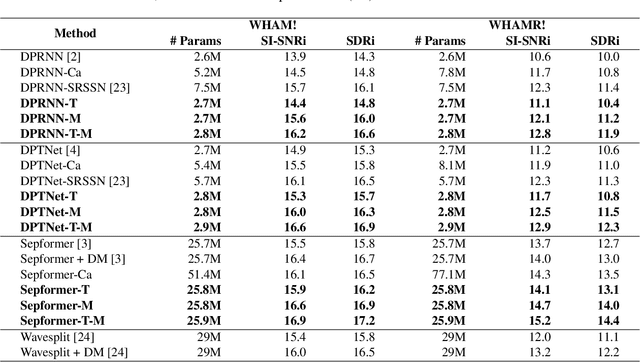
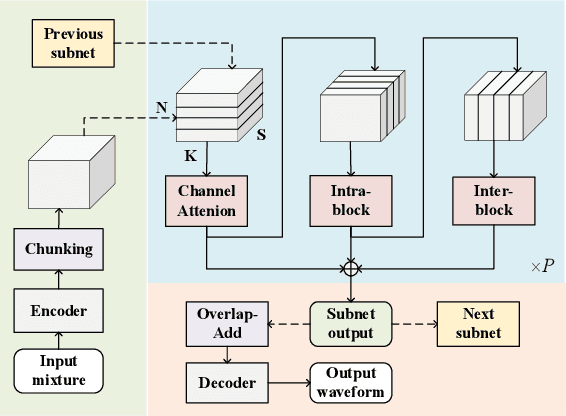
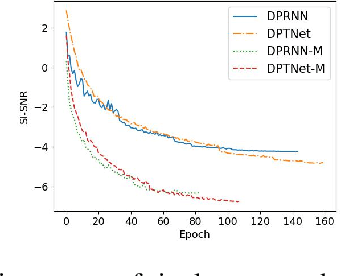
In noisy and reverberant environments, the performance of deep learning-based speech separation methods drops dramatically because previous methods are not designed and optimized for such situations. To address this issue, we propose a multi-stage end-to-end learning method that decouples the difficult speech separation problem in noisy and reverberant environments into three sub-problems: speech denoising, separation, and de-reverberation. The probability and speed of searching for the optimal solution of the speech separation model are improved by reducing the solution space. Moreover, since the channel information of the audio sequence in the time domain is crucial for speech separation, we propose a triple-path structure capable of modeling the channel dimension of audio sequences. Experimental results show that the proposed multi-stage triple-path method can improve the performance of speech separation models at the cost of little model parameter increment.
ChatCAD: Interactive Computer-Aided Diagnosis on Medical Image using Large Language Models
Feb 14, 2023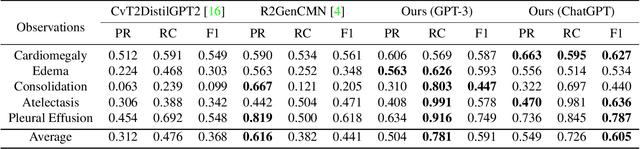



Large language models (LLMs) have recently demonstrated their potential in clinical applications, providing valuable medical knowledge and advice. For example, a large dialog LLM like ChatGPT has successfully passed part of the US medical licensing exam. However, LLMs currently have difficulty processing images, making it challenging to interpret information from medical images, which are rich in information that supports clinical decisions. On the other hand, computer-aided diagnosis (CAD) networks for medical images have seen significant success in the medical field by using advanced deep-learning algorithms to support clinical decision-making. This paper presents a method for integrating LLMs into medical-image CAD networks. The proposed framework uses LLMs to enhance the output of multiple CAD networks, such as diagnosis networks, lesion segmentation networks, and report generation networks, by summarizing and reorganizing the information presented in natural language text format. The goal is to merge the strengths of LLMs' medical domain knowledge and logical reasoning with the vision understanding capability of existing medical-image CAD models to create a more user-friendly and understandable system for patients compared to conventional CAD systems. In the future, LLM's medical knowledge can be also used to improve the performance of vision-based medical-image CAD models.
Better Than Whitespace: Information Retrieval for Languages without Custom Tokenizers
Oct 11, 2022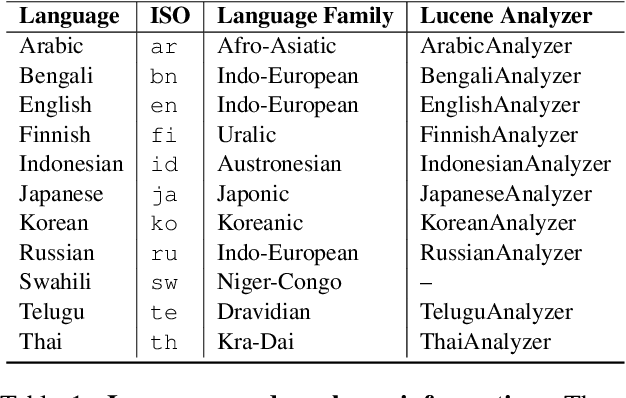
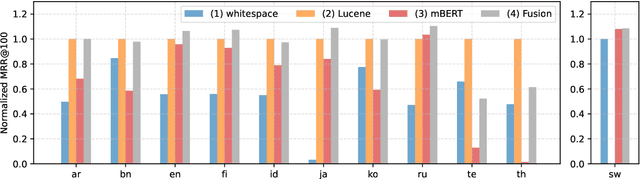
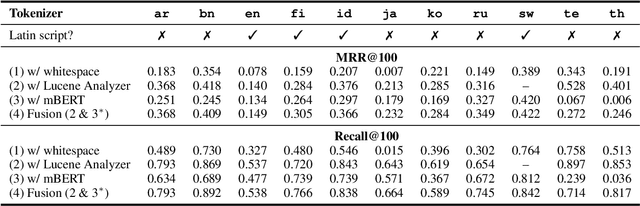
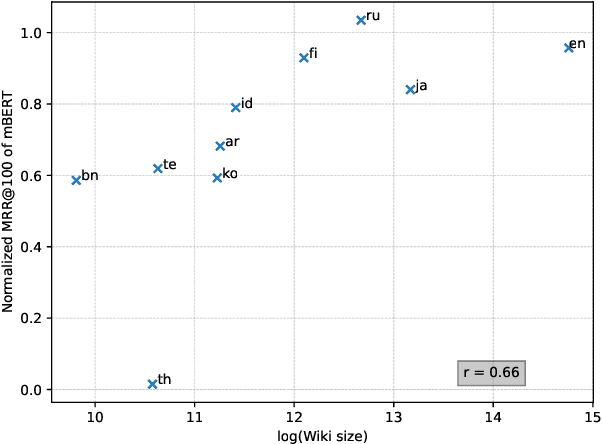
Tokenization is a crucial step in information retrieval, especially for lexical matching algorithms, where the quality of indexable tokens directly impacts the effectiveness of a retrieval system. Since different languages have unique properties, the design of the tokenization algorithm is usually language-specific and requires at least some lingustic knowledge. However, only a handful of the 7000+ languages on the planet benefit from specialized, custom-built tokenization algorithms, while the other languages are stuck with a "default" whitespace tokenizer, which cannot capture the intricacies of different languages. To address this challenge, we propose a different approach to tokenization for lexical matching retrieval algorithms (e.g., BM25): using the WordPiece tokenizer, which can be built automatically from unsupervised data. We test the approach on 11 typologically diverse languages in the MrTyDi collection: results show that the mBERT tokenizer provides strong relevance signals for retrieval "out of the box", outperforming whitespace tokenization on most languages. In many cases, our approach also improves retrieval effectiveness when combined with existing custom-built tokenizers.
TPGNN: Learning High-order Information in Dynamic Graphs via Temporal Propagation
Oct 03, 2022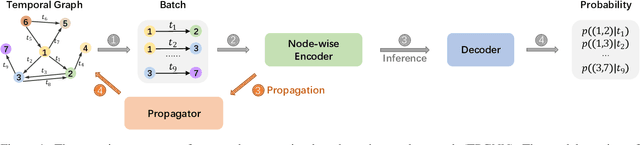
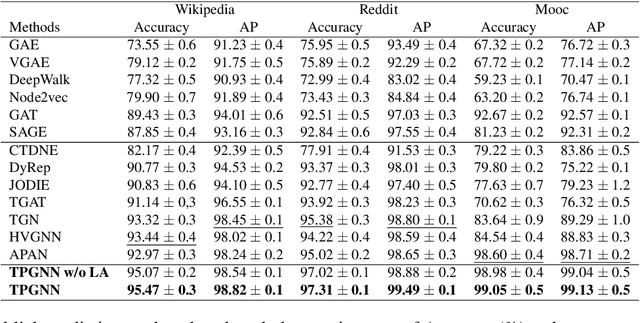
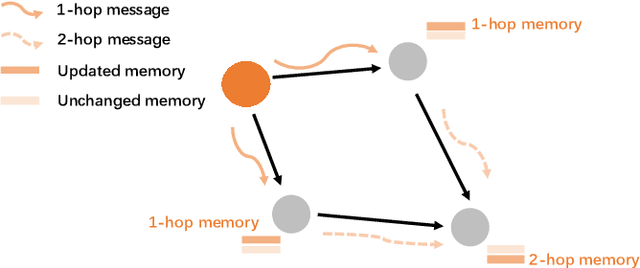

Temporal graph is an abstraction for modeling dynamic systems that consist of evolving interaction elements. In this paper, we aim to solve an important yet neglected problem -- how to learn information from high-order neighbors in temporal graphs? -- to enhance the informativeness and discriminativeness for the learned node representations. We argue that when learning high-order information from temporal graphs, we encounter two challenges, i.e., computational inefficiency and over-smoothing, that cannot be solved by conventional techniques applied on static graphs. To remedy these deficiencies, we propose a temporal propagation-based graph neural network, namely TPGNN. To be specific, the model consists of two distinct components, i.e., propagator and node-wise encoder. The propagator is leveraged to propagate messages from the anchor node to its temporal neighbors within $k$-hop, and then simultaneously update the state of neighborhoods, which enables efficient computation, especially for a deep model. In addition, to prevent over-smoothing, the model compels the messages from $n$-hop neighbors to update the $n$-hop memory vector preserved on the anchor. The node-wise encoder adopts transformer architecture to learn node representations by explicitly learning the importance of memory vectors preserved on the node itself, that is, implicitly modeling the importance of messages from neighbors at different layers, thus mitigating the over-smoothing. Since the encoding process will not query temporal neighbors, we can dramatically save time consumption in inference. Extensive experiments on temporal link prediction and node classification demonstrate the superiority of TPGNN over state-of-the-art baselines in efficiency and robustness.