 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Modified EDAS Method Based on Cumulative Prospect Theory for Multiple Attributes Group Decision Making with Interval-valued Intuitionistic Fuzzy Information
Nov 05, 2022
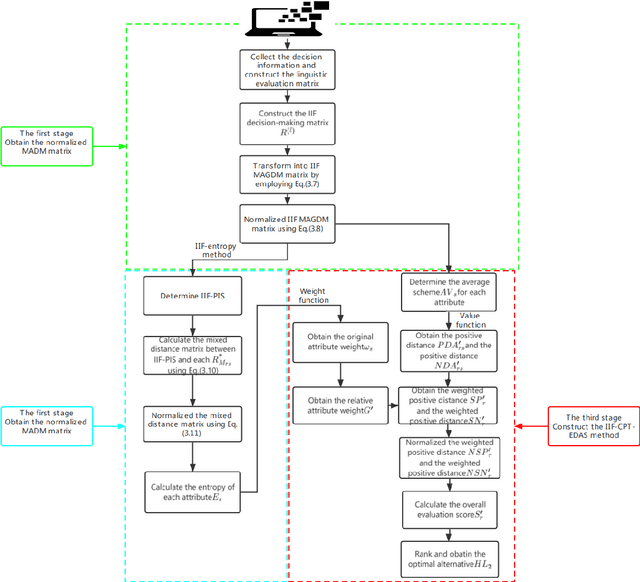
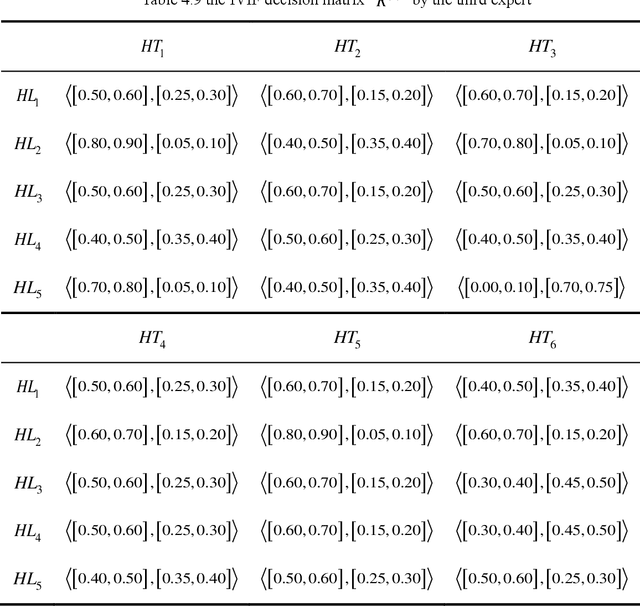
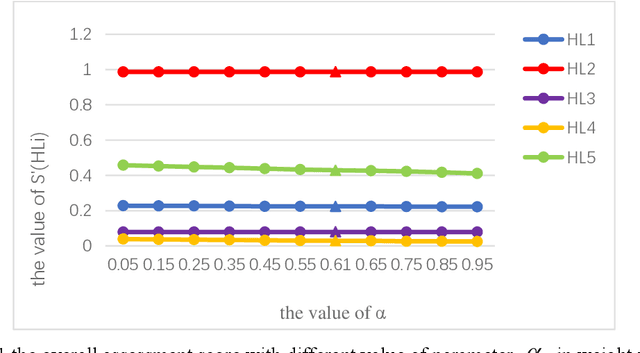
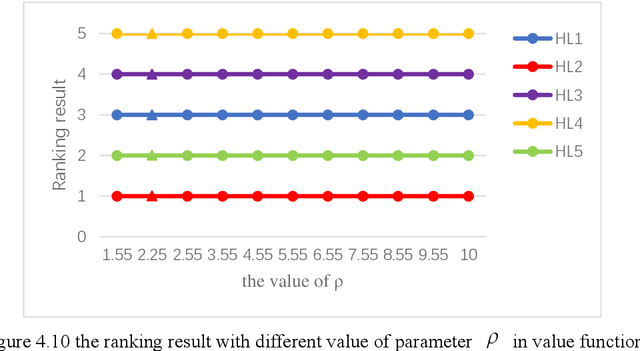
The Interval-valued intuitionistic fuzzy sets (IVIFSs) based on the intuitionistic fuzzy sets combines the classical decision method is in its research and application is attracting attention. After comparative analysis, there are multiple classical methods with IVIFSs information have been applied into many practical issues. In this paper, we extended the classical EDAS method based on cumulative prospect theory (CPT) considering the decision makers (DMs) psychological factor under IVIFSs. Taking the fuzzy and uncertain character of the IVIFSs and the psychological preference into consideration, the original EDAS method based on the CPT under IVIFSs (IVIF-CPT-MABAC) method is built for MAGDM issues. Meanwhile, information entropy method is used to evaluate the attribute weight. Finally, a numerical example for project selection of green technology venture capital has been given and some comparisons is used to illustrate advantages of IVIF-CPT-MABAC method and some comparison analysis and sensitivity analysis are applied to prove this new methods effectiveness and stability.
Efficient fair PCA for fair representation learning
Feb 26, 2023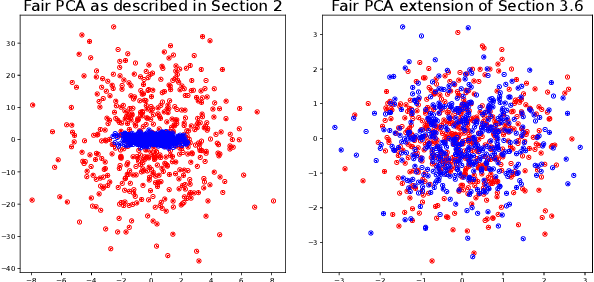
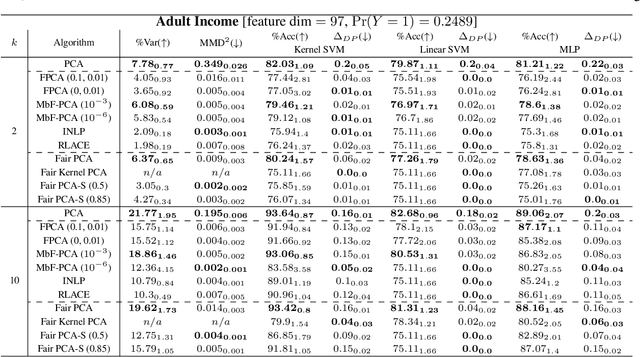
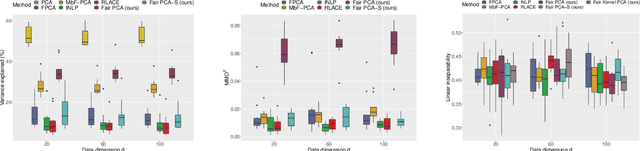

We revisit the problem of fair principal component analysis (PCA), where the goal is to learn the best low-rank linear approximation of the data that obfuscates demographic information. We propose a conceptually simple approach that allows for an analytic solution similar to standard PCA and can be kernelized. Our methods have the same complexity as standard PCA, or kernel PCA, and run much faster than existing methods for fair PCA based on semidefinite programming or manifold optimization, while achieving similar results.
Artificial Influence: An Analysis Of AI-Driven Persuasion
Mar 15, 2023Persuasion is a key aspect of what it means to be human, and is central to business, politics, and other endeavors. Advancements in artificial intelligence (AI) have produced AI systems that are capable of persuading humans to buy products, watch videos, click on search results, and more. Even systems that are not explicitly designed to persuade may do so in practice. In the future, increasingly anthropomorphic AI systems may form ongoing relationships with users, increasing their persuasive power. This paper investigates the uncertain future of persuasive AI systems. We examine ways that AI could qualitatively alter our relationship to and views regarding persuasion by shifting the balance of persuasive power, allowing personalized persuasion to be deployed at scale, powering misinformation campaigns, and changing the way humans can shape their own discourse. We consider ways AI-driven persuasion could differ from human-driven persuasion. We warn that ubiquitous highlypersuasive AI systems could alter our information environment so significantly so as to contribute to a loss of human control of our own future. In response, we examine several potential responses to AI-driven persuasion: prohibition, identification of AI agents, truthful AI, and legal remedies. We conclude that none of these solutions will be airtight, and that individuals and governments will need to take active steps to guard against the most pernicious effects of persuasive AI.
DICNet: Deep Instance-Level Contrastive Network for Double Incomplete Multi-View Multi-Label Classification
Mar 15, 2023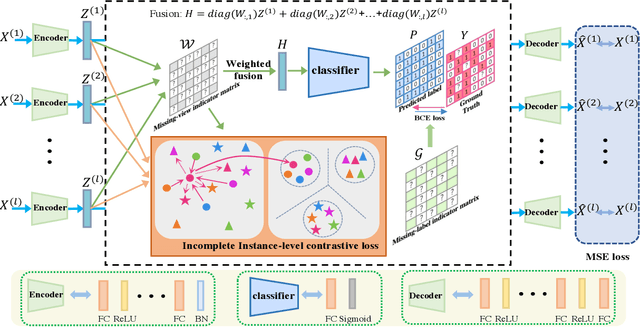
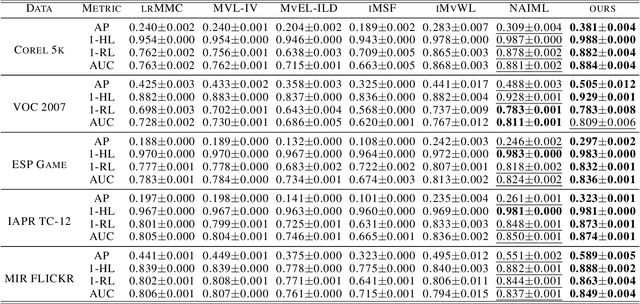
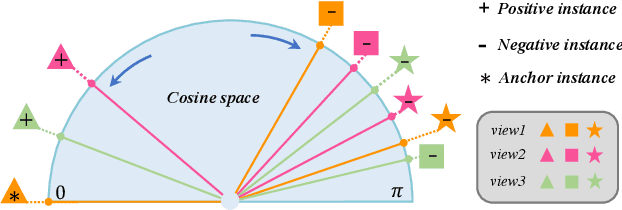
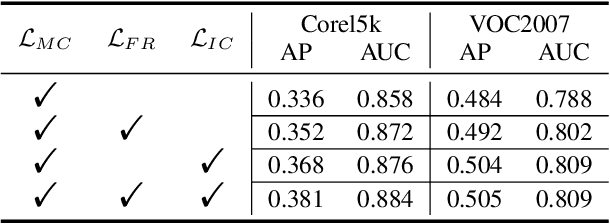
In recent years, multi-view multi-label learning has aroused extensive research enthusiasm. However, multi-view multi-label data in the real world is commonly incomplete due to the uncertain factors of data collection and manual annotation, which means that not only multi-view features are often missing, and label completeness is also difficult to be satisfied. To deal with the double incomplete multi-view multi-label classification problem, we propose a deep instance-level contrastive network, namely DICNet. Different from conventional methods, our DICNet focuses on leveraging deep neural network to exploit the high-level semantic representations of samples rather than shallow-level features. First, we utilize the stacked autoencoders to build an end-to-end multi-view feature extraction framework to learn the view-specific representations of samples. Furthermore, in order to improve the consensus representation ability, we introduce an incomplete instance-level contrastive learning scheme to guide the encoders to better extract the consensus information of multiple views and use a multi-view weighted fusion module to enhance the discrimination of semantic features. Overall, our DICNet is adept in capturing consistent discriminative representations of multi-view multi-label data and avoiding the negative effects of missing views and missing labels. Extensive experiments performed on five datasets validate that our method outperforms other state-of-the-art methods.
Computing Functions Over-the-Air Using Digital Modulations
Mar 15, 2023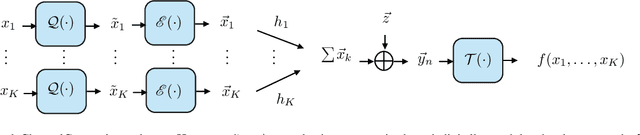
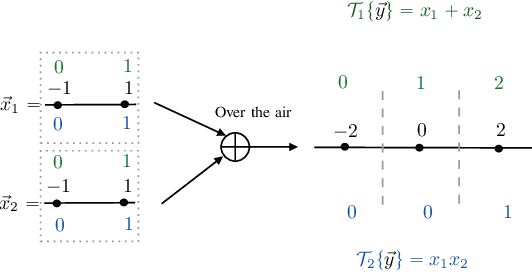
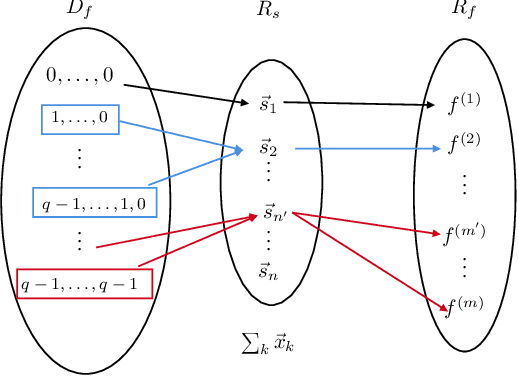
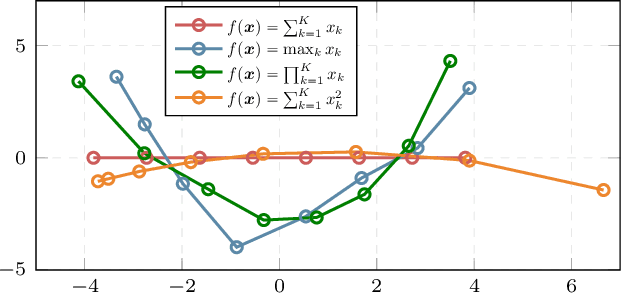
Over-the-air computation (AirComp) is a known technique in which wireless devices transmit values by analog amplitude modulation so that a function of these values is computed over the communication channel at a common receiver. The physical reason is the superposition properties of the electromagnetic waves, which naturally return sums of analog values. Consequently, the applications of AirComp are almost entirely restricted to analog communication systems. However, the use of digital communications for over-the-air computations would have several benefits, such as error correction, synchronization, acquisition of channel state information, and easier adoption by current digital communication systems. Nevertheless, a common belief is that digital modulations are generally unfeasible for computation tasks because the overlapping of digitally modulated signals returns signals that seem to be meaningless for these tasks. This paper breaks through such a belief and proposes a fundamentally new computing method, named ChannelComp, for performing over-the-air computations by any digital modulation. In particular, we propose digital modulation formats that allow us to compute a wider class of functions than AirComp can compute, and we propose a feasibility optimization problem that ascertains the optimal digital modulation for computing functions over-the-air. The simulation results verify the superior performance of ChannelComp in comparison to AirComp, particularly for the product functions, with around 10 dB improvement of the computation error.
Memory-augmented Online Video Anomaly Detection
Feb 21, 2023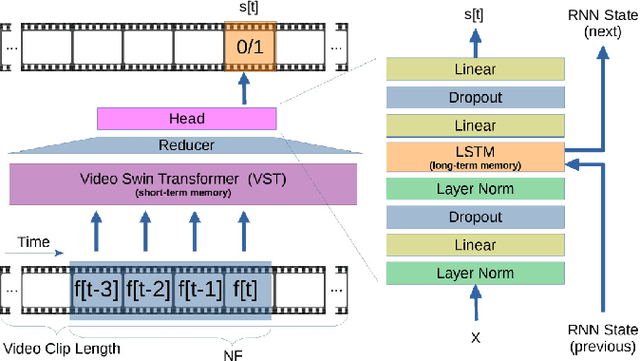


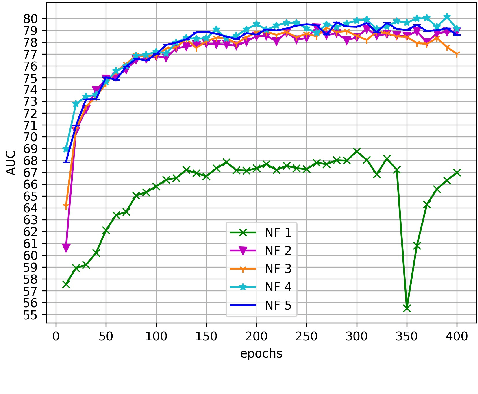
The ability to understand the surrounding scene is of paramount importance for Autonomous Vehicles (AVs). This paper presents a system capable to work in a real time guaranteed response times and online fashion, giving an immediate response to the arise of anomalies surrounding the AV, exploiting only the videos captured by a dash-mounted camera. Our architecture, called MOVAD, relies on two main modules: a short-term memory to extract information related to the ongoing action, implemented by a Video Swin Transformer adapted to work in an online scenario, and a long-term memory module that considers also remote past information thanks to the use of a Long-Short Term Memory (LSTM) network. We evaluated the performance of our method on Detection of Traffic Anomaly (DoTA) dataset, a challenging collection of dash-mounted camera videos of accidents. After an extensive ablation study, MOVAD is able to reach an AUC score of 82.11%, surpassing the current state-of-the-art by +2.81 AUC. Our code will be available on https://github.com/IMPLabUniPr/movad/tree/icip
MVFusion: Multi-View 3D Object Detection with Semantic-aligned Radar and Camera Fusion
Feb 21, 2023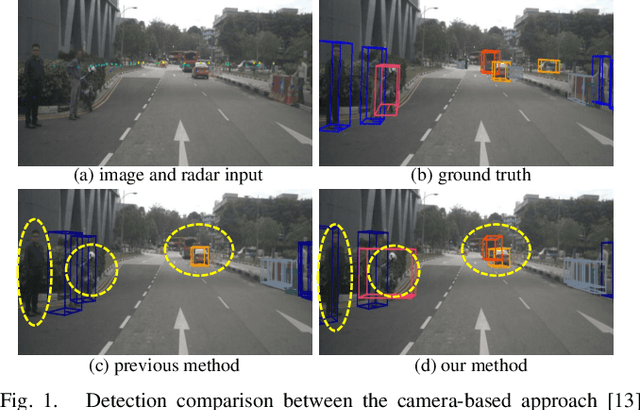
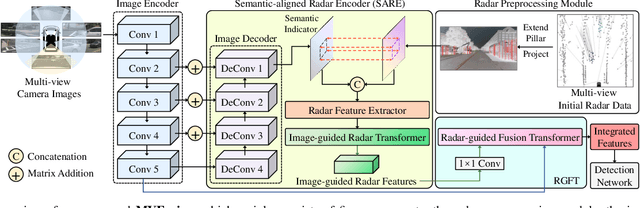

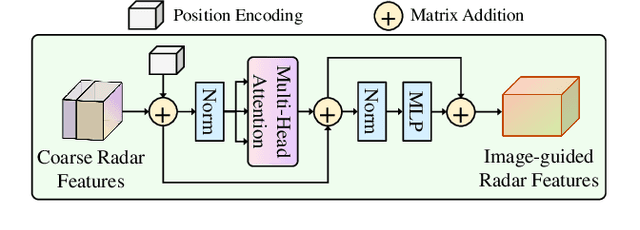
Multi-view radar-camera fused 3D object detection provides a farther detection range and more helpful features for autonomous driving, especially under adverse weather. The current radar-camera fusion methods deliver kinds of designs to fuse radar information with camera data. However, these fusion approaches usually adopt the straightforward concatenation operation between multi-modal features, which ignores the semantic alignment with radar features and sufficient correlations across modals. In this paper, we present MVFusion, a novel Multi-View radar-camera Fusion method to achieve semantic-aligned radar features and enhance the cross-modal information interaction. To achieve so, we inject the semantic alignment into the radar features via the semantic-aligned radar encoder (SARE) to produce image-guided radar features. Then, we propose the radar-guided fusion transformer (RGFT) to fuse our radar and image features to strengthen the two modals' correlation from the global scope via the cross-attention mechanism. Extensive experiments show that MVFusion achieves state-of-the-art performance (51.7% NDS and 45.3% mAP) on the nuScenes dataset. We shall release our code and trained networks upon publication.
Schema Inference for Interpretable Image Classification
Mar 12, 2023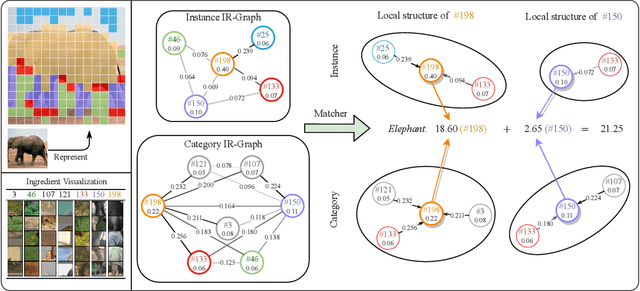
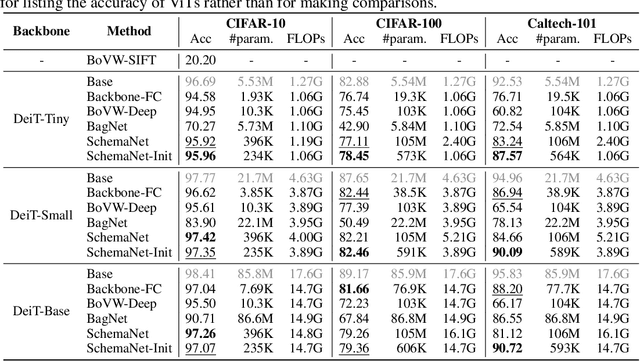
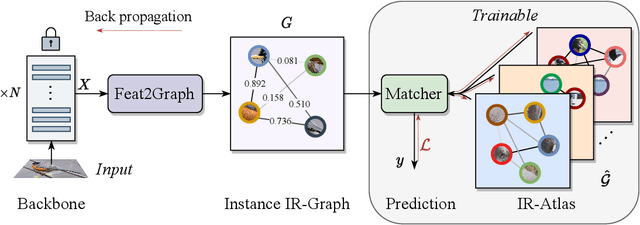
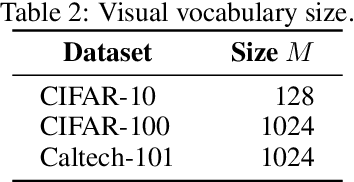
In this paper, we study a novel inference paradigm, termed as schema inference, that learns to deductively infer the explainable predictions by rebuilding the prior deep neural network (DNN) forwarding scheme, guided by the prevalent philosophical cognitive concept of schema. We strive to reformulate the conventional model inference pipeline into a graph matching policy that associates the extracted visual concepts of an image with the pre-computed scene impression, by analogy with human reasoning mechanism via impression matching. To this end, we devise an elaborated architecture, termed as SchemaNet, as a dedicated instantiation of the proposed schema inference concept, that models both the visual semantics of input instances and the learned abstract imaginations of target categories as topological relational graphs. Meanwhile, to capture and leverage the compositional contributions of visual semantics in a global view, we also introduce a universal Feat2Graph scheme in SchemaNet to establish the relational graphs that contain abundant interaction information. Both the theoretical analysis and the experimental results on several benchmarks demonstrate that the proposed schema inference achieves encouraging performance and meanwhile yields a clear picture of the deductive process leading to the predictions. Our code is available at https://github.com/zhfeing/SchemaNet-PyTorch.
Scale-aware Two-stage High Dynamic Range Imaging
Mar 12, 2023
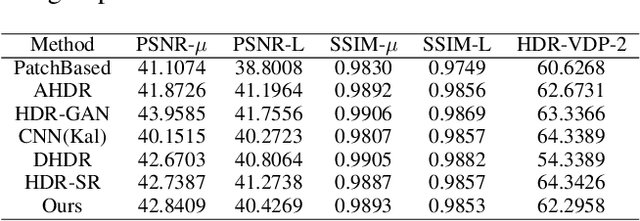
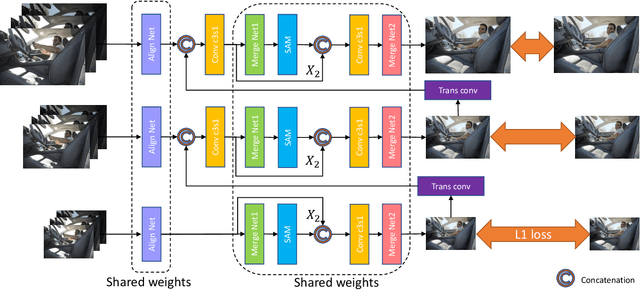
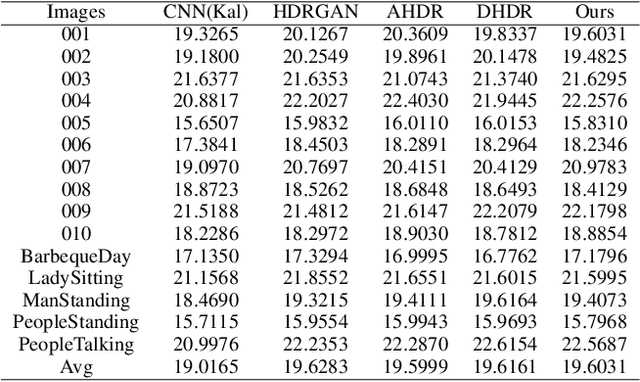
Deep high dynamic range (HDR) imaging as an image translation issue has achieved great performance without explicit optical flow alignment. However, challenges remain over content association ambiguities especially caused by saturation and large-scale movements. To address the ghosting issue and enhance the details in saturated regions, we propose a scale-aware two-stage high dynamic range imaging framework (STHDR) to generate high-quality ghost-free HDR image. The scale-aware technique and two-stage fusion strategy can progressively and effectively improve the HDR composition performance. Specifically, our framework consists of feature alignment and two-stage fusion. In feature alignment, we propose a spatial correct module (SCM) to better exploit useful information among non-aligned features to avoid ghosting and saturation. In the first stage of feature fusion, we obtain a preliminary fusion result with little ghosting. In the second stage, we conflate the results of the first stage with aligned features to further reduce residual artifacts and thus improve the overall quality. Extensive experimental results on the typical test dataset validate the effectiveness of the proposed STHDR in terms of speed and quality.
Non-orthogonal multiple access enhanced multi-user semantic communication
Mar 12, 2023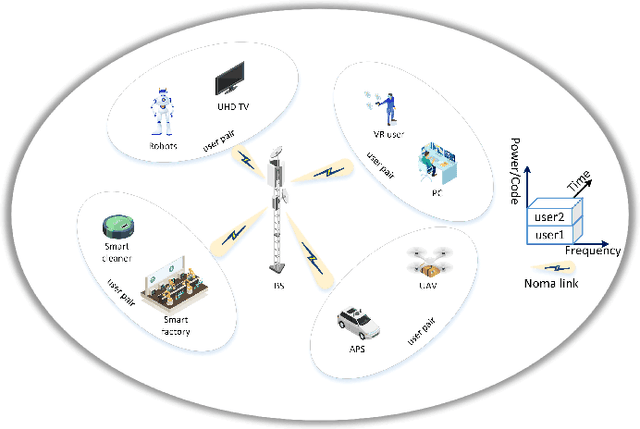
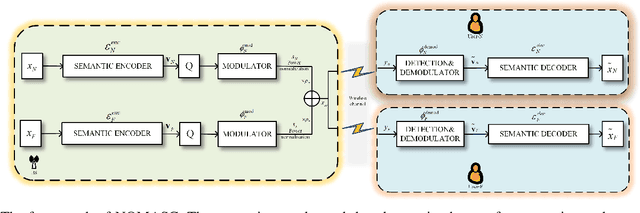
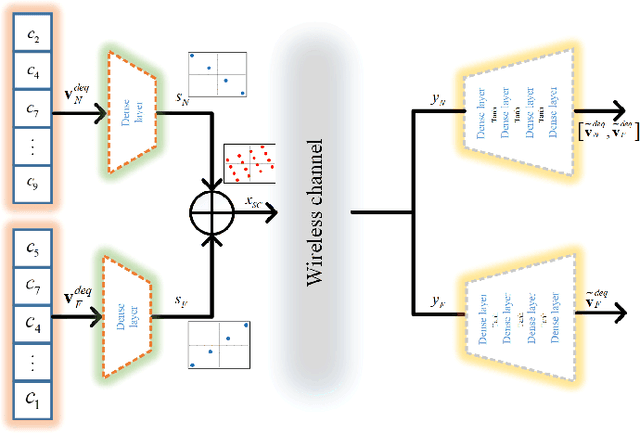
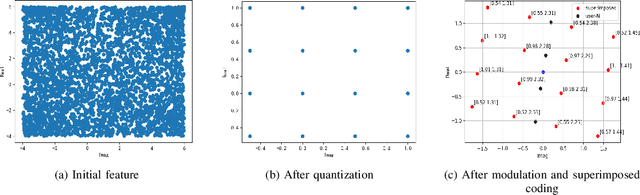
Semantic communication serves as a novel paradigm and attracts the broad interest of researchers. One critical aspect of it is the multi-user semantic communication theory, which can further promote its application to the practical network environment. While most existing works focused on the design of end-to-end single-user semantic transmission, a novel non-orthogonal multiple access (NOMA)-based multi-user semantic communication system named NOMASC is proposed in this paper. The proposed system can support semantic tranmission of multiple users with diverse modalities of source information. To avoid high demand for hardware, an asymmetric quantizer is employed at the end of the semantic encoder for discretizing the continuous full-resolution semantic feature. In addition, a neural network model is proposed for mapping the discrete feature into self-learned symbols and accomplishing intelligent multi-user detection (MUD) at the receiver. Simulation results demonstrate that the proposed system holds good performance in non-orthogonal transmission of multiple user signals and outperforms the other methods, especially at low-to-medium SNRs. Moreover, it has high robustness under various simulation settings and mismatched test scenarios.