 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TRELM: Towards Robust and Efficient Pre-training for Knowledge-Enhanced Language Models
Mar 17, 2024
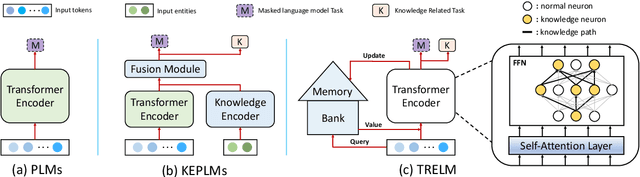

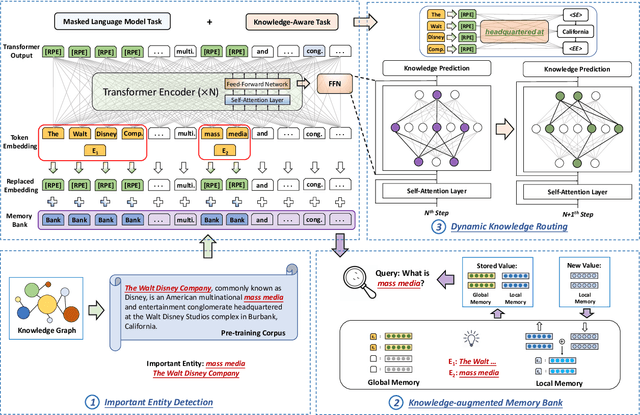
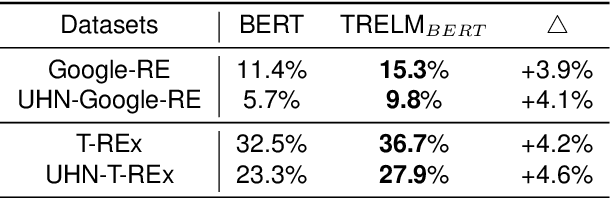
KEPLMs are pre-trained models that utilize external knowledge to enhance language understanding. Previous language models facilitated knowledge acquisition by incorporating knowledge-related pre-training tasks learned from relation triples in knowledge graphs. However, these models do not prioritize learning embeddings for entity-related tokens. Moreover, updating the entire set of parameters in KEPLMs is computationally demanding. This paper introduces TRELM, a Robust and Efficient Pre-training framework for Knowledge-Enhanced Language Models. We observe that entities in text corpora usually follow the long-tail distribution, where the representations of some entities are suboptimally optimized and hinder the pre-training process for KEPLMs. To tackle this, we employ a robust approach to inject knowledge triples and employ a knowledge-augmented memory bank to capture valuable information. Furthermore, updating a small subset of neurons in the feed-forward networks (FFNs) that store factual knowledge is both sufficient and efficient. Specifically, we utilize dynamic knowledge routing to identify knowledge paths in FFNs and selectively update parameters during pre-training. Experimental results show that TRELM reduces pre-training time by at least 50% and outperforms other KEPLMs in knowledge probing tasks and multiple knowledge-aware language understanding tasks.
Concatenate, Fine-tuning, Re-training: A SAM-enabled Framework for Semi-supervised 3D Medical Image Segmentation
Mar 17, 2024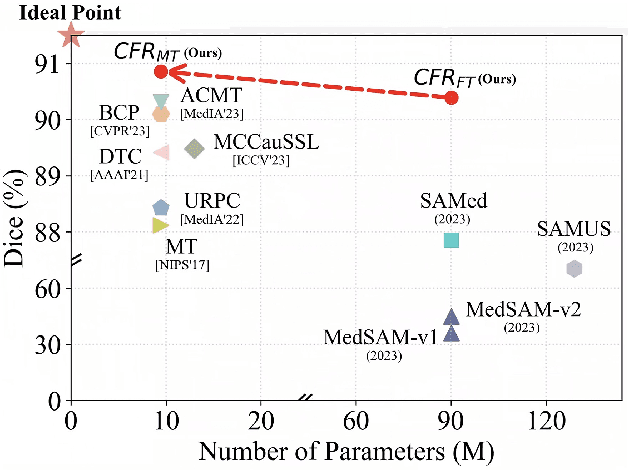
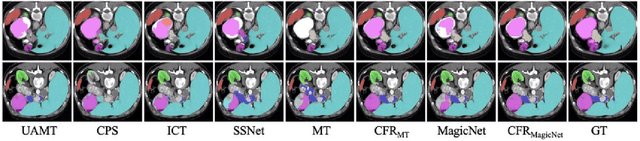
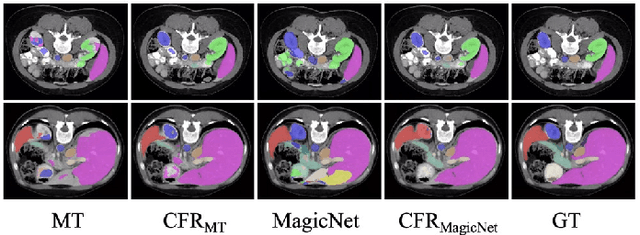
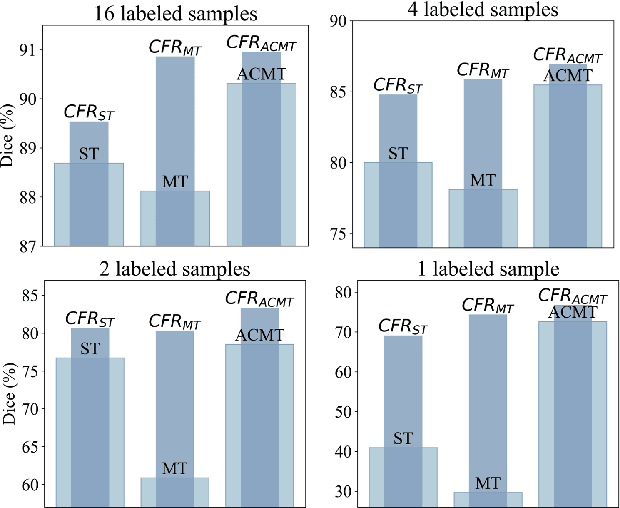
Segment Anything Model (SAM) fine-tuning has shown remarkable performance in medical image segmentation in a fully supervised manner, but requires precise annotations. To reduce the annotation cost and maintain satisfactory performance, in this work, we leverage the capabilities of SAM for establishing semi-supervised medical image segmentation models. Rethinking the requirements of effectiveness, efficiency, and compatibility, we propose a three-stage framework, i.e., Concatenate, Fine-tuning, and Re-training (CFR). The current fine-tuning approaches mostly involve 2D slice-wise fine-tuning that disregards the contextual information between adjacent slices. Our concatenation strategy mitigates the mismatch between natural and 3D medical images. The concatenated images are then used for fine-tuning SAM, providing robust initialization pseudo-labels. Afterwards, we train a 3D semi-supervised segmentation model while maintaining the same parameter size as the conventional segmenter such as V-Net. Our CFR framework is plug-and-play, and easily compatible with various popular semi-supervised methods. Extensive experiments validate that our CFR achieves significant improvements in both moderate annotation and scarce annotation across four datasets. In particular, CFR framework improves the Dice score of Mean Teacher from 29.68% to 74.40% with only one labeled data of LA dataset.
A Fourier Transform Framework for Domain Adaptation
Mar 12, 2024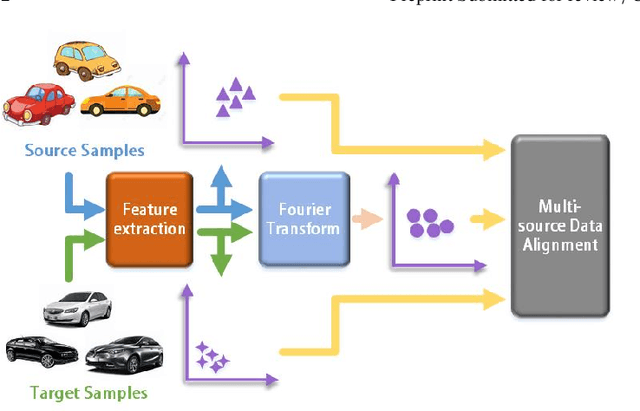
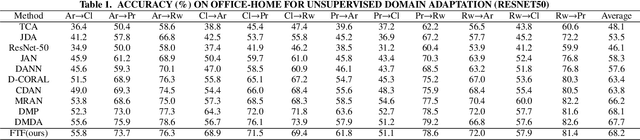
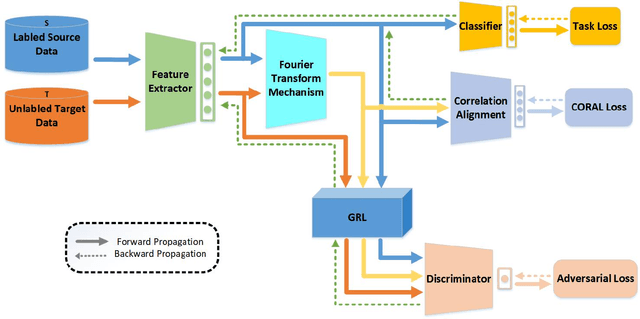

By using unsupervised domain adaptation (UDA), knowledge can be transferred from a label-rich source domain to a target domain that contains relevant information but lacks labels. Many existing UDA algorithms suffer from directly using raw images as input, resulting in models that overly focus on redundant information and exhibit poor generalization capability. To address this issue, we attempt to improve the performance of unsupervised domain adaptation by employing the Fourier method (FTF).Specifically, FTF is inspired by the amplitude of Fourier spectra, which primarily preserves low-level statistical information. In FTF, we effectively incorporate low-level information from the target domain into the source domain by fusing the amplitudes of both domains in the Fourier domain. Additionally, we observe that extracting features from batches of images can eliminate redundant information while retaining class-specific features relevant to the task. Building upon this observation, we apply the Fourier Transform at the data stream level for the first time. To further align multiple sources of data, we introduce the concept of correlation alignment. To evaluate the effectiveness of our FTF method, we conducted evaluations on four benchmark datasets for domain adaptation, including Office-31, Office-Home, ImageCLEF-DA, and Office-Caltech. Our results demonstrate superior performance.
Adversarial Training with OCR Modality Perturbation for Scene-Text Visual Question Answering
Mar 14, 2024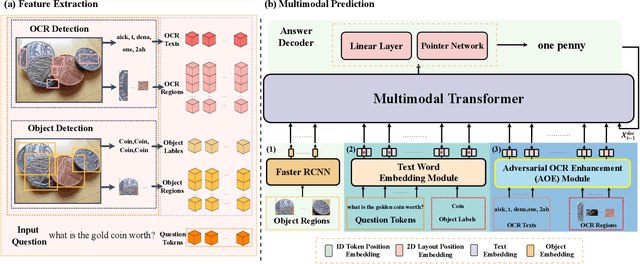
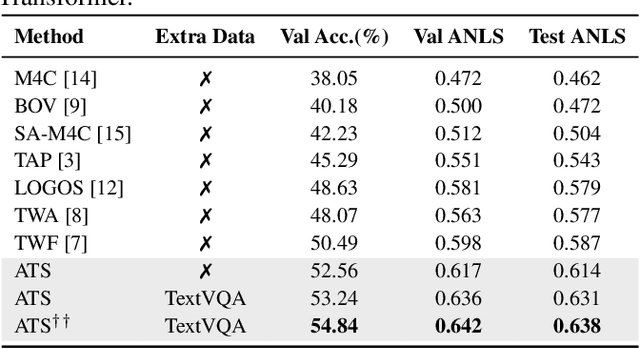
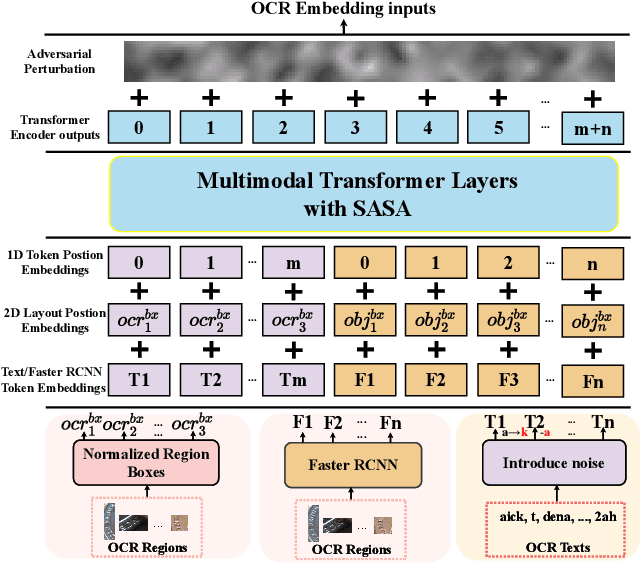
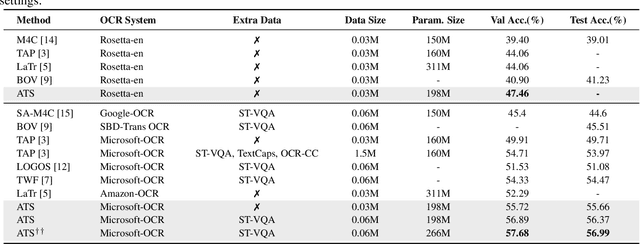
Scene-Text Visual Question Answering (ST-VQA) aims to understand scene text in images and answer questions related to the text content. Most existing methods heavily rely on the accuracy of Optical Character Recognition (OCR) systems, and aggressive fine-tuning based on limited spatial location information and erroneous OCR text information often leads to inevitable overfitting. In this paper, we propose a multimodal adversarial training architecture with spatial awareness capabilities. Specifically, we introduce an Adversarial OCR Enhancement (AOE) module, which leverages adversarial training in the embedding space of OCR modality to enhance fault-tolerant representation of OCR texts, thereby reducing noise caused by OCR errors. Simultaneously, We add a Spatial-Aware Self-Attention (SASA) mechanism to help the model better capture the spatial relationships among OCR tokens. Various experiments demonstrate that our method achieves significant performance improvements on both the ST-VQA and TextVQA datasets and provides a novel paradigm for multimodal adversarial training.
[RE] Modeling Personalized Item Frequency Information for Next-basket Recommendation
Feb 27, 2024This paper focuses on reproducing and extending the results of the paper: "Modeling Personalized Item Frequency Information for Next-basket Recommendation" which introduced the TIFU-KNN model and proposed to utilize Personalized Item Frequency (PIF) for Next Basket Recommendation (NBR). We utilized publicly available grocery shopping datasets used in the original paper and incorporated additional datasets to assess the generalizability of the findings. We evaluated the performance of the models using metrics such as Recall@K, NDCG@K, personalized-hit ratio (PHR), and Mean Reciprocal Rank (MRR). Furthermore, we conducted a thorough examination of fairness by considering user characteristics such as average basket size, item popularity, and novelty. Lastly, we introduced novel $\beta$-VAE architecture to model NBR. The experimental results confirmed that the reproduced model, TIFU-KNN, outperforms the baseline model, Personal Top Frequency, on various datasets and metrics. The findings also highlight the challenges posed by smaller basket sizes in some datasets and suggest avenues for future research to improve NBR performance.
Federated Modality-specific Encoders and Multimodal Anchors for Personalized Brain Tumor Segmentation
Mar 18, 2024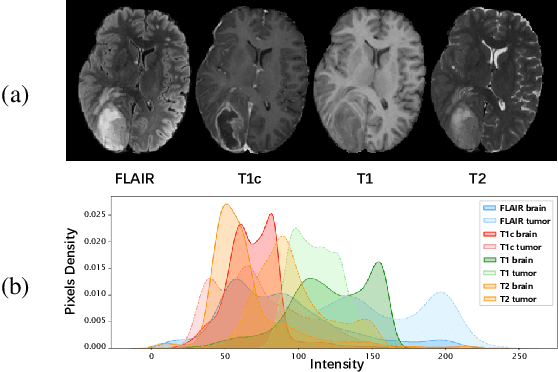
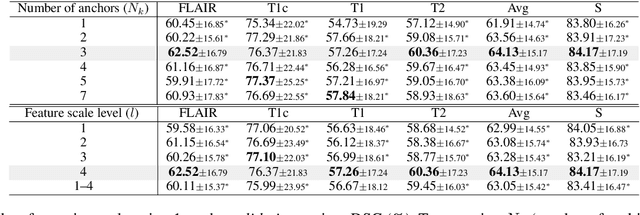
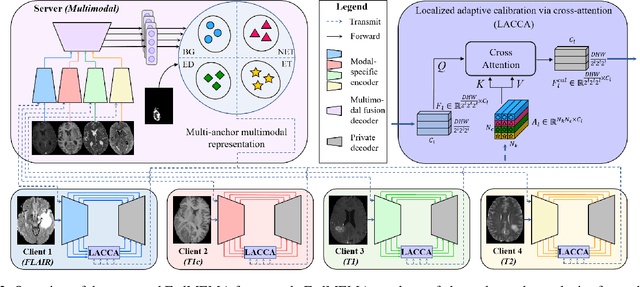
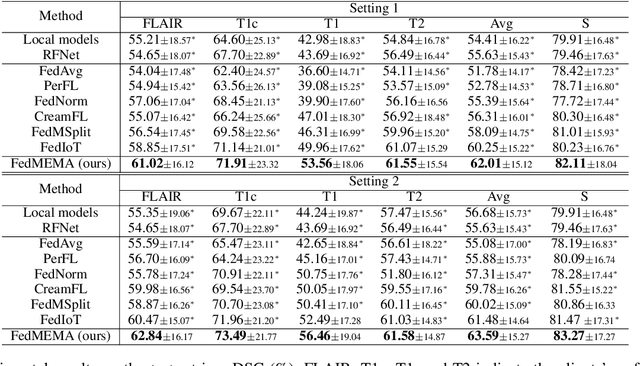
Most existing federated learning (FL) methods for medical image analysis only considered intramodal heterogeneity, limiting their applicability to multimodal imaging applications. In practice, it is not uncommon that some FL participants only possess a subset of the complete imaging modalities, posing inter-modal heterogeneity as a challenge to effectively training a global model on all participants' data. In addition, each participant would expect to obtain a personalized model tailored for its local data characteristics from the FL in such a scenario. In this work, we propose a new FL framework with federated modality-specific encoders and multimodal anchors (FedMEMA) to simultaneously address the two concurrent issues. Above all, FedMEMA employs an exclusive encoder for each modality to account for the inter-modal heterogeneity in the first place. In the meantime, while the encoders are shared by the participants, the decoders are personalized to meet individual needs. Specifically, a server with full-modal data employs a fusion decoder to aggregate and fuse representations from all modality-specific encoders, thus bridging the modalities to optimize the encoders via backpropagation reversely. Meanwhile, multiple anchors are extracted from the fused multimodal representations and distributed to the clients in addition to the encoder parameters. On the other end, the clients with incomplete modalities calibrate their missing-modal representations toward the global full-modal anchors via scaled dot-product cross-attention, making up the information loss due to absent modalities while adapting the representations of present ones. FedMEMA is validated on the BraTS 2020 benchmark for multimodal brain tumor segmentation. Results show that it outperforms various up-to-date methods for multimodal and personalized FL and that its novel designs are effective. Our code is available.
ViT-CoMer: Vision Transformer with Convolutional Multi-scale Feature Interaction for Dense Predictions
Mar 15, 2024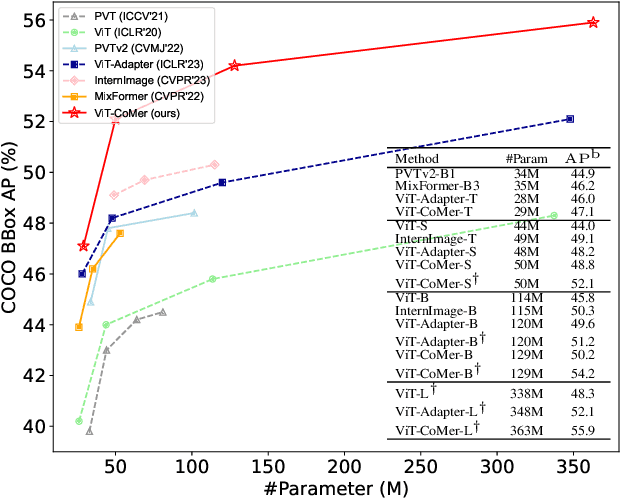
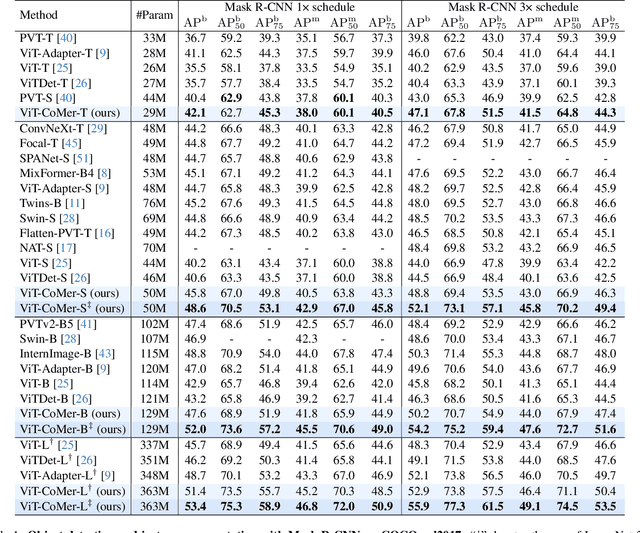
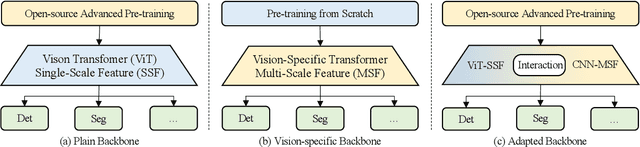
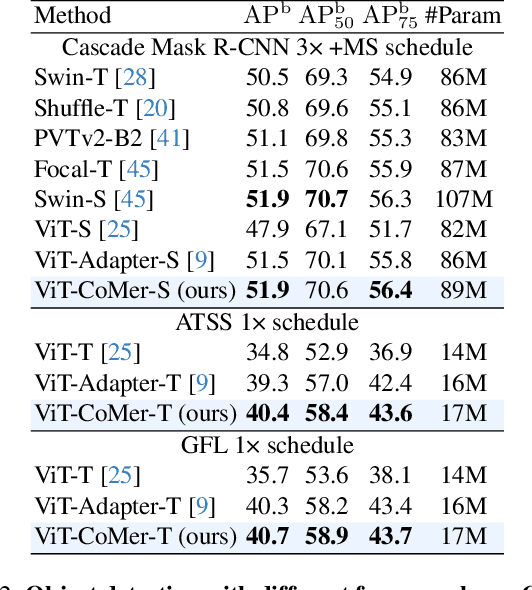
Although Vision Transformer (ViT) has achieved significant success in computer vision, it does not perform well in dense prediction tasks due to the lack of inner-patch information interaction and the limited diversity of feature scale. Most existing studies are devoted to designing vision-specific transformers to solve the above problems, which introduce additional pre-training costs. Therefore, we present a plain, pre-training-free, and feature-enhanced ViT backbone with Convolutional Multi-scale feature interaction, named ViT-CoMer, which facilitates bidirectional interaction between CNN and transformer. Compared to the state-of-the-art, ViT-CoMer has the following advantages: (1) We inject spatial pyramid multi-receptive field convolutional features into the ViT architecture, which effectively alleviates the problems of limited local information interaction and single-feature representation in ViT. (2) We propose a simple and efficient CNN-Transformer bidirectional fusion interaction module that performs multi-scale fusion across hierarchical features, which is beneficial for handling dense prediction tasks. (3) We evaluate the performance of ViT-CoMer across various dense prediction tasks, different frameworks, and multiple advanced pre-training. Notably, our ViT-CoMer-L achieves 64.3% AP on COCO val2017 without extra training data, and 62.1% mIoU on ADE20K val, both of which are comparable to state-of-the-art methods. We hope ViT-CoMer can serve as a new backbone for dense prediction tasks to facilitate future research. The code will be released at https://github.com/Traffic-X/ViT-CoMer.
Large language model-powered chatbots for internationalizing student support in higher education
Mar 16, 2024This research explores the integration of chatbot technology powered by GPT-3.5 and GPT-4 Turbo into higher education to enhance internationalization and leverage digital transformation. It delves into the design, implementation, and application of Large Language Models (LLMs) for improving student engagement, information access, and support. Utilizing technologies like Python 3, GPT API, LangChain, and Chroma Vector Store, the research emphasizes creating a high-quality, timely, and relevant transcript dataset for chatbot testing. Findings indicate the chatbot's efficacy in providing comprehensive responses, its preference over traditional methods by users, and a low error rate. Highlighting the chatbot's real-time engagement, memory capabilities, and critical data access, the study demonstrates its potential to elevate accessibility, efficiency, and satisfaction. Concluding, the research suggests the chatbot significantly aids higher education internationalization, proposing further investigation into digital technology's role in educational enhancement and strategy development.
Function-space Parameterization of Neural Networks for Sequential Learning
Mar 16, 2024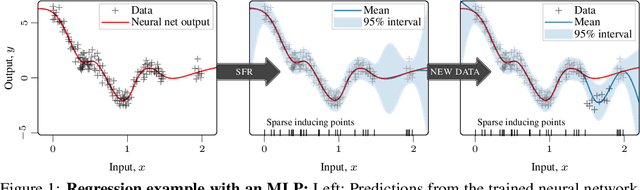
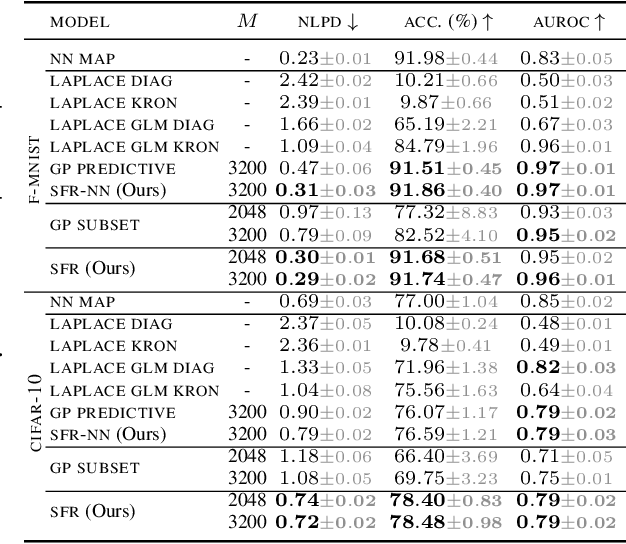
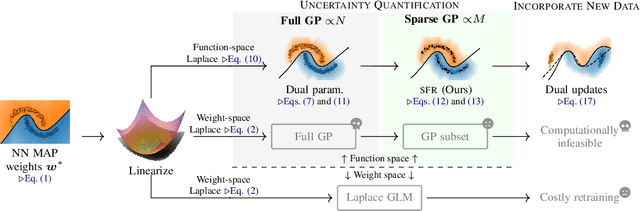
Sequential learning paradigms pose challenges for gradient-based deep learning due to difficulties incorporating new data and retaining prior knowledge. While Gaussian processes elegantly tackle these problems, they struggle with scalability and handling rich inputs, such as images. To address these issues, we introduce a technique that converts neural networks from weight space to function space, through a dual parameterization. Our parameterization offers: (i) a way to scale function-space methods to large data sets via sparsification, (ii) retention of prior knowledge when access to past data is limited, and (iii) a mechanism to incorporate new data without retraining. Our experiments demonstrate that we can retain knowledge in continual learning and incorporate new data efficiently. We further show its strengths in uncertainty quantification and guiding exploration in model-based RL. Further information and code is available on the project website.
Vision-based Vehicle Re-identification in Bridge Scenario using Flock Similarity
Mar 12, 2024


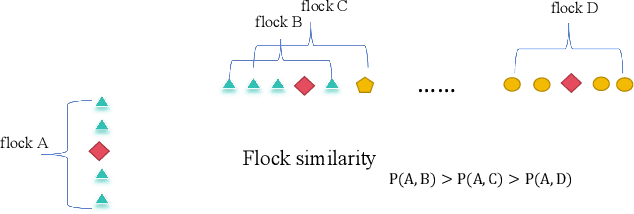
Due to the needs of road traffic flow monitoring and public safety management, video surveillance cameras are widely distributed in urban roads. However, the information captured directly by each camera is siloed, making it difficult to use it effectively. Vehicle re-identification refers to finding a vehicle that appears under one camera in another camera, which can correlate the information captured by multiple cameras. While license plate recognition plays an important role in some applications, there are some scenarios where re-identification method based on vehicle appearance are more suitable. The main challenge is that the data of vehicle appearance has the characteristics of high inter-class similarity and large intra-class differences. Therefore, it is difficult to accurately distinguish between different vehicles by relying only on vehicle appearance information. At this time, it is often necessary to introduce some extra information, such as spatio-temporal information. Nevertheless, the relative position of the vehicles rarely changes when passing through two adjacent cameras in the bridge scenario. In this paper, we present a vehicle re-identification method based on flock similarity, which improves the accuracy of vehicle re-identification by utilizing vehicle information adjacent to the target vehicle. When the relative position of the vehicles remains unchanged and flock size is appropriate, we obtain an average relative improvement of 204% on VeRi dataset in our experiments. Then, the effect of the magnitude of the relative position change of the vehicles as they pass through two cameras is discussed. We present two metrics that can be used to quantify the difference and establish a connection between them. Although this assumption is based on the bridge scenario, it is often true in other scenarios due to driving safety and camera location.